kafka入门:简介、使用场景、设计原理
2019独角兽企业重金招聘Python工程师标准>>> 
问题导读:
1.zookeeper在kafka的作用是什么?
2.kafka中几乎不允许对消息进行“随机读写”的原因是什么?
3.kafka集群consumer和producer状态信息是如何保存的?
4.partitions设计的目的的根本原因是什么?
一、入门
1、简介
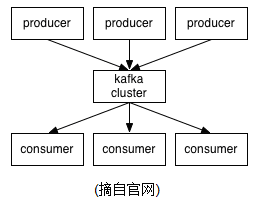
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
2、Topics/logs
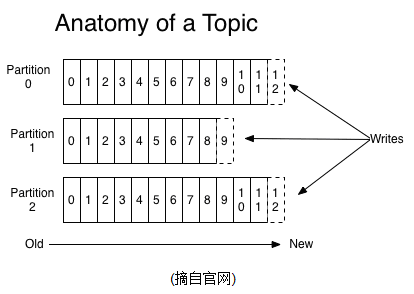
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
kafka和JMS(Java Message Service)实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值..(offset将会保存在zookeeper中,参见下文)
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响.
partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.(具体原理参见下文).
3、Distribution
一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等.
Consumers
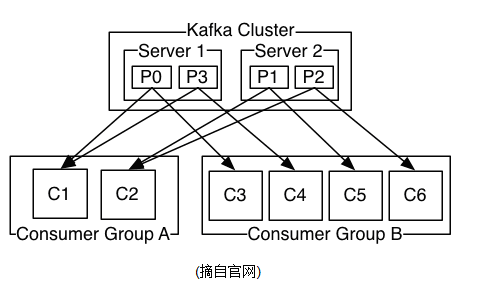
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.
Guarantees
1) 发送到partitions中的消息将会按照它接收的顺序追加到日志中
2) 对于消费者而言,它们消费消息的顺序和日志中消息顺序一致.
3) 如果Topic的"replicationfactor"为N,那么允许N-1个kafka实例失效.
二、使用场景
1、Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的"事务性""消息传输担保(消息确认机制)""消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2、Websit activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、Log Aggregation
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统.
三、设计原理
kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力.
1、持久性
kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性.且无论任何OS下,对文件系统本身的优化几乎没有可能.文件缓存/直接内存映射等是常用的手段.因为kafka是对日志文件进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数.
2、性能
需要考虑的影响性能点很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题.kafka并没有提供太多高超的技巧;对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker;对于consumer端也是一样,批量fetch多条消息.不过消息量的大小可以通过配置文件来指定.对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换. 其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑.可以将任何在网络上传输的消息都经过压缩.kafka支持gzip/snappy等多种压缩方式.
3、生产者
负载均衡: producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会经过任何"路由层".事实上,消息被路由到哪个partition上,有producer客户端决定.比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的.
其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更事件.
异步发送:将多条消息暂且在客户端buffer起来,并将他们批量的发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。不过这也有一定的隐患,比如说当producer失效时,那些尚未发送的消息将会丢失。
4、消费者
consumer端向broker发送"fetch"请求,并告知其获取消息的offset;此后consumer将会获得一定条数的消息;consumer端也可以重置offset来重新消费消息.
在JMS实现中,Topic模型基于push方式,即broker将消息推送给consumer端.不过在kafka中,采用了pull方式,即consumer在和broker建立连接之后,主动去pull(或者说fetch)消息;这中模式有些优点,首先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息消费的数量,batch fetch.
其他JMS实现,消息消费的位置是有prodiver保留,以便避免重复发送消息或者将没有消费成功的消息重发等,同时还要控制消息的状态.这就要求JMS broker需要太多额外的工作.在kafka中,partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见kafka broker端是相当轻量级的.当消息被consumer接收之后,consumer可以在本地保存最后消息的offset,并间歇性的向zookeeper注册offset.由此可见,consumer客户端也很轻量级.
5、消息传送机制
对于JMS实现,消息传输担保非常直接:有且只有一次(exactly once).在kafka中稍有不同:
1) at most once: 最多一次,这个和JMS中"非持久化"消息类似.发送一次,无论成败,将不会重发.
2) at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功.
3) exactly once: 消息只会发送一次.
at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后"未处理"的消息将不能被fetch到,这就是"at most once".
at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态.
exactly once: kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的.
通常情况下"at-least-once"是我们搜选.(相比at most once而言,重复接收数据总比丢失数据要好).
6、复制备份
kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower和consumer一样,消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它.即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(不同于其他分布式存储,比如hbase需要"多数派"存活才行)
当leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个"up-to-date"的follower.选择follower时需要兼顾一个问题,就是新leaderserver上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.在选举新leader,需要考虑到"负载均衡".
7.日志
如果一个topic的名称为"my_topic",它有2个partitions,那么日志将会保存在my_topic_0和my_topic_1两个目录中;日志文件中保存了一序列"log entries"(日志条目),每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置..每个partition在物理存储层面,有多个log file组成(称为segment).segmentfile的命名为"最小offset".kafka.例如"00000000000.kafka";其中"最小offset"表示此segment中起始消息的offset.

