(一)目标检测经典模型回顾
转载自知乎:https://zhuanlan.zhihu.com/p/34142321
关于作者: @李家丞同济大学数学系本科在读,现为格灵深瞳算法部实习生。
-------------------------------------------------------------------------------------------------------
近年来,深度学习模型逐渐取代传统机器视觉方法而成为目标检测领域的主流算法,本系列文章将回顾早期的经典工作,并对较新的趋势做一个全景式的介绍,帮助读者对这一领域建立基本的认识。由于作者学历尚浅,水平有限,不实和不当之处也请指出和纠正,欢迎大家评论交流。
(一)目标检测经典模型回顾
(二)目标检测模型的评测与训练技巧
(三)目标检测新趋势之基础网络结构演进、分类定位的权衡
(四)目标检测新趋势之特征复用、实时性
(五)目标检测新趋势拾遗
-------------------------------------------------------------------------------------------------------
导言:目标检测的任务表述
如何从图像中解析出可供计算机理解的信息,是机器视觉的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。
那么,如何理解一张图片?根据后续任务的需要,有三个主要的层次。
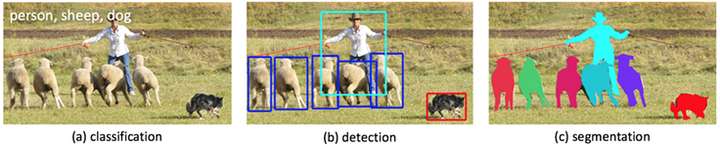 图像理解的三个层次
图像理解的三个层次
一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
本系列文章关注的领域是目标检测,即图像理解的中层次。
(一)目标检测经典工作回顾
本文结构
两阶段(2-stage)检测模型
两阶段模型因其对图片的两阶段处理得名,也称为基于区域(Region-based)的方法,我们选取R-CNN系列工作作为这一类型的代表。
R-CNN: R-CNN系列的开山之作
论文链接: Rich feature hierarchies for accurate object detection and semantic segmentation
本文的两大贡献:1)CNN可用于基于区域的定位和分割物体;2)监督训练样本数紧缺时,在额外的数据上预训练的模型经过fine-tuning可以取得很好的效果。第一个贡献影响了之后几乎所有2-stage方法,而第二个贡献中用分类任务(Imagenet)中训练好的模型作为基网络,在检测问题上fine-tuning的做法也在之后的工作中一直沿用。
传统的计算机视觉方法常用精心设计的手工特征(如SIFT, HOG)描述图像,而深度学习的方法则倡导习得特征,从图像分类任务的经验来看,CNN网络自动习得的特征取得的效果已经超出了手工设计的特征。本篇在局部区域应用卷积网络,以发挥卷积网络学习高质量特征的能力。
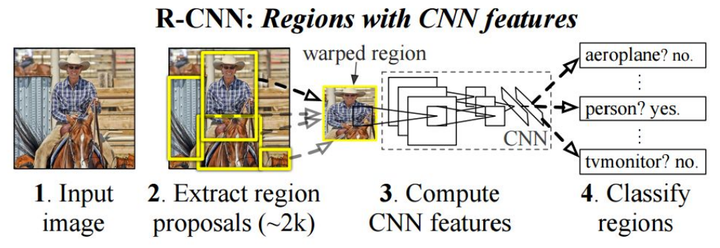 R-CNN网络结构
R-CNN网络结构
R-CNN将检测抽象为两个过程,一是基于图片提出若干可能包含物体的区域(即图片的局部裁剪,被称为Region Proposal),文中使用的是Selective Search算法;二是在提出的这些区域上运行当时表现最好的分类网络(AlexNet),得到每个区域内物体的类别。
另外,文章中的两个做法值得注意。
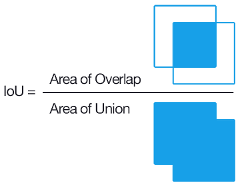 IoU的计算
IoU的计算
一是数据的准备。输入CNN前,我们需要根据Ground Truth对提出的Region Proposal进行标记,这里使用的指标是IoU(Intersection over Union,交并比)。IoU计算了两个区域之交的面积跟它们之并的比,描述了两个区域的重合程度。
