sql server的搜索_在SQL Server中进行全文本搜索
sql server的搜索
介绍 (Introduction)
In most cases, we will use clustered and non-clustered indexes to help a query go faster, but these kinds of indexes have their own limitations and cannot be used for fast text lookup. For instance, a LIKE operator will lead SQL Server to scan the whole table in order to pick up values that meet the expression next to this operator. This means it won’t be fast in every case, even if an index is created for considered column.
在大多数情况下,我们将使用聚簇和非聚簇索引来帮助查询更快,但是这些类型的索引有其自身的局限性,不能用于快速文本查找。 例如,一个LIKE运算符将导致SQL Server扫描整个表,以获取满足该运算符旁边表达式的值。 这意味着即使为考虑的列创建索引,它也不会在每种情况下都很快。
Microsoft SQL Server comes up with an answer to part of this issue with a Full-Text Search feature. This feature lets users and application run character-based lookups efficiently by creating a particular type of index referred to as a Full-Text Index. This index can be built on the top of one or more columns for a particular table. These columns can be of following data types:
Microsoft SQL Server通过全文搜索功能为部分问题提供了答案。 通过创建称为全文索引的特定类型的索引,此功能使用户和应用程序可以有效地运行基于字符的查找。 该索引可以建立在特定表的一列或多列的顶部。 这些列可以是以下数据类型:
- char,
- 字符
- varchar,
- varchar ,
- nchar,
- nchar ,
- nvarchar,
- nvarchar ,
- text,
- 文字
- ntext,
- 文字
- image,
- 图片
- xml,
- xml
- varbinary(max)
- varbinary(最大)
- FILESTREAM
- 文件流
The building and usage of Full-Text indexes is always performed in a specific language context like English or French.
全文索引的建立和使用始终在特定的语言环境(例如英语或法语)中执行。
In the following sections, we will first take some time to understand overview how a Full-Text Search feature works. In this part, we will define some concepts and use them to understand how a Full-Text Index is built and maintained. We’ll even go through an illustrative example. Once we are done with theoretical aspects, we’ll then focus on some practical aspects in order to use and maintain this feature: we will see how to create a Full-Text indexed table, how to list out which tables have a Full-Text index and on which columns and much more
在以下各节中,我们将首先花一些时间来概述“全文搜索”功能的工作原理。 在这一部分中,我们将定义一些概念,并使用它们来理解如何建立和维护全文索引。 我们甚至将通过一个说明性示例。 一旦完成了理论方面的工作,我们便将重点放在一些实际方面,以便使用和维护此功能:我们将看到如何创建全文索引表,如何列出具有全文索引的表索引以及在哪些列上等等
概念 (Concepts)
Definitions
定义
Now that we know what the purpose of Full-Text Search feature is, let’s invest some time in the understanding of how it works. This will help us manage this feature.
现在我们知道了全文搜索功能的目的是什么,让我们花一些时间来了解它的工作原理。 这将帮助我们管理此功能。
Notice that, already at SQL Server installation, we can tell that this feature is special as the installer defines a daemon service called “fdhost.exe”. This process will be referred in following as the “filter daemon host“.
请注意,在SQL Server安装中,我们已经知道该功能很特殊,因为安装程序定义了一个名为“ fdhost.exe”的守护程序服务。 以下将该过程称为“过滤器守护程序主机”。
It is started by a service launcher called MSSQLFDLauncher for security concerns. It will exchange data with SQL Server service (sqlservr.exe) via shared memory or a named pipe. Fdhost.exe process will access, filter and tokenize user data in order to actually build Full-Text indexes. It’s also called to analyze Full-Text queries, including word breaking and stemming (see below for more info).
出于安全方面的考虑,它由称为MSSQLFDLauncher的服务启动器启动。 它将通过共享内存或命名管道与SQL Server服务(sqlservr.exe)交换数据。 Fdhost.exe进程将访问,过滤和标记用户数据,以便实际构建全文索引。 它也被称为分析全文查询,包括分词和词干分析(更多信息,请参见下文)。
This means that the entire Full-Text Search feature is spread across these two processes: fdhost.exe and sqlserv.exe and that some components of this feature interact with each other’s. Let’s review these components:
这意味着整个全文搜索功能分布在以下两个过程中:fdhost.exe和sqlserv.exe,并且该功能的某些组件相互交互。 让我们回顾一下这些组件:
- User tables – (sqlserv.exe) – tables for which a full-text index exists. 用户表 –(sqlserv.exe)–存在全文索引的表。
- Full-Text gatherer – in sqlserv.exe – a thread responsible for scheduling and driving index population so as for monitoring. 全文收集器 –在sqlserv.exe中–一个负责调度和驱动索引填充以便进行监视的线程。
- Thesaurus files – (sqlserv.exe)– files that contain synonyms of search terms. 同义词库文件 (sqlserv.exe)–包含搜索词同义词的文件。
- StopLists – in sqlserv.exe – objects that contain list of common words that can be ignored as they are not significant for a lookup (e.g. « and », « or », « but ») StopLists –在sqlserv.exe中–包含可被忽略的常用单词列表的对象,因为它们对于查找而言并不重要(例如«和»,«或»,«但»)
- Query Processor thread – (sqlserv.exe)– thread that compiles and executes T-SQL queries and send Full-Text search to the Full-Text Engine twice: once at compilation and once during query execution. The query results is matched against the full-text index. 查询处理器线程 –(sqlserv.exe)–编译和执行T-SQL查询并将全文搜索两次发送到全文引擎的线程:一次在编译时,一次在查询执行期间。 查询结果与全文索引匹配。
- Full-Text Engine – (sqlserv.exe)– can be seen as part of the Query Processor. It compiles and runs full-text queries and takes stoplists and thesaurus files into account before sending back results sets for these queries. 全文引擎 (sqlserv.exe)可以看作是查询处理器的一部分。 它会编译并运行全文查询,并在向回发送这些查询的结果集之前,考虑到停机清单和同义词库文件。
