Spark之SparkStreaming理论篇
简介
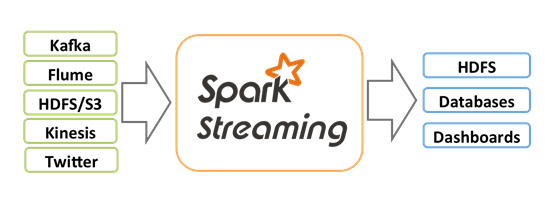
Spark Streaming用于流式数据的处理。Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。结果也能保存在很多地方,如HDFS,数据库等。Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。
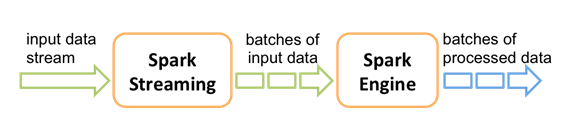
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的DStream。支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
对比
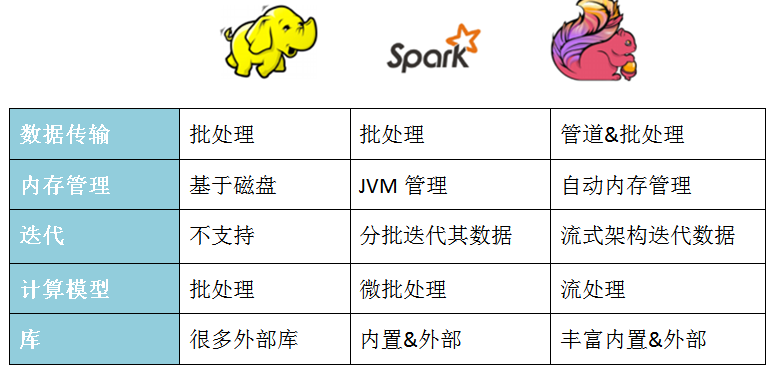
批处理比较
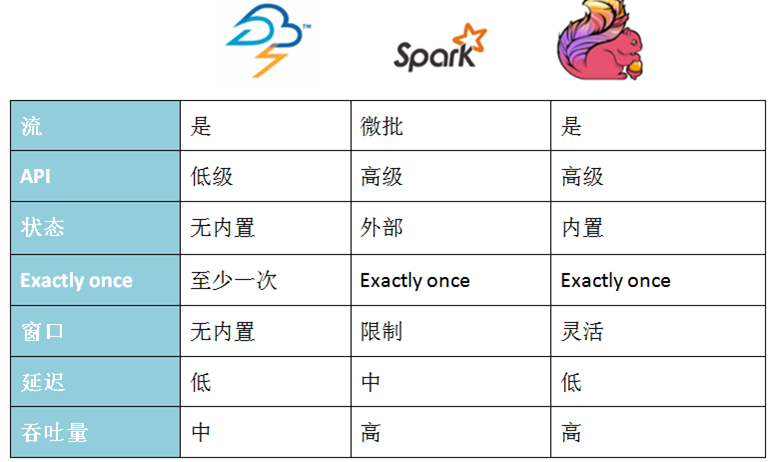
流处理比较
后续会更新Flink的学习笔记。
HelloWorld
pom
1234567891011121314151617181920 |
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>sparkstreaming</artifactId> <groupId>com.hph</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion>
<artifactId>helloworld</artifactId> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> </dependency> </dependencies>
</project>
|
123456789101112131415161718192021222324 |
import org.apache.spark.SparkConfimport org.apache.spark.streaming.{Seconds, StreamingContext}
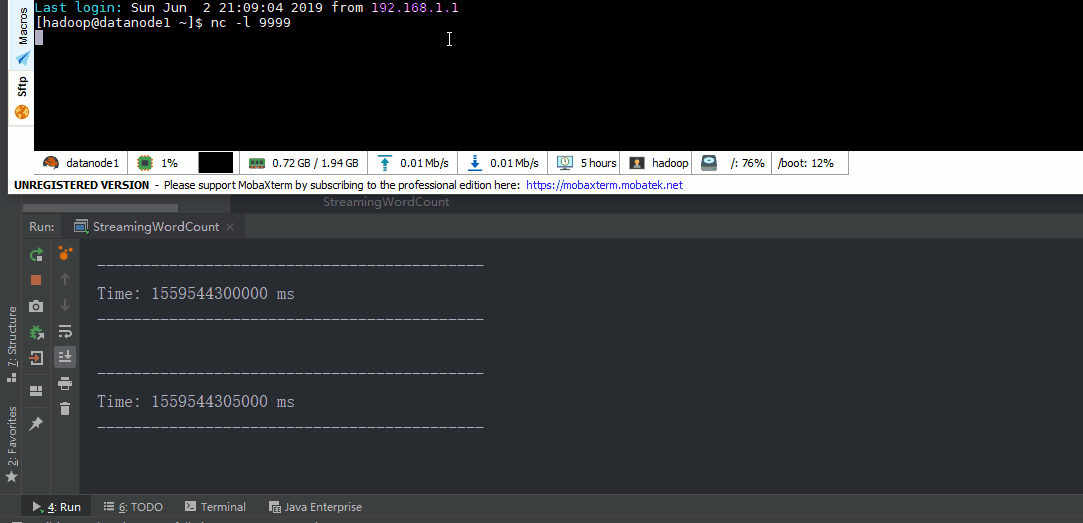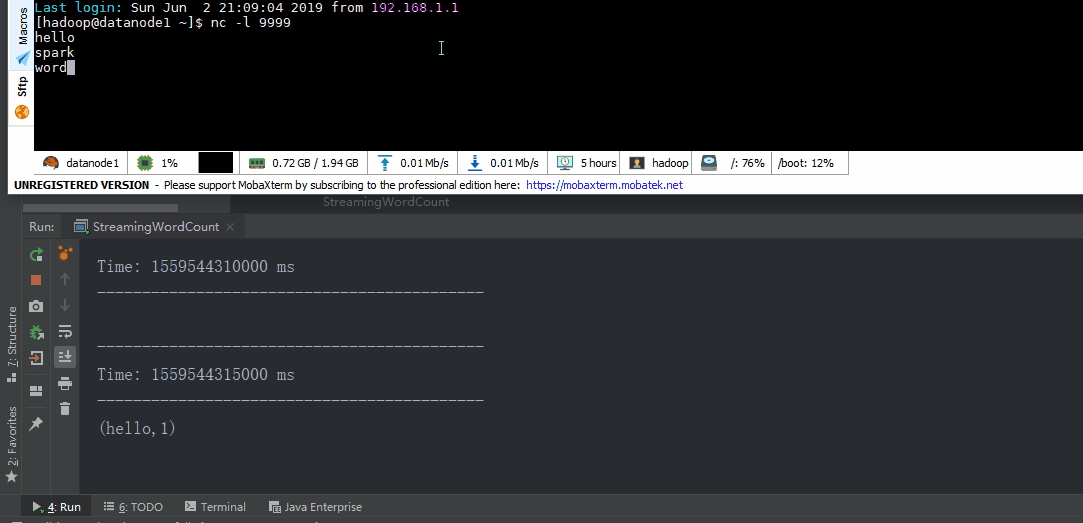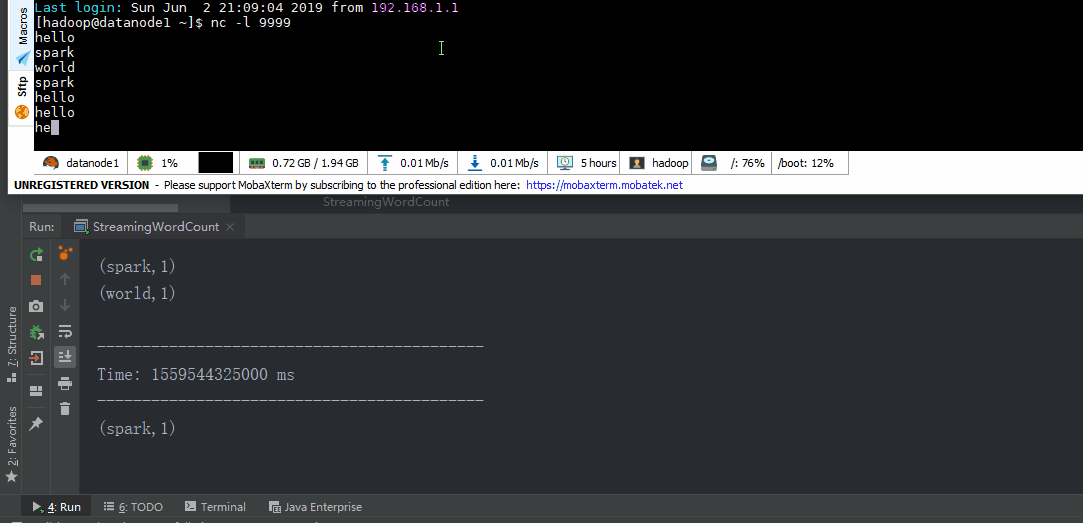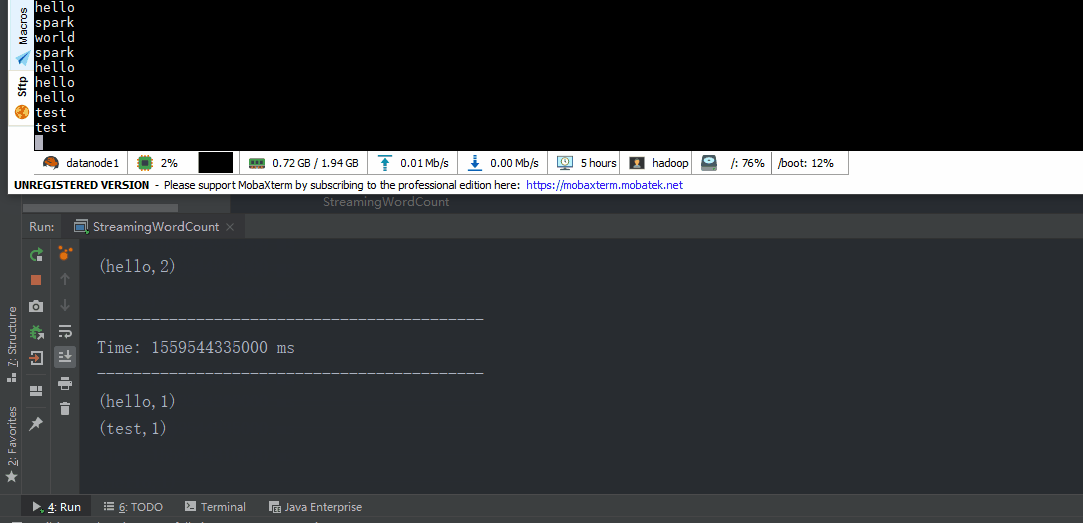
