A/N GPU架构解析
经常有网友问这样的问题:“为什么ATI显卡的流处理器要比NVIDIA多那么多,而性能却差不多呢?”这个问题往简单里说就是它们的算法不同,当然这是不负责任的说法。往复杂里说那么三言两语就讲不清楚了,因为涉及到双方GPU的核心架构以及截然相反的设计理念。
在DX9时代,大家都是通过“(像素)管线”来衡量显卡的性能等级,而到了DX10时代,统一渲染架构的引入使得显卡不再区分“像素”和“顶点”,因此“管线”这种说法逐渐淡出了大家的视野,取而代之的是全新的“流处理器”,“流处理器”的数量直接影响显卡的性能。

从DX10到DX10.1再到DX11,转眼间显卡已经发展到了第四代,但实际上不管ATI还是NVIDIA,它们的新一代显卡都是在最早的DX10显卡架构基础上不断优化、改进、扩充而来的。换句话说,即便是到了DX11时代,NVIDIA与ATI的性能大战依然是G80与R600架构的延续。
那么,我们就很有必要对双方的GPU图形架构进行深入研究,详细分析各自的优势与劣势,并且顺便解答网友心中的疑惑:为什么A卡的流处理器要比N卡多很多?
第2页
● “管线”的由来——1个时钟周期4次运算
在图形处理中,最常见的像素都是由RGB(红黄蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的算数逻辑运算器(ALU)。

传统像素管线/Shader示意图
数据的基本单元是Scalar(标量),就是指一个单独的值,GPU的ALU进行一次这种变量操作,被称做1D标量。由于传统GPU的ALU在一个时钟周期可以同时执行4次这样的并行运算,所以ALU的操作被称做4D Vector(矢量)操作。
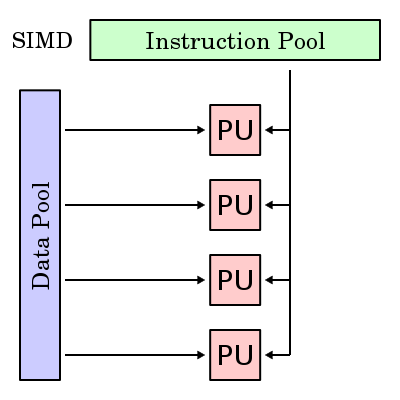
SIMD架构示意图
一个矢量就是N个标量,一般来说绝大多数图形指令中N=4。所以,GPU的ALU指令发射端只有一个,但却可以同时运算4个通道的数据,这就是SIMD(Single Instruction Multiple Data,单指令多数据流)架构。
● “管线”弊端越发明显,引入混合型设计
显然,SIMD架构能够有效提升GPU的矢量处理性能,由于顶点和像素的绝大部分运算都是4D Vector,它只需要一个指令端口就能在单周期内完成4倍运算量,效率达到100%。但是4D SIMD架构一旦遇到1D标量指令时,效率就会下降到原来的1/4,3/4的模块被完全浪费。为了缓解这个问题,ATI和NVIDIA在进入DX9时代后相继采用混合型设计,比如R300就采用了3D+1D的架构,允许Co-issue操作(矢量指令和标量指令可以并行执行),NV40以后的GPU支持2D+2D和3D+1D两种模式,虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上分支预测的情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。

改进的管线/Shader结构
可以这么理解,传统的1条管线里面包含了4个基本运算单元,在早期这种架构的执行效率还是很高的,因为大多数程序指令都是4D的。但由于API和游戏复杂Shader指令的发展,4D指令所占比重开始下降,3D/2D/1D等混合指令频繁出现,所以传统的管线式架构效率越来越低!
第3页
到了DX10时代,不再区分像素单元和顶点单元,还加入了新的几何着色单元,这样GPU的Shader单元不仅要处理像素和顶点操作,还要负责几何等其它操作,混合型指令所占比重越来越大,必须放弃传统的管线式架构。
● G80的标量流处理器架构
因此,NVIDIA从G80开始架构作了变化,把原来的4D着色单元彻底打散,流处理器不再针对矢量设计,而是统统改成了标量运算单元。每一个ALU都有自己的专属指令发射器,初代产品拥有128个这样的1D运算器,称之为流处理器。这些流处理器可以按照动态流控制智能的执行各种4D/3D/2D/1D指令,无论什么类型的指令执行效率都能接近于100%!