文章中特别提到,IoU阈值的选择对结果影响显著,这里要谈两个threshold,一个用来识别正样本(如跟ground truth的IoU大于0.5),另一个用来标记负样本(即背景类,如IoU小于0.1),而介于两者之间的则为难例(Hard Negatives),若标为正类,则包含了过多的背景信息,反之又包含了要检测物体的特征,因而这些Proposal便被忽略掉。
另一点是位置坐标的回归(Bounding-Box Regression),这一过程是Region Proposal向Ground Truth调整,实现时加入了log/exp变换来使损失保持在合理的量级上,可以看做一种标准化(Normalization)操作。
小结
R-CNN的想法直接明了,即将检测任务转化为区域上的分类任务,是深度学习方法在检测任务上的试水。模型本身存在的问题也很多,如需要训练三个不同的模型(proposal, classification, regression)、重复计算过多导致的性能问题等。尽管如此,这篇论文的很多做法仍然广泛地影响着检测任务上的深度模型革命,后续的很多工作也都是针对改进这一工作而展开,此篇可以称得上"The First Paper"。
Fast R-CNN: 共享卷积运算
论文链接:Fast R-CNN
文章指出R-CNN耗时的原因是CNN是在每一个Proposal上单独进行的,没有共享计算,便提出将基础网络在图片整体上运行完毕后,再传入R-CNN子网络,共享了大部分计算,故有Fast之名。
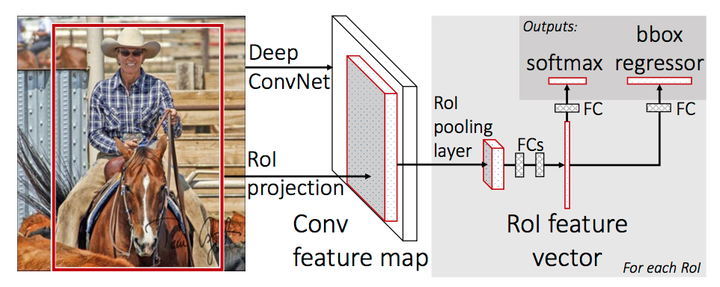 Fast R-CNN网络结构
Fast R-CNN网络结构
上图是Fast R-CNN的架构。图片经过feature extractor得到feature map, 同时在原图上运行Selective Search算法并将RoI(Region of Interset,实为坐标组,可与Region Proposal混用)映射到到feature map上,再对每个RoI进行RoI Pooling操作便得到等长的feature vector,将这些得到的feature vector进行正负样本的整理(保持一定的正负样本比例),分batch传入并行的R-CNN子网络,同时进行分类和回归,并将两者的损失统一起来。
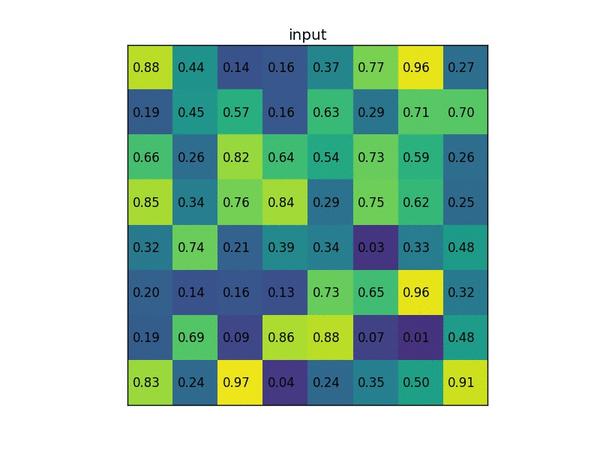
RoI Pooling图示,来源:https://blog.deepsense.ai/region-of-interest-pooling-explained/
RoI Pooling 是对输入R-CNN子网络的数据进行准备的关键操作。我们得到的区域常常有不同的大小,在映射到feature map上之后,会得到不同大小的特征张量。RoI Pooling先将RoI等分成目标个数的网格,再在每个网格上进行max pooling,就得到等长的RoI feature vector。
文章最后的讨论也有一定的借鉴意义:
- multi-loss traing相比单独训练classification确有提升
- multi-scale相比single-scale精度略有提升,但带来的时间开销更大。一定程度上说明CNN结构可以内在地学习尺度不变性
- 在更多的数据(VOC)上训练后,精度是有进一步提升的
- Softmax分类器比"one vs rest"型的SVM表现略好,引入了类间的竞争
- 更多的Proposal并不一定带来精度的提升
小结
Fast R-CNN的这一结构正是检测任务主流2-stage方法所采用的元结构的雏形。文章将Proposal, Feature Extractor, Object Classification&Localization统一在一个整体的结构中,并通过共享卷积计算提高特征利用效率,是最有贡献的地方。
Faster R-CNN: 两阶段模型的深度化
论文链接:Faster R-CNN: Towards Real Time Object Detection with Region Proposal Networks
