深度学习人体姿态估计算法综述
https://www.infoq.cn/article/6Btg0-1crfmb7svRGa6H
人体骨架是以图形形式对一个人的方位所进行的描述。本质上,骨架是一组坐标点,可以连接起来以描述该人的位姿。骨架中的每一个坐标点称为一个“部分(part)”(或关节、关键点)。两个部分之间的有效连接称为一个“对(pair)“(或肢体)。注意,不是所有的部分之间的两两连接都能组成有效肢体。下图是一个典型的人体骨架举例。
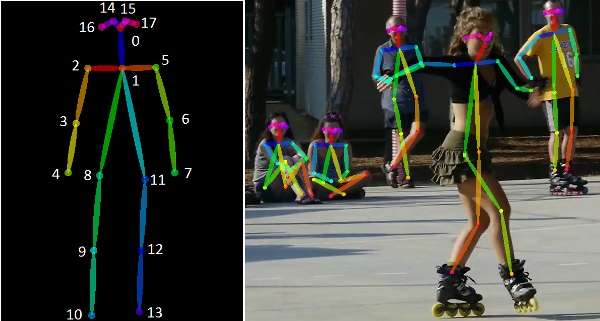
人体姿态估计有多个应用场景,其中一些应用将在本博客的最后讨论。多年来,人们发展出了多种人体姿态估计算法。最早(也是最慢)的方法通常针对图像中仅有一个人的情景,只估计单个人的姿态。这些方法通常首先识别出各个部分,然后在它们之间形成连接以创建姿态。
自然,这种单人姿态估计不太适用于很多现实生活中的情形,因为在真实情况下往往图像中包含很多个人。
多人姿态估计
多人姿态估计比单人姿态估计要难一些,因为图像中的人数以及每个人的位置是未知的。一般来说,我们可以用以下两种方法之一来解决这些问题:
比较简单的方法是先使用一个人体检测器,然后再估计检测器检出的每个人的关节,进而恢复每个人的姿态。这种方法被称为自顶向下的方法。
另外一种方法是先检测出一幅图像中的所有关节(即每个人的关节),然后将检出的关节连接 / 分组,从而找出属于各个人的关节。这种方法叫做自底向上方法。

一般情况下,自顶向下的方法比自底向上的方法更容易实现,因为添加检测算法比增加连接 / 分组算法要简单得多。很难去评判这两种方法哪种的整体性能更好,因为这种性能比较的本质是在比较人体检测器和连接 / 分组算法哪个更好(实际上是没有可比性的)。
在本文中,我们主要介绍基于深度学习算法的多人人体姿态估计。在下一节中,我们将介绍一些当前比较流行的自顶向下和自底向上方法。
深度学习方法
1. OpenPose
OpenPose(https://arxiv.org/pdf/1812.08008.pdf)是当前最流行的几种多人人体姿态估计算法之一。OpenPose 大获成功的一部分原因是它在 GitHub 上开源了其实现代码(https://github.com/CMU-Perceptual-Computing-Lab/openpose),并配有详细的说明文档。
和很多自底向上的方法一样,OpenPose 首先检测出图像中所有人的关节(关键点),然后将检出的关键点分配给每个对应的人。下图展示了 OpenPose 模型的架构。
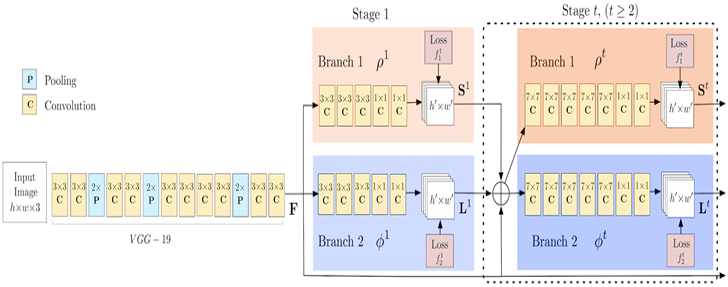
OpenPose 网络首先使用前面的几个网络层(在上面的流程图中使用的是 VGG-19),从图像中提取特征。接下来,这些特征被传给两个平行的卷积层分支。第一个分支用来预测 18 个置信图,每个图代表人体骨架中的一个关节。第二个分支预测一个集合,该集合中包含 38 个关节仿射场(Part Affinity Fields,PAFs),描述各关节之间的连接程度。