G8X家族核心架构图
如此一来,对于依然占据主流的4D矢量操作来说,G80需要让1个流处理器在4个周期内才能完成,或者是调动4个流处理器在1个周期内完成,那么G80的执行效率岂不是很低?没错,所以NVIDIA大幅提升了流处理器工作频率(两倍于核心频率),扩充了流处理器的规模(128个),这样G80的128个标量流处理器的运算能力就基本相当于传统的64个(128×2/4)4D矢量ALU。

G8X/G9X系列:8个流处理器为一组,2x8=16个为一簇
当然这只是在处理4D指令时的情形,随着图形画面越来越复杂,1D、2D、3D指令所占比例正在逐年增多,而G80在遇到这种指令时可说是如鱼得水,与4D一样不会有任何效能损失,指令转换效率高并且对指令的适应性非常好,这样G80就将GPU Shader执行效率提升到了新的境界!

MIMD架构示意图
与传统的SIMD架构不同,G80的这种标量流处理器被称为MIMD(Multiple Instruction Multiple Data,多指令多数据流)架构。G80的架构听起来很完美,但也存在不可忽视的缺点:根据前面的分析可以得知,4个1D标量ALU和1个4D矢量ALU的运算能力是相当的,但是前者需要4个指令发射端和4个控制单元,而后者只需要1个,如此一来MIMD架构所占用的晶体管数将远大于SIMD架构!
第4页
G80的128个1D标量ALU听起来规模很庞大,而且将4D矢量指令转换为4个1D标量指令时的效率也能达到100%,但实际上如果用相同的晶体管规模,可以设计出更加庞大的ALU运算器,这就是R600的流处理器架构。
● ATI改进传统架构,制造庞大规模的流处理器
与革命性的G80架构不同,R600身上有很多传统GPU的影子,其Stream Processing Units很像上代的Shader Units,它依然是传统的SIMD架构。

R600拥有4个SIMD阵列,每个SIMD阵列包括了16个Stream Processing Units,这样总共就是64个,但不能简单地认为它拥有64个流处理器,因为R600的每个Units内部包含了5个ALU:

我们来仔细看看R600的流处理器架构:Branch Execution Unit(分歧执行单元)就是指令发射和控制器,它获得指令包后将会安排至它管辖下5个ALU,进行流控制和条件运算。General Purpose Registers(通用寄存器)存储输入数据、临时数值和输出数据,并不存放指令。
由于内部的5个1D ALU共享同一个指令发射端口,因此宏观上R600应该算是SIMD(单指令多数据流)的5D矢量架构。但是R600内部的这5个ALU与传统GPU的ALU有所不同,它们是各自独立能够处理任意组合的1D/2D/3D/4D/5D指令,完美支持Co-issue(矢量指令和标量指令并行执行),因此微观上可以将其称为5D Superscalar超标量架构。

通过上图就可以清楚的看到,单指令多数据流的超标量架构可以执行任意组合形式的混合指令,在一个Stream Processing Units内部的5个ALU可以在单时钟周期内进行5次MAD(Multiply-Add,乘加)运算,其中比较“胖”的ALU除了MAD之外还能执行一些函数(SIN、COS、LOG、EXP等)运算,在特殊条件下提高运算效率!
现在我们就知道R600确实拥有64x5=320个流处理器。R600的流处理器之所以能比G80多好几倍就是得益于SIMD架构,可以用较少的晶体管堆积出庞大规模的流处理器。但是在指令执行效率方面,SIMD架构非常依赖于将离散指令重新打包组合的算法和效率,正所谓有得必有失。
通过前面的分析我们可以初步得出这样的结论:G80的MIMD标量架构需要占用额外的晶体管数,在流处理器数量和理论运算能力方面比较吃亏,但却能保证超高的执行效率;而R600的SIMD超标量架构可以用较少的晶体管数获得很多的流处理器数量和理论运算能力,但执行效率方面要依具体情况而定。
第5页
G80和R600都是不计成本的作品,成本高、功耗发热大,随着新工艺逐渐走向成熟,双方不约而同的推出了改良版的核心,使得新高端产品的以大规模量产,这就诞生了G92和RV670核心,这两颗GPU虽然都拥有众多诱人的新特性,但实际上核心架构方面没有任何的变化。
● G92相对于G80的改进:
1. 制造工艺由90nm升级至65nm;
2. 新工艺集成度更高,G92的GPU核心部分与2D输出模块(NVIO)合二为一,是单芯片设计;
3. PCI-E控制器升级支持2.0版本,带宽倍增;
4. 高清视频解码引擎由VP1升级至VP2,支持MPEG2和H.264的完全硬解码,VC-1部分硬解码;
5. 加入HDCP支持和HDMI输出支持;
6. 显存控制器由384bit降至256bit,这是控制成本的需要。由于显存控制器绑定光栅单元(ROP),因此G92的光栅单元只有16个,而G80是24个;
7. 纹理寻址单元数量加倍,纹理采样效率提升。
在以上诸多改进之中,只有这一项才是设计到核心架构的,因此这里重点介绍:
G80的流处理器结构

