微调︱caffe中fine-tuning模型三重天(函数详解、框架简述)+微调技巧
本文主要参考caffe官方文档[《Fine-tuning a Pretrained Network for Style Recognition》](http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/02-fine-tuning.ipynb)
是第二篇案例。笔者对其进行了为期一周的断断续续的研究,笔者起先对python/caffe并不了解+英语不好,阅读+理解的时间有点长,前前后后过了不下十遍终于从这第二篇文档看出些端倪来了。本系列主要是以python编译实现为主,不涉及caffe命令行训练。
本系列纯粹笔者自己领悟,如有问题,非常,非常欢迎看客指出,感激~
.
.
一、fine-tuning模型的三种状态
从阅读《Fine-tuning a Pretrained Network for Style Recognition》这篇文章来看,主要把fine-tuning的三种状态都简述了一遍,该教程可谓足够良心:
- 状态一:只预测,不训练。
相对快、简单,针对那些已经训练好,现在要实际对未知数据进行标注的项目,其中用DummyData来做模具,非常高效;
- 状态二:训练,但只训练最后分类层。
针对一类,fine-tuning的模型最终的分类以及符合要求,现在只是在他们的基础上进行类别降维。
- 状态三:完全训练,分类层+之前卷积层都训练
跟状态二的差异很小,当然状态三比较耗时+需要训练GPU资源,不过非常适合fine-tuning到自己想要的模型里面,预测精度相比状态二也提高不少。
一般来看,在分类任务里面,imagenet的一系列模型或者更好的google inception V3模型,他们已经分别有900W、6000W的数量和1000、6000分类,足够应付很多识别任务的时候,可以采取状态二、三的训练模式。fine-tuning好了之后就可以采用状态一,只进行相对应的预测。
一些成品框架整理:
imagenet的一系列模型:https://github.com/BVLC/caffe/tree/master/models google
inception V3模型caffe代码(未训练):Google Inception V3 for
Caffe
google inception V3数据:https://github.com/openimages/dataset# google
inception
V3&V4框架叙述:GoogleNet的Inception_v1、Inception_v2、Inception_v3、Inception_v4(整理)
.
.
二、函数介绍
《Fine-tuning a Pretrained Network for Style Recognition》在本篇官方文档中,主要应用的是caffeNet这一套框架。
1、caffe训练文件种类
caffe在训练时候会有以下几类训练必须文件:
- deploy.prototxt:框架文件,用在预测+训练场景,caffenet函数生成
- solver.prototxt:参数文件,用在训练场景,solver函数生成
- train_val.prototxt:数据集文件,用在训练场景
- x.caffemodel:模型权值参数文件
以上的一些函数,会在后续应用中由下面的函数生成。
.
2、函数介绍一:caffenet函数
caffenet函数主要作用就是返回、制造caffeNet框架训练时候所需的框架文件:deploy.prototxt
输入:数据、标签、层名、学习率设置
输出:deploy文件
caffenet(data, label=None, train=True, num_classes=1000,classifier_name='fc8', learn_all=False)# data代表训练数据# label代表新数据标签,跟num_classes类似,跟给出数据的标签数量一致,譬如新数据的标签有5类,那么就是5# train,是否开始训练,默认为true# num_classes代表fine-tuning来得模型的标签数,如果fine-tuning是ImageNet是千分类,那么num_classes=1000# classifier_name,最后的全连接层名字,如果是fine-tuning需要重新训练的话,则需要修改最后的全连接层# learn_all,这个变量用于将学习率设置为0,在caffenet中,如果learn_all=False,则使用frozen_param设置网络层的学习率,即学习率为0 其中label和num_classes比较容易混淆,label是这次训练时候要使用的标签数量。num_classes代表要微调的模型原来的标签数量。
learn_all状态二与状态三主要区别,决定着是否训练卷积层。
一般只是设置train参数较多:caffenet(train=FLASE)
.
