Kubernetes监控之Heapster源码分析
源码版本
heapster version: release-1.2
简介
Heapster是Kubernetes下的一个监控项目,用于进行容器集群的监控和性能分析。
基本的功能及概念介绍可以回顾我之前的一篇文章:《Kubernetes监控之Heapster介绍》。
随着的Heapster的版本迭代,支持的功能越越来越多,比如新版本支持更多的后端数据存储方式:OpenTSDB、Monasca、Kafka、Elasticsearch等等。看过低版本(如v0.18)的源码,会发现v1.2版本的源码架构完全变了样,架构扩展性越来越强,源码学无止境!
上面很多介绍这篇文章并不会涉及,我们还是会用到最流行的模式:Heapster + InfluxDB。
监控系统架构图:
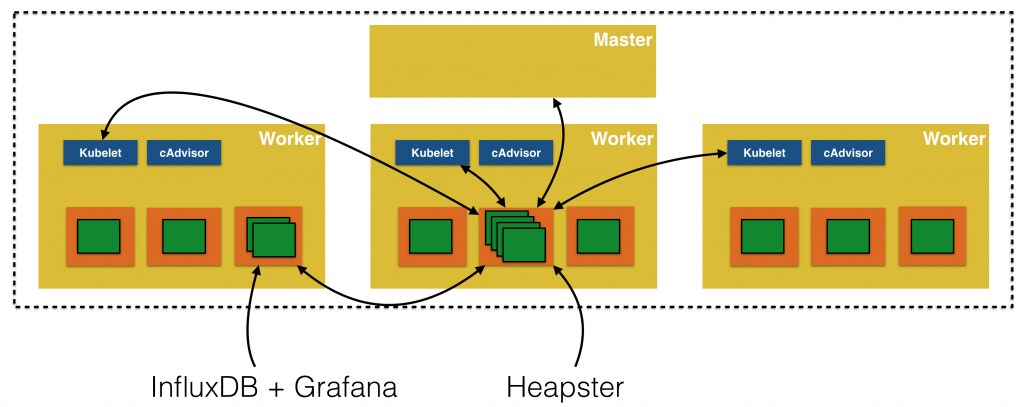
该图很好的描述了监控系统的关键组件,及数据流向。
在源码分析之前我们先介绍Heapster的实现流程,由上图可以看出Heapster会从各个Node上kubelet获取相关的监控信息,然后进行汇总发送给后台数据库InfluxDB。
这里会涉及到几个关键点:
k8s集群会增删Nodes,Heapster需要获取这些sources并做相应的操作
Heapster后端数据库怎么存储?是否支持多后端?
Heapster获取到数据后推送给后端数据库,那么其提供了API的数据该从何处获取?本地cache?
Heapster从kubelet获取到的数据是否需要处理?还是能直接存储到后端
等等..
一起分析完heapster源码实现,就能进行解惑了。
启动命令
先列出我解析源码时所用的命令,及参数使用,便于后面的理解。
# heapster --source=kubernetes:http://<master-ip>:8080?inClusterConfig=false\&useServiceAccount=false --sink=influxdb:http://<influxdb-ip>:8086启动流程
从Heapster的启动流程开始分析其实现,前面做了简单的分析,可以带着问题去看源码会有更好的收获。
main()
路径: heapster/metrics/heapster.go
func main() {...// 根据--source参数的输入来创建数据源// 我们这里会使用kubernetes,下面会根据k8s来解析sourceFactory := sources.NewSourceFactory()// 创建该sourceProvider时,会创建Node的ListWatch,用于监控k8s节点的增删情况,因为这些才是数据的真实来源.// 该sourceProvider会包含nodeLister,还有kubeletClient,用于跟各个节点的kubelet通信,获取cadvisor数据sourceProvider, err := sourceFactory.BuildAll(argSources)if err != nil {glog.Fatalf("Failed to create source provide: %v", err)}// 创建sourceManager,其实就是sourceProvider + ScrapeTimeout,用于超时获取数据sourceManager, err := sources.NewSourceManager(sourceProvider, sources.DefaultMetricsScrapeTimeout)if err != nil {glog.Fatalf("Failed to create source manager: %v", err)}// 根据--sink创建数据存储后端// 我们这里会使用influxDB,来作为数据的存储后端sinksFactory := sinks.NewSinkFactory()// 创建sinks时会返回各类对象:// metricSink: 可以理解为本地的metrics数据池,Heapster API获取到的数据都是从该对象中获取的,默认一定会创建// sinkList: Heapster在新版本中支持多后端数据存储,比如你可以指定多个不同的influxDB,也可以同时指定influxDB和Elasticsearch。// historicalSource: 需要配置,我们暂时没有用到metricSink, sinkList, historicalSource := sinksFactory.BuildAll(argSinks, *argHistoricalSource)if metricSink == nil {glog.Fatal("Failed to create metric sink")}if historicalSource == nil && len(*argHistoricalSource) > 0 {glog.Fatal("Failed to use a sink as a historical metrics source")}for _, sink := range sinkList {glog.Infof("Starting with %s", sink.Name())}// 创建sinkManager,会根据之前的sinkList,创建对应数量的协程,用于从sink的数据管道中获取数据,然后推送到对应的后端sinkManager, err := sinks.NewDataSinkManager(sinkList, sinks.DefaultSinkExportDataTimeout, sinks.DefaultSinkStopTimeout)if err != nil {glog.Fatalf("Failed to created sink manager: %v", err)}// 创建对象,用于处理各个kubelet获取到的metrics数据// 最终都会加入到dataProcessors,在最终的处理函数中会进行遍历并调用其process()metricsToAggregate := []string{core.MetricCpuUsageRate.Name,core.MetricMemoryUsage.Name,core.MetricCpuRequest.Name,core.MetricCpuLimit.Name,core.MetricMemoryRequest.Name,core.MetricMemoryLimit.Name,}metricsToAggregateForNode := []string{core.MetricCpuRequest.Name,core.MetricCpuLimit.Name,core.MetricMemoryRequest.Name,core.MetricMemoryLimit.Name,}// 速率计算对象dataProcessors := []core.DataProcessor{// Convert cumulaties to rateprocessors.NewRateCalculator(core.RateMetricsMapping),}kubernetesUrl, err := getKubernetesAddress(argSources)if err != nil {glog.Fatalf("Failed to get kubernetes address: %v", err)}kubeConfig, err := kube_config.GetKubeClientConfig(kubernetesUrl)if err != nil {glog.Fatalf("Failed to get client config: %v", err)}kubeClient := kube_client.NewOrDie(kubeConfig)// 会创建podLister、nodeLister、namespaceLister,用于从k8s