G92的流处理器结构
上面两幅架构图清楚的体现出了G80和G92的差异。NVIDIA GPU的流处理器簇和纹理单元还有一级缓存是绑定在一起的,G80的每簇内建了8个纹理过滤单元(Texture Filtering Unit)和4个纹理寻址单元(Texture Addressing Unit),总共数目就是64个TFU和32个TAU。而G92则提升至每组内建8个TFU和8个TAU,总共64个TFU和64个TAU,也就是纹理寻址单元数量加倍。
更多的TAU可令单一周期处理更多的纹理采样操作,部分情况下纹理处理器效率提升一倍!虽然DX9C时代反复强调高像素/纹理比例,但DX10时代引入了更多的纹理操作,并且SM4.0支持更复杂的纹理阵列,以便让物体表面拥有更丰富的细节,并且在超高分辨率下也不至于失真,但也对纹理操作提出了较高的要求,NVIDIA此举意在提升Call of Juarez、Crysis这种高精度游戏中的效率。
事实上,除了G80核心之外,G84、G86、G92、G96等所有衍生出来的小核心都改进了纹理单元设计,也就是说从8600GT开始起纹理寻址单元的数量就与纹理过滤单元相等了,只是中低端显卡的变化未能引起大家的重视。
● RV670相对于R600的改进:
1. 制造工艺由80nm升级至55nm;
2. PCI-E控制器升级支持2.0版本,带宽倍增;
3. 高清解码引擎由原来的Shader解码升级为UVD引擎,支持H.264和VC-1的完全硬解码;
4. 显存控制器由512bit降至256bit,这是控制成本的需要,而且以R600和RV670的运算能力其实不需要太高的显存位宽;
5. 支持PowerPlay节能技术,待机功耗很低;
6. API升级至DX10.1;
虽然API升级了,但实际上只不过是加入了新的Shader Model 4.1指令集而已,流处理器架构方面没有变化,甚至光栅单元和纹理单元都没有任何改动。
由于R600/RV670的架构是显存控制器并没有绑定光栅单元,虽然RV670的显存位宽减少了,但并没有造成太多的性能损失,反而由于频率的提升得以反超。因此G92相比G80是性能下降了,而RV670相比R600是有所提升,但最终的结果RV670和G92的差距依然很大。
可以看出,G92和RV670在技术方面的改进其实都是差不多,真正最关键的(流处理器)核心架构方面其实没有任何变化。
第6页
G92虽然有着众多G80所不具备的新特性,但本质上来讲它是G80削减成本的产物。而NVIDIA真正第二代DX10核心应该是GT200才对,下面我们就看看GT200相对于G80的改进。
● GT200架构的变化
众所周知,GT200最大的变化就是拥有240个流处理器,而且显存位宽高达512bit,当然这只是表象,真正核心架构方面的改进如下:

