可应用于实际的14个NLP突破性研究成果(四)
可应用于实际的14个NLP突破性研究成果(一)
可应用于实际的14个NLP突破性研究成果(二)
可应用于实际的14个NLP突破性研究成果(三)
11.对序列建模的通用卷积和递归网络的实证评估作者:SHAOJIE BAI,J。ZICO KOLTER,VLADLEN KOLTUN
论文摘要
对于大多数深度学习实践者来说,序列建模与循环网络是同义词。然而,最近的研究结果表明,卷积架构在语音合成和机器翻译等任务上的表现优于循环网络。给定一个新的序列建模任务或数据集,应该使用哪种架构?我们对序列建模的一般卷积和循环架构进行了系统的评价。我们在广泛的标准任务中评估这些模型。我们的结果表明,一个简单的卷积架构在不同的任务和数据集上的表现优于LSTM等典型的循环网络。我们的结论是,需要重新考虑序列建模和循环网络之间的共同关联,卷积网络应该被视为序列建模任务的一个自然起点我们提供了相关代码:http://github.com/locuslab/TCN。
总结
本文的作者质疑了一个常见假设,即循环架构应该是序列建模任务的默认起点。他们的结果表明,时间卷积网络(TCN)在多个序列建模任务中明显优于长短期记忆网络(LSTMs)和门控循环单元网络等典型的循环架构。
论文的核心思想是什么?
1、时间卷积网络(TCN)是基于最近提出的最佳实践(如扩张卷积和残差连接)设计的,它在一系列复杂的序列建模任务中表现得明显优于通用的循环架构。
2、TCN表现出比循环架构更长的记忆,因此更适合需要较长的历史记录的任务。
关键成就是什么?
· 在序列建模任务上提供了卷积架构和循环体系结构系统的比较。
· 设计了卷积体系结构,它可以作为序列建模任务的方便且强大的起点。
AI社区的对其评价?
在使用RNN之前,一定要先从CNN开始。
未来的研究领域是什么?
为了提高TCN在不同序列建模任务中的性能,需要进一步精化架构和算法。
可能应用的商业领域?
· 引入TCN可以提高依赖于循环架构进行序列建模的AI系统的性能。其中包括以下任务:
§机器翻译;
§语音识别;
§音乐和语音生成。
你在哪里可以得到代码?
1ã如论文摘要所述,研究人员通过GitHub存储库提供了官方代码。
2、你还可以查看PhilippeRémy提供的Keras实施的TCN。
12.用于文本分类的通用语言模型微调-ULMFiT作者:JEREMY HOWARD和SEBASTIAN RUDER
论文摘要
迁移学习在计算机视觉方面取得了很多成功,但是同样的方法应用在NLP领域却行不通。所以我们提出了通用语言模型微调(ULMFiT),这是一种有效的转移学习方法,可以应用于NLP中的任何任务。该方法在6个文本分类任务上的性能明显优于现有的文本分类方法,在大部分的数据集上测试使得错误率降低了18-24%。此外,仅有100个标记样本训练的结果也相当不错。我们已经开源我们的预训练模型和代码。
总结
Howard和Ruder建议使用预先训练的模型来解决各种NLP问题。使用这种方法的好处是你无需从头开始训练模型,只需对原始模型进行微调。通用语言模型微调(ULMFiT)的方法优于最先进的结果,它将误差降低了18-24%。更重要的是,ULMFiT可以只使用100个标记示例,就能与10K标记示例中从头开始训练的模型的性能相匹配。
论文的核心思想是什么?
· 为了解决缺乏标记数据的难题,研究人员建议将转移学习应用于NLP问题。因此,你可以使用另一个经过训练的模型来解决类似问题作为基础,然后微调原始模型以解决你的特定问题,而不是从头开始训练模型。
· 但是,这种微调应该考虑到几个重要的考虑因素:
§不同的层应该进行不同程度地微调,因为它们捕获不同类型的信息。
§如果学习速率首先线性增加然后线性衰减,则将模型的参数调整为任务特定的特征将更有效。
§微调所有层可能会导致灾难性的遗忘;因此,从最后一层开始逐渐微调模型可能会更好。
关键成就是什么?
