元学习概述(Meta-Learning)
![]()
转载自: 凉爽的安迪-深度瞎学
一文入门元学习(Meta-Learning)
写在前面:迄今为止,本文应该是网上介绍【元学习(Meta-Learning)】最通俗易懂的文章了( 保命),主要目的是想对自己对于元学习的内容和问题进行总结,同时为想要学习Meta-Learning的同学提供一下简单的入门。笔者挑选了经典的paper详读,看了李宏毅老师深度学习课程元学习部分,并附了MAML的代码。为了通俗易懂,我将数学推导和工程实践分开两篇文章进行介绍。如果看不懂,欢迎来捶我( )~~
如果大家觉得有帮助,可以帮忙点个赞或者收藏一下,这将是我继续分享的动力~
以下是本文的主要框架:
- Introduction
- Meta Learning实施——以MAML为例
- Reptile
- What's more
全文大约4000字,阅读完大概需要12分钟。
1. Introduction
通常在机器学习里,我们会使用某个场景的大量数据来训练模型;然而当场景发生改变,模型就需要重新训练。但是对于人类而言,一个小朋友成长过程中会见过许多物体的照片,某一天,当Ta(第一次)仅仅看了几张狗的照片,就可以很好地对狗和其他物体进行区分。
元学习Meta Learning,含义为学会学习,即learn to learn,就是带着这种对人类这种“学习能力”的期望诞生的。Meta Learning希望使得模型获取一种“学会学习”的能力,使其可以在获取已有“知识”的基础上快速学习新的任务,如:
- 让Alphago迅速学会下象棋
- 让一个猫咪图片分类器,迅速具有分类其他物体的能力
需要注意的是,虽然同样有“预训练”的意思在里面,但是元学习的内核区别于迁移学习(Transfer Learning),关于他们的区别,我会在下文进行阐述。
接下来,我们通过对比机器学习和元学习这两个概念的要素来加深对元学习这个概念的理解。
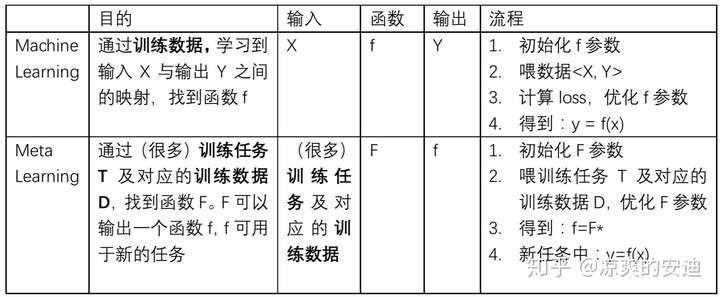
在机器学习中,训练单位是一条数据,通过数据来对模型进行优化;数据可以分为训练集、测试集和验证集。在元学习中,训练单位分层级了,第一层训练单位是任务,也就是说,元学习中要准备许多任务来进行学习,第二层训练单位才是每个任务对应的数据。
二者的目的都是找一个Function,只是两个Function的功能不同,要做的事情不一样。机器学习中的Function直接作用于特征和标签,去寻找特征与标签之间的关联;而元学习中的Function是用于寻找新的f,新的f才会应用于具体的任务。有种不同阶导数的感觉。又有种老千层饼的感觉,你看到我在第二层,你把我想象成第一层,而其实我在第五层。。。
2. Meta Learning实施——以MAML为例
