基于Elastic Search的搜索广告召回方案
如果你对搜索广告,竞价排序,或者Elastic Search技术感兴趣,读读这篇文章或许多少能有所收获。作者不是计算广告领域的专家,如果作为读者的你是这个方面的专家发现本文浅薄,希望留下你宝贵的意见。
因为ES版本升级很快,很多功能支持程度也伴随版本的升级而改变,本文内容基于Elastic Search 5.4.1实现。
什么是搜索广告
举个最常见的例子,当我们在淘宝上购物搜索时候,例如输入“猫粮”
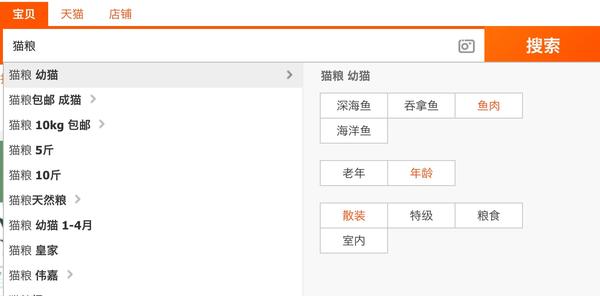
在搜索结果的第一个,你会看到有个小小的广告二字,这条返回结果就是搜索广告的“杰作”了。

不同的运营平台会提供给商家后台采买关键词,设置出价和匹配模式等。当用户发起搜索时,根据规则,首先召回采买关键词的商家,然后对这些召回商家排序,返回广告商家。
一般来说,这类广告的收费模式都是按照点击收费(CPC),所以排序肯定不能按照单纯的价高者得。因为即使商家出价再高,但是由于相关度和商家质量问题,而无人点击,平台依然没有任何营收,既浪费了平台流量,也没有给商家贡献转化。普遍来说,对于CPC广告,排序一般基于商户出价Bid * 预估CTR(点击率)。排序在计算广告中占据着举足轻重的地位,提高AUC,CTR等指标,也让无数青年才俊掉了不少头发。不过排序并不是本文介绍的重点,如果你感兴趣,可以搜索LR,GBDT,FM,OCPC等关键词,相信你会有很多的收获。如果有机会,笔者也希望可以写机器学习相关的文章,本文主要介绍搜索广告的召回部分的实现。
文档
每一条商户关键词的出价是一个文档,JSON描述如下:
{"id":123456"weight": 201, "biding": "天润酸奶", "lon": 117.60715739693345, "shopId": 400, "matchMode": "SpitContain", "lat": 27.555006197000644, "open": true
}
其中 id 代表推广计划ID,weight 是商家出价,biding 是商户出价的关键词,lon,lat 描述商户地理坐标,open 描述店铺当前状态。matchMode 是商户设置的匹配模式,匹配模式 的含义是,只有在用户搜索词和出价的关键词 之间的匹配满足一定条件的时候,才会生效(不能仅仅一直想完全一样的情况哦)。在不同业务场景下,文档需要的数据是不同的。
笔者提供了一个简单的Python程序可以生成一些测试文档,并索引到ES中,需要的朋友可以到这里下载 测试数据生成器,该程序会生成50万商家的2500万条采买记录,关键词词库含有2万条关键词。
匹配模式
笔者定义了四种搜索词和关键词匹配模式:
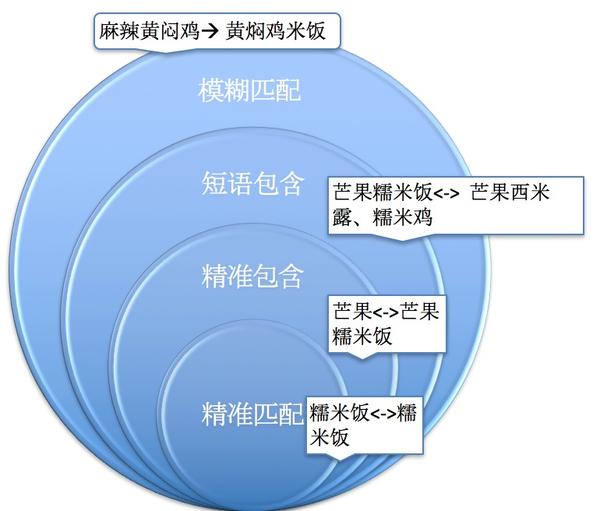
具体定义如下:
设定 Q 为用户搜索(Query),K 为商户出价的关键词(Keyword)
精准匹配:Q = K
例:糯米饭(Q) = 糯米饭(K)
精准包含:Q 是 K的子串
例:芒果(Q)= 芒果糯米饭(K)
短语包含:T 是 K的子串,其中 T 是 Q 的任意分词词项(Term)
例:芒果糯米饭(Q) = 芒果西米露(K),芒果糯米饭 的分词词项:芒果、糯米饭,其中 芒果 是关键词 芒果西米露 的子串。
模糊匹配:S是K的子串,其中S是T的同义词
例:麻辣黄闷鸡(Q)= 黄焖鸡米饭(K),麻辣黄闷鸡 分词为:麻辣、黄闷鸡,黄闷鸡的同义词为黄焖鸡(S),而S是K的子串。
关于匹配模式的工作模式可以举个例子
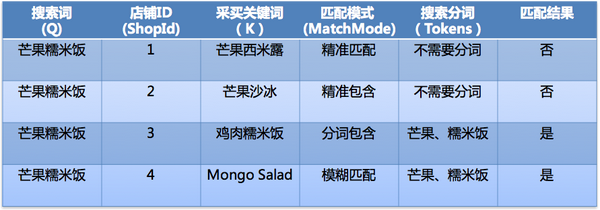
所以召回要解决两个问题:
a. 支持基于关键词文档的全文检索
b. 支持匹配模式
基于Elastic Search的搜索召回
召回的所有逻辑也可以使用Lucene拓展编写,好处是可以高度整合业务逻辑到索引,缺点是开发成本高。本文将采用Elastic Search作为搜索召回引擎,ES的默认配置,远远不能实现我们的需要的功能,所以需要做一些额外工作。
a. 中文和行业词库的扩展(本文采用美食词汇)
b. 同义词模糊匹配支持
c. 基于匹配模式的过滤器
1. 中文索引和行业词库扩展
这里我们使用到了大名鼎鼎的 IK - Analyzer 插件,IK的目录中存在
config/custom/mydict.dic
文件,把相关的行业词汇放入其中即可。验证如下:
curl -XGET 'localhost:9200/_analyze?pretty' -d '{ "analyzer":"ik_smart",
"text":"附近哪里有黄焖鸡米饭或者腾冲大救驾"
}'
分词结果如下
