暹罗网络目标跟踪_暹罗网络的友好介绍
暹罗网络目标跟踪
In the modern Deep learning era, Neural networks are almost good at every task, but these neural networks rely on more data to perform well. But, for certain problems like face recognition and signature verification, we can’t always rely on getting more data, to solve this kind of tasks we have a new type of neural network architecture called Siamese Networks.
在现代深度学习时代,神经网络几乎可以胜任每项任务,但是这些神经网络需要更多的数据才能表现良好。 但是,对于诸如人脸识别和签名验证之类的某些问题,我们不能总是依靠获取更多数据来解决这类任务,我们拥有一种新型的神经网络架构,称为暹罗网络。
It uses only a few numbers of images to get better predictions. The ability to learn from very little data made Siamese networks more popular in recent years. In this article, we will explore what it is and how to develop a signature verification system with Pytorch using Siamese Networks.
它仅使用少量图像来获得更好的预测。 从很少的数据中学习的能力使得暹罗网络近年来变得越来越流行。 在本文中,我们将探讨它是什么以及如何使用Pytorch使用Siamese Networks开发签名验证系统。
什么是连体网络!? (What are Siamese Networks!?)
A Siamese Neural Network is a class of neural network architectures that contain two or more identical subnetworks. ‘identical’ here means, they have the same configuration with the same parameters and weights. Parameter updating is mirrored across both sub-networks. It is used to find the similarity of the inputs by comparing its feature vectors, so these networks are used in many applications
暹罗神经网络是一类神经网络体系结构,其中包含两个或多个相同的子网络 。 “ 相同”在这里是指它们具有相同的配置和相同的参数和权重。 参数更新反映在两个子网中。 它用于通过比较其特征向量来查找输入的相似性,因此这些网络被用于许多应用中
Traditionally, a neural network learns to predict multiple classes. This poses a problem when we need to add/remove new classes to the data. In this case, we have to update the neural network and retrain it on the whole dataset. Also, deep neural networks need a large volume of data to train on. SNNs, on the other hand, learn a similarity function. Thus, we can train it to see if the two images are the same (which we will do here). This enables us to classify new classes of data without training the network again.
传统上,神经网络会学习预测多个类别。 当我们需要向数据添加/删除新类时,这会带来问题。 在这种情况下,我们必须更新神经网络并在整个数据集中对其进行重新训练。 而且,深度神经网络需要大量的数据进行训练。 另一方面,SNN学习相似性函数。 因此,我们可以训练它以查看两个图像是否相同(我们将在此处执行)。 这使我们能够分类新的数据类别,而无需再次训练网络。
暹罗网络的优缺点: (Pros and Cons of Siamese Networks:)
The main advantages of Siamese Networks are,
暹罗网络的主要优势是:
More Robust to class Imbalance: With the aid of One-shot learning, given a few images per class is sufficient for Siamese Networks to recognize those images in the future
更加稳健的班级失衡:借助单次学习,每个班级只有几张图像就足以让暹罗网络将来识别这些图像
Nice to an ensemble with the best classifier: Given that its learning mechanism is somewhat different from Classification, simple averaging of it with a Classifier can do much better than average 2 correlated Supervised models (e.g. GBM & RF classifier)
很高兴与拥有最佳分类器的合奏:鉴于其学习机制与分类有所不同,因此使用分类器对它进行简单平均可以比平均2个相关监督模型(例如GBM和RF分类器)做得更好
Learning from Semantic Similarity: Siamese focuses on learning embeddings (in the deeper layer) that place the same classes/concepts close together. Hence, can learn semantic similarity.