object StreamingWordCount extends App { //创建配置 val sparkConf = new SparkConf().setAppName("streaming word count").setMaster("local[*]") //创建StreamingContext val ssc = new StreamingContext(sparkConf, Seconds(5)) //从socket接口数据 val lineDStream = ssc.socketTextStream("datanode1", 9999)
val wordDStream = lineDStream.flatMap(_.split(" ")) val word2CountDStream = wordDStream.map((_, 1)) val result = word2CountDStream.reduceByKey(_ + _)
result.print()
//启动 ssc.start() ssc.awaitTermination()
}
|
模式
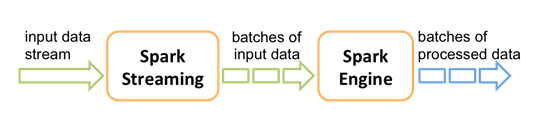
Spark Streaming使用“微批次”的架构,把流式计算看作一系列连续的小规模批处理来对待。Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD。 处理的结果可以以批处理的方式传给外部系统。因此严格意义上来说Spark Streaming并不是一个真正的实时计算框架。
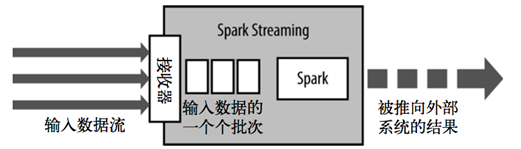
Spark Streaming的编程抽象是离散化流,也就是DStream。它是一个 RDD 序列,每个RDD代表数据流中一个时间片内的数据。

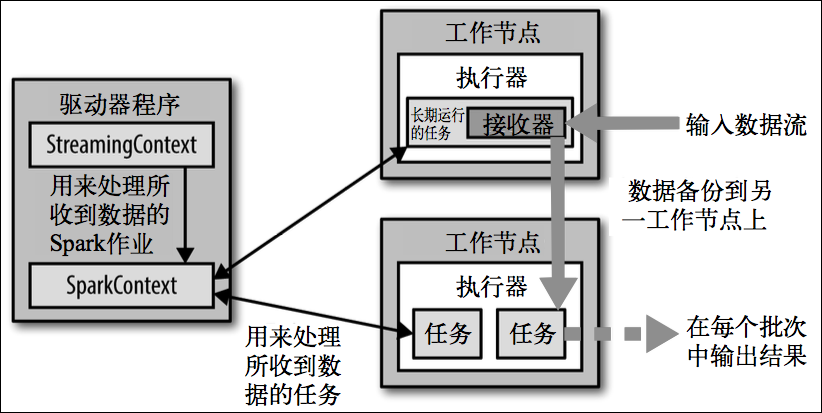
Spark Streaming 在 Spark 的驱动器程序 工作节点的结构的执行过程如下图所示。Spark Streaming 为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为 RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样。驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