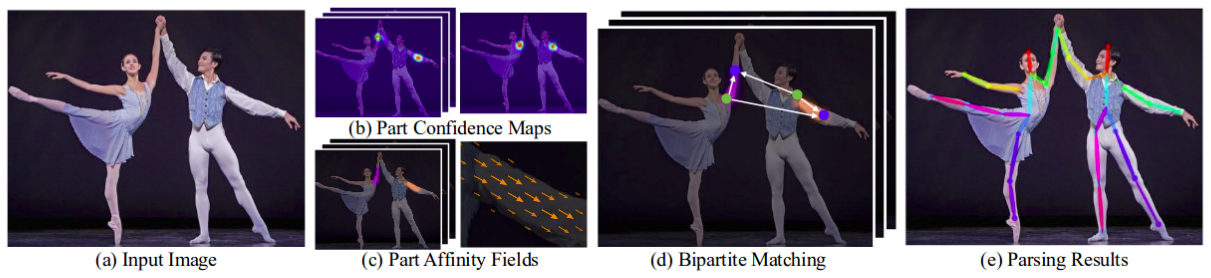
接着,OpenPose 用一连串的步骤来优化每个分支的预测值。使用关节置信图,可以在每个关节对之间形成二分图(如上图所示)。使用 PAF 值,二分图里较弱的连接被删除。通过上述步骤,可以检出图中所有人的人体姿态骨架,并将其分配给正确的人。针对该算法更详细的解释,请参考其论文:
https://arxiv.org/pdf/1812.08008.pdf
和这篇博客:
https://arvrjourney.com/human-pose-estimation-using-openpose-with-tensorflow-part-2-e78ab9104fc8。
2. DeepCut
DeepCut(https://arxiv.org/abs/1511.06645)是一个自底向上的多人人体姿态估计方法。针对人体姿态估计任务,作者定义了以下问题:
生成一个由 D 个关节候选项组成的候选集合。该集合代表了图像中所有人的所有关节的可能位置。在上述关节候选集中选取一个子集。
为每个被选取的人体关节添加一个标签。标签是 C 个关节类中的一个。每个关节类代表一种关节,如“胳膊”“腿”“躯干”等。
将被标记的关节划分给每个对应的人。

上述几个问题可以被建模为整数线性规划问题(ILP,链接:https://en.wikipedia.org/wiki/Integer_programming),从而被一起解决。考虑二值随机变量的三元组 (x,y,z),其中的二值变量的域如下图所示:
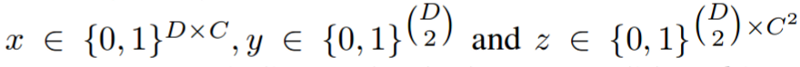
考虑候选集 D 中的两个候选关节 d 和 d’,以及类别集 C 中的两个类 c 和 c’。关节候选项是通过 Faster RCNN(https://arxiv.org/abs/1506.01497)或稠密 CNN 获得的。现在,我们有下述声明:
如果 x(d,c) = 1,代表候选关节 d 属于类别 c。
同样,x(d,d’) = 1 代表候选关节 d 和 d’属于同一人。
作者还定义了 z(d,d’,c,c’) = x(d,c) * y(d,d’)。如果上式值为 1,则代表候选关节 d 属于类别 c,候选关节 d’属于类别 c’,且候选关节 d 和 d’属于同一人。
最后一个声明可以用于划分不同人的姿态。显然,上述声明可以表示成关于 (x,y,z) 的线性方程组。这样一来,整数线性规划(ILP)的模型就建立好了,多人姿态估计就可以化为解这组线性方程的问题。想要了解线性方程组的具体形式和更详细的分析,请参见原论文(链接:https://arxiv.org/pdf/1511.06645.pdf)。
3. RMPE(AlphaPose)
RMPE(https://arxiv.org/abs/1612.00137)是一个流行的自顶向下姿态估计算法。该论文的作者认为,自顶向下方法的性能通常依赖于人体检测器的精度,毕竟人体姿态估计是在检测器检出的框的区域内进行的。因此,错误的定位和重复的候选框会使姿态检测算法的性能降低。

