循环链表之双循环链表
接着上一篇博文,把循环链表里的双循环链表的基本操纵按照我个人的理解进行总结一下。
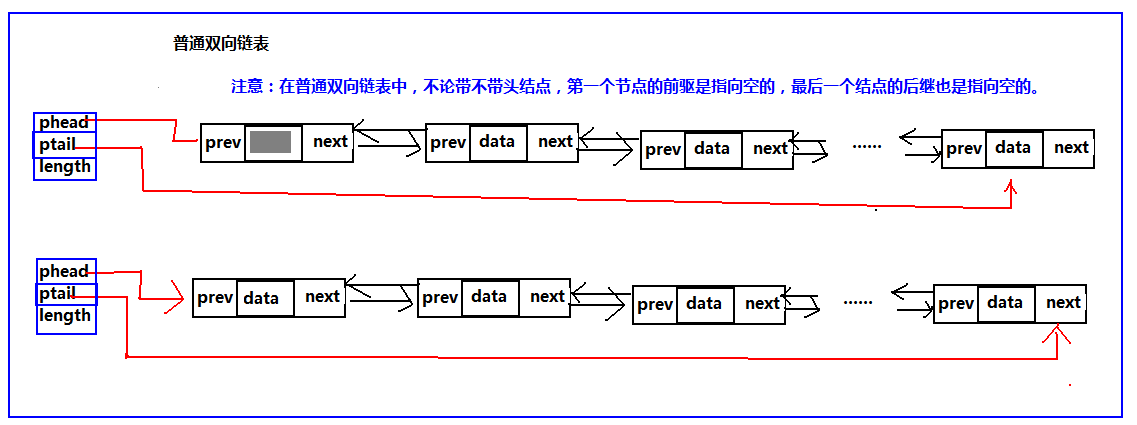
依然沿袭过去的风格,进入双循环链表之前,先提另一种结构,双向链表,先有了双向链表再有了双循环链表。这两种结构和单链表一样都有带头结点和不带头结点之分。我们先来看一下这几种结构的结构图:
双链表
双循环链表
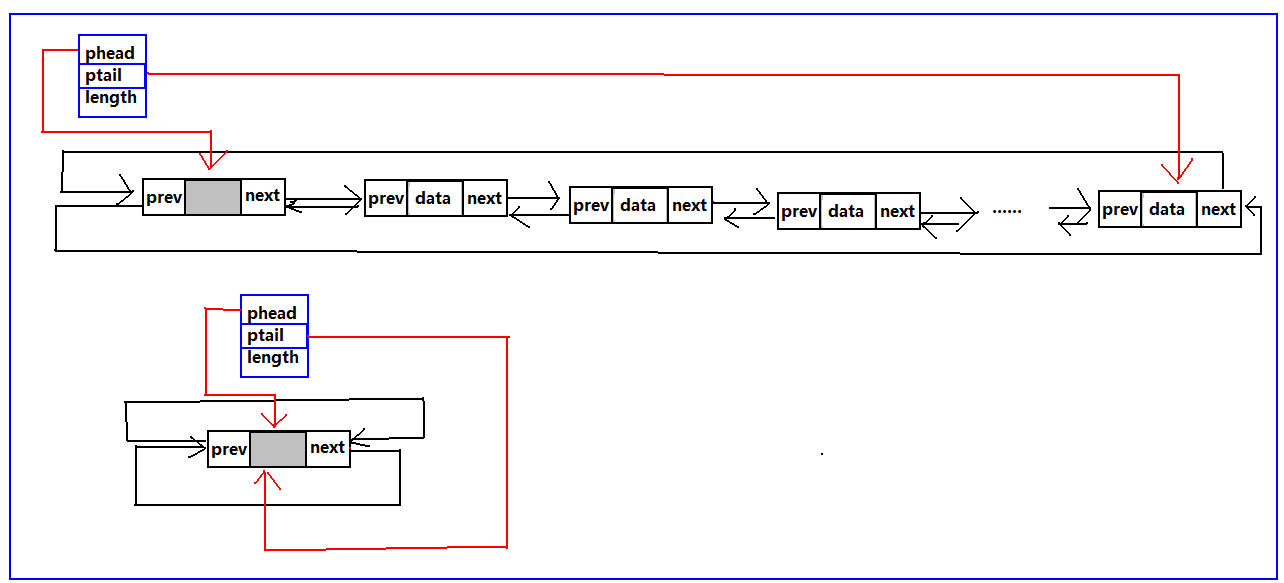
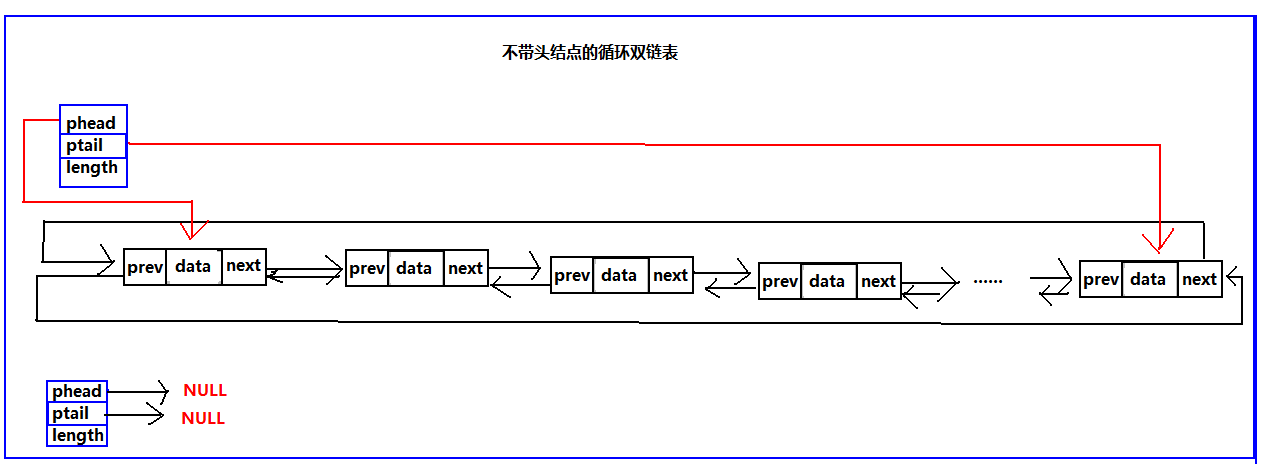
既然单向链表有普通的链表也就是不循环的链表、那么双向链表也一样,也有普通的双向链表和双向循环链表;也有带头结点,不带头结点的结构,这里依然是两种结构都给出算法,但是普通的循环链表不写,这里只写循环双链表。
首先我们先给出结构定义等部分的代码:
typedef int Status;
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int ElemType;
//定义双链表的结点
typedef struct node
{
ElemType data;
struct node *next;
struct node *prev;
}Node;
typedef struct node *SeqNode;
//定义管理链表的结构
typedef struct list
{
struct node *phead;
struct node *ptail;
size_t length;
}List;
//判断结点是否为空,空返回FALSE,不空返回TRUE;
Status IsEmpty(SeqNode p)
{
if(NULL ==p)
{
return FALSE;
}
return TRUE;
}
//构造新结点,写后面的插入函数后会重复使用构造节点的代码,因此将重复代码封装在函数中减少重复代码量
Node *BuyNode(ElemType x)
{
SeqNode s = (Node*)malloc(sizeof(Node));
if(FALSE == IsEmpty(s))
{
