贝叶斯推断应用:垃圾邮件过滤
附上新博客地址:月光森林
引入
仍然是“信息内容安全” 课程的一个实验总结。为了理解整个原理,不但重新复习了一边贝叶斯,还因为对“联合概率”理解不透彻,直接翻译了一篇文章 —— 联合概率(翻译)。特此对整个实验进行总结。
准备
- 50封邮件,25封垃圾邮件和25封正常邮件
- 操作系统: ubuntu 16.04
- python版本: 3.5.2
- 参考 :
- 贝叶斯推断及互联网应用(一):定理简介
- 贝叶斯推断及互联网应用(二):过滤垃圾邮件
- Combining Probabilities
- 联合概率(翻译)
文档树
.
├── bayes.py
├── test
│ ├── 18.txt
│ └── 4.txt
├── train
│ ├── ham
│ │ ├── 1.txt
│ │ ├── …
│ │ ├── 3.txt
│ │ ├── 5.txt
│ │ ├── …
│ │ └── 25.txt
│ └── spam
│ ├── 1.txt
│ ├── …
│ ├── 17.txt
│ ├── 19.txt
│ ├── …
│ └── 25.txt
└── tree.txt4 directories, 52 files
bayes.py 文件是整个垃圾邮件分类的python代码,因为整个邮件分类是基于贝叶斯推断的,所以起名为bayes.py 。
train文件夹 下是训练邮件集,其中ham文件夹下的都是正常邮件,spam文件夹下都是垃圾邮件。
test文件夹是测试集 因为老师只给了垃圾邮件和正常邮件各25封,所以从这两个类别当中分别随机抽取了一封作为测试邮件。从文档树中可以看到,其中test文件夹下的 ‘4.txt’ 和 ‘18.txt’ 就是指随即抽取的邮件是ham中的第4封邮件和spam中的第18封邮件
tree.txt 是用 linux 命令 elonlin@TARDIS:~$ tree > tree.txt 生成的文档树文件,就是上面的文档树。大部分重复性不利于总览的内容本人用省略号代替了并且重新调整了一下这个树的姿势,总之是为了方便一览了。
程序过程解释
垃圾邮件分类的数学基础是贝叶斯推断(bayesian inference)。整个程序过程主要有以下几个部分构成:
step 1 : 提取邮件并处理
- 使用 os 模块中的
listdir(path)命令获得 path 指示的文件夹下的所有文件的文件名 - 用
with open(file) as f :打开文件,使用文件的read()方法 读取文件内容到一个名为 txt 的字符串。 删除 txt 中的标点符号,这个步骤可参考
在Python去掉标点符号字符串的最佳方式 中的回答: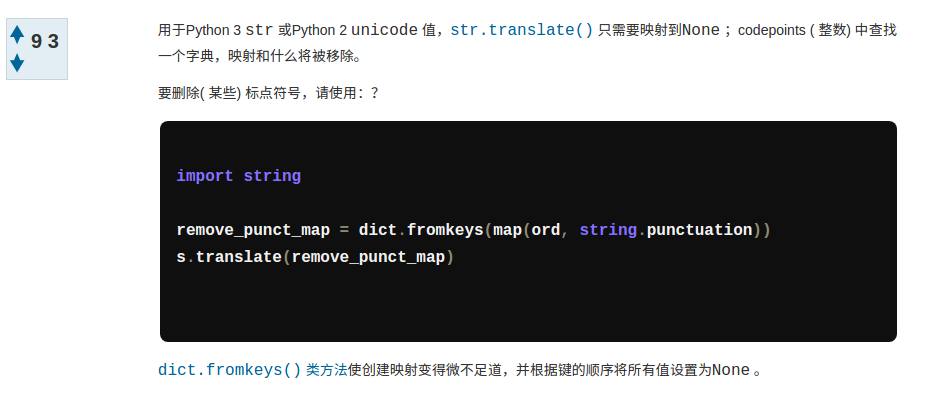
区别在于我的代码中将所有的标点映射为空格,所以 fromkeys 的代码变成了remove_punct = dict.fromekeys(map(ord, string.punctuation), ' ') s.translate(remove_punct)使用字符串的
split()方法将提取出的字符串分割开,并将所有单词放入一个set()容器当中。
以上四个步骤全部包含在 bayes.py 的 getEmail(emailClass) 函数 和 processEmail(email) 函数中。
step 2 : 获得在 ham 和 spam 中每个单词的频数
这个步骤在代码中只是一个函数 getWordFrequency(emailClass) 。emailClass 表示邮件类别,即 ham 或者 spam 。返回的是一个字典,字典的 key值是单词,value值是这个单词的频数。
另外要说明的是,这里的频数并不是指这个单词出现了多少次,而是指这个单词在多少封邮件当中出现过。例如:一个单词 sex 出现在3封邮件中,分别出现了3次,4次,2次,则这个单词 sex 的频数我们这里确定为3(因为它出现在3封邮件中),而不是 3 + 4 + 2 = 9 。
step 3 : 计算每个单词的后验概率
这一段代码包含在(某种意义上的)“主函数”当中 :
- 通过step 1和 step 2定义的函数取得 ham 和 spam 中每个单词的频数及每个类别邮件的数量;
- 创建单词的先验概率字典
preiorProbability{},并初始化每一个单词的先验概率为0.00; - 使用