3、函数介绍二:style_net 风格函数
该函数封装了上面的函数一caffenet,返回的是具有style_net特色的框架训练文件deploy.prototxt
同时该函数也是《Fine-tuning a Pretrained Network for Style Recognition》中唯一的数据输入的地方。
而且还使用了ImageData层,这一函数笔者看了很久。
输入:学习率设置、子集设置、训练设置
输出:deploy文件
def style_net(train=True, learn_all=False, subset=None): if subset is None: subset = 'train' if train else 'test' source = caffe_root + 'data/flickr_style/%s.txt' % subset transform_param = dict(mirror=train, crop_size=227, mean_file=caffe_root + 'data/ilsvrc12/imagenet_mean.binaryproto') style_data, style_label = L.ImageData( transform_param=transform_param, source=source, batch_size=50, new_height=256, new_width=256, ntop=2) return caffenet(data=style_data, label=style_label, train=train, num_classes=NUM_STYLE_LABELS, classifier_name='fc8_flickr', learn_all=learn_all) 注意点:train和subset之间的冲突。subset在这的权限就是决定是用验证集还是测试集,当然其实这一功能train参数也可以实现,subset在这是为了更灵活操作函数使用。train在这功能还挺多:
- train=TRUE,如果在不设置subset情况下则是代表使用训练集数据。同时框架文件deploy的训练是打开的,数据输入的时候,mirror功能也是打开着的。
- train=FALSE,代表使用验证集,框架文件deploy不训练,只预测。
- 其中还有一个ImageData层,作为数据输入层,在整个文档中,是唯一数据输入入口,source是数据的来源。会在其他博客详细说明ImageData(caffe︱ImageData层、DummyData层作为原始数据导入的应用)。
- 该函数需要在data/flickr_style/**.txt有训练集+测试集的txt文件
- 需要有数据集的mean文件,此时应用的是caffeNet的mean文件
- 重置了最后的全连接层fc8_flickr
.
4、函数介绍三:caffe.Net预测框引擎(网络生成)
输入:deploy框架文件、模型weight权值
输出:caffe引擎文件,用于后续
caffe.Net(imagenet_net_filename, weights, caffe.TEST)# caffe.Net(deploy文件,模型权值,caffe.TEST)imagenet_net_filename是deploy文件,是整个框架的文件,也是caffenet/style_net得到的文件;
专门用于整个网络的生成
.
5、函数介绍四:预测函数disp_preds
输入:引擎文件(函数三)、新预测图片image,标签labels,K代表预测top多少、name便于输出
输出:返回print,top的准确率+分类标签,后期要改成return
def disp_preds(net, image, labels, k=5, name='ImageNet'): input_blob = net.blobs['data'] net.blobs['data'].data[0, ...] = image probs = net.forward(start='conv1')['probs'][0] top_k = (-probs).argsort()[:k] print 'top %d predicted %s labels =' % (k, name) print '\n'.join('\t(%d) %5.2f%% %s' % (i+1, 100*probs[p], labels[p]) for i, p in enumerate(top_k)) 预测函数disp_preds,通过函数三得到的引擎,进行net.forward前馈,通过net.forward(start=’conv1’)[‘probs’][0]获得所有标签的概率,然后通过排序输出top5
其中,labels如果是在验证集上就没有,那么可以不填的。
那么在之上作者封装了用于风格识别的函数:
def disp_imagenet_preds(net, image): disp_preds(net, image, imagenet_labels, name='ImageNet') def disp_style_preds(net, image): disp_preds(net, image, style_labels, name='style') .
6、函数介绍五:solver函数
输入:框架文件,(一般是caffenet/style_net之后)、学习率base_lr
输出:参数文件solver
def solver(train_net_path, test_net_path=None, base_lr=0.001)# train_net_path训练框架文件,一般是caffenet函数之后的deploy文件内容# test_net_path# base_lr,学习率.
7、函数介绍六:run_solvers训练函数
输入:迭代次数(niter)、参数文件solvers(函数五)、迭代间隔(disp_interval)
输出:loss/acc/weights值
def run_solvers(niter, solvers, disp_interval=10): """Run solvers for niter iterations, returning the loss and accuracy recorded each iteration. `solvers` is a list of (name, solver) tuples.""" blobs = ('loss', 'acc') loss, acc = ({name: np.zeros(niter) for name, _ in solvers} for _ in blobs) for it in range(niter): for name, s in solvers: s.step(1) # run a single SGD step in Caffe loss[name][it], acc[name][it] = (s.net.blobs[b].data.copy() for b in blobs) if it % disp_interval == 0 or it + 1 == niter: loss_disp = '; '.join('%s: loss=%.3f, acc=%2d%%' % (n, loss[n][it], np.round(100*acc[n][it])) for n, _ in solvers) print '%3d) %s' % (it, loss_disp) # Save the learned weights from both nets. weight_dir = tempfile.mkdtemp() weights = {} for name, s in solvers: filename = 'weights.%s.caffemodel' % name weights[name] = os.path.join(weight_dir, filename) s.net.save(weights[name]) return loss, acc, weights # niter,迭代次数# solvers,solver参数文件# disp_interval,.