printf("out of mommery\n");
return FALSE;
}
s->data = x;
s->next = NULL;
s->prev = NULL;
return s;
}
//查找函数:按照值插入,都需要找到需要插入的位置,为了优化代码,因此将这一部分封装起来。
//查找要插入的结点,因为双循环链表可以通过当前节点找到自己的地址,因此不需用额外的变量保存当前的地址,
//查找成功返回当前结点的地址,查找失败返回最后一个空间的地址
Node *Find(List head,SeqNode s,ElemType x)
{
while(head.length--)
{
if(s->data < x)
{
s = s->next;
continue;
}
return s;
}
return s;
}
//查找函数:按照值删除,都需要找到需要插入的位置,为了优化代码,因此将这一部分封装起来。
//查找要插入的结点,因为双循环链表可以通过当前节点找到自己的地址,因此不需用额外的变量保存当前的地址,
//查找成功返回当前结点的地址,查找失败返回NULL
Node *_Find(List head,SeqNode s,ElemType x)
{
while(head.length--)
{
if(s->data == x)
{
return s;
}
s = s->next;
}
return NULL;
}
初始化
初始化的时候,就是要建立一个空表,上图中已经给出了空表的示意图,那么 初始化就是建立这样一个结构。
//初始化带头结点的双向循环链表,初始化成功返回TRUE,失败FALSE.
Status Init_Yes_SeqNode(List *head)
{
SeqNode s = BuyNode(0);
if(FALSE == IsEmpty(s))
{
printf("初始化失败\n");
return FALSE;
}
head->length = 0;
head->phead = s;
head->ptail = s;
s->next = s;
s->prev = s;
return TRUE;
}
//初始化不带头结点的循环双链表,初始化成功返回TRUE,失败FALSE.
