Python实现离线音频转文字(时间分隔+区分说话人)
Python实现离线音频转文字(时间分隔+区分说话人)
文章目录
- Python实现离线音频转文字(时间分隔+区分说话人)
- 前言
- 领取转写时长
- 创建个人应用
- 运行Python代码
- 运行环境
- 解决思路
- 修改参数
- 代码下载
前言
- 前阵子因工作原因,需要将一些录音文件转为文字,方便后续记录和摘要。在尝试付费使用了一些成熟的语音识别转写APP后,偶然发现讯飞开放平台有5小时免费时长可领取使用。
- 虽是免费,但是需要自己编写代码进行使用,于是参考了官网的API使用说明,自己实现了一个python版本的离线音频转写,默认支持普通话和英语。
领取转写时长
- 浏览器打开讯飞开放平台首页:https://www.xfyun.cn/,点击“语音识别”→“语音转写”,进入语音转写模块页面。
- 完成新用户的注册登录认证后,即可领取免费时长。
- **注意:**因为我们要实现的是离线音频上传后转写为文字,所以领取免费时长时领的是“语音转写”,而不是“语音听写”。
创建个人应用
- 注册登录并领取免费时长后,右上角点击“控制台”,进入控制台页面,并创建一个新应用。
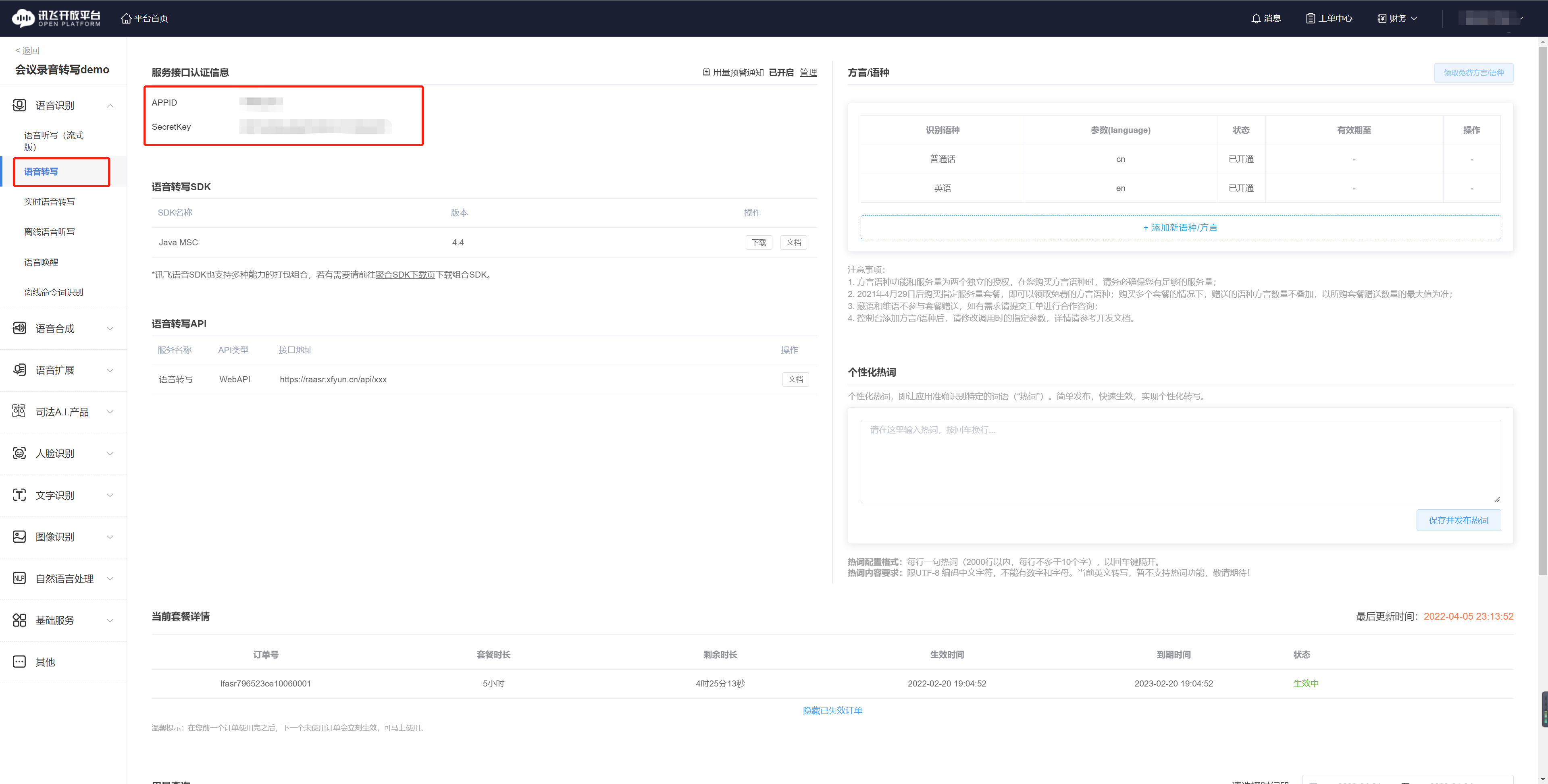
- 创建应用后,进入应用管理页面,点击“语音转写”模块,获取APPID和密钥,后面代码运行要用到这两个参数。
运行Python代码
运行环境
- Python3.7
- 需要特别注意的依赖库:requests==2.21.0
解决思路