从语义相似性中学习:暹罗语专注于学习嵌入(在更深的层次中),这些嵌入将相同的类/概念放在一起。 因此,可以学习语义相似性 。
The downsides of the Siamese Networks can be,
暹罗网络的缺点可能是,
Needs more training time than normal networks: Since Siamese Networks involves quadratic pairs to learn from (to see all information available) it is slower than normal classification type of learning(pointwise learning)
比普通网络需要更多的培训时间:由于暹罗网络涉及二次学习(以查看所有可用信息),因此比正常分类学习(逐点学习)慢
Doesn’t output probabilities: Since training involves pairwise learning, it won’t output the probabilities of the prediction, but the distance from each class
不输出概率:由于训练涉及成对学习,因此它不会输出预测的概率,但会输出每个类的距离
暹罗网络中使用的损耗函数: (Loss functions used in Siamese Networks:)
Since training of Siamese networks involves pairwise learning usual, Cross entropy loss cannot be used in this case, mainly two loss functions are mainly used in training these Siamese networks, they are
由于暹罗网络的训练通常涉及成对学习,因此在这种情况下不能使用交叉熵损失,主要是在训练这些暹罗网络时主要使用两个损失函数,它们是
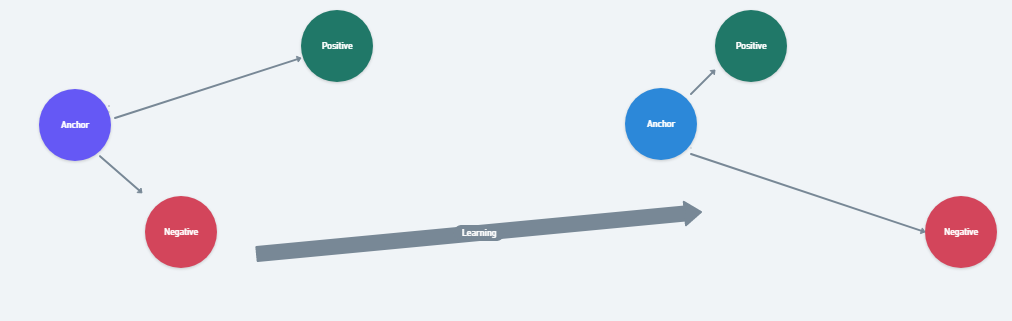
Triplet loss is a loss function where a baseline (anchor) input is compared to a positive (truthy) input and a negative (falsy) input. The distance from the baseline (anchor) input to the positive (truthy) input is minimized, and the distance from the baseline (anchor) input to the negative (falsy) input is maximized.
三重损失是一种损失函数,其中将基线(锚定)输入与正(真实)输入和负(虚假)输入进行比较。 从基线(锚)输入到正(真实)输入的距离最小,并且从基线(锚)输入到负(虚假)输入的距离最大。
In the above equation, alpha is a margin term used to “stretch” the distance differences between similar and dissimilar pairs in the triplet, fa, fa, fn are the feature embeddings for the anchor, positive and negative images.
在上述公式中,alpha是用于“拉伸”三元组中相似和不相似对之间的距离差异的余量项,fa,fa,fn是锚点,正像和负像的特征嵌入。
During the training process, an image triplet (anchor image, negative image, positive image)(anchor image, negative image, positive image) is fed into the model as a single sample. The idea behind this is that distance between the anchor and positive images should be smaller than that between the anchor and negative images.
在训练过程中,将三元组图像(锚图像,负图像,正图像)(锚图像,负图像,正图像)作为单个样本输入到模型中。 这背后的想法是锚点和正像之间的距离应小于锚点和负像之间的距离。
Contrastive Loss: is a popular loss function used highly nowadays, It is a distance-based loss as opposed to more conventional error-prediction losses. This loss is used to learn embeddings in which two similar points have a low Euclidean distance and two dissimilar points have a large Euclidean distance.
对比损失 :是当今流行的损失函数,它是基于距离的损失 ,而不是传统的误差预测损失 。 该损失用于学习其中两个相似点的欧氏距离较小而两个不相似点的欧氏距离较大的嵌入。
And we defined Dw which is just the Euclidean distance as :
我们将Dw等于欧几里德距离定义为:
Gw is the output of our network for one image.