- Full-Text Indexer – (sqlserv.exe)– This thread builds the structure used to store index tokens. 全文索引器 –(sqlserv.exe)–此线程构建用于存储索引令牌的结构。
- Filter Daemon Manager – (sqlserv.exe)– this thread monitors the status of the fdhost.exe daemon service. 筛选器后台程序管理器 –(sqlserv.exe)–此线程监视fdhost.exe后台程序服务的状态。
- Protocol Handler Thread – (fdhost.exe) – this thread pulls data from memory for further processing and accesses data from a user table. 协议处理程序线程 –(fdhost.exe)–该线程从内存中提取数据以进行进一步处理,并从用户表访问数据。
- Filters – (fdhost.exe) – they are specific by document type and allow the extraction of text data from various data types like varbinary, image or xml. They will be used, for instance, in order to remove any embedded formatting on the text of a MS Word document. You can run following query in order to get an overview of the filters defined by default: 过滤器 –(fdhost.exe)–特定于文档类型,可以从各种数据类型(如varbinary,image或xml)中提取文本数据。 例如,将使用它们来删除MS Word文档文本上的任何嵌入式格式。 您可以运行以下查询,以获取默认情况下定义的过滤器的概述:
EXEC sp_help_fulltext_system_components 'filter'; - Word breakers and 分词系统和stemmers (fdhost.exe) – Each language has its set of word breakers. These components help to find the boundaries of each word in a sentence based on lexical rules of its associated language. So they help tokenizing sentences. Moreover, each word breaker is used in pair with a stemmer component. This component helps to find the root of a verb (its inflectional form) and conjugates verb, also based on language-specific rules. For instance, it will consider all these forms as being the same: “writing”, “wrote”, “writer” are all forms of the word “write”. Words identified by either of these components are inserted as keywords into a full-text index. 词干分析器 (fdhost.exe)–每种语言都有其分词器集合。 这些组件有助于根据其相关语言的词汇规则找到句子中每个单词的边界。 因此,它们有助于标记化句子。 此外,每个断字器与词干提取器组件一起使用。 该组件还基于特定于语言的规则,帮助找到动词的根(其变形形式)和共轭动词。 例如,它将所有这些形式都视为相同:“写作”,“写”,“作家”都是“写作”一词的所有形式。 由这两个组件之一标识的单词将作为关键字插入全文索引。
Architecture of a Full-Text Index
全文索引的体系结构
First of all, we have to know that any full-text index is stored into what Microsoft calls a “ full-text catalog”. It’s like a container for Full-Text indexes. Why did Microsoft define a logical container for Full-Text indexes? Simply because these indexes are usually split across multiple internal tables that are called full-text index fragments. These fragments are created as we insert or update records.
首先,我们必须知道任何全文索引都存储在Microsoft所谓的“全文目录”中。 就像全文索引的容器一样。 Microsoft为什么要为全文索引定义逻辑容器? 仅仅因为这些索引通常被拆分为多个内部表,这些内部表称为全文索引片段。 这些片段是在我们插入或更新记录时创建的。
We can get back data about a Full-Text Index using dynamic management views and functions. One of these is the sys.dm_fts_index_keywords_by_document function. It returns a data set with the following columns:
我们可以使用动态管理视图和功能来获取有关全文索引的数据。 其中之一是sys.dm_fts_index_keywords_by_document函数。 它返回包含以下列的数据集:
- A hexadecimal representation of the keyword
关键字的十六进制表示形式 - A human-readable representation of the keyword
关键字的易于理解的表示形式 - The identifier of the column subject to a Full-Text Index
接受全文索引的列的标识符 - The identifier of the document or the row from which the current keyword has been indexed
索引当前关键字的文档或行的标识符 - The number of times this keyword has been found in that document or row indicated by previous column
在该文档或上一列指示的行中找到此关键字的次数
Here is a sample results set:
这是一个示例结果集:
In that results set, we can see that for document with identifier “14536”, there are 3 occurrences of “%)” keyword.
在该结果集中,我们可以看到,对于标识符为“ 14536”的文档,出现了3个“%)”关键字。
This allows us to tell that a Full-Text index is an “inverted index” as it’s generated from a given data source and maps the results of this generation back to its data source. We can also notice that it computes statistics on the fly about the occurrence count. If we check Full-Text DMVs documentation, we’ll notice that these statistics can be obtained:
这使我们知道全文索引是从给定数据源生成的“ 反向索引 ”,并将该生成的结果映射回其数据源。 我们还可以注意到,它可以动态计算有关发生次数的统计信息。 如果我们查看全文DMV文档 ,则会注意到可以获得以下统计信息:
- by document,
根据文件 - by property,
按财产 - by keywords.
通过关键字。
This means that a Full-Text index is not really comparable to a normal index. But it’s not the only difference:
这意味着全文索引实际上无法与普通索引媲美。 但这不是唯一的区别:
- We can define only one Full-Text index per table while we can define multiple ones for normal indexes.
每个表只能定义一个全文索引,而普通索引可以定义多个索引。 - population. In contrast to normal indexes, these populations are not part of a transaction. This means that even though the data has been inserted in a Full-Text indexed table, which happens once the transaction that inserts these data is committed, this does not necessarily mean that the Full-Text index has been updated. Full-Text index population is asynchronous. 人口” 。 与正常索引相反,这些总体不是事务的一部分。 这意味着即使已将数据插入全文索引表中(一旦提交了插入这些数据的事务后也会发生),这并不一定意味着已更新全文索引。 全文索引填充是异步的。
- There is no grouping of normal indexes into an index catalog.
