PWA系列 - Cache API 的设计与实现
一 前言
Cache API 是ServiceWorker 的一种新的应用缓存机制,它提供了可编程的缓存操作方式, 能实现各种缓存策略,可以非常细粒度的操控资源缓存。
但我们对Cache API的了解也仅限于此?Cache API在浏览器的存储结构是怎样的,在存储容量方面有什么限制,在技术上是如何实现的,为什么会这样去设计?
本文尝试分析解答Cache API相关问题, 让大家对Cache API有更加深入的理解。
二 设计思想
(1)Chromium Cache API 设计
Chromium Cache API 设计者 给Cache API 的定位是“ServiceWorker 的一种新的应用缓存机制”。他们把Cache API定位为Application Cache,我们就很容易理解Chromium内部Cache API代码实现会大量重用Application Cache的代码,使用一样的存储类型(Temporary),使用一样的存储后端(Very Simple Backend)。
至于为什么这样定位,目前还未找到官方的解析,我自己的理解是,Chromium在最初设计Cache API时,仅仅是为了给ServiceWorker提供一个加强版的Application Cache。后来Cache API在成为W3C规范的过程中,各方积极参与讨论需求和实现,它的内涵才越来越丰富,它的使用场景也不再局限于ServiceWorker。
Chromium Cache API 实现的整体结构图:
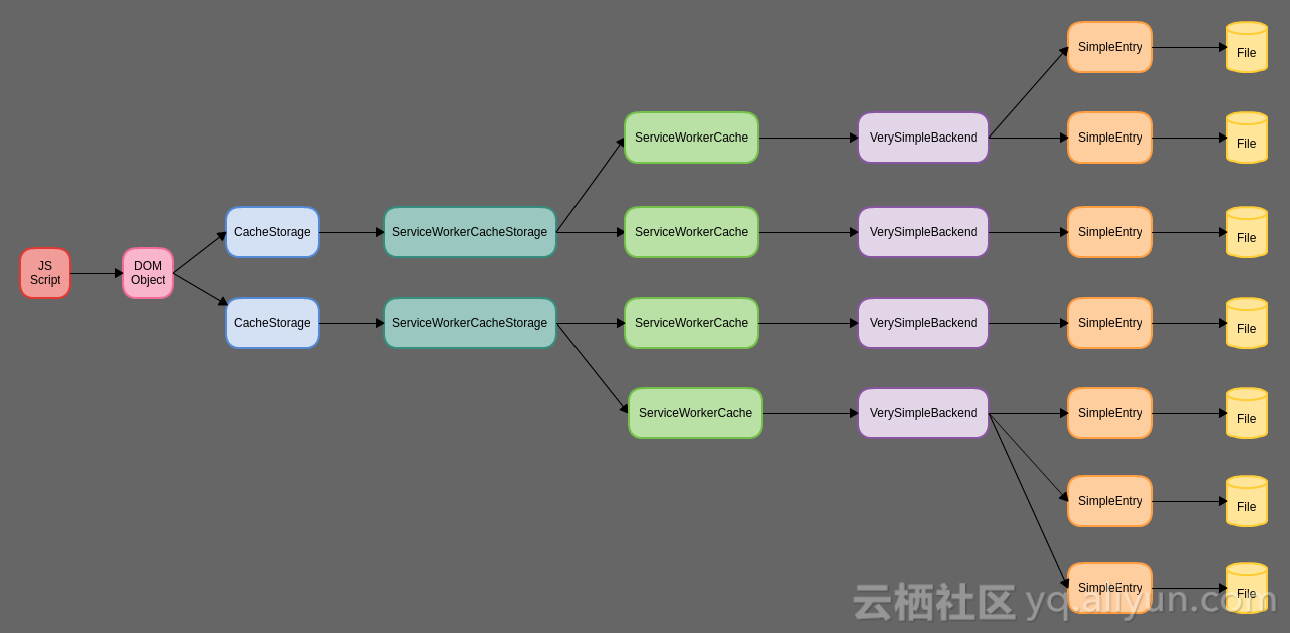
(2)Firefox Cache API 设计
Firefox Cache API 设计者 在博客文章中描述了他的想法,最初是想重用HTTP Cache 或者 基于IndexedDB去实现,但Cache API规范在不断演进,一些规范细节与上述解决方案存在不可调和的冲突。
- 比如,HTTP Cache中,一个URL只能对应一个Response,但Cache API规范要求同一URL(不同的Header)可以对应多个Response,另外,HTTP Cache没有使用容量管理系统(QuotaManager)而Cache API需要使用。
- IndexedDB 基于结构克隆(structured cloning),还不支持流式数据(streaming data),这样,Response可能会非常大,从网络回来会非常慢,会明显增大内存使用。
基于上述原因,Firefox决定基于SQLite为Cache API实现一套新的存储机制。使用SQLite的原因是:
- SQLite支持transaction。
- SQLite是一个经过充分测试的系统,大家都非常清楚它的注意事项和性能特征。
- SQL提供了灵活的查询引擎来实现和微调Cache匹配算法。
Firefox Cache API 实现的整体结构图:
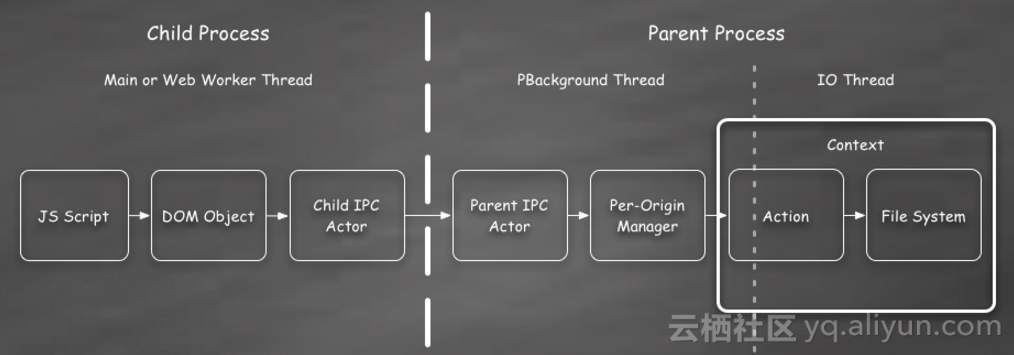
(3)W3C规范Cache API的要求
Window和WorkerGlobalScope都提供了caches对象,caches提供了一系列异步方法,可以创建和操作Cache对象。- 一个域名(origin)可以有多个不同名称的Cache对象,同一域名下的cacheName + Cache由同一 name to cache map管理。
- Cache 不能在不同域名之间共享,完全独立于浏览器的HTTP cache,但同一域名下的Window对象和ServiceWorker对象可以共用。
- Cache 完全由开发者控制,增加,删除,更新,等等操作,都需要由开发者去控制。
注意:下文只讨论Chromium Blink内核Cache API的设计实现。
三 CacheStorage的实现
(1)CacheStorage的创建
我们知道,规范里CacheStorage对应的内核的ServiceWorkerCacheStorage对象,CacheStorage 管理一系列 Cache 对象,它提供了很多JS接口用于操作Cache 对象。
- CacheStorage.open() 用于获取一个 Cache 对象实例。
- CacheStorage.match() 用于检查CacheStorage 中是否存在以Request 为Key的Cache 对象。
- CacheStorage.has() 用于检查是否存在指定名称的Cache 对象。
- CacheStorage.keys() 用于返回CacheStorage 中所有Cache 对象的Key列表。
- CacheStorage.delete() 用于删除指定名称的Cache 对象。
那么,CacheStorage的存储管理对象在浏览器内核是如何被创建的呢?请看代码流程:
self.caches.open(cacheName)
--> blink::CacheStorage::open
--> blink::ServiceWorkerCacheStorageDispatcher::dispatchOpen
--> content::ServiceWorkerCacheListener::OnCacheStorageOpen