Status Init_No_Head(List *head)
{
head->length = 0;
head->phead = NULL;
head->ptail = NULL;
return FALSE;
}
双循环链表头插
个人一直觉得只要结构弄清了,写代码就好办了。所以我继续给出头插的示意图:
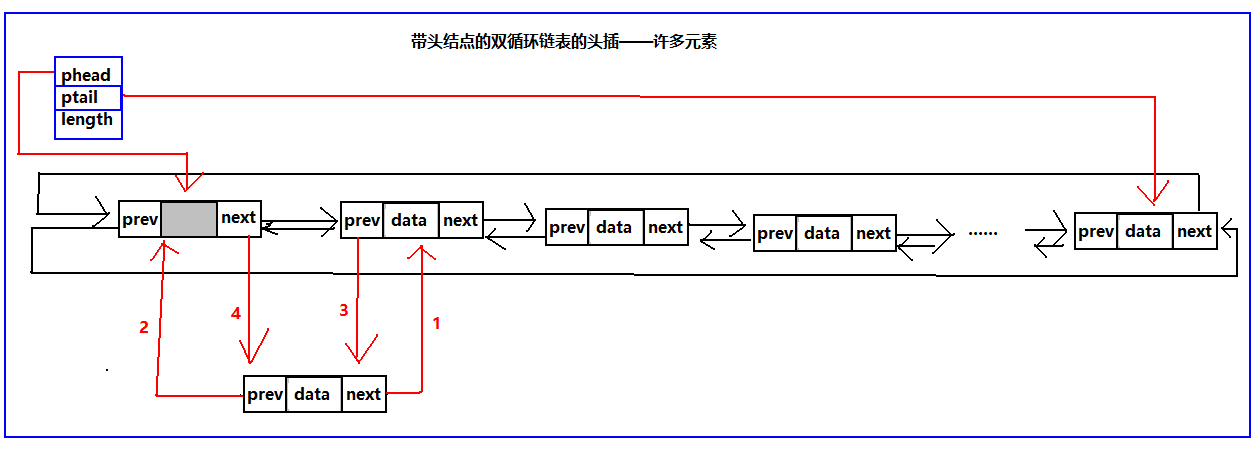

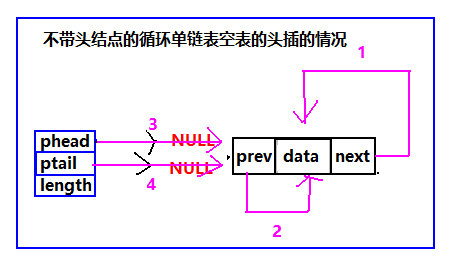
具体代码实现如下
//带头结点的的双循环双链表头插,插入成功返回TRUE,失败返回FALSE
Status Insert_Yes_Head(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
//需要注意这里SeqNode 定义的变量是一个结点类型的指针,BuyNode(x)函数是我之前定义的函数,用来构造结点的,后边不在说明
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
s->next = head->phead->next;
s->prev = head->phead;
s->next->prev = s;
s->prev->next = s;
if(0 == head->length) //处理空表的情况
{
head->ptail = s;
}
head->length++;
return TRUE;
}
//不带头结点的循环双链表头插,插入成功返回TRUE,失败返回FALSE
Status Insert_No_Head(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
if(0 == head->length)
{
s->next = s;
s->prev = s;
head->phead = s;
head->ptail = s;
}
s->next = head->phead;
s->prev = head->ptail;
s->next->prev = s;
s->prev->next = s;
head->phead = s;
head->length++;
return TRUE;
}
双循环链表尾插
我们继续看图:

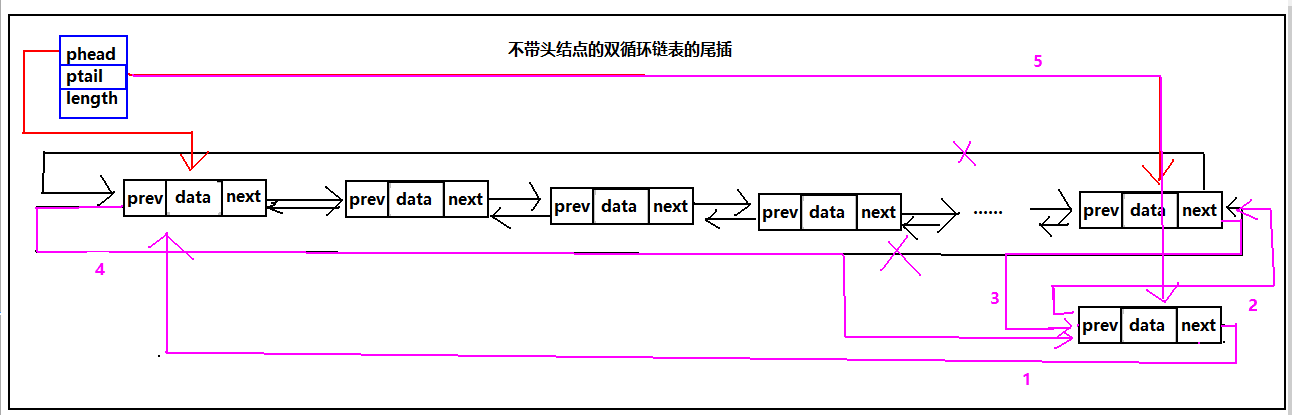

图看明白了,只要按照步骤来写带就可以了。
具体的实现代码如下:
//带头结点的双循环链表的尾插,插入成功返回TRUE,失败返回FALSE
Status Insert_Yes_Tail(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
s->next = head->phead;
s->prev = head->ptail;
s->prev->next = s;
s->next->prev = s;
head->ptail = s;
head->length++;
return TRUE;