没有将普通索引分组到索引目录中。
How a Full-Text Index is populated
如何填充全文索引
As index population is asynchronous, what tells SQL Server it’s time to actually start a population? There is actually an option that is called “Change Tracking”, which can be configured by Full-Text Index and has several possible values:
由于索引填充是异步的,是什么告诉SQL Server实际开始填充的时间了? 实际上有一个称为“更改跟踪”的选项,可以通过全文索引进行配置,并且具有多个可能的值:
- AUTO: asks SQL Server to track data changes for a table and automatically requestsindex population
- AUTO :要求SQL Server跟踪表的数据更改并自动请求索引填充
- MANUAL: asks SQL Server to track data changes for a table but let user himself request for index population. This means that there could be hours or days before the Full-Text is updated
- MANUAL :要求SQL Server跟踪表的数据更改,但让用户自己请求索引填充。 这意味着全文更新可能需要几个小时或几天才能完成
- OFF: means that SQL Server won’t track data changes and maintenance of this index is performed totally manually. On systems using this feature extensively, this mode could eventually require large maintenance windows as population would have to check read all the table.
- OFF :表示SQL Server将不会跟踪数据更改,并且完全手动执行此索引的维护。 在广泛使用此功能的系统上,此模式最终可能需要较大的维护窗口,因为人口不得不检查所有表。
You will find below a diagram that summarizes the way a Full-Text Index has to be populated (for the first time or based on user activity) with only one new or updated record.
您将在下面的图表中总结出仅使用一个新的或更新的记录(第一次或基于用户活动)填充全文索引的方式。
There is one important thing to notice: index population is initiated by sqlserv.exe and the population is actually performed by fdhost.exe. As discussed above, this population won’t happen every time a user created or changed a record in a Full-Text indexed table. Instead, when change tracking is in AUTO mode, it’s the Full-Text Gatherer thread (inside sqlserv.exe) that will tell fdhost.exe to start index population. This is part of the explanation why index population process is not synchronous with data modifications.
有一件重要的事情要注意:索引填充由sqlserv.exe启动,而填充实际上由fdhost.exe执行。 如上所述,这种填充不会在用户每次在全文索引表中创建或更改记录时发生。 相反,当更改跟踪处于AUTO模式时,它将是全文收集器线程(在sqlserv.exe内部),该线程将告诉fdhost.exe开始索引填充。 这是为什么索引填充过程与数据修改不同步的解释的一部分。
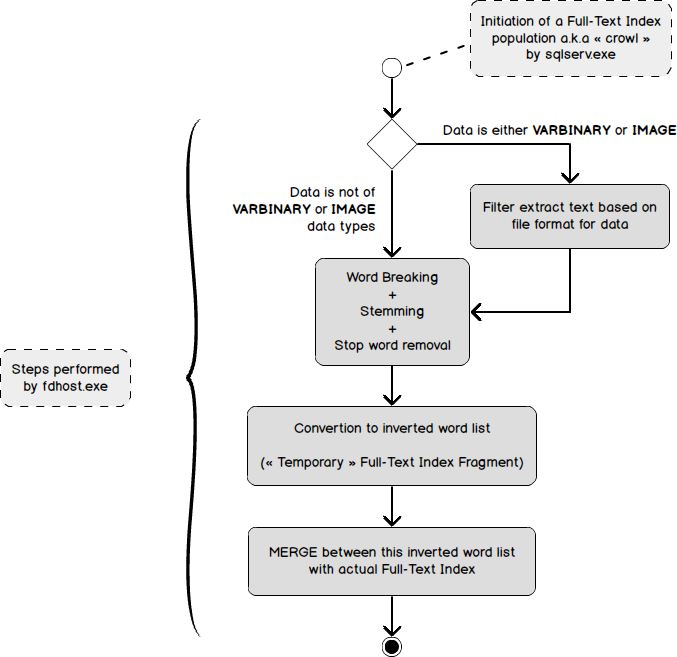
Full-Text Index population by example
全文索引人口示例
Let’s say we have a table called MyDocs with two columns, one called DocId that uniquely identifies a record and one called Comments that contains a comment on the document in plain text, so it’s a VARCHAR column.
假设我们有一个名为MyDocs的表,该表有两列,一个称为DocId的表,该表唯一地标识一条记录,另一个名为注释的表 ,以纯文本形式包含对该文档的注释,因此它是VARCHAR列。
Let’s now assume this table has three records in as follows:
现在,假设该表具有以下三个记录:
Now, let’s say that we already created a Full-Text Index on that table and SQL Server decided that it’s time to populate it.
现在,假设我们已经在该表上创建了全文索引,SQL Server决定是时候填充它了。
It will first take care of the row with 1 as value for DocId column. It will tokenize the contents of Comments column and start to build an index fragment that maps the each token to this record like this:
首先将处理以1作为DocId列值的行。 它将标记注释列的内容,并开始构建一个索引片段,将每个标记映射到该记录,如下所示:
It will then cut “full-text” into “full” and “text” and remove the “on” keyword as it’s a stop word we’ll have following keywords list:
然后,它将“全文”切成“全文”和“文本”,并删除“ on”关键字,因为它是一个停用词,我们将在以下关键字列表中列出:
Note: Notice that the index is build using alphabetical ordering
注意 :请注意,索引是使用字母顺序构建的
It will do the same with the second document so that the keywords list will be composed of: “cool” , “indexes”, “resources” and “tables”. It will then analyze the Comments column for the third document and build following keywords list: “cool”, “Full-Text”, “Full”, “Text” and “workshop”.
它将与第二个文档相同,因此关键字列表将由“ cool”,“ indexs”,“ resources”和“ tables”组成。 然后它将分析第三个文档的“ 注释”列,并建立以下关键字列表:“酷”,“全文”,“全文”,“文本”和“车间”。
The results of the analysis for each document could lead to the creation of an index fragment. If we put them together, we have following list of keywords:
每个文档的分析结果都可能导致创建索引片段。 如果我们将它们放在一起,则会有以下关键字列表:
The list above would be the actual data stored in our Full-Text index as the table was empty. You can check that this is actually what you get by running the code in the Appendix A of this article. But, it’s recommended to read all this article before going straight to this appendix!