Gw是我们的网络针对一幅图像的输出。
使用暹罗网络进行签名验证: (Signature verification with Siamese Networks:)

As Siamese networks are mostly used in verification systems such as face recognition, signature verification, etc…, Let’s implement a signature verification system using Siamese neural networks on Pytorch
由于暹罗网络主要用于面部识别,签名验证等验证系统中,因此让我们在Pytorch上使用暹罗神经网络来实现签名验证系统
数据集和预处理数据集: (Dataset and Preprocessing the Dataset:)
We are going to use the ICDAR 2011 dataset which consists of the signatures of the dutch users both genuine and fraud, and the dataset itself is separated as train and folders, inside each folder, it consists of users folder separated as genuine and forgery, also the labels of the dataset is available as CSV files, you can download the dataset from here
我们将使用ICDAR 2011数据集,该数据集由荷兰用户的真实签名和欺诈签名组成,数据集本身分为火车和文件夹,在每个文件夹内,它由分别由真实和伪造的用户文件夹组成,数据集的标签以CSV文件形式提供,您可以从此处下载数据集
Now to fed this raw data into our neural network, we have to turn all the images into tensors and add the labels from the CSV files to the images, to do this we can use the custom dataset class from Pytorch, here is how our full code will look like
现在要将这些原始数据输入到我们的神经网络中,我们必须将所有图像转换为张量,然后将CSV文件中的标签添加到图像中,为此,我们可以使用Pytorch中的自定义数据集类,以下是完整的代码看起来像
Now after preprocessing the dataset, in PyTorch we have to load the dataset using Dataloader class, we will use the transforms function to reduce the image size into 105 pixels of height and width for computational purposes
现在,在对数据集进行预处理之后,在PyTorch中,我们必须使用Dataloader类加载数据集,我们将使用transforms函数将图像大小缩小为高度和宽度的105个像素,以进行计算
神经网络架构: (Neural Network Architecture:)
Now let’s create a neural network in Pytorch, we will use the neural network architecture which will be similar, as described in the Signet paper
现在让我们在Pytorch中创建一个神经网络,我们将使用类似于Signet论文所述的神经网络架构。
In the above code, we have created our network as follows, The first convolutional layers filter the 105*105 input signature image with 96 kernels of size 11 with a stride of 1 pixel. The second convolutional layer takes as input the(response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5. The third and fourth convolutional layers are connected to one another without any intervention of pooling or normalization of layers. The third layer has 384 kernels of size 3 connected to the (normalized, pooled, and dropout) output of the second convolutional layer. The fourth convolutional layer has 256 kernels of size 3 This leads to the neural network learning fewer lower level features for smaller receptive fields and more features for higher-level or more abstract features. The first fully connected layer has 1024 neurons, whereas the second fully connected layer has 128 neurons. This indicates that the highest learned feature vector from each side of SigNet has a dimension equal to 128, so where is the other network?
在上面的代码中,我们按如下方式创建了我们的网络:第一个卷积层使用96个大小为11的内核(跨度为1个像素)过滤105 * 105输入签名图像。 第二个卷积层将第一个卷积层的(响应归一化和池化)输出作为输入,并使用256个大小为5的内核对其进行过滤。第三和第四个卷积层彼此连接,而无需任何池化或归一化干预层。 第三层具有384个大小为3的内核,这些内核连接到第二个卷积层的(标准化,合并和丢失)输出。 第四卷积层具有大小为3的256个内核。这导致神经网络针对较小的接收场学习较少的较低层特征,而对于较高层或更多抽象特征学习更多特征。 第一完全连接层具有1024个神经元,而第二完全连接层具有128个神经元。 这表明从SigNet的每个侧面学习的最高特征向量的维数等于128,那么另一个网络在哪里?
Since the weights are constrained to be identical for both networks, we use one model and feed it two images in succession. After that, we calculate the loss value using both the images and then backpropagate. This saves a lot of memory and also computational efficiency.
