DQN 笔记 State-action Value Function(Q-function)
1 State-action Value Function(Q-function)
1.1 和 状态价值函数的对比
在DQN笔记:MC & TD_UQI-LIUWJ的博客-CSDN博客 中,状态价值函数的输入是一个状态。它是根据状态去计算出,看到这个状态以后,累积奖励的期望是多少。
状态-动作价值函数【State-action Value Function】的输入是一个状态、动作对。它的意思是说,在某一个状态采取某一个动作,假设我们都使用演员 π ,得到的累积奖励的期望值有多大。
1.2 一个需要注意的问题
有一个需要注意的问题是,这个演员π,在看到状态 s 的时候,它采取的动作不一定是 a。
Q-function 假设在状态 s 强制采取动作 a。不管你现在考虑的这个演员π, 它会不会采取动作 a,这不重要。在状态 s 强制采取动作 a。
接下来的状态就进入”自动模式“,让演员π 按照他设定的策略继续玩下去。这样得到的期望奖励才是
1.3 两种写法
Q-function 有两种写法:
- 输入是状态跟动作,输出就是一个标量;
![]()
- 输入是一个状态,输出就是好几个值。
![]()
假设动作是离散的,动作就只有 3 个可能:往左往右或是开火。
那这个 Q-function 输出的 3 个值就分别代表 a 是向左的时候的 Q 值,a 是向右的时候的 Q 值,还有 a 是开火的时候的 Q 值。
要注意的事情是,这种写法只有离散动作才能够使用。如果动作是无法穷举的,你只能够用第一种写法,不能用第二种写法。
2 策略改进
有了这个 Q-function,我们就可以决定要采取哪一个动作,我们就可以进行策略改进(Policy Improvement)了。
2.1 大致思路
大致思路如下,假设你有一个初始的演员π,这个 π 跟环境互动,会收集数据。
接下来学习一个演员π的 Q 值(衡量一下π 在某一个状态强制采取某一个动作,接下来用π 这个策略 会得到的期望奖励)【TD,MC皆可】
学习出一个 Q-function 以后,就可以去找一个新的策略 π′ ,π′ 一定会比原来的策略π 还要好。
这样一直循环下去,policy 就会越来越好。
2.2 什么是更好的策略?
这边”好“是说,对所有可能的状态 s 而言,。
也就是说我们走到同一个状态 s 的时候,如果拿π 继续跟环境互动下去,我们得到的奖励一定会小于等于用π′ 跟环境互动下去得到的奖励。
2.3 如何找更好的策略?
有了 Q-function 以后,怎么找这个 π′ 呢?
![]()
我们可以根据上式来查找 π′
假设你已经学习出π 的 Q-function,今天在某一个状态 s,你把所有可能的动作 a 都一一带入这个 Q-function,看看哪一个 a 可以让 Q-function 的值最大,那这个动作就是π′ 会采取的动作。
这边要注意一下,给定这个状态 s,你的策略π 并不一定会采取动作a,我们是给定某一个状态 s 强制采取动作 a,用π 继续互动下去得到的期望奖励,这个才是 Q-function 的定义。
2.4 为什么用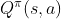 决定出来的 π′ 一定会比π 好?
决定出来的 π′ 一定会比π 好?
这里也就是要说明,假设有一个策略叫做 π′,它是由决定的。我们要证对所有的状态 s 而言,
。
首先,
。因为在状态 s根据π 这个演员,它会采取的动作就是π(s)
同时,我们根据策略更新的方式,知道:(因为 a 是所有动作里面可以让 Q 最大的那个动作)
而最大的那个动作就是π′(s),所以有:
于是有:
而 π只是当前状态为s的时候,是会导致最大的Q(s,a),之后的各个状态s',则不一定是最大的Q(s',a)。而π' 会保证所有的状态s,Q(s,a)都是最大的。所以后者一定大于等于前者。
所以,我们可以估计某一个策略的 Q-function,接下来你就可以找到另外一个策略 π′ 比原来的策略还要更好。
3 target network
![]()
我们在学习 Q-function 的时候,也会用到 TD:在状态st,你采取动作at 以后,你得到奖励rt ,然后跳到状态
。然后根据这个 Q-function,会得到:
所以在学习的时候,我们希望我们的Q-function,输入st,at 得到的值,跟输入
得到的值中间,我们希望它差了一个rt。
但是实际上这样的一个输入并不好学习。
假设这是一个回归问题,
是网络的输出,
是目标,你会发现目标也是会随着训练过程而动的。
当然要实现这样的训练,其实也没有问题,就是你在做反向传播的时候,
的参数会被更新,这样会导致训练变得不太稳定,因为假设你把
解决方法是,你会把其中一个 Q 网络,通常是你会把右边这个 Q 网络固定住。
也就是说你在训练的时候,你只更新左边的 Q 网络的参数,而右边的 Q 网络的参数会被固定住。
因为右边的 Q 网络负责产生目标,所以叫
目标网络 target network。
因为目标网络是固定的,所以你现在得到的目标因为目标网络是固定的,我们只调左边网络的参数,它就变成是一个回归问题。
在实现的时候,可以左边的 Q 网络更新好几次以后,再去用更新过的 Q 网络替换这个目标网络。
但左右两个Q网络不要一起动,它们两个一起动的话,结果会很容易不稳定。
(思路和PPO 有点类似强化学习笔记:PPO 【近端策略优化(Proximal Policy Optimization)】_UQI-LIUWJ的博客-CSDN博客_ppo算法
3.1 形象的例子诠释target network
我们可以通过猫追老鼠的例子来直观地理解为什么要 fix target network。猫是
Q estimation,老鼠是Q target。一开始的话,猫离老鼠很远,所以我们想让这个猫追上老鼠。
因为 Q target 也是跟模型参数相关的,所以每次优化后,Q target 也会动。这就导致一个问题,猫和老鼠都在动。