watch各个资源的增删情况// 防止获取数据失败podLister, err := getPodLister(kubeClient)if err != nil {glog.Fatalf("Failed to create podLister: %v", err)}nodeLister, err := getNodeLister(kubeClient)if err != nil {glog.Fatalf("Failed to create nodeLister: %v", err)}podBasedEnricher, err := processors.NewPodBasedEnricher(podLister)if err != nil {glog.Fatalf("Failed to create PodBasedEnricher: %v", err)}dataProcessors = append(dataProcessors, podBasedEnricher)namespaceBasedEnricher, err := processors.NewNamespaceBasedEnricher(kubernetesUrl)if err != nil {glog.Fatalf("Failed to create NamespaceBasedEnricher: %v", err)}dataProcessors = append(dataProcessors, namespaceBasedEnricher)// 这里的对象append顺序会有一定的要求// 比如Pod的有些数据需要进行containers数据的累加得到dataProcessors = append(dataProcessors,processors.NewPodAggregator(),&processors.NamespaceAggregator{MetricsToAggregate: metricsToAggregate,},&processors.NodeAggregator{MetricsToAggregate: metricsToAggregateForNode,},&processors.ClusterAggregator{MetricsToAggregate: metricsToAggregate,})nodeAutoscalingEnricher, err := processors.NewNodeAutoscalingEnricher(kubernetesUrl)if err != nil {glog.Fatalf("Failed to create NodeAutoscalingEnricher: %v", err)}dataProcessors = append(dataProcessors, nodeAutoscalingEnricher)// 这是整个Heapster功能的关键处// 根据sourceManger、sinkManager、dataProcessors来创建manager对象manager, err := manager.NewManager(sourceManager, dataProcessors, sinkManager, *argMetricResolution,manager.DefaultScrapeOffset, manager.DefaultMaxParallelism)if err != nil {glog.Fatalf("Failed to create main manager: %v", err)}// 开始创建协程,从各个sources获取metrics数据,并经过dataProcessors的处理,然后export到各个用于后端数据存储的sinksmanager.Start()// 以下的就是创建Heapster server,用于提供各类API// 通过http.mux及go-restful进行实现// 新版的heapster还支持TLShandler := setupHandlers(metricSink, podLister, nodeLister, historicalSource)addr := fmt.Sprintf("%s:%d", *argIp, *argPort)glog.Infof("Starting heapster on port %d", *argPort)mux := http.NewServeMux()promHandler := prometheus.Handler()if len(*argTLSCertFile) > 0 && len(*argTLSKeyFile) > 0 {if len(*argTLSClientCAFile) > 0 {authPprofHandler, err := newAuthHandler(handler)if err != nil {glog.Fatalf("Failed to create authorized pprof handler: %v", err)}handler = authPprofHandlerauthPromHandler, err := newAuthHandler(promHandler)if err != nil {glog.Fatalf("Failed to create authorized prometheus handler: %v", err)}promHandler = authPromHandler}mux.Handle("/", handler)mux.Handle("/metrics", promHandler)healthz.InstallHandler(mux, healthzChecker(metricSink))// If allowed users is set, then we need to enable Client Authenticationif len(*argAllowedUsers) > 0 {server := &http.Server{Addr: addr,Handler: mux,TLSConfig: &tls.Config{ClientAuth: tls.RequestClientCert},}glog.Fatal(server.ListenAndServeTLS(*argTLSCertFile, *argTLSKeyFile))} else {glog.Fatal(http.ListenAndServeTLS(addr, *argTLSCertFile, *argTLSKeyFile, mux))}} else {mux.Handle("/", handler)mux.Handle("/metrics", promHandler)healthz.InstallHandler(mux, healthzChecker(metricSink))glog.Fatal(http.ListenAndServe(addr, mux))}
}介绍了Heapster的启动流程后,大致能明白了该启动过程分为几个关键点:
创建数据源对象
创建后端存储对象list
创建处理metrics数据的processors
创建manager,并开启数据的获取及export的协程
开启Heapster server,并支持各类API
下面进行一一介绍。
创建数据源
先介绍下相关的结构体,因为这才是作者的核心思想。
创建的sourceProvider是实现了MetricsSourceProvider接口的对象。
先看下MetricsSourceProvider:
type MetricsSourceProvider interface {GetMetricsSources() []MetricsSource
}每个最终返回的对象,都需要提供GetMetricsSources(),看字面意识就可以知道就是提供所有的获取Metrics源头的接口。
我们的参数--source=kubernetes,所以其实我们真实返回的结构是kubeletProvider.
