正则表达式检测电子邮件_电子邮件中的垃圾邮件检测
正则表达式检测电子邮件
深层学习计划 (DEEP LEARNING PROJECT)
Have you ever wondered how a machine translates language? Or how voice assistants respond to questions? Or how mail gets automatically classified into spam or not spam?
您是否想过机器如何翻译语言? 还是语音助手如何回答问题? 或者如何将邮件自动分类为垃圾邮件?
All these tasks are done through Natural Language Processing (NLP), which processes text into useful insights that can be applied to future data. In the field of artificial intelligence, NLP is one of the most complex areas of research due to the fact that text data is contextual. It needs modification to make it machine-interpretable and requires multiple stages of processing for feature extraction.
所有这些任务都通过自然语言处理(NLP)完成,该处理将文本处理为有用的见解 , 这些见解可应用于将来的数据。 在人工智能领域,由于文本数据是上下文相关的,因此NLP是最复杂的研究领域之一。 它需要进行修改以使其可以机器解释,并且需要多个处理阶段才能进行特征提取。
Classification problems can be broadly split into two categories: binary classification problems, and multi-class classification problems. Binary classification means there are only two possible label classes, e.g. a patient’s condition is cancerous or it isn’t, or a financial transaction is fraudulent or it is not. Multi-class classification refers to cases where there are more than two label classes. An example of this is classifying the sentiment of a movie review into positive, negative, or neutral.
分类问题可以大致分为两类:二元分类问题和多分类问题。 二进制分类意味着只有两种可能的标签类别,例如,患者的状况是癌变还是不是癌变,或者金融交易是否是欺诈性或不是。 多类别分类是指标签类别超过两个的情况。 例如,将电影评论的情绪分为正面,负面或中性。
There are many types of NLP problems, and one of the most common types is the classification of strings. Examples of this include the classification of movies/news articles into different genres and the automated classification of emails into a spam or not spam. I’ll be looking into this last example in more detail for this article.
NLP问题有很多类型,最常见的一种是string的分类 。 这样的示例包括将电影/新闻文章分类为不同类型,以及将电子邮件自动分类为垃圾邮件或非垃圾邮件。 我将在本文中更详细地研究最后一个示例。
问题描述 (Problem Description)
Understanding the problem is a crucial first step in solving any machine learning problem. In this article, we will explore and understand the process of classifying emails as spam or not spam. This is called Spam Detection, and it is a binary classification problem.
理解问题是解决任何机器学习问题的关键的第一步。 在本文中,我们将探索和理解将电子邮件分类为垃圾邮件或非垃圾邮件的过程。 这称为垃圾邮件检测,它是一个二进制分类问题。
The reason to do this is simple: by detecting unsolicited and unwanted emails, we can prevent spam messages from creeping into the user’s inbox, thereby improving user experience.
这样做的原因很简单:通过检测未经请求和不需要的电子邮件,我们可以防止垃圾邮件爬入用户的收件箱,从而改善用户体验。
数据集 (Dataset)
Let’s start with our spam detection data. We’ll be using the open-source Spambase dataset from the UCI machine learning repository, a dataset that contains 5569 emails, of which 745 are spam.
让我们从垃圾邮件检测数据开始。 我们将使用UCI机器学习存储库中的开源Spambase数据集 ,该数据集包含5569封电子邮件,其中745 封为垃圾邮件。
The target variable for this dataset is ‘spam’ in which a spam email is mapped to 1 and anything else is mapped to 0. The target variable can be thought of as what you are trying to predict. In machine learning problems, the value of this variable will be modeled and predicted by other variables.
此数据集的目标变量是“垃圾邮件”,在该垃圾邮件中, 垃圾邮件被映射为1 ,其他任何内容都被映射为0。可以将目标变量视为您要预测的内容。 在机器学习问题中,此变量的值将由其他变量建模和预测。
A snapshot of the data is presented in figure 1.
数据快照如图1所示。

Task: To classify an email into the spam or not spam.
任务:将电子邮件分类为垃圾邮件还是非垃圾邮件。
To get to our solution we need to understand the four processing concepts below. Please note that the concepts discussed here can also be applied to other text classification problems.
为了获得我们的解决方案,我们需要了解以下四个处理概念。 请注意,此处讨论的概念也可以应用于其他文本分类问题。
- Text Processing
文字处理 - Text Sequencing
文字排序 - Model Selection
选型 - Implementation
实作

1.文字处理 (1. Text Processing)
Data usually comes from a variety of sources and often in different formats. For this reason, transforming your raw data is essential. However, this transformation is not a simple process, as text data often contain redundant and repetitive words. This means that processing the text data is the first step in our solution.