我们先对比机器学习的过程来进一步理解元学习。如下图所示,机器学习的一般过程如下:
- 设计网络网络结构,如CNN、RNN等;
- 选定某个分布来初始化参数;(以上其实决定了初始的f的长相,选择不同的网络结构或参数相当于定义了不同的 f );
- 喂训练数据,根据选定的Loss Function计算Loss;
- 梯度下降,逐步更新 ;
- 得到最终的 f ;
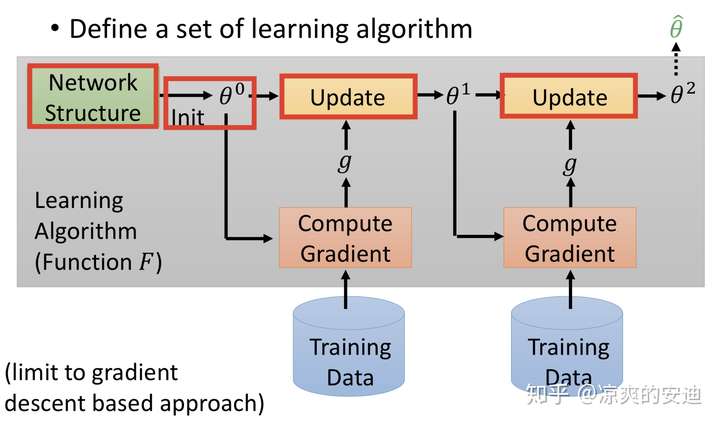
其中,红色方框里的“配置”都是由人为设计的,我们又叫做“超参数“。Meta Learning中希望把这些配置,如网络结构,参数初始化,优化器等由机器自行设计(注:此处区别于AutoML,迁移学习(Transfer Learning)和终身学习(Life Long Learning) ),使网络有更强的学习能力和表现。
上文已经提到,【元学习中要准备许多任务来进行学习,而每个任务又有各自的训练集和测试集】。我们结合一个具体的任务,来介绍元学习和MAML的实施过程。
有一个图像数据集叫Omniglot:https://github.com/brendenlake/omniglot。
![]()
Omniglot包含1623个不同的火星文字符,每个字符包含20个手写的case。这个任务是判断每个手写的case属于哪一个火星文字符。
如果我们要进行N-ways,K-shot(数据中包含N个字符类别,每个字符有K张图像)的一个图像分类任务。比如20-ways,1-shot分类的意思是说,要做一个20分类,但是每个分类下只有1张图像的任务。我们可以依据Omniglot构建很多N-ways,K-shot任务,这些任务将作为元学习的任务来源。构建的任务分为训练任务(Train Task),测试任务(Test Task)。特别地,每个任务包含自己的训练数据、测试数据,在元学习里,分别称为Support Set和Query Set。
MAML的目的是获取一组更好的模型初始化参数(即让模型自己学会初始化)。我们通过(许多)N-ways,K-shot的任务(训练任务)进行元学习的训练,使得模型学习到“先验知识”(初始化的参数)。这个“先验知识”在新的N-ways,K-shot任务上可以表现的更好。
接下来介绍MAML的算法流程:
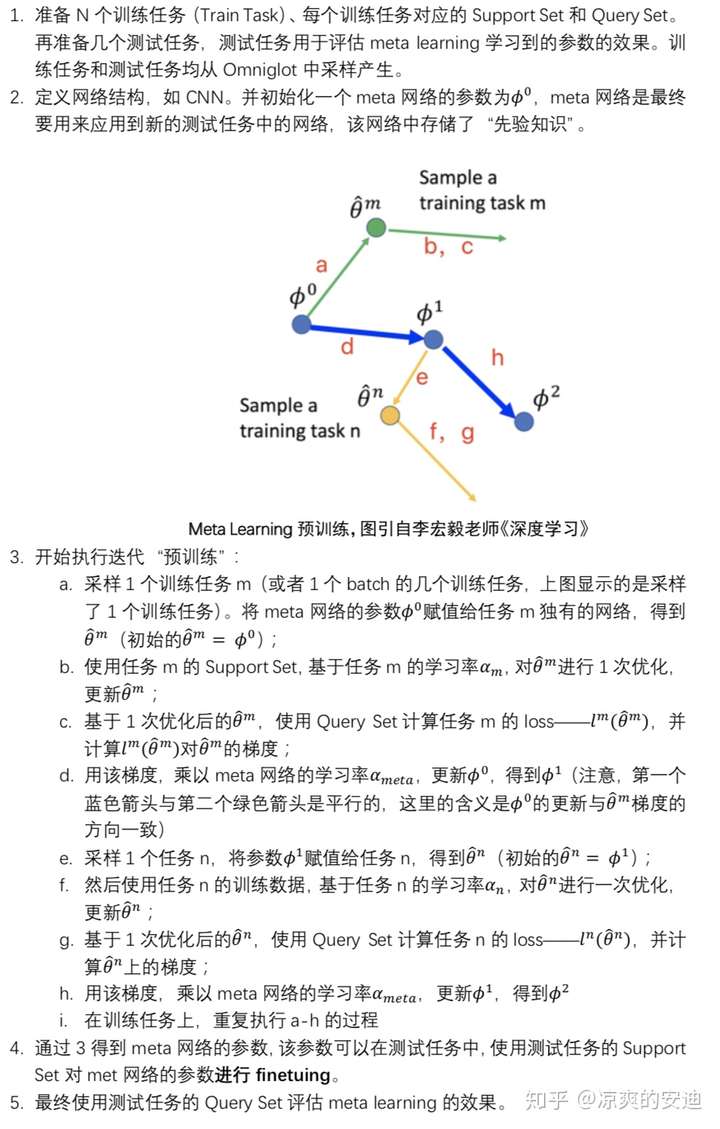
当然,在“预训练”阶段,也可以sample出1个batch的几个任务,那么在更新meta网络时,要使用sample出所有任务的梯度之和。
注意:在MAML中,meta网络与子任务的网络结构必须完全相同。
这里面有几个小问题:
- MAML的执行过程与model pretraining & transfer learning的区别是什么?