路径: heapster/metrics/sources/kubelet/kubelet.go
type kubeletProvider struct {// 用于从k8s获取最新的nodes信息,然后根据kubeletClient,合成各个metricSourcesnodeLister *cache.StoreToNodeLister// 反射reflector *cache.Reflector// kubeletClient相关的配置,比如端口:10255kubeletClient *KubeletClient
}结构介绍完了,看下具体的创建过程,跟kubernetes相关的关键接口是NewKubeletProvider():
func NewKubeletProvider(uri *url.URL) (MetricsSourceProvider, error) {// 创建kubernetes master及kubelet client相关的配置kubeConfig, kubeletConfig, err := GetKubeConfigs(uri)if err != nil {return nil, err}// 创建kubeClient及kubeletClientkubeClient := kube_client.NewOrDie(kubeConfig)kubeletClient, err := NewKubeletClient(kubeletConfig)if err != nil {return nil, err}// 获取下所有的Nodes,测试下创建的client是否能正常通讯if _, err := kubeClient.Nodes().List(kube_api.ListOptions{LabelSelector: labels.Everything(),FieldSelector: fields.Everything()}); err != nil {glog.Errorf("Failed to load nodes: %v", err)}// 监控k8s的nodes变更// 这里会创建协程进行watch,便于后面调用nodeLister.List()列出所有的nodes。// 该Watch的实现,需要看下apiServer中的实现,后面会进行讲解lw := cache.NewListWatchFromClient(kubeClient, "nodes", kube_api.NamespaceAll, fields.Everything())nodeLister := &cache.StoreToNodeLister{Store: cache.NewStore(cache.MetaNamespaceKeyFunc)}reflector := cache.NewReflector(lw, &kube_api.Node{}, nodeLister.Store, time.Hour)reflector.Run()// 结构在前面介绍过return &kubeletProvider{nodeLister: nodeLister,reflector: reflector,kubeletClient: kubeletClient,}, nil
}该过程会涉及到较多的技术点,比如apiServer中的watch实现,reflector的使用。这里不会进行细讲,该文章主要是针对heapster的源码实现,apiServer相关的实现后面会进行单独输出。
这里需要注意的是创建了ListWath,需要关注后面哪里用到了nodeLister.List()进行nodes的获取。
创建后端服务
前面已经提到后端数据存储会有两处,一个是metricSink,另一个是influxdbSink。所以这里会涉及到两个结构:
type MetricSink struct {// 锁lock sync.Mutex// 长时间存储metrics数据,默认时间是15minlongStoreMetrics []stringlongStoreDuration time.Duration// 短时间存储metrics数据,默认时间是140sshortStoreDuration time.Duration// 短时存储空间shortStore []*core.DataBatch// 长时存储空间longStore []*multimetricStore
}该结构就是用于heapster API调用时获取的数据源,这里会分为两种数据存储方式:长时存储和短时存储。所以集群越大时,heapster占用内存越多,需要考虑该问题如何处理或者优化。
type influxdbSink struct {// 连接后端influxDB数据库的clientclient influxdb_common.InfluxdbClient// 锁sync.RWMutexc influxdb_common.InfluxdbConfigdbExists bool
}这个就是我们配置的InfluxDB的结构,是我们真正的数据存储后端。
开始介绍创建后端服务流程,从sinksFactory.BuildAll()接口直接入手。
路径: heapster/metrics/sinks/factory.go
func (this *SinkFactory) BuildAll(uris flags.Uris, historicalUri string) (*metricsink.MetricSink, []core.DataSink, core.HistoricalSource) {result := make([]core.DataSink, 0, len(uris))var metric *metricsink.MetricSinkvar historical core.HistoricalSource// 根据传入的"--sink"参数信息,进行build// 支持多后端数据存储,会进行遍历并创建for _, uri := range uris {// 关键接口sink, err := this.Build(uri)if err != nil {glog.Errorf("Failed to create sink: %v", err)continue}if uri.Key == "metric" {metric = sink.(*metricsink.MetricSink)}if uri.String() == historicalUri {if asHistSource, ok := sink.(core.AsHistoricalSource); ok {historical = asHistSource.Historical()} else {glog.Errorf("Sink type %q does not support being used for historical access", uri.Key)}}result = append(result, sink)}// 默认metricSink一定会创建if metric == nil {uri := flags.Uri{}uri.Set("metric")sink, err := this.Build(uri)if err == nil {result = append(result, sink)metric = sink.(*metricsink.MetricSink)} else {glog.Errorf("Error while creating metric sink: %v", err)}}if len(historicalUri) > 0 && historical == nil {glog.Errorf("Error while initializing historical access: unable to use sink %q as a historical source", historicalUri)}return metric, result, historical
}该接口流程比较简单,就是对传入参数进行判断,然后调用this.Build()进行创建,这里只需要注意即使没有配置metric,也会进行metricSink的创建。
func (this *SinkFactory) Build(uri flags.Uri) (core.DataSink, error) {switch uri.Key {。。。case "influxdb":return influxdb.CreateInfluxdbSink(&uri.Val)。。。case "metric":return metricsink.NewMetricSink(140*time.Second, 15*time.Minute, []string{core.MetricCpuUsageRate.MetricDescriptor.Name,core.MetricMemoryUsage.MetricDescriptor.Name}), nil。。。default:return nil, fmt.Errorf("Sink not recognized: %s", uri.Key)}
}influxdb的创建其实就是根据传入的参数然后创建一个config结构,用于后面创建连接influxDB的client;
metric的创建其实就是初始化了一个MetricSink结构,需要注意的是传入的第三个参数,因为这是用于指定哪些metrics需要进行长时间存储,默认就是cpu/usage和memory/usage,因为这两个参数用户最为关心。
具体的创建接口就不在深入了,较为简单。
到这里BuildAll()就结束了,至于返回值前面已经做过介绍,就不在累赘了。
其实没那么简单,还有一步:sinkManager的创建。
进入sinks.NewDataSinkManager()接口看下:
func NewDataSinkManager(sinks []core.DataSink, exportDataTimeout, stopTimeout time.Duration) (core.DataSink, error) {sinkHolders := []sinkHolder{}// 遍历前面创建的sinkListfor _, sink := range sinks {// 为每个sink添加一个dataChannel和stopChannel// 用于获取数据和stop信号sh := sinkHolder{sink: sink,dataBatchChannel: make(chan *core.DataBatch),stopChannel: make(chan bool),}sinkHolders = append(sinkHolders, sh)// 每个sink都会创建一个协程// 从dataChannel获取数据,并调用sink.export()导出到后端数据库go func(sh sinkHolder) {for {select {case data := <-sh.dataBatchChannel:export(sh.sink, data)case isStop := <-sh.stopChannel:glog.V(2).Infof("Stop received: %s", sh.sink.Name())if isStop {sh.sink.Stop()return}}}}(sh)}return &sinkManager{sinkHolders: sinkHolders,exportDataTimeout: exportDataTimeout,stopTimeout: stopTimeout,}, nil