其中每个partiton中所持有的segments列表信息会存储在zookeeper中.
当segment文件尺寸达到一定阀值时(可以通过配置文件设定,默认1G),将会创建一个新的文件;当buffer中消息的条数达到阀值时将会触发日志信息flush到日志文件中,同时如果"距离最近一次flush的时间差"达到阀值时,也会触发flush到日志文件.如果broker失效,极有可能会丢失那些尚未flush到文件的消息.因为server意外实现,仍然会导致log文件格式的破坏(文件尾部),那么就要求当server启东是需要检测最后一个segment的文件结构是否合法并进行必要的修复.
获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数).根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可.
日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表,把保存时间超过阀值的文件直接删除(根据文件的创建时间).为了避免删除文件时仍然有read操作(consumer消费),采取copy-on-write方式.
关于kafka说明可以参考:http://kafka.apache.org/documentation.html
转载于:https://my.oschina.net/stephenzhang/blog/537625
kafka入门:简介、使用场景、设计原理相关推荐
- Kafka学习总结(1)——Kafka入门简介
Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务.它主要用于处理活跃的流式数据. ...
- 转—正弦波逆变器入门到精通----逆变器设计原理
下文部分引用自电源网,是一篇介绍逆变器的实际设计原理的文章,部分电路在实验室验证过,效果不错,本文只涉及原理不涉及实物及参数.当时手头需要做一个功率较大的光伏发电电路,要求系统最大功率追踪,且实现并网 ...
- 大数据之Kafka入门简介
目录 前言: 1.Kafka是什么 2.JMS是什么 3.Kafka核心组件(重点) 总结: 目录 前言: 作为流式计算中的一个组件,对于它的组成以及运行的原理,学习者也需要相关的了解.以下主要简单介 ...
- 快速入门ESP32的硬件设计原理以及典型应用案例UART串口转WIFI智能硬件,以及ESP32-Lyra(智能音频台)设计方案。
前言:可私信免费领取 该手册是中文版的ESP32硬件设计指南,提供了ESP32 系列产品的硬件信息,包括ESP32 芯片,ESP-WROOM-32 模组以及ESP32-DevKitC 开发板.包含开发 ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
为什么80%的码农都做不了架构师?>>> kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 问题导读: 1.zookeeper在kafka的作用是什么? 2. ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建--转载
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- 李克华 云计算高级群: 292870151 195907286 交流:Hadoop、NoSQL、分布式、lucene、solr、nutch kafka入门:简介、使用场景、设计原理、主要配置及集群搭
一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设计实现上完全不同 ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭
李克华 云计算高级群: 292870151 195907286 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch kafka入门:简介.使用场景.设计原理.主要配置及集群搭 ...
- kafka分区与分组原理_大数据技术-Kafka入门
在大数据学习当中,主要的学习重点就是大数据技术框架,针对于大数据处理的不同环节,需要不同的技术框架来解决问题.以Kafka来说,主要就是针对于实时消息处理,在大数据平台当中的应用也很广泛.大数据学习一 ...
最新文章
- Bootstrap -- 插件: 按钮状态、折叠样式、轮播样式
- 网络:窗口控制下的重发机制、流量控制
- 一分钟快速入门openstack
- ITK:在图像中找到最大和最小
- linux cd 一些用法
- vb怎样同时打开2个excel工作簿_【赠书】不打开工作簿也能批量合并不同文件夹下多个表格的数据...
- app自动化之移动端测试基础知识
- IntelliJ IDEA 下载安装以及破解码大集合
- (哈工大)计算机网络体系结构——OSI、TCP/IP、5层模型
- 传递组播与广播帧:数据待传指示传递信息(DTIM)
- 从unity3d官网下载教程
- 各银行信用卡延误险整理
- python 吉他_Python中用于比较吉他弦的Matplotlib幅值_频谱单位
- 数据科学如此火爆,为什么找个工作还那么难?
- 怎么把分钟转化成秒_一分钟短视频文案范文怎么写?短视频文案必爆公式分享(附文案范文模板)...
- You Can’t Future-Proof Solutions
- 【元胞自动机】元胞自动机双边教室疏散【含Matlab源码 1208期】
- Kali linux学习入门-Kali菜单中各工具功能
- 大学计算机在线作业答案,上海交通大学《计算机》在线作业二参考答案
- 【毕业N年系列】 毕业第一年
热门文章
- knx智能照明控制系统电路图_智能照明控制系统(KNX)讲解
- python xml etree_Python 标准库之 xml.etree.ElementTree
- 西交大计算机系分数线,西安交通大学专业排名及分数线
- php单例模式详解,PHP 单例模式解析和实战
- BPSK、8PSK、QPSK、16QAM、64QAM区别与联系
- zabbix重点笔记
- centos6.0 LAMP源码安装
- 10 Linux之yum源码安装
- 短信猫JAVA二次开发包SMSLib,org.smslib.TimeoutException: No response from device解决方案...
- python采集人脸_python获取人脸的代码分享