Linear Counting算法
在上文中,我们知道传统的精确基数计数算法在数据量大时会存在一定瓶颈,瓶颈主要来自于数据结构合并和内存使用两个方面。因此出现了很多基数估计的概率算法,这些算法虽然计算出的结果不是精确的,但误差可控,重要的是这些算法所使用的数据结构易于合并,同时比传统方法大大节省内存。
在这一篇文章中,我们讨论Linear Counting算法。
简介
Linear Counting(以下简称LC)在1990年的一篇论文“A linear-time probabilistic counting algorithm for database applications”中被提出。作为一个早期的基数估计算法,LC在空间复杂度方面并不算优秀,实际上LC的空间复杂度与上文中简单bitmap方法是一样的(但是有个常数项级别的降低),都是O(Nmax)O(Nmax),因此目前很少单独使用LC。不过作为Adaptive Counting等算法的基础,研究一下LC还是比较有价值的。
基本算法
思路
LC的基本思路是:设有一哈希函数H,其哈希结果空间有m个值(最小值0,最大值m-1),并且哈希结果服从均匀分布。使用一个长度为m的bitmap,每个bit为一个桶,均初始化为0,设一个集合的基数为n,此集合所有元素通过H哈希到bitmap中,如果某一个元素被哈希到第k个比特并且第k个比特为0,则将其置为1。当集合所有元素哈希完成后,设bitmap中还有u个bit为0。则:
n^=−mlogumn^=−mlogum
为n的一个估计,且为最大似然估计(MLE)。
示意图如下:
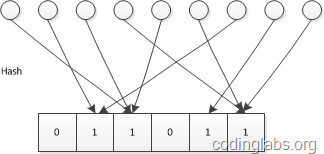
推导及证明
(对数学推导不感兴趣的读者可以跳过本节)
由上文对H的定义已知n个不同元素的哈希值服从独立均匀分布。设AjAj为事件“经过n个不同元素哈希后,第j个桶值为0”,则:
P(Aj)=(1−1m)nP(Aj)=(1−1m)n
又每个桶是独立的,则u的期望为:
E(u)=∑mj=1P(Aj)=m(1−1m)n=m((1+1−m)−m)−n/mE(u)=∑j=1mP(Aj)=m(1−1m)n=m((1+1−m)−m)−n/m
当n和m趋于无穷大时,其值约为me−n/mme−n/m
令:
E(u)=me−n/mE(u)=me−n/m
得:
n=−mlogE(u)mn=−mlogE(u)m
显然每个桶的值服从参数相同0-1分布,因此u服从二项分布。由概率论知识可知,当n很大时,可以用正态分布逼近二项分布,因此可以认为当n和m趋于无穷大时u渐进服从正态分布。
因此u的概率密度函数为:
f(x)=1σ2π√e−(x−μ)22σ2f(x)=1σ2πe−(x−μ)22σ2
由于我们观察到的空桶数u是从正态分布中随机抽取的一个样本,因此它就是μμ的最大似然估计(正态分布的期望的最大似然估计是样本均值)。
又由如下定理:
设f(x)f(x)是可逆函数x^x^是xx的最大似然估计,则f(x^)f(x^)是f(x)f(x)的最大似然估计。
且−mlogxm−mlogxm是可逆函数,则n^=−mlogumn^=−mlogum是−mlogE(u)m=n−mlogE(u)m=n的最大似然估计。
偏差分析
下面不加证明给出如下结论:
Bias(n^n)=E(n^n)−1=et−t−12nBias(n^n)=E(n^n)−1=et−t−12n
StdError(n^n)=m√(et−t−1)1/2nStdError(n^n)=m(et−t−1)1/2n
其中t=n/mt=n/m
以上结论的推导在“A linear-time probabilistic counting algorithm for database applications”可以找到。
算法应用