数据通常来自各种来源,并且通常采用不同的格式。 因此,转换原始数据至关重要。 但是,这种转换不是一个简单的过程,因为文本数据通常包含冗余和重复的单词。 这意味着处理文本数据是我们解决方案的第一步。
The fundamental steps involved in text preprocessing are
文本预处理涉及的基本步骤是
A. Cleaning the raw dataB. Tokenizing the cleaned data
A.清理原始数据B. 标记清理的数据
A.清理原始数据 (A. Cleaning the Raw Data)
This phase involves the deletion of words or characters that do not add value to the meaning of the text. Some of the standard cleaning steps are listed below:
此阶段涉及删除不会增加文字含义价值的单词或字符。 下面列出了一些标准的清洁步骤:
- Lowering case
小写 - Removal of special characters
删除特殊字符 - Removal of stopwords
删除停用词 - Removal of hyperlinks
删除超链接 - Removal of numbers
删除号码 - Removal of whitespaces
删除空格
小写 (Lowering Case)
Lowering the case of text is essential for the following reasons:
出于以下原因,减少文本的大小写是必不可少的:
- The words, ‘TEXT’, ‘Text’, ‘text’ all add the same value to a sentence
单词“ TEXT”,“ Text”,“ text”都为句子添加了相同的值 - Lowering the case of all the words is very helpful for reducing the dimensions by decreasing the size of the vocabulary
减少所有单词的大小写对于通过减小词汇量来减小维度非常有帮助
def to_lower(word): result = word.lower() return result删除特殊字符 (Removal of special characters)
This is another text processing technique that will help to treat words like ‘hurray’ and ‘hurray!’ in the same way.
这是另一种文本处理技术,将有助于处理“ hurray”和“ hurray!”之类的单词。 以同样的方式。
def remove_special_characters(word): result=word.translate(str.maketrans(dict.fromkeys(string.punctuation))) return result去除停用词 (Removal of stop words)
Stopwords are commonly occurring words in a language like ‘the’, ‘a’, and so on. Most of the time they can be removed from the text because they don’t provide valuable information.
停用词是常见的单词,如“ the”,“ a”等语言。 大多数情况下,由于它们不提供有价值的信息,因此可以将其从文本中删除。
def remove_stop_words(words): result = [i for i in words if i not in ENGLISH_STOP_WORDS] return result删除超链接 (Removal of hyperlinks)
Next, we remove any URLs in the data. There is a good chance that email will have some URLs in it. We don’t need them for our further analysis as they do not add any value to the results.
接下来,我们删除数据中的所有URL。 电子邮件很有可能会包含一些URL。 我们不需要它们进行进一步的分析,因为它们不会为结果增加任何价值。
def remove_hyperlink(word): return re.sub(r"http\S+", "", word)For more details on text preprocessing techniques, check out the article below.
有关文本预处理技术的更多详细信息,请查看下面的文章。
B.标记清理数据 (B. Tokenizing the Cleaned Data)
Tokenization is the process of splitting text into smaller chunks, called tokens. Each token is an input to the machine learning algorithm as a feature.
令牌化是将文本分成较小的块(称为令牌)的过程。 每个标记都是作为功能向机器学习算法输入的。
keras.preprocessing.text.Tokenizer is a utility function that tokenizes a text into tokens while keeping only the words that occur the most in the text corpus. When we tokenize the text, we end up with a massive dictionary of words, and they won’t all be essential. We can set ‘max_features’ to select the top frequent words that we want to consider.