Faster R-CNN是2-stage方法的奠基性工作,提出的RPN网络取代Selective Search算法使得检测任务可以由神经网络端到端地完成。粗略的讲,Faster R-CNN = RPN + Fast R-CNN,跟RCNN共享卷积计算的特性使得RPN引入的计算量很小,使得Faster R-CNN可以在单个GPU上以5fps的速度运行,而在精度方面达到SOTA(State of the Art,当前最佳)。
本文的主要贡献是提出Regional Proposal Networks,替代之前的SS算法。RPN网络将Proposal这一任务建模为二分类(是否为物体)的问题。
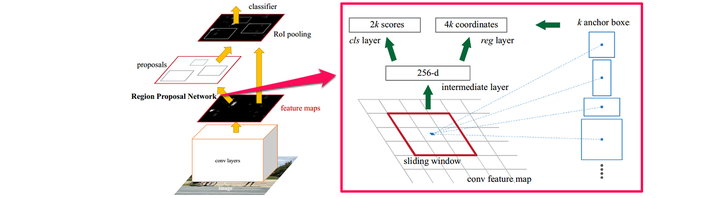 Faster R-CNN网络结构
Faster R-CNN网络结构
第一步是在一个滑动窗口上生成不同大小和长宽比例的anchor box(如上图右边部分),取定IoU的阈值,按Ground Truth标定这些anchor box的正负。于是,传入RPN网络的样本数据被整理为anchor box(坐标)和每个anchor box是否有物体(二分类标签)。RPN网络将每个样本映射为一个概率值和四个坐标值,概率值反应这个anchor box有物体的概率,四个坐标值用于回归定义物体的位置。最后将二分类和坐标回归的损失统一起来,作为RPN网络的目标训练。
由RPN得到Region Proposal在根据概率值筛选后经过类似的标记过程,被传入R-CNN子网络,进行多分类和坐标回归,同样用多任务损失将二者的损失联合。
小结
Faster R-CNN的成功之处在于用RPN网络完成了检测任务的"深度化"。使用滑动窗口生成anchor box的思想也在后来的工作中越来越多地被采用(YOLO v2等)。这项工作奠定了"RPN+RCNN"的两阶段方法元结构,影响了大部分后续工作。
单阶段(1-stage)检测模型
单阶段模型没有中间的区域检出过程,直接从图片获得预测结果,也被成为Region-free方法。
YOLO
论文链接:You Only Look Once: Unified, Real-Time Object Detection
YOLO是单阶段方法的开山之作。它将检测任务表述成一个统一的、端到端的回归问题,并且以只处理一次图片同时得到位置和分类而得名。
YOLO的主要优点:
- 快。
- 全局处理使得背景错误相对少,相比基于局部(区域)的方法, 如Fast RCNN。
- 泛化性能好,在艺术作品上做检测时,YOLO表现比Fast R-CNN好。
![]()
YOLO网络结构
YOLO的工作流程如下:
1.准备数据:将图片缩放,划分为等分的网格,每个网格按跟Ground Truth的IoU分配到所要预测的样本。
2.卷积网络:由GoogLeNet更改而来,每个网格对每个类别预测一个条件概率值,并在网格基础上生成B个box,每个box预测五个回归值,四个表征位置,第五个表征这个box含有物体(注意不是某一类物体)的概率和位置的准确程度(由IoU表示)。测试时,分数如下计算:
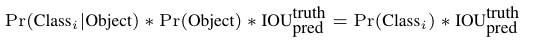
等式左边第一项由网格预测,后两项由每个box预测,以条件概率的方式得到每个box含有不同类别物体的分数。 因而,卷积网络共输出的预测值个数为S×S×(B×5+C),其中S为网格数,B为每个网格生成box个数,C为类别数。
3.后处理:使用NMS(Non-Maximum Suppression,非极大抑制)过滤得到最后的预测框
损失函数的设计
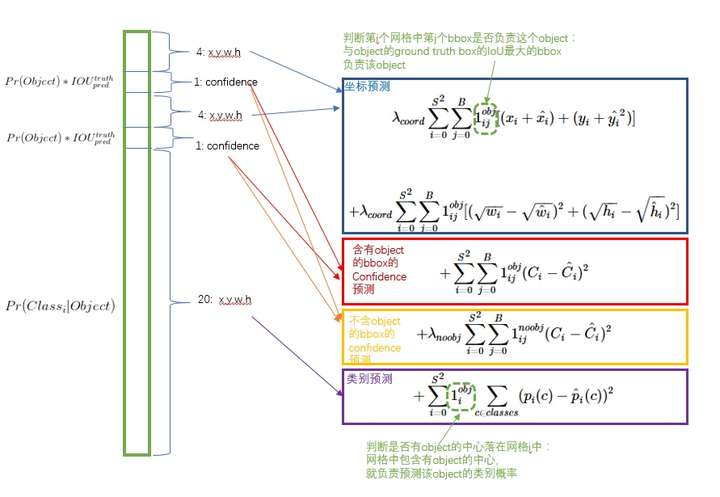 YOLO的损失函数分解,来源:https://zhuanlan.zhihu.com/p/24916786
YOLO的损失函数分解,来源:https://zhuanlan.zhihu.com/p/24916786
损失函数被分为三部分:坐标误差、物体误差、类别误差。为了平衡类别不均衡和大小物体等带来的影响,损失函数中添加了权重并将长宽取根号。
小结
YOLO提出了单阶段的新思路,相比两阶段方法,其速度优势明显,实时的特性令人印象深刻。但YOLO本身也存在一些问题,如划分网格较为粗糙,每个网格生成的box个数等限制了对小尺度物体和相近物体的检测。
SSD: Single Shot Multibox Detector