由于表为空,因此上面的列表将是存储在全文索引中的实际数据。 您可以通过运行本文附录A中的代码来检查这是否确实是您所获得的。 但是,建议直接阅读本附录之前,先阅读所有本文!
如何创建启用了全文本的表 (How to create a table with Full-Text enabled)
Let’s say we have a table called [dbo].[DM_OBJECT_FILE] already created using following statement.
假设我们已经使用以下语句创建了一个名为[dbo]。[DM_OBJECT_FILE]的表。
CREATE TABLE [dbo].[DM_OBJECT_FILE] ([FILE_ID] [int] NOT NULL,[FILE_FIN] [int] NOT NULL,[FILE_TITLE] [Varchar] (255) ,[OBJ_ID] [int] NOT NULL ,[FILE_ATT] [smallint] NOT NULL,[FILE_PATH] [Varchar] (500) NULL,[FILE_EXT] [Varchar](50) NULL,[FILE_TXT] [varbinary] (max) NULL,[FILE_KEYWORDS] [Varchar] (1000) NULL,[FILE_STATUS] [smallint] NULL,[FILE_TXT_SIZE] [Int] default 0,[OBJ_FILE_IDX_DOCTYPE] [Varchar] (3) Null,CONSTRAINT [PK_DM_OBJECT_FILE] PRIMARY KEY CLUSTERED ([FILE_ID])
)Each file imported into that table is uniquely identified by FILE_ID column, FILE_TXT column refers to the contents of this file and OBJ_FILE_IDX_DOCTYPE refers to the kind of document that is stored in the FILE_TXT column.
导入该表的每个文件都由FILE_ID列唯一标识, FILE_TXT列引用此文件的内容, OBJ_FILE_IDX_DOCTYPE引用存储在FILE_TXT列中的文档的类型。
Now, we are willing to create a Full-Text Index on this table. This means that Full-Text feature should already be installed on our instance. To check whether it’s the case or not, we can use the following query:
现在,我们愿意在此表上创建全文索引。 这意味着全文功能应该已经安装在我们的实例上。 要检查是否存在这种情况,我们可以使用以下查询:
SELECT CASE FULLTEXTSERVICEPROPERTY('IsFullTextInstalled')WHEN 1 THEN 'Full-Text installed.' ELSE 'Full-Text is NOT installed.' END
;If it appears that Full-Text is not installed, you should consider to install it first.
如果似乎未安装全文,则应考虑先安装它。
As soon as you are sure that Full-Text feature is installed, we should check that FullText search is enabled for the database where our table is stored. We can check it with the following statement:
一旦确定已安装全文功能,就应该检查是否为存储表的数据库启用了全文搜索。 我们可以使用以下语句进行检查:
SELECT is_fulltext_enabled
FROM sys.databases
WHERE database_id = DB_ID()We should get following output:
我们应该得到以下输出:
If we don’t, we should run following T-SQL statement:
如果不这样做,则应运行以下T-SQL语句:
exec sp_fulltext_database 'enable'; But this is not the end! We also want to check if there is already a full-text catalog, which is a virtual database object that does not belong to any filegroup and refers to a group of Full-Text indexes. To do so, we will run the following query:
但这还没有结束! 我们还想检查是否已经有一个全文目录,它是一个虚拟数据库对象,它不属于任何文件组,而是引用一组全文索引。 为此,我们将运行以下查询:
select *
FROM sys.fulltext_catalogsIf this query did not return any row, then we have to create one or more fulltext catalogs and set one of them as default. To perform this action, we will use a statement based on CREATE FULLTEXT CATALOG as follows:
如果此查询未返回任何行,则我们必须创建一个或多个全文目录并将它们之一设置为默认目录。 为了执行此操作,我们将使用基于CREATE FULLTEXT CATALOG的语句,如下所示:
CREATE FULLTEXT CATALOG FullTextCatalog AS DEFAULT;Now, we are ready to create the Full-Text index on [dbo].[DM_OBJECT_FILE] table. To create such an index we have to have some information:
现在,我们准备在[dbo]。[DM_OBJECT_FILE]表上创建全文索引。 要创建这样的索引,我们必须具有一些信息:
- What is the key index to be used in order to uniquely identify records?
用于唯一标识记录的关键索引是什么? - What columns should be part of the index? (Here: FILE_TXT column will be used)
- 索引应包含哪些列? (此处:将使用FILE_TXT列)
- What type of document does the column represent and in which column this information is stored? (Here: OBJ_FILE_IDX_DOCTYPE column will be used)
- 该列代表哪种类型的文档,并且此信息存储在哪一列中? (此处:将使用OBJ_FILE_IDX_DOCTYPE列)
- Which language is used in this column or is it preferable to be totally neutral regarding language interpretation?
在本专栏中使用哪种语言,或者最好在语言解释上完全保持中立? - Do we enable change tracking and let the index update by itself or do we manage this part ourselves?
我们是否启用更改跟踪并让索引本身更新,还是我们自己管理这一部分?
You will find below the create statement for a Full-Text Index on FILE_TXT column from table dbo.DM_OBJECT_FILE, with neutral language interpretation, automatic update and no stop list.
您将在表dbo.DM_OBJECT_FILE的 FILE_TXT列上的全文索引的create语句下面找到,该语句具有中性语言解释,自动更新且没有停止列表。
CREATE FULLTEXT INDEX ON dbo.DM_OBJECT_FILE (FILE_TXT TYPE COLUMN OBJ_FILE_IDX_DOCTYPE LANGUAGE 0
) KEY INDEX PK_DM_OBJECT_FILE
WITH CHANGE_TRACKING = AUTO, STOPLIST=OFF
;如何更改全文索引的配置 (How to change the configuration of a Full-Text Index)
There is a T-SQL command called ALTER FULLTEXT INDEX that allows us to perform some operations on a Full-Text Index like:
有一个称为ALTER FULLTEXT INDEX的T-SQL命令,它使我们可以对全文索引执行一些操作,例如:
- Enable or disable the index
启用或禁用索引 - Enable or disable change tracking for Full-Text Index population. If it stays enabled, we can tell SQL Server whether to automatically schedule an index population based on user activity or to let us do it manually.