keras.preprocessing.text.Tokenizer是一个实用程序功能,可将文本标记为标记,同时仅保留文本语料库中出现keras.preprocessing.text.Tokenizer的单词。 当我们标记文本时,我们最终得到了一个庞大的单词词典,它们并不是必不可少的。 我们可以设置' max_features '来选择我们要考虑的最常见的单词。
max_feature = 50000 #number of unique words to considerfrom keras.preprocessing.text import Tokenizertokenizer = Tokenizer(num_words=max_feature)tokenizer.fit_on_texts(x_train)x_train_features = np.array(tokenizer.texts_to_sequences(x_train))x_test_features = np.array(tokenizer.texts_to_sequences(x_test))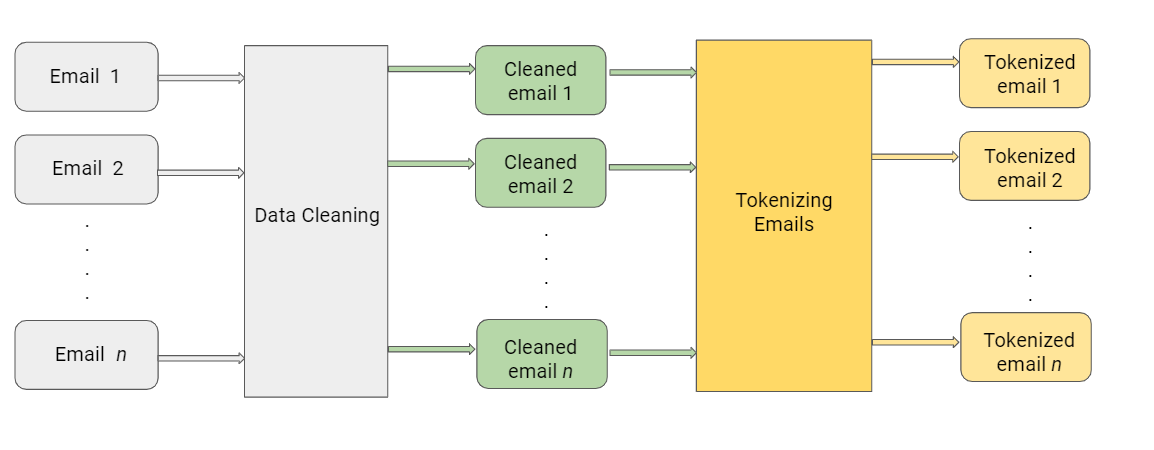

2.文本排序 (2. Text Sequencing)
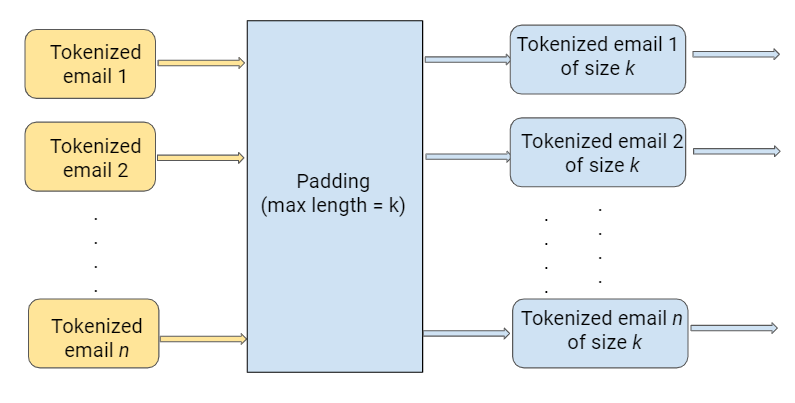
一个。 填充 (a. Padding)
Making the tokens for all emails an equal size is called padding.
使所有电子邮件的令牌大小相等称为填充 。
We send input in batches of data points. Information might be lost when inputs are of different sizes. So, we make them the same size using padding, and that eases batch updates.
我们分批发送输入数据点。 当输入大小不同时,信息可能会丢失。 因此,我们使用填充使它们具有相同的大小,从而简化了批量更新。
The length of all tokenized emails post-padding is set using ‘max_len’.
填充后所有标记的电子邮件的长度是使用“ max_len ”设置的。
Code snippet for padding :
用于填充的代码段:
from keras.preprocessing.sequence import pad_sequencesx_train_features = pad_sequences(x_train_features,maxlen=max_len)x_test_features = pad_sequences(x_test_features,maxlen=max_len)b。 标记编码目标变量 (b. Label the encoding target variable)
The model will expect the target variable as a number and not a string. We can use a Label encoder from sklearn, to convert our target variable as below.
模型将期望目标变量为数字而不是字符串。 我们可以使用sklearn,的Label编码器, sklearn,转换目标变量。
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()train_y = le.fit_transform(target_train.values)test_y = le.transform(target_test.values)
3.选型 (3. Model Selection)
A movie consists of a sequence of scenes. When we watch a particular scene, we don’t try to understand it in isolation, but rather in connection with previous scenes. In a similar fashion, a machine learning model has to understand the text by utilizing already-learned text, just like in a human neural network.