--> content::ServiceWorkerCacheStorageManager::OpenCache
--> content::ServiceWorkerCacheStorageManager::FindOrCreateServiceWorkerCacheManager
--> new ServiceWorkerCacheStorage
一些需要注意的点:
- CacheStorage任意方法的调用,都有可能会引起ServiceWorkerCacheStorage对象的创建。
- ServiceWorkerCacheStorageManager持有一个cache_storage_map_(std::map<GURL, ServiceWorkerCacheStorage*>),这个map管理了所有的origin+ServiceWorkerCacheStorage。
- 一个域名(比如,origin: https://chaoshi.m.tmall.com/)只会创建一个ServiceWorkerCacheStorage对象。
- ServiceWorkerCacheStorage 持有一个cache_map_(std::map<std::string, base::WeakPtr<ServiceWorkerCache> >),这个map管理了同一域名下所有的cacheName+ServiceWorkerCache。
- 同一域名下的ServiceWorkerCacheStorage都放在同一目录,目录路径如下,
storage_path: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/CacheStorage/8f9fa7c394456a3f75c7c0aca39d897179ba4003
其中8f9fa7c394456a3f75c7c0aca39d897179ba4003是origin(https://chaoshi.m.tmall.com/)的hash值(使用base::SHA1HashString计算)。
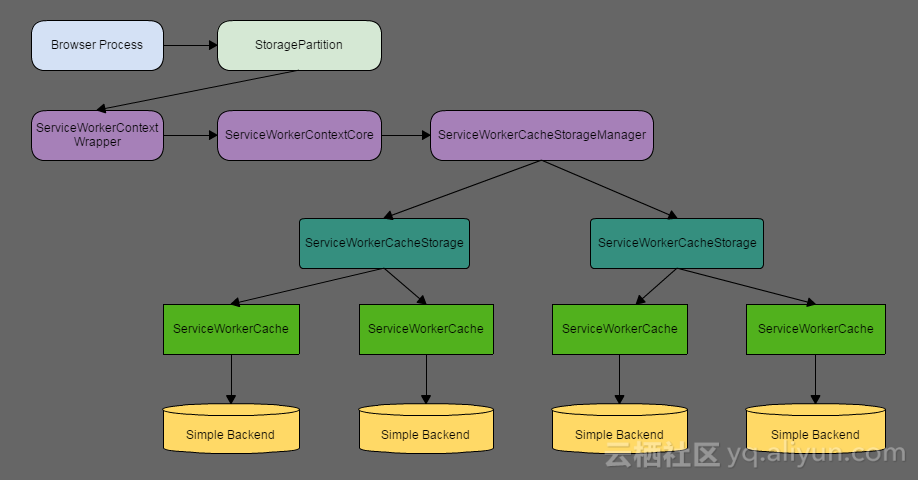
(2)CacheStorage相关对象关系
CacheStorage有非常多的关联对象,它们之间的关系如下:
1. 单进程模式的Chromium浏览器,比如,基于Chrome Android WebView的U4浏览器,一般会持有一个StoragePartition(对应的存储区为 /data/data/com.UCMobile/app_core_ucmobile)。
2. 一个StoragePartition会持有一个ServiceWorkerContext。
3. ServiceWorkerContextWrapper实现了ServiceWorkerContext,它会持有一个ServiceWorkerContextCore。
4. ServiceWorkerContextCore持有一个ServiceWorkerCacheStorageManager。
5. ServiceWorkerCacheStorageManager会为每一个域名创建一个ServiceWorkerCacheStorage。
6. ServiceWorkerCacheStorage会为每一个cacheName创建一个ServiceWorkerCache。
7. 每一个ServiceWorkerCache对应一个SimpleBackend的存储后端。
它们之间的详细关系,请参考下图:
四 Cache的实现
(1)Cache的创建
我们知道,规范里 Cache 对应内核的ServiceWorkerCache对象,提供了已缓存的 Request / Response 对象体的存储管理机制。它提供了一系列管理存储的JS接口。
- Cache.put() 用于把Request / Response 对象体放进指定的Cache。
- Cache.add() 用于获取一个Request 的 Response,并将Request / Response 对象体放进指定的Cache。注:等价于 fetch(request) + Cache.put(request, response)。
- Cache.addAll() 用于获取一组Request 的 Response,并将该组Request / Response 对象体放进指定的Cache。
- Cache.keys() 用于获取Cache 中所有Key列表,一般是Request的列表。
- Cache.match() 用于查找是否存在以Request 为Key的Cache 对象。
- Cache.matchAll() 用于查找是否存在一组以Request 为Key的Cache 对象组。
- Cache.delete() 用于删除以Request 为Key的Cache Entry。注意,Cache不会过期,只能显式删除 。
前端开发者可以使用 CacheStorage.open() 来获取Cache 对象的实例.
我们看看这种创建ServiceWorkerCache对象的过程:self.caches.open(cacheName) // 比如,cacheName: tm/chaoshi-fresh/4.2.17
