中文分词jieba python 学习
中文分词工具,结巴分词很好用,以下是验证小结。
import jieba
import jieba.analyse
import jieba.posseg as pseg
import time
filename='tianlongbabu.txt'
def file_jieba_wordcout(filename):
file=open(filename,'r').read()
file=jieba.cut(file)
dict={}
for word in file:
if word in dict:
dict[word]+=1
else:
dict[word]=1
file.close()
return dict
def print_top100(filename):
words=file_jieba_wordcout(filename)
dict1=sorted(words.items(),key=lambda item:item[1], reverse = True)
for item in dict1[:100]:
print(item[0],item[1])
# wordcout 前100 次
# print_top100(filename)
#基于 TF-IDF 算法的关键词抽取
# TFIDF_result=jieba.analyse.extract_tags(open(filename,'rU').read(), topK=100, withWeight=False, allowPOS=())
# print(TFIDF_result)
# 基于 TextRank 算法的关键词抽取
TextRank_result=jieba.analyse.textrank(open(filename,'rU').read(), topK=100, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
print(TextRank_result)
#词性标注
print_top100(filename) 通过结果看出,单纯top100结果包括了,空等无意义的停止词。
, 87017, 62909,。 27480,的 17698,“ 16965,” 16894,: 15125,了 14420,是 9740,我 9553,你 9429,他 8770,道 8408,? 7084,在 5547,也 5088,… 5033,这 4613,那 4093,不 3790,便 3657,又 3358,、 3264,说 3261,她 3230,! 3228,得 3142,人 2845,有 2797,去 2766,来 2430,将 2427,却 2242,都 2215,上 2162,中 2088,要 2072,但 2042,和 2037,说道 2016,到 2007,一 1959,着 1889,段誉 1881,向 1834,听 1774,之 1624,自己 1576,已 1534,只 1518,叫 1502,虚竹 1467,一个 1383,见 1368,好 1333,给 1330,‘ 1321,’ 1319,什么 1265,萧峰 1231,大 1217,而 1147,下 1110,想 1099,不是 1050,再 1025,为 1020,武功 1020,等 1019,就 1018,对 1003,甚么 997,过 996,么 945,跟 934,还 928,没 928,一声 878,瞧 833,乔峰 832,可 832,从 824,王语嫣 814,谁 799,段 795,咱们 782,杀 782,慕容复 781,不知 763,与 754,师父 750,心中 746,走 743,个 742,出 740,无 718,以 718,知道 709,段正淳 706,出来 706,
基于 TF-IDF 算法的关键词抽取。可以看出当前天龙八部的词频比较高的词语。可以看出主角有哪些。
段誉、虚竹、乔峰、
['段誉', '虚竹', '萧峰', '乔峰', '慕容复', '说道', '王语嫣', '武功', '段正淳', '木婉清', '丐帮', '甚么', '鸠摩智', '游坦之', '阿朱', '自己', '师父', '内力', '丁春秋', '大理', '包不同', '一声', '什么', '阿紫', '帮主', '星宿', '心下', '少林', '咱们', '不是', '鳄神', '心中', '便是', '一个', '童姥', '不知', '姑娘', '弟子', '契丹', '爹爹', '南海', '乌老大', '心想', '段延庆', '之中', '只见', '钟灵', '少林寺', '如何', '倘若', '突然', '出来', '见到', '当真', '登时', '身子', '众人', '如此', '功夫', '段公子', '知道', '云中鹤', '保定', '不敢', '声音', '伸手', '少女', '脸上', '西夏', '女子', '当下', '慕容公子', '性命', '穴道', '两人', '钟万仇', '巴天石', '左手', '眼见', '风波恶', '和尚', '耶律洪基', '只是', '当即', '跟着', '叶二娘', '之极', '方丈', '姊姊', '马夫人', '阿紫道', '不能', '二人', '只觉', '师兄', '王姑娘', '之下', '原来', '喝道', '这般']
TF-IDF 看看金瓶梅结果