}
//不带头结点的双循环链表的尾插,插入成功返回TRUE,失败返回FALSE
Status Insert_No_Tail(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
printf("out of memory\n ");
return FALSE;
}
if(0 == head->length) //处理空链表的情况
{
head->phead = s;
head->ptail = s;
s->next = s;
s->prev = s;
}
s->next = head->phead;
s->prev = head->ptail;
s->next->prev = s;
s->prev->next = s;
head->ptail = s;
head->length++;
return TRUE;
}
双循环链表的按值插(这里是按照从小到大的顺序)
双循环链表按值插入(这里是从小到大的顺序),无论是带头结点还是不带头结点,当是空表的时候,直接插入链表,不需用查找插入位置。
其他情况调用Find函数查找要插入的位置,Find函数的返回值是要插入的地址的后一个元素的地址。由于双循环链表可以同过当前元素找到前一个结点所以Find返回来的地址就可以完成插入操作。当是空表的时候,与头插或者尾插的空表示意图一样,读者返回到前边看,这里不给出示意图,这里只给出有元素的按值插入示意图:
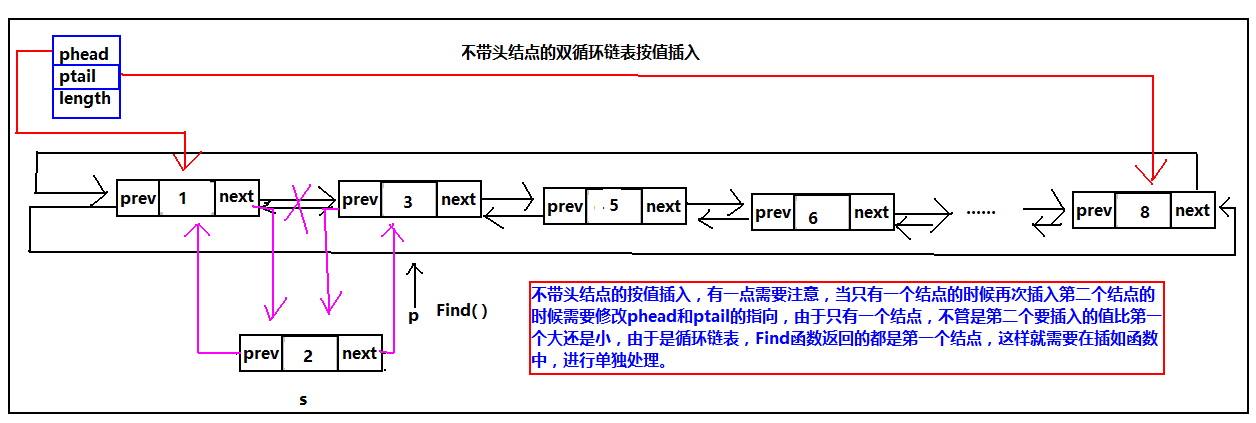
不带头结点的按值插入,有一点需要注意,当只有一个结点的时候再次插入第二个结点的时候需要修改phead和ptail的指向,由于只有一个结点,不管是第二个要插入的值比第一个大还是小,由于是循环链表,Find函数返回的都是第一个结点,这样就需要在插如函数中,进行单独处理。

由于带头结点,所以不会出现不带头结点那种需要单独处理的特殊情况,但是带头节点与不带头结点都有共同的特殊情况,那就是空表时的情况。
具体代码实现:
//带头结点的按值插入,插入成功返回TRUE,失败返回FALSE。
Status Insert_Yse_Value(List *head,ElemType value)
{
SeqNode s = BuyNode(value);
SeqNode p = NULL;
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
if(0 == head->length) //处理空表的情况
{
s->next = head->phead;
s->prev = head->phead;
head->phead->next = s;
head->ptail = s;
head->phead->prev = s;
head->length++;
return TRUE;
}
p = Find(*head,head->phead->next,value); //Find函数,之前定义的,返回要插入的位置的地址。