论文链接:SSD: Single Shot Multibox Detector
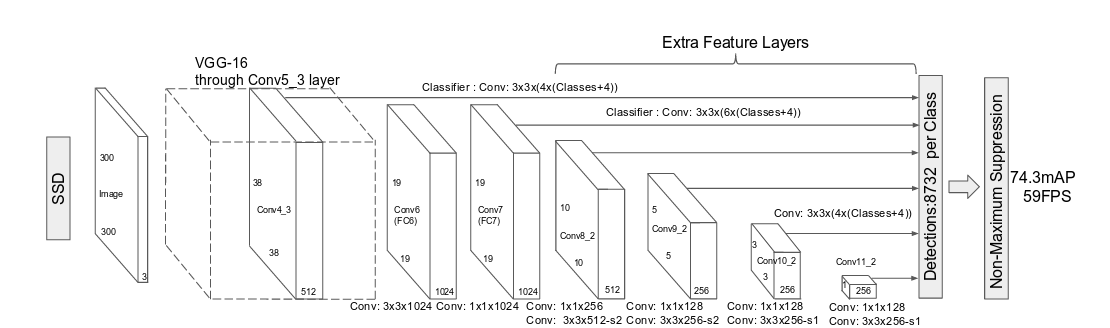 SSD网络结构
SSD网络结构
SSD相比YOLO有以下突出的特点:
- 多尺度的feature map:基于VGG的不同卷积段,输出feature map到回归器中。这一点试图提升小物体的检测精度。
- 更多的anchor box,每个网格点生成不同大小和长宽比例的box,并将类别预测概率基于box预测(YOLO是在网格上),得到的输出值个数为(C+4)×k×m×n,其中C为类别数,k为box个数,m×n为feature map的大小。
小结
SSD是单阶段模型早期的集大成者,达到跟接近两阶段模型精度的同时,拥有比两阶段模型快一个数量级的速度。后续的单阶段模型工作大多基于SSD改进展开。
检测模型基本特点
最后,我们对检测模型的基本特征做一个简单的归纳。
 两阶段检测模型Pipeline,来源:https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
两阶段检测模型Pipeline,来源:https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
检测模型整体上由基础网络(Backbone Network)和检测头部(Detection Head)构成。前者作为特征提取器,给出图像不同大小、不同抽象层次的表示;后者则依据这些表示和监督信息学习类别和位置关联。检测头部负责的类别预测和位置回归两个任务常常是并行进行的,构成多任务的损失进行联合训练。
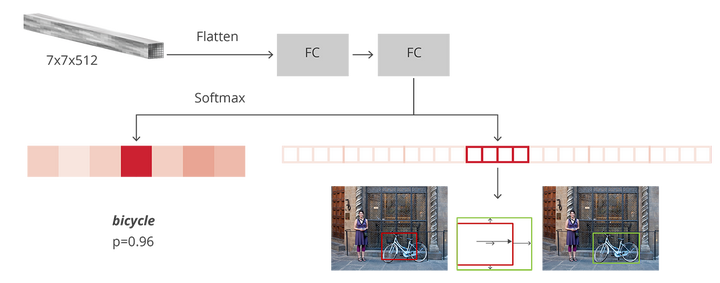 检测模型头部并行的分支,来源同上
检测模型头部并行的分支,来源同上
相比单阶段,两阶段检测模型通常含有一个串行的头部结构,即完成前背景分类和回归后,把中间结果作为RCNN头部的输入再进行一次多分类和位置回归。这种设计带来了一些优点:
- 对检测任务的解构,先进行前背景的分类,再进行物体的分类,这种解构使得监督信息在不同阶段对网络参数的学习进行指导
- RPN网络为RCNN网络提供良好的先验,并有机会整理样本的比例,减轻RCNN网络的学习负担
这种设计的缺点也很明显:中间结果常常带来空间开销,而串行的方式也使得推断速度无法跟单阶段相比;级联的位置回归则会导致RCNN部分的重复计算(如两个RoI有重叠)。
另一方面,单阶段模型只有一次类别预测和位置回归,卷积运算的共享程度更高,拥有更快的速度和更小的内存占用。读者将会在接下来的文章中看到,两种类型的模型也在互相吸收彼此的优点,这也使得两者的界限更为模糊。
在下一篇中,我们将介绍检测模型的评测指标与评测数据集,并总结常用的训练和建模技巧。
小补充:
• RCNN
RCNN(Regions with CNN features)是将CNN方法应用到目标检测问题上的一个里程碑,由年轻有为的RBG大神提出,借助CNN良好的特征提取和分类性能,通过RegionProposal方法实现目标检测问题的转化。
算法可以分为四步:
1)候选区域选择
Region Proposal是一类传统的区域提取方法,可以看作不同宽高的滑动窗口,通过窗口滑动获得潜在的目标图像,关于Proposal大家可以看下SelectiveSearch,一般Candidate选项为2k个即可,这里不再详述;
根据Proposal提取的目标图像进行归一化,作为CNN的标准输入。
2)CNN特征提取
标准CNN过程,根据输入进行卷积/池化等操作,得到固定维度的输出;
3)分类与边界回归
实际包含两个子步骤,一是对上一步的输出向量进行分类(需要根据特征训练分类器);二是通过边界回归(bounding-box regression) 得到精确的目标区域,由于实际目标会产生多个子区域,旨在对完成分类的前景目标进行精确的定位与合并,避免多个检出。
![]()
RCNN存在三个明显的问题:
1)多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
