python seaborn 散点图矩阵_Kaggle、Python数据可视化seaborn(四):散点图
在本教程中,您将学习如何创建高级散点图。
准备好笔记本
和往常一样,我们从设置编码环境开始。import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
print("Setup Complete")
加载并检查数据
我们将使用一个(合成的)保险费用数据集,看看我们是否能理解为什么有些客户比其他人支付更多。
如果您愿意,您可以在这里阅读关于数据集的更多信息。# Path of the file to read
insurance_filepath = "../input/insurance.csv"
# Read the file into a variable insurance_data
insurance_data = pd.read_csv(insurance_filepath)
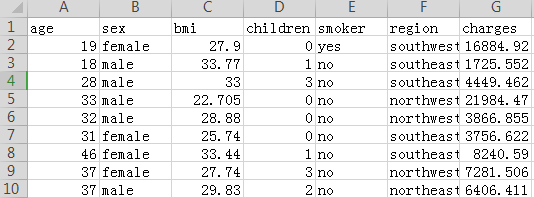
与往常一样,我们通过打印前五行来检查数据集是否正确加载。insurance_data.head()
散点图
要创建简单的散点图,我们使用sns.scatterplot命令并指定以下值:水平x轴(x = insurance_data ['bmi']),和
垂直y轴(y = insurance_data ['charge'])。sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
输出:
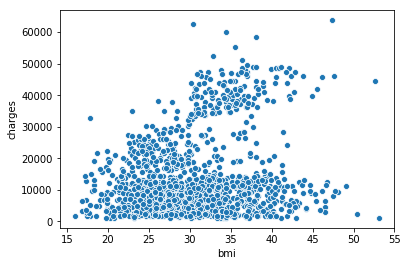
上面的散点图表明,体重指数(BMI)和保险费用正相关,而BMI较高的客户通常也倾向于支付更高的保险费用。 (这种模式是有道理的,因为高BMI通常与慢性疾病的高风险相关。)
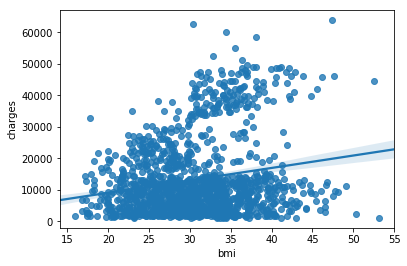
要仔细检查此关系的强度,您可能希望添加回归线或最适合数据的线。 我们通过将命令更改为sns.regplot来完成此操作。sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])
输出:/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
颜色编码的散点图
我们可以使用散点图来显示三个变量之间的关系!一种方法是用颜色编码这些点。
例如,为了了解吸烟是如何影响BMI和保险成本之间的关系,我们可以用“吸烟者”来对这些点进行颜色编码,并在坐标轴上标出另外两列(BMI, charge)。sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])
输出:
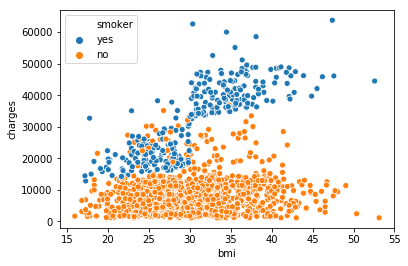
这个散点图显示,随着体重指数的增加,不吸烟的人愿意支付更多的钱,而吸烟的人支付更多。
为了进一步强调这一事实,我们可以使用sns.lmplot命令添加两个回归线,分别对应于吸烟者和非吸烟者。(您会注意到,相对于非吸烟者,吸烟者的回归曲线斜率要大得多!)sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)
输出:/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
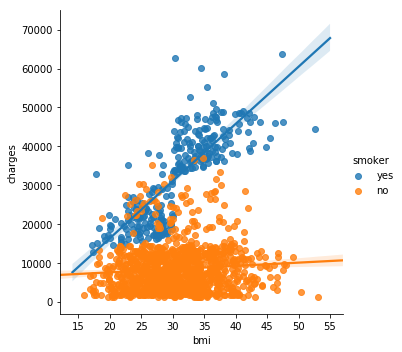
sns.lmplot命令的工作原理与您目前学到的命令略有不同:我们没有设置x=insurance_data['bmi']来选择insurance_data中的'bmi'列,而是设置x="bmi"来指定列的名称。
同样,y="charge "和hue=" smoking "也包含列的名称
我们使用data=insurance_data指定数据集。
最后,还有一个你会学到的图,它可能看起来和你习惯看到的散点图有点不同。通常,我们使用散点图来突出两个连续变量(如“bmi”和“charge”)之间的关系。但是,我们可以调整散点图的设计,使其在一个主轴上显示一个分类变量(如“smoking”)。我们将此图类型称为分类散点图,并使用sns.swarmplot命令构建它。sns.swarmplot(x=insurance_data['smoker'],
y=insurance_data['charges'])
输出:

除此之外,这幅图还告诉我们:平均而言,非吸烟者的收费比吸烟者低,而且支付最多的顾客是吸烟者;而花费最少的顾客是非吸烟者。
本地可运行代码:import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Path of the file to read
insurance_filepath = "data-for-datavis/insurance.csv"
# Read the file into a variable insurance_data
insurance_data = pd.read_csv(insurance_filepath)
print(insurance_data.head())
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
# 添加回归线
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])
# 颜色区分
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])
# 2条回归线
sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)
# 分类散点图
sns.swarmplot(x=insurance_data['smoker'],
y=insurance_data['charges'])
plt.show()
python seaborn 散点图矩阵_Kaggle、Python数据可视化seaborn(四):散点图相关推荐
- Py之Seaborn:数据可视化Seaborn库的柱状图、箱线图(置信区间图)、散点图/折线图、核密度图/等高线图、盒形图/小提琴图/LV多框图的组合图/矩阵图实现
Py之Seaborn:数据可视化Seaborn库的柱状图.箱线图(置信区间图).散点图/折线图.核密度图/等高线图.盒形图/小提琴图/LV多框图的组合图/矩阵图实现 目录
- Python数据可视化的例子——散点图(scatter)
(关系型数据的可视化) 散点图用于发现两个数值变量之间的关系 如果需要研究两个数值型变量之间是否存在某种关系,例如正向的线性关系,或者是趋势性的非线性关系,那么散点图将是最佳的选择. 1.matplo ...