- 为何在meta网络赋值给具体训练任务(如任务m)后,要先更训练任务的参数,再计算梯度,更新meta网络?
- 在更新训练任务的网络时,只走了一步,然后更新meta网络。为什么是一步,可以是多步吗?
问题1:MAML的执行过程与model pretraining & transfer learning的区别是什么?
我们将meta learning与model pretraining的loss函数写出来。

注意这两个loss函数的区别:
- meta learning的L来源于训练任务上网络的参数更新过一次后(该网络更新过一次以后,网络的参数与meta网络的参数已经有一些区别),然后使用Query Set计算的loss;
- model pretraining的L来源于同一个model的参数(只有一个),使用训练数据计算的loss和梯度对model进行更新;如果有多个训练任务,我们可以将这个参数在很多任务上进行预训练,训练的所有梯度都会直接更新到model的参数上。
看一下二者的更新过程简图:
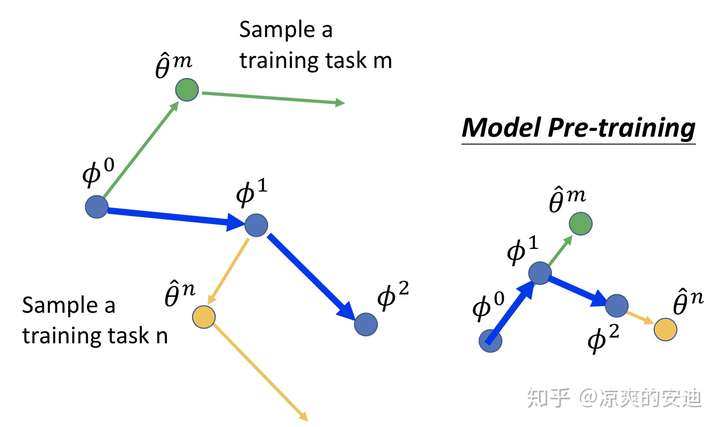
- MAML是使用子任务的参数,第二次更新的gradient的方向来更新参数(所以左图,第一个蓝色箭头的方向与第二个绿色箭头的方向平行;左图第二个蓝色箭头的方向与第二个橘色箭头的方向平行)
- 而model pretraining是使用子任务第一步更新的gradient的方向来更新参数(子任务的梯度往哪个方向走,model的参数就往哪个方向走)。
从sense上直观理解:
- model pretraining最小化当前的model(只有一个)在所有任务上的loss,所以model pretraining希望找到一个在所有任务(实际情况往往是大多数任务)上都表现较好的一个初始化参数,这个参数要在多数任务上当前表现较好。
- meta learning最小化每一个子任务训练一步之后,第二次计算出的loss,用第二步的gradient更新meta网络,这代表了什么呢?子任务从【状态0】,到【状态1】,我们希望状态1的loss小,说明meta learning更care的是初始化参数未来的潜力。
一个关注当下,一个关注潜力。
- 如下图所示,model pretraining找到的参数 φ,在两个任务上当前的表现比较好(当下好,但训练之后不保证好);
- 而MAML的参数 φ 在两个子任务当前的表现可能都不是很好,但是如果在两个子任务上继续训练下去,可能会达到各自任务的局部最优(潜力好)。