- 参考讯飞开放平台上的接口说明和使用demo,输入APPID和密钥后,可访问对应的语音转写接口API,得到转写后的文字数据。
- 返回数据中包括每一句话的起始点、结束点、说话人、文字内容,所需要做的是对返回的JSON格式数据进行相应的读取,转为可读性高的文本文件。
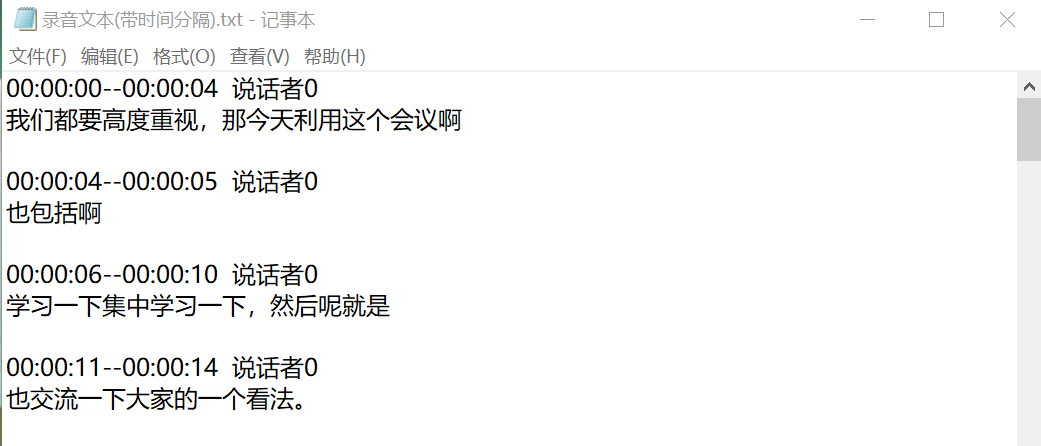
- 笔者代码中所做到的,一个是将整段的文本保存下来,不做时间分隔以及说话人区分,便于单人单段演讲或讲话的录音文件转写;另一个是做了时间分隔和说话人区分的版本,便于多人会议或讨论的录音文件转写。

- 时间分隔的算法思路是,记录上一句话的结束点,如果与当前这一句话的起始点重合(精确到毫秒),说明这两句话是紧密衔接着的,可以拼接在一起。于是设置一个缓冲区存放当前拼接着的文本,如果上下两句不衔接,则将缓冲区内容写入文件,刷新缓冲区,放入当前句子的文本内容。遍历平台返回数据的每一句话,不断更新和写入缓冲区,便实现了整段音频做了时间分隔并写入文件。
- 两种转写方式的文本均有保存到代码同目录下,保存格式为txt文件。以下为时间分分割版本的截图:
修改参数
- 运行代码时,需修改相关参数为自己创建的应用的APPID和密钥,以及想要转写的录音文件路径。

代码下载
代码资源地址:讯飞开放平台音频转文字(python)
Python实现离线音频转文字(时间分隔+区分说话人)相关推荐
- 使用Python轻松识别音频中文字(Whisper)
使用Python轻松识别音频中文字 一.前言 在开会或是讨论问题的时候,我们总有一些内容需要记录下来.但由于各种原因,我们无法做到全面细致的记录.事后我们可能需要补充这些细节性内容,而回放视频或是录音 ...