- 大数据可视化python_大数据分析之Python数据可视化的四种简易方法
本篇文章探讨了大数据分析之Python数据可视化的四种简易方法,希望阅读本篇文章以后大家有所收获,帮助大家对相关内容的理解更加深入. < 数据可视化是任何数据科学或机器学习项目的一个重要组成部分 ...
- python 财务分析可视化方法_Python数据可视化的四种简易方法
Python数据可视化的四种简易方法 作者:PHPYuan 时间:2018-11-28 03:40:43 摘要: 本文讲述了热图.二维密度图.蜘蛛图.树形图这四种Python数据可视化方法. 数据可视 ...
- Py之seaborn:数据可视化seaborn库(二)的组合图可视化之密度图/核密度图分布可视化、箱型图/散点图、小提琴图/散点图组合可视化的简介、使用方法之最强攻略(建议收藏)
Py之seaborn:数据可视化seaborn库(二)的组合图可视化之密度图/核密度图分布可视化.箱型图/散点图.小提琴图/散点图组合可视化的简介.使用方法之最强攻略(建议收藏) 目录 二.组合图可视 ...
- Python: 除matplotlib外还有哪些数据可视化库?
Python: 除matplotlib外还有哪些数据可视化库? matplotlib算是python比较底层的可视化库,可定制性强.图表资源丰富.简单易用.达到出版质量级别. 其它的可视化库诸如: s ...
- 用python进行简单的数据分析和数据可视化
用python进行简单的数据分析和数据可视化 本篇文章主要是初步探索数据分析,简单了解数据分析大致流程 数据来源:来自于Kaggle平台上的一个项目:Explore San Francisco cit ...
- 在R、Python和Julia中常用的数据可视化技术
俗话说"一图胜千言".通过各种图片和图形化展示,我们可以更清晰地表达很多抽象概念.理论.数据模式或某些想法.在本章中,我们首先解释为什么应该关心数据可视化.然后,我们将讨论几种在R ...
- Py之seaborn:数据可视化seaborn库(三)的矩阵图可视化之jointplot/JointGrid/pairplot/PairGrid/FacetGrid密度图等的函数源代码详解之最强攻略
Py之seaborn:数据可视化seaborn库(三)的矩阵图可视化之jointplot/JointGrid/pairplot/PairGrid/FacetGrid折线图/柱状图+散点图/矩形密度图的 ...
- python爬虫数据可视化_适用于Python入门者的爬虫和数据可视化案例
本篇文章适用于Python小白的教程篇,如果有哪里不足欢迎指出来,希望对你帮助. 本篇文章用到的模块: requests,re,os,jieba,glob,json,lxml,pyecharts,he ...
最新文章
- Automatically highlight current page in menu via Javascript
- JQuery动态执行javascript代码的方法
- java中map比较大小_java中对map根据value进行排序
- hdu 2824 The Euler function
- python请输入你的名字_实现《你的名字》同款滤镜,python+opencv
- 挂机宝装mysql_挂机宝安装
- 一起Polyfill系列:让Date识别ISO 8601日期时间格式
- 交换二叉树中所有结点的左右子树的位置
- js打印不询问直接打印_直接成型喷墨打印的五个关键注意事项
- 激光导航agv常见的三大应用场景是什么?
- 百度公司关于SEO的建议
- html5超级玛丽小游戏
- 在Windows本地安装ElasticSearch和Kibana
- clappr:可扩展网页媒体播放器使用(在vue中的使用)
- 模糊控制(二)模糊控制——模糊推理
- 降噪蓝牙耳机推荐什么牌子好?入耳式降噪蓝牙耳机推荐
- 计算机高级 论文怎么考,干货丨如何在一个月内通过高级软考证
- Uniapp实现小程序获取用户微信信息功能
- 2022华为杯A题第二问详细思路分析移动场景超分辨定位问题
- SpringMVC学习系列(6) 之 数据验证