['西门庆', '月娘', '妇人', '李瓶儿', '金莲', '伯爵', '银子', '说道', '春梅', '两个', '甚么', '后边', '那里', '敬济', '玳安', '淫妇', '明日', '一面', '小厮', '出来', '老爹', '潘金莲', '房里', '今日', '打发', '娘子', '来家', '妗子', '陈敬济', '大姐', '只见', '娇儿', '大舅', '屋里', '房中', '吴月娘', '吃酒', '吩咐', '这里', '不知', '玉楼', '一个', '因问', '桂姐', '只顾', '姐姐', '孟玉楼', '一日', '于是', '起身', '老婆', '起来', '大娘', '正是', '众人', '一回', '玳安道', '薛嫂', '丫头', '如今', '门首', '老人家', '书童', '奴才', '伙计', '迎春', '琴童', '晚夕', '在家', '家中', '进来', '连忙', '姑子', '姐夫', '就是', '五娘', '武松', '衣服', '罢了', '那话', '婆子', '一时', '守备', '来旺儿', '武大', '吴银儿', '大官人', '前边', '童儿', '春梅道', '韩道国', '人家', '王六儿', '敬济道', '知道', '儿来', '玉箫', '那日', '平安', '亲家']
基于 TextRank 算法的关键词抽取结果。
虚竹关联性竟然最大
['说道', '虚竹', '只见', '便是', '不知', '师父', '丐帮', '大理', '弟子', '不能', '出来', '内力', '南海', '知道', '姑娘', '少林', '众人', '契丹', '星宿', '见到', '跟着', '身子', '鳄神', '心想', '声音', '西夏', '伸手', '不可', '不会', '女子', '帮主', '眼见', '起来', '保定', '功夫', '说话', '双手', '对方', '大师', '不住', '兄弟', '爹爹', '右手', '来到', '没有', '听到', '中原', '性命', '少女', '问道', '敌人', '包不同', '无法', '方丈', '江湖', '全身', '武士', '先生', '不肯', '出去', '抓住', '公子', '就算', '穴道', '出手', '适才', '公主', '喝道', '生死', '兵刃', '段誉', '姊姊', '汉子', '不料', '不得', '不到', '声响', '高手', '大哥', '实在', '人家', '六脉', '手掌', '手指', '还有', '皇帝', '大家', '儿子', '取出', '苏星河', '长剑', '想到', '父亲', '主人', '露出', '英雄', '鲜血', '夫人', '大叫', '不见']
['西门庆', '妇人', '说道', '银子', '出来', '只见', '玳安', '起来', '打发', '不知', '娘子', '小厮', '吩咐', '众人', '起身', '看见', '人家', '进来', '衣服', '敬济', '知道', '老婆', '大姐', '淫妇', '吃酒', '学生', '坐下', '门首', '听见', '不想', '丫头', '姐姐', '收拾', '走来', '大舅', '饮酒', '东京', '说话', '伙计', '提刑', '出去', '书童', '出门', '老人家', '奴才', '来家', '不见', '西门', '小人', '看着', '进去', '守备', '衙门', '老爷', '方才', '坐在', '汉子', '孩子', '姐夫', '亲家', '琴童', '时分', '大娘', '还有', '来到', '不得', '取出', '问道', '伺候', '走到', '婆子', '大户', '回来', '官人', '放在', '没有', '衣裳', '娇儿', '不肯', '分付', '家人', '穿着', '床上', '奶奶', '雪娥', '磕头', '迎接', '姑子', '御史', '妈妈', '哥儿', '轿子', '花子', '大人', '观看', '花园', '丫鬟', '孩儿', '韩道国', '大门']
TF-IDF模型:
http://www.cnblogs.com/hanacode/articles/4819328.html
tf-idf模型的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。该模型主要包含了两个因素:
1) 词w在文档d中的词频tf (Term Frequency),即词w在文档d中出现次数count(w, d)和文档d中总词数size(d)的比值:
tf(w,d) = count(w, d) / size(d)
2) 词w在整个文档集合中的逆向文档频率idf (Inverse Document Frequency),即文档总数n与词w所出现文件数docs(w, D)比值的对数:
idf = log(n / docs(w, D))
tf-idf模型根据tf和idf为每一个文档d和由关键词w[1]...w[k]组成的查询串q计算一个权值,用于表示查询串q与文档d的匹配度:
tf-idf(q, d)
= sum { i = 1..k | tf-idf(w[i], d) }
= sum { i = 1..k | tf(w[i], d) * idf(w[i]) }
举个栗子
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?
