RABBITMQ集群及HA、LB
RABBITMQ集群及HA、LB
一、Rabbitmq简介
RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
AMQP,即Advanced message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
rabbitmq是使用erlang开发的,集群非常方便,且天生就支持并发分布式,但自身并不支持负载均衡. 常规的博客介绍都是说rabbitmq有几种部署模式,其中最常用的也就两种:
1,单一模式: 就是不做ha...
2,镜像模式模式: active/active模式的ha,当master挂掉了,按照策略选择某个slave(其实就是最先加入集群的那个slave)来担当master的角色。
1. Rabbitmq系统架构
RabbitMQ Server: 也叫broker server,是一种传输服务,负责维护一条从Producer到consumer的路线,保证数据能够按照指定的方式进行传输。
Producer,数据的发送方。
Consumer,数据的接收方。
Exchanges 接收消息,转发消息到绑定的队列。主要使用3种类型:direct, topic, fanout。
Queue RabbitMQ内部存储消息的对象。相同属性的queue可以重复定义,但只有第一次定义的有效。
Bindings 绑定Exchanges和Queue之间的路由。
Connection: 就是一个TCP的连接。Producer和consumer都是通过TCP连接到RabbitMQ Server的。
Channel:虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
二、 Rabbitmq安装
1. 安装 erlang 虚拟机
###安装 erlang 虚拟机,Rabbitmq 基于 erlang 语言开发,所以需要安装 erlang 虚拟机。
wget http://www.erlang.org/download/otp_src_R15B01. tar .gz
tar -xvf otp_src_R15B01.tar .gz
cdotp_src_R15B01
yum install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC unixODBC-devel
./configure --prefix=/usr/local/erlang --enable-hipe --enable-threads --enable-smp-support --enable-kernel-poll
make &make install
2. 安装 rabbitmq
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.6/rabbitmq-server-generic-unix-3.5.6. tar .gz
tar -xvf rabbitmq-server-generic-unix-3.2.1. tar .gz
mv rabbitmq_server-3.2.1 /usr/local/rabbitmq
cd /usr/local/rabbitmq/
rm LICENSE* -rf
# sbin/rabbitmqctl #<--提示没找到 erlang 虚拟机
sbin/rabbitmqctl: line 29: exec: erl: not found
##建立软连接,解决 erlang 虚拟机路径问题
ln -s /usr/local/erlang/bin/erl /usr/local/bin/
mkdir /data/rabbitmq/data /data/rabbitmq/log -p #<--建立存放数据日志目录
# vim /usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env .conf
RABBITMQ_NODE_IP_ADDRESS=10.168.185.96
RABBITMQ_MNESIA_BASE=/data/rabbitmq/data
RABBITMQ_LOG_BASE=/data/rabbitmq/log
# vim /usr/local/rabbitmq/etc/rabbitmq/rabbitmq #<--设置日志级别
[
{rabbit, [{log_levels, [{connection, error}]}]}
].
启动 rabbitmq
/usr/local/rabbitmq/sbin/rabbitmq-server –detached& 启后默认端口是: rabbitmq 的 默认端口是 5672.