--> content::ServiceWorkerCacheListener::OnCacheStorageOpen
--> content::ServiceWorkerCacheStorage::OpenCache // cache_map_查询不到cacheName,即为首次创建
--> content::ServiceWorkerCacheStorage::SimpleCacheLoader::CreateCache
--> content::ServiceWorkerCacheStorage::SimpleCacheLoader::CreateCachePrepDirInPool
--> content::ServiceWorkerCacheStorage::SimpleCacheLoader::CreateCachePreppedDir
--> content::ServiceWorkerCacheStorage::SimpleCacheLoader::CreateServiceWorkerCache
--> content::ServiceWorkerCache::CreatePersistentCache
--> new ServiceWorkerCache
我们看看ServiceWorkerCache对应的存储目录,
- origin: https://chaoshi.m.tmall.com/
- cache_path: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/CacheStorage/8f9fa7c394456a3f75c7c0aca39d897179ba4003/7353b21ee437f3877043ae17a5d5ba6395fdbd31
- 其中7353b21ee437f3877043ae17a5d5ba6395fdbd31是cacheName(tm/chaoshi-fresh/4.2.17)的hash值(使用base::SHA1HashString计算)。
还有一种情况也需要重新创建ServiceWorkerCache对象,我们看看这类创建的过程:content::ServiceWorkerCacheListener::OnCacheStorageOpen
--> content::ServiceWorkerCacheStorage::OpenCache // cache_map_可以查询到cacheName,非首次创建
--> content::ServiceWorkerCacheStorage::GetLoadedCache
// 发现cache_map_中cacheName对应的ServiceWorkerCache对象为空,需要重新创建
--> content::ServiceWorkerCacheStorage::SimpleCacheLoader::CreateServiceWorkerCache
--> content::ServiceWorkerCache::CreatePersistentCache
--> new ServiceWorkerCache
这种情况是,ServiceWorkerCache已析构,但ServiceWorkerCacheStorage还未析构,这时在cache_map_可以查询到cacheName,但里面的ServiceWorkerCache已为空。
为什么ServiceWorkerCacheStorage还未析构,而ServiceWorkerCache会已析构呢?从前面可以看到,ServiceWorkerCacheStorage是由ServiceWorkerCacheStorageManager管理的,而ServiceWorkerCacheStorageManager一般是全局唯一的,即一般ServiceWorkerCacheStorage是不会析构的。
但是,ServiceWorker线程关闭会引起ServiceWorkerCache的析构,流程如下,content::ServiceWorkerDispatcherHost::OnWorkerStopped
--> content::EmbeddedWorkerRegistry::OnWorkerStopped
--> content::EmbeddedWorkerInstance::OnStopped
--> content::ServiceWorkerVersion::OnStopped
--> content::ServiceWorkerCacheListener::~ServiceWorkerCacheListener
--> content::ServiceWorkerCache::~ServiceWorkerCache
所以,就会出现上面描述的ServiceWorkerCacheStorage还未析构,而ServiceWorkerCache会已析构的情况。
(2)Cache的存储限制
ServiceWorker 规范并没有明确规定ServiceWorkerCache的容量限制,那么,Chromium内核的浏览器是如何限制的呢?