{"tokens" : [#省略若干.......{"token" : "黄焖鸡米饭","start_offset" : 5,"end_offset" : 10,"type" : "CN_WORD","position" : 3},{"token" : "或者","start_offset" : 10,"end_offset" : 12,"type" : "CN_WORD","position" : 4},{"token" : "腾冲大救驾","start_offset" : 12,"end_offset" : 17,"type" : "CN_WORD","position" : 5}]
}
可见 黄焖鸡米饭 和 腾冲大救驾 已经作为单独的词汇被识别出来了。
2. 同义词匹配支持
ES是支持同义词逻辑的,不过需要一些配置,这个配置可以在创建索引的时候指定。
curl -XPUT 'http://localhost:9200/search_ad_index' -d '{ "settings": { "analysis": { "filter": { "my_synonym_filter": { "type": "synonym",
"synonyms_path":"analysis/synonym.txt"
}
},
"analyzer": { "ik_syno": { "type":"custom",
"tokenizer": "ik_smart",
"search_analyzer": "ik_smart",
"filter": [
"lowercase",
"my_synonym_filter"
]
}
}
}
}
}'
同时还要把同义词库定义在如下文件
config/analysis/synonym.txt
为了说明问题,本文定义了一个很简单的同义词库
黄闷鸡,黄梦鸡,huangmenjimifan,huangmenji,黄焖鸡,黄焖鸡米饭
Dongyingong,冬阴功,冬阴功汤
然后在 biding 字段,配置支持同义词的Analyzer
curl -XPOST 'http://localhost:9200/search_ad_index/shop_keyword/_mapping' -d '
{ "properties": { "biding": { "type": "text",
"analyzer": "ik_syno",
"search_analyzer": "ik_syno"
}
}
}'
现在我们索引一条文档,然后测试一下同义词是否生效
curl -XPOST 'localhost:9200/search_ad_index/shop_keyword/1' -d '{ "weight" : 201,
"biding" : "黄焖鸡米饭",
"lon" : 117.60715739693345,
"shopId" : 400,
"matchMode" : "SpitContain",
"lat" : 27.555006197000644,
"open" : true
}'
搜索脚本如下:
curl -XPOST 'localhost:9200/search_ad_index/shop_keyword/_search?pretty' -d '{ "query":{ "match":{ "biding":"huangmenji"
}
}
}'
召回结果如下:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"failed" : 0},"hits" : {"total" : 1,"max_score" : 0.58874476,"hits" : [{"_index" : "search_ad_index","_type" : "shop_keyword","_id" : "1","_score" : 0.58874476,"_source" : {"weight" : 201,"biding" : "黄焖鸡米饭","lon" : 117.60715739693345,"shopId" : 400,"matchMode" : "SpitContain","lat" : 27.555006197000644,"open" : true}}]}
}
我们在同义词库定义了,huangmenji = 黄焖鸡 = 黄焖鸡米饭
用huangmenji做搜索词,召回了 biding = 黄焖鸡米饭 的文档,说明同义词已经被ES支持了。
3. 基于匹配模式的过滤器
既然ES已经支持了同义词和行业词汇分词,那么已经满足了匹配模式中最广泛的模糊匹配,基于模糊匹配的返回结果,把不满足匹配模式的文档过滤掉,就获得满足业务的结果了。笔者用一个例子说明 多匹配模式 的支持过程。
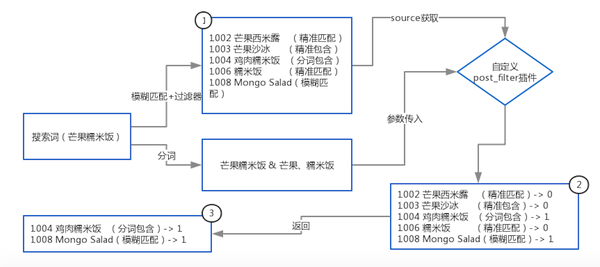
首先,使用ES的模糊搜索,获得所有匹配的文档,如 标记①所示,简化文档记录为:
商户ID,商户出价关键词,商户设置的匹配模式。例如第一条记录商户1002,Bid了关键词芒果西米露,但是只有在用户搜索和关键词精准匹配的时候,才生效。