由于两个网络的权重均被限制为相同,因此我们使用一个模型,并连续为其提供两个图像。 之后,我们同时使用图像和反向传播来计算损耗值。 这样可以节省大量内存并节省计算效率。
损失函数: (Loss Function:)
For this task, we will use Contrastive Loss, which learns embeddings in which two similar points have a low Euclidean distance and two dissimilar points have a large Euclidean distance, In Pytorch the implementation of Contrastive Loss will be as follows,
对于此任务,我们将使用“对比损失”,它学习了两个相似点的欧几里得距离较小而两个不同点的欧几里德距离较大的嵌入,在Pytorch中,对比损失的实现如下:
培训网络: (Training the Network:)
The training process of a Siamese network is as follows:
暹罗语网络的培训过程如下:
- Initialize the network, loss function, and Optimizer(we will be using Adam for this project)
初始化网络,损失函数和优化器(我们将在项目中使用Adam) - Pass the first image of the image pair through the network.
将图像对的第一张图像通过网络。 - Pass the second image of the image pair through the network.
将图像对的第二个图像通过网络。 - Calculate the loss using the outputs from the first and second images.
使用第一张图片和第二张图片的输出计算损耗。 - Back propagate the loss to calculate the gradients of our model.
反向传播损失以计算模型的梯度。 - Update the weights using an optimizer
使用优化器更新权重 - Save the model
保存模型
The model was trained for 20 epochs on google colab for an hour, the graph of the loss over time is shown below.
该模型在Google colab上训练了20个小时,历时一个小时,其损失随时间变化的图表如下所示。

测试模型: (Testing the model:)
Now let’s test our signature verification system on the test dataset,
现在让我们在测试数据集上测试我们的签名验证系统,
- Load the test dataset using DataLoader class from Pytorch
使用来自Pytorch的DataLoader类加载测试数据集 - Pass the image pairs and the labels
传递图像对和标签 - Find the euclidean distance between the images
找出图像之间的欧式距离 - Based on the euclidean distance print the output
基于欧氏距离打印输出
The predictions were as follows,
预测如下
结论: (Conclusion:)
In this article, we discussed how Siamese networks are different from normal deep learning networks and implemented a Signature verification system using Siamese networks, you can find the entire code here
在本文中,我们讨论了暹罗网络与普通深度学习网络的区别,并使用暹罗网络实现了签名验证系统,您可以在此处找到完整的代码
翻译自: https://towardsdatascience.com/a-friendly-introduction-to-siamese-networks-85ab17522942
暹罗网络目标跟踪
相关文章:
- Iphone/Android开发囧事
- 囧——线性规划与网络流24题之网络流入门经典
- 2008网络盛典年度网络流行语候选:囧(jiǒng)
- 囧事百科
- 面试囧事
- 囧
- 百度百科里头的“和谐”
- access中本年度的四月一日_有朝一日重逢,定会深深地相拥 |为你读诗
- “万物皆可卷”的今天,名校学生开了一门“内卷课”
- 2016-12-07 体力王哈鲁与自行车
- 开启春光撼路者的深夜博客
- 千里走单骑:09-北京到上海骑记--Day8.艰难连云港
- 如何打开Office 2007文档
- 支持html文件格式的网盘,Word文档支持哪些文件格式?
- Microsoft Office Word、Excel 和 PowerPoint 2007 文件格式兼容包
- Office Excel 文件格式保存--兼容模式
- Microsoft Office Open XML 格式和文件扩展名
- Microsoft Office Word、Excel 和 PowerPoint 2007 文件格式兼容包(简体中文)
- Office 2003打开Office 2007文件格式的兼容软件包
- 成年人的标志:把反馈当作礼物
- 程序员的自我救赎,使用python开发性格分析工具
- HR专家训练营-X版本 成为HR专家系列(X版本)
- 《做工作中最受欢迎的人》读书笔记1
- [性格][管理]《九型人格》 -- 唐·理查德·里索(美)、拉斯·赫德森(美)
- 【干货】九型人格与自我修炼!你是哪种性格?更适合什么工作?
