大数据学习——Flume入门
文章目录
- 一、Flume概述
- 1.1、Flume定义
- 1.2、Flume基础架构
- 二、Flume快速入门
- 2.1、安装Flume部署
- 2.2、入门案例
- 2.2.1、监控端口数据(官方案例)
- 2.2.2、实时监控单个追加文件
- 2.2.3、监控文件 升级版
- 2.2.4、监控文件夹变化
- 2.2.5、断点续传——实时监控目录文件追加修改
- 三、Flume进阶
- 3.1、Flume事务
- 3.2、Agent内部原理
- 3.3、拓扑结构
- 3.3.1、简单串联
- 3.3.2、合并(Consolidation)
- 3.3.3、多路复用
- 3.3.4、负载均衡和故障转移
- 3.4、开发案例
- (一)、复制以及多路复用
- (二)、负载均衡和故障转移
- (三)、聚合(Consolidation)
- 3.5、自定义Interceptor(拦截器)
- 3.6、自定义Source
- 3.7、自定义Sink
- 四、常见面试题
- 四、常见面试题
一、Flume概述
![]()
1.1、Flume定义
Flume是Cloudera(Hadoop的三大发型版本之一公司)提供的一个高可用,高可靠的分布式的海量日志采集、聚合和传输系统。Flume基于流式架构,灵活简单
为什么使用Flume
我们Java后台的日志数据需要使用大数据工具来进行实时分析处理时候,就需要通过Flume来进行流式采集,交给大数据服务器进行分析计算。解决的就是这个实时问题!
如果对实时性要求不高的场景也可以选择每天定时上传日志文件到HDFS上,也就用不到Flume。
Flume的主要作用:实时读取服务器本地磁盘的数据,并将数据写入到HDFS!
1.2、Flume基础架构
![]()
Flume在服务器运行时,是一个JVM进程(Agent),运行在JVM虚拟机上。以事件(Event)的形式将数据从源头传输到目的地。
三大组件
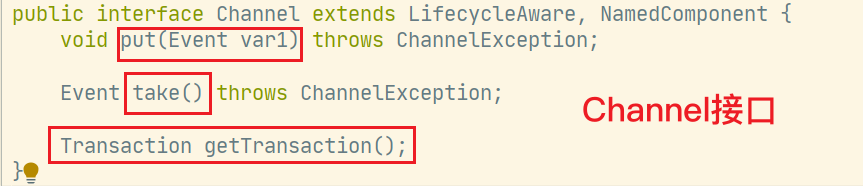
Source:对接外部用于采集日志数据
Channel:作为缓冲区调节Source读取和Sink写出

Sink:对接外部用于写出数据
以上三个组件在特殊的开发环境下支持自定义!!
Event
是Flume在传输数据的传输单元,以Event的形式将数据从源头传输到目的地。
由两部分构成:
- Header存放该event的一些属性(KV结构)
- Body存放传输的数据内容(字节数组)
结构有点类似网络信息传输的包。
二、Flume快速入门
Flume官网地址
Flume全版本下载地址当前最新版本为1.9.0,本次我们学习使用1.7.0版本!
Flume1.7.0用户使用文档
2.1、安装Flume部署
将压缩包放入/opt/software目录下
解压到/opt/module目录中
tar -zxvf /opt/software/apache-hive-1.7.0 -C /opt/module/将其目录下conf/目录中flume-env.sh.template改名为flume-env.sh,并进行以下配置
export JAVA_HOME=/opt/module/jdk1.8.0_251
2.2、入门案例
2.2.1、监控端口数据(官方案例)
案例需求:
使用Flume监听端口(NetCat Source),将端口中传输过来的数据 输出到控制台(Logger Sink)。
步骤实现
安装netcat工具
sudo yum install -y ncnetcat的基本使用
使用
nc -lk port开启对端口xxx的持续监听(-lk:listen,keep open)(服务端)
在另一台主机上使用
nc hostname port与对应主机上的端口建立连接(客户端)然后客户端和服务端就可以相互通信了!!
一旦服务端停止,客户端相继断开。
判断44444端口是否被占用
sudo netstat -tunlp | grep 44444创建Flume-Agent配置文件
flume-netcat-logger.conf在flume的根目录下创建job文件夹,在job文件夹中创建此配置文件。并添加一下内容(官方的配置文件):
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1我们先来解读一下这个配置文件做了些什么=>
# 第一部分:为名为a1的agent进行组件命名 sources:r1, sinks:k1, channels:c1 > 发现组件后都有一个s,可以看出在一个Agent中是可以同时存在多个source、channel、sink的# 第二部分:配置source相关信息 r1.type: 名为r1的source通过netcat采集获取数据(监听端口) r1.bind: 监听端口的主机名 r1.port: 监听的端口号# 第三部分:配置sink k1.type: 名为k1的sink通过logger来输出数据(控制台输出)# 第四部分:配置channel c1.type: 名为c1的channel使用memory作为缓冲区(内存缓冲) c1.capacity: channel的事件(event)容量 c1.trancactionCapacity: 传输事务的最大事件(event)容量# 第五部分:source、sink和channel对接配置 a1.sources.r1.channels a1.sinks.k1.channel > source配置项是channels,而sink配置项是channel。下面有图可以查看 > 这就说明channel是可以接受来自多个source的信息的,一个source的信息也可以写到多个channel中 > channel的数据也可以供多个sink获取数据写出,**而每个sink只能从一个channel中获取数据写出**以下是官方文档中给出的
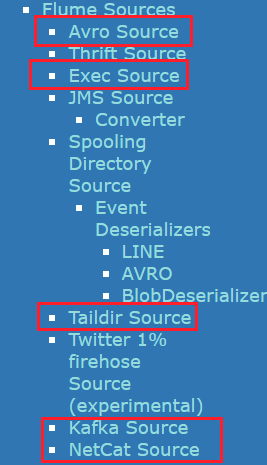
NetCat Source的配置清单:可对应第二部分的source配置,其他更多参照官方文档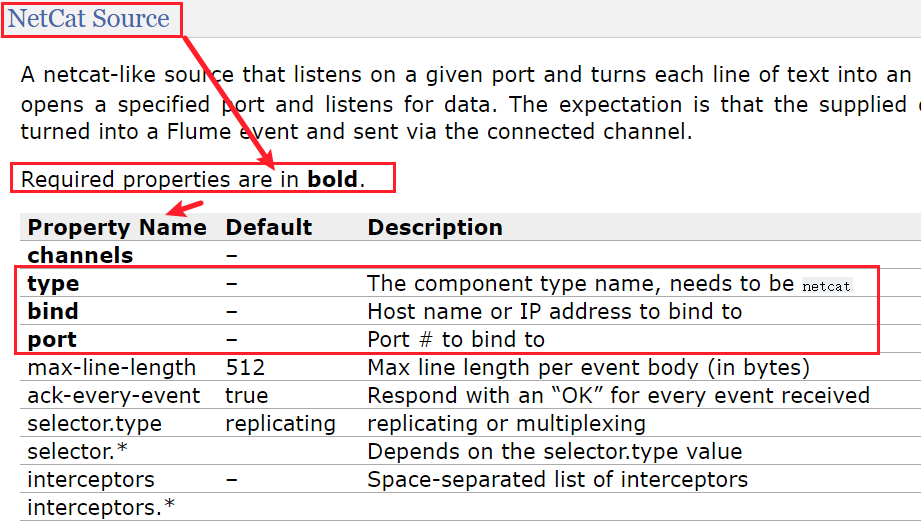
以下是官方文档给出的
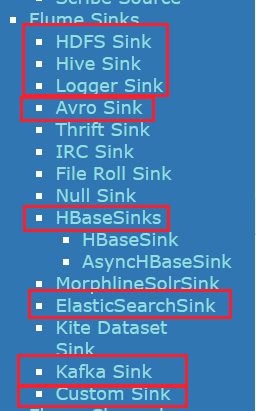
logger sink的配置清单:对应第三部分sink配置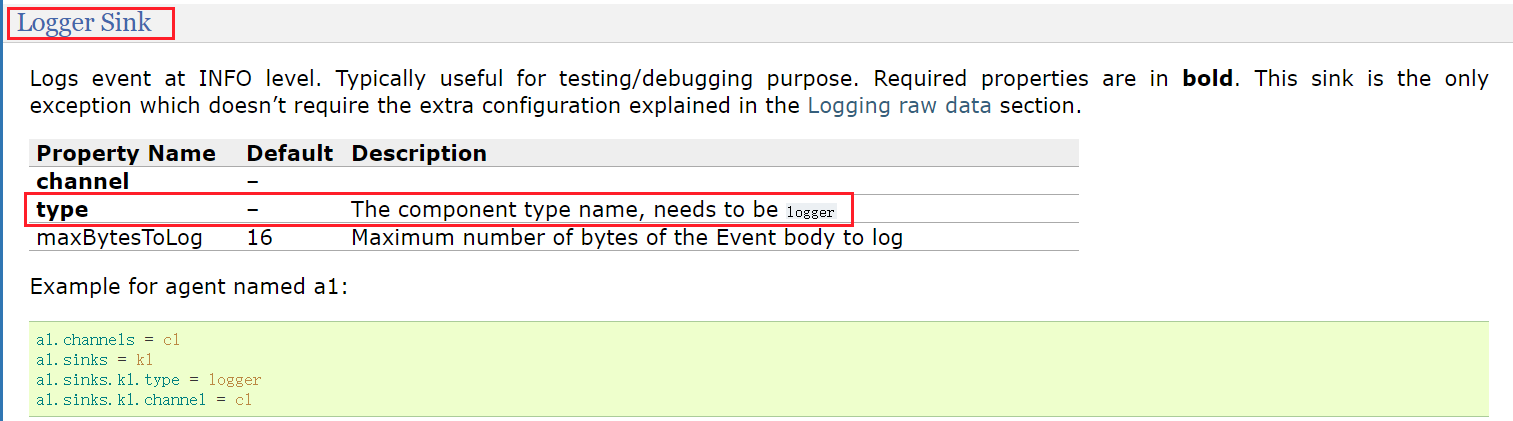
channel也不例外,官方文档也有对应的配置清单
启动一个Flume-Agent
bin/flume-ng agent --conf conf --conf-file job/netcat-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console--conf/-c基本配置文件目录--conf-file/-f配置文件名--name/-nagent的名字-Dflume.root.logger=INFO,console将所有INFO日志消息输出到控制台(附加配置)
或者使用
bin/flume-ng agent -c conf/ -f job/netcat-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console使用netcat进行连接
启动agent之后,运行flume进程的主机就相当一个netcat的服务端!我们之前的主机名写的是localhost,所以我们连接也只能在本地上连接
nc localhost 44444,如果要跨主机连接,可以将配置文件中bind主机名改为hadoop102测试发送信息
可以看到Flume控制台输出的内容确实是以Event为单位,分为headers和body两大部分!!