2)针对传统CNN需要固定尺寸的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
3)每一个ProposalRegion都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
• SPP-Net
智者善于提出疑问,既然CNN的特征提取过程如此耗时(大量的卷积计算),为什么要对每一个候选区域独立计算,而不是提取整体特征,仅在分类之前做一次Region截取呢?智者提出疑问后会立即付诸实践,于是SPP-Net诞生了。
![]()
SPP-Net在RCNN的基础上做了实质性的改进:
1)取消了crop/warp图像归一化过程,解决图像变形导致的信息丢失以及存储问题;
2)采用空间金字塔池化(SpatialPyramid Pooling )替换了 全连接层之前的最后一个池化层(上图top),翠平说这是一个新词,我们先认识一下它。
为了适应不同分辨率的特征图,定义一种可伸缩的池化层,不管输入分辨率是多大,都可以划分成m*n个部分。这是SPP-net的第一个显著特征,它的输入是conv5特征图 以及特征图候选框(原图候选框 通过stride映射得到),输出是固定尺寸(m*n)特征;
还有金字塔呢?通过多尺度增加所提取特征的鲁棒性,这并不关键,在后面的Fast-RCNN改进中该特征已经被舍弃;
最关键的是SPP的位置,它放在所有的卷积层之后,有效解决了卷积层的重复计算问题(测试速度提高了24~102倍),这是论文的核心贡献。
![]()
尽管SPP-Net贡献很大,仍然存在很多问题:
1)和RCNN一样,训练过程仍然是隔离的,提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数;
2)SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果;
3)在整个过程中,Proposal Region仍然很耗时。
• Fast-RCNN
问题很多,解决思路同样也非常巧妙,ok,再次感谢 RBG 大神的贡献,直接引用论文原图(描述十分详尽)。
Fast-RCNN主要贡献在于对RCNN进行加速,快是我们一直追求的目标(来个山寨版的奥运口号- 更快、更准、更鲁棒),问题在以下方面得到改进:
1)卖点1 - 借鉴SPP思路,提出简化版的ROI池化层(注意,没用金字塔),同时加入了候选框映射功能,使得网络能够反向传播,解决了SPP的整体网络训练问题;
2)卖点2 - 多任务Loss层
A)SoftmaxLoss代替了SVM,证明了softmax比SVM更好的效果;
B)SmoothL1Loss取代Bouding box回归。
将分类和边框回归进行合并(又一个开创性的思路),通过多任务Loss层进一步整合深度网络,统一了训练过程,从而提高了算法准确度。
3)全连接层通过SVD加速
这个大家可以自己看,有一定的提升但不是革命性的。
4)结合上面的改进,模型训练时可对所有层进行更新,除了速度提升外(训练速度是SPP的3倍,测试速度10倍),得到了更好的检测效果(VOC07数据集mAP为70,注:mAP,mean Average Precision)。
接下来分别展开这里面的两大卖点:
![]()
其中 为判别函数,为1时表示选中为最大值,0表示被丢弃,误差不需要回传,即对应 权值不需要更新。如下图所示,对于输入 xi 的扩展公式表示为:
![]()
(i,r,j) 表示 xi 在第 r 个框的第 j 个节点是否被选中为最大值(对应上图 y0,8 和 y1,0),xi 参数在前向传导时受后面梯度误差之和的影响。
![]()
多任务Loss层(全连接层)是第二个核心思路,如上图所示,其中cls_score用于判断分类,bbox_reg计算边框回归,label为训练样本标记。
其中Lcls为分类误差:
![]()
px 为对应Softmax分类概率,pl 即为label所对应概率(正确分类的概率),pl = 1时,计算结果Loss为0, 越小,Loss值越大(0.01对应Loss为2)。
