Rocketmq源码分析(一)整体架构
1 系列
- 整体架构图
- producer端发送消息
- broker端接收消息
- broker端消息的存储
- consumer消费消息
- 分布式事务的实现
- 定时消息的实现
- 关于顺序消费
- 关于重复消息
- 关于高可用
2 整体架构图
先来看下官方给出的整体架构图
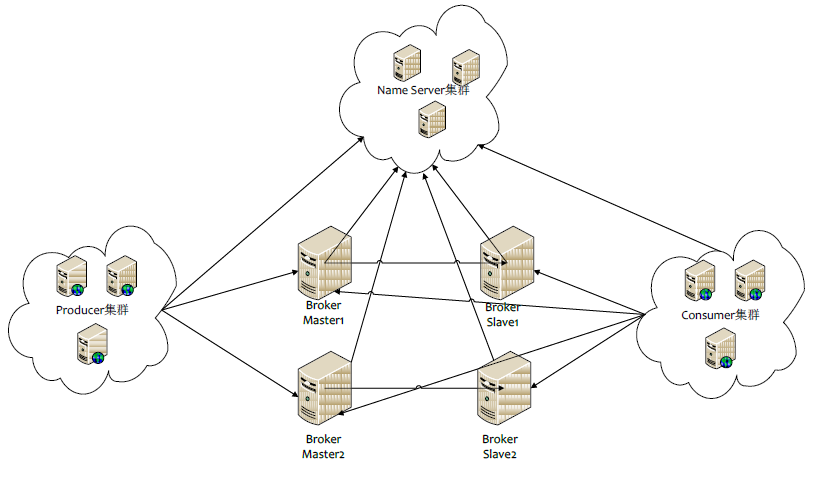
- Producer集群:拥有相同的producerGroup,一般来讲,Producer不必要有集群的概念,这里的集群仅仅在RocketMQ的分布式事务中有用到
- Name Server集群:提供topic的路由信息,路由信息数据存储在内存中,broker会定时的发送路由信息到nameserver中的每一个机器,来进行更新,所以name server集群可以简单理解为无状态(实际情况下可能存在每个nameserver机器上的数据有短暂的不一致现象,但是通过定时更新,大部分情况下都是一致的)
- broker集群:一个集群有一个统一的名字,即brokerClusterName,默认是DefaultCluster。一个集群下有多个master,每个master下有多个slave。master和slave算是一组,拥有相同的brokerName,不同的brokerId,master的brokerId是0,而slave则是大于0的值。master和slave之间可以进行同步复制或者是异步复制。
- consumer集群:拥有相同的consumerGroup。
下面来说说他们之间的通信关系
- Producer和Name Server:每一个Producer会与Name Server集群中的一台机器建立TCP连接,会从这台Name Server上拉取路由信息。
- Producer和broker:Producer会和它要发送的topic相关的master类型的broker建立TCP连接,用于发送消息以及定时的心跳信息。broker中会记录该Producer的信息,供查询使用
- broker与Name Server:broker(不管是master还是slave)会和每一台Name Server机器来建立TCP连接。broker在启动的时候会注册自己配置的topic信息到Name Server集群的每一台机器中。即每一台Name Server都有该broker的topic的配置信息。master与master之间无连接,master与slave之间有连接
- Consumer和Name Server:每一个Consumer会和Name Server集群中的一台机器建立TCP连接,会从这台Name Server上拉取路由信息,进行负载均衡
- Consumer和broker:Consumer可以与master或者slave的broker建立TCP连接来进行消费消息,Consumer也会向它所消费的broker发送心跳信息,供broker记录。
3 kafka的架构图
来看下kafka的整体架构图
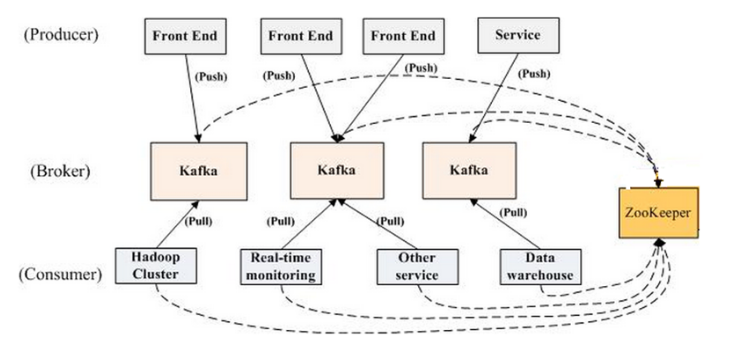