8、函数介绍七:eval_style_net
输入:模型权值(run_solver之后)、迭代间隔10
输出:caffe.Net引擎、总体精确度
def eval_style_net(weights, test_iters=10): test_net = caffe.Net(style_net(train=False), weights, caffe.TEST) accuracy = 0 for it in xrange(test_iters): accuracy += test_net.forward()['acc'] accuracy /= test_iters return test_net, accuracy 在文档中,该函数主要用于对比精准度+生成预测引擎
.
.
三、三重天的状态简述
前篇也有提到模型fine-tuning的时候,官方文档《Fine-tuning a Pretrained Network for Style Recognition》中的三种微调状态:
- 状态一:只预测,不训练
- 状态二:训练,但只训练最后分类层
- 状态三:完全训练,分类层+之前卷积层都训练
当然,状态一+状态三的组合最佳,从官方文档的实验来看,状态三比状态二仅仅只训练最后的一层精度提高不少。
一个项目,拿到新的图像,进行一部分的标注,利用状态三进行训练,训练完的模型灌给状态一进行新图片的预测。
那么接下来会简单以函数串联的形式来复盘一下:
.
1、状态一:纯预测,不训练
应用场景:单独预测阶段,模型已经训练完毕。借用DummyData层来较快完成预测任务
- 1、利用DummyData设置备选图框,给新来的图像留个坑,L.DummyData函数
dummy_data=L.DummyData(shape=dict(dim=[1, 3, 227, 227])) 不同框架size不一致,要根据框架来定,caffenet在这里就是227
- 2、构建框架文件deploy.prototxt,用caffenet函数
net_filename=caffenet(data=dummy_data, train=False)- 3、设置预测引擎,caffe.Net函数
weights = caffe_root +'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
assert os.path.exists(weights)
net=caffe.Net(net_filename, weights, caffe.TEST)其中需要加载框架权值,以及上面的deploy文件
- 4、单张预测,disp_imagenet_preds函数
disp_imagenet_preds(net, image)image为新图片信息,net为前面的网络引擎net
其中image是图像的信息
改进的方向:数据输入的改进,可以通过imageData每个batch输入,并进行预测
.
2、状态二:训练,只训练最后的全连接层
应用场景:当数据基本类似,那么全连接层之前就不变,学习率不变; 最后的全连接层进行一次训练。
- 1、★生成框架文件deploy.prototxt:
style_net(train=True) Learn_all 没打开,所以只能训练全连接层。状态二与状态三唯一的区别就在这,如果learn_all=False,则使用frozen_param设置网络层的学习率,即学习率为0
- 2、生成参数文件solver.prototxt ,solver函数
style_solver_filename =solver(style_net(train=True)) 只输入框架文件,然后根据框架文件生成了solver参数文件,其中也附带了数据导入,那么如果是自己fine-tuning就需要进行修改。
- 3、生成训练引擎get_solver
style_solver = caffe.get_solver(style_solver_filename) 输入的是上面生成的参数文件。输出的是训练引擎
- 4、加载模型权值copy_from,.net.copy_from
weights = caffe_root +'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
assert os.path.exists(weights)
style_solver.net.copy_from(weights) 这一步是加载已经训练好的权值,一般第一次是fine-tuning来的.caffemodel权值,那么如果中途停掉在启动,那么启动的权值就是上次训练到一半的权值参数,可以继续训练下去。
- 5、训练run_solvers
solvers = [('pretrained', style_solver)]
niter=200
loss, acc, weights =run_solvers(niter, solvers)
这里只迭代200次,返回整个训练重要的三项内容:loss/acc/weights
- 6、返回预测引擎+训练准确率eval_style_net
style_weights=weights['pretrained']test_net, accuracy = eval_style_net(style_weights)返回预测引擎caffeNet+整个训练的准确率
- 7、预测函数disp_style_preds
disp_style_preds(test_net, image)输入的是,上面生成的训练引擎+新图像的特征信息,文档中是用imageData层来作为前期图像数据信息提取的方式,那么也可以自己用其他的方式来transformer
然后返回print,top5的准确率+分类标签。
- 8、图片展示函数deprocess_net_image
plt.imshow(deprocess_net_image(image)) deprocess_net_image为图像转化函数,可以显示图像。
.