即在正确分类的情况下,回归框与Label框之间的误差(Smooth L1), 对应描述边框的4个参数(上下左右or平移缩放),g对应单个参数的差异,|x|>1 时,变换为线性以降低离群噪声:
![]()
Ltotal为加权目标函数(背景不考虑回归Loss):
![]()
细心的小伙伴可能发现了,我们提到的SPP的第三个问题还没有解决,依然是耗时的候选框提取过程(忽略这个过程,Fast-RCNN几乎达到了实时),那么有没有简化的方法呢?
必须有,搞学术一定要有这种勇气。
• Faster-RCNN
对于提取候选框最常用的SelectiveSearch方法,提取一副图像大概需要2s的时间,改进的EdgeBoxes算法将效率提高到了0.2s,但是这还不够。
候选框提取不一定要在原图上做,特征图上同样可以,低分辨率特征图意味着更少的计算量,基于这个假设,MSRA的任少卿等人提出RPN(RegionProposal Network),完美解决了这个问题,我们先来看一下网络拓扑。
![]()
通过添加额外的RPN分支网络,将候选框提取合并到深度网络中,这正是Faster-RCNN里程碑式的贡献。
RPN网络的特点在于通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),提取对应9个候选窗口(anchor)的特征,用于目标分类和边框回归,与FastRCNN类似。
目标分类只需要区分候选框内特征为前景或者背景。
边框回归确定更精确的目标位置,基本网络结构如下图所示:
![]()
训练过程中,涉及到的候选框选取,选取依据:
1)丢弃跨越边界的anchor;
2)与样本重叠区域大于0.7的anchor标记为前景,重叠区域小于0.3的标定为背景;
对于每一个位置,通过两个全连接层(目标分类+边框回归)对每个候选框(anchor)进行判断,并且结合概率值进行舍弃(仅保留约300个anchor),没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
从模型训练的角度来看,通过使用共享特征交替训练的方式,达到接近实时的性能,交替训练方式描述为:
1)根据现有网络初始化权值w,训练RPN;
2)用RPN提取训练集上的候选区域,用候选区域训练FastRCNN,更新权值w;
3)重复1、2,直到收敛。
因为Faster-RCNN,这种基于CNN的real-time 的目标检测方法看到了希望,在这个方向上有了进一步的研究思路。至此,我们来看一下RCNN网络的演进,如下图所示:
Faster RCNN的网络结构(基于VGG16):
![]()
Faster实现了端到端的检测,并且几乎达到了效果上的最优,速度方向的改进仍有余地,于是YOLO诞生了。
- R-FCN
原文:https://arxiv.org/abs/1605.06409v2
参考:http://www.jianshu.com/p/db1b74770e52
图 8
R-FCN的总体框架如图 8 所示:
① 原图输入卷积层提取特征,输出特征图feature maps
② feature maps 输入RPN网络提取候选框ROIs
③ 将ROIs映射到feature maps上
④ 再经过一个ROI Pooling Layer进行池化
⑤ 最后对其进行vote,即分类,确定其类别
细节:
图 9
1)如图 9 所示,我们来看一下红框中左边卷积到右边的过程:
feature maps 再经过一个卷积层,这个卷积层有k^2*(C+1)个卷积核,即输出k^2*(C+1)新的特征图,我们称之为position-sensitive score maps(位置敏感的得分图)。对于这些score maps,k一般默认取3,C表示类别数,C+1表示类别数加上背景。
举个例子,我们假设k=3,C=6,那么最后生成的score maps有3*3*(6+1)=63张,对于每一类有9张,即上图中红框右边对应的九种颜色代表k*k=9,每种颜色的厚度表示类别数为(C+1)=7类,总的厚度即为所有score maps的数量k^2*(C+1)=63张。
图 10
2)如图 10 所示,我们看一下对score maps进行池化的过程:
还是以上文为例,7个类别(6个物体类 + 1个背景类),有63张score maps,每一类为9张,这个9就对应上图红框左边的9种颜色。我们知道,之前通过RPN提取到了ROIs并将其映射到了score maps上,而这里的池化则只是针对于ROI进行的。我们同样将ROI平均分成k*k=3*3=9份,每一份我们称之为bin,如上图左边的九宫格所示,每一次池化操作只对一个bin进行。
比如说对于橙色的score maps,只关注ROI部分,我们只对其ROI的左上角那个bin进行平均池化,输出为上图红框右边对应的橙色格子
接着对黄色ROI的上面中间那个bin进行平均池化,输出为右边黄色的格子
然后对浅黄色ROI的右上角那个bin进行平均池化,输出为右边浅黄色的格子
之后对绿色ROI的左侧中间那个bin进行平均池化,输出为右边绿色的格子
以此类推………………
最终我们可以得到如图 10 红框右边所示的k*k=3*3=9种颜色的九宫格,他的厚度为(C+1),表示有C+1种类别。
这里只对ROI的某个bin进行池化,目的是为了记录位置信息
图 11
3)如图 11 所示,我们最后看一下对池化层的输出进行vote(投票)的过程:
对于池化层输出的特征图,它有(C+1)张,即(C+1)种类别,我们取其中一个类别c1为例,单独看它那张表示为九宫格的特征图,对它的9个bins分别进行vote(投票),最后取平均,得到对于c1这个类别的评分。以此类推,可以得到其他类别的相应评分,最终将所有这(C+1)个评分表示成向量的形式输入softmax函数,得到对应于原图中这个ROI的类别判定。
• YOLO
YOLO来自于“YouOnly Look Once”,你只需要看一次,不需要类似RPN的候选框提取,直接进行整图回归就可以了,简单吧?
![]()
算法描述为:
1)将图像划分为固定的网格(比如7*7),如果某个样本Object中心落在对应网格,该网格负责这个Object位置的回归;
2)每个网格预测包含Object位置与置信度信息,这些信息编码为一个向量;
3)网络输出层即为每个Grid的对应结果,由此实现端到端的训练。
YOLO算法的问题有以下几点:
1)7*7的网格回归特征丢失比较严重,缺乏多尺度回归依据;
2)Loss计算方式无法有效平衡(不管是加权或者均差),Loss收敛变差,导致模型不稳定。
Object(目标分类+回归)<=等价于=>背景(目标分类)
导致Loss对目标分类+回归的影响,与背景影响一致,部分残差无法有效回传;
整体上YOLO方法定位不够精确,贡献在于提出给目标检测一个新的思路,让我们看到了目标检测在实际应用中真正的可能性。
• SSD
由于YOLO本身采用的SingleShot基于最后一个卷积层实现,对目标定位有一定偏差,也容易造成小目标的漏检。
借鉴Faster-RCNN的Anchor机制,SSD(Single Shot MultiBox Detector)在一定程度上解决了这个问题,我们先来看下SSD的结构对比图。
基于多尺度特征的Proposal,SSD达到了效率与效果的平衡,从运算速度上来看,能达到接近实时的表现,从效果上看,要比YOLO更好。
-----------------------------------------------------------------------------------------------------------*-*----
更多详细内容请关注公众号:目标检测和深度学习
![]()
---------------------------------------------------------------------------------------------------------------…^-^……---------
(一)目标检测经典模型回顾相关推荐
- 大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
目标检测是深度学习的一个重要应用,就是在图片中要将里面的物体识别出来,并标出物体的位置,一般需要经过两个步骤: 1.分类,识别物体是什么 2.定位,找出物体在哪里 除了对单个物体进行检测,还要 ...