为解决这一问题,作者提出了使用对称空间变换网络(Symmetric Spatial Transformer Network,SSTN)来从不准确的候选框中抽取高质量的单人区域。然后,作者使用了一个单人的姿态估计器(Single Person Pose Estimator,SPPE)来从抽取到的区域中估计此人的姿态骨架。接着,作者用一个空间逆变换网络(Spatial De-Transformer Network,SDTN),将估计出的姿态重新映射到图像坐标系下。最后,用一个参数化的姿态非极大抑制(Non-Maximum Suppression,NMS)方法来处理重复预测的问题。
另外,作者还引入了一种姿态候选生成器(Pose Guided Proposals Generator),来增广训练样本,以便更好地训练 SPPE 和 SSTN 网络。RMPE 的显著特征是,该方法可以推广到任意的人体检测算法和 SSPE 的组合。
4. Mask RCNN
Mask RCNN(https://arxiv.org/abs/1703.06870)是一个非常流行的语义和实例分割架构。该模型可以同时预测图像中多个物体的候选框位置及分割其语义信息的 mask。该模型的基础架构很容易被扩展到人体姿态估计上来。
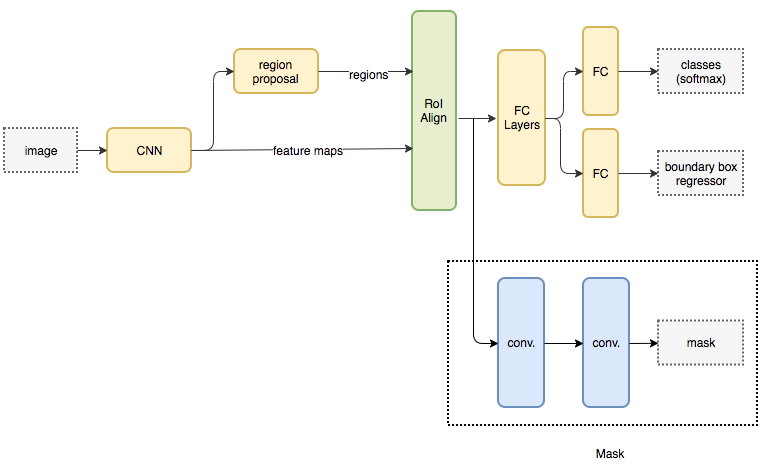
其基本架构首先使用 CNN 从图像中提取特征图。这些特征接着被用于一个区域候选网络(Regin Proposal Network, RPN)来为各个对象生成候选框。候选框会从 CNN 提取出的特征图中选取一个区域。由于候选框可能会有多种尺寸,网络接下来会采用一个层,称为 RoIAlign,用来减小特征图的尺寸,使它们具有相同的尺寸。现在,抽取出的特征被传给平行的 CNN 分支,用来输出候选框和分割 mask 的最终预测。
我们现在主要关注一下分割的分支。假设我们图像中的对象可以属于 K 个类别中的一个。分割分支输出 K 个尺寸为 m*m 的二值 mask,每个二值 mask 代表只属于该类别的所有对象。我们可以将每种特征点建模为一个类别,然后将姿态估计任务看作一个分割任务,从而提取图像中每个人的特征点。
与此同时,可以训练一个对象检测算法来确定每个人的位置。通过组合每个人的位置信息和他们的特征点集合,我们可以得到图像中每个人的人体骨架。
该方法和自顶向下方法比较类似,但不同的是,其人体检测步骤和关键点检测步骤是同时进行的。换句话说,人体检测步骤和关键点检测步骤是相互独立的。
5. 其他方法
多人人体姿态估计是一个很大的问题,有许多其他方法。限于篇幅,我们只选择了其中的几种方法在本文中加以介绍。如需要获取更详尽的方法列表,请参见以下链接:
人体姿态估计的优秀方法(Awesome Human Pose Estimation,https://github.com/cbsudux/awesome-human-pose-estimation)