//这里我提一下这个判断条件,给Find函数传过去的地址,是首元结点的地址,所以当Find()函数返回的地址为head->phead时,说明该元素需要插入到表尾,所以就需要修改ptial的指向。
if(head->phead == p)
{
head->ptail = s;
}
s->next = p;
s->prev = p->prev;
s->prev->next = s;
s->next->prev = s;
head->length++;
return TRUE;
}
//不带头结点的按值插入,插入成功返回TRUE,失败返回FALSE。
Status Insert_No_Value(List *head,ElemType value)
{
SeqNode s = BuyNode(value);
SeqNode p = NULL;
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
if(0 == head->length) //处理空表的情况
{
head->phead = s;
head->ptail = s;
s->next = s;
s->prev = s;
head->length++;
return TRUE;
}
p = Find(*head,head->phead,value); //Find函数,之前定义的,返回要插入的位置的地址。
s->next = p;
s->prev = p->prev;
p->prev = s;
s->prev->next = s;
//重点说一下这一部分,由于没有头结点,所以当Find()函数head->phead时,有可能是往头插,也有可能是往尾插,所以就需要进行判断,当Find()函数的返回值等于头指针时,如果将要插入的值大于首元结点的值,那么就是说,要插入的值是往最后插,即就是需要把ptail修改指向新结点。否则修改phead。
if(head->phead == p)
{
if( s->data > head->ptail->data)
{
head->ptail = s;
}
else
{
head->phead = s;
}
}
head->length++;
return TRUE;
}
循环双链表的头删
不论是带头结点的链表还是不带头结点当链表为空时直接返回FALSE;对于带头结点和不带头结点的双循环链表,都需要注意一个结点的情况,对于带头结点的双循环链表,由于phead始终是指向头结点的,所以,不需用修改头指针的指向,以及最后一个节点的next域除了当删除到最后一个结点时,其他的都不用修改phead、ptail、ptail->next、phead->prev。然而对于不带头结点就需要每次维护循环链表的完整性,修改这些值。我们继续看图:
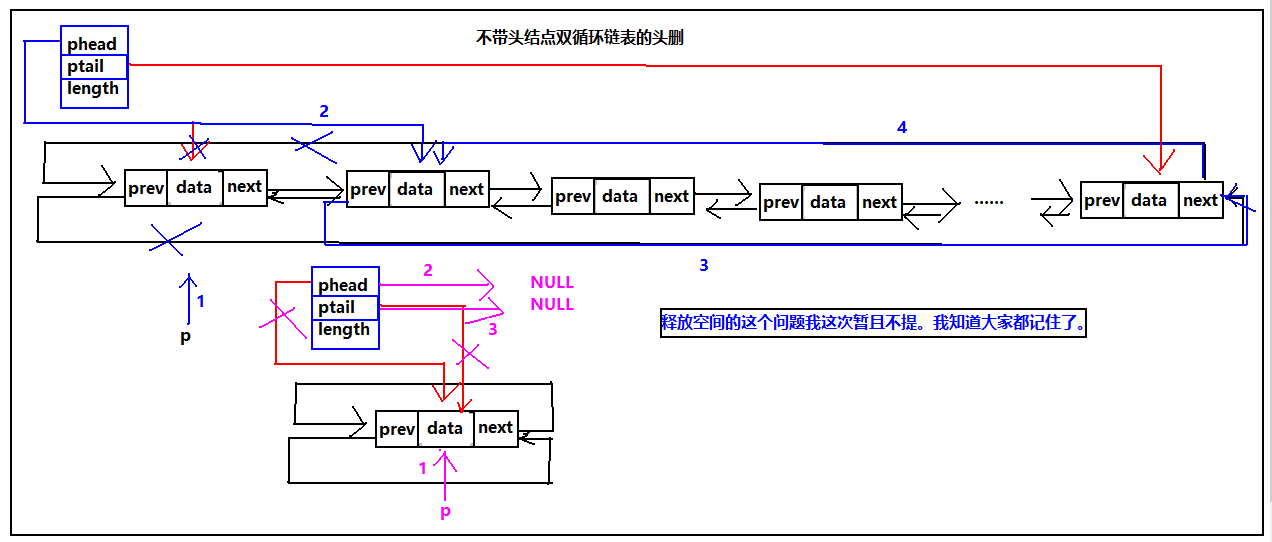
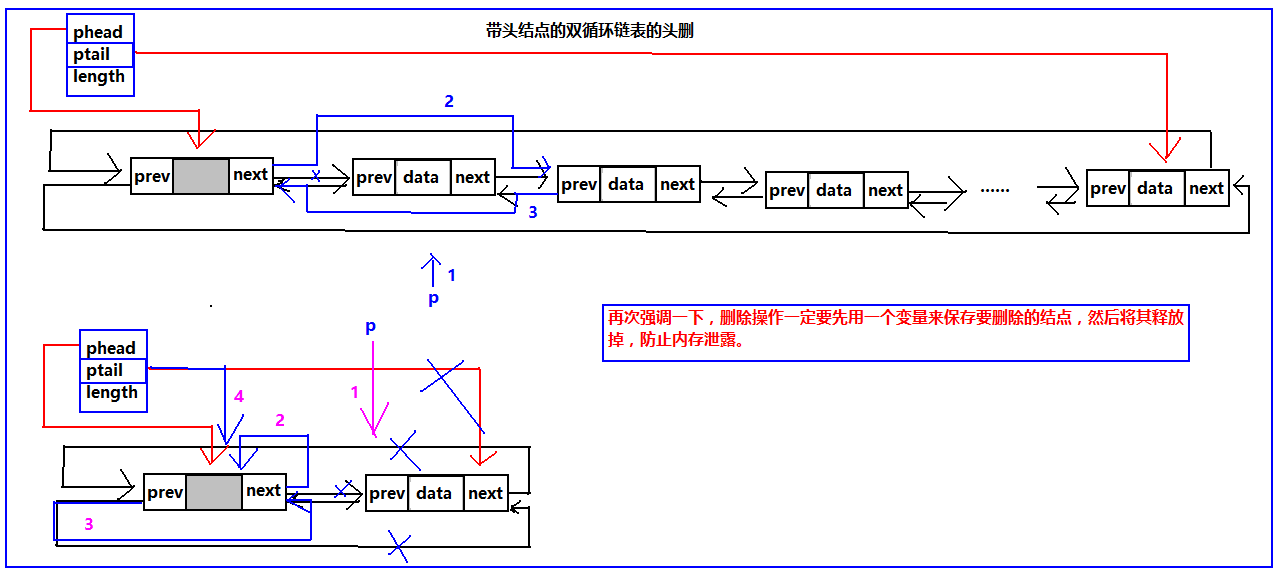
具体代码实现:
//带头结点的循环双链表的头删,删除失败返回FALSE,删除成功返回TRUE.