注意
StreamingContext一旦启动,对DStreams的操作就不能修改了。
在同一时间一个JVM中只有一个StreamingContext可以启动
stop() 方法将同时停止SparkContext,可以传入参数stopSparkContext用于只停止StreamingContext
在Spark1.4版本后,如何优雅的停止SparkStreaming而不丢失数据,通过设置sparkConf.set(“spark.streaming.stopGracefullyOnShutdown”,”true”) 即可。在StreamingContext的start方法中已经注册了Hook方法。
12345678910111213141516171819202122232425262728293031323334353637383940414243 |
def start(): Unit = synchronized { state match { case INITIALIZED => startSite.set(DStream.getCreationSite()) StreamingContext.ACTIVATION_LOCK.synchronized { StreamingContext.assertNoOtherContextIsActive() try { validate()
// Start the streaming scheduler in a new thread, so that thread local properties // like call sites and job groups can be reset without affecting those of the // current thread. ThreadUtils.runInNewThread("streaming-start") { sparkContext.setCallSite(startSite.get) sparkContext.clearJobGroup() sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false") savedProperties.set(SerializationUtils.clone(sparkContext.localProperties.get())) scheduler.start() } state = StreamingContextState.ACTIVE } catch { case NonFatal(e) => logError("Error starting the context, marking it as stopped", e) scheduler.stop(false) state = StreamingContextState.STOPPED throw e } StreamingContext.setActiveContext(this) } logDebug("Adding shutdown hook") // force eager creation of logger shutdownHookRef = ShutdownHookManager.addShutdownHook( StreamingContext.SHUTDOWN_HOOK_PRIORITY)(stopOnShutdown) // Registering Streaming Metrics at the start of the StreamingContext assert(env.metricsSystem != null) env.metricsSystem.registerSource(streamingSource) uiTab.foreach(_.attach()) logInfo("StreamingContext started") case ACTIVE => logWarning("StreamingContext has already been started") case STOPPED => throw new IllegalStateException("StreamingContext has already been stopped") } }
|
DStreams
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据。
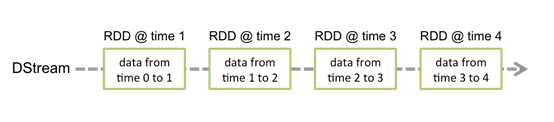
对数据的操作也是按照RDD为单位来进行的
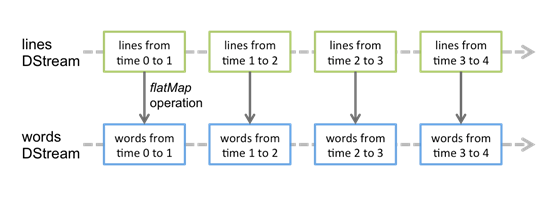
计算过程由Spark engine来完成
Spark之SparkStreaming理论篇相关推荐
- Spark之SparkSQL理论篇
Spark SQL 理论学习: 简介 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用. 特点 1)易整合 2) ...