for...in...循环得到每个单词的先验概率,这里采用的公式阮一峰老师博客里提到的:
P(S|W)=P(W|S)P(S)P(W|S)P(S)+P(W|H)P(H)P(S|W)=P(W|S)P(S)P(W|S)P(S)+P(W|H)P(H)P(S | W) = \frac {P(W | S)P(S)} {P(W | S)P(S) + P(W|H)P(H)}
因为ham和spam的邮件数量相同,所以其先验概率 P(S)P(S)P(S) 和 P(H)P(H)P(H) 是相同的,均为 50%50%50\%, 所以公式简化为 :
P(S|W)=P(W|S)P(W|S)+P(W|H)P(S|W)=P(W|S)P(W|S)+P(W|H)P(S|W) = \frac {P(W | S)} {P(W | S) + P(W | H)}
在代码中 P(W|S)P(W|S)P(W | S) 用spamProbability 变量表示, P(W|H)P(W|H)P(W | H) 用 hamProbability 表示。
如果当前单词在某个类别当中没有出现过,则可规定这个单词在这个类别中的后验概率是 0.010.010.01, 这个值也是阮一峰老师博客当中提到的。
step 4 : 分类函数
这过步骤主要体现在 bayes.py 中的 testEmail(email, threshold = 0.5) 函数中。email 参数表示email文件, threshold参数表示阀值,当计算得到的结果大于threshold时表示这是一封垃圾邮件(spam), 否则这是一封正常邮件(ham), 这里默认 threshold = 0.5。
对于给定的测试email,计算过程如下 :
- 使用
processEmail()函数处理得到这封email的单词集合wordSet 。 - 将这封邮件中每个单词和它的后验概率放入列表
posteriorProbabilityOfThisEmail[]中 ,如果这个单词在字典posteriorProbability{}中并没有出现过,则指定其值为 0.40.40.4, 这也是阮一峰老师博客当中提到的。 - 按照每个单词的概率值从大到小排序。sort函数的用法可参考Python3 的list.sort函数。
- 最后,计算联合概率。这个地方关于联合概率的计算可以参考本人的之前的翻译:联合概率(翻译),文中也给出了原文链接。这里只取出先验概率最大的前15个词计算联合概率,公式为:
P=∏14j=0Pj∏14j=0Pj+∏14j=0(1−Pj)P=∏j=014Pj∏j=014Pj+∏j=014(1−Pj)P = \frac {\prod_{j = 0}^{14}P_j} {\prod_{j = 0}^{14}P_j + \prod_{j = 0}^{14}(1 - P_j)}
这里 ∏14j=0Pj∏j=014Pj\prod_{j = 0}^{14}P_j 用 变量fracTop 在for...in...循环中累乘表示, 用变量fracBottom累乘表示 ∏14j=0(1−Pj)∏j=014(1−Pj)\prod_{j = 0}^{14}(1 - P_j) 。
- 返回判定结果,如果
fracTop / (fracTop + fracBottom)的值大于阀值threshold则判定为spam, 否则判定为 ham 。
step 5 : 准备工作完成,开始测试
读取”./test/” 文件夹下的两个文件进行测试,这个步骤也是放在 “主函数”当中的。然后,就等待判定结果吧。
完整代码
#/usr/bin/python3
#coding :utf-8import os, string# step 1 : get E-mail and process them