3、状态三:end-to-end 完全训练
**应用场景:**fine-tuning整个框架,精度来说,比状态二要好不少,而且具有自己的特色,这一状态是fine-tuning主要使用的状态。
- 1、★生成框架文件deploy.prototxt:
end_to_end_net=style_net(train=True, learn_all=True)Learn_all 打开,所以训练卷积层+全连接层。状态二与状态三的区别就在这。learn_all参数默认值为False,当其为False时,意味着预训练的层(conv1到fc7)的lr_mult=0,我们仅仅学习了最后一层。
- 2、★生成参数文件solver.prototxt ,solver函数
style_solver_filename =solver(end_to_end_net,base_lr=base_lr) 只输入框架文件,然后根据框架文件生成了solver参数文件,其中也附带了数据导入,那么如果是自己fine-tuning就需要进行修改。
状态三,这里还要设置学习率base_lr为0.001,因为是fine-tuning,越小越好。
- 3、生成训练引擎get_solver
style_solver = caffe.get_solver(style_solver_filename) 输入的是上面生成的参数文件。输出的是训练引擎
- 4、加载模型权值copy_from,.net.copy_from
weights = caffe_root +'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
assert os.path.exists(weights)
style_solver.net.copy_from(weights) 这一步是加载已经训练好的权值,一般第一次是fine-tuning来的.caffemodel权值,那么如果中途停掉在启动,那么启动的权值就是上次训练到一半的权值参数,可以继续训练下去。
- 5、训练run_solvers
solvers = [('pretrained', style_solver)]
niter=200
loss, acc, weights =run_solvers(niter, solvers) 这里只迭代200次,返回整个训练重要的三项内容:loss/acc/weights
- 6、返回预测引擎+训练准确率eval_style_net
style_weights=weights['pretrained']
test_net, accuracy = eval_style_net(style_weights)输入的是已经训练好的weight,返回预测引擎caffeNet+整个训练的准确率
- 7、预测函数disp_style_preds
disp_style_preds(test_net, image)输入的是,上面生成的训练引擎+新图像的特征信息,文档中是用imageData层来作为前期图像数据信息提取的方式,那么也可以自己用其他的方式来transformer
然后返回print,top5的准确率+分类标签。
- 8、图片展示函数deprocess_net_image
plt.imshow(deprocess_net_image(image)) deprocess_net_image为图像转化函数,可以显示图像。
.
.
四、微调注意事项
本文参考:实验 | 百行代码实现Kaggle排名Top 5%的图像分类比赛
.
1、为什么要微调?
因为我们只有数千张训练样本,而深度网络的参数非常多,这就意味着训练图片的数量要远远小于参数搜索的空间,因此,如 果只是随机初始化深度网络然后用这数千张图片进行训练,非常容易产生“过拟合”(Overfitting)的现象。
可以想象这样一组参数的网络已经“看过”了大量 的图片,因此泛化能力大大提高了,提取出来的视觉特征也更加的鲁棒和有效。
.
2、提高预测精度技巧一:预测的图片做图像增强
这个技巧指的是,当我们训练好某个模型后,对于某张测试图片,我们可以使用类似数据扩增的技巧生成与该张图片相类似的多张图片,并把这些图片送进我们训练 好的网络中去预测,我们取那些投票数最高的类别为最终的结果。Github仓库中的predict_average_augmentation.py实现 的就是这个想法,其效果也非常明显。
.
3、交叉验证训练多个模型
还记得我们之前说到要把三千多张图片分为训练集和验证集吗?这种划分其实有很多种。一种常见的划分是打乱图片的顺序,把所有的图片平均分为K份,那么我们 就可以有K种<训练集,验证集>的组合,即每次取1份作为验证集,剩余的K-1份作为训练集。因此,我们总共可以训练K个模型,那么对于每张 测试图片,我们就可以把它送入K个模型中去预测,最后选投票数最高的类别作为预测的最终结果。我们把这种方式成为“K折交叉验证”(K-Fold Cross-Validation)。下图表示的就是一种5折交叉验证的数据划分方式。
.
4、平衡采样
来源:技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
很多数据集存在样本不均衡的问题,有些类别特别多,有些类别特别少。训练模型时,从一个图像列表中依次读取样本训练。这样的话,小类样本参与训练的机会就比大类少。
训练出来的模型会偏向于大类,即大类性能好,小类性能差。
平衡采样策略就是把样本按类别分组,每个类别生成一个样本列表。训练过程中先随机选择1个或几个类别,然后从各个类别所对应的样本列表中随机选择样本。这样可以保证每个类别参与训练的机会比较均衡。在PASCAL VOC数据集上,使用平衡采样性能可以提升约0.7个点。
.