停止程序:
/usr/local/rabbitmq/sbin/rabbitmqctl stop #若单机有多个实例,则在 rabbitmqctl 后加–n 指定名称
3. RABBITMQ页面(web)管理
启用 rabbitmq web 管理插件:
/usr/local/rabbitmq/sbin/rabbitmq-plugins enable rabbitmq_management
关闭 rabbitmq 管理插件:
/usr/local/rabbitmq/sbin/rabbitmq-plugins disable rabbitmq_management
列出所有插件:
/usr/local/rabbitmq/sbin/rabbitmq-plugins list
4. Rabbitmq创建用户
如果是集群的话,只要在一台主机设置即可,其它会自动同步。
#rabbitmqctl add_user admin 123456 –admin为新建的用户,123456为密码
#rabbitmqctl set_user_tags admin administrator –将用户设置为管理员角色
#rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
–在 / 虚拟主机里设置iom用户配置权限,写权限,读权限。.*是正则表达式里用法。rabbitmq的权限是根据不同的虚拟主机(virtual hosts)配置的,同用户在不同的虚拟主机(virtual hosts)里可能不一样。
5. Rabbitmq安全特性
(1)publish消息确认机制
如果采用标准的 AMQP 协议,则唯一能够保证消息不会丢失的方式是利用事务机制 — 令 channel 处于 transactional 模式、向其 publish 消息、执行 commit 动作。在这种方式下,事务机制会带来大量的多余开销,并会导致吞吐量下降 250% 。为了补救事务带来的问题,引入了 confirmation 机制(即 Publisher Confirm)。
confirm 机制是在channel上使用 confirm.select方法,处于 transactional 模式的 channel 不能再被设置成 confirm 模式,反之亦然。
在 channel 被设置成 confirm 模式之后,所有被 publish 的后续消息都将被 confirm(即 ack) 或者被 nack 一次。但是没有对消息被 confirm 的快慢做任何保证,并且同一条消息不会既被 confirm 又被 nack 。
RabbitMQ 将在下面的情况中对消息进行 confirm :
RabbitMQ发现当前消息无法被路由到指定的 queues 中;
非持久属性的消息到达了其所应该到达的所有 queue 中(和镜像 queue 中);
持久消息到达了其所应该到达的所有 queue 中(和镜像 queue 中),并被持久化到了磁盘(被 fsync);
持久消息从其所在的所有 queue 中被 consume 了(如果必要则会被 acknowledge)。
(2)consumer消息确认机制
为了保证数据不被丢失,RabbitMQ支持消息确认机制,即acknowledgments。
如果没启动消息确认机制,RabbitMQ在consumer收到消息后就会把消息删除。
启用消息确认后,consumer在处理数据后应通过回调函数显示发送ack, RabbitMQ收到ack后才会删掉数据。如果consumer一段时间内不回馈,RabbitMQ会将该消息重新分配给另外一个绑定在该队列上的consumer。另一种情况是consumer断开连接,但是获取到的消息没有回馈,则RabbitMQ同样重新分配。
注意:如果consumer 没调用basic.qos 方法设置prefetch_count=1,那即使该consumer有未ack的messages,RabbitMQ仍会继续发messages给它。
(3)消息持久化
消息确认机制确保了consumer退出时消息不会丢失,但如果是RabbitMQ本身因故障退出,消息还是会丢失。为了保证在RabbitMQ出现意外情况时数据仍没有丢失,需要将queue和message都要持久化。
queue持久化:channel.queue_declare(queue=’hello’, durable=True)
message持久化:channel.basic_publish(exchange=”,
routing_key=”task_queue”,
body=message,
properties=pika.BasicProperties(
delivery_mode = 2,) #消息持久化
)
即使有消息持久化,数据也有可能丢失,因为rabbitmq是先将数据缓存起来,到一定条件才保存到硬盘上,这期间rabbitmq出现意外数据有可能丢失。
网上有测试表明:持久化会对RabbitMQ的性能造成比较大的影响,可能会下降10倍不止。
三、Rabbitmq集群
1. RABBITMQ集群基本概念
一个RABBITMQ集 群中可以共享user,virtualhosts,queues(开启Highly Available Queues),exchanges等。但message只会在创建的节点上传输。当message进入A节点的queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。
RABBITMQ的集群节点包括内存节点、磁盘节点。内存节点的元数据仅放在内存中,性能比磁盘节点会有所提升。不过,如果在投递message时,打开了message的持久化,那么内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。一个集群至少要有一个磁盘节点。
2. RABBITMQ搭建集群
(1) 部署网络环境:
有三台机器(mq-cluster1,2,3) rabbitmq的执行用户为rabbitmq,所属组rabbitmq。直接将以下内容其加到/etc/hosts文件中
其中mq-cluster1为master,其余的为slave
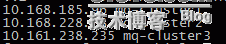
(2) 同步erlang.cookie文件
我是以mq-cluster1为master的,所以需要将其内容覆盖到mq-cluster2和mq-cluster3中
杀掉rabbitmq2和rabbitmq3的rabbitmq进程:
#ps –ef|grep rab|awk ‘{print $2}’|xargs kill -9。–用service rabbitmq-servier stop停止会有遗留进程。
scp 同步完成后,启动mq_cluster2和mq_cluster3的rabbitmq服务
(3) 设置ha模式
rabbitmqctl set_policy [-p <vhostpath>] [--priority <priority>] [--apply-to <apply-to>] <name> <pattern> <definition>
name 策略名称
pattern 正则表达式,用来匹配资源,符合的就会应用设置的策略
definition 是json格式设置的策略。
apply-to 表示策略应用到什么类型的地方,一般有queues,exchange和all,默认是all
priority 是个整数优先级
其中ha-mode有三种模式:
all: 同步至所有的.