}这里会为每个sink创建协程,等待数据的到来并最终将数据导入到对应的后端数据库。
这里需要带个问号,既然channel有一端在收,总得有地方会发送,这会在后面才会揭晓。
go协程 + channel的方式,是golang最常见的方式,确实便用。
创建数据Processors
因为cAdvisor返回的原始数据就包含了nodes和containers的相关数据,所以heapster需要创建各种processor,用于处理成不同类型的数据,比如pod, namespace, cluster,node。
还有些数据需要计算出速率,有些数据需要进行累加,不同类型拥有的metrics还不一样等等情况。
看下源码:
func main() {...// 计算namespace和cluster的metrics值时,下列数据需要进行累加求值metricsToAggregate := []string{core.MetricCpuUsageRate.Name,core.MetricMemoryUsage.Name,core.MetricCpuRequest.Name,core.MetricCpuLimit.Name,core.MetricMemoryRequest.Name,core.MetricMemoryLimit.Name,}// 计算node的metrics值时,下列数据需要进行累加求值metricsToAggregateForNode := []string{core.MetricCpuRequest.Name,core.MetricCpuLimit.Name,core.MetricMemoryRequest.Name,core.MetricMemoryLimit.Name,}// RateMetricsMapping中的数据需要计算速率,比如cpu/usage_rate,network/rx_ratedataProcessors := []core.DataProcessor{// Convert cumulaties to rateprocessors.NewRateCalculator(core.RateMetricsMapping),}kubernetesUrl, err := getKubernetesAddress(argSources)if err != nil {glog.Fatalf("Failed to get kubernetes address: %v", err)}kubeConfig, err := kube_config.GetKubeClientConfig(kubernetesUrl)if err != nil {glog.Fatalf("Failed to get client config: %v", err)}kubeClient := kube_client.NewOrDie(kubeConfig)// 创建pod的ListWatch,用于从k8s server监听pod变更podLister, err := getPodLister(kubeClient)if err != nil {glog.Fatalf("Failed to create podLister: %v", err)}// 创建node的ListWatch,用于从k8s server监听node变更nodeLister, err := getNodeLister(kubeClient)if err != nil {glog.Fatalf("Failed to create nodeLister: %v", err)}// 该podBasedEnricher用于解析从sources获取到的pod和container的metrics数据,// 然后对pod和container进行数据完善,比如添加labels.但这里还不会处理metricsValuepodBasedEnricher, err := processors.NewPodBasedEnricher(podLister)if err != nil {glog.Fatalf("Failed to create PodBasedEnricher: %v", err)}dataProcessors = append(dataProcessors, podBasedEnricher)// 跟上面的podBasedEnricher同理,需要注意的是在append时有先后顺序namespaceBasedEnricher, err := processors.NewNamespaceBasedEnricher(kubernetesUrl)if err != nil {glog.Fatalf("Failed to create NamespaceBasedEnricher: %v", err)}dataProcessors = append(dataProcessors, namespaceBasedEnricher)// 这里的对象会对metricsValue进行处理,对应的数据进行累加求值dataProcessors = append(dataProcessors,processors.NewPodAggregator(),&processors.NamespaceAggregator{MetricsToAggregate: metricsToAggregate,},&processors.NodeAggregator{MetricsToAggregate: metricsToAggregateForNode,},&processors.ClusterAggregator{MetricsToAggregate: metricsToAggregate,})dataProcessors = append(dataProcessors, processors.NewRcAggregator())nodeAutoscalingEnricher, err := processors.NewNodeAutoscalingEnricher(kubernetesUrl)if err != nil {glog.Fatalf("Failed to create NodeAutoscalingEnricher: %v", err)}dataProcessors = append(dataProcessors, nodeAutoscalingEnricher)Processors的功能基本就是这样了,相对有点复杂,数据处理的样式和类别较多。
各个对象的Process()方法就不进行一一介绍了,就是按照顺序一个一个的填充core.DataBatch数据。有兴趣的可以逐个看下,可以借鉴下实现的方式。
获取源数据并存储
前面的都是铺垫,开始介绍heapster的关键实现,进行源数据的获取,并导出到后端存储。
先介绍相关结构:
type Manager interface {Start()Stop()
}Manager是需要实现Start和stop方法的接口。而真实创建的对象其实是realManager:
type realManager struct {// 数据源source core.MetricsSource// 数据处理对象processors []core.DataProcessor// 后端存储对象sink core.DataSink// 每次scrape数据的时间间隔resolution time.Duration// 创建多个scrape协程时,需要sleep这点时间,防止异常scrapeOffset time.Duration// scrape 停止的管道stopChan chan struct{}// housekeepSemaphoreChan chan struct{}// 超时housekeepTimeout time.Duration
}关键的代码如下:
manager, err := manager.NewManager(sourceManager, dataProcessors, sinkManager, *argMetricResolution,manager.DefaultScrapeOffset, manager.DefaultMaxParallelism)if err != nil {glog.Fatalf("Failed to create main manager: %v", err)}manager.Start()首先会根据前面创建的sourceManager, dataProcessors, sinkManager对象,再创建manager。
路径: heapster/metrics/manager/manager.go
func NewManager(source core.MetricsSource, processors []core.DataProcessor, sink core.DataSink, resolution time.Duration,scrapeOffset time.Duration, maxParallelism int) (Manager, error) {manager := realManager{source: source,processors: processors,sink: sink,resolution: resolution,scrapeOffset: scrapeOffset,stopChan: make(chan struct{}),housekeepSemaphoreChan: make(chan struct{}, maxParallelism),housekeepTimeout: resolution / 2,}for i := 0; i < maxParallelism; i++ {manager.housekeepSemaphoreChan <- struct{}{}}return &manager, nil
}前面介绍了该关键结构readlManager,继续进入manager.Start():