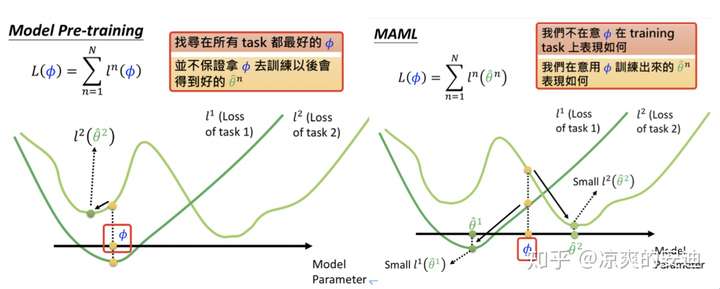
这里有一个toy example可以表现MAML的执行过程与model pretraining & transfer learning的区别。
训练任务:给定N个函数,y = asinx + b(通过给a和b不同的取值可以得到很多sin函数),从每个函数中sample出K个点,用sample出的K个点来预估最初的函数,即求解a和b的值。
训练过程:用这N个训练任务sample出的数据点分别通过MAML与model pretraining训练网络,得到预训练的参数。
如下图,用橘黄色的sin函数作为测试任务,三角形的点是测试任务中sample出的样本点,在测试任务中,我们希望用sample出的样本点还原橘黄色的线。
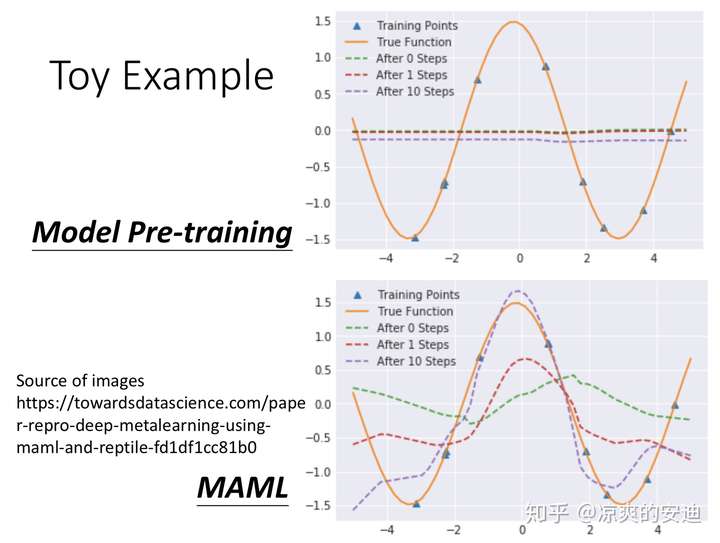
- model pretraining的结果,在测试任务上,在finetuning之前,绿色线是一条水平线,finetuning之后还原的线基本还是一条水平线。因为在预训练的时候,有很多sin函数,model pretraining希望找到一个在所有任务上都效果较好的初始化结果,但是许多sin函数波峰和波谷重叠起来,基本就是一条水平线。用这个初始化的结果取finetuning,得到的结果仍然是水平线。
- MAML的初始化结果是绿色的线,和橘黄色的线有差异。但是随着finetuning的进行,结果与橘黄色的线更加接近。
问题2:为何在meta网络赋值给具体训练任务(如任务m)后,要先更训练任务的参数,再计算梯度,更新meta网络?
这个问题其实在问题1中已经进行了回答,更新一步之后,避免了meta learning陷入了和model pretraining一样的训练模式,更重要的是,可以使得meta模型更关注参数的“潜力”。
问题3:在更新训练任务的网络时,只走了一步,然后更新meta网络。为什么是一步,可以是多步吗?
李宏毅老师的课程中提到:
- 只更新一次,速度比较快;因为meta learning中,子任务有很多,都更新很多次,训练时间比较久。
- MAML希望得到的初始化参数在新的任务中finetuning的时候效果好。如果只更新一次,就可以在新任务上获取很好的表现。把这件事情当成目标,可以使得meta网络参数训练是很好(目标与需求一致)。
- 当初始化参数应用到具体的任务中时,也可以finetuning很多次。
- Few-shot learning往往数据较少。
那么MAML中的训练任务的网络可以更新多次后,再更新meta网络吗?