exactly: 同步最多N个机器. 当现有集群机器数小于N时,同步所有,大于等于N时则不进行同步. N需要额外通过ha-params来指定.
nodes: 只同步至符合指定名称的nodes. N需要额外通过ha-params来指定.# 这里设置的是同步全部的queue, 可以按需自己选择指定的queue
rabbitmqctl set_policy ha-all '.*' '{"ha-mode":"all"}'
(4) cluster2,3加入集群
在mq-cluster2和mq-cluster3中分别执行:
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@mq-cluster1
rabbitmqctl start_app
加入之后, 可以通过rabbitmqctl cluster_status来查看cluster状态.
ps:默认加入是一disc模式加入,可以执行rabbitmqctl change_cluster_node_type <ram|disc>进行模式的修改
(5) 更改节点属性
#rabbitmqctl stop_app –停止rabbitmq服务
#rabbitmqctl change_cluster_node_type disc/ram –更改节点为磁盘或内存节点
#rabbitmqctl start_app –开启rabbitmq服务
在rabbitmq 2.中使用:
#rabbitmqctl stop_app
#rabbitmqctl force_cluster rabbit@mq-cluster1 #不加自己的node_name,是ram模式
#rabbitmqctl force_cluster rabbit@mq-cluster1 rabbit@mq-cluster2 #加自己的node_name 是disk模式
3. RABBITMQ退出集群
假设要把rabbitmq2退出集群
在rabbitmq2上执行
#rabbitmqctl stop_app
#rabbitmqctl reset
#rabbitmqctl start_app
在集群主节点上执行
# rabbitmqctl forget_cluster_node rabbit@mq-cluster2
4. RABBITMQ集群重启
集群重启时,最后一个挂掉的节点应该第一个重启,如果因特殊原因(比如同时断电),而不知道哪个节点最后一个挂掉。可用以下方法重启:
先在一个节点上执行
#rabbitmqctl force_boot
#service rabbitmq-server –detached&
在其他节点上执行
#service rabbitmq-server –detached&
查看cluster状态是否正常(要在所有节点上查询)。
#rabbitmqctl cluster_status
如果有节点没加入集群,可以先退出集群,然后再重新加入集群。
上述方法不适合内存节点重启,内存节点重启的时候是会去磁盘节点同步数据,如果磁盘节点没起来,内存节点一直失败。
5. 注意事项
§ cookie在所有节点上必须完全一样,同步时一定要注意。
§ erlang是通过主机名来连接服务,必须保证各个主机名之间可以ping通。可以通过编辑/etc/hosts来手工添加主机名和IP对应关系。如果主机名ping不通,rabbitmq服务启动会失败。
§ 如果queue是非持久化queue,则如果创建queue的那个节点失败,发送方和接收方可以创建同样的queue继续运作。但如果是持久化queue,则只能等创建queue的那个节点恢复后才能继续服务。
§ 在集群元数据有变动的时候需要有disk node在线,但是在节点加入或退出的时候所有的disk node必须全部在线。如果没有正确退出disk node,集群会认为这个节点当掉了,在这个节点恢复之前不要加入其它节点。