func (rm *realManager) Start() {go rm.Housekeep()
}func (rm *realManager) Housekeep() {for {// Always try to get the newest metricsnow := time.Now()// 获取数据的时间段,默认是1minstart := now.Truncate(rm.resolution)end := start.Add(rm.resolution)// 真正同步一次的时间间隔,默认是1min + 5stimeToNextSync := end.Add(rm.scrapeOffset).Sub(now)select {case <-time.After(timeToNextSync):rm.housekeep(start, end)case <-rm.stopChan:rm.sink.Stop()return}}
}继续看rm.housekeep(start, end), 该接口就传入了时间区间,其实cAdvisor就是支持时间区间来获取metrics值。
func (rm *realManager) housekeep(start, end time.Time) {if !start.Before(end) {glog.Warningf("Wrong time provided to housekeep start:%s end: %s", start, end)return}select {case <-rm.housekeepSemaphoreChan:// ok, good to gocase <-time.After(rm.housekeepTimeout):glog.Warningf("Spent too long waiting for housekeeping to start")return}go func(rm *realManager) {defer func() { rm.housekeepSemaphoreChan <- struct{}{} }()// 从sources获取数据data := rm.source.ScrapeMetrics(start, end)// 遍历processors,然后进行数据处理for _, p := range rm.processors {newData, err := process(p, data)if err == nil {data = newData} else {glog.Errorf("Error in processor: %v", err)return}}// 最终将数据导出到后端存储rm.sink.ExportData(data)}(rm)
}逻辑比较简单,会有三个关键:
源数据获取
数据处理
导出到后端
先看下rm.source.ScrapeMetrics()接口实现.
路径: heapster/metrics/sources/manager.go
func (this *sourceManager) ScrapeMetrics(start, end time.Time) *DataBatch {// 调用了nodeLister.List()获取最新的k8s nodes列表,再根据之前配置的kubelet端口等信息,返回sources// 在创建sourceProvider时,会创建node的ListWatch,所以这里nodeLister可使用list()sources := this.metricsSourceProvider.GetMetricsSources()responseChannel := make(chan *DataBatch)。。。// 遍历各个source,然后创建协程获取数据for _, source := range sources {go func(source MetricsSource, channel chan *DataBatch, start, end, timeoutTime time.Time, delayInMs int) {// scrape()接口其实就是调用了kubeletMetricsSource.ScrapeMetrics()// 每个node都会组成对应的kubeletMetricsSource// ScrapeMetrics()就是从cAdvisor中获取监控信息,并进行了decodemetrics := scrape(source, start, end)...select {// 将获取到的数据丢入responseChannel// 下面会用到case channel <- metrics:// passed the response correctly.returncase <-time.After(timeForResponse):glog.Warningf("Failed to send the response back %s", source)return}}(source, responseChannel, start, end, timeoutTime, delayMs)}response := DataBatch{Timestamp: end,MetricSets: map[string]*MetricSet{},}latencies := make([]int, 11)responseloop:for i := range sources {...select {// 获取前面创建的协程得到的数据case dataBatch := <-responseChannel:if dataBatch != nil {for key, value := range dataBatch.MetricSets {response.MetricSets[key] = value}}。。。case <-time.After(timeoutTime.Sub(now)):glog.Warningf("Failed to get all responses in time (got %d/%d)", i, len(sources))break responseloop}}...return &response
}该接口的逻辑就是先通过nodeLister获取k8s所有的nodes,这样便能知道所有的kubelet信息,然后创建对应数量的协程从各个kubelet中获取对应的cAdvisor监控信息,进行处理后再返回。
获取到数据后,就需要调用各个processors的Process()接口进行数据处理,接口太多就不一一介绍了,挑个node_aggregator.go进行介绍:
func (this *NodeAggregator) Process(batch *core.DataBatch) (*core.DataBatch, error) {for key, metricSet := range batch.MetricSets {// 判断下该metric是否是pod的// metricSet.Labels都是前面就进行了填充,所以前面说需要注意每个processor的append顺序if metricSetType, found := metricSet.Labels[core.LabelMetricSetType.Key]; found && metricSetType == core.MetricSetTypePod {// Aggregating podsnodeName, found := metricSet.Labels[core.LabelNodename.Key]if nodeName == "" {glog.V(8).Infof("Skipping pod %s: no node info", key)continue}if found {// 获取nodeKey,比如: node:172.25.5.111nodeKey := core.NodeKey(nodeName)// 前面都是判断该pod在哪个node上,然后该node的数据是需要通过这些pod进行累加得到node, found := batch.MetricSets[nodeKey]if !found {glog.V(1).Info("No metric for node %s, cannot perform node level aggregation.")} else if err := aggregate(metricSet, node, this.MetricsToAggregate); err != nil {return nil, err}} else {glog.Errorf("No node info in pod %s: %v", key, metricSet.Labels)}}}return batch, nil
}基本流程就是这样了,有需要的可以各个深入查看。
最后就是数据的后端存储。
这里会涉及到两部分:metricSink和influxdbSink。
从rm.sink.ExportData(data)接口入手:
路径: heapster/metrics/sinks/manager.go
func (this *sinkManager) ExportData(data *core.DataBatch) {var wg sync.WaitGroup// 遍历所有的sink,这里其实就两个for _, sh := range this.sinkHolders {wg.Add(1)// 创建协程,然后将之前获取的data丢入dataBatchChannelgo func(sh sinkHolder, wg *sync.WaitGroup) {defer wg.Done()glog.V(2).Infof("Pushing data to: %s", sh.sink.Name())select {case sh.dataBatchChannel <- data:glog.V(2).Infof("Data push completed: %s", sh.sink.Name())// everything okcase <-time.After(this.exportDataTimeout):glog.Warningf("Failed to push data to sink: %s", sh.sink.Name())}}(sh, &wg)}// Wait for all pushes to complete or timeout.wg.Wait()
}千辛万苦,你把数据丢入sh.dataBatchChannel完事了?
dataBatchChannel有点眼熟,因为之前创建sinkManager的时候,也创建了协程并监听了该管道,所以真正export数据是在之前就完成了,这里只需要把数据丢入管道即可。
所以golang中协程与协程之间的通信,channel才是王道啊!