这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是----"的"、"是"、"在"----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
第一步,计算词频。
考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
或者
第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
TextRank 算法:
https://my.oschina.net/letiantian/blog/351154
TextRank算法基于PageRank,用于为文本生成关键字和摘要。其论文是:
Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
先从PageRank讲起。
PageRank
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式:
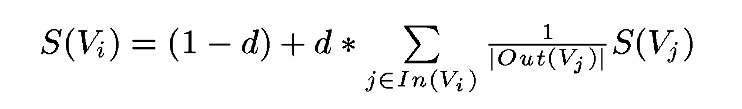
S(Vi)是网页i的中重要性(PR值)。d是阻尼系数,一般设置为0.85。In(Vi)是存在指向网页i的链接的网页集合。Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
举个例子:
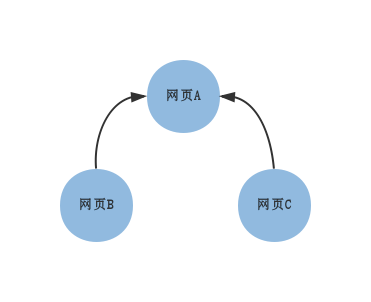
上图表示了三张网页之间的链接关系,直觉上网页A最重要。可以得到下面的表:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
横栏代表其实的节点,纵栏代表结束的节点。若两个节点间有链接关系,对应的值为1。
根据公式,需要将每一竖栏归一化(每个元素/元素之和),归一化的结果是:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
上面的结果构成矩阵M。我们用matlab迭代100次看看最后每个网页的重要性:
M = [0 1 1 0 0 00 0 0];PR = [1; 1 ; 1];for iter = 1:100PR = 0.15 + 0.85*M*PR;disp(iter);disp(PR);
end运行结果(省略部分):
......950.40500.15000.1500960.40500.15000.1500970.40500.15000.1500980.40500.15000.1500990.40500.15000.15001000.40500.15000.1500最终A的PR值为0.4050,B和C的PR值为0.1500。
如果把上面的有向边看作无向的(其实就是双向的),那么:
M = [0 1 1 0.5 0 00.5 0 0];PR = [1; 1 ; 1];for iter = 1:100PR = 0.15 + 0.85*M*PR;disp(iter);disp(PR);
end运行结果(省略部分):
.....981.45950.77030.7703991.45950.77030.77031001.45950.77030.7703依然能判断出A、B、C的重要性。
使用TextRank提取关键字
将原文本拆分为句子,在每个句子中过滤掉停用词(可选),并只保留指定词性的单词(可选)。由此可以得到句子的集合和单词的集合。
每个单词作为pagerank中的一个节点。设定窗口大小为k,假设一个句子依次由下面的单词组成:
w1, w2, w3, w4, w5, ..., wnw1, w2, ..., wk、w2, w3, ...,wk+1、w3, w4, ...,wk+2等都是一个窗口。在一个窗口中的任两个单词对应的节点之间存在一个无向无权的边。
基于上面构成图,可以计算出每个单词节点的重要性。最重要的若干单词可以作为关键词。
使用TextRank提取关键短语
参照“使用TextRank提取关键词”提取出若干关键词。若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键短语。
例如,在一篇介绍“支持向量机”的文章中,可以找到三个关键词支持、向量、机,通过关键短语提取,可以得到支持向量机。
使用TextRank提取摘要
将每个句子看成图中的一个节点,若两个句子之间有相似性,认为对应的两个节点之间有一个无向有权边,权值是相似度。
通过pagerank算法计算得到的重要性最高的若干句子可以当作摘要。
论文中使用下面的公式计算两个句子Si和Sj的相似度:

分子是在两个句子中都出现的单词的数量。|Si|是句子i的单词数。
由于是有权图,PageRank公式略做修改:

实现TextRank
因为要用测试多种情况,所以自己实现了一个基于Python 2.7的TextRank针对中文文本的库TextRank4ZH。位于:
https://github.com/someus/TextRank4ZH
下面是一个例子:
#-*- encoding:utf-8 -*-import codecs
from textrank4zh import TextRank4Keyword, TextRank4Sentencetext = codecs.open('./text/01.txt', 'r', 'utf-8').read()
tr4w = TextRank4Keyword(stop_words_file='./stopword.data') # 导入停止词#使用词性过滤,文本小写,窗口为2
tr4w.train(text=text, speech_tag_filter=True, lower=True, window=2) print '关键词:'
# 20个关键词且每个的长度最小为1
print '/'.join(tr4w.get_keywords(20, word_min_len=1)) print '关键短语:'
# 20个关键词去构造短语,短语在原文本中出现次数最少为2
print '/'.join(tr4w.get_keyphrases(keywords_num=20, min_occur_num= 2)) tr4s = TextRank4Sentence(stop_words_file='./stopword.data')# 使用词性过滤,文本小写,使用words_all_filters生成句子之间的相似性
tr4s.train(text=text, speech_tag_filter=True, lower=True, source = 'all_filters')print '摘要:'
print '\n'.join(tr4s.get_key_sentences(num=3)) # 重要性最高的三个句子运行结果如下:
关键词:
媒体/高圆圆/微/宾客/赵又廷/答谢/谢娜/现身/记者/新人/北京/博/展示/捧场/礼物/张杰/当晚/戴/酒店/外套
关键短语:
微博
摘要:
中新网北京12月1日电(记者 张曦) 30日晚,高圆圆和赵又廷在京举行答谢宴,诸多明星现身捧场,其中包括张杰(微博)、谢娜(微博)夫妇、何炅(微博)、蔡康永(微博)、徐克、张凯丽、黄轩(微博)等
高圆圆身穿粉色外套,看到大批记者在场露出娇羞神色,赵又廷则戴着鸭舌帽,十分淡定,两人快步走进电梯,未接受媒体采访
记者了解到,出席高圆圆、赵又廷答谢宴的宾客近百人,其中不少都是女方的高中同学另外, jieba分词提供的基于TextRank的关键词提取工具。 snownlp也实现了关键词提取和摘要生成。
下一步采用贝叶斯算法再分析一把。
中文分词jieba python 学习相关推荐
- 中文分词jieba学习笔记
中文分词jieba学习笔记 一.分词模式 二.自定义词典 2.1 命令 2.2 使用方式 三.关键词抽取(基于TF-IDF算法) 3.1 用jieba.analyse.extract_tags() 3 ...