每个ServiceWorkerCache对象的容量, Chromium40内核限制为512M,Chromium50及以上版本内核不作限制(即为std::numeric_limits<int>::max)。当然,这只是ServiceWorker层面的限制,它还会受浏览器QuotaManager的限制。
QuotaManager对每个域名可用存储空间也有限制,算法(Chromium57)可简单描述如下,
Temporary类型存储限额 = 【系统磁盘可用空间(available_disk_space) + 浏览器全局已使用空间(global_limited_usage)】/ 3 (注:kTemporaryQuotaRatioToAvail = 3)
每个域名可使用Temporary类型存储限额 = Temporary类型存储限额 / 5 (注:QuotaManager::kPerHostTemporaryPortion = 5)
比如,系统磁盘可用空间为570M, 浏览器全局已使用空间为30M,那么 每个域名可使用Temporary类型存储限额 = (570+30)/ 3 / 5 = 40M。
上述例子中,虽然ServiceWorkerCache在ServiceWorker层面的限制为512M,非常大,但它也不能超出每个域名的限制(40M),即同一域名下的ServiceWorkerCache也只能使用40M。
一般来说,ServiceWorker层面对ServiceWorkerCache的限制都会大于浏览器对每个域名的限制,所以,通常可理解为,ServiceWorkerCache仅受浏览器QuotaManager对域名可使用存储的限制。
(3)Cache的存储后端
前面提到,每个ServiceWorkerCache会对应一个SimpleBackend的存储后端。那么,这个SimpleBackend是如何创建的呢?请看代码流程:
content::ServiceWorkerCache::Match
--> content::ServiceWorkerCache::Init // 检查是否已初始化,如果还未初始化,就会进行初始化
--> content::ServiceWorkerCache::CreateBackend // 初始化的过程会创建SimpleBackend
--> disk_cache::CreateCacheBackend
--> new CacheCreator
--> CacheCreator::Run
--> new disk_cache::SimpleBackendImpl
从上述流程可以看到,ServiceWorkerCache相关方法(比如,match)的调用,会检查它是否已初始化,如果还未初始化,就会进行初始化,初始化的过程会创建SimpleBackend。
(4)Cache Entry的创建
ServiceWorkerCache提供了已缓存的 Request / Response 对象体的存储管理机制。这些Request / Response 对象体就作为ServiceWorkerCache对应的SimpleBackend的Entrys。
我们看看这些Entry是如何创建的,请看代码流程:
content::ServiceWorkerCache::Put
--> content::ServiceWorkerCache::PutImpl
--> disk_cache::SimpleBackendImpl::CreateEntry // 创建Entry
--> disk_cache::SimpleEntryImpl::CreateEntry
--> disk_cache::SimpleSynchronousEntry::CreateEntry
--> disk_cache::SimpleSynchronousEntry::InitializeForCreate
--> disk_cache::SimpleSynchronousEntry::CreateFiles // 创建Entry对应的文件
ServiceWorkerCache的put或add等方法,会引起它对应的SimpleBackend Entry的创建,每个Entry会对应一个文件。
我们看看Entry文件的存储目录,
Entry File Name: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/CacheStorage/8f9fa7c394456a3f75c7c0aca39d897179ba4003/7353b21ee437f3877043ae17a5d5ba6395fdbd31/3d1d89ddbe7c000f_0
其中,3d1d89ddbe7c000f_0 是由文件名(比如,https://g.alicdn.com/??tm/chaoshi-fresh/4.2.17/index.bundle.css)和文件索引(比如,file_index: 0)一起生成的一个hash值。
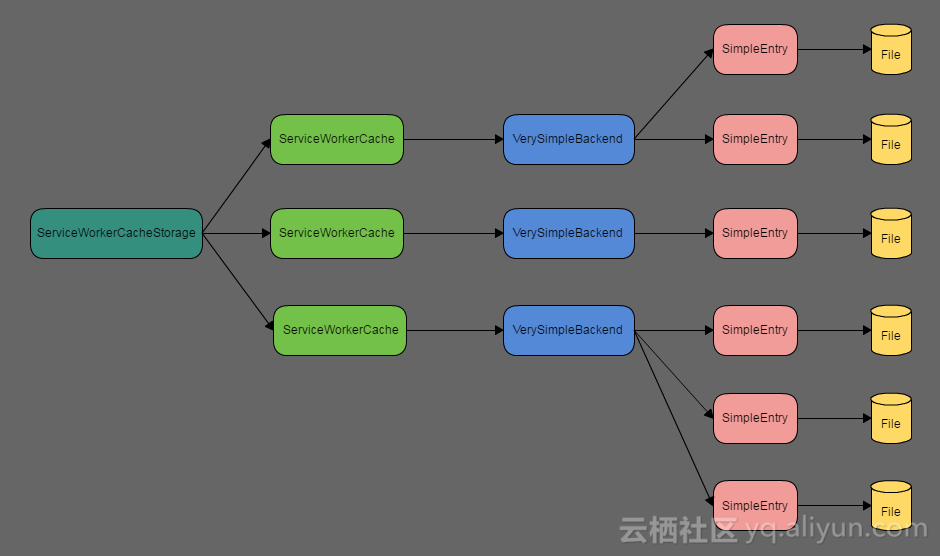
(5)Cache相关对象关系
Cache有非常多的关联对象,它们之间的关系如下:
1. 规范里CacheStorage对应的内核的ServiceWorkerCacheStorage对象,Cache 对应内核的ServiceWorkerCache对象。
2. ServiceWorkerCacheStorage会为每一个cacheName创建一个ServiceWorkerCache。
3. 每个ServiceWorkerCache有一个SimpleBackend。
4. 每个SimpleBackend有若干个SimpleEntry。
5. 每个SimpleEntry有一个文件。 比如天猫页面的cacheName(tm/chaoshi-fresh/4.2.17)对应有多个SimpleEntry文件,其中一个SimpleEntry文件为https://g.alicdn.com/tm/chaoshi-fresh/4.2.17/index.bundle.css。
它们之间的详细关系,请参考下图:
五 Script Cache的实现
(1)ServiceWorker Script Cache的创建
上面介绍了ServiceWorkerCache和ServiceWorkerCacheStorage的实现,它们负责管理ServiceWorker控制的资源的缓存。
那么,ServiceWorker Script(比如,serviceworker.js)本身是如何存储的呢?
我们先来看看ServiceWorker Script创建Cache Backend的过程:
content::ServiceWorkerWriteToCacheJob::OnResponseStarted
--> content::ServiceWorkerWriteToCacheJob::WriteHeadersToCache
--> content::ServiceWorkerStorage::CreateResponseWriter
--> content::ServiceWorkerStorage::disk_cache // 如果disk_cache_为空,才继续创建
--> content::AppCacheDiskCache::InitWithDiskBackend
--> content::AppCacheDiskCache::Init
--> disk_cache::CreateCacheBackend
--> new CacheCreator
--> CacheCreator::Run
--> new disk_cache::SimpleBackendImpl
其中,创建Cache Backend的参数如下,
- cache_type:3 (APP_CACHE)
- backend_type:2 (CACHE_BACKEND_SIMPLE )
- max_bytes:262144000 (250M)
- cache_path: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/Cache
我们可以看到,所有ServiceWorker Script共用同一存储后端(SimpleBackend),共用同一存储目录,存储大小限制为250M,存储类型为APP_CACHE, Backend类型为CACHE_BACKEND_SIMPLE。
(2)ServiceWorker Script Entry的创建
从上面可以看到ServiceWorker Script会使用SimpleBackend作为存储后端,那么,它的Entry是怎么创建的呢?