ExportData有两个,一个一个讲吧。
先来关键的influxDB.
路径: heapster/metrics/sinks/influxdb/influxdb.go
func (sink *influxdbSink) ExportData(dataBatch *core.DataBatch) {...dataPoints := make([]influxdb.Point, 0, 0)for _, metricSet := range dataBatch.MetricSets {// 遍历MetricValuesfor metricName, metricValue := range metricSet.MetricValues {var value interface{}if core.ValueInt64 == metricValue.ValueType {value = metricValue.IntValue} else if core.ValueFloat == metricValue.ValueType {value = float64(metricValue.FloatValue)} else {continue}// Prepare measurement without fieldsfieldName := "value"measurementName := metricNameif sink.c.WithFields {// Prepare measurement and field namesserieName := strings.SplitN(metricName, "/", 2)measurementName = serieName[0]if len(serieName) > 1 {fieldName = serieName[1]}}// influxdb单条数据结构point := influxdb.Point{// 度量值名称,比如cpu/usageMeasurement: measurementName,// 该tags就是在processors中进行添加,主要是pod_name,node_name,namespace_name等Tags: metricSet.Labels,// 该字段就是具体的值了Fields: map[string]interface{}{fieldName: value,},// 时间戳Time: dataBatch.Timestamp.UTC(),}// append到dataPoints,超过maxSendBatchSize数量后直接sendData到influxdbdataPoints = append(dataPoints, point)if len(dataPoints) >= maxSendBatchSize {sink.sendData(dataPoints)dataPoints = make([]influxdb.Point, 0, 0)}}// 遍历LabeledMetrics,主要就是filesystem的数据// 不太明白为何要将filesystem的数据进行区分,要放到Labeled中?什么意图?望高手指点,谢谢// 接下来的操作就跟上面MetricValues的操作差不多了for _, labeledMetric := range metricSet.LabeledMetrics {。。。point := influxdb.Point{Measurement: measurementName,Tags: make(map[string]string),Fields: map[string]interface{}{fieldName: value,},Time: dataBatch.Timestamp.UTC(),}for key, value := range metricSet.Labels {point.Tags[key] = value}for key, value := range labeledMetric.Labels {point.Tags[key] = value}dataPoints = append(dataPoints, point)if len(dataPoints) >= maxSendBatchSize {sink.sendData(dataPoints)dataPoints = make([]influxdb.Point, 0, 0)}}}if len(dataPoints) >= 0 {sink.sendData(dataPoints)}
}该接口中有一处不太明白,metricSet中的LabeledMetrics和MetricsValue有何差别,为何要将filesystem的数据进行区分对待,放入LabeldMetrics?
看代码的过程中没有得到答案,望大神指点迷津,多谢多谢!
有问题,但也不影响继续往下学习,接着看下MetricSink:
func (this *MetricSink) ExportData(batch *core.DataBatch) {this.lock.Lock()defer this.lock.Unlock()now := time.Now()// 将数据丢入longStore和shortStore// 需要根据保存的时间将老数据丢弃this.longStore = append(popOldStore(this.longStore, now.Add(-this.longStoreDuration)),buildMultimetricStore(this.longStoreMetrics, batch))this.shortStore = append(popOld(this.shortStore, now.Add(-this.shortStoreDuration)), batch)
}该逻辑比较简单,就是将数据丢入两个Store中,然后把过期数据丢弃。
这里提醒一点,heapster API调用时先会从longStore中匹配数据,没匹配上的话再从shortStore获取,而longStore中存储的数据类型前面已经做过介绍。
终于结束了。。
Heapster API创建
前面的主流业务都介绍完了,Heapster本身也提供了API用于开发者进行使用与测试。
继续分析代码吧:
// 关键接口,后面分析handler := setupHandlers(metricSink, podLister, nodeLister, historicalSource)。。。// 创建http的mux多分器,用于http.Server的路由mux := http.NewServeMux()// prometheus:最新出现的人气很高的监控系统,值得了解学习下,后续安排!promHandler := prometheus.Handler()// 支持TLS,我们用了httpif len(*argTLSCertFile) > 0 && len(*argTLSKeyFile) > 0 {。。。} else {// 多分器分了"/"和"/metrics"// 进入"/",还会进行细分,里面使用到了go-restfulmux.Handle("/", handler)mux.Handle("/metrics", promHandler)// 注册健康检测接口healthz.InstallHandler(mux, healthzChecker(metricSink))// 启动Serverglog.Fatal(http.ListenAndServe(addr, mux))}这里的关键是setupHandlers()接口,需要学习下里面如何使用go-restful进行请求路由的。
k8s apiServer中也大量使用了go-restful,在学习该源码时有进行过分析
路径: heapster/metrics/handlers.go