为全文索引填充启用或禁用更改跟踪。 如果保持启用状态,我们可以告诉SQL Server是根据用户活动自动调度索引填充,还是让我们手动进行索引填充。 - Add, modify or edit the list of columns that should be part of the Full-Text Index.
添加,修改或编辑应作为全文索引一部分的列的列表。 - Control index population (only useful when we did not enabled change tracking in automated mode)
控制索引填充(仅当我们未启用自动模式下的更改跟踪时才有用)
For further details, please refer to Microsoft’s documentation page.
有关更多详细信息,请参阅Microsoft的文档页面 。
如何在查询中使用全文索引 (How to use a Full-Text Index in queries)
Once everything is in place, our Full-Text Index is created on our table and we can start using it with built-in functions. Following functions are predicate functions. This means that it returns a Boolean value that can be used in a WHERE clause.
一切就绪后,将在我们的表上创建全文索引,我们可以将其与内置函数一起使用。 以下函数是谓词函数。 这意味着它返回可以在WHERE子句中使用的布尔值。
| Function Name | Explanation |
| CONTAINS |
Searches for precise or fuzzy (less precise) matches to single words and phrases, words within a certain distance of one another, or weighted matches in SQL Server. Appropriate types of lookups:
Example usage: |
| FREETEXT |
Searches for values that match the meaning and not just the exact wording of the words in the search condition. This function will:
Example usage: |
| CONTAINSTABLE |
Same lookup as CONTAINS function except that it returns a table of rows with following columns:
Simple example usage: look for “blabla” or “huh” |
| FREETEXTTABLE |
Returns a table of zero, one, or more rows for those columns containing character-based data types for values that match the meaning, but not the exact wording, of the text in the specified column. Simple example usage: look for “blabla” or “huh” |
| 功能名称 | 说明 |
| 包含 |
搜索与单个单词和短语,彼此之间一定距离内的单词或SQL Server中的加权匹配的精确或模糊(不太精确)匹配。 适当的查询类型:
用法示例: |
| 自由文本 |
搜索匹配含义的值,而不仅仅是搜索条件中单词的确切措词。 该功能将:
用法示例: |
| 可容纳 |
与CONTAINS函数的查询方式相同,只不过它返回包含以下各列的行表:
简单示例用法:查找“ blabla”或“ huh” |
| 自由文本表 |
对于包含基于字符的数据类型的那些列,返回一个零,一个或多个行的表,这些值的值与指定列中文本的含义(而不是确切的措词)相匹配。 简单示例用法:查找“ blabla”或“ huh” |
Here is a comparison in terms of the number of results between CONTAINSTABLE and FREETEXTTABLE predicates using the example usage above.
这是使用上面的示例用法在CONTAINSTABLE和FREETEXTTABLE谓词之间的结果数量方面的比较。
Firstly, the results of CONTAINSTABLE:
首先, CONTAINSTABLE的结果:
Secondly, the results of FREETEXTTABLE:
其次, FREETEXTTABLE的结果:
As we can see, for the first one, we get back only 13 rows and ranking value is not that high while the second returns 17 rows more and ranking values are higher. Furthermore, we can check that the ordering of keys is different: The key 16575 is at the fourth position in the first screen capture while it’s at the second position in the second one.
我们可以看到,对于第一个,我们只返回13行,并且排名值不那么高,而第二个则返回17行,并且排名值更高。 此外,我们可以检查按键的顺序是否不同:按键16575在第一个屏幕捕获中位于第四位置,而在第二个屏幕捕获中位于第二位置。
These predicate functions can be used extensively and are not limited to fixed lookups. Instead, there is extensive grammar functionality associated to its lookup parameter. On each documentation page for these functions, we will find the definition of a <contains_search_condition> in the function’s grammatical definition. If we look closely at this grammar, we can see that it’s very rich and we have to learn this in order to get the most power out of Full-Text Search feature!
这些谓词功能可以广泛使用,并且不限于固定查找。 取而代之的是,有与其查询参数关联的广泛语法功能。 在这些函数的每个文档页面上,我们都会在函数的语法定义中找到<contains_search_condition>的定义。 如果我们仔细看一下该语法,就会发现它非常丰富,我们必须学习该语法,才能充分利用全文搜索功能!