- 基于Python的离线OCR图片文字识别(三)——支持PDF文件
前面第一个版本实现了基本的ocr功能,可以对某图像文件进行处理,将ocr结果以同名txt文件的方式保存在图像文件同路径下: 然后在第二个版本中又实现了对文件夹参数的支持,也即可以对某个包含大量图像文件 ...
- 基于Python的离线OCR图片文字识别(五)——终极版本
至此,终于迎来了离线ocr的终极大结局,命令行后面参数既支持图像文件.图像文件夹,还支持PDF图像类型的文件,既支持通过json文件进行参数配置,又支持帮助文档,easyOCR包既支持允许字符集(也即 ...
- 基于Python的离线OCR图片文字识别(一)——命令行方式对图像文件处理生成同名txt文件
应用背景:在正式开始文章之前,先阐述一下项目的应用背景--项目需要对已有的电子档案数据进行"大数据"处理和呈现,但是由于之前进行档案电子化时都是以扫描文件的图像格式存储在硬盘上(准 ...
- 基于Python的离线OCR图片文字识别(四)——支持txt文件指定路径保存
虽然在前面在第二次升级时就已经通过json配置文件支持将ocr识别结果txt保存到指定的文件夹里了,但由于指定待识别文件夹时文件夹里面可能包含多个不同的子文件夹.不同的子文件夹里面可能包含同名的图像文 ...
- python是哪个人创造的文字_创造中国汉字的人是谁
展开全部 创造汉字的没有人知道,因为汉字应该是在商朝诞生的,而商朝的历史已经彻底被儒家第一位圣人鸡蛋(周62616964757a686964616fe4b893e5b19e31333366303731 ...
- ffmpeg m4a 转pcm_FFmpeg提取视频音频python将音频转文字
ffmpeg提取视频中的音频-pcm ffmpeg -y -i input.mp4 -vn -codec copy out.m4a ffmpeg -i out.m4a -f segment -segm ...
- python 时间函数 毫秒_利用python进行播放音频与录音,骚操作!
现如今,我们的学习知识的渠道越来越多,我们也要充分利用自己的感官去汲取知识.当我们看书累的时候,我们完全可以听过听书来学习,这样的平台也很多,pk 哥之前也写过关于下载喜马拉雅音频爬虫的方法:Pyth ...
- 看日本电影再也不怕看不懂了,6行Python代码轻松实现音频转文字
前面几天想看一个电影(至于什么电影就不说了),搜了半天没有中文字幕. 这种事情,你是不是也预定过!很痛苦,有声音和图形.但是你听不懂!嗯? 于是,我想想现在的科技这么发达,难道找不到音频转文字的软件吗 ...
最新文章
- 干货丨先搞懂这八大基础概念,再谈机器学习入门
- 阿里mysql同步工具otter的docker镜像
- windows11图文安装流程
- Linux使用lvresize扩展或缩减LV逻辑卷大小
- Java Script 学习笔记(一)
- [Vue warn]: Duplicate keys detected: ‘0‘. This may cause an update error.
- 使用ASP.NET Core 3.x 构建 RESTful API - 2. 什么是RESTful API
- 数据处理工具(一)——Matplotlib
- stanford-parser for C#
- Linux笔记-nohup和
- CSS:前端布局——网格布局Grid
- 使用Java实现一元二次方程求根计算器
- 模数转换器(ADC)选型参考指南
- 【Zeekr_Tech】初谈我们共同的目标 NPDS + Agile
- 汽车学习---汽车知识大全【all】
- [现代控制理论]7_线性控制器设计_Linear Controller Design
- 基于JavaScript实现拼图游戏
- matlab 语音识别为文字,语音识别(Speech Recognition)是让机器通过识别和理解过程把语音信号转变为相应的文本...
- 区块链行业缺乏统一标准,成为金融新基建尚存距离
- 番外篇:韩国网游兴起