2.2.2、实时监控单个追加文件
案例需求:
实时监控hive的日志文件(/opt/module/hive-1.2.2/logs/hive.log)
- exec source
- memory channel
- logger sink
实现步骤
配置文件
file-flume-logger.conf除了第二部分的source配置需要查看官方文档的配置清单,其他可以完全照抄
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive-1.2.2/logs/hive.log# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1官方给出的exec source配置清单:
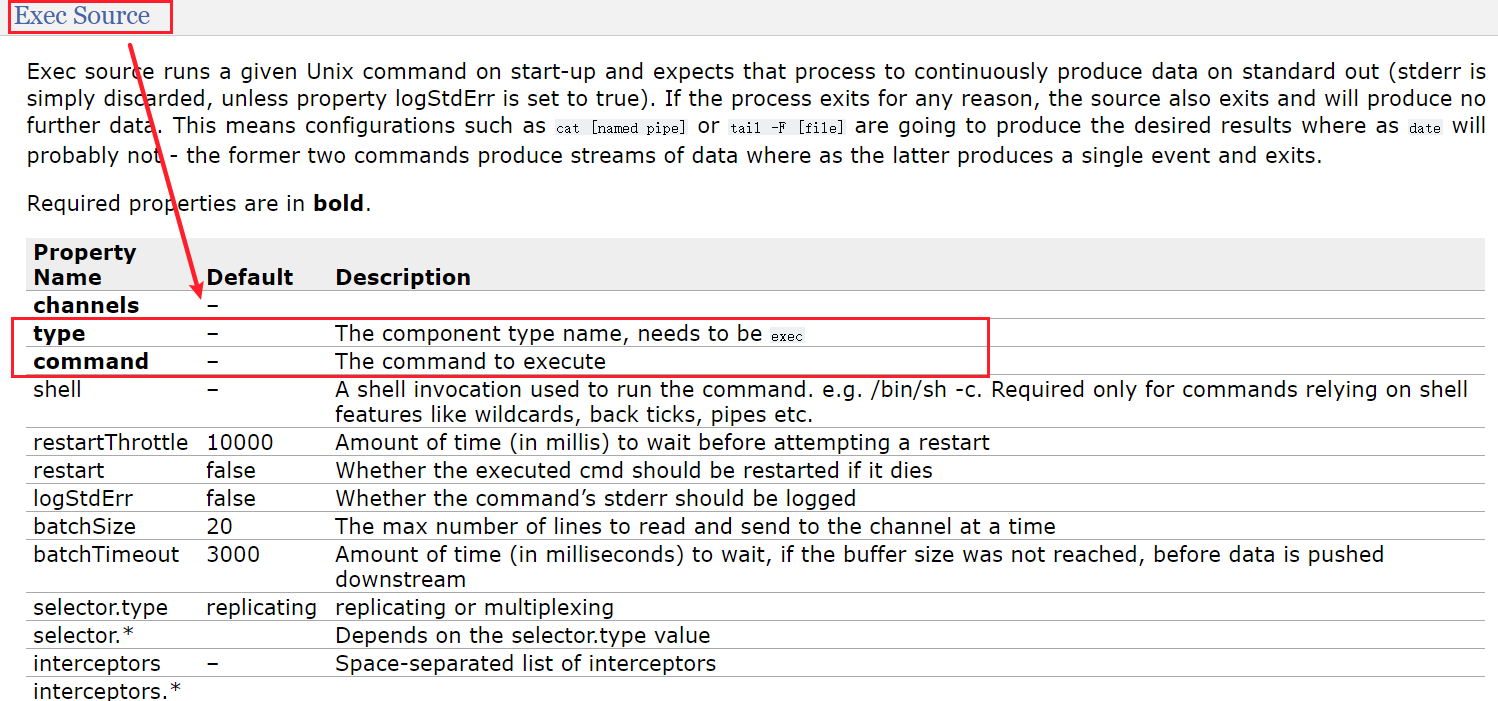
官方示例:
a1.sources = r1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /var/log/secure a1.sources.r1.channels = c1tail命令官方的推荐使用-F而非-f两者的区别在于,使用-F时,当文件发生变化导致监控失败,会自动进行尝试重新监控。启动flume-agent,开始监控hive.log
bin/flume-ng agent -c conf/ -f job/file-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console启动hive,执行查询,观察flume的控制台输出情况
首先会读取日志文件的末尾10行,输出到控制台。
监控成功!!
2.2.3、监控文件 升级版
将控制台的输出内容转移输出到HDFS上!
- HDFS sink
准备工作
将以下jar包导入到flume的lib目录下:(这里的Hadoop相关Jar包最好与Hadoop环境版本相同)
![]()
配置项解读
查看官方给出的配置清单,HDFS sink在生产环境中使用的频率还是比较高的!