来看看他们之间的连接关系
- Producer和broker:Producer会和它所要发送的topic相关的broker建立TCP连接,并通过broker进行其他broker的发现(这个没有依赖ZooKeeper进行服务发现)
- broker和ZooKeeper:broker会将自己注册在ZooKeeper上,同时依赖ZooKeeper做一些分布式协调
- Consumer和ZooKeeper:Consumer会将自己注册在ZooKeeper上,同时依赖ZooKeeper进行broker发现以及将消费offset记录在ZooKeeper上
- Consumer和Broker:Consumer连接topic相关的broker进行消息的消费
4 RocketMQ和kafka的对比
4.1 消息的存储
我们知道topic是一类消息的统称,为了提高消息的写入和读取并发能力,将一个topic的消息进行拆分,可以分散到多个broker中。kafka上称为分区,而RocketMQ称为队列。
对于kafka:为了防止一个分区的消息文件过大,会拆分成一个个固定大小的文件,所以一个分区就对应了一个目录。分区与分区之间是相互隔离的。
对于RocketMQ:则是所有topic的数据混在一起进行存储,默认超过1G的话,则重新创建一个新的文件。消息的写入过程即写入该混杂的文件中,然后又有一个线程服务,在不断的读取分析该混杂文件,将消息进行分拣,然后存储在对应队列目录中(存储的是简要信息,如消息在混杂文件中的offset,消息大小等)
所以RocketMQ需要2次寻找,第一次先找队列中的消息概要信息,拿到概要信息中的offset,根据这个offset再到混杂文件中找到想要的消息。而kafka则只需要直接读取分区中的文件即可得到想要的消息。
看下这里给出的RocketMQ的日志文件图片分布式开放消息系统(RocketMQ)的原理与实践
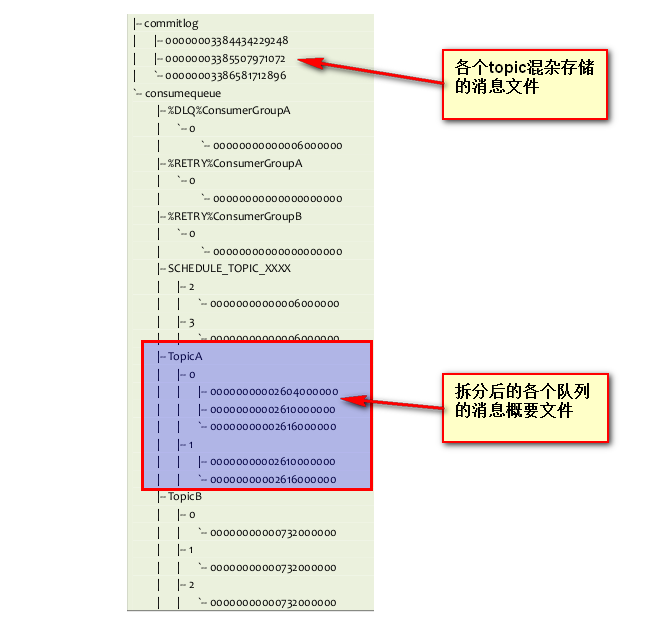
这里我自己认为RocketMQ的做法还是值得商榷的,这样的做法在同步刷盘、异步刷盘时效率相对高些(由于量大所以效率相对高些),但是全部的topic往一个文件里面写,每次写入要进行加锁控制,本来不相干的topic却相互影响,就降低的写入的效率。这个锁的粒度有点大了,我自己认为应该一个队列对应一个CommitLog,这样做就是减少锁的粒度问题。
4.1 Prdocuer端的服务发现
就是Producer端如何来发现新的broker地址。
对于kafka来说:Producer端需要配置broker的列表地址,Producer也从一个broker中来更新broker列表地址(从中发现新加入的broker)。
对于RocketMQ来说:Producer端需要Name Server的列表地址,同时还可以定时从一个HTTP地址中来获取最新的Name Server的列表地址,然后从其中的一台Name Server来获取全部的路由信息,从中发现新的broker。
4.1 消费offset的存储
对于kafka:Consumer将消费的offset定时存储到ZooKeeper上,利用ZooKeeper保障了offset的高可用问题。