- 【深度学习】特征值分解与特征向量
- 记一次Tomcat服务部署,启动过滤器异常,问题查找过程
- opencv_contrib扩展模块的安装(CMake编译器)及解决文件下载失败的问题(超详细)
- Django项目开发案例教程【可在此基础上进行开发】
- C语言:字符函数与字符串函数(一)
暹罗网络目标跟踪_暹罗网络的友好介绍相关推荐
- 神经网络 目标跟踪_图神经网络的多目标跟踪
神经网络 目标跟踪 Multiple object tracking(MOT) is the task of studying object appearance and movements to a ...
- python目标跟踪_商汤开源最大目标跟踪库PySOT,代码已正式上线!
前几天 CVer推送一篇:重磅!商汤开源最大目标跟踪库PySOT:含SiamRPN++和SiamMask等算法,介绍了来自商汤科技的STVIR(SenseTime Video Intelligence ...
- SA-Siam:用于实时目标跟踪的双重连体网络A Twofold Siamese Network for Real-Time Object Tracking
原文链接 摘要: 1.本文核心一:将图像分类任务中的语义特征(Semantic features)与相似度匹配任务中的外观特征(Appearance features)互补结合,非常适合与目标跟踪任务 ...
- Siamese-fc孪生网络目标跟踪
全名:Fully-Convolutional Siamese Networks for Object Tracking 论文摘自ECCV Workshop 2016,由Luca Bertinetto. ...
- 目标跟踪之光流法---光流法简单介绍
光流的概念是Gibson在1950年首先提出来的.它是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系 ...
- 贝叶斯网络python代码_贝叶斯网络,看完这篇我终于理解了(附代码)!
1. 对概率图模型的理解 概率图模型是用图来表示变量概率依赖关系的理论,结合概率论与图论的知识,利用图来表示与模型有关的变量的联合概率分布.由图灵奖获得者Pearl开发出来. 如果用一个词来形容概率图 ...
- 生成对抗网络gan原理_生成对抗网络(GAN)的半监督学习
前言 如果您曾经听说过或研究过深度学习,那么您可能就知道MNIST, SVHN, ImageNet, PascalVoc或者其他数据集.这些数据集都有一个共同点: 它们由成千上万个有标签的数据组成. ...
- python网络编程内容_图解Python网络编程
Python Python开发 Python语言 图解Python网络编程 本篇索引 (1)基本原理 本篇指的网络编程,仅仅是指如何在两台或多台计算机之间,通过网络收发数据包:而不涉及具体的应用层功能 ...
- 网络协议分层_接口测试之网络分层和数据
网络分层和数据 上一小节中介绍了接口测试中一些必要重要的定义,这一节我们来讨论一下在学习接口测试过程中我们要关注的最重要的东西:网络分层和数据. 首先,我们来尝试理解一下,为什么网络是要分层的呢? 我 ...
最新文章
- 随机森林算法4种实现方法对比测试:DolphinDB速度最快,XGBoost表现最差
- 【重要】如何彻底夯实CV基础,有三AI三大导师一起带你学习!
- CUDA从入门到精通(零):写在前面
- 浅尝boost之timer
- Androidの多线程之更新ui(Thread+Handler+Message)
- vue中class绑定函数
- C语言getchar函数
- UltraEdit汇编语言高亮
- 百度网盘,莫名其妙把文件删除了
- 机器学习笔记(二十九):决策树、信息熵
- ARM开发6.3.1 基础实训( 1 ) 单个数码 LED 的显示输出系统设计( 1)--LPC21XX
- 计算机学科a类排名,哈工大17个学科排名位列A类
- VUCA时代,3招让项目计划管理更科学有序!
- 爬虫入门到放弃系列07:js混淆、eval加密、字体加密三大反爬技术
- 青龙面板-美团外卖天天神卷
- Gpsd pps移植
- linux的超级酷工具之Emacs
- PS流详解(载荷H264)
- 实现鼠标移入移出显示隐藏元素
- 什么是数据标准,如何做好数据标准管理?