![]()
除了默认黑体的必须配置以外,以上圈出的都是常用的HDFS sink的配置
来看一个官方给出的配置示例:
![]()
HDFS sink的别名大全:
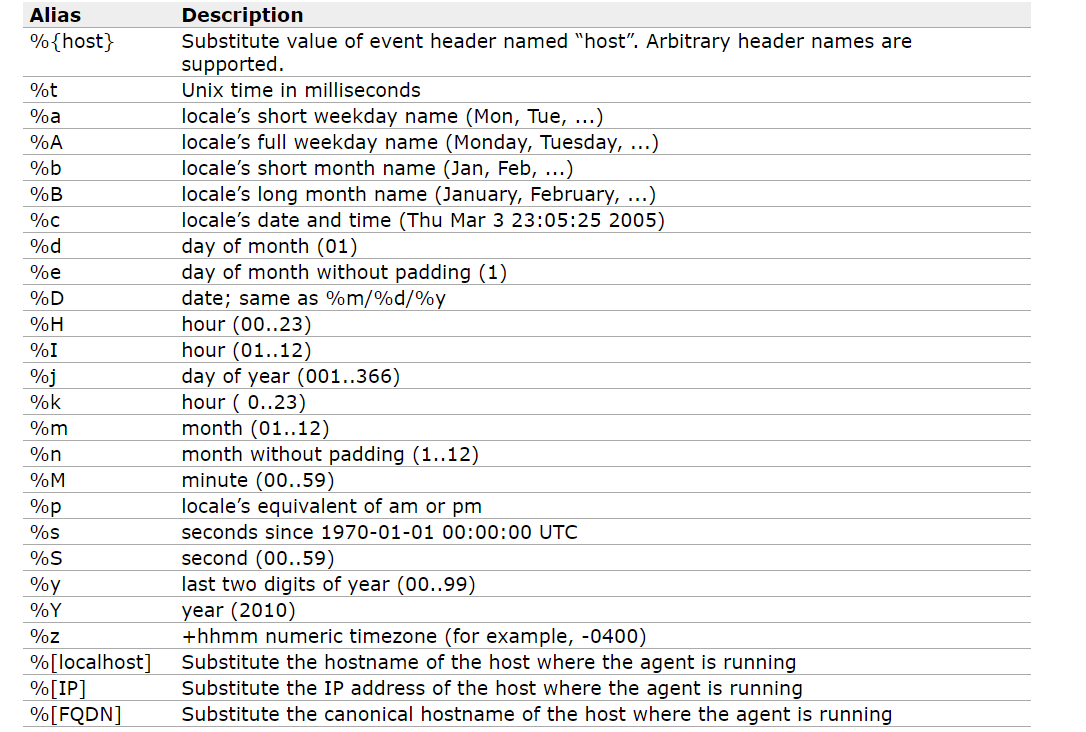
来对这些常用的配置项做一下详细的解读:
文件前、后缀
filePrefixfileSuffix
在向HDFS写入文件的时候,自定义文件的前后缀,可以使用别名。例如
a1.sinks.k1.hdfs.filePrefix=%t a1.sinks.k1.hdfs.fileSuffix=.logroll文件滚动
在向HDFS中写入的数据的时候,总不能只向一个文件中写入的吧,当达到一定条件时,需要强制滚动文件(切换到一个新文件),这样=利于数据的分离,避免文件太大影响效率。但是如果配置不当又会导致大量的小文件产生!!
rollInterval: 文件滚动之间的时间间隔(默认30s)rollSize: 滚动前,文件大小上限(默认1024kb)rollCount:滚动前 写入事件的最大次数(默认10)
以上三个配置项,只要满足其一就会进行一次文件滚动!!**三个配置项都可以配置为0,代表不作为判断项。**例如:
# 每60s滚动一次 a1.sinks.k1.hdfs.rollInterval=60 # 文件大小达到128×1024×1024=134217728 实际配置时尽量比这个小!保证一个文件能存放到一个块中 a1.sinks.k1.hdfs.rollSize=134217700 # rollCount不作为判断项,无论多少的Event都不影响 a1.sinks.k1.hdfs.rollCount=0可以看到当前的环境下其实使用默认的配置中很容易产生小文件,所以根据业务需求适当配置!!
批处理写入文件
batchSize: 当Event数量达到一定值,flush写入到HDFS中。(默认100)其实到达一定时间也会被强制刷新写入到HDFS
文件存储格式和编码解码器
codeC:编/解码器(可选:gzip, bzip2, lzo, lzop, snappy)仅当文件格式(fileType)是CompressedStream时配置!!fileType: 文件存储格式(默认SequenceFile,可选:SequenceFileorDataStreamorCompressedStream)
文件夹滚动
除了之前说的文件需要不断滚动,当我们需要配合使用Hive的分区表的时候,我们也希望定时切换文件夹,例如每天一个文件夹,文件夹下每个小时又分一个文件夹。==如果要使用此功能,必要配置中hdfs.path就不能写死而是使用别名!==否则滚来滚去都是这个文件夹没有效果!!
round: 是否开启文件夹滚动(默认为false)需要设置为true才能生效roundValue:滚动的间隔单元(Unit)数(默认1,每过一个Unit滚动一次)roundUnit:滚动的间隔单元单位(默认second,可选:second,minuteorhour.)
使用本地时间戳
useLocalTimeStamp(默认false,使用header中的时间戳),由于我们现在的header中什么都没有,如果不设置为true,那么所有与时间相关的都不会生效。
实现步骤
Flume配置文件
file-flume-hdfs.conf# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive-1.2.2/logs/hive.log# Describe the sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path=hdfs://hadoop102:9000/flume/%Y%m%d/%H # 文件前缀 a1.sinks.k1.hdfs.filePrefix=log- # 文件夹滚动 a1.sinks.k1.hdfs.round=true a1.sinks.k1.hdfs.roundValue=1 a1.sinks.k1.hdfs.roundUnit=hour # 使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp=true # 批处理最大数量 a1.sinks.k1.hdfs.batchSize=1000 # 文件存储类型 a1.sinks.k1.hdfs.fileType=DataStream # 文件滚动 a1.sinks.k1.hdfs.rollInterval=60 a1.sinks.k1.hdfs.rollSize=134217700 a1.sinks.k1.hdfs.rollCount=0# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1启动开始监控
bin/flume-ng agent -n a1 -c conf/ -f job/file-flume-hdfs.conf
![]()
每当日志变化时,在文件滚动的间隔时间内,所有的事件都会被 传输写入到临时文件(.tmp)中!文件滚动时间到达且有新的Event过来就会重新创建文件,之前的临时文件变为持久性文件!如果只是到了滚动时间,而没有Event过来是不会创建文件的!
2.2.4、监控文件夹变化
案例需求
实时监控一个文件夹下的文件添加,并实时同步到HDFS上。
- Spooling Directory Source
- HDFS sink
Spooling Directory Source配置清单
![]()
基本配置
spoolDir写明要监控的文件夹,只能监控文件的个数的增加,但是并不能监测到文件内容的变化!!
fileSuffix:完成同步后添加的文件后缀当被监控的目录下的文件被同步到了HDFS上时,会为本地文件系统中的文件加上后缀(默认
.COMPLETED)includePattern,ignorePattern文件‘黑白名单’使用正则表达式,设置哪些文件同步,哪些不同步。
实现步骤
创建一个文件夹用于监控(/opt/module/flume-1.7.0/upload)
配置文件
spooldir-flume-hdfs.conf修改2.2.3、的配置文件中source部分即可:
a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /opt/module/flume-1.7.0/upload/启动
bin/flume-ng agent -n a1 -c conf/ -f job/spooldir-flume-hdfs.conf测试
启动时upload文件夹下什么都没有,所以HDFS上也没有输出文件。
创建文件test.txt 拷贝到 upload/
HDFS上出现输出文件,大小和test.txt内容一样! upload/文件夹中的test.txt被加上了COMPLETED后缀!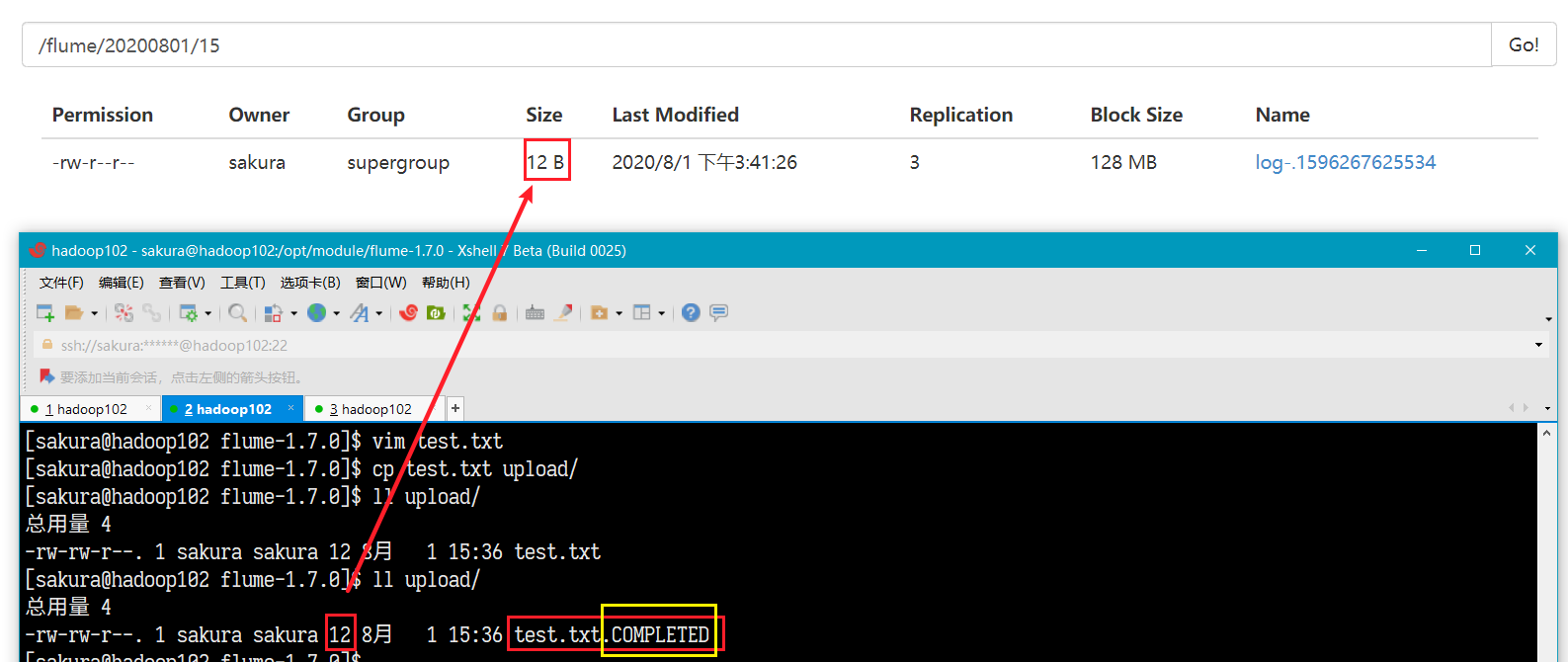
测试直接在upload/下创建文件
也可以正常同步到。但是当同步过后,继续修改文件是同步不到修改的内容的!!!