Status Delite_Yes_Head(List *head)
{
SeqNode p = head->phead->next;
if(head->phead == p)
{
printf("链表中已空,无元素可删\n");
return FALSE;
}
head->phead->next = p->next;
p->next->prev = head->phead;
free(p);
p = NULL;
if(1 == head->length) //处理删除时只有一个结点时的情况
{
head->ptail = head->phead;
}
head->length--;
return TRUE;
}
//不带头结点的头删,删除失败返回FALSE,删除成功返回TRUE.
Status Delite_No_Head(List *head)
{
SeqNode p = head->phead;
if(NULL == p)
{
printf("链表已空,已经无元素可以删除\n");
return FALSE;
}
if(1 == head->length) //处理删除时只有一个结点时的情况
{
head->phead = NULL;
head->ptail = NULL;
}
else //处理一般情况
{
head->phead = p->next;
p->next->prev = head->phead;
head->ptail->next = head->phead; //维护循环链表的完整性
head->phead->prev = head->ptail;
}
free(p);
p = NULL;
head->length--;
return TRUE;
}
循环双链表的尾删
由于尾删每次都需要修改ptail的指向,并且修改头结点的prev的指向,所以对于带头结点的双循环链表,所有情况都是一样的不需用单独处理那种情况,然而对于不带头结点的双循环链表,由于删除最后一个结点后phead和ptail都会指向NULL,所以要对不带头结点的双循环链表的一个结点的情况单独处理。ok,能用图解决的问题觉绝不废话,当然这是玩笑 ,好了我们来看图:
,好了我们来看图:
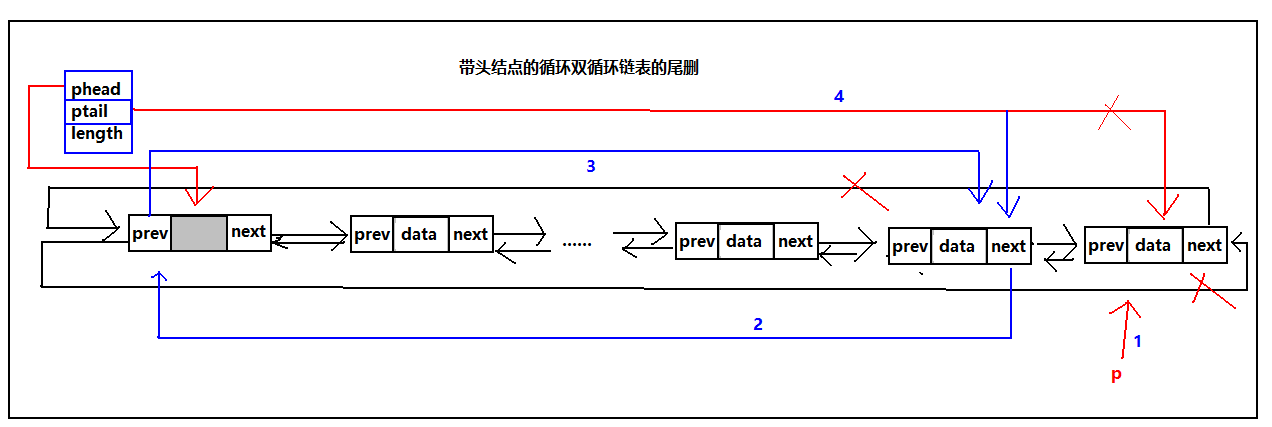

具体代码实现:
//带头结点的尾删,删除成功返回TRUE,失败返回FALSE;
Status Delite_Yes_Tail(List *head)
{
SeqNode p = head->ptail;
if(head->phead == p)
{
printf("链表已空、已经无元素可以删除\n");
return FALSE;
}
p->prev->next = head->phead;
head->phead->prev = p->prev;
head->ptail = p->prev;
free(p);
p = NULL;
head->length--;
return TRUE;
}
//不带头结点的循环双链表的尾删
Status Delite_No_Tail(List *head)
{
SeqNode p = head->ptail;
if(NULL == p)
{
printf("链表已空、已经无元素可以删除\n");
return FALSE;
}
if(1 == head->length) //处理只有一个结点的情况
{
head->phead = NULL;
head->ptail = NULL;
}
else
{
p->prev->next = head->phead;
head->phead->prev = p->prev;
head->ptail = p->prev;
}
free(p); //释放结点空间
p = NULL;
head->length--;
return TRUE;
}
循环双链表的尾删
为了便于操作,这里就要用到之前写的另一个Find函数,注意这两个Find是不一样的这里Find函数名是_Find函数名前有个下划线,这只是从名字上的差别,它的功能也不同_Find函数在链表中搜索一个特定值,如果搜索到返回当前地址,没有搜索到返回NULL。
然后对于带头结点的双循环单链表,就有这么几种情况,1、如果表为空,直接返回不用查找了。2、如果_Find返回NULL,说明表中没有此元素,所以也删除失败,3、再就是找到元素,返回它的地址,将其删除掉释放掉空间,这里需要注意,由于带头结点phead始终指向头结点,绝不需要修改phead的指向,但是当删除ptail指向的结点时就需要修改指向。这个要单独处理。
对于不带头结点的双循环链表。1、同样如果链表为空,不用查找直接返回,删除失败;2、如果_Find返回NULL,说明表中没有此元素,所以也删除失败;3、再就是找到元素,对于不带头结点的链表,又分为四种情况:a、如果phead == ptail 并且 _Find 返回的地址等于他们说明链表只有一个结点,并且要把他删除了;b、如果_Find 返回的地址 == ptail 就需要修改 ptail的指向以及附带的指向;c、如果_Find 返回的地址 == phead 就需要修改phead的指向以及附带的指向。d、再就是一般情况,注意这几个条件判断是有顺序的,如果没有顺序就需要b和c再添加条件。接下来我们继续不看图了,直接上代码,这篇都画了那么多图了,并且这里会出现的情况,也就是之前那么多删除操作的综合,ok,所以没有图咯,不上图了呢,代码呢我就会给出尽可能多的注释。