· 显著优于最先进的技术:将误差降低18-24%;
· 所需的标记数据要少得多,但性能可以保障。
AI社区对其的看法是什么?
· 预先训练的ImageNet模型的可用性已经改变了计算机视觉领域,ULMFiT对于NLP问题可能具有相同的重要性。
· 此方法可以应用于任何语言的任何NLP任务。
未来的研究领域的方向是什么?
· 改进语言模型预训练和微调。
· 将这种新方法应用于新的任务和模型(例如,序列标记、自然语言生成、蕴涵或问答)。
可能应用的商业领域?
· ULMFiT可以更有效地解决各种NLP问题,包括:
§识别垃圾邮件、机器人、攻击性评论;
§按特定功能对文章进行分组;
§对正面和负面评论进行分类;
§查找相关文件等
你在哪里可以得到实现代码?
Fast.ai提供ULMFiT的官方实施,用于文本分类,并作为fast.ai库的一部分。
13.用非监督学习来提升语言理解,作者:ALEC RADFORD,KARTHIK NARASIMHAN,TIM SALIMANS,ILYA SUTSKEVER
论文摘要
自然语言理解包括各种各样的任务,例如文本蕴涵、问答、语义相似性评估和文档分类。虽然大量未标记的文本语料库很丰富,但用于学习这些特定任务的标记数据很少。我们证明,通过对多种未标记文本语料库中的语言模型进行生成预训练,然后对每项特定任务进行辨别性微调,可以实现这些任务的巨大收益。与以前的方法相比,我们在微调期间利用任务感知输入转换来实现有效传输,同时对模型架构进行最少的更改。我们证明了我们的方法在广泛的自然语言理解基准上的有效性。例如,我们在常识推理(Stories Cloze Test)上获得8.9%的性能改善,在问答(RACE)上达到5.7%,在文本蕴涵(MultiNLI)上达到1.5%。
总结
OpenAI团队建议通过在多种未标记文本语料库中预先训练语言模型,然后使用标记数据集对每个特定任务的模型进行微调,从而可以显著改善了语言理解。他们还表明,使用Transformer模型而不是传统的递归神经网络可以显著提高模型的性能,这种方法在所研究的12项任务中有9项的表现优于之前的最佳结果。
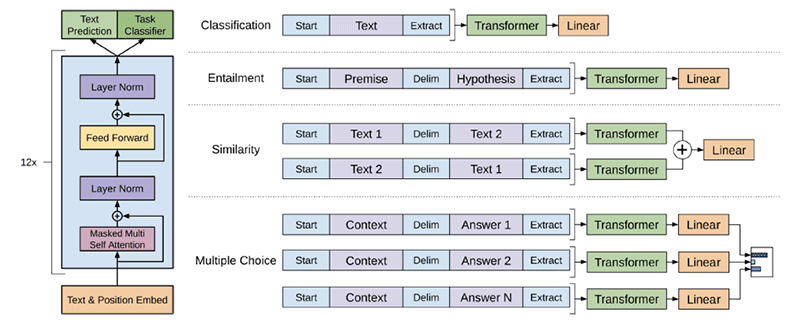
论文的核心思想是什么?
· 通过在未标记数据上学习神经网络模型的初始参数,然后使用标记数据使这些参数适应特定任务,结合使用无监督预训练和监督微调。
· 通过使用遍历样式方法避免跨任务对模型体系结构进行大量更改:
§预训练模型是在连续的文本序列上训练的,但是问题回答或文本蕴涵等任务具有结构化输入。
§解决方案是将结构化输入转换为预先训练的模型可以处理的有序序列。
· 使用Transformer模型而不是LSTM,因为这些模型提供了更加结构化的内存,用于处理文本中的长期依赖关系。
取得了什么关键成就?
· 对于自然语言推理(NLI)的任务,通过在SciTail上获得5%的性能改进和在QNLI上获得5.8%的性能改进。
· 对于QA和常识推理的任务,表现优于以前的最佳结果-在Story Cloze上高达8.9%,在RACE上高达5.7%。
· 通过在QQP上实现4.2%的性能改善,刷新了3个语义相似性任务中的2个的最新结果。
· 对于分类任务,获得CoLA的45.4分,而之前的最佳结果仅为35分。
AI社区对其看法是什么?