论文及代码(Papers with Code,https://paperswithcode.com/sota/multi-person-pose-estimation-on-mpii-multi)
应用
姿态估计可以应用在很多领域。接下来就列举其中的一些。
1. 动作识别
追踪一段时间内一个人姿态的变化也可以应用在动作、手势和步态识别上。在这方面有好几个应用场景,包括:
用于检测一个人是否摔倒或疾病
用于健身、体育和舞蹈等的自动教学
用于理解全身的肢体语言(如机场跑道信号、交警信号等)
用于增强安保和监控

2. 运动捕捉和增强现实
人体姿态估计的一个有趣应用是 CGI(computer graphic image,一种电影制造技术)应用。如果可以检测出人体姿态,那么图形、风格、特效增强、设备和艺术造型等就可以被加载在人体上。通过追踪人体姿态的变化,渲染的图形可以在人动的时候“自然”地与人“融合”。

姿态估计的一个很好的可视化例子是 Animoji(https://www.wired.com/story/all-the-face-tracking-tech-behind-apples-animoji/)。虽然在 Animoji 中只是跟踪了人脸的结构,但这个技术可以被扩展到人体关键点上。同样的概念可以被用于渲染增强现实(AR)元素,使其能够模仿人的运动。
3. 训练机器人
除了手动为机器人编程、让它们跟随特定的路径,我们也可以让机器人跟随一个做特定动作的人体骨架。人类教练可以仅通过演示特定的动作,来教机器人学习这一动作。接着,机器人就可以计算如何移动自己的活动关节,来进行相同的动作。
4. 控制台中的运动追踪
姿态估计的一个有趣应用是在交互游戏中追踪人体对象的运动。比较流行的 Kinect 使用 3D 姿态估计(采用 IR 传感器数据)来追踪人类玩家的运动,从而利用它来渲染虚拟人物的动作。
结论
人体姿态估计领域发展迅速,因此可以应用在越来越多的任务上。另外,相关领域的研究,例如姿态追踪,可以大大增强姿态估计的应用范围。本文列举的概念并不全面,但介绍的几个算法和应用较为典型,适合入门者阅读。
本文首发于 medium 平台,英文原文链接:https://medium.com/beyondminds/an-overview-of-human-pose-estimation-with-deep-learning-d49eb656739b
转载于:https://www.cnblogs.com/davidwang456/articles/10898205.html
深度学习人体姿态估计算法综述相关推荐
- 人工智能 信道估计 深度学习_深度学习人体姿态估计算法综述
作者 | Bharath Raj 译者 | 李志 编辑 | Vincent AI 前线导读:人体姿态估计的任务是从包含人体的图片中检测出人体关键点,并恢复人体位姿.随着深度学习的发展,越来越多的深度学 ...
- 深度学习-人体姿态估计
个人微信公众号:AI研习图书馆 ID:(Art-Intelligence) 欢迎关注,交流学习,共同进步~ 1.人体姿态估计简介 人体姿态估计(Human Posture Estimation),是通 ...