基于①返回的文档,可以在内存中过滤,只不过笔者不希望ES返回太多文档,增加网络负担也可能将有用的文档截取掉,所以笔者用ES的Java Plugin实现了一个 PostFilter,可以在 ES 匹配文档后返回结果前,过滤掉不符合规则的文档,基于性能的考虑使用Java语言实现原生的Plugin。
这个PostFilter需要传入用户搜索 ,和基于用户搜索的分词列表
,他是分词项
的数组。PostFilter的伪代码如下:
IF doc.matchMode is 精准匹配 Thenreturn Q equalTo doc.biding
ELSE IF doc.matchMode is 精准包含 Then return doc.biding substring Q
ELSE IF doc.matchMode is 分词包含 Then return doc.biding substring T
ELSEreturn true
②展示了过滤器工作的结果,那些不满足商户匹配模式的关键词条目被打分为 0, 将被过滤掉,而满足条件的被打分 1, 将在结果中保留。
③是经过过滤器后,返回的最终文档集合。
笔者把 PostFilter 的代码托管在 GitHub 上,可以在这里找到: MatchModePostFilter 需要实验的朋友,可以 Maven package 生成 .zip 文件,解压后放入 ES_HOME/plugins目录下即可生效。
将可以实现功能的上文所云,浓缩到一条搜索脚本如下:
POST /search_ad_index/_search?pretty
{"size":100,"query": {"bool": {"must": {"match": {"biding": "麻辣香锅冒菜" #用户查询}}, "filter": [ #其他业务过滤器,可以自己定义{"range": {"lat": {"gt": 31.5, "lt": 32.6}}}, {"range": {"lon": {"gt": 118.3, "lt": 119.4}}}, {"term": {"open": true}}]}}, "post_filter": {"script": {"script": {"inline": "match_mode_scoring", #指定原生脚本名"lang": "native", "params": {"query": "麻辣香锅冒菜", #用户查询"tokens": "麻辣香锅;冒菜" #用户查询分词}}}}
}
部分返回结果如下:
{"_index": "fuzzy_search_ad","_type": "shop_keyword","_id": "1","_score": 12.347956,"_source": {"weight": 139,"biding": "麻辣香锅冒菜","lon": 118.31,"shopId": 122,"matchMode": "Exact","lat": 31.51,"open": true}},{"_index": "fuzzy_search_ad","_type": "shop_keyword","_id": "2660337","_score": 6.4009247,"_source": {"weight": 338,"biding": "蛋蛋麻辣香锅","lon": 119.21255552940255,"shopId": 53206,"matchMode": "Fuzzy","lat": 31.71452073144111,"open": true}},{"_index": "fuzzy_search_ad","_type": "shop_keyword","_id": "3895216","_score": 6.3706484,"_source": {"weight": 196,"biding": "蛋蛋麻辣香锅","lon": 118.58495088376293,"shopId": 77904,"matchMode": "Fuzzy","lat": 31.94751527254444,"open": true}}
结束语
到这里,关于搜索广告文档召回就介绍到这里了。基于ES或者Lucence(ES的倒排索引实现)我们可以很轻易的实现倒排索引,如果深入挖掘还能实现很多制定化的需求。
传送门:https://zhuanlan.zhihu.com/p/28390635
基于Elastic Search的搜索广告召回方案相关推荐
- 基于Elastic Search的推荐系统“召回”策略
当我们打开一个资讯APP刷新闻时,有没有想过,系统是如何迅速推送给我们想看的内容?资讯APP背后有一个巨大的内容池,系统是如何判断要不要将某条资讯推送给我们的呢?这就是今天想跟大家探讨的问题--推荐系 ...