<contains_search_condition> ::= { <simple_term> | <prefix_term> | <generation_term> | <generic_proximity_term> | <custom_proximity_term> | <weighted_term> } | { ( <contains_search_condition> ) { { AND | & } | { AND NOT | &! } | { OR | | } } <contains_search_condition> [ ...n ] } <simple_term> ::= { word | "phrase" }
<prefix term> ::= { "word*" | "phrase*" }
<generation_term> ::= FORMSOF ( { INFLECTIONAL | THESAURUS } , <simple_term> [ ,...n ] ) <generic_proximity_term> ::= { <simple_term> | <prefix_term> } { { { NEAR | ~ } { <simple_term> | <prefix_term> } } [ ...n ] } <custom_proximity_term> ::= NEAR ( { { <simple_term> | <prefix_term> } [ ,…n ] | ( { <simple_term> | <prefix_term> } [ ,…n ] ) [, <maximum_distance> [, <match_order> ] ] } ) <maximum_distance> ::= { integer | MAX } <match_order> ::= { TRUE | FALSE } <weighted_term> ::= ISABOUT ( { { <simple_term> | <prefix_term> | <generation_term> | <proximity_term> } [ WEIGHT ( weight_value ) ] } [ ,...n ] )Moreover, other functions returning a table have been added starting SQL Server 2012. These are:
此外,从SQL Server 2012开始,还添加了其他返回表的函数。这些函数是:
- semantickeyphrasetable 语义关键短语
- semanticsimilaritydetailstable 语义相似性详细
- semanticsimilaritytable 语义相似表
寻找与全文功能有关的信息 (Looking for information related to the Full-Text feature)
How to get the list of supported languages
如何获取支持的语言列表
We can run following query in order to get back the list of supported languages and their language identifier:
我们可以运行以下查询以获取受支持语言及其语言标识符的列表:
SELECT *
FROM sys.fulltext_languages
ORDER BY lcidHere is a sample of the results set:
这是结果集的示例:
How to get the list of Full-Text indexes in a particular database
如何获取特定数据库中的全文本索引列表
Let’s say we want to list out which tables and columns are used with the Full-Text feature. To do so, we can run the following query:
假设我们要列出与全文功能一起使用的表和列。 为此,我们可以运行以下查询:
SELECT SCHEMA_NAME(tbl.schema_id) as SchemaName,tbl.name AS TableName, FT_ctlg.name AS FullTextCatalogName,i.name AS UniqueIndexName,scols.name AS IndexedColumnName
FROM sys.tables tbl
INNER JOIN sys.fulltext_indexes FT_idx
ON tbl.[object_id] = FT_idx.[object_id]
INNER JOIN sys.fulltext_index_columns FT_idx_cols
ON FT_idx_cols.[object_id] = tbl.[object_id]
INNER JOINsys.columns scols
ON FT_idx_cols.column_id = scols.column_idAND FT_idx_cols.[object_id] = scols.[object_id]
INNER JOIN sys.fulltext_catalogs FT_ctlg
ON FT_idx.fulltext_catalog_id = FT_ctlg.fulltext_catalog_id
INNER JOIN sys.indexes i
ON FT_idx.unique_index_id = i.index_idAND FT_idx.[object_id] = i.[object_id];Here is a sample results:
这是一个示例结果:
How to check the results of a Full-Text parsing
如何检查全文分析的结果
There are two ways to check how Full-Text feature parses a given text depending on the source of the text.
有两种方法可以检查全文功能如何根据文本的来源来解析给定的文本。
Source of the text is a String
文本的来源是一个字符串
If you want to check fast what keywords you would get for a particular string, you might want to use sys.dm_fts_parser built-in function.
如果要快速检查特定字符串将获得哪些关键字,则可能要使用sys.dm_fts_parser内置函数。
Here is an example of call to that function.
这是对该函数的调用示例。
- The first parameter is the string that has to be parsed.
第一个参数是必须解析的字符串。 - The second parameter is the language identifier. Here, it’s set to 0, which means it’s neutral.
第二个参数是语言标识符。 在这里,它设置为0,这意味着它是中性的。 - The hhird parameter is the identifier of the stoplist. Here no stoplist is used.
hhird参数是非索引字表的标识符。 此处不使用非索引字表。 - The last parameter tells this function whether to be sensitive or not to accents. Here, we asked for insensitivity.
最后一个参数告诉该功能是否对重音敏感。 在这里,我们要求保持不敏感。
In other words, this function will take the information you would provide when creating a Full-Text Index.
换句话说,此功能将使用您在创建全文索引时将提供的信息。
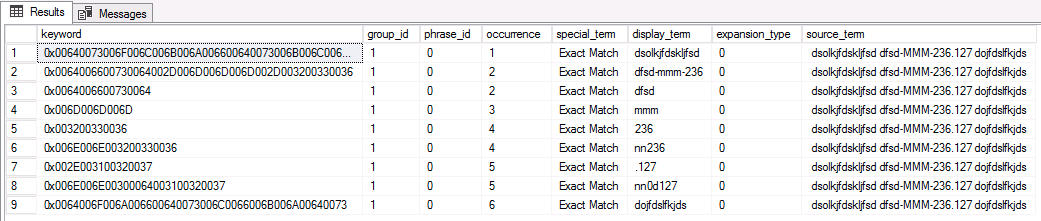
select * from sys.dm_fts_parser('" dsolkjfdskljfsd dfsd-MMM-236.127 dojfdslfkjds"',0,NULL,0
) ;Here are corresponding results. We can see that from this simple line, we get multiple keywords generated:
这是相应的结果。 我们可以从这一简单的行中看到,我们生成了多个关键字:
Source of the text is a Full-Text Index
文本来源是全文索引
If a table is already created with a Full-Text index, we would use another dynamic management function (DMF) called sys.dm_fts_index_keywords which takes as a parameter:
如果已经使用全文索引创建了一个表,我们将使用另一个名为sys.dm_fts_index_keywords的动态管理功能(DMF)作为参数:
- The database identifier in which it should look at
应该在其中查看的数据库标识符 - The object identifier in that database
该数据库中的对象标识符
It returns a dataset with a hexadecimal representation of the keyword, its corresponding form in the plain text, the identifier of the column in which the keyword has been found and finally the number of documents where this keyword can be found.
它返回一个数据集,该数据集以关键字的十六进制表示形式,其对应的纯文本格式,在其中找到关键字的列的标识符以及最终可以找到该关键字的文档数。
You will find below a T-SQL query to get back keywords found by Full-Text feature in our dbo.DM_OBJECT_FILE table so as its results set.
您将在T-SQL查询下面找到dbo.DM_OBJECT_FILE表中的“全文本”功能找到的关键字,以获取其结果集。
select *
From sys.dm_fts_index_keywords(DB_ID(),OBJECT_ID('dbo.DM_OBJECT_FILE'))
How to maintain Full-Text Indexes with change tracking in AUTO mode
如何在自动模式下使用更改跟踪维护全文索引
If you are DBA, you can’t neglect the question of maintenance for these particular indexes that are Full-Text indexes. Except for large systems, I think there is no reason to set change tracking to another mode than AUTO. That’s the reason why we will just cover this mode.