- 深度学习人体姿态估计:2014-2020全面调研
今天分享一篇人体姿态估计综述. 来自北卡夏洛特, 戴顿大学, 德州大学达拉斯分校,中佛罗里达大学的研究人员对该领域的研究发展进行了综述.基于输入数据和推理程序的系统分析和比较,作者对基于深度学习的 2 ...
- 2019深度学习人体姿态估计指南
本文素材来源于nanonets技术博客网站,经本人编辑首发于CSDN,仅供技术分享所用,不作商用. 原文地址:https://blog.nanonets.com/human-pose-estimati ...
- OpenCV进阶(6)基于OpenCV的深度学习人体姿态估计之多人篇
在之前的文章中,我们使用OpenPose模型对一个人进行人体姿势估计.在这篇文章中,我们将讨论如何进行多人姿势估计. 当一张照片中有多个人时,姿态估计会产生多个独立的关键点.我们需要找出哪组关键点属于 ...
- 从DeepNet到HRNet,这有一份深度学习“人体姿势估计”全指南
大数据文摘出品 来源:blog.nanonets 作者:栾红叶.熊琰.周家乐.钱天培 从DeepNet到HRNet,这有一份深度学习"人体姿势估计"全指南 几十年来,人体姿态估计( ...
- 病虫害模型算法_基于深度学习的目标检测算法综述
sigai 基于深度学习的目标检测算法综述 导言 目标检测的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小,是机器视觉领域的核心问题之一.由于各类物体有不同的外观,形状,姿态,加上成像 ...
- 基于深度学习的目标检测算法综述(一)
基于深度学习的目标检测算法综述(一) 基于深度学习的目标检测算法综述(二) 基于深度学习的目标检测算法综述(三) 本文内容原创,作者:美图云视觉技术部 检测团队,转载请注明出处 目标检测(Object ...
- 基于深度学习的目标检测算法综述(从R-CNN到Mask R-CNN)
深度学习目标检测模型全面综述:Faster R-CNN.R-FCN和SSD 从RCNN到SSD,这应该是最全的一份目标检测算法盘点 基于深度学习的目标检测算法综述(一) 基于深度学习的目标检测算法综述 ...
最新文章
- C++ 中multiset 的使用
- JavaScript 学习笔记 之事件
- I2C死锁原因及解决方法
- JavaScript 更新对象属性
- 双向链表VS单向链表
- Spring MVC —— 前后台传递JSON
- Azure下通过Powreshell批量添加、删除VM终结点
- Jacobi matrix——一种对向量方程的梯度描述方式
- 51Nod-1259-整数划分 V2
- 重磅!Intel联合OpenStack基金会发布Kata Container项目
- QQ邮箱服务器协议,理解邮件服务流程——SMTP、IMAP、POP3 协议
- PS图片上传图片 同时生成微缩图
- 消息中间件RabbitMQ
- java list逆序_Java使用ListIterator逆序ArrayList
- Maven的settings.xml文件结构之Servers,Mirror和Repository
- SOMv3.3.3二次开发中LUA脚本对机基础操作指南
- 操作系统内核Hack:(二)底层编程基础
- Python之爬虫 搭建代理ip池
- 我用python分析了李子柒的辣酱真的好吃吗?
- jdk11 下载与安装(非常详细,一步不落!!!)
热门文章
- java map输出中括号,从地图检索数据时获取双方括号
- java socket回调_Java ServerSocketChannel SocketChannel(回调)
- 全志uboot修改_全志SDK编译问题解决二:build uboot only
- c++ 冒泡排序_学习笔记-详解冒泡排序
- 剪切工具怎么用_原创度检测工具是怎么用的?优质的内容更容易获得平台推荐...
- 三星note4安装linux,Leanote Ubuntu 源码安装
- python搭建自动化测试平台_如何用python语言搭建自动化测试环境
- 怎么批量抠复杂的图_怎么用手机修图,抠图、拼图,证件照制作?
- mysql join大小表顺讯_MySQL优化器join顺序
- halcon 定位_HALCON高级篇:单个相机的尺寸测量