尝试重复添加同一文件

文件内容被成功上传!!但是文件名并没有被修改,查看flume日志,出现报错
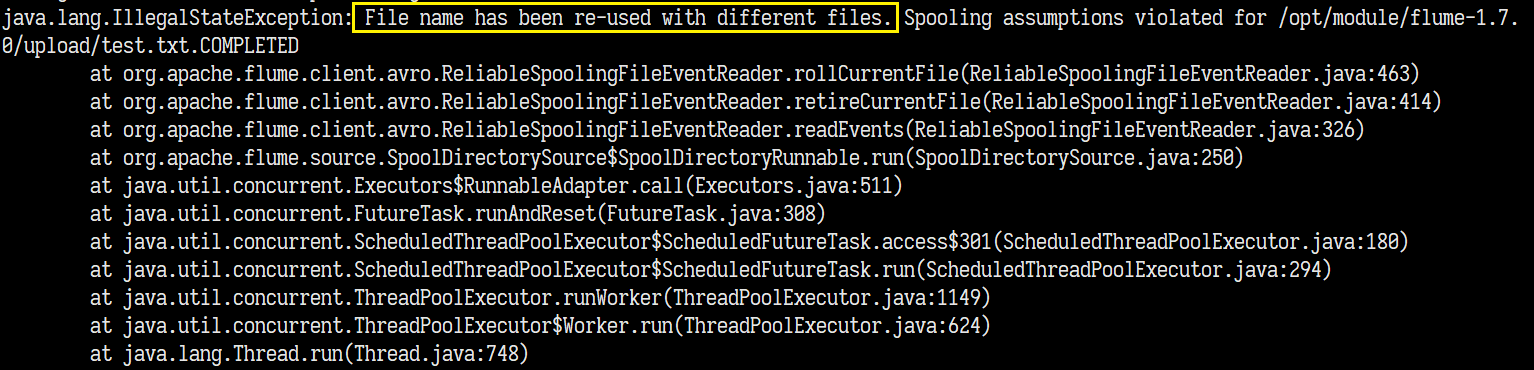
尝试添加.COMPLETED后缀的文件
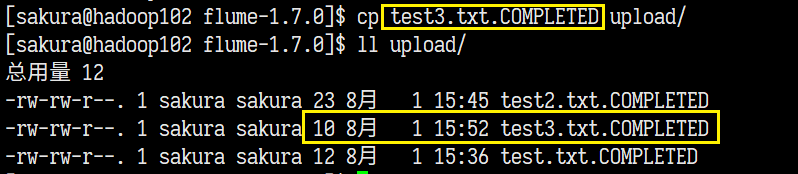
HDFS上并没有同步到!!!
增加配置再次测试
# 不同步xx.tmp文件 a1.sources.r1.ignorePattern=([^ ]*\.tmp)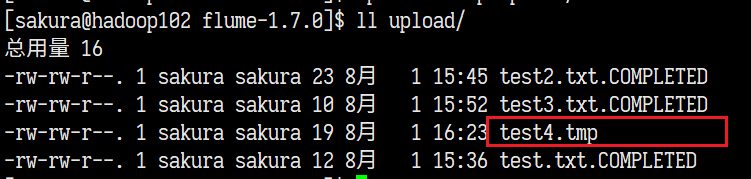
果然test4.tmp就没有被同步到!!
测试总结
- 上传的文件,同步输出到HDFS上,只同步文件内容!!
- 对已上传同步的文件进行修改,修改的内容无法被同步监测到!!
- 不要多次上传同一文件,会导致文件内容同步成功,但是在修改文件名的时候失败!
fileSuffix==尽量选择未使用的后缀,==否则会导致无法被监控到!
2.2.5、断点续传——实时监控目录文件追加修改
案例需求
监控一个或者多个的文件修改,并且支持断点续传
- Taildir source
Exec Source监控文件变化存在的问题:
不支持断点续传
如果生产环境中,Flume挂掉,再次启动的时候只能传输最后10行的数据!!
正常情况下有数据重复
每次启动都要将文件的最后10行传输,可能存在数据的重复。
使用 -c +0每次从文件头扫描监控
可以解决生产时挂掉导致大部分数据丢失的问题,但是平时使用数据重复率飙升!
只能监控一个文件
这几个问题就决定了ExecSource不适合用来做文件内容追加修改监控
而使用TailDir,使用了一个positionFile记录上一次传输的位置,即使挂掉,中间的文件修改在重启之后也会被正确传输!
而且可以同时监控多个文件!!
TaildirSource配置清单
![]()
filegroups:文件组,多个组使用空格分隔filegroups.<filegroupName>:为每个文件组设置监控文件的路径!(每个文件组只能有一个监控文件!!多次设置会进行覆盖,仅最后一次有效)positionFile:用于记录上一次传输位置的json文件的存放位置
官方示例:
![]()
实现步骤
创建一个文件夹用于监控(/opt/module/files)
配置文件
taildir-flume-logger.conf# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1# Describe/configure the source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups=f1 f2 a1.sources.r1.filegroups.f1=/opt/module/flume-1.7.0/files/file1.txt a1.sources.r1.filegroups.f2=/opt/module/flume-1.7.0/files/file2.txt a1.sources.r1.positionFile=/opt/module/flume-1.7.0/positionFile/position.json# Describe the sink a1.sinks.k1.type = logger# Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1启动
bin/flume-ng agent -n a1 -c conf/ -f job/taildir-flume-logger.conf -Dflume.root.logger=INFO,console测试
第一次启动就输出了两个文件夹中已有的内容:
是因为positionFile里面对两个文件的位置记录都为0。
向文件中追加内容
关闭Flume进程模拟掉线,继续追加内容到文件中,然后重启Flume
得益于positionFile的存在,即使Flume进程挂了,再次启动也能继续传输,甚至断线期间的修改也能被正常传输!!
查看positionFile
使用inode(文件的唯一标识)对应文件,并记录着两个文件的上一次传输位置以及文件的路径!
即使文件中途发生了重命名,移动会失去监控,在恢复到原始位置和名字时又会重新被监控。
三、Flume进阶
3.1、Flume事务
![]()
事务作用
Flume作为一个数据传输工具,保证数据的安全性和传输的可靠性就显得尤为重要!!而事务特性的引入就很好保证了这两个问题!!