电影由一系列场景组成。 当我们观看一个特定的场景时,我们并不是试图孤立地理解它,而是与先前的场景联系起来。 就像在人类神经网络中一样,机器学习模型也必须通过利用已经学习的文本来理解文本。
In traditional machine learning models, we cannot store a model’s previous stages. However, Recurrent Neural Networks (commonly called RNN) can do this for us. Let’s take a closer look at RNNs below.
在传统的机器学习模型中,我们无法存储模型的先前阶段。 但是,递归神经网络(通常称为RNN)可以为我们做到这一点。 让我们仔细看看下面的RNN。
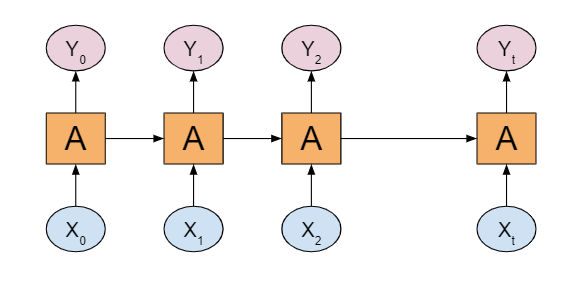
An RNN has a repeating module that takes input from the previous stage and gives its output as input to the next stage. However, in RNNs we can only retain information from the most recent stage. To learn long-term dependencies, our network needs memorization power. Here’s where Long Short Term Memory Networks (LSTMs) come to the rescue.
RNN具有一个重复模块,该模块接收来自上一级的输入,并将其输出作为输入提供给下一级。 但是,在RNN中,我们只能保留最近阶段的信息。 要了解长期依赖性,我们的网络需要记忆能力。 这就是抢救长期短期记忆网络(LSTM)的地方。
LSTMs are a special case of RNNs, They have the same chain-like structure as RNNs, but with a different repeating module structure.
LSTM是RNN的特例,它们具有与RNN相同的链状结构,但具有不同的重复模块结构。
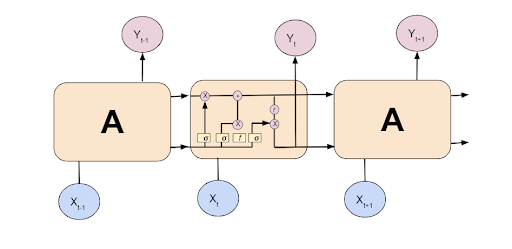
To perform LSTM even in reverse order, we’ll use a Bi-directional LSTM.
为了以相反的顺序执行LSTM,我们将使用双向LSTM。

4.实施 (4. Implementation)
嵌入 (Embedding)
Text data can be easily interpreted by humans. But for machines, reading and analyzing is a very complex task. To accomplish this task, we need to convert our text into a machine-understandable format.
文本数据很容易被人解释。 但是对于机器而言,读取和分析是一项非常复杂的任务。 为了完成此任务,我们需要将文本转换为机器可理解的格式。
Embedding is the process of converting formatted text data into numerical values/vectors which a machine can interpret.
嵌入是将格式化的文本数据转换为机器可以解释的数值/向量的过程。
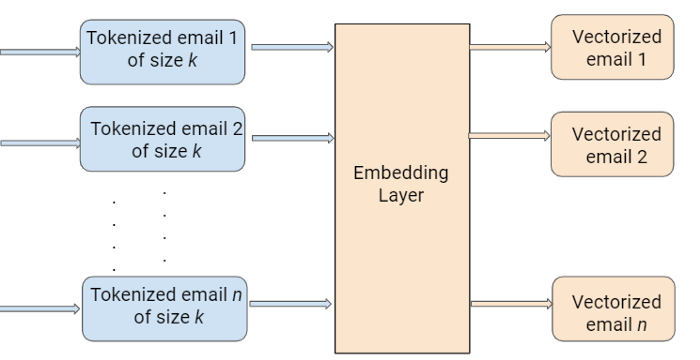
import tensorflow as tffrom keras.layers import Dense,LSTM, Embedding, Dropout, Activation, Bidirectional#size of the output vector from each layerembedding_vector_length = 32#Creating a sequential modelmodel = tf.keras.Sequential()#Creating an embedding layer to vectorizemodel.add(Embedding(max_feature, embedding_vector_length, input_length=max_len))#Addding Bi-directional LSTMmodel.add(Bidirectional(tf.keras.layers.LSTM(64)))#Relu allows converging quickly and allows backpropagationmodel.add(Dense(16, activation='relu'))#Deep Learninng models can be overfit easily, to avoid this, we add randomization using drop outmodel.add(Dropout(0.1))#Adding sigmoid activation function to normalize the outputmodel.