- 计算广告(3)----搜索广告召回匹配
一.搜索广告形态 1.平台算法主要分两部分:召回匹配 + 推荐排序 (1)召回匹配: 智能创意优化[广告配图(图案增强等).静态动态文案生成(文案融合).样式橱窗优化.信息流等] 扩触发(即召回):搜 ...
- Elastic Search 深入搜索
全文搜索 match 使用operator : and提升精度 GET /my_index/my_type/_search {"query": {"match" ...
- 从二值检索到层次竞买图——让搜索广告关键词召回焕然新生
丨目录: · 背景 · 广告改写的历史与新目标 · 从两阶段到一段式:二值海选 · 从一段式到联合召回:层次竞买图 · 关键词召回的业务思考 本文主要分享过去一年我们在搜索广告召回的传统领域--关键词 ...
- 【AI in 美团】深度学习在美团搜索广告排序的应用实践
转自:https://mp.weixin.qq.com/s/9Fcj5lO-JPfFVnRSSM_56w [AI in 美团]深度学习在美团搜索广告排序的应用实践 AI(人工智能)技术已经广泛应用于美 ...
- Elastic Search Java API(文档操作API、Query DSL查询API)、es搜索引擎实战demo
elastic search实战小demo:https://github.com/simonsfan/springboot-quartz-demo,分支:feature_es 之前在 Elastic ...
- 计算广告及搜索广告简介
序言: 本来打算写文章介绍一下业界内广告搜索引擎的业务及架构的,但是觉得应该先介绍一下整个搜索广告的大背景的,所以周末学习了一下斯坦福大学的Introduction to Computational ...
- 北京内推 | 京东搜索广告算法团队招聘NLP算法实习生
合适的工作难找?最新的招聘信息也不知道? AI 求职为大家精选人工智能领域最新鲜的招聘信息,助你先人一步投递,快人一步入职! 京东 京东商业提升事业部(原广告部)成立于2014年初,承担着京东全站流量 ...
- CIKM 2021 | 基于异质图学习的搜索广告关键词推荐
丨目录: - 摘要 - 背景 - 问题定义 - 方法 - 在离线实验 - 结语 - 相关文献 ▐ 摘要 近年来,在线广告在消费者侧的大量工作受到了广泛关注,对广告平台来说,广告主营销优化工作在广告系统 ...
- CIKM 2021 | 基于异质图学习的搜索广告关键词推荐模型及实践
猜你喜欢 0.[免费下载]2021年11月热门报告盘点1.如何搭建一套个性化推荐系统?2.从零开始搭建创业公司后台技术栈3.全民K歌推荐系统算法.架构及后台实现4.微博推荐算法实践与机器学习平台演进5 ...
最新文章
- python pip 安装报错 error in setup command: use_2to3 is invalid. 解决方法
- 什么是 CMS - Content Management System
- .NET的Snk使用方法
- unity应用开发实战案例_「简历」STAR法则的实战应用,附手把手教学案例
- 关于idea的git账号与电脑的git账号不一致的问题。已解决!
- 性能提升120倍!滴滴东北大学提出自动结构化剪枝压缩算法框架
- 弱电施工流程及规范(二)
- this is a test
- 论文投稿,遭遇身份歧视该咋办?
- StyTr^2:Image Style Transfer with Transformers
- 【图数据库】Neo4j下载、安装、配置、服务注册(国内ftp快速下载)
- python 画图十大工具_Python画图工具matplotlib的使用(图形并茂)
- 计算机安装系统后鼠标无法使用,重装系统后鼠标不能用
- 网络上的计算机无权限访问权限,权限,教您怎么解决无internet访问权限
- mindspore详解
- 浅谈机器视觉的相机,镜头选型和打光
- 昔日无痕,沧桑有迹-魔幻般的2020
- Perfect Triples(思维/规律)
- d盘莫名其妙被占空间 win10_Win10系统C盘空间突然爆满的解决方法
- 照度/感光度(Lux)