Flume中事务的结构
在一个Flume Agent中同时存在两个事务
- 推送Event的Put事务
- 拉取Event的Take事务
Put事务
完整流程:
Source从外部读取数据后封装为Event对象实例,批次提交到一个事务中。事务中使用doPut方法将批数据中的Event加入到临时缓冲区(putList)
当缓冲区中数据达到一定数量或者批次数据传输完成,使用doCommit推送缓冲区的Event,并检查Channel中内存队列中是否足够存放这些Event,若全部成功推送则清空临时缓冲区,若Channel内存不足则使用doRollback将数据回滚。
三个方法,调用顺序:
doPutdoCommitdoRollback
一个区,临时缓冲区putList
Take事务
完整流程:
Sink创建一个事务,使用doTake将Event从Channel队列批次取出放入缓冲区takeList,缓冲区数据到达一定数量使用doCommit准备将缓冲区的数据发送给Sink写出,若数据全部成功发送清空缓冲区,否则调用doRollback将缓冲区数据归还到Channel内存队列中。
三个方法,调用顺序
doTakedoCommitdoRollback
一个区,缓冲区takeList
了解这些方法的调用过程和事务的执行过程,是便于我们后续编写自定义Source、Sink时调用对应的方法来用代码实现事务功能。
3.2、Agent内部原理
参考博客:
Flume Agent 内部原理概述
Flume Sink组、Sink处理器
基础架构复习
Flume Agent中包含三大组件:Source、Channel、Sink。
以上三个组件都运行在Agent(一个JVM应用程序)上,且数量没有限制!
每个Source至少对接一个Channel,每个Sink只能对接一个Channel,但是每个Channel可以对接多个Source以及多个Sink!!
数据在Flume中间传输以事件(Event)作为基本单位,Event的数据结构包含头部信息(Header)和数据体(Body)
新内容导入
接下来我们会将Event在Flume中传输的过程进行拆分,了解学习内部的原理,需要引入以下几个新的概念:
- Channel处理器(Channel Processor)
- 拦截器(Interceptor)
- Channel选择器(ChannelSelector)
- Sink组(SinkGroup)
- Sink运行器(Sink Runner)
- Sink处理器(SinkProcessor)
我们先用两张图来看一下他们之间的运作流程:
Source和Channel交互:
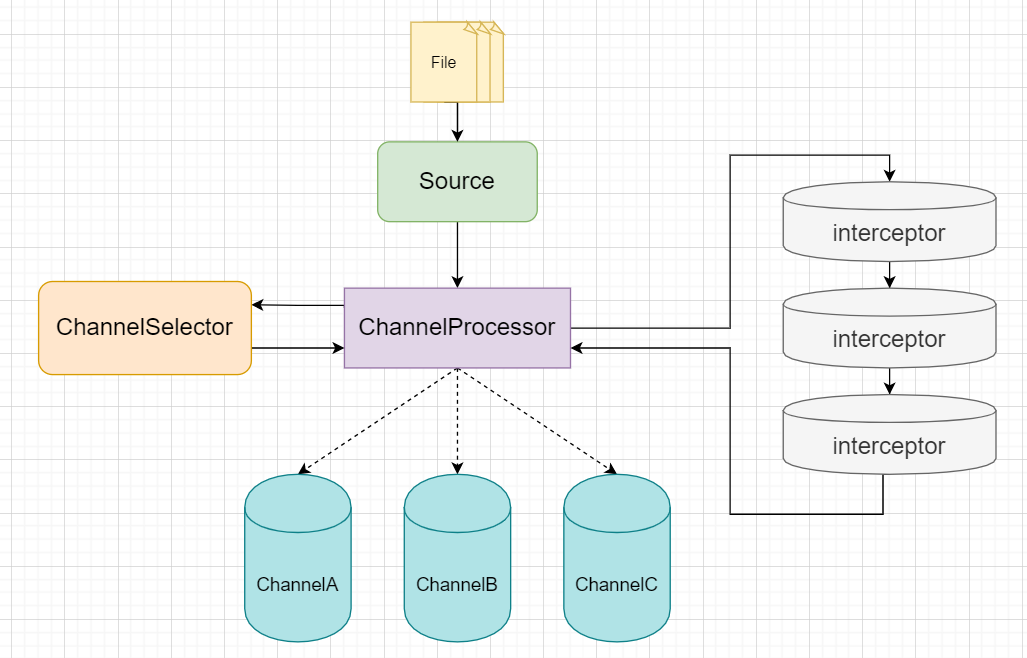
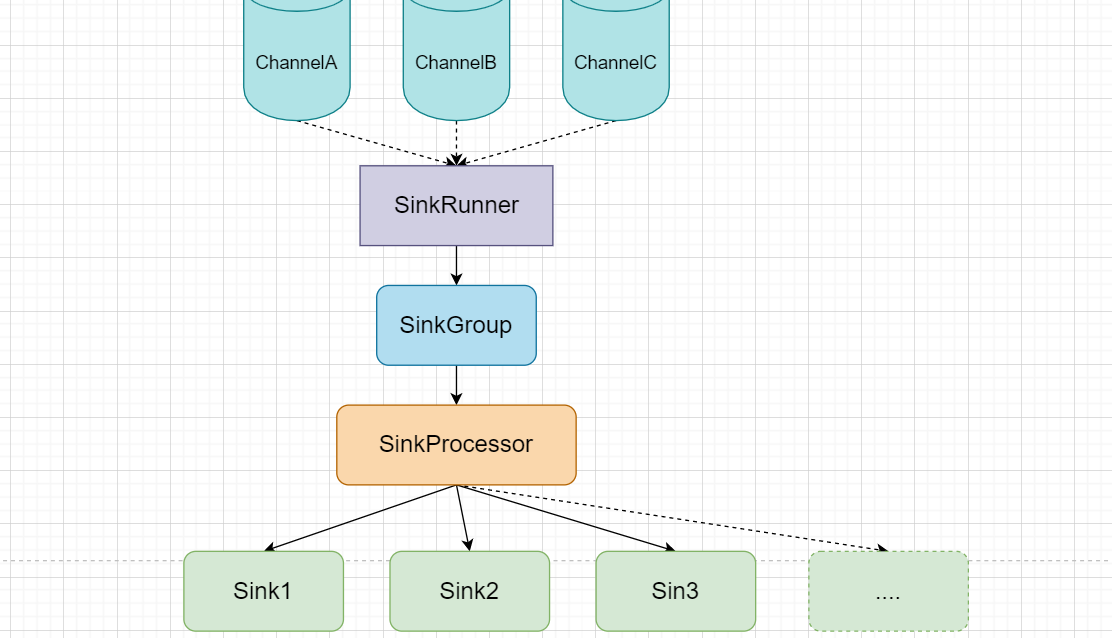
Channel和Sink交互:
简述以下Agent中工作流程:
Source从特定的位置读取到数据并封装为Event对象
封装好的批次Event,交给ChannelProcessor(每个Source都有自己的ChannelProcessor)
Channel处理器会将这些Event使用拦截器做一遍过滤,筛选出符合要求的Event,返回到Channel处理器
Channel处理器访问ChannelSelector,通过选择器来确定这些Event发到哪个Channel中
ChannelSelector官方提供了两种分别对应两种选择策略,同时支持自定义!!
Replicating Channel Selector (default): 所有与Source绑定的Channel都发送Multiplexing Channel Selector:自定义Source的数据发往那些ChannelChannel接收到Event后,与SinkRunner对接,每个SinkRunner运行一个Sink组,一般Sink组用于RPC Sink,在层之间以负载均衡或者故障转移方式交发送数据
每个Sink组中可以有多个Sink,组中每个Sink单独配置,包括从哪个Channel中拉取数据等。
SinkProcessor决定了对应的Sink组中哪个Sink来拉取哪个Channel中的数据
SinkProcessor官方有三种,也支持自定义Default Sink Processor:只有一个Sink,不强制要求Sink组Failover Sink Processor: 故障转移Load Balance Processor: 负载均衡
3.3、拓扑结构
当需要跨机器去读取数据时候,就需要在不同的机器上运行Agent,Agent之间的信息传递就需要使用网络拓扑,官网给出了三种拓扑结构。
3.3.1、简单串联
![]()
在节点之间交换数据的时候,通常会用到AVRO Sink和AVRO Source,分别设置在两个Agent中,然后通过AVRO RPC进行数据传输!两个节点就能被串联起来,方便取数据。
3.3.2、合并(Consolidation)
![]()
通过图就能理解,当需要从多个位置(节点)读取数据的时候,此种拓扑结构可以很好地解决这个问题,有两种实现方式:
- 可以是多个节点往固定的端口发送数据然后使用一个Agent在端口接收数据进行合并
- 也可以是多个节点各自选择端口,然后Agent使用多个Source来从这些端口中接受数据进行合并
3.3.3、多路复用
![]()
当一个位置的数据想要发送到多个目的地。这种拓扑结构就能解决问题,但是明显ChannelSelector就要使用默认的ReplicatingChannelSelector
3.3.4、负载均衡和故障转移
其拓扑结构刚好与合并相反,使用一台接收事件,然后使用Sink组转发到多个的Agent中去完成写出的工作。多个Agent增大了缓存Event的数量,降低了单个Agent的写出压力,并且提高了可用性。
3.4、开发案例
(一)、复制以及多路复用
案例描述:
启动三个Flume Agent,其中Agent1负责监控文件的变动,使用AVRO RPC与Agent2进行数据交换,Agent2将采集的数据写入HDFS,同时Agent1与Agent3同样使用AVRO RPC进行数据交换,Agent3将采集数据写入本地文件夹
图示:
![]()
看到这个图会不会很好奇,在Agent1中同样是数据为什么需要两个MemoryChannel和Sink,这就涉及到我们所说的Sink组了,同一个Sink组中除了默认的SinkProcessor外,就只有负载均衡和故障转移的SinkProcessor了,注定同一个Sink组中的所有Sink的写出位置都是相同的,那么想要写到不同的位置就需要多个Sink组。
配置清单与配置文件
FileRoll Sink:
![]()
Avro Sink:
![]()
Avro Source:
![]()
可以看出AVRO是专门一套用于节点端口数据传递的 Source和Sink,其配置和NetCat十分相似!