- 视频教程-隐马尔科夫算法:中文分词神器-深度学习
隐马尔科夫算法:中文分词神器 在中国知网从事自然语言处理和知识图谱的开发,并负责带领团队完成项目,对深度学习和机器学习算法有深入研究. 吕强 ¥49.00 立即订阅 扫码下载「CSDN程序员学院APP ...
- 中文分词算法python代码_中文分词算法之最大正向匹配算法(Python版)
最大匹配算法是自然语言处理中的中文匹配算法中最基础的算法,分为正向和逆向,原理都是一样的. 正向最大匹配算法,故名思意,从左向右扫描寻找词的最大匹配. 首先我们可以规定一个词的最大长度,每次扫描的时候 ...
- Lucene 5.2.1 + jcseg 1.9.6中文分词索引(Lucene 学习序列2)
Lucene 5.2.1 + jcseg 1.9.6中文分词索引(Lucene 学习序列2) jcseg是使用Java开发的一个开源的中文分词器,使用流行的mmseg算法实现.是一款独立的分词组件,不 ...
- Python中文分词--jieba的基本使用
中文分词的原理 1.中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词. 分词就是将连续的字序列按照一定的规范重新组合成词序列的过程 2.现有的 ...
- Python中文分词 jieba 十五分钟入门与进阶
文章目录 整体介绍 三种分词模式与一个参数 关键词提取 中文歧义测试与去除停用词 三种可以让分词更准确的方法 并行计算 整体介绍 jieba 基于Python的中文分词工具,安装使用非常方便,直接pi ...
- python中文分词---jieba
原文地址:http://blog.csdn.net/sherlockzoom/article/details/44566425 jieba "结巴"中文分词:做最好的 Python ...
- python中文分词jieba总结
1. GitHub:https://github.com/fxsjy/jieba 2.分词 jieba.cut 方法接受三个输入参数: 需要分词的字符串:cut_all 参数用来控制是否采用全模式:H ...
- 中文分词(jieba)
中文分词 中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词.分词就是将连续的字序列按照一定的规范重新组合成词序列的过程.jieba 是目前Py ...
最新文章
- Java springMVC POI 导出 EXCEL
- Stream流与Lambda表达式(一) 杂谈
- 22 岁专访库克、B 站 3 天涨粉百万,他将毕设树莓派扫描仪升级,繁星散落在校空!...
- Node HTTP/2 Server Push 从了解到放弃
- ttc转ttf在线网站_文件格式怎么在线互转?迅捷PDF转换器告诉你
- class ts 扩展方法_ts类型声明文件的正确使用姿势
- Spring面向切面编程
- 有个需求mybatis 插入的时候不知道有哪些字段,需要动态的传入值和字段
- 673. 最长递增子序列的个数
- java 多线程生产者_java-Runnable加锁实现生产者和消费者的多线程问题
- cobol to java_cobol to java
- 博阅likebook alita专用pdf制作
- 科技通讯PSD分层海报出击!Hello 5G时代
- 李炎恢php学习视频教程下载
- [4G+5G专题-145]: 一体化小基站- 5G小基站软件建议架构概述
- 基于SpringBoot+Vue前后端分离的在线教育平台项目
- zblog php建站教程_Z-BlogPHP主题制作教程
- 2022科技公司薪酬排行榜,来了!
- Java中的Dao是什么意思?
- anemometer mysql5.6_slowlog分析anemometer平台搭建