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])print(model.summary())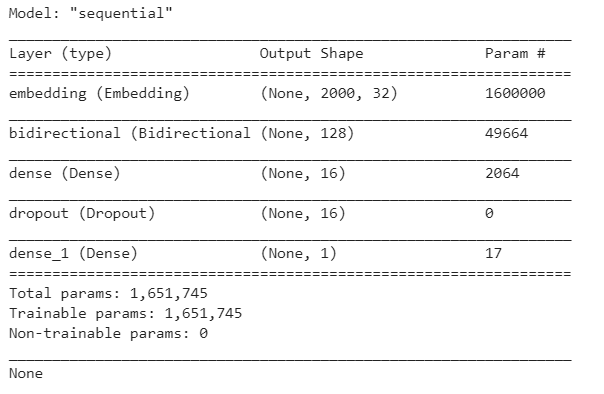
history = model.fit(x_train_features, train_y, batch_size=512, epochs=20, validation_data=(x_test_features, test_y))y_predict = [1 if o>0.5 else 0 for o in model.predict(x_test_features)]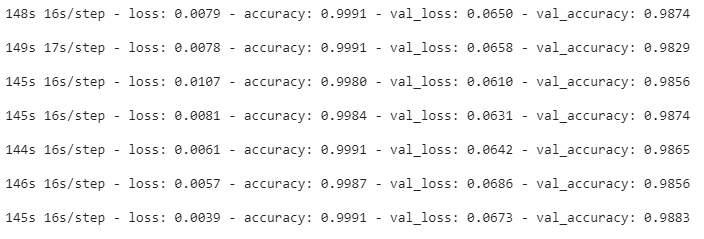
Through the above, we have successfully fit a bi-directional LSTM model on our email data and detected 125 of 1114 emails as spam.
通过以上操作,我们已经成功地在电子邮件数据上建立了双向LSTM模型,并检测到1114封电子邮件中有125封为垃圾邮件。
Since the percentage of spam in data is often low, Measuring the model’s performance by accuracy alone is not recommended. We need to evaluate it using other performance metrics as well, which we’ll look at below.
由于垃圾邮件在数据中的百分比通常较低,因此不建议仅通过准确性来衡量模型的性能。 我们还需要使用其他性能指标对其进行评估,我们将在下面进行介绍。

性能指标 (Performance Metrics)
Precision and recall are the two most widely used performance metrics for a classification problem to get a better understanding of the problem. Precision is the fraction of the relevant instances from all the retrieved instances. Precision helps us to understand how useful the results are. The recall is the fraction of relevant instances from all the relevant instances. Recall helps us understand how complete the results are.
精度和召回率是分类问题中使用最广泛的两个性能指标,可以更好地理解该问题。 精度是所有检索到的实例中相关实例的分数。 精度可以帮助我们了解结果的实用性。 召回是所有相关实例中相关实例的一部分。 召回有助于我们了解结果的完整性。
The F1 Score is the harmonic mean of precision and recall.
F1分数是精确度和查全率的谐波平均值。
For example, consider that a search query results in 30 pages, of which 20 are relevant, but the results fail to display 40 other relevant results. In this case, the precision is 20/30, and recall is 20/60. Therefore, our F1 Score is 4/9.
例如,假设一个搜索查询的结果为30个页面,其中20个是相关的,但是该结果无法显示40个其他相关的结果。 在这种情况下,精度为20/30,召回率为20/60。 因此,我们的F1得分是4/9。
Using F1-score as a performance metric for spam detection problems is a good choice.