由于是三个Agent,所以就需要三个配置文件:
Agent1:
# 组件命名
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2# source配置(TailDir Source)
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = file1
a1.sources.r1.filegroups.file1 = /opt/module/data/flume_data/example1.log
a1.sources.r1.positionFile=/opt/module/flume-1.7.0/positionFile/example1_position.json# sink配置(AVRO Sink)
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4545a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4646# Channel配置 (MemoryChannel)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100# 对接Channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
Agent2:
# 组件命名
a2.sources = r1
a2.channels = c1
a2.sinks = k1# Source配置 (AVRO Source)
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4545# Sink配置
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path=hdfs://hadoop102:9000/flume/%Y%m%d/%H# 文件前缀
a2.sinks.k1.hdfs.filePrefix=log-# 文件夹滚动
a2.sinks.k1.hdfs.round=true
a2.sinks.k1.hdfs.roundValue=1
a2.sinks.k1.hdfs.roundUnit=hour# 使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp=true# 批处理最大数量
a2.sinks.k1.hdfs.batchSize=1000# 文件存储类型
a2.sinks.k1.hdfs.fileType=DataStream# 文件滚动
a2.sinks.k1.hdfs.rollInterval=60
a2.sinks.k1.hdfs.rollSize=134217700
a2.sinks.k1.hdfs.rollCount=0# Channel配置 (MemoryChannel)
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100# 对接Channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
Agent3:
# 组件命名
a3.sources = r1
a3.channels = c1
a3.sinks = k1# Source配置 (AVRO Source)
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4646# Sink配置 (File Roll Sink)
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/flume-1.7.0/files/# Channel配置 (MemoryChannel)
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100# 对接Channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
启动测试
注意启动顺序!!先启动下游!ARVO RPC中 AVRO Source是服务端,AVRO Sink是客户端。
bin/flume-ng agent -n a3 -c conf/ -f job/example1/agent3.conf
bin/flume-ng agent -n a2 -c conf/ -f job/example1/agent2.conf
bin/flume-ng agent -n a1 -c conf/ -f job/example1/agent1.conf
测试情况:
RollFileSink的输出文件夹下每30秒生成一个文件,文件中只有变化的内容,若没有对监控文件修改也会生成文件但是内容为空!
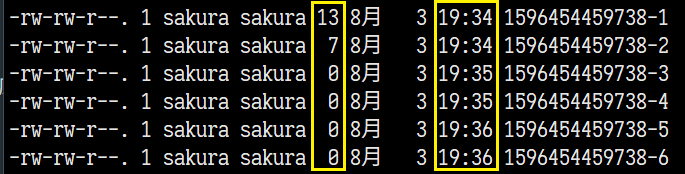
HDFS上成功生成文件记录着修改内容:
(二)、负载均衡和故障转移
故障转移案例
配置三个Flume Agent,Agent1使用NetCat Source接受数据,然后使用Sink组 使用两个AVRO Sink与Agent2、Agent3连接,Agent2和Agent3将接受数据输出到控制台(logger Sink)。期间停掉Agent2或Agent3中任意一台,查看变化。
![]()
FailOver Sink Processor配置清单
![]()
根据文档中所给的提示:要创建一个Sink Group,并且为其中每个Sink指定一个唯一的priority(优先级),优先级越高优先从Channel中拉取事件。
maxpenalty:故障转移的时间上限。(默认30000ms=30s)意思是:从知道机器挂掉后最长30s内都不会去尝试给这个Agent发送数据(即使30s内已经恢复),30s后才会重新尝试建立连接发送数据。
三个配置文件
Agent1
# 组件命名
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1# Source配置 NetCat
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop102
a1.sources.r1.port = 44444# Sink配置 AVRO Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4545a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4646# Channel配置 MemoryChanne
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 对接Channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1# FailOver Processor配置
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
Agent2:
a2.sources = r1
a2.sinks = k1
a2.channels = c1# Source配置 AVRO Source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4545# Sink配置 Logger Sink
a2.sinks.k1.type = logger# Channel配置 MemoryChannel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100# 对接Channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
Agent3相同,只需修改agent名字和 AVRO Source接收的端口就行了。。此次省略
启动测试
![]()
存活Agent中优先级最高的拉取数据。
由于故障挂掉的Agent重启之后,仍然可以接收数据!!
在Flume的日志文件中,就能看到当我们关闭Agent的时候,会提示Agent被加入到了FailOver List:
![]()
负载均衡(LoadBalance Processor)配置清单:
![]()
简直不要太简单!!!完全可以使用官方给出的配置,默认使用轮询进行负载均衡!
这里的backoff关联到退避算法,是对Agent挂掉后机器选择的一种策略,建议开启。
(三)、聚合(Consolidation)
案例描述
还是三个Agent,不过这次不同三个Agent分布在三台主机上,Agent1接收NetCat监听端口发送的数据,Agent2使用TailDir监控文件,两者使用AVRO Sink与Agent3建立连接,Agent3做聚合处理,将接受的数据输出到控制台
![]()
配置文件
Agent1
# 组件命名
a1.sources = r1
a1.channels = c1
a1.sinks = k1# Source配置 TailDir Source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/data/flume_data/example3.log
a1.sources.r1.positionFile = /opt/module/flume-1.7.0/positionFile/example3_position.json# Sink配置 AVRO Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop104
a1.sinks.k1.port = 4545# Channel配置 MemoryChannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 对接Channe
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Agent2
# 组件命名
a2.sources = r1
a2.channels = c1
a2.sinks = k1# Source配置 NetCat Source
a2.sources.r1.type = netcat
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 44444# Sink配置 AVRO Sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop104
a2.sinks.k1.port = 4545# Channel配置 MemoryChannel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100# 对接Channe
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
Agent3
# 组件命名
a3.sources = r1
a3.channels = c1
a3.sinks = k1# Source配置 AVRO Source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop104
a3.sources.r1.port = 4545# Sink配置 Logger Sink
a3.sinks.k1.type = logger# Channel配置 MemoryChannel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100# 对接Channe
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
启动测试
![]()
这只是实现方式的中的一种:
- 需要合并的Agent往合并Agent所在的主机的同一个端口发送数据,用于合并的Agent从那个端口中取数据进行集中输出。
还有一种就是:
- 需要合并的Agent自定义选择合并Agent所在主机的端口,然后用于Agent从这些个端口中取出数据然后进行集中输出。
3.5、自定义Interceptor(拦截器)
拦截器
首先拦截器是什么不用多说了吧,字面意义上很容易理解,就是把xx拦住,然后做一些不可描述的事情【坏笑】,然后放行。或者说直接原路打回,不处理。
在Flume中拦截器作用于Event,不可描述的操作就是在Event的头部(Header)添加一些东西,或者也可以修改Body部分。
使用拦截器在Header中添加一些KV键值对后,就可以方便后续配合使用Multiplexing Channel Selector,利于对Event的分类。
为什么Flume需要拦截器?