G80/G92拥有128个流处理器,这些流处理器分为8组TPC(线程处理器簇),每组16个SP(流处理器),这16个SP又分为两组SM(多核流处理器),SM是不可拆分的最小单元,是8核心设计。
GTX200将TPC数量从8个扩充至10个,而且在每个TPC内部,SM从2个增加到3个,SM依然是8核心设计。如此一来,GTX200核心的流处理器数量就是,8×3×10=240个,几乎是G80的两倍,但却不是256个。
纹理单元部分,GTX200的每个TPC内部拥有8个TF,这样总共就是8×10=80个纹理单元。G80/G92的流处理器与纹理单元的比率是128:64=2:1,而GT200的流处理器与纹理单元的比率是240:80=3:1,正是GT200微架构方面的变化造成了这一结果。
● GTX200核心微架构改进
GTX200核心在流处理器、纹理单元数量上的扩充是很容易理解的,其实除了扩充规模之外,在架构的细微之处还有不少的改进,这些都有助于提高新核心在未来游戏或通用计算中的执行效能:
1. 每个SM可执行线程上限提升:G80/G92核心每个SM(即不可拆分的8核心流处理器)最多可执行768条线程,而GTX200核心的每个SM提升至1024条,而且GTX200拥有更多的SM,芯片实力达到原来的2.5倍!

2. 每个SM的指令寄存器翻倍:GTX200与G80核心在SM结构上基本相同的,但功能有所提升,在执行线程数增多的同时,NVIDIA还将每个SM中间的Local Memory容量翻倍(从16K到32K)。Local Memory用于存储SM即将执行的上千条指令,容量增大意味着可以存储更多的指令、超长的指令、或是各种复杂的混合式指令,这对于提高SM的执行效能大有裨益。

双倍寄存器的优势:代表DX10性能的3DMarkVantage得分直接提升15%
当前和未来的DX10游戏,越来越多的使用复杂的混合式Shader指令,一旦排队中的超长指令溢出或者在N个周期内都排不上队,那么就会造成效率下降的情况,此时双倍寄存器容量的优势就体现出来了。由于Local Memory并不会消耗太多晶体管,因此将其容量翻倍是很合算的。
第7页
显然,RV670未能从R600失败的阴影中走出来,而RV770则是AMD的扬眉吐气之作,这颗相对GT200来说非常小巧的核心拥有不可思议的实力,现在我们就来回顾一下它的核心架构细节。
● RV770架构的变化
RV770的核心架构,它源自于R600,但青出于蓝而胜于蓝,AMD对核心几乎所有的模块都进行了改进,而且规模和数量方面大大加强。HD4850/4870令人惊讶的性能表现就是源自于核心架构。

首先来看看流处理器部分:RV670/R600是4组SIMD,每组16个Shader,每个Shader 5个流处理器;RV770是10组SIMD,每组16个Shader,每个Shader 5个流处理器,也就是说流处理器部分只是单纯的扩充规模而已,并没有任何改进。

纹理单元和光栅单元部分,和流处理器一样都是数量翻了2.5倍,但值得一提的是,抗锯齿算法已经由R600/RV670的流处理器部分转移至光栅单元部分,因此RV770的AA效率大幅提高,一举超越了所有N卡重现X1000时代的辉煌,这也就是RV770表现令人惊异的主要原因。

在纹理单元与显存控制器之间设有一级缓存,RV770核心相比RV670,L1 TC容量翻倍,再加上数量同比增加2.5倍,因此RV770的总L1容量达到了RV670/R600的五倍之多!
另外,RV770还放弃了使用多年的环形总线,估计是因为高频率下数据存取命中率的问题,回归了交叉总线设计,有效提高了显存利用率,并节约了显存带宽。
总的来说,虽然流处理器部分没有做改动,但RV770的整体架构相对于RV670可以说是脱胎换骨,这也是它大获成功的奥秘所在!
第8页
在大获成功的RV770基础上,AMD率先发布了首颗DX11图形核心——RV870,当然现在AMD已经不使用数字来命名GPU核心的,它的真正代号是Cypress。
● Cypres架构的变化
除了显存位宽维持256bit不变之外,Cypress的其它所有规格都正好是RV770的两倍,而且在流处理器部分可以看作是双核心的设计,几乎就是并排放置了两颗RV770核心:

为什么要使用这种双核心的设计呢?因为当流处理器扩充至1600个这样的恐怖规模时,不仅芯片设计制造的难度非常高,而且相应的缓存和控制模块难以管理协调如此众多的流处理器,因此一分为二的做法效率将会更高。
Cypress这样的结构与双核CPU十分相似,两颗“核心”各自独立,独享L1、共享L2和内存控制器等其他总线模块,而两颗“核心”之间则通过专用的数据共享及请求总线通信。

为了配合这两颗“核心”众多流处理器的工作,装配引擎内部设计有双倍的Rasterizer(光栅器)和Hierarchial-Z(多级Z缓冲模块),这是与RV770最大的不同。

在流处理器部分,RV870相对于RV770改进有限,只是加入了DX11新增的位操作类指令,并优化了Sum of Absolute Differences(SAD,误差绝对值求和)算法,指令执行速度提升12倍,此项指令可以在OpenCL底层执行。SAD算法应用最多的就是H.264/AVC编码的移动向量估算部分(约占整个AVC编码总时间的80%),如此一来使用RV870做视频编码类通用计算时,性能会大幅提升!
基本上,除了新增DirectX 11支持之外,Cypress相对于RV770在架构方面的改进非常有限。HD5000系列主要是凭借40nm和新一代GDDR5显存在功耗控制方面做的非常完美,虽然官方称抗锯齿效能大幅改进,但通过我们实际测试来看相对RV770提升非常小,因为RV770做的已经非常优秀了,另外HD5000系列的Eyefinity多屏显示器技术是一大卖点。
第9页
Cypress已经发布了半年之久,而NVIDIA方面的GF100依然是犹抱琵琶半遮面。GF100核心之所以延期这么久,一方面是因为NVIDIA遭遇了40nm新制程良率不足的困扰,另一方面GF100在核心架构方面的改进非常巨大,NVIDIA力图打造一颗在DX11和GPU计算方面都趋于完美的核心。
● GF100架构改进要点预览

如果说Cypress是“双核心”设计的话,那么GF100的流处理器部分就是“四核心”设计,因为其raster units(光栅化引擎)是以GPC(线程处理器簇)为单位的,一式四份。而raster units的功能就是以流水线的方式执行边缘/三角形设定(Edge/Triangle Setup)、光栅化(Rasterization)、Z轴压缩(Z-Culling)等操作。上页我们介绍过Cypress的Rasterizer和Hierarchial-Z双份的,而GF100则是四份的,虽然命名有所不同但功能是相同的。

另外,GF100拥有更多的PolyMorph(多形体引擎),是以SM(流处理器)为单位分配的,拥有多达16组。多形体引擎则要负责顶点拾取(Vertex Fetch)、细分曲面(Tessellation)、视口转换(Viewport Transform)、属性设定(Attribute Setup)、流输出(Stream Output)等五个方面的处理工作,DX11中最大的变化之一细分曲面单元(Tessellator)就在这里,因此GF100的理论Tessellation性能将会远超Cypress,因为Cypress只有一个Tessellator单元。

至于流处理器核心部分,则是经过了重新设计,与GT200/G92/G80相比是焕然一新,因此NVIDIA将其称为CUDA核心而不再是流处理器。
GF100的512个CUDA核心都符合IEEE 754-2008浮点算法(Cypress也是如此)和完整的32位整数算法,而后者在过去只是模拟的,事实上仅能计算24-bit整数乘法;同时全面引入的还有积和熔加运算(Fused Multiply-Add/FMA)。此外双精度浮点(FP64)性能大大提升,峰值执行率可以达到单精度浮点(FP32)的1/2,而过去只有1/8,AMD从R600开始到现在的Cypress核心都是1/5,没有做任何变化。