- Spark之RDD理论篇
Spark的基石RDD: RDD与MapReduce Spark的编程模型是弹性分布式数据集(Resilient Distributed Dataset,RDD),它是MapReduce的扩展和延申, ...
- 一口气说完MR、Storm、Spark、SparkStreaming和Flink
这是彭文华的第92篇原创 一直想写一篇大数据计算引擎的综述,但是这个话题有点大.今天试试看能不能一口气写完.没想到一口气从7点写到了凌晨2点 大数据计算的起点是Hadoop的MapReduce.之前虽 ...
- 艾伟_转载:学习 ASP.NET MVC (第五回)理论篇
本系列文章导航 学习 ASP.NET MVC (第一回)理论篇 学习 ASP.NET MVC (第二回)实战篇 学习 ASP.NET MVC (第三回)实战篇 学习 ASP.NET MVC (第四回) ...
- 一步步教你轻松学朴素贝叶斯模型算法理论篇1
一步步教你轻松学朴素贝叶斯模型理论篇1 (白宁超2018年9月3日17:51:32) 导读:朴素贝叶斯模型是机器学习常用的模型算法之一,其在文本分类方面简单易行,且取得不错的分类效果.所以很受欢迎,对 ...
- RabbitMQ学习总结 第一篇:理论篇
目录 RabbitMQ学习总结 第一篇:理论篇 RabbitMQ学习总结 第二篇:快速入门HelloWorld RabbitMQ学习总结 第三篇:工作队列Work Queue RabbitMQ学习总结 ...
- 解密回声消除技术之一(理论篇)
http://hulong988.blog.51cto.com 解密回声消除技术之一(理论篇) 2009-06-11 22:24:58 标签:语音 职场 休闲 通讯 原创作品,允许转载,转载时请务必以 ...
- 【机器学习】Logistic Regression 的前世今生(理论篇)
Logistic Regression 的前世今生(理论篇) 本博客仅为作者记录笔记之用,不免有很多细节不对之处. 还望各位看官能够见谅,欢迎批评指正. 博客虽水,然亦博主之苦劳也. 如需转载,请附上 ...
- php switch 函数,PHP丨PHP基础知识之条件语SWITCH判断「理论篇」
Switch在一些计算机语言中是保留字,其作用大多情况下是进行判断选择.以PHP来说,switch(开关语句)常和case break default一起使用 典型结构 switch($control ...
最新文章
- 近段时间佛我就偶尔无
- 基于sqlcmd命令行工具管理SQL server
- Oracle 中重新编译无效的存储过程, 或函数、触发器等对象(转)
- Java编程思想之-匿名内部类
- P2766-最长不下降子序列问题【网络流,dp】
- 工作235:splice
- oracle转sparksql工具化,不使用Sqoop流程,利用CacheManager直接完成SparkSQL数据流直接回写Oracle...
- 前端开发知识点解答-HTML-面试
- php简单验证码实例,php结合GD库简单实现验证码的示例代码
- 【TI-ONE系列教程(四)】如何使用 TI-ONE Notebook 玩转算法大赛
- 二维分类教案_屈老师中班数学教案《有趣的笔》
- win 7更改计算机用户名和密码错误,win7系统一开机就显示用户名和密码错误故障的解决方法...
- 官方验证!雨林木风 Ghost XP SP3 装机版 ylmf_xp3_yn9.8 !!附:官方全部MD5!
- ROS教程(四):RVIZ使用教程(详细图文)
- 服务器空文件夹无法删除怎么办,空的文件夹无法删除怎么办 空的文件夹无法删除的原因【图文】...
- Jenkins Pipeline 一键部署SpringBoot项目
- 基于Spring+SpringMVC+MyBatis超市进销存管理系统
- A Game of Thrones(11)
- c语言 运行出现错误代码,运行出现 debug error
- Gido推出电商快递服务,从中国到越南只需三天