然后它们就会在优化空间里面到处乱动,就会产生非常奇怪的优化轨迹,这就使得训练过程十分不稳定。
所以我们可以固定 Q target,让老鼠动得不是那么频繁,可能让它每 5 步动一次,猫则是每一步都在动。
如果老鼠每 5 次动一步的话,猫就有足够的时间来接近老鼠。然后它们之间的距离会随着优化过程越来越小,最后它们就可以拟合,拟合过后就可以得到一个最好的Q 网络。
4 探索
4.1 遇到的问题
当我们使用 Q-function 的时候,policy 完全取决于 Q-function。给定某一个状态,你就穷举所有的 a, 看哪个 a 可以让 Q 值最大,它就是采取的动作。——value based
这个跟策略梯度不一样,在做策略梯度的时候,输出其实是随机的。我们输出一组动作的概率分布,根据这组动作的概率分布去做采样, 所以在策略梯度里面,你每次采取的动作是不一样的,是有随机性的。——policy based强化学习笔记:Policy-based Approach_UQI-LIUWJ的博客-CSDN博客
而对于Q-function,如果每次采取的动作总是固定的,会有什么问题呢?
会遇到的问题就是这不是一个好的收集数据的方式。因为计算Q(S,a)的时候,除了第一步强制指定的动作a之外,之后的每一步都只确定性地取决策,丧失了exploration的机制。
4.2 解决方法
这个问题其实就是探索-利用窘境(Exploration-Exploitation dilemma)问题。
我们使用Epsilon Greedy(ε-greedy) ,和generalized policy iteration with MC 中的一致
DQN 笔记 State-action Value Function(Q-function)相关推荐
- JavaScript学习笔记02【基础——对象(Function、Array、Date、Math)】
w3school 在线教程:https://www.w3school.com.cn JavaScript学习笔记01[基础--简介.基础语法.运算符.特殊语法.流程控制语句][day01] JavaS ...
- 台湾国立大学郭彦甫Matlab教程笔记(6)user define function
台湾国立大学郭彦甫Matlab教程笔记(6)user define function 这一部分是function的讲解 scripts vs. functions 1.scripts and func ...
- ABAP学习笔记之——第十一章:Function ALV
一.Function ALV Function ALV 从名字中可以推出,是由 Function(函数)形式提供,因此开发者只需适当使用以有的功能即可.没有必要创建屏幕也没有必要一一写出代码,因此可认 ...
- DQN 笔记 double DQN
1 DQN的问题 在DQN 笔记 State-action Value Function(Q-function)_UQI-LIUWJ的博客-CSDN博客 中,我们知道DQN的学习目标是 但是,这个Q的 ...
- function java_java.util.function之function
Function类包含四种方法,其中一个抽象方法apply(),两个default方法andThen()和compose(),以及一个静态方法identity(). 实例化Function的时候需要实 ...
- ( function(){…} )()和( function (){…} () )是两种立即执行函数
函数声明:function fnName () {-}; 函数表达式 var fnName = function () {-}; 匿名函数:function () {}; fnName(); func ...
- js立即执行函数: (function ( ){...})( ) 与 (function ( ){...}( ))
( function(){-} )() ( function (){-} () ) 是两种javascript立即执行函数的常见写法,最初我以为是一个括号包裹匿名函数,再在后面加个括号调用函数,最后达 ...
- Loss Function , Cost Function and Kernel Function in ML(To be continued)
机器学习中的损失函数.代价函数.核函数 1.Definiton Shark Machine Learning Library–分别有介绍 "objective function, cost ...
- window. onload=function(){} 与 $(function(){}) 的区别
页面加载事件:window.οnlοad=function(){} 和 $(function(){}); 1.window.οnlοad=function(){}是js原生的事件: 2.$(funct ...
最新文章
- 《赛博朋克2077》是捏脸游戏?上科大学生社团开发了一款赛博“滤镜”
- 两台电脑通过usb共享网络_避开网络限制,通过蓝牙共享网络连接
- 已知服务器ftp的账号密码,求解数据库表的内容
- Javascript闭包概念剖析
- javascript实现自动添加文本框功能
- 做人真善美,做事拖后腿
- Selenium alert 弹窗处理
- 六级词汇打卡第三天(三)
- xposed环境搭建
- request.form 和 Request.QueryString 区别
- Wannacry勒索病毒样本分析
- HTML——表白(效果+代码)
- unity 使物体跟随路径点自动移动位置 插值旋转
- 实验吧-web-天下武功唯快不破
- 六. 先有鸡还是先有蛋?--SLAM
- linux 登陆 历史,linux记录每次登陆的历史命令
- Vue,React,微信小程序,快应用,TS 和 Koa 一把梭
- 基于PHP的鲜花商城系统
- 关于Unity3D的初步学习研究周记
- Logi-KafkaManager安装