至于显存控制器方面的改进,还有显存ECC等外围功能就不多做介绍了。总而言之,GF100核心是GPU自从进入DX10时代以来,架构变化最大的一次,在GPU图形架构和并行计算架构方面都有了革命性的进步,因此备受玩家和业界期待。现在据可靠消息表明GF100架构的GTX480显卡将在本月26日准时发布,届时我们将会为大家献上全方位的架构分析及性能评测,让我们一同期待吧!■
A/N GPU架构解析相关推荐
- PowerVR 7架构解析
作为对ARM Mali-T800系列的直接回应,Imagination日前正式发布了新一代移动GPU PowerVR Series7系列,包括高端7XT.低端7XE两个子系列. 下边,我们就细细看看它 ...
- 智能化视频开发神器来了,AV Pipeline Kit 架构解析
作者 | 宋慧 出品 | CSDN 在中国,93.4%的上网者都是网络视频.短视频的受众.随着宽带提速,5G 普及,用户对网络视频播放速度和清晰度需求水涨船高.AI 技术让音视频有了更多玩法,例如用户 ...
- AMD统一渲染GPU架构 历程回顾与评测
AMD统一渲染GPU架构 历程回顾与评测 前言:NVIDIA公司历经长时间酝酿的Fermi架构高端产品GTX480/GTX470发布已经结束,经历了长达一个月的忙碌,我们已经了解到了这款产品的 ...
- GPU工作原理,可编程渲染管线,图形流水线和GPU架构
由于计算机图形的性质,最图形管线已构造为计算状态与数据流动作为它们之间的数据流.每个阶段工作在一组元素,如顶点,三角形或像素.下图1 [ Shr99 ]给出了典型的OpenGL固定管道. 图1: 在 ...
- NVIDIA VPI架构解析
VPI 架构解析 文章目录 VPI 架构解析 概述 支持的平台 算法 算法负载 无负载算法 后端 CPU CUDA PVA VIC NVENC OFA 流 缓冲器 Images 图像视图 锁 图像格式 ...
- 深度学习 Transformer架构解析
文章目录 一.Transformer背景介绍 1.1 Transformer的诞生 1.2 Transformer的优势 1.3 Transformer的市场 二.Transformer架构解析 2. ...
- 特斯拉Tesla Model 3整体架构解析(上)
特斯拉Tesla Model 3整体架构解析(上) 一辆特斯拉 Model 3型车在硬件改造后解体 Sensors for ADAS applications 特斯拉 Model 3型设计的传感器组件 ...
- The JVM Architecture Explained-JVM架构解析(译)
2019独角兽企业重金招聘Python工程师标准>>> 翻译原文:https://dzone.com/articles/jvm-architecture-explained JVM架 ...
- 千万级在线推送系统架构解析
2019独角兽企业重金招聘Python工程师标准>>> 千万级在线推送系统架构解析 移动短消息是大家所熟知的一种信息推送方式, 基于信令通道的推送在简单信息的体验方面已经被大家所接受 ...
- 超低延迟直播架构解析
本文由百度智能云-视频云直播技术架构师--朱晓恩 在百度开发者沙龙线上分享的演讲内容整理而成.内容从低延时直播背景与机遇出发,分析低延迟直播技术,重点分享百度在低延迟直播技术的实践工作. 文/ 朱晓恩 ...
最新文章
- 28岁自学python来得及吗_我28岁了,还能成为一名程序员吗?迷茫和沮丧中
- boot spring 解析csv_文件系统(02):基于SpringBoot框架,管理Xml和CSV文件类型-阿里云开发者社区...
- C 关于unsigned int compzero = ~0;与unsigned int compzero = 0xFFFF; 的区别!
- Android魔法(第四弹)—— 一步步实现百叶窗效果
- Python 之 进程
- 《机器学习实战》配套代码下载
- Oracle基本安全之用户、角色和权限操作
- 《计算机网络 自顶向下方法》 第2章 应用层 Part1
- python的内建数据结构包括_Python中3种内建数据结构:列表、元组和字典
- lolcat :一个在 Linux 终端中输出彩虹特效的命令行工具
- SAS Planet下载卫星地图
- smartupload功能介绍
- layui后台管理系统 - 权限树表格
- 计算机访问周期,访问周期最短的存储器是
- java学生成绩分90及格_Java基础练习:题目:利用条件运算符的嵌套来完成此题:学习成绩=90分的同学用A表示,60-89分之间的用B表示,60分以下 的用C表示。 - 菜鸟头头...
- tomcat去掉项目名称直接访问项目
- 统计学中假设检验有关P值的讨论
- javascript教程完整版,JavaScript视频教程
- 计算机二级证书中专能考吗,中专可以考什么资格证
- Git工作原理_繁星漫天_新浪博客