//带头结点的按照值,删除,这里先不考虑重复值,删除成功返回TRUE,失败返回FALSE;
Status Delite_Yes_Value(List *head,ElemType value)
{
SeqNode p = NULL;
if(0 == head->length) //表为空,不用查找,删除失败,直接返回FALSE
{
printf("链表已空,%d删除失败\n",value);
return FALSE;
}
p = _Find(*head,head->phead->next,value);
if(NULL == p) //查找完成,表中不存在特定值的情况,删除失败,返回FALSE
{
printf("%d删除失败,链表中没有%d\n",value,value);
return FALSE;
}
if(head->ptail == p ) //删除尾结点的情况,就需要修改ptail指向
{
head->ptail = head->ptail->prev;
}
p->prev->next = p->next;
p->next->prev = p->prev;
free(p);
p = NULL;
head->length--;
return TRUE;
}
//不带头结点的按照值删除,这里不考虑重复值,只删除第一个遇到的,删除成功返回TRUE,失败返回FALSE;
Status Delite_No_Value(List *head,ElemType value)
{
SeqNode p = head->phead;
if(FALSE == IsEmpty(p)) //表为空,不用查找,删除失败,直接返回
{
printf("链表已空,%d删除失败\n",value);
return FALSE;
}
p = _Find(*head,head->phead,value);
if(NULL == p) //查找完成,表中不存在特定值的情况,删除失败,返回FALSE
{
printf("%d删除失败,链表中没有%d元素\n",value,value);
return FALSE;
}
//表中元素只有一个并且要删除的元素就是这一个,就需要修改phead 和 ptail的指向
if(head->phead == head->ptail && p == head->phead)
{
head->phead = NULL;
head->ptail = NULL;
}
//删除头结点的情况,就需要修改phead指向,以及附带的其他指向,使其保持循环结构的完整性
else if(head->phead == p)
{
head->phead = head->phead->next;
head->ptail = head->phead;
}
//删除尾结点的情况,就需要修改ptail指向,以及附带的其他指向,使其保持循环结构的完整性
else if(head->ptail == p)
{
head->ptail = head->ptail->prev;
head->phead->prev = head->phead;
}
//一般情况
p->prev->next = p->next;
p->next->prev = p->prev;
free(p);
p = NULL;
head->length--;
return TRUE;
}
循环双链表的打印输出
//打印输出不带头结点的循环双链表中所有元素。
void Show_No(List head)
{
SeqNode p = head.phead;
if(NULL == p)
{
printf("链表为空\n");
return ;
}
if(1 == head.length)
{
printf("%d ",p->data);
printf("\n");
return ;
}
while(head.phead != p->next)
{
printf("%d ",p->data);
p = p->next;
}
printf("%d ",p->data);
printf("\n");
}
//打印输出带头结点的循环双链表中所有元素。
void Show_Yes(List head)
{
SeqNode p = head.phead->next;
while(head.phead != p)
{
printf("%d ",p->data);
p = p->next;
}
printf("\n");
}
写到这里循环链表的基本操作就写完了,当然有几个操作没有写,比如排序,这里先不写,后边会有一个专题是写排序的。还有获取链表长度等大家都很容易实现的就没有写,主要把带头结点不带头结点的插入删除对比的实现。后续会继续完善。好了以上就是双循环链表的基本操作,双循环链表写完了,线性表也就告一段落了。ok,从线性表到链表,我把带头节点不带头结点的基本操作都尽可能多的实现了,我们会发现带头结点的操作会方便了好多。接下来,数据结构继续向前推进
循环链表之双循环链表相关推荐
- 双循环链表(C++)
在C++里,存在多种类型的表,其中有一种线性表,链表则是一种线性表,正如它的名字一样,链表的样子就像是用一条链子串起来的表(这里,我主要讲的是双循环链表) 而用来连接链子的每个环节的是指针,在最基本的 ...