func setupHandlers(metricSink *metricsink.MetricSink, podLister *cache.StoreToPodLister, nodeLister *cache.StoreToNodeLister, historicalSource core.HistoricalSource) http.Handler {runningInKubernetes := true// 创建container,指定route类型为CurlyRouter// 这些都跟go-restful基础有关,有兴趣的可以看下原理wsContainer := restful.NewContainer()wsContainer.EnableContentEncoding(true)wsContainer.Router(restful.CurlyRouter{})// 注册v1版本相关的api,包括官方介绍的"/api/v1/model"a := v1.NewApi(runningInKubernetes, metricSink, historicalSource)a.Register(wsContainer)// 这个metricsApi注册了"/apis/metrics/v1alpha1"的各类命令// 暂不关心m := metricsApi.NewApi(metricSink, podLister, nodeLister)m.Register(wsContainer)handlePprofEndpoint := func(req *restful.Request, resp *restful.Response) {name := strings.TrimPrefix(req.Request.URL.Path, pprofBasePath)switch name {case "profile":pprof.Profile(resp, req.Request)case "symbol":pprof.Symbol(resp, req.Request)case "cmdline":pprof.Cmdline(resp, req.Request)default:pprof.Index(resp, req.Request)}}// Setup pporf handlers.ws = new(restful.WebService).Path(pprofBasePath)ws.Route(ws.GET("/{subpath:*}").To(metrics.InstrumentRouteFunc("pprof", handlePprofEndpoint))).Doc("pprof endpoint")wsContainer.Add(ws)return wsContainer
}关键在于v1版本的API注册,继续深入a.Register(wsContainer):
func (a *Api) Register(container *restful.Container) {// 注册"/api/v1/metric-export" API// 用于从shortStore中获取所有的metrics信息ws := new(restful.WebService)ws.Path("/api/v1/metric-export").Doc("Exports the latest point for all Heapster metrics").Produces(restful.MIME_JSON)ws.Route(ws.GET("").To(a.exportMetrics).Doc("export the latest data point for all metrics").Operation("exportMetrics").Writes([]*types.Timeseries{}))// ws必须要add到container中才能生效container.Add(ws)// 注册"/api/v1/metric-export-schema" API// 用于导出所有的metrics name,比如network-rx// 还会导出还有的labels,比如pod-namews = new(restful.WebService)ws.Path("/api/v1/metric-export-schema").Doc("Schema for metrics exported by heapster").Produces(restful.MIME_JSON)ws.Route(ws.GET("").To(a.exportMetricsSchema).Doc("export the schema for all metrics").Operation("exportmetricsSchema").Writes(types.TimeseriesSchema{}))container.Add(ws)// 注册metircSink相关的API,即"/api/v1/model/"if a.metricSink != nil {glog.Infof("Starting to Register Model.")a.RegisterModel(container)}if a.historicalSource != nil {a.RegisterHistorical(container)}
}官方资料中介绍heapster metric model,我们使用到这些API也会比较多。
进入a.RegisterModel(container)看下:
func (a *Api) RegisterModel(container *restful.Container) {ws := new(restful.WebService)// 指定所有命令的prefix: "/api/v1/model"ws.Path("/api/v1/model").Doc("Root endpoint of the stats model").Consumes("*/*").Produces(restful.MIME_JSON)// 在这里增加各类命令,比如"/metrics/,/nodes/"等等addClusterMetricsRoutes(a, ws)// 列出所有的keysws.Route(ws.GET("/debug/allkeys").To(metrics.InstrumentRouteFunc("debugAllKeys", a.allKeys)).Doc("Get keys of all metric sets available").Operation("debugAllKeys"))container.Add(ws)
}继续看addClusterMetricsRoutes():
func addClusterMetricsRoutes(a clusterMetricsFetcher, ws *restful.WebService) {。。。if a.isRunningInKubernetes() {// 列出所有namespaces的APIws.Route(ws.GET("/namespaces/").To(metrics.InstrumentRouteFunc("namespaceList", a.namespaceList)).Doc("Get a list of all namespaces that have some current metrics").Operation("namespaceList"))// 获取指定namespaces的metricsws.Route(ws.GET("/namespaces/{namespace-name}/metrics").To(metrics.InstrumentRouteFunc("availableNamespaceMetrics", a.availableNamespaceMetrics)).Doc("Get a list of all available metrics for a Namespace entity").Operation("availableNamespaceMetrics").Param(ws.PathParameter("namespace-name", "The name of the namespace to lookup").DataType("string")))// 获取namespace指定的metrics值ws.Route(ws.GET("/namespaces/{namespace-name}/metrics/{metric-name:*}").To(metrics.InstrumentRouteFunc("namespaceMetrics", a.namespaceMetrics)).Doc("Export an aggregated namespace-level metric").Operation("namespaceMetrics").Param(ws.PathParameter("namespace-name", "The name of the namespace to lookup").DataType("string")).Param(ws.PathParameter("metric-name", "The name of the requested metric").DataType("string")).Param(ws.QueryParameter("start", "Start time for requested metrics").DataType("string")).Param(ws.QueryParameter("end", "End time for requested metric").DataType("string")).Param(ws.QueryParameter("labels", "A comma-separated list of key:values pairs to use to search for a labeled metric").DataType("string")).Writes(types.MetricResult{}))。。。}。。。
}Heapster API的注册基本就这样了,在花点时间看下API的实现吧。
我们挑一个例子做下分析,获取某个pod的指定的metrics值.