· 该论文通过使用基于Transformer模型而非LSTM扩展了ULMFiT研究,并将该方法应用于更广泛的任务。
· “这正是我们希望我们的ULMFiT工作能够发挥作用的地方!”Jeremy Howard,fast.ai的创始人。
未来的研究领域是什么?
进一步研究自然语言理解和其他领域的无监督学习,以便更好地理解无监督学习的时间和方式。
可能应用的商业领域?
OpenAI团队的方法通过无监督学习增强了自然语言理解,因此可以帮助标记数据集稀疏或不可靠的NLP应用。
在哪里可以得到实现代码?
Open AI团队在GitHub上的公开了代码和模型。
14.语境化词向量解析:架构和表示,作者:MATTHEW E. PETERS,MARK NEUMANN,LUKE ZETTLEMOYER,WEN-TAU YIH
论文摘要
最近研究显示从预训练的双向语言模型(biLM)导出的上下文词表示为广泛的NLP任务提供了对现有技术的改进。然而,关于这些模型如何以及为何如此有效的问题,仍然存在许多问题。在本文中,我们提出了一个详细的实证研究,探讨神经结构的选择(例如LSTM,CNN)如何影响最终任务的准确性和所学习的表征的定性属性。我们展示了如何在速度和准确性之间的权衡,但所有体系结构都学习了高质量的上下文表示,这些表示优于四个具有挑战性的NLP任务的字嵌入。此外,所有架构都学习随网络深度而变化的表示,从基于词嵌入层的专有形态学到基于较低上下文层的局部语法到较高范围的语义。总之,这些结果表明,无人监督的biLM正在学习更多关于语言结构的知识。
总结
今年早些时候艾伦人工智能研究所的团队介绍了ELMo嵌入,旨在更好地理解预训练的语言模型表示。为此,他们精心设计了无监督和监督任务上广泛研究学习的单词和跨度表示。研究结果表明,独立于体系结构的学习表示随网络深度而变化。
论文的核心思想是什么?
· 预训练的语言模型大大提高了许多NLP任务的性能,将错误率降低了10-25%。但是,仍然没有清楚地了解为什么以及如何在实践中进行预训练。
· 为了更好地理解预训练的语言模型表示,研究人员凭经验研究神经结构的选择如何影响:
§直接终端任务准确性;
§学习表示的定性属性,即语境化词表示如何编码语法和语义的概念。
什么是关键成就?
· 确认在速度和准确度之间存在权衡,在评估的三种架构中-LSTM,Transformer和Gated CNN:
§LSTM获得最高的准确度,但也是最慢的;
§基于Transformer和CNN的模型比基于LSTM的模型快3倍,但也不太准确。
· 证明由预先训练的双向语言模型(biLM)捕获的信息随网络深度而变化:
§深度biLM的词嵌入层专注于词形态,与传统的词向量形成对比,传统的词向量在该层也编码一些语义信息;
§biLM的最低上下文层只关注本地语法;
· 证明了biLM激活可用于形成对语法任务有用的短语表示。
AI社区对其看法是什么?
· 该论文在EMNLP 2018上发表。
· “对我来说,这确实证明了预训练的语言模型确实捕获了与在ImageNet上预训练的计算机视觉模型相似的属性。”AYLIEN的研究科学家Sebastian Ruder。
未来的研究领域是什么?
· 使用明确的句法结构或其他语言驱动的归纳偏见来增强模型。
· 将纯无监督的biLM训练目标与现有的注释资源以多任务或半监督方式相结合。
可能应用的商业领域?
1、通过更好地理解预训练语言模型表示所捕获的信息,研究人员可以构建更复杂的模型,并增强在业务环境中应用的NLP系统的性能。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
可应用于实际的14个NLP突破性研究成果(四)相关推荐
- 可应用于实际的14个NLP突破性研究成果(一)
语言理解对计算机来说是一个巨大的挑战.幼儿可以理解的微妙的细微差别仍然会使最强大的机器混淆.尽管深度学习等技术可以检测和复制复杂的语言模式,但机器学习模型仍然缺乏对我们的语言真正含义的基本概念性理解. ...
