Tensorflow学习—— 预创建的 Estimator
预创建的 Estimator
本文档介绍了 TensorFlow 编程环境,并向您展示了如何在 TensorFlow 中解决鸢尾花分类问题。
前提条件
在使用本文档中的示例代码之前,您需要执行以下操作:
- 安装 TensorFlow。
- 如果您是使用 virtualenv 或 Anaconda 安装的 TensorFlow,请激活您的 TensorFlow 环境。
通过执行以下命令来安装或升级 Pandas:
pip install pandas
获取示例代码
按照下列步骤获取我们将要使用的示例代码:
通过输入以下命令从 GitHub 克隆 TensorFlow 模型代码库:
git clone https://github.com/tensorflow/models将此分支内的目录更改为包含本文档中所用示例的位置:
cd models/samples/core/get_started/本文档中介绍的程序是 premade_estimator.py。此程序使用 iris_data.py 获取其训练数据。
运行程序
您可以像运行任何 Python 程序一样运行 TensorFlow 程序。例如:
python premade_estimator.py该程序应该会输出训练日志,然后对测试集进行一些预测。例如,以下输出的第一行显示该模型认为测试集中的第一个样本是山鸢尾的可能性为 99.6%。由于测试集中的第一个样本确实是山鸢尾,因此该模型预测得还比较准确。
...
Prediction is "Setosa" (99.6%), expected "Setosa"Prediction is "Versicolor" (99.8%), expected "Versicolor"Prediction is "Virginica" (97.9%), expected "Virginica"如果程序生成错误(而不是答案),请思考下列问题:
- 您是否正确安装了 TensorFlow?
- 您使用的 TensorFlow 版本是否正确?
- 您是否激活了 TensorFlow 所在的安装环境?(此问题仅与某些安装机制有关。)
编程堆栈
在详细了解程序本身之前,我们先来了解编程环境。如下图所示,TensorFlow 提供一个包含多个 API 层的编程堆栈:
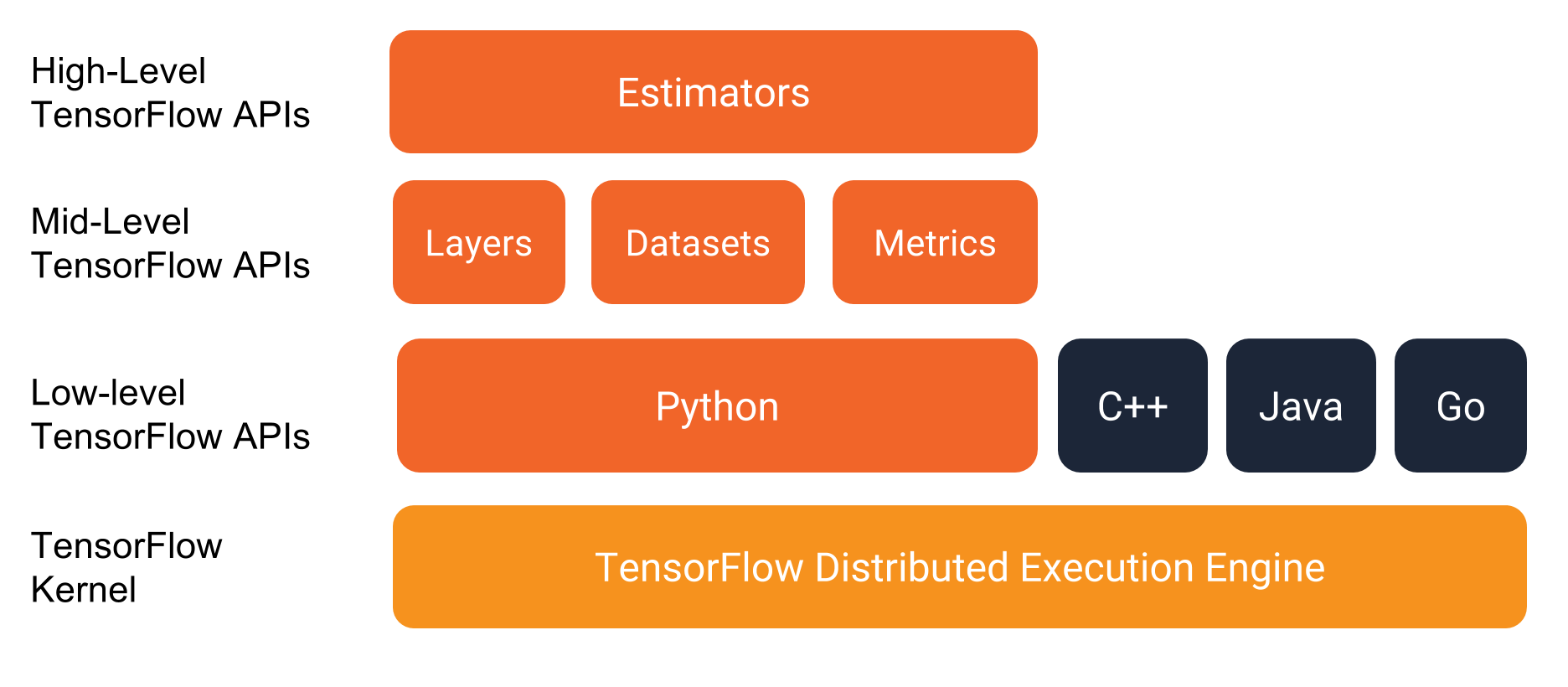
我们强烈建议使用下列 API 编写 TensorFlow 程序:
- Estimator:代表一个完整的模型。Estimator API 提供一些方法来训练模型、判断模型的准确率并生成预测。
- Estimator 的数据集:构建数据输入管道。Dataset API 提供一些方法来加载和操作数据,并将数据馈送到模型中。Dataset API 与 Estimator API 合作无间。
对鸢尾花进行分类:概览
本文档中的示例程序构建并测试了一个模型,此模型根据鸢尾花的花萼和花瓣大小将其分为三种不同的品种。

从左到右:山鸢尾(提供者:Radomil,依据 CC BY-SA 3.0 使用)、变色鸢尾(提供者:Dlanglois,依据 CC BY-SA 3.0 使用)和维吉尼亚鸢尾(提供者:Frank Mayfield,依据 CC BY-SA 2.0 使用)。
数据集
鸢尾花数据集包含四个特征和一个标签。这四个特征确定了单株鸢尾花的下列植物学特征:
- 花萼长度
- 花萼宽度
- 花瓣长度
- 花瓣宽度
我们的模型会将这些特征表示为 float32 数值数据。