四、Rabbitmq HA
1. 镜像队列概念
镜像队列可以同步queue和message,当主queue挂掉,从queue中会有一个变为主queue来接替工作。
镜像队列是基于普通的集群模式的,所以你还是得先配置普通集群,然后才能设置镜像队列。
镜像队列设置后,会分一个主节点和多个从节点,如果主节点宕机,从节点会有一个选为主节点,原先的主节点起来后会变为从节点。
queue和message虽然会存在所有镜像队列中,但客户端读取时不论物理面连接的主节点还是从节点,都是从主节点读取数据,然后主节点再将queue和message的状态同步给从节点,因此多个客户端连接不同的镜像队列不会产生同一message被多次接受的情况。
2. 配置镜像队列
沿用3.2的环境,现在我们把名为“hello”的队列设置为同步给所有节点
#rabbitmqctl set_policy ha-all ‘hello’ ‘{“ha-mode”:”all”}’
ha-all 是同步模式,指同步给所有节点,还有另外两种模式ha-exactly表示在指定个数的节点上进行镜像,节点的个数由ha-params指定,ha-nodes表示在指定的节点上进行镜像,节点名称通过ha-params指定;
hello 是同步的队列名,可以用正则表达式匹配;
{“ha-mode”:”all”} 表示同步给所有,同步模式的不同,此参数也不同。
执行上面命令后,可以在web管理界面查看queue 页面,里面hello队列的node节点后会出现+2标签,表示有2个从节点,而主节点则是当前显示的node(xf7021是测试用的名字,按4-2应该为rabbitmq(1-3))。
3. 测试rabbitmq的ha
测试的python代码,依次发送消息到三个rabbitmq-server中,
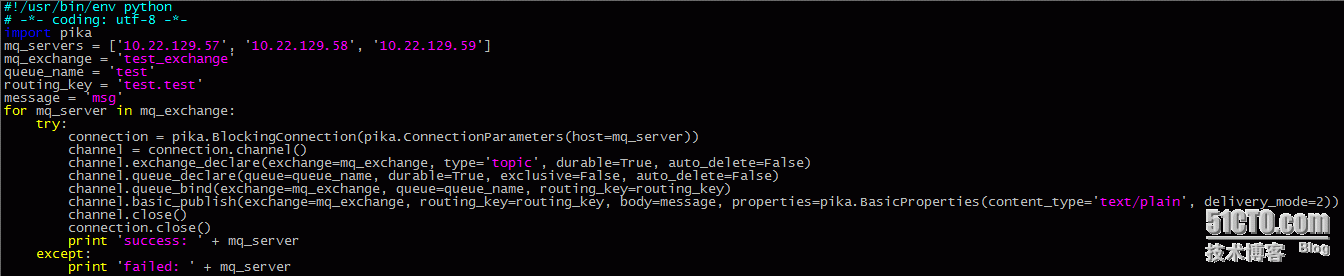
可以随机的操作去关闭任意一个mq-cluster上的rabbitmq-server服务, 再通过rabbitmqctl list_queues来查看消息的数量. 可以看到,尽管master挂了,消息依然能够发送成功,且当挂掉的机器(master或者slave)重新起起来之后,消息会马上同步过去.
4. 搭建haproxy
安装和初始配置haproxy此处从略.
在配置好的/etc/haproxy/haproxy.cfg尾端加上以下内容
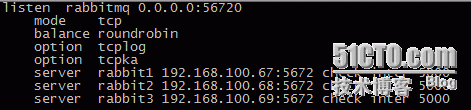
接着启动haproxy
haproxy -f /etc/haproxy/haproxy.cfg -D
5. 测试rabbitmq的haproxy下的lb
将之前的测试代码中的
mq_servers = ['10.22.129.57', '10.22.129.58', '10.22.129.59']
改成
mq_servers = ['10.22.129.53', '10.22.129.53', '10.22.129.53']
执行测试代码,发现三个消息均发送成功,然后即使手动关闭其中一台mq,消息依然发送成功,通过rabbitctl list_queues也依然可以看到消息是成功收到3条的.
至此,可以看到rabbitmq-server成功的解除了single-point状态。
转载于:https://blog.51cto.com/linuxpython/1716372
RABBITMQ集群及HA、LB相关推荐
- rabbitmq 集群 ha负载 Consumer raised exception, processing can restart if the connection factory
情况是酱紫滴 线上有一个rabbitmq 集群,一台磁盘模式的 两台内存模式的. 使用erlang 做cookie 做同步.haproxy做负载 在连接一会后 程序抛出异常 Consumer rais ...
- Rabbitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- 基于高可用配置的RabbitMQ集群实践
本文将提供一个基于高可用配置的RabbitMQ集群方案.通过介绍RabbitMQ的基本概念.主要作用和使用场景,并搭建RabbitMQ单节点环境.用程序演示消息发送接收过程,以及搭建RabbitMQ高 ...
- 自己的笔记本上设置RabbitMQ集群
RabbitMQ 是用 erlang 开发的,集群非常方便,因为 erlang 天生就是一门分布式语言,但其本身并不支持负载均衡.Rabbit 模式大概分为以下三种:单一模式.普通模式和镜像模式. 单 ...
- hbase1.1.1 连接集群_除了HAProxy,RabbitMQ集群还可以这样用
全网最简单的安装手册 // 安装erlang wget https://packagecloud.io/install/repositories/rabbitmq/erlang/script.rpm. ...
- RabbitMQ集群、镜像部署配置
2019独角兽企业重金招聘Python工程师标准>>> 1 RABBITMQ简介及安装 RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端, ...
- Rabbitmq集群高可用部署详细
清风万里的季节,周末本该和亲人朋友一起消遣这烂漫的花花草草,或是懒洋洋的晒个太阳听听风声鸟鸣.无奈工作使然,理想使然,我回到啦公司,敲起啦键盘,撸起啦代码,程序狗的世界一片黯然,一片黯然,愿天下所有努 ...
- K8S 部署rabbitmq集群
K8S 部署rabbitmq集群 版本介绍 名称 版本 k8s 1.18 rabbitmq 3.8 命名空间:rabbitmq 我这里已经建立 configmap 配置文件 [root@k8s-mas ...
- rabbitmq集群部署及配置
rabbitmq集群部署及配置 文章目录 rabbitmq集群部署及配置 前言 一.原理介绍 二.部署方案 1.环境介绍 2.部署过程 小结 前言 消息中间件rabbitmq,一般以集群方式部署,主要 ...
- docker 部署rabbitmq,k8s部署rabbitmq集群,跟踪和监控rabbitmq
全栈工程师开发手册 (作者:栾鹏) 架构系列文章 rabbit原理和架构可以参考https://blog.csdn.net/luanpeng825485697/article/details/8208 ...
最新文章
- 勇士斗恶龙:没那么复杂的Js闭包(改)
- java中懒汉饿汉编写及比较
- eclipse安装weblogic Server服务器
- 小程序导航组件navigator活学活用
- myeclipse2014删除antlr-2.7.2.jar--解决struts和hibernate包冲突
- c++ 带参数的宏定义实现反射机制
- LQR轨迹跟踪算法Python/Matlab算法实现_LQRmatrix推导(2)
- 安卓java自实现mp3播放器,Android MediaPlayer实现音乐播放器实例代码
- 昔年浅谈做害虫消杀防护的用什么推广效果好?
- .net5 程序 在docker 中运行
- paip.网站接入QQ登录总结
- ssh-keygen 指定路径
- 道格拉斯普克算法(简化线段点)
- 浙大翁恺pat练习题_中国大学MOOC-翁恺-C语言-PAT习题及解答-第二周
- 【日常计算机问题】win11、win10解决公共WiFi认证不弹出的问题。电脑没有弹出认证界面。以广州图书馆i-guangdong;i广东为例
- 论语之宪问第十四、卫灵公第十五、季氏第十六
- 为什么Tesla显卡那么贵
- TensorFlow之文本分类算法-2
- 把一个字符串中的大写字母和小写字母分别存储到一个新的字符串中
- welcome.php,welcome.php
热门文章
- C# Serilog日志框架
- C#获取实体的属性和值(通用于BS、cs架构)
- C调用PYTHON运行奇怪崩溃的一例及解决办法
- cudaMemcpy的性能问题
- 在tunnelbroker为服务器IP建立IPV6 Tunnel
- python中把输出结果写到一个文件中_python 文件中字符串过滤,并将结果输出到另一个文件中(源码)...
- 100阶乘c语言如何实现,求10000的阶乘(c语言代码实现)
- VC++使用dump定位release程序崩溃问题
- docker中 system limit for_java中的split函数的坑
- 计算机读不出光盘,win7光盘读不出来怎么办|win7光驱读不出光盘的解决方法