在应用LC算法时,主要需要考虑的是bitmap长度m的选择。这个选择主要受两个因素的影响:基数n的量级以及容许的误差。这里假设估计基数n的量级大约为N,允许的误差为ϵϵ,则m的选择需要遵循如下约束。
误差控制
这里以标准差作为误差。由上面标准差公式可以推出,当基数的量级为N,容许误差为ϵϵ时,有如下限制:
m>et−t−1(ϵt)2m>et−t−1(ϵt)2
将量级和容许误差带入上式,就可以得出m的最小值。
满桶控制
由LC的描述可以看到,如果m比n小太多,则很有可能所有桶都被哈希到了,此时u的值为0,LC的估计公式就不起作用了(变成无穷大)。因此m的选择除了要满足上面误差控制的需求外,还要保证满桶的概率非常小。
上面已经说过,u满足二项分布,而当n非常大,p非常小时,可以用泊松分布近似逼近二项分布。因此这里我们可以认为u服从泊松分布(注意,上面我们说u也可以近似服从正态分布,这并不矛盾,实际上泊松分布和正态分布分别是二项分布的离散型和连续型概率逼近,且泊松分布以正态分布为极限):
当n、m趋于无穷大时:
Pr(u=k)=(λkk!)e−λPr(u=k)=(λkk!)e−λ
因此:
Pr(u=0)<e−5=0.007Pr(u=0)<e−5=0.007
由于泊松分布的方差为λλ,因此只要保证u的期望偏离0点5–√5的标准差就可以保证满桶的概率不大约0.7%。因此可得:
m>5(et−t−1)m>5(et−t−1)
综上所述,当基数量级为N,可接受误差为ϵϵ,则m的选取应该遵从
m>β(et−t−1)m>β(et−t−1)
其中β=max(5,1/(ϵt)2)β=max(5,1/(ϵt)2)
下图是论文作者预先计算出的关于不同基数量级和误差情况下,m的选择表:
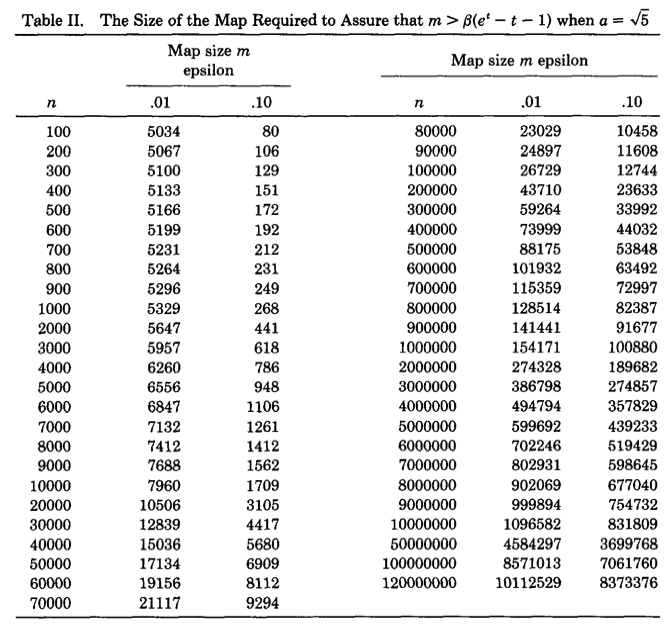
可以看出精度要求越高,则bitmap的长度越大。随着m和n的增大,m大约为n的十分之一。因此LC所需要的空间只有传统的bitmap直接映射方法的1/10,但是从渐进复杂性的角度看,空间复杂度仍为O(Nmax)O(Nmax)。
合并
LC非常方便于合并,合并方案与传统bitmap映射方法无异,都是通过按位或的方式。
小结
这篇文章主要介绍了Linear Counting。LC算法虽然由于空间复杂度不够理想已经很少被单独使用,但是由于其在元素数量较少时表现非常优秀,因此常被用于弥补LogLog Counting在元素较少时误差较大的缺陷,实际上LC及其思想是组成HyperLogLog Counting和Adaptive Counting的一部分。
在下一篇文章中,我会介绍空间复杂度仅有O(log2(log2(Nmax)))O(log2(log2(Nmax)))的基数估计算法LogLog Counting。
Linear Counting算法相关推荐
- 解读Cardinality Estimation算法(第二部分:Linear Counting)
在上一篇文章中,我们知道传统的精确基数计数算法在数据量大时会存在一定瓶颈,瓶颈主要来自于数据结构合并和内存使用两个方面.因此出现了很多基数估计的概率算法,这些算法虽然计算出的结果不是精确的,但误差可控 ...
- MATLAB实现DLT(Direct Linear Transform)算法
MATLAB实现DLT(Direct Linear Transform)算法 转载备用 作者:My_CSDN_Bo_Ke 来源:CSDN 原文:https://blog.csdn.net/weix ...
- C#实现DLT直接线性变换(Direct Linear Transform)算法
C#实现DLT直接线性变换(Direct Linear Transform)算法 参考资料: 1.武大版<工业测量技术与数据处理>P100-P106 2.转载博文--MATLAB实现DLT ...