该标签确定了鸢尾花品种,品种必须是下列任意一种:
- 山鸢尾 (0)
- 变色鸢尾 (1)
- 维吉尼亚鸢尾 (2)
我们的模型会将该标签表示为 int32 分类数据。
下表显示了数据集中的三个样本:
| 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 | 品种(标签) |
|---|---|---|---|---|
| 5.1 | 3.3 | 1.7 | 0.5 | 0(山鸢尾) |
| 5.0 | 2.3 | 3.3 | 1.0 | 1(变色鸢尾) |
| 6.4 | 2.8 | 5.6 | 2.2 | 2(维吉尼亚鸢尾) |
算法
该程序会训练一个具有以下拓扑结构的深度神经网络分类器模型:
- 2 个隐藏层。
- 每个隐藏层包含 10 个节点。
下图展示了特征、隐藏层和预测(并未显示隐藏层中的所有节点):
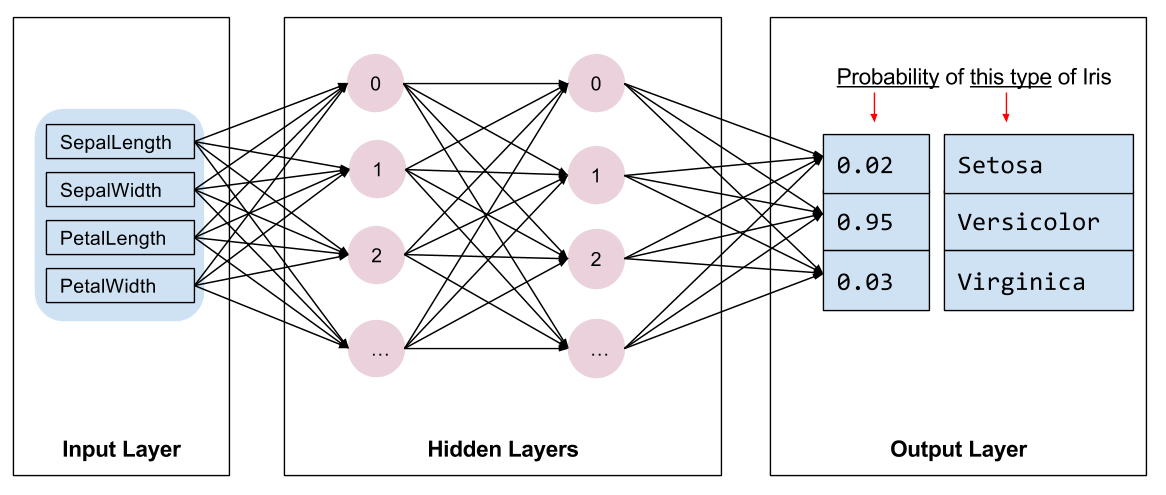
推理
在无标签样本上运行经过训练的模型会产生三个预测,即相应鸢尾花属于指定品种的可能性。这些输出预测的总和是 1.0。例如,对无标签样本的预测可能如下所示:
- 0.03(山鸢尾)
- 0.95(变色鸢尾)
- 0.02(维吉尼亚鸢尾)
上面的预测表示指定无标签样本是变色鸢尾的概率为 95%。
采用 Estimator 进行编程的概览
Estimator 是 TensorFlow 对完整模型的高级表示。它会处理初始化、日志记录、保存和恢复等细节部分,并具有很多其他功能,以便您可以专注于模型。有关更多详情,请参阅 Estimator。
Estimator 是从 tf.estimator.Estimator 衍生而来的任何类。TensorFlow 提供一组预创建的 Estimator(例如 LinearRegressor)来实现常见的机器学习算法。除此之外,您可以编写自定义 Estimator。我们建议在刚开始使用 TensorFlow 时使用预创建的 Estimator。
要根据预创建的 Estimator 编写 TensorFlow 程序,您必须执行下列任务:
- 创建一个或多个输入函数。
- 定义模型的特征列。
- 实例化 Estimator,指定特征列和各种超参数。
- 在 Estimator 对象上调用一个或多个方法,传递适当的输入函数作为数据的来源。
我们来看看如何针对鸢尾花分类实施这些任务。
创建输入函数
您必须创建输入函数来提供用于训练、评估和预测的数据。
输入函数是返回 tf.data.Dataset 对象的函数,此对象会输出下列含有两个元素的元组:
features- Python 字典,其中:- 每个键都是特征的名称。
- 每个值都是包含此特征所有值的数组。
label- 包含每个样本的标签值的数组。
为了向您展示输入函数的格式,请查看下面这个简单的实现:
def input_evaluation_set():features = {'SepalLength': np.array([6.4, 5.0]),'SepalWidth': np.array([2.8, 2.3]),'PetalLength': np.array([5.6, 3.3]),'PetalWidth': np.array([2.2, 1.0])}labels = np.array([2, 1])return features, labels输入函数可以以您需要的任何方式生成 features 字典和 label 列表。不过,我们建议使用 TensorFlow 的 Dataset API,它可以解析各种数据。概括来讲,Dataset API 包含下列类:
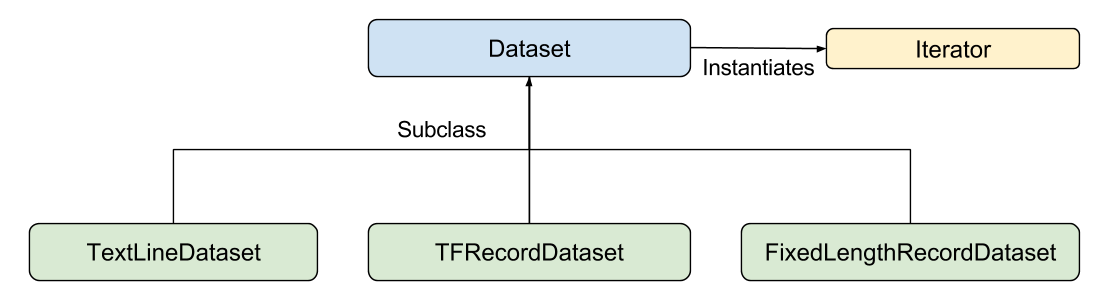
各个类如下所示:
Dataset- 包含创建和转换数据集的方法的基类。您还可以通过该类从内存中的数据或 Python 生成器初始化数据集。TextLineDataset- 从文本文件中读取行。TFRecordDataset- 从 TFRecord 文件中读取记录。FixedLengthRecordDataset- 从二进制文件中读取具有固定大小的记录。Iterator- 提供一次访问一个数据集元素的方法。
Dataset API 可以为您处理很多常见情况。例如,使用 Dataset API,您可以轻松地从大量并行文件中读取记录,并将它们合并为单个数据流。
为了简化此示例,我们将使用 Pandas 加载数据,并利用此内存中的数据构建输入管道。
以下是用于在此程序中进行训练的输入函数(位于 iris_data.py 中):
def train_input_fn(features, labels, batch_size):"""An input function for training"""# Convert the inputs to a Dataset.dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))# Shuffle, repeat, and batch the examples.return dataset.shuffle(1000).repeat().batch(batch_size)定义特征列
特征列是一个对象,用于说明模型应该如何使用特征字典中的原始输入数据。在构建 Estimator 模型时,您会向其传递一个特征列的列表,其中包含您希望模型使用的每个特征。tf.feature_column 模块提供很多用于在模型中表示数据的选项。
对于鸢尾花问题,4 个原始特征是数值,因此我们会构建一个特征列的列表,以告知 Estimator 模型将这 4 个特征都表示为 32 位浮点值。因此,创建特征列的代码如下所示:
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():my_feature_columns.append(tf.feature_column.numeric_column(key=key))特征列可能比上述示例复杂得多。我们将在入门指南的后面部分详细介绍特征列。
我们已经介绍了希望模型如何表示原始特征,现在可以构建 Estimator 了。
实例化 Estimator
鸢尾花问题是一个经典的分类问题。幸运的是,TensorFlow 提供了几个预创建的分类器 Estimator,其中包括:
tf.estimator.DNNClassifier:适用于执行多类别分类的深度模型。tf.estimator.DNNLinearCombinedClassifier:适用于宽度和深度模型。tf.estimator.LinearClassifier:适用于基于线性模型的分类器。
对于鸢尾花问题,tf.estimator.DNNClassifier 似乎是最好的选择。我们将如下所示地实例化此 Estimator:
# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer.