小小Flume,一个数据传输的中间件,为什么要用拦截器大做文章?
首先,生产环境中我们使用Flume采集的多方数据,我们希望这些数据能够被区分开来放到不同的位置!!
杠精:那你就用独立的Agent串联啊,哪个地方的到哪去一条条线写清楚不就能控制了!
其次,这些数据中存在脏数据我们需要剔除
杠精:这。。。
最后,我们希望即使是发到同一个目的地(例如HDFS),也能够按照数据的内容进行分类然后放到不同的位置(例如不同目录)
杠精:拦截器,算你nb
拦截器配置Multiplexing Channel Selector实现多路复用,就可以完美解决上面这些需求!!
拦截器在头部添加标志,多路选择器根据头部的标志信息,决定Event去向的Channel。
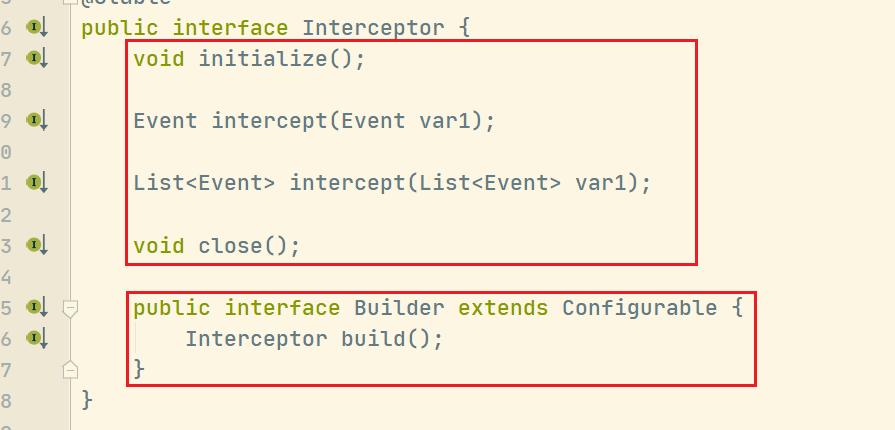
Interceptor接口
四个方法:
initalize()初始化方法,每次使用拦截器只调用一次intercept(Event event)对单个事件的拦截处理intercept(List<Event> eventList)对批事件的处理close()拦截器使用结束,用于关闭释放资源
内部还有一个接口,在我们实现的时候,也要对应创建一个内部类实现此接口(Builder)并重写两个方法
build()用于实例化拦截器configure()用于配置拦截器的相关一些额外配置
已有的实现类:

代码自定义实现拦截器
案例需求描述:
自定义一个拦截器,并结合使用Multiplexing Channel Selector,判断Event中的数据内容是否包含"hello"单词,如果包含则输出到控制台,若果不包含就放到其他位置。
其中涉及到**Multiplexing Channel Selector的配置以及自定义拦截器的配置,**我们稍后再说。
对了,我们先来看看Event类的操作和使用:
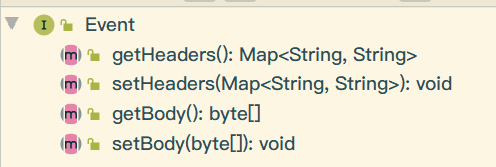
四个方法简洁明了。傻子都能看得懂了吧!!!
自定义拦截器类
public class HelloInterceptor implements Interceptor {/*** 用于批事件处理方法的返回列表*/private List<Event> handledEvents;@Overridepublic void initialize() {handledEvents = new ArrayList<>();}/*** 处理单个事件* @param event* @return*/@Overridepublic Event intercept(Event event) {// 获取事件的头部Map<String, String> headers = event.getHeaders();// 获取时间的数据本体String body = new String(event.getBody());// 判断数据内容if (body.contains("hello")) {headers.put("hasHello", "Y");} else {headers.put("hasHello", "N");}return event;}/*** 批事件处理* @param list* @return*/@Overridepublic List<Event> intercept(List<Event> list) {// 1.清空列表handledEvents.clear();// 2.循环调用单事件处理的方法list.forEach(x -> handledEvents.add(intercept(x)));return handledEvents;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {/*** @return* 实例化拦截器*/@Overridepublic Interceptor build() {return new HelloInterceptor();}@Overridepublic void configure(Context context) {}}
}
这就是一个简单的Interceptor实现啦。下一步就是Agent的配置了!
先上图:
![]()
Multiplexing Channel Selector配置以及拦截器的配置
先看多路选择器的配置清单:
![]()
官方案例:
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4
重点关注一下最后四行,倒数二三行像是给mapping中 CZ和US指定了Channel!!这正是我们想要的!!倒数第四行还有一个header中取出的state,莫非?? 莫非!? 莫非?! 莫非!!
对!!其实CZ和US只是header中名为state的key所对应的两个value!!所以说结合多路选择器就可以按照头部的标记决定Event的去向!!
那么按照我们的拦截器代码就能推出我们要配置的多路选择器配置内容:
a1.sources = r1
a1.channels = c1 c2
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = hasHello
a1.sources.r1.selector.mapping.Y = c1
a1.sources.r1.selector.mapping.N = c2
a1.sources.r1.selector.default = c1
自定义拦截器如何配置?
官方文档案例:
小知识:文档中反复提起的FQCN,全拼是fully qualified class name(全限定类名)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 拦截器命名
a1.sources.r1.interceptors = i1 i2
# 拦截器的类型(使用已有的拦截器类型 或者 自定义类的全限定类名$Builder)
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.HostInterceptor$Builder
# 以下省略...
a1.sources.r1.interceptors.i1.preserveExisting = false
a1.sources.r1.interceptors.i1.hostHeader = hostname
a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
a1.sinks.k1.filePrefix = FlumeData.%{CollectorHost}.%Y-%m-%d
a1.sinks.k1.channel = c1
配置启动
把写好的拦截器程序打包放到flume的lib目录下
三个配置文件:
Agent1:
# 组件命名 a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2# Source配置 NetCat Source a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop102 a1.sources.r1.port = 44444# Sink配置 AVRO Sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop103 a1.sinks.k1.port = 4545a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop104 a1.sinks.k2.port = 4545# Channel配置 MemoryChannel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100# ChannelSelector配置 MultiplexingChannelSelector a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = hasHello a1.sources.r1.selector.mapping.Y = c1 a1.sources.r1.selector.mapping.N = c2# Interceptor配置 HelloInterceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.sakura.interceptor.HelloInterceptor$Builder# Channel对接 a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2Agent2:
# 组件命名 a2.sources = r1 a2.channels = c1 a2.sinks = k1# Source配置 AVRO Source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop103 a2.sources.r1.port = 4545# Sink配置 LoggerSink a2.sinks.k1.type = logger# Channel配置 MemoryChannel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100# 对接Channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1Agent3配置文件与Agent2大致相同,修改avro source的bind和agent的名字就可以了,这里省略。。
启动
先2,3后1
测试结果:
![]()
3.6、自定义Source
为什么要自定义Source?
虽然官方提供了很多可选的Source,但是依然不足以满足我们的业务需求,所以官方也给出了自定义Source的方案,我们可以通过固定的逻辑框架来实现独属于我们的Source。
官方的自定义Source模板
public class MySource extends AbstractSource implements Configurable, PollableSource {private String myProp;@Overridepublic void configure(Context context) {String myProp = context.getString("myProp", "defaultValue");// Process the myProp value (e.g. validation, convert to another type, ...)// Store myProp for later retrieval by process() methodthis.myProp = myProp;}@Overridepublic void start() {// Initialize the connection to the external client}@Overridepublic void stop () {// Disconnect from external client and do any additional cleanup// (e.g. releasing resources or nulling-out field values) ..}@Overridepublic Status process() throws EventDeliveryException {Status status = null;try {// This try clause includes whatever Channel/Event operations you want to do// Receive new dataEvent e = getSomeData();// Store the Event into this Source's associated Channel(s)getChannelProcessor().processEvent(e);status = Status.READY;} catch (Throwable t) {// Log exception, handle individual exceptions as neededstatus = Status.BACKOFF;// re-throw all Errorsif (t instanceof Error) {throw (Error)t;}} finally {txn.close();}return status;}
}
整个代码的重点在于process()方法,透过这个方法我们能看到之前我们在Flume事务和Agent原理中讲到的那些东西。
所有的Source配置项都以全局属性的形式存在,使用context.getString()到配置文件中取,或者直接使用默认值。
等等… 这些细节我们边写边说吧
自定义Source代码实现
extends AbstractSource implements Configurable, PollableSource继承实现这些类官方模板中的
start()和stop()用于和外部数据源客户端建立/断开连接(例如MySQL)这两个方法是可选实现,这里我们做的是简单的实现就不使用这俩方法了。接口中必须实现的四个方法:
void configure(Context context)Status process()long getBackOffSleepIncrement()long getMaxBackOffSleepInterval()
关键在于前两个方法,后俩和BackOff的时间设置有关。
process()方法的任务- 将数据封装为Event对象
- 将封装好的Event交给ChannelProcessor处理(查看源码!!)