我们先看看代码的流程,
content::ServiceWorkerWriteToCacheJob::OnResponseStarted
--> content::ServiceWorkerWriteToCacheJob::WriteHeadersToCache
--> content::AppCacheResponseWriter::CreateEntryIfNeededAndContinue
--> content::AppCacheDiskCache::CreateEntry
--> disk_cache::SimpleBackendImpl::CreateEntry // 创建Entry
--> disk_cache::SimpleEntryImpl::CreateEntry
--> disk_cache::SimpleSynchronousEntry::CreateEntry
--> disk_cache::SimpleSynchronousEntry::InitializeForCreate
--> disk_cache::SimpleSynchronousEntry::CreateFiles // 创建对应的文件
创建Entry的详细信息如下,
- url: https://ucbrowser.github.io/pwa/message-channel2/service-worker-2.js
- key:10
- file_index:0 (注:file_index为0是指需要新创建文件)
- entry_hash: 8885558157644453297
- entry_path_: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/Cache
- entry_filename: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/Cache/7b4fd8111178d5b1_0
其中,每一个Script URL会对应一个key和entry_hash,entry_hash会有一个file_index,entry_hash经过一定的算法换算,会生成最终的Entry文件名(比如, 7b4fd8111178d5b1_0)。
它们之间的关系,请参考下图:
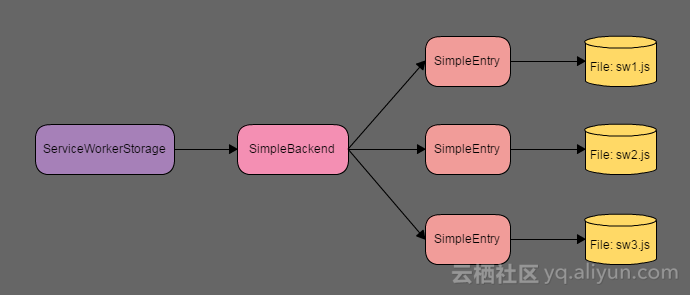
(3)ServiceWorker Script Cache相关对象关系
Script Cache相关对象的关系如下:
1. 单进程模式的Chromium浏览器,比如,基于Chrome Android WebView的U4浏览器,一般会持有一个StoragePartition(对应的存储区为 /data/data/com.UCMobile/app_core_ucmobile)。
2. 一个StoragePartition会持有一个ServiceWorkerContext。
3. ServiceWorkerContextWrapper实现了ServiceWorkerContext,它会持有一个ServiceWorkerContextCore。
4. ServiceWorkerContextCore持有一个ServiceWorkerStorage。
5. ServiceWorkerStorage管理ServiceWorker Script相关的存储,其中使用SimpleBackend存储Script文件本身,使用LevelDB存储ServiceWorker注册信息。
6. ServiceWorkerStorage持有一个disk cache的SimpleBackend作为存储后端。
它们之间的关系,请参考下图:
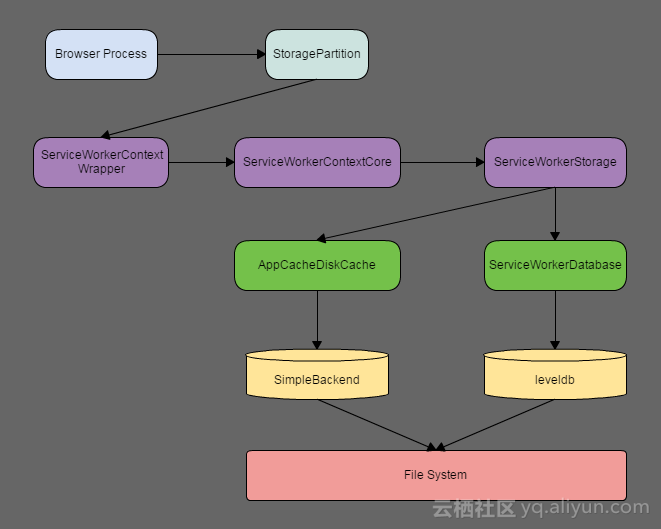
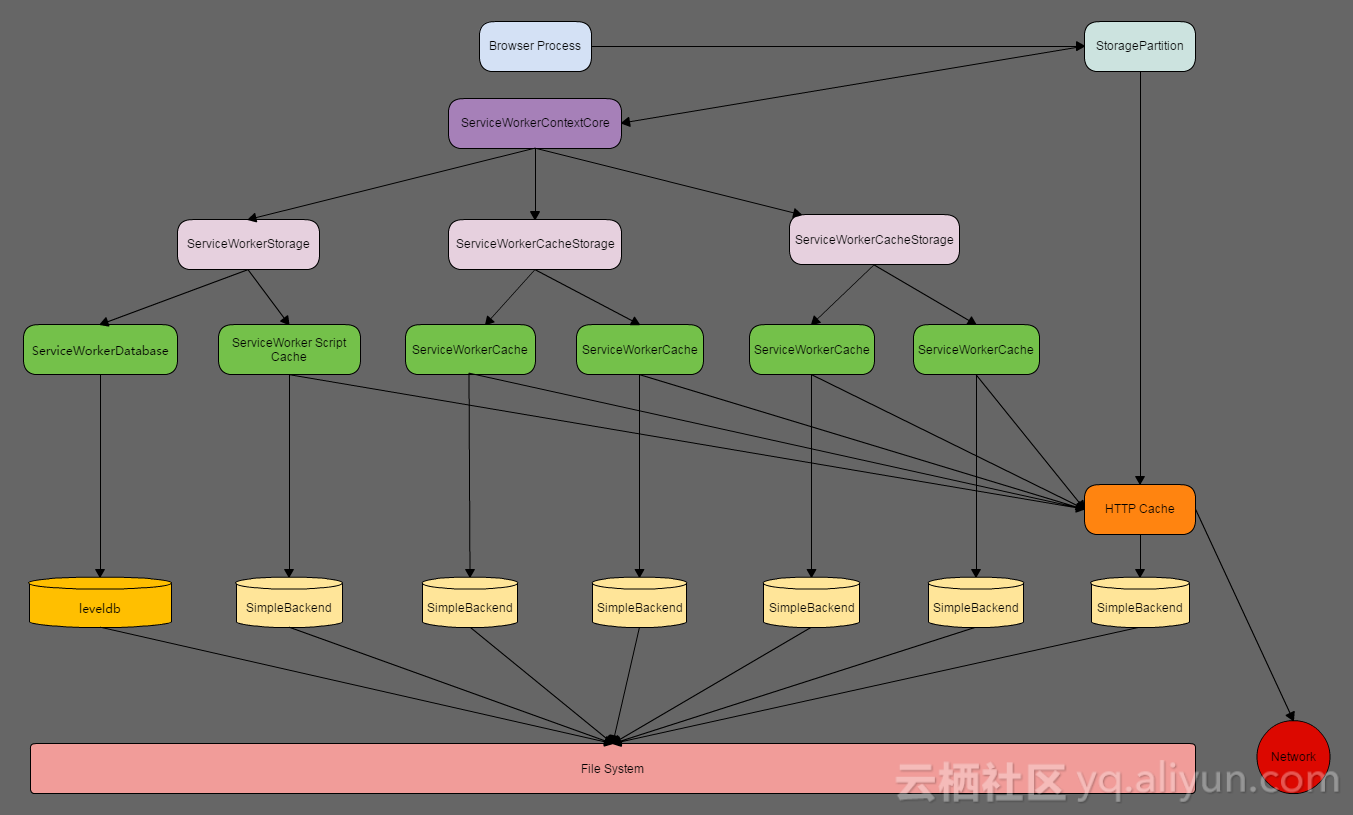
六 各种Cache的关系
前面描述了ServiceWorkerCache和ServiceWorker Script Cache,它们和HTTP Cache是什么关系呢?