classifier = tf.estimator.DNNClassifier(feature_columns=my_feature_columns,# Two hidden layers of 10 nodes each.hidden_units=[10, 10],# The model must choose between 3 classes.n_classes=3)训练、评估和预测
我们已经有一个 Estimator 对象,现在可以调用方法来执行下列操作:
- 训练模型。
- 评估经过训练的模型。
- 使用经过训练的模型进行预测。
训练模型
通过调用 Estimator 的 train 方法训练模型,如下所示:
# Train the Model.
classifier.train(input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),steps=args.train_steps)我们将 input_fn 调用封装在 lambda 中以获取参数,同时提供一个不采用任何参数的输入函数,正如 Estimator 预计的那样。steps 参数告知方法在训练多步后停止训练。
评估经过训练的模型
模型已经过训练,现在我们可以获取一些关于其效果的统计信息。以下代码块会评估经过训练的模型对测试数据进行预测的准确率:
# Evaluate the model.
eval_result = classifier.evaluate(input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))与我们对 train 方法的调用不同,我们没有传递 steps 参数来进行评估。我们的 eval_input_fn 只生成一个周期的数据。
运行此代码会生成以下输出(或类似输出):
Test set accuracy: 0.967利用经过训练的模型进行预测(推理)
我们已经有一个经过训练的模型,可以生成准确的评估结果。我们现在可以使用经过训练的模型,根据一些无标签测量结果预测鸢尾花的品种。与训练和评估一样,我们使用单个函数调用进行预测:
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {'SepalLength': [5.1, 5.9, 6.9],'SepalWidth': [3.3, 3.0, 3.1],'PetalLength': [1.7, 4.2, 5.4],'PetalWidth': [0.5, 1.5, 2.1],
}predictions = classifier.predict(input_fn=lambda:iris_data.eval_input_fn(predict_x,batch_size=args.batch_size))predict 方法返回一个 Python 可迭代对象,为每个样本生成一个预测结果字典。以下代码输出了一些预测及其概率:
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')for pred_dict, expec in zip(predictions, expected):class_id = pred_dict['class_ids'][0]probability = pred_dict['probabilities'][class_id]print(template.format(iris_data.SPECIES[class_id],100 * probability, expec))运行上面的代码会生成以下输出:
...