def processEmail(email) :remove_punct = dict.fromkeys(map(ord, string.punctuation), ' ')with open(email) as f:txt = f.read()txt = txt.translate(remove_punct)return set(txt.split())def getEmail(emailClass) :path = './train/' + emailClass + '/'email = [processEmail(path + fileName) for fileName in os.listdir(path)]return email, len(os.listdir(path))# step 2 : get word frequency of the email's classdef getWordFrequency(emailClass) :emailWordSet, emailCount = getEmail(emailClass)wordict = {}for wordSet in emailWordSet :for word in wordSet :wordict[word] = wordict.setdefault(word, 0) + 1return wordict, emailCount# step 4 : calculate classified result of test email
def testEmail(email, threshold = 0.5) :wordSet = processEmail(email)posteriorProbabilityOfThisEmail = []for word in wordSet :if word in posteriorProbability :probability = posteriorProbability[word]else :probability = 0.4posteriorProbabilityOfThisEmail.append((word, probability))posteriorProbabilityOfThisEmail.sort(key = lambda x: x[1], reverse = True)fracTop,fracBottom = 1, 1for i in range(max(len(posteriorProbabilityOfThisEmail), 15)) :fracTop *= posteriorProbabilityOfThisEmail[i][1]fracBottom *= 1 - posteriorProbabilityOfThisEmail[i][1]return 'spam' if fracTop / (fracTop + fracBottom) > threshold else 'ham'#step 3: calculate posterior probability
ham, hamEmailCount = getWordFrequency('ham')
spam,spamEmailCount = getWordFrequency('spam')
posteriorProbability = dict.fromkeys((list(ham) + list(spam)), 0)
for word in posteriorProbability :hamPriority = ham[word] / hamEmailCount if word in ham else 0.01spamPriority = spam[word] / spamEmailCount if word in spam else 0.01posteriorProbability[word] = spamPriority / (hamPriority + spamPriority)#step 5 : test start
path = './test/'
for fileName in os.listdir(path) :result = testEmail(path + fileName)print ("the result of '", fileName, "' : ", result)
最终结果

perfect~
贝叶斯推断应用:垃圾邮件过滤相关推荐
- 朴素贝叶斯算法实现垃圾邮件过滤
朴素贝叶斯算法实现垃圾邮件过滤 1.1 题目的主要研究内容 (1)贝叶斯垃圾邮件过滤技术是一种电子邮件过滤的统计学技术,它使用贝叶斯分类来进行垃圾邮件的判别. (2)贝叶斯分类的运作是借着使用标记(一 ...
- 朴素贝叶斯算法实现垃圾邮件过滤(Python3实现)
目录 1.朴素贝叶斯实现垃圾邮件分类的步骤 2.邮件数据 3.代码实现 4.朴素贝叶斯的优点和缺点 1.朴素贝叶斯实现垃圾邮件分类的步骤 (1)收集数据:提供文本文件. (2)准备数据:将文本文件解析 ...