一般来说,浏览器Browser进程有一个存储区(StoragePartition),存储区里面的各种缓存的关系如下,
1. 每一个StoragePartition会对应一个ServiceWorkerContextCore和一个HTTPCache的实例。
2. 每一个ServiceWorkerContextCore会有一个ServiceWorkerStorage和多个ServiceWorkerCacheStorage(注:一般一个域名有一个)。
3. 每个ServiceWorkerStorage会有一个ServiceWorkerDatabase和一个ServiceWorker Script Cache。其中,ServiceWorkerDatabase存储所有ServiceWorker的注册信息,ServiceWorker Script Cache存储所有ServiceWorker Script文件。
4. 每个ServiceWorkerCacheStorage可以有多个ServiceWorkerCache。
5. 每个ServiceWorkerCache会有一个SimpleBackend。ServiceWorker Script Cache有一个SimpleBackend。HTTPCache有一个SimpleBackend。
6. ServiceWorker Script Cache和ServiceWorkerCache,在自己的SimpleBackend找不到相应的缓存文件,就会到HTTPCache的SimpleBackend去查找,还找不到就会走网络。
它们之间的关系,请参考下图:
七 综述
上面详细介绍了ServiceWorker CacheStorage和Script Cache存储相关的设计和实现。存储作为浏览器最基础的模块,是非常复杂的,文章只涉及了里面比较基础的内容,更深入的内容需要大家继续学习研究。
理解ServiceWorker相关的存储细节,有什么作用呢,特别是对前端开发者来说,有必要了解这么细节的内容吗?
我们先来看看一些问题,
问题一:ServiceWorker线程启动后为什么可以立刻进入active状态呢?回答:ServiceWorker Script相关的状态信息是持久化到leveldb的数据库的。线程启动后可以立刻从数据库中读取Script的状态(比如,actvie)。
问题二:为什么多进程操作ServiceWorker的缓存会出现问题?回答:ServiceWorker相关缓存的底层存储都使用了系统的文件系统(File System),而文件系统一般是不支持多进程访问的。
问题三: Cache是否可以在不同域名下共享?回答:从上面的分析来看,每个域名(origin)只会有一个ServiceWorkerCacheStorage(对应规范的 CacheStorage),每个ServiceWorkerCacheStorage可以有多个ServiceWorkerCache(对应规范的 Cache)。(1)同一域名下的ServiceWorkerCacheStorage都放在同一目录,存储路径如下,
storage_path: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/CacheStorage/8f9fa7c394456a3f75c7c0aca39d897179ba4003 其中8f9fa7c394456a3f75c7c0aca39d897179ba4003是origin(https://chaoshi.m.tmall.com/)的hash值(使用base::SHA1HashString计算)。
(2)每一个cacheName对应一个ServiceWorkerCache,存储路径如下,
origin: https://chaoshi.m.tmall.com/
cache_path: /data/data/com.UCMobile/app_core_ucmobile/Service Worker/CacheStorage/8f9fa7c394456a3f75c7c0aca39d897179ba4003/7353b21ee437f3877043ae17a5d5ba6395fdbd31其中7353b21ee437f3877043ae17a5d5ba6395fdbd31是cacheName(tm/chaoshi-fresh/4.2.17)的hash值(使用base::SHA1HashString计算)
不同域名下,CacheStorage的目录是不一样的(比如,8f9fa7c394456a3f75c7c0aca39d897179ba4003),它下面Cache的目录就更加不一样了(比如,7353b21ee437f3877043ae17a5d5ba6395fdbd31)。
由于不同域名下 Cache 的目录路径是不一样的,所以是不能共用的。