- 数据结构-单向循环链表、双向循环链表、仿真链表
一.单向循环链表: 1.概念: 单向循环链表是单链表的另一种形式,其结构特点是链表中最后一个结点的指针不再是结束标记,而是指向整个链表的第一个结点,从而使单链表形成一个环. 和单链表相比,循环单链表的 ...
- 双链表及其他链式结构:双循环链表的创建算法(尾插法)
请设计一个算法实现用尾插法创建一个双循环链表.调用已写好的函数printlist将该双循环链表中的元素从前向后打印一遍,然后再从后向前打印一遍. #include <stdio.h>#in ...
- 线性表----循环链表和静态链表
1.循环链表 1.1 循环单链表 循环单链表和单链表的区别在于,表中最后一个结点指针不在是null,而是头指针,从而使整个链表形成一个环 此时判断单链表是否为空,条件就是头结点的指针是否等于头指针 此 ...
- 单循环,双向,双循环链表
单向循环链表 相比于单向链表,单向循环链表仅仅是将单向链表的尾节点指向了头节点 #include <stdio.h> #include <stdlib.h>typedef st ...
- 【数据结构与算法】 01 链表 (单链表、双向链表、循环链表、块状链表、头结点、链表反转与排序、约瑟夫环问题)
一.线性表 1.1 概念与特点 1.2 线性表的存储结构 1.3 常见操作 1.4 应用场景 二.链表 2.1 链表简介 2.2 单向链表(单链表) 2.21 基本概念 2.22 单链表基本操作 2. ...
- 基于单向循环链表及内核链表的航班管理系统
该项目使用单向循环链表存放客户端登录信息,用内核链表存放航班信息.通过在单链表中定义指针数组成员来关联两个链表的信息: 功能:有登录及注册界面,如果没有账号则需要注册.登录模块分为普通用户登录以及管理 ...
- c语言josephus问题循环链表,循环单链表(C语言,无头节点,附约瑟夫杀人问题)...
实现以下操作 init 初始化 traverse 遍历 head_add 头追加(),尾追加(尾插法)只需要注释掉函数最后一行的头指针赋值 len 长度 insert 指定位置插入 search 正. ...
- 数据结构之线性表----一文看懂顺序表、单链表、双链表、循环链表
线性表是数据结构中比较基础的内容,不过也是入门的所需要客服的第一个难关.因为从这里开始,就需要我们动手编程,这就对很多同学的动手能力提出了挑战.不过这些都是我们需要克服的阵痛,学习新的知识总是痛苦 ...
最新文章
- Java中的多线程总结
- CSS 行内格式化上下文中的各种高度计算
- python编程实例下载-python网络编程之文件下载实例分析
- hdu5651 xiaoxin juju needs help (多重集的全排列+逆元)
- linux ubuntu下ffmpeg的安装
- suzhou jinjihu lake half round marathon
- 肉肉谈对需求设计的想法--到底是功能驱动界面?还是界面驱动功能?
- 冒泡排序-----选择排序1-2
- 整合MyBatis---SpringBoot
- 设计模式-结构型模式-装饰模式
- asp.net mvc 包含了一个 html 的助手类在哪里,c# - 在App_Code中使用@HTML的ASP.NET MVC Razor Helper - 堆栈内存溢出...
- 【全网最全的博客美化系列教程】08.自定义地址栏Logo
- H5 37-背景缩写
- discuz开发,登录次数过多,锁定解决方法
- SVN创建分支与合并(命令与界面)
- [C#]文件中转站程序及源码
- 利用C++求解一元二次方程
- 分部积分法的快速运算:表格法
- JAVA POI导出EXCEL设置自定义样式(线框加粗,合并指定行,合计求和,冻结行)
- Cocoapods的安装 简单教程(有待完善)