- 控制Event的处理,为其设置状态(State: READY or BACKOFF)
configure(Context context)方法- 读取配置文件中的配置并为Source中的属性设值
包装Event时,需要用到Event接口的一个实现类:SimpleEvent 另外一个实现类(JSONEvent);
使用getChannelProcessor().processEvent(event);完成Event的处理,包括拦截器,事务,Channel选择
来看看源码:
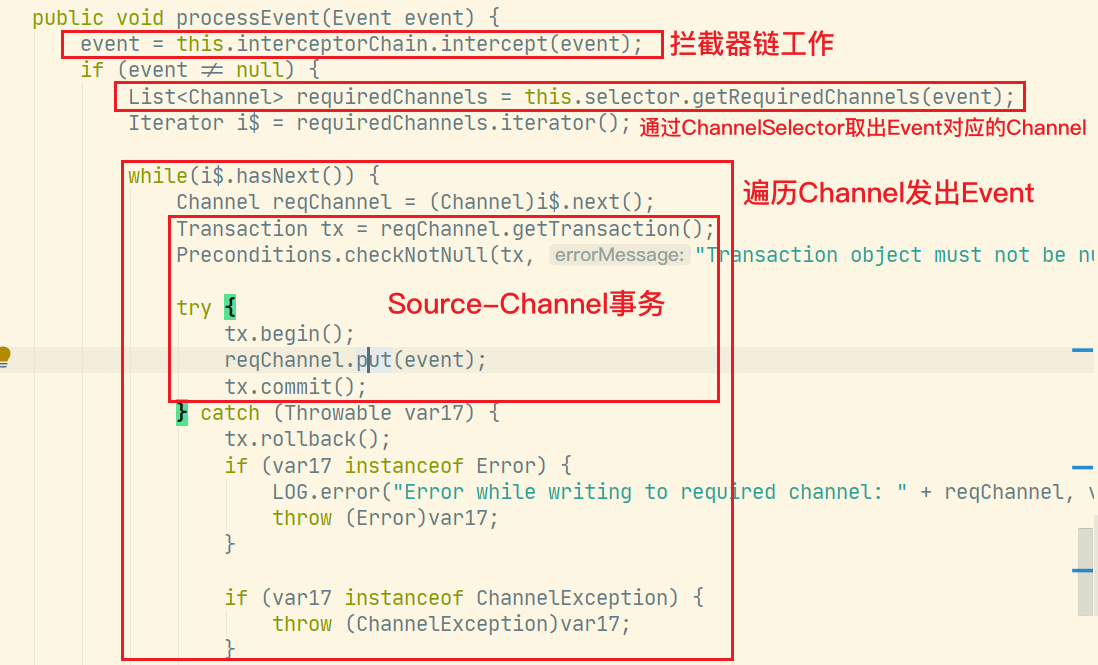
之前事务中讲到的doPut、doCommit、doRollBack现在都见到活物了!!!拦截器链和Selector的工作顺序也得以验证。
完整代码:
public class MySource extends AbstractSource implements Configurable, PollableSource {/*** 数据前缀*/private String prefix;/*** 数据后缀*/private String suffix;@Overridepublic void configure(Context context) {// 读取配置文件或使用默认值(data)prefix = context.getString("prefix", "data");suffix = context.getString("suffix", "data");}/*** 1. 接收数据包装为Event* 2. 将Event传给Channel** @return* @throws EventDeliveryException*/@Overridepublic Status process() throws EventDeliveryException {Status status = null;try {// 模拟接收数据for (int i = 0; i < 5; i++) {SimpleEvent event = new SimpleEvent();// 为 Event设置数据本体event.setBody((prefix + "--" + i + "--" + suffix).getBytes());getChannelProcessor().processEvent(event);}status = Status.READY;} catch (Exception e) {e.printStackTrace();// 发送失败 status置为 BACKOFFstatus = Status.BACKOFF;}// 延迟两秒try {TimeUnit.SECONDS.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}return status;}@Overridepublic long getBackOffSleepIncrement() {return 0;}@Overridepublic long getMaxBackOffSleepInterval() {return 0;}
}
这个Source有两个配置项:
- prefix
- suffix
默认值都是data。
数据由Source自己伪造就是那个for循环
大数据学习——Flume入门相关推荐
- 大数据学习路线-入门精简
大数据学习路线入门精简 大数据的学习路程还是比较漫长的,最重要一点!!耐下心来踏踏实实去学,既然选择了就不要放弃,加油吧.
- 大数据学习规划(新手入门)
前言: 一.背景介绍 二.大数据介绍 正文: 一.大数据相关的工作介绍 二.大数据工程师的技能要求 三.大数据学习规划 四.持续学习资源推荐(书籍,博客,网站) 五.项目案例分析(批处理+实时处理) ...
- 2018大数据学习路线从入门到精通
最近很多人问小编现在学习大数据这么多,他们都是如何学习的呢.很多初学者在萌生向大数据方向发展的想法之后,不免产生一些疑问,应该怎样入门?应该学习哪些技术?学习路线又是什么?今天小编特意为大家整理了一份 ...
- 大数据学习入门规划?和学习路线
大数据方向的工作目前分为三个主要方向: 01.大数据工程师 02.数据分析师 03.大数据科学家 04.其他(数据挖掘本质算是机器学习,不过和数据相关,也可以理解为大数据的一个方向吧) 一.大数 ...
- 大数据架构师从入门到精通 学习必看宝典
经常有初学者在博客和QQ问我,自己想往大数据方向发展,该学哪些技术,学习路线是什么样的,觉得大数据很火,就业很好,薪资很高.如果自己很迷茫,为了这些原因想往大数据方向发展,也可以,那么我就想问一下,你 ...
- 大数据架构师入门学习
经常有初学者在博客和QQ问我,自己想往大数据方向发展,该学哪些技术,学习路线是什么样的,觉得大数据很火,就业很好,薪资很高.如果自己很迷茫,为了这些原因想往大数据方向发展,也可以,那么我就想问一下,你 ...
- 大数据学习指南从入门到精通
目录 大数据学习指南从入门到精通 前言 一.大数据基础 二.大数据必学Java基础 三.ZooKeeper 四.大数据环境搭建 五.Hadoop 六.Hive 七.HBase 八.Kafka 九.Sc ...
- 24.大数据学习之旅——spark手把手带你入门
Spark介绍 Apache Spark™ is a fast and general engine for large-scale data processing. Spark Introduce ...
- 大数据学习之小白快速了解flume
flume的整体基础架构包括三个,分别是source,chanel, sink. 下面是官网的截图: 因此,优化要从三个组件的角度去分别优化. 大数据学习群119599574 1.source sou ...
最新文章
- 【微服务架构】SpringCloud之断路器(hystrix)
- 阿提拉公司 java_Atitit 文件上传 架构设计 实现机制 解决方案 实践java php c#.net js javascript c++ python...
- LoadRunner监控mysql利器-SiteScope(转)
- 商业智能项目错误经验总结(三) 需求调研
- 何时开始phonics学习及配套阅读训练zz
- 【Python相关】jupyter平台最强插件没有之一
- go语言switch中判断多个值
- leetcode 19. 删除链表的倒数第N个节点(双指针)
- maven 之 setting.xm 的配置详解、说明
- php 数据映射,数据映射模式(Data Mapper)
- c 语言基础笔试题1
- qplot函数添加回归曲线R方方差分析表
- 我读《写给大家看的设计书》
- STM32开发(2)----CubeMX的安装和使用
- 修改BCM4322 ID 和国家码完美支持黑苹果和5G WiFi频段
- 更改分类算法的阙值的资料
- 小米手机彻底关闭广告经验分享
- 企业微信实现扫码登录
- 从0开始学习python7:Python中词频统计以及sort的排序用法
- 基于Python进行餐饮订单数据分析