- python:基于朴素贝叶斯算法的垃圾邮件过滤分类
目录 一.朴素贝叶斯算法 1.概述 2.推导过程 二.实现垃圾邮件过滤分类 1.垃圾邮件问题背景 2.朴素贝叶斯算法实现垃圾邮件分类的步骤 3.python实现 参考学习网址:https://blog ...
- 贝叶斯算法:垃圾邮件过滤
准备 100封邮件,50封垃圾邮件和50封正常邮件 参考 : 贝叶斯算法原理 程序过程解释 垃圾邮件分类的数学基础是贝叶斯推断(bayesian inference).整个程序过程主要 ...
- 机器学习:朴素贝叶斯算法与垃圾邮件过滤
简介 贝叶斯算法是由英国数学家托马斯·贝叶斯提出的,这个算法的提出是为了解决"逆向概率"的问题.首先我们先来解释下正向概率与逆向概率的含义: 正向概率:假设一个箱子里有5个黄色球和 ...
- 【机器学习实战】朴素贝叶斯应用之垃圾邮件过滤
1.什么是朴素贝叶斯 2.贝叶斯公式 3.朴素贝叶斯常用的三个模型 4.朴素贝叶斯实现垃圾邮件过滤的步骤 5.垃圾邮件过滤实验: (一).准备收集好的数据集,并下载到本地文件夹 (二).朴素贝叶斯分类 ...
- 利用贝叶斯算法对垃圾邮件进行分类处理
代码及注释如下: #使用贝叶斯算法实现垃圾邮件过滤 #将一个大字符串解析为字符串列表 def textParse(bigString):import relistOfTokens = re.split ...
- 基于朴素贝叶斯+Python实现垃圾邮件分类和结果分析
基于朴素贝叶斯+Python实现垃圾邮件分类 朴素贝叶斯原理 请参考: 贝叶斯推断及其互联网应用(二):过滤垃圾邮件 Python实现 源代码主干来自: python实现贝叶斯推断--垃圾邮件分类 我 ...
- 利用朴素贝叶斯算法识别垃圾邮件
转载自:http://blog.csdn.net/wowcplusplus/article/details/25190809 朴素贝叶斯算法是被工业界广泛应用的机器学习算法,它有较强的数学理论基础,在 ...
- 机器学习——朴素贝叶斯算法(垃圾邮件分类)
朴素贝叶斯算法介绍以及垃圾邮件分类实现 1.一些数学知识 2.贝叶斯公式 3.朴素贝叶斯算法 (1)介绍 (2)核心思想 (3)朴素贝叶斯算法 (4)拉普拉斯修正 (5)防溢出策略 (6)一般过程 ( ...
最新文章
- numpy中的一些常见函数
- python 获取打包后二进制所在目录
- ubuntu 安装deb_Ubuntu不完全小坑指南
- 在alv grid中的列中设置icon图标
- spring boot 中json数据处理
- 如何在发文一小时后预测出公众号的阅读量?
- react.js从入门到精通(六)——路由的使用
- Ansible Tower - 使用入门 3 - 通过模板运行 Git 上的 Playbook 和 Role
- 计算机网络 第四章 网络层
- 刚写完的商城erp + 这个商城前台,新鲜出炉。自己1个人写, 包括php框架和前端html页面....
- oracle迁移性能对比,SQL Server 2015与Oracle性能对比.doc
- IDEA导入Git中项目
- 深度学习的未来在单片机身上?
- 1.Prometheus 监控技术与实践 --- 云计算时代的监控系统
- 利用词袋模型和TF-IDF实现Large Movie Review Dataset文本分类
- 如何在echarts地图默认的行政区(县)新增一个没有编号的区(如甘肃省天水市的区县新增一个新安区)
- 收藏的兼容各浏览器的日历控件(ie6-11\ff\google\safri)
- “醉牛前端”重新起航!
- 运动蓝牙耳机挑选要注意什么?蓝牙耳机知识科普
- Ruby中yield和block的用法