对于RocketMQ:Consumer将消费的offset定时存储到broker所在的机器上,这个broker优先是master,如果master挂了的话,则会选择slave来存储,broker也是将这些offset定时刷新到本地磁盘上,同时slave会定时的访问master来获取这些offset。
4.2 consumer负载均衡
对于负载均衡,在出现分区或者队列增加或者减少的时候、Consumer增加或者减少的时候都会进行reblance操作。
对于RocketMQ:客户端自己会定时对所有的topic的进行reblance操作,对于每个topic,会从broker获取所有Consumer列表,从broker获取队列列表,按照负载均衡策略,计算各自负责哪些队列。这种就要求进行负载均衡的时候,各个Consumer获取的数据是一致的,不然不同的Consumer的reblance结果就不同。
对于kafka:kafka之前也是客户端自己进行reblance,依靠ZooKeeper的监听,来监听上述2种情况的出现,一旦出现则进行reblance。现在的版本则将这个reblance操作转移到了broker端来做,不但解决了RocketMQ上述的问题,同时减轻了客户端的操作,是的客户端更加轻量级,减少了和其他语言集成的工作量。详细见这篇文章Kafka设计解析(四):Kafka Consumer解析
4.3 Name Server和ZooKeeper
Name Server和ZooKeeper的作用大致是相同的,从宏观上来看,Name Server做的东西很少,就是保存一些运行数据,Name Server之间不互连,这就需要broker端连接所有的Name Server,运行数据的改动要发送到每一个Name Server来保证运行数据的一致性(这个一致性确实有点弱),这样就变成了Name Server很轻量级,但是broker端就要做更多的东西了。
而ZooKeeper呢,broker只需要连接其中的一台机器,运行数据分发、一致性都交给了ZooKeeper来完成。
目前先就这几个大的组件进行简单的对比,后续会对某些细节进行详细说明。
Rocketmq源码分析(一)整体架构相关推荐
- jQuery 2.0.3 源码分析core - 整体架构
拜读一个开源框架,最想学到的就是设计的思想和实现的技巧. 废话不多说,jquery这么多年了分析都写烂了,老早以前就拜读过, 不过这几年都是做移动端,一直御用zepto, 最近抽出点时间把jquery ...
- jQuery源码分析系列 : 整体架构
query这么多年了分析都写烂了,老早以前就拜读过, 不过这几年都是做移动端,一直御用zepto, 最近抽出点时间把jquery又给扫一遍 我也不会照本宣科的翻译源码,结合自己的实际经验一起拜读吧! ...
- Nmap源码分析(整体架构)
整体架构 功能目录 docs :相关文档 libdnet-stripped :开源网络接口库 liblinear:开源大型线性分类库 liblua:开源Lua脚本语言库 libnetutil:基本的网 ...