5、其他
来源:技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
难例挖掘(OHEM [5])。使用了难例挖掘后,收敛更快,训练更稳定。在ImageNet DET数据集上,性能可以提升1个多点。
多尺度训练。使用多尺度训练的话,可以让参与训练的目标大小分布更加均衡,使模型对目标大小具有一定的鲁棒性。
.
6、预测技巧
来源:技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
预测阶段,我们用了多尺度预测,水平翻转,和检测框投票。
。当使用多尺度预测,水平翻转,还有多模型Ensemble时,对于同一张测试图像,我们会得到好几组结果。对于这些结果,最直观的融合方式就是把所有的检测框放在一起,然后用非极大值抑制(NMS)处理一下。但是我们发现另一种方式效果更好,就是把RPN和FRCN分开来做。
先对RPN做多尺度、水平翻转、多模型的融合,得到一组固定的Proposal之后,再对FRCN进行多尺度、水平翻转、多模型的融合。
RPN的融合用NMS更好,FRCN的融合用对Proposal的置信度和Bounding Box位置取平均值的方式更好。
延伸一:状态一,直接更改了全连接层可以直接使用吗?
同时,对于状态一,官方文档中也是进行了预测,如果在没有训练卷积层+全连接层的情况下,强行更改会出现以下的情况——所有的预测分类都是均等的:
untrained_style_net = caffe.Net(style_net(train=False, subset='train'), weights, caffe.TEST) disp_style_preds(untrained_style_net, image)
top 5 predicted style labels =(1) 20.00% Detailed(2) 20.00% Pastel(3) 20.00% Melancholy(4) 20.00% Noir(5) 20.00% HDRuntrained_style_net中,train=False代表关闭训练引擎(solver/caffe.get_solver/run_solver),subset=’train’代表使用训练集。
因为我们的分类器初始化为0(观察caffenet,没有权值滤波其经过最后的内积层),softmax的输入应当全部为0,因此,我们看到每个标签的预测结果为1/N,这里n为5,因此所有的预测结果都为20%。(来源博客:caffe学习笔记10.1–Fine-tuning a Pretrained Network for Style Recognition(new))
所以,如果要修改最后的全连接层,那么至少需要状态二,不然输出不了你想要的结果。
.
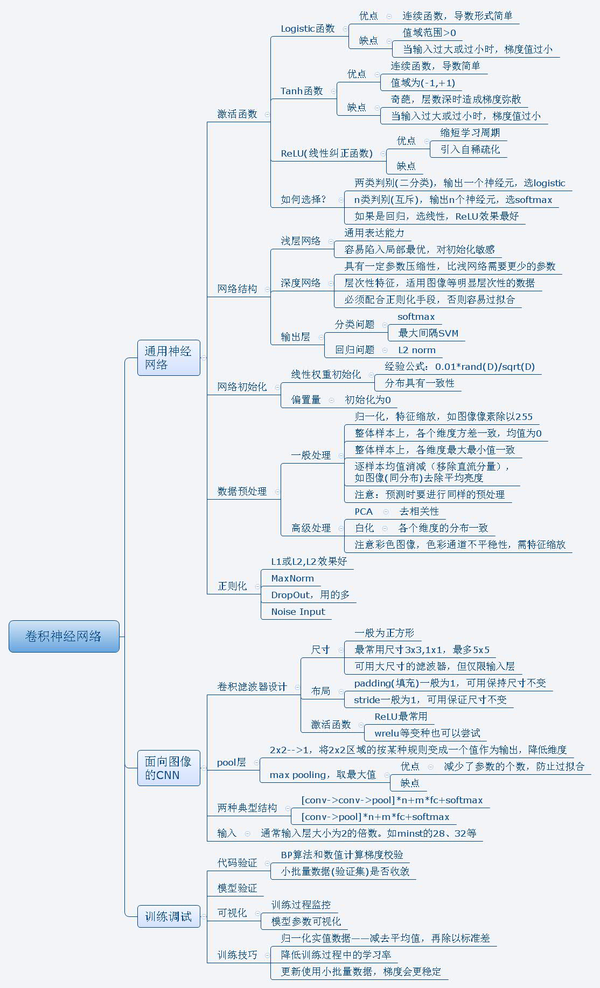
延伸二:一些CNN卷积的总结
来源于:人脸检测与深度学习
微调︱caffe中fine-tuning模型三重天(函数详解、框架简述)+微调技巧相关推荐
- Caffe中常用的层:Dropout层详解
dropout可以让模型训练时,随机让网络的某些节点不工作(输出置零),也不更新权重,其他过程不变.我们通常设定一个dropout radio=p,即每个输出节点以概率p置0(不工作,权重不更新),假 ...