- 《基于海思35xx nnie引擎进行经典目标检测算法模型推理》视频课程介绍
前言 沉寂两个月,终于将新的视频课程<<基于海思35xx nnie引擎进行经典目标检测算法模型推理>>(其链接为https://edu.csdn.net/course/deta ...
- 【R-CNN论文翻译】目标检测经典论文R-CNN最新版本(v5版)全面中文翻译
R-CNN目标检测的奠基性文章,学习目标检测必看的经典论文之一,后续有Fast R-CNN,Faster R-CNN一系列论文. 目前网上能找到的论文翻译版本要么不全,要么不是最新版本的(论文从201 ...
- CVPR 2021 | 视觉目标检测大模型GAIA:面向行业的视觉物体检测一站式解决方案
作者丨常清 编辑丨机器之心 中国科学院自动化研究所智能感知与计算研究中心联合华为等企业提出面向行业的视觉物体检测一站式解决方案 GAIA. 在深度学习与大数据的浪潮下,视觉目标检测在各个基准数据集上已 ...
- 中科院自动化所与华为联合提出!视觉目标检测大模型GAIA
点上方计算机视觉联盟获取更多干货 仅作学术分享,不代表本公众号立场,侵权联系删除 转载于:机器之心 AI博士笔记系列推荐 周志华<机器学习>手推笔记正式开源!可打印版本附pdf下载链接 中 ...
- 目标检测经典论文——Fast R-CNN论文翻译(中英文对照版):Fast R-CNN(Ross Girshick, Microsoft Research(微软研究院))
目标检测经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为纯中文版,中英文对照版请稳步:[Fast R-CNN纯中文版] Fast R-CNN Ross Girshick Mic ...
- 目标检测经典算法和API详解(笔记)
文章目录 商品目标检测 1. 目标检测概述 1.1.项目演示介绍 学习目标 1.1.1 项目演示 1.1.2 项目结构 1.1.3 项目安排 1.2 图像识别背景 学习目标 1.2.1 图像识别三大任 ...
- 目标检测经典论文——YOLOv2论文翻译(纯中文版):YOLO9000:更好、更快、更强
目标检测经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为纯中文版,中英文对照版请稳步:[YOLOv2中英文对照版] YOLO9000:更好.更快.更强 Joseph Redmo ...
- 目标检测经典论文——Faster R-CNN论文翻译(纯中文版):Faster R-CNN:通过Region Proposal网络实现实时目标检测
目标检测经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为纯中文版,中英文对照版请稳步:[Faster R-CNN中英文对照版] Faster R-CNN:通过Region Pr ...
- 目标检测经典论文——Fast R-CNN论文翻译(纯中文版):Fast R-CNN(微软研究院)
目标检测经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为纯中文版,中英文对照版请稳步:[Fast R-CNN中英文对照版] Fast R-CNN Ross Girshick 微 ...
最新文章
- HashMap根据value值排序
- Spring系列(五):@Lazy懒加载注解用法介绍
- decimal类型对象里面定义什么类型_奥斯塔罗 单身开启桃花雷达 现阶段的我适合什么类型的对象?...
- 2019汇总之从4个关键词看单细胞与肝癌文献
- CMake使用介绍(2)
- 零点起飞学php下载,零点起飞学PHP(附光盘)/零点起飞学编程
- Linux svn服务器搭建
- QQ文件上传不了:什么年代了,还使用简单的关键词过滤,智能一点可好
- 最新声鉴卡H5网页源码_完整可运转,引流专用神器
- Informix数据库查询表的锁级别
- 自然语言处理入门理论知识
- cobaltstrike (cs 使用)初使用
- vscode超炫敲击特效嘎嘎帅!!!
- php 数组 批量替换字符串,php数组替换字符串
- 一次zookeeper启动失败的解决过程
- 用bat执行ps1脚本
- 蓝桥杯2014省赛——等额本金(Java)
- 根据密码子生成蛋白质序列(根据字典破译密码)
- 再次阅读乔布斯的讲演—“好学若饥、谦卑若愚”
- python~计算公式的值