将F1分数用作垃圾邮件检测问题的性能指标是一个不错的选择。
from sklearn.metrics import confusion_matrix,f1_score, precision_score,recall_scorecf_matrix =confusion_matrix(test_y,y_predict)tn, fp, fn, tp = confusion_matrix(test_y,y_predict).ravel()print("Precision: {:.2f}%".format(100 * precision_score(test_y, y_predict)))print("Recall: {:.2f}%".format(100 * recall_score(test_y, y_predict)))print("F1 Score: {:.2f}%".format(100 * f1_score(test_y,y_predict)))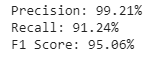
import seaborn as snsimport matplotlib.pyplot as pltax= plt.subplot()#annot=True to annotate cellssns.heatmap(cf_matrix, annot=True, ax = ax,cmap='Blues',fmt='');# labels, title and ticksax.set_xlabel('Predicted labels');ax.set_ylabel('True labels');ax.set_title('Confusion Matrix');ax.xaxis.set_ticklabels(['Not Spam', 'Spam']); ax.yaxis.set_ticklabels(['Not Spam', 'Spam']);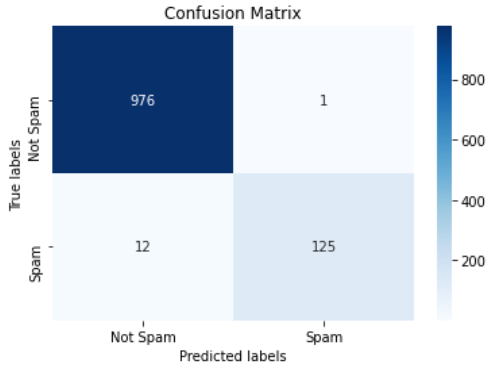
A model with an F1 score of 95% is a good-to-go model. Keep in mind, however, that these results are based on the training data we used. When applying a model like this to real-world data, we still need to actively monitor the model’s performance over time. We can also continue to improve the model by responding to results and feedback by doing things like adding features and removing misspelled words.
F1分数为95%的模型是不错的模型。 但是请记住,这些结果基于我们使用的训练数据。 在将这样的模型应用于实际数据时,我们仍然需要随着时间的推移积极地监视模型的性能。 我们还可以通过执行诸如添加功能和删除拼写错误的单词之类的结果来响应结果和反馈,从而继续改进模型。

摘要 (Summary)
In this article, we created a spam detection model by converting text data into vectors, creating a BiLSTM model, and fitting the model with the vectors. We also explored a variety of text processing techniques, text sequencing techniques, and deep learning models, namely RNN, LSTM, BiLSTM.
在本文中,我们通过将文本数据转换为向量,创建BiLSTM模型并使用向量对模型进行拟合来创建垃圾邮件检测模型。 我们还探索了多种文本处理技术,文本排序技术和深度学习模型,即RNN,LSTM,BiLSTM。
The concepts and techniques learned in this article can be applied to a variety of natural language processing problems like building chatbots, text summarization, language translation models.
本文中学到的概念和技术可以应用于各种自然语言处理问题,例如构建聊天机器人,文本摘要,语言翻译模型。

If you would like to experiment with the custom dataset yourself, you can download the annotated data on UCI machine learning repository and the code at Github. This article is originally published on Lionbridge.ai.
如果您想自己尝试使用自定义数据集,则可以在UCI机器学习存储库上下载带注释的数据,并在Github上下载代码。 本文最初在Lionbridge.ai上发布。
Thanks for the read. I am going to write more beginner-friendly posts in the future too. Follow me up on Medium to be informed about them. I welcome feedback and can be reached out on Twitter ramya_vidiyala and LinkedIn RamyaVidiyala. Happy learning!
感谢您的阅读。 我将来也会写更多对初学者友好的文章。 跟我上Medium ,以了解有关它们的信息。 我欢迎您提供反馈,可以在Twitter ramya_vidiyala和LinkedIn RamyaVidiyala上与他们联系 。 学习愉快!
翻译自: https://towardsdatascience.com/spam-detection-in-emails-de0398ea3b48
正则表达式检测电子邮件
相关文章:
- Zuul1与Spring Cloud Gateway的区别
- mysql制作搜索引擎_MySQL 实现一个简单版搜索引擎,真是绝了!
- 正和岛青年徽商正和塾小组2021年首聚—走进掌榕
- oracle调优(1)
- DevExtreme UI框架在可视化应用程序Nvisual中的实践应用
- 简述计算机视觉中的单眼线索,知觉-心理学文章-壹心理
- 曾经,被嫌弃的腾讯股权——读《腾讯传》
- 【观察】从新华三2022十大技术趋势,看数字化如何重塑未来社会
- Apache HBase
- 指数投资的收益幻觉
- 关于动态抽样(Dynamic Sampling)
- 第二章:线性表
- HA 高可用软件系统保养指南
- 程序员如何写好简历 一份优秀的程序员简历是什么样的?
- 如何面对失败?