对应的接口:heapster/metrics/api/v1/model_handler.go
func (a *Api) podMetrics(request *restful.Request, response *restful.Response) {a.processMetricRequest(// 根据URI传入的ns和pod名字,拼装成key,如:"namespace:default/pod:123"core.PodKey(request.PathParameter("namespace-name"),request.PathParameter("pod-name")),request, response)
}根据URI的输入参数并调用processMetricRequest()接口,获取对应的metric value:
func (a *Api) processMetricRequest(key string, request *restful.Request, response *restful.Response) {// 时间区间start, end, err := getStartEndTime(request)if err != nil {response.WriteError(http.StatusBadRequest, err)return}// 获取metric Name,比如"/cpu/usage"metricName := request.PathParameter("metric-name")// 根据metricName进行转换,比如将cpu-usage转换成cpu/usage_rate// 所以这里需要注意cpu-usage不等于/cpu/usage,一个表示cpu使用率,一个表示cpu使用量convertedMetricName := convertMetricName(metricName)// 获取请求中的labels,根据是否有指定labels来调用不同的接口labels, err := getLabels(request)if err != nil {response.WriteError(http.StatusBadRequest, err)return}var metrics map[string][]core.TimestampedMetricValueif labels != nil {// 该接口从metricSet.LabeledMetrics中获取对应的valuemetrics = a.metricSink.GetLabeledMetric(convertedMetricName, labels, []string{key}, start, end)} else {// 该接口先从longStoreMetrics中进行匹配,匹配不到的话再从shortStore中获取对应的metricValuemetrics = a.metricSink.GetMetric(convertedMetricName, []string{key}, start, end)}// 将获取到的metricValue转换成MetricPoint格式的值,会有多组"时间戳+value"converted := exportTimestampedMetricValue(metrics[key])// 将结果进行responseresponse.WriteEntity(converted)
}OK,大功告成!API的实现也讲完了,很多API都是相通的,最终都会调用相同的接口,所以不一一介绍了。
这里需要注意heapster的API的URI还有多种写法,比如/api/v1/model/cpu-usage,等价于/api/v1/model/cpu/usage_rate/,别误理解成/cpu/usage了,这两个概念不一样,一个是cpu使用率,一个是cpu使用量。
上面的提醒告诉我们,没事多看源码,很多误解自然而然就解除了!
笔者能力有限,看源码也在于学习提升能力,当然也会有较多不理解或者理解不当的地方,希望各位能予以矫正,多谢多谢!
扩展
上面的介绍完了Heapster的实现,我们可以思考下是否可以动手修改源码,比如增加一些对象的metrics信息。
笔者考虑是否可以直接支持RC/RS/Deployment的metrics信息,让业务层可以直接拿到服务的整体信息。
参考资料
Heapster官方资料:https://github.com/kubernetes...
InfluxDB github: https://github.com/influxdata...
Kubernetes监控之Heapster源码分析相关推荐
- kubeadm源码分析(内含kubernetes离线包,三步安装)
k8s离线安装包 三步安装,简单到难以置信 kubeadm源码分析 说句实在话,kubeadm的代码写的真心一般,质量不是很高. 几个关键点来先说一下kubeadm干的几个核心的事: kubeadm ...
- Kubernetes StatefulSet源码分析
2019独角兽企业重金招聘Python工程师标准>>> Author: xidianwangtao@gmail.com,Based on Kubernetes 1.9 摘要:Kube ...
- Spring Developer Tools 源码分析:二、类路径监控
在 Spring Developer Tools 源码分析一中介绍了 devtools 提供的文件监控实现,在第二部分中,我们将会使用第一部分提供的目录监控功能,实现对开发环境中 classpath ...
- Kubernetes Client-go Informer 源码分析
几乎所有的Controller manager 和CRD Controller 都会使用Client-go 的Informer 函数,这样通过Watch 或者Get List 可以获取对应的Objec ...
- kubeadm源码分析(kubernetes离线安装包,三步安装)
k8s离线安装包 三步安装,简单到难以置信 kubeadm源码分析 说句实在话,kubeadm的代码写的真心一般,质量不是很高. 几个关键点来先说一下kubeadm干的几个核心的事: kubeadm ...
- k8s源码分析 pdf_Spark Kubernetes 的源码分析系列 - features
1 Overview features 包里的代码,主要是用于构建 Spark 在 K8S 中的各类资源所需要的特征,个人觉得可以理解成这些 features 就是帮你写各类 Kind 的 YAML ...
- Kubernetes Node Controller源码分析之配置篇
2019独角兽企业重金招聘Python工程师标准>>> Author: xidianwangtao@gmail.com Kubernetes Node Controller源码分析之 ...
- kubernetes 源码分析之节点异常时 pod 驱逐过程
概述 在 Kubernetes 集群中,当节点由于某些原因(网络.宕机等)不能正常工作时会被认定为不可用状态(Unknown 或者 False 状态),当时间超过了 pod-eviction-time ...
- 【SA8295P 源码分析】28 - QNX Ethernet MAC 驱动 之 emac_mdio_link_monitor_thrd() MDIO监控线程 源码分析
[SA8295P 源码分析]28 - QNX Ethernet MAC 驱动 之 emac_mdio_link_monitor_thrd MDIO监控线程 源码分析 一.emac_mdio_link_ ...
最新文章
- mysql中sql语句
- python日志输出到屏幕,python日志写入文件
- 电气专业的你,2022届求职进展如何?
- php编程习惯,经验分享:PHP编程的5个良好习惯(二)
- 三巨头垄断全球农业-丰收节贸易会:世界最大种子农药公司
- c++中多线程传递参数原理分析
- python求定积分的函数_手搓计算化学(GTO积分by python)
- zabbix 之 配置iptables允许10050端口
- 北大计算机最好的班叫什么,中国大学计算机最好的班,再次迎来“图灵奖”导师,赶超“姚班”...
- 9个有趣的Python小项目,练手必备(附源码)
- Oracle数据库的下载与安装教程详解
- Maven的pom.xml文件配置,热步署(九)
- 解决服务器上传的tar格式的中不可以解压tar格式的压缩包 zip解压中文会在文件中显示乱码
- vue02(脚手架,部署,helloworld)
- 蒋宇捷——程序员的进化 - 在拉勾1024程序员节上的演讲
- 《千与千寻》与《天空之城》配色分享
- 《从零开始搭建游戏服务器》Linux开发环境配置
- C#垃圾回收机制GC
- mac 硬盘未正常推出解决办法
- 计算机2级mysql有用吗_计算机二级证书对程序员并没有什么卵用!