- DLT(Direct Linear Transform)算法
一.定义 直接线性变换解法是建立像点的"坐标仪坐标"和相应物点的物方空间坐标直接的线性关系的解法. 直接线性变换解法的特点: 不归心.不定项 不需要内外方位元素的起始值 物方空间需 ...
- 解读Cardinality Estimation算法(第三部分:LogLog Counting)
上一篇文章介绍的Linear Counting算法相较于直接映射bitmap的方法能大大节省内存(大约只需后者1/10的内存),但毕竟只是一个常系数级的降低,空间复杂度仍然为O(Nmax)O(Nmax ...
- Cardinality_estimate
Cardinality estimate in short 基数计数(cardinality counting)是实际应用中一种常见的计算场景,在数据分析.网络监控及数据库优化等领域都有相关需求.精确 ...
- 解读Cardinality Estimation算法(第四部分:HyperLogLog Counting)
在前一篇文章中,我们了解了LogLog Counting.LLC算法的空间复杂度为O(log2(log2(Nmax))),并且具有较高的精度,因此非常适合用于大数据场景的基数估计.不过LLC也有自己的 ...
- 神奇的HyperLogLog算法
2019独角兽企业重金招聘Python工程师标准>>> 原文链接:http://rainybowe.com/blog/2017/07/13/%E7%A5%9E%E5%A5%87%E7 ...
- 解读Cardinality Estimation算法(第一部分:基本概念)
基数计数(cardinality counting)是实际应用中一种常见的计算场景,在数据分析.网络监控及数据库优化等领域都有相关需求.精确的基数计数算法由于种种原因,在面对大数据场景时往往力不从心, ...
- HyperLogLog 算法原理及其在 Redis 中的实现
一.问题引入 大家在项目上可能会遇到过下面这些相同或者类似的需求: 统计一个APP的日活量(DAU)和月活量(MAU).日活(月活)是指在一个统计日(统计月)之内,登录或者使用产品的不同用户数量,它是 ...
最新文章
- 敏捷原则比敏捷框架更重要
- java面试总结-(hibernate ibatis struts2 spring)
- Eclipse VIM
- 中级计算机培训班心得,计算机中级培训学习心得体会
- shell 脚本比较字符串相等_shell字符串比较判断是否为数字
- python:pytest中的setup和teardown
- 5调色板怎么打开_CAD打开较大的图纸就卡死的解决方法
- python中typeerror是什么意思_TypeError:在Python中
- 传智播客 C/C++学习笔记 函数调用 模型
- xmm1是什么器件_第三章基于Multisim10在模拟电路实验中的应用
- 成就电子电路设计高手(二),EDA在电子电路设计中的应用
- Docker 官方安装文档
- Woolies因滥发垃圾邮件被罚款100万澳元
- 解决因多网卡导致dubbo注册到ZK的IP错误问题,dubbox(当当,2.8.4)升级至dubbo(Apache,2.7.15)并集成
- 关于把数据库放在阿里云上,实现共享
- vue给div绑定keyup的enter事件实现接电话(结合阿里云软电话SDK)
- 金蝶KIS标准版会计期间超过三期。。。
- 现代信号处理——时频分析与时频分布(时频分布的基本理论)
- 产品交付周期计算公式_使用周期时间指标优化工程团队的交付
- 老黄因ChatGPT大赚311亿/ 中国移动公布实名NFT交易专利/C919首航航班确定...今日更多新鲜事在此...
热门文章
- IPO图(INPUT PROCESS OUTPUT)
- 金蝶服务器组件无法正常工作,K3组件kdsvrmgr无法正常工作
- 总结 27 类深度学习主要神经网络:结构图及应用
- Deep Graph Contrastive Representation Learning
- 【课程作业】情感分析方向SKEP: Sentiment Knowledge Enhanced Pretraining for Sentiment Analysis阅读报告
- 【大厂面试】面试官看了赞不绝口的Redis笔记(三)分布式篇
- ECMAScript 2022 正式发布
- mysql migration 使用_DbMigration的使用方法
- 论文-OpenDialKG: Explainable Conversational Reasoning with Attention-based Walks over Knowledge Grap
- 《数字孪生》(Yanlz+VR元宇宙+Unity+SteamVR+云技术+5G+AI+虚拟现实+数字映射+仿真+物理模型+传感器更新+运动历史+多学科+多物理量+多尺度+多概率+立钻哥哥++==)