如果您是DBA,则不能忽略这些作为全文索引的特殊索引的维护问题。 除了大型系统,我认为没有理由将更改跟踪设置为AUTO以外的其他模式。 这就是我们仅介绍此模式的原因。
Actually, it’s difficult to get good recommendations about the way we should do this. For example, I haven’t found a rule from Microsoft that says “if there is 10% fragmentation then reorganize, if it’s more than 30% then rebuild the index”, which is the common guideline for normal index maintenance.
实际上,很难获得关于我们应该如何执行此操作的好的建议。 例如,我还没有找到Microsoft的规则,即“如果有10%的碎片然后重新组织,如果超过30%的碎片就重新建立索引”,这是正常索引维护的通用准则。
After reading the paragraph above, there are questions that should emerge:
阅读以上段落之后,应该出现一些问题:
- How do we rebuild a full-text index?
我们如何重建全文索引? - Can a Full-Text index be fragmented?
全文索引可以分段吗? - If so, how could we get some details on this?
如果是这样,我们如何获得有关此方面的详细信息? - Once we have details on this, how to determine when it’s necessary to take corrective actions?
一旦我们掌握了详细信息,如何确定何时需要采取纠正措施?
How to reorganize or rebuild a particular Full-Text index?
如何重组或重建特定的全文本索引?
There is no capability to reorganize or rebuild a given Full-Text index except by dropping and recreating it, using DROP FULLTEXT INDEX and CREATE FULLTEXT INDEX commands.
除了使用DROP FULLTEXT INDEX和CREATE FULLTEXT INDEX命令删除和重新创建给定的全文本索引外,无法重组或重建给定的全文本索引。
However, let’s remember that these indexes are grouped into a logical container called a Full-Text catalog. While we can’t rebuild or reorganize a particular index, we can do it on a Full-Text catalog using ALTER FULLTEXT CATALOG T-SQL command.
但是,请记住,这些索引被分组到一个称为“全文目录”的逻辑容器中。 尽管我们无法重建或重新组织特定的索引,但是我们可以使用ALTER FULLTEXT CATALOG T-SQL命令在全文目录上进行操作。
ALTER FULLTEXT CATALOG catalog_name
{ REBUILD [ WITH ACCENT_SENSITIVITY = { ON | OFF } ]
| REORGANIZE
| AS DEFAULT
}Can a Full-Text index be fragmented?
全文索引可以分段吗?
The answer to this question is pretty obvious as we said that, by design, the Full-Text index is built using index fragments created during index population (or index crawl). This means that, yes, Full-Text indexes can suffer fragmentation and a high fragmentation will obviously have a direct impact on application performances.
这个问题的答案非常明显,因为我们说过,按照设计,全文索引是使用在索引填充(或索引搜寻)期间创建的索引片段构建的。 这意味着,是的,全文索引可能会发生碎片,而高度碎片显然会直接影响应用程序性能。
How to check for Full-Text index fragmentation?
如何检查全文索引碎片?
Microsoft provides a set of management tables or views that we can query in order to get an overview of Full-Text index fragmentation. These are:
Microsoft提供了一组管理表或视图,我们可以查询这些管理表或视图以获取全文本索引碎片的概述。 这些是:
- sys.fulltext_catalogs in order to get the list of Full-Text Catalogs
- sys.fulltext_catalogs以获取全文目录的列表
- sys.fulltext_indexes in order to get the list of Full-Text Indexes
- sys.fulltext_indexes以获取全文索引列表
- sys.fulltext_index_fragments in order to get the list of index fragments
- sys.fulltext_index_fragments以获取索引片段列表
We can combine data from these management objects in order to get back an overview of:
我们可以合并来自这些管理对象的数据,以便获得以下概述:
- Which indexes are in which Full-Text Catalog?
哪些全文目录包含哪些索引? - How much space is consumed by a Full-Text Index?
全文索引会消耗多少空间? - On which object a Full-Text Index in based?
全文索引基于哪个对象? - How important the fragmentation is (in size (Mb) and percent)
碎片的重要性(大小(Mb)和百分比)
This can be performed using the following query, which is an adaptation of the one published by Geoff Patterson on StackExchange:
可以使用以下查询来执行此操作,该查询是Geoff Patterson在StackExchange上发布的查询的改编:
WITH FragmentationDetails
AS (SELECT table_id,COUNT(*) AS FragmentsCount,CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS IndexSizeMb,CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mbFROM sys.fulltext_index_fragmentsGROUP BY table_id
)
SELECT DB_NAME() AS DatabaseName,ftc.fulltext_catalog_id AS CatalogId, ftc.[name] AS CatalogName, fti.change_tracking_state AS ChangeTrackingState,fti.object_id AS BaseObjectId, QUOTENAME(OBJECT_SCHEMA_NAME(fti.object_id)) + '.' + QUOTENAME(OBJECT_NAME(fti.object_id)) AS BaseObjectName,f.IndexSizeMb AS IndexSizeMb, f.FragmentsCount AS FragmentsCount, f.largest_fragment_mb AS IndexLargestFragmentMb,f.IndexSizeMb - f.largest_fragment_mb AS IndexFragmentationSpaceMb,CASEWHEN f.IndexSizeMb = 0 THEN 0ELSE 100.0 * (f.IndexSizeMb - f.largest_fragment_mb) / f.IndexSizeMbEND AS IndexFragmentationPct
FROM sys.fulltext_catalogs ftc
JOIN sys.fulltext_indexes fti
ON fti.fulltext_catalog_id = ftc.fulltext_catalog_id
JOIN FragmentationDetails fON f.table_id = fti.object_id
;Here is a sample result. For image readability, rows have been split into two sets:
这是一个示例结果。 为了提高图像的可读性,将行分为两组:
When do we need to take corrective actions?
我们什么时候需要采取纠正措施?
I haven’t seen any recommendations about this on Microsoft’s documentation website but here are the results of my searches:
我没有在Microsoft文档网站上看到有关此的任何建议,但这是我的搜索结果:
- Based on the researches of Geoff Patterson, he defined that a Full-Text Index needs to be rebuilt starting at 10% of fragmentation.