问题四:同一域名下不同子路径下ServiceWorker使用了同样的cacheName,它们的Cache会存储在同一目录吗?回答:从上面的分析来看,每个域名(origin)只会有一个ServiceWorkerCacheStorage(对应规范的 CacheStorage),每个ServiceWorkerCacheStorage可以有多个ServiceWorkerCache(对应规范的 Cache)。每一个cacheName对应一个ServiceWorkerCache,而且cacheName决定了ServiceWorkerCache的存储目录,即同一域名同一cacheName会使用同样的存储目录。所以,同一域名同一cacheName的Cache会存储在同一目录,这些Cache可以被同一域名下的ServiceWorker共用。注意:前端需要自行管理cacheName,避免不同的ServiceWorker对同一cacheName操作而产生冲突。
上述列举的一些问题,在未了解ServiceWorker Cache存储相关的知识之前,我们很难较好的回答。理解ServiceWorker相关的存储细节,有助于加深理解ServiceWorker的一些功能和特性。
希望大家能深入理解ServiceWorker的存储体系,从而能更好的使用Cache API, 更好的发挥Cache API的优势。
八 参考文档
Implement Cache and CacheStorage for ServiceWorkers - Mozilla
Implement Cache API for ServiceWorker - Chromium
Design of Cache API in Blink
Implementing the Service Worker Cache API in Gecko
PWA系列 - Cache API 的设计与实现相关推荐
- odoo10参考系列--ORM API 一(记录集、环境、通用方法和创建模型)
记录集 版本8.0中新东西: 这个在Odoo8.0中新加的API的页面文档应该是不断向前发展的主要开发API.同时它还提供了关于移植或桥接版本7和更早版本的"旧API"的信息,但没 ...
- 小白学Pytorch 系列--Torch API(1)
小白学Pytorch 系列–Torch API Torch version 1.13 Tensors TORCH.IS_TENSOR 如果obj是PyTorch张量,则返回True. 注意,这个函数只 ...
- DDD系列 实战一 应用设计案例 (golang)
DDD系列 实战一 应用设计案例 (golang) 基于 ddd 的设计思想, 核心领域需要由纯内存对象+基础设施的抽象的接口组成 独立于外部框架: 比如 web 框架可以是 gin, 也可以是 be ...
- RESTful API的设计原则
说在前面,这篇文章是无意中发现的,因为感觉写的很好,所以翻译了一下.由于英文水平有限,难免有出错的地方,请看官理解一下.翻译和校正文章花了我大约2周的业余时间,如有人愿意转载请注明出处,谢谢^_^ P ...
- C#进阶系列——DDD领域驱动设计初探(五):AutoMapper使用
前言:前篇搭建了下WCF的代码,就提到了DTO的概念,对于为什么要有这么一个DTO的对象,上章可能对于这点不太详尽,在此不厌其烦再来提提它的作用: 从安全上面考虑,领域Model都带有领域业务,让Cl ...
- REST API URI 设计的七准则
在了解 REST API URI 设计的规则之前,让我们快速过一下我们将要讨论的一些术语. URI REST API 使用统一资源标识符(URI)来寻址资源.在今天的网站上,URI 设计范围从可以清楚 ...
- 关于API的设计和需求抽象
一,先来谈抽象吧,因为抽象跟后面的API的设计是息息相关的 有句话说的好(不知道谁说的了):计算机科学中的任何问题都可以抽象出一个中间层就解决了. 抽象是指在思维中对同类事物去除其现象的.次要的方面, ...
- 从涂鸦到发布 —— 理解API的设计过程
要想设计出可以正常运行的Web API,对基于web的应用的基本理解是一个良好的基础.但如果你的目标是创建出优秀的API,那么仅凭这一点还远远不够.设计优秀的API是一个艰难的过程,如果它恰巧是你当前 ...
- 优秀的API接口设计原则及方法
一旦API发生变化,就可能对相关的调用者带来巨大的代价,用户需要排查所有调用的代码,需要调整所有与之相关的部分,这些工作对他们来说都是额外的.如果辛辛苦苦完成这些以后,还发现了相关的bug,那对用户的 ...
最新文章
- 图解排序算法(四)之归并排序
- [Informix] unload load
- 【Strurts框架】第一节Action-通配符
- 5.微服务设计 --- 分解单块系统
- 管理感悟:主管加班,员工才会加班
- studio 3T 使用
- mac已安装flash控件_如何在Mac上安装和更新Flash
- Java实验—四子棋进阶
- mac系统连接服务器教程视频教程,mac os教程视频
- 苹果手机升级13无法开机_苹果手机无法开机的解决方法
- 程序员如何提一个好问题?
- exp与expdp区别
- k8s篇-网络-Ingress对象详解
- 吐槽下Excel的十大不规范使用问题
- 四图秒懂BN、LN和IN
- bdd java 界面测试_行为驱动:第一个BDD测试用例
- C++学习之回调函数
- Python3 - Docker部署caffe open_nsfw 图片鉴黄
- 软件测试期末总复习(知识点+习题+答案)
- 利用MATLAB制作基于艾宾浩斯记忆曲线的背单词计划