- 可应用于实际的14个NLP突破性研究成果(三)
论文摘要 当前最先进的语义角色标记(SRL)使用深度神经网络,但没有明确的语言特征.之前的工作表明,抽象语法树可以显著改善SRL,从而提高模型准确性.在这项研究中,我们提出了语言学的自我关注(LISA ...
- 可应用于实际的14个NLP突破性研究成果(二)
论文摘要 尽管最近在训练高质量的句子嵌入上做出了很多的努力,但是大家仍然对它们所捕捉的内容缺乏了解.基于句子分类的'Downstream'tasks通常用于评估句子表示的质量.然而任务的复杂性使得它很 ...
- 计算机研究与发展 介绍,我院NLP团队研究成果论文被《计算机研究与发展》期刊录用...
2020年6月15日,华南师范大学软件学院"自然语言处理与智能软件技术"研究团队(简称:NLP团队),在团队负责人曾碧卿教授带领下,在EI期刊<计算机研究与发展>上,录 ...
- 搜狗开源最新NLP研究成果,打造业内最全机器阅读理解工具包SMRC
晓查 发自 凹非寺 量子位 出品 | 公众号 QbitAI 上周,搜狗在GitHub低调发布了机器阅读理解工具包SMRC(Sogou Machine Reading Comprehension). 这 ...
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- 2021年14项世界互联网领先科技成果发布
来源:桐乡发布 9月26日下午,由国家互联网信息办公室.浙江省人民政府主办的2021年"世界互联网领先科技成果发布活动"在乌镇互联网国际会展中心乌镇厅举行.华为鸿蒙操作系统.北斗卫 ...
- 人工智能 | 自然语言处理(NLP)研究团队
博主github:https://github.com/MichaelBeechan 博主CSDN:https://blog.csdn.net/u011344545 Natural Language ...
- 做 NLP 算法研究,去大公司还是创业公司?
答案当然不是大公司.虽说计算资源这一个点,现在语言模型越搞越大,创业公司恐怕很难负担得起训练成本. 但这么想通常都是错的. 有一家 NLP 创业公司不仅解决了这个问题:他们今年初与国内一家大型云服务企 ...
最新文章
- tensorflow入门(二)
- 2019求职面经推荐(算法工程师-来自知乎某位大佬)
- python 线程等待_详解python多线程之间的同步(一)
- boost学习之 时间和日期 timer
- 实验2 java_《Java程序设计》实验2
- VB2005.Net 环境下使用Jmail组件发送邮件
- 华为认证HCNA-IoT物联网工程师培训视频
- K-th Number
- ASP.NET基础培训 - Cookie的正确利用
- 用python实现单词本功能
- [2020-07]如何获取百度访客搜索关键字(竞价、推广、SEO)
- 形如in (‘111,222,333‘) 的 ,Oracle的in函数(报错:无效数字)
- java实现Calendar求两个日期差
- 知识图谱嵌入|KG-BERT代码 ConvE ConvR
- vivo X Fold和OPPO Find N
- 在英特尔独立显卡上部署YOLOv5 v7.0版实时实例分割模型
- 青龙面板-- 咸鱼吃鱼(废-已不能使用)
- CSS3 3D旋转立方
- 办公总结——WPS表格拆分单元格及排序
- C#,数值计算,求解微分方程的吉尔(Gear)四阶方法与源代码
热门文章
- linux tar 大小不同,linux – 如何在使用tar时设置bzip2块大小?
- java连接mysql封装代码_JDBC连接数据库方法的封装,以及查询数据方法的封装
- linux docker查看容器状态,Docker容器状态命令行工具——Ctop
- python获取坐标颜色,python – 根据一组坐标的数据着色地图
- 怎么调整字段长短_【芝士蛋糕怎么总烤不熟呢?】
- leetcode 111 --- 二叉树最小深度
- android 分享到豆瓣,Android项目总结之社会化分享
- java break和return的区别_【java】break,continue和return区别
- android+自定义版本号,Android打包版本号设置方法
- php spry文本域_Spry框架及验证构件