Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货!
SparkSQL数据源:从各种数据源创建DataFrame
因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的代码优化,生成以及执行流程,所以 sql,dataframe,datasets 的入口都是 sqlContext。
可用于创建 spark dataframe 的数据源有很多:

SparkSQL数据源:RDD
val sqlContext = new org.apache.spark.sql.SQLContext(sc)// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._// Define the schema using a case class.case class Person(name: String, age: Int)// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)) sqlContext.createDataFrame(people)SparkSQL数据源:Hive
当从Hive 中读取数据时,Spark SQL 支持任何Hive 支持的存储格式(SerDe),包括文件、RCFiles、ORC、Parquet、Avro,以及Protocol Buffer(当然Spark SQL也可以直接读取这些文件)。
要连接已部署好的Hive,需要拷贝hive-site.xml、core-site.xml、hdfs-site.xml到Spark 的./conf/ 目录下即可
如果不想连接到已有的hive,可以什么都不做直接使用HiveContext:
Spark SQL 会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作metastore_db
如果你尝试使用HiveQL 中的CREATE TABLE(并非CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的/user/hive/warehouse 目录中(如果你的classpath 中有配好的hdfs-site.xml,默认的文件系统就是HDFS,否则就是本地文件系统)。
SparkSQL数据源:Hive读写
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
SparkSQL数据源:访问不同版本的metastore
从Spark1.4开始,Spark SQL可以通过修改配置去查询不同版本的?Hive metastores(不用重新编译)

SparkSQL数据源:Parquet
Parquet(http://parquet.apache.org/)是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。
Parquet 格式经常在Hadoop 生态圈中被使用,它也支持Spark SQL 的全部数据类型。Spark SQL 提供了直接读取和存储Parquet 格式文件的方法。
val sqlContext = new org.apache.spark.sql.SQLContext(sc)// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._// Define the schema using a case class.case class Person(name: String, age: Int)// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()people.write.parquet("xxxx")val parquetFile = sqlContext.read.parquet("people.parquet")//Parquet files can also be registered as tables and then used in SQL statements.parquetFile.registerTempTable("parquetFile")val teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")teenagers.map(t => "Name: " + t(0)).collect().foreach(println)SparkSQL数据源:Parquet-- Partition Discovery
在Hive中通常会用分区表来优化性能,比如:
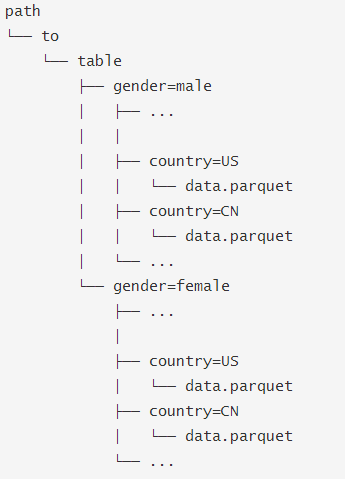
SQLContext.read.parquet或者SQLContext.read.load只需要指定path/to/table,SparkSQL会自动从路径中提取分区信息,返回的DataFrame 的schema 将是:

当然你可以使用Hive读取方式:
hiveContext.sql("FROM src SELECT key, value").
SparkSQL数据源:Json
SparkSQL支持从Json文件或者Json格式的RDD读取数据
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 可以是目录或者文件夹val path = "examples/src/main/resources/people.json"val people = sqlContext.read.json(path)// The inferred schema can be visualized using the printSchema() method.
people.printSchema()// Register this DataFrame as a table.people.registerTempTable("people")// SQL statements can be run by using the sql methods provided by sqlContext.val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")// Alternatively, a DataFrame can be created for a JSON dataset represented by// an RDD[String] storing one JSON object per string.val anotherPeopleRDD = sc.parallelize("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)val anotherPeople = sqlContext.read.json(anotherPeopleRDD)SparkSQL数据源:JDBC
val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:postgresql:dbserver","dbtable" -> "schema.tablename")).load()支持的参数:
![]()
转载于:https://www.cnblogs.com/zlslch/p/6944860.html
Spark SQL 编程API入门系列之SparkSQL数据源相关推荐
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了"池"的概念. 引入"HBase里的连接池" ...
- Hadoop MapReduce编程 API入门系列之查找相同字母组成的字谜(三)
找出相同单词的所有单词.现在,是拿取部分数据集(如下)来完成本项目. 项目需求 一本英文书籍包含成千上万个单词或者短语,现在我们需要在大量的单词中,找出相同字母组成的所有anagrams(字谜). 思 ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)...
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)...
本博文的主要内容是: 1.rdd基本操作实战 2.transformation和action流程图 3.典型的transformation和action RDD有3种操作: 1. Trandform ...
- Windows SDK编程 API入门系列(转)
之一 -那'烦人'的Windows数据类型 原创文章,转载请注明作者及出处. 首发 http://blog.csdn.net/beyondcode http://www.cnblogs.com/bey ...
- HBase编程 API入门系列之put(客户端而言)(1)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. [hadoop@HadoopSlave1 conf]$ cat regionservers HadoopMaster Hadoop ...
- Hadoop MapReduce编程 API入门系列之join(二十六)
天气记录数据库 气象站数据库 气象站和天气记录合并之后的示意图如下所示. 011990-99999 SIHCCAJAVRI 195005150700 0 011990-99999 SIHCCAJAVR ...
最新文章
- 上交2017计算机专业就业,上海交通大学计算机科学与工程系(CSE)
- vue点击改变data_vue实现响应式原理即vue如何监听data的每个属性的变化
- 数据库计划中的14个才略
- MapReduce-Reduce端join操作-步骤分析
- 二、python框架相关知识体系
- php过滤掉不乱码json,PHP JSON编码后,中文乱码的解决方式
- mysql identity 获取_如何获取MySQL中Identity列的种子值?
- html lineheight div,html – Chrome上的文本输入:line-height似乎有最小值
- RocketMQ的一些基本概念和RocketMQ特性的讲解
- java 扫描自定义注解_利用spring 自定义注解扫描 找出使用自定义注解的类
- rhel6mysql管理_RHEL 6平台MySQL数据库服务器的安装方法
- net framework 4.0安装未成功,原因是?
- VSCode安装教程详细简单版
- 读取金税盘数据库_金税盘无法连接数据库是怎么回事
- 面试时,当HR问“你有什么要问我的吗”时,应该问什么?
- optim优化器的使用
- wireshark排查网络延迟问题
- Android Canvas.scale缩放
- SAP 各个模块简介以及常用的数据表
- 软 RAID 和硬 RAID的比较概览
热门文章
- 【OpenJ_Bailian - 2299 】Ultra-QuickSort (归并排序 或 离散化 + 树状数组)
- mysql录数据总是错误_MySQL数据库出错
- mysql中error 1786_mysql错误处理之ERROR1786(HY000)_MySQL
- centos php mysql 5.6 安装_centos7安装nginx、php5.5、mysql5.6
- 华为副总鸿蒙,“哄蒙”败北!华为副总裁落实最新消息,鸿蒙3月31日正式亮剑...
- c#和python更适合爬虫_python在爬虫方面有哪些优势呢?
- linux 商业游戏,Ubuntu下安装试玩原生Linux版商业游戏Braid
- 最强阿里巴巴历年经典面试题汇总:C++研发岗
- 简单暴力到dp的优化(初级篇)
- SPI、I2C、UART 三种串行总线对比介绍