- Mongodb 源码分析:整体架构
最近一直在学习Mongodb的源码,很希望能够搞清楚Mongodb内部的具体实现.从Mongodb中文社区和其他人的博客里面学到了很多, 因此, 开了这个博客希望把自己学到的一些分享给大家. 任何源码 ...
- 《RocketMQ源码分析》NameServer如何处理Broker的连接
<RocketMQ源码分析>NameServer如何处理Broker的连接 NameServer 介绍 NameServer 功能 动态路由发现和注册 服务剔除 创建NameServerC ...
- RocketMQ源码分析之延迟消息
文章目录 前言 一.延迟消息 1.特点 2.使用场景 3.demo 二.发送延迟消息 三.broker端存储延迟消息 四.总结 1.延迟消息工作原理 2.延迟消息在消费者消费重试中的应用 前言 本篇文 ...
- mq消费者组_「架构师MQ进阶」RocketMQ源码分析(四)- 源代码包结构分析
在前面第一篇中已经将源代码下载到本地了,本篇主要是介绍代码中相关模块到作用.036.Rocket-MQ-Source-code-cover.png 一.源码结构 RocketMQ源码组织方式基于Mav ...
- underscore源码剖析之整体架构
前言 最近打算好好看看underscore源码,一个是因为自己确实荒废了基础,另一个是underscore源码比较简单,比较易读. 本系列打算对underscore1.8.3中关键函数源码进行分析,希 ...
- RocketMQ 源码分析 —— 集成 Spring Boot
点击上方"芋道源码",选择"设为星标" 做积极的人,而不是积极废人! 源码精品专栏 原创 | Java 2020 超神之路,很肝~ 中文详细注释的开源项目 RP ...
- RocketMQ源码分析之RocketMQ事务消息实现原理上篇(二阶段提交)
在阅读本文前,若您对RocketMQ技术感兴趣,请加入 RocketMQ技术交流群 根据上文的描述,发送事务消息的入口为: TransactionMQProducer#sendMessageInTra ...
最新文章
- 当今世界最受人们重视的十大经典算法
- .net框架读书笔记---通用对象操作(一)
- 怎样快速掌握深度学习TensorFlow框架?
- 百度seo排名点击器_SEO整站优化思路 - 百度seo排名点击
- 阿里P8架构师谈:JVM的内存分配、运行原理、回收算法机制
- Oracle 实验7 存储过程
- java中的泛型(E)
- CSS3/jQuery创意盒子动画菜单
- OpenCL将数组从内存copy到显存
- opencv 修改 读取路径_opencv中读取图像的绝对路径问题
- Mac安装Python并使用GUI界面设计
- 有关费尔防火墙一书TDI代码“网上邻居”不能访问功能的修复
- 软件项目工作量评估方法COSMIC重点笔记
- [week15] ZJM 与霍格沃兹 —— 字符串哈希
- PR免费转场 PR剪辑视频图形转场PR动态图形模板MOGRT
- Android动画 补间动画
- 学习笔记:星火第一讲-使用Apollo 学习自动驾驶
- Rails 用 RJS 简单有效的实现页面局部刷新
- arm rtx教程_【RTX操作系统教程】第4章 RTX操作系统介绍
- 移动、电信、联通、QQ币、游戏点卡快速秒充体验
热门文章
- 图像融合亮度一致_博文精选 | 基于深度学习的低光照图像增强方法总结
- 设置一个双色球脚本(2)并带颜色输出
- Maven 加载ojdbc14.jar报错,解决方法
- 转机器学习系列(9)_机器学习算法一览(附Python和R代码)
- 在linux oracle 10g/11g x64bit环境中,goldengate随os启动而自己主动启动的脚本
- 跟新centos的yum源
- andorid程序UI线程下开启子线程闪退错误解决
- Android—开发过程中的相关注意事项
- python播放wav文件_python3 写一个WAV音频文件播放器的代码
- linux 怎么设置静态ip,如何在Linux中设置静态IP地址和配置网络