- LSTM模型预测sin函数详解
注解: fun_data()函数生成训练数据和标签,同时生成测试数据和测试标签HIDDEN_SIZE = 128,使用128维的精度来定义LSTM的状态和输出精度,就是LSTM中的h,c lstm_m ...
- Numpy中stack(),hstack(),vstack()函数详解
这三个函数有些相似性,都是堆叠数组,里面最难理解的应该就是stack()函数了,我查阅了numpy的官方文档,在网上又看了几个大牛的博客,发现他们也只是把numpy文档的内容照搬,看完后还是不能理解, ...
- java中sort的cmp_快速排序(cmp函数详解)
缘由:上次给某同学讲 Collections.sort() 在Comparator接口重写compare方法,被比较规则卡壳,于是有了下文@Override public int compareTo( ...
- Excel中ROUND、ROUNDUP、ROUNDDOWN函数详解
在Excel中,很多时候都会用到Round函数,今天就来看下 Microsoft Excel 中 ROUND 函数.ROUNDUP函数和ROUNDDOWN函数的公式语法和用法. ROUND函数(对数值 ...
- 【Torch API】pytorch 中torch.ones_like和torch.zeros_like函数详解
torch.ones_like函数和torch.zeros_like函数的基本功能是根据给定张量,生成与其形状相同的全1张量或全0张量,示例如下: input = torch.rand(2, 3) p ...
- timm 视觉库中的 create_model 函数详解
timm 视觉库中的 create_model 函数详解 最近一年 Vision Transformer 及其相关改进的工作层出不穷,在他们开源的代码中,大部分都用到了这样一个库:timm.各位炼丹师 ...
- Java内存模型(JMM)详解-可见性volatile
这里写自定义目录标题 Java内存模型(JMM)详解-可见性 什么是JMM JMM存在的意义 为什么示例demo中不会打印 i 的值 如何解决可见性问题 **深入理解JMM内存模型** JAVA内存模 ...
- 从零开始学前端 - 7. CSS盒模型 margin和padding详解
作者: 她不美却常驻我心 博客地址: https://blog.csdn.net/qq_39506551 微信公众号:老王的前端分享 每篇文章纯属个人经验观点,如有错误疏漏欢迎指正.转载请附带作者信息 ...
- execvp函数详解_如何在C / C ++中使用execvp()函数
execvp函数详解 In this article, we'll take a look at using the execvp() function in C / C++. 在本文中,我们将介绍如 ...
最新文章
- Android应用程序组件Content Provider的启动过程源代码分析(6)
- installation of igraph for python2.7
- 中国剩余定理(模板+代码)
- python列表的小东西_小谈python里 列表 的几种常用用法
- 过滤器 拦截器 controller 页面 的执行顺序
- Kubernetes 小白学习笔记(8)--kubernetes的基础概念
- Category为什么会覆盖原来类中的方法?
- 使用GDAL库读取SRTM格式的高程数据
- AutoCAD.net 自定义窗体及面板与CAD交互时的焦点切换问题(C#)
- Java基础第三天复习
- vue实现二维码批量打印功能
- java常见正则表达式用法
- log是什么文件可以删除吗?log文件被删怎么恢复?
- CASS中基于高程点并生成等高线的方法
- Python socket和前端html
- pkt2flow的使用
- 【偷鸡系列】华为OD机试 :找终点
- 机器视觉技术助力工业物联网发展,起到核心作用。
- java自学——java的基本讲解和变量、字符串、运算符的简单介绍
- 2020-11-16 css使用颜色渐变绘制梯形
热门文章
- 掌握 cinder-scheduler 调度逻辑 - 每天5分钟玩转 OpenStack(48)
- fir.im Weekly - 2016 开年技术干货分享
- Android组件间的数据传输
- 新浪搜索Tabpage
- Educational Codeforces Round 41 (Rated for Div. 2)
- Windows 10 Creators Update隐私策略变动一览
- 解决问题 WebDriverException: Message: unknown error: cannot find Chrome binary
- 实现两个虚拟域内用户相互收发邮件
- CentOS 下解决ssh登录 locale 警告
- UVa 10986 - Sending email