Prediction is "Setosa" (99.6%), expected "Setosa"Prediction is "Versicolor" (99.8%), expected "Versicolor"Prediction is "Virginica" (97.9%), expected "Virginica"总结
使用预创建的 Estimator 可以快速高效地创建标准模型。
您已经开始编写 TensorFlow 程序,现在请查看以下资料:
- 检查点:了解如何保存和恢复模型。
- Estimator 的数据集:详细了解如何将数据导入模型中。
- 创建自定义 Estimator:了解如何编写针对特定问题进行自定义的 Estimator。
Tensorflow学习—— 预创建的 Estimator相关推荐
- Tensorflow学习—— Estimator简介
本文档介绍了 Estimator - 一种可极大地简化机器学习编程的高阶 TensorFlow API.Estimator 会封装下列操作: 训练 评估 预测 导出以供使用 您可以使用我们提供的预创建 ...
- 创建自定义 Estimator
ref 本文档介绍了自定义 Estimator.具体而言,本文档介绍了如何创建自定义 Estimator 来模拟预创建的 Estimator DNNClassifier 在解决鸢尾花问题时的行为.要详 ...
- Win10:tensorflow学习笔记(4)
前言 学以致用,以学促用.输出检验,完整闭环. 经过前段时间的努力,已经在电脑上搭好了深度学习系统,接下来就要开始跑程序了,将AI落地了. 安装win10下tensforlow 可以参照之前的例子:w ...
- Tensorflow学习——Keras
Keras 是一个用于构建和训练深度学习模型的高阶 API.它可用于快速设计原型.高级研究和生产,具有以下三个主要优势: 方便用户使用 Keras 具有针对常见用例做出优化的简单而一致的界面.它可针对 ...
- TensorFlow学习笔记12----Creating Estimators in tf.contrib.learn
原文教程:tensorflow官方教程 记录关键内容与学习感受.未完待续.. Creating Estimators in tf.contrib.learn --tf.contrib.learn框架, ...
- Tensorflow笔记(八)——Estimator
1.概述 TF1.3开始引入estimator,通过框架图可以看到Estimator是属于High level的API,而Mid-level API分别是: Layers:用来构建网络结构 Datas ...
- TensorFlow学习——入门篇
本文主要通过一个简单的 Demo 介绍 TensorFlow 初级 API 的使用方法,因为自己也是初学者,因此本文的目的主要是引导刚接触 TensorFlow 或者 机器学习的同学,能够从第一步开始 ...
- tensorflow学习笔记二——建立一个简单的神经网络拟合二次函数
tensorflow学习笔记二--建立一个简单的神经网络 2016-09-23 16:04 2973人阅读 评论(2) 收藏 举报 分类: tensorflow(4) 目录(?)[+] 本笔记目的 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记--使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
最新文章
- Ubuntu 12.04 64bit或者CentOS 6.3 64bit上搭建OpenRTMFP/Cumulus服务器
- 极速开发之Spring Boot五种热部署方式
- 首次使用Windbg调试dNet程序
- php类型优先级_PHP: 运算符优先级 - Manual
- 感知器python代码
- html中的expand属性,expand的用法总结大全
- jira在linux下面的安装和配置
- CTF基础理论知识01
- CRM Extension field render and property handling
- RedHat 脚本搭建dns服务!
- 乐玩自动化测试模块_自动化测试模型(一)自动化测试模型介绍
- 适配器模式(Adapter模式)
- 关于AI的目标导向型行动计划
- 第五章 神经网络和误差逆传播法算法(BP)的推导
- 卖计算机英语对话,英语购买电脑情景对话.doc
- 寻租——乞丐没有白拿施舍
- 无线wifi摄像头怎样可以远程监控
- 详解用Java实现爬虫:HttpClient和Jsoup的介绍及使用(请求方式、请求参数、连接池、解析获取元素)
- IE无法上网,360浏览器部分网站无法打开
- 怎么安装aptdaemon模块_dlt-daemon安装教程