- 是性格决定命运,还是命运造就性格?
- 惊叹!前NASA员工绘大型精美地面立体画(高清组图)
- 三维形体的数据结构(1)半边数据结构
- 美国计算机加音乐专业,美国音乐博士解析
- 电网负荷调度三维组态软件V2.0
- python制作猫和老鼠游戏我觉得可以学一手@
- 夏目漱石《我是猫》读后感
- mac键盘上符号的快捷键_Mac键盘符号实际上是什么意思?
- python print输出指定小数位数
- Double 判断小数位数
- JavaScript保留小数位数代码
- mysql 保留小数位数
- mysql保留小数位数函数
- java判断小数位数_java如何获取一个double的小数位数
- java精确小数位数的几种方法
正则表达式检测电子邮件_电子邮件中的垃圾邮件检测相关推荐
- 使用自然语言处理来检测电子邮件中的垃圾邮件
Have you ever wondered how a machine translates language? Or how voice assistants respond to questio ...
- 垃圾邮件检测_如何在您的电子邮件中检测垃圾邮件
垃圾邮件检测 Nowadays, the SPAM coming into your mailbox is disguised forms of any type of trying to look ...
- 5.11 程序示例--垃圾邮件检测-机器学习笔记-斯坦福吴恩达教授
程序示例–垃圾邮件检测 邮件内容的预处理 下面展示了一封常见的 email,邮件内容包含了一个 URL (http://www.rackspace.com/),一个邮箱地址(groupname-uns ...
- 电子邮件服务器限制匿名,匿名(垃圾)邮件的根源—网络上几乎所有服务器都不可避免的“漏洞-站长资讯中心...
大家在看到这篇文章的小标题的时候,或许很多人都知道了这个"漏洞",而有的人在看文章的过程中,知道这个"漏洞",也有的人或许会惊诧,因为小标题好像说得太过严重,不 ...
- 垃圾邮件分类器_如何在10个步骤中构建垃圾邮件分类器
垃圾邮件分类器 If you're just starting out in Machine Learning, chances are you'll be undertaking a classif ...
- python垃圾邮件识别_【Python】垃圾邮件识别
下载W3Cschool手机App,0基础随时随地学编程 导语 利用简单的机器学习算法实现垃圾邮件识别. 让我们愉快地开始吧~ 相关文件 密码: qa49 数据集源于网络,侵歉删. 开发工具 Pytho ...
- yolov3为什么对大目标检测不好_基于改进Yolov3的目标检测的研究
晏世武 罗金良 严庆 摘要:目标检测在视频监控.无人驾驶系统.机械自动化等领域起着重要作用.在如今大数据的背景下,为进一步提高Yolov3在不同数据集下的性能,本文以KITTI数据集为基础,利用重新調 ...
- 朴素贝叶斯算法代码实现(垃圾邮件检测)
1.文本预处理 (1)分词 首先需要对文本进行分词操作,转换为list,同时词语全部小写,并去除字母数量小于等于2的单词 # 将词切分为list def textParse(input_string) ...
- 编程基础 垃圾回收_编程中的垃圾回收指南
编程基础 垃圾回收 什么是垃圾回收? (What is Garbage Collection?) In general layman's terms, Garbage collection (GC) ...
最新文章
- 查看已安装tensorflow版本
- 利用spring session解决共享Session问题
- 时代天使点燃口腔赛道,瑞尔集团离下一只“牙茅”还有多远?
- swift语言 数组定义_Swift3中数组创建方法
- 从Java角度看Golang
- 【动态规划】叠放箱子问题(ssl 1640)
- 前端学习(2101):javascript高阶函数得使用
- java 循环删除hashmap中的键值对,解决java.util.ConcurrentModificationException报错
- Stack与queue的底层实现、区别。
- 《C++游戏开发》笔记十三 平滑过渡的战争迷雾(一) 原理:Warcraft3地形拼接算法...
- 我大学时代的好朋友要结婚了!
- 防勒索病毒的个人解析
- json rpgmv 加密_【RPG Maker MV插件编程】【实例教程6】存档的加密解密与保护
- Linux 使用shell命令复制文件
- java new jsonparser_JsonParser is deprecated
- win10 蓝牙忽然消失 华硕主板
- HBase整合MR本地IDEA运行
- P1606 [USACO07FEB]荷叶塘Lilypad Pond(最短路计数)
- nnDetection复现Luna16 附模型
- java中的applet的问题