- 根据Geoff Patterson的研究 ,他定义了全文索引需要从碎片的10%开始重建。
- his blog post, Barry Kind suggests to reorganize the Full-Text catalog when 30 to 50 fragments per table are reached. 他的博客文章中 ,Barry Kind建议在每张表达到30到50个碎片时重新组织全文目录。
There are some tests that have to be done in order to find the right set of criteria but they won’t be covered by this article.
为了找到正确的标准,必须进行一些测试,但是本文不会涉及这些测试。
Next article in this series:
本系列的下一篇文章:
- How to automatically maintain Full-Text indexes and catalogs如何自动维护全文索引和目录
附录A –创建测试的代码。MyDocs表 (Appendix A – code to create testing.MyDocs table)
You will find below the T-SQL instructions that will allow you to check the results we announced in section Full-Text Index population by example.
您可以在T-SQL指令下方找到,该指令可让您查看示例中的全文索引填充一节中宣布的结果。
create schema testing;DROP TABLE testing.MyDocs;create table testing.MyDocs (DocId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_MyDocs PRIMARY KEY,Comments VARCHAR(MAX)
);insert into testing.MyDocs (comments)
values ('Best book ever on Full-Text Index'),('Cool resource on indexes and tables'),('Cool workshop on Full-Text')
;CREATE FULLTEXT INDEX ON testing.MyDocs(Comments LANGUAGE 1033 /* English */
) KEY INDEX PK_MyDocs
;select * From sys.dm_fts_index_keywords_by_document(DB_ID(DB_NAME()),OBJECT_ID('testing.MyDocs'))
--where document_id = 3
;select * From sys.dm_fts_index_keywords(DB_ID(DB_NAME()),OBJECT_ID('testing.MyDocs'))-- cleanups
DROP TABLE testing.MyDocsDROP SCHEMA testing;翻译自: https://www.sqlshack.com/hands-full-text-search-sql-server/
sql server的搜索
sql server的搜索_在SQL Server中进行全文本搜索相关推荐
- 【SQL学习记录】SQL Server全文本搜索
1 全文本搜索 (Full-text Search) 1.1 全文本搜索简介 全文本搜索支持查询: 一个或多个特定单词 以特定的文本开头 特定单词的各种词性(动词.名词.形容词.进行时.过去时等) 和 ...
- mysql全文本搜索
前言 1️⃣ :mysql环境准备 2️⃣ :简单的表查询 3️⃣ :通配符+正则表达式 4️⃣ :mysql函数与分组 5️⃣ :子查询_联结查询_组合查询 第一部分:我们准备环境:安装数据库+创建 ...
- 数据库9:联结表 高级联结 组合查询 全文本搜索
第十五章联结表 Sql最强大的功能之一就是能在数据检索查询的执行中联结(join)表.联结是利用sql的select能执行的最重要的操作,能很好的理解联结及其语法是学习sql的一个极为重要的组成部分. ...
- MySQL(十)操纵表及全文本搜索
一.创建表 MySQL不仅用于表数据操作,还可以用来执行数据库和表的所有操作,包括表本身的创建和处理. 创建表一般有如下两种方式: ①使用具有交互式创建和管理表的工具: ②直接使用MySQL语句操纵表 ...
- MySQL数据检索+查询+全文本搜索
[0]README 0.1)本文部分文字描述转自"MySQL 必知必会",旨在review"MySQL数据检索+查询+全文本搜索" 的基础知识: [1]使用子查 ...
- 《MySQL必知必会》学习笔记——组合查询、全文本搜索
文章目录 第17章 组合查询 1. 创建组合查询 2. UNION规则 3. 包含或取消重复的行 4. 对组合查询结果排序 第18章 全文本搜索 1. 理解全文本搜索 2. 使用全文本搜索 2.1 启 ...
- MySql学习之组合查询(UNION)和全文本搜索(Match()和Against())
组合查询 一.何为组合查询? 组合查询的目的就是利用UNION操作符将多条SELECT语句的查询结果组合成一个结果集,供我们使用. 有两种基本情况下需要使用组合查询: 1.在单个查询中从不同的表返回类 ...
- mysql 学习记录 全文本搜索
第十八章 全文本搜索 mysql最常用的引擎是MYISAM和InnoDb,前者支持全文本搜索,后者不支持. 全文本搜索搜索速度更快,搜索条件更精确,搜索结果更智能化.使用like子句也可以完成,但全文 ...
- 如何使用MySQL的全文本搜索功能
全本文搜索 1.全文本搜索 1.1理解全文本搜索 2.使用全文搜索 2.1启用全文本搜索支持 2.2进行全文本搜索 2.3使用查询扩展 2.4布尔文本搜索 2.5全文搜索的使用说明 1.全文本搜索 1 ...
最新文章
- MOSS 权限管理总结
- github 使用总结-----转
- 《剑指offer》-- 数组中的逆序对、最小的K个数、从1到n整数中1出现的次数、正则表达式匹配、数值的整数次方
- TypeScript 编译生成的 JavaScript 源代码里的 ɵcmp 属性
- leetcode287. 寻找重复数(二分法)
- 第四次作业类测试代码+036+吴心怡
- php的list函数的使用,php list函数如何使用
- eclipse中run运行不了_Springboot专辑:运行 Spring Boot 应用的 3 种方式!
- 网络编程学习记录-1
- [转载] python机器学习第三章:使用scikit-learn实现机器学习分类算法
- 在Chrome浏览器中保存的密码有多安全?
- 托福试卷真题_托福考试真题 - 韩语自学网
- BS7799, ISO/IEC 17799, ISO/IEC 27001容易混淆
- 4.1 android 头像,微商抠图软件换头像app
- 巨潮网怎么下载年报_如何下载上市公司财务报表?
- 关于基本勾股数规律的探讨总结与例题!
- python day8
- 实现自己人生小目标之微信抢红包项目
- html网页屏保,屏幕保护是什么
- AltiumDesigner中如何将原理图导成黑白色图