我觉得可以。直观上感觉,更新次数决定了子任务对于meta网络的影响程度,我觉得这个步数可以作为一个参数来调。
另外,即将介绍的下一个网络——Reptile,也是对训练任务网络进行多次更新的。
3. Reptile
Reptile与MAML有点像,我们先看一下Reptile的训练简图:
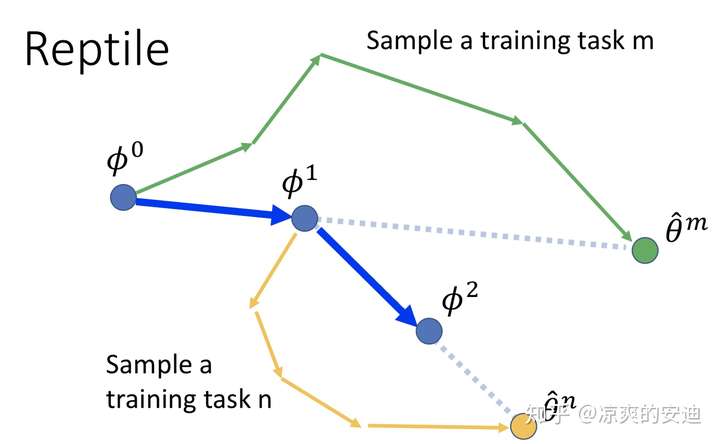
Reptile的训练过程如下:
 Reptile,每次sample出1个训练任务
Reptile,每次sample出1个训练任务  Reptile,每次sample出1个batch训练任务
Reptile,每次sample出1个batch训练任务
在Reptile中:
- 训练任务的网络可以更新多次
- reptile不再像MAML一样计算梯度(因此带来了工程性能的提升),而是直接用一个参数 ϵ 乘以meta网络与训练任务的网络参数的差来更新meta网络参数
- 从效果上来看,Reptile效果与MAML基本持平
4. What's more
元学习入门部分的文章基本就分享到这里了~
- 从出发点上来看,元学习和model pretraining有点像,即,都是让网络具有一些先验知识。
- 从训练过程的设计来看,元学习更关注模型的潜力,而model pretraining更注重模型当下在多数情况下的表现,效果孰好孰坏很难直接判定。这大概也就是仰望天空和脚踏实地的区别hahaha
- 元学习除了可以初始化参数以外,还有一些设计可以帮助确定网络结构,如何更新参数等等这里有李宏毅老师的一个课程大家可以关注一下https://www.youtube.com/watch?v=c10nxBcSH14 。
最后的最后,求赞求收藏求关注~
参考文献
- Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017: 1126-1135.
- Nichol A, Schulman J. Reptile: a scalable metalearning algorithm[J]. arXiv preprint arXiv:1803.02999, 2018, 2: 2.
- https://github.com/dragen1860/MAML-TensorFlow
- https://www.youtube.com/watch?v=c10nxBcSH14
- https://www.bilibili.com/video/BV1JE411g7XF?p=80
元学习概述(Meta-Learning)相关推荐
- 【李宏毅】元学习(Meta learning)的概念与步骤
[李宏毅]元学习(Meta learning)的概念与步骤 1 概念 2 元学习步骤 2.1 定义一组学习算法 2.2 评价一个学习算法 F F F 的好坏 只讲了元学习概念和步骤,简单做了解,稍微复 ...
- 强化学习-把元学习(Meta Learning)一点一点讲给你听
目录 0 Write on the front 1 What is meta learning? 2 Meta Learning 2.1 Define a set of learning algori ...
- 深度强化元学习教程---元学习概述
深度强化元学习是近期深度学习技术的一个另人瞩目的新兴领域,其利用元学习,解决了深度学习需要大数据集的问题,以及强化学习收敛慢的问题.同时元学习还可以适用于环境不断改变的应用场景,具有巨大的应用前景. ...
- 迁移学习概述(Transfer Learning)
迁移学习概述(Transfer Learning) 迁移学习概述 背景 定义及分类 关键点 基于实例的迁移 基于特征的迁移 特征选择 特征映射 基于共享参数的迁移 深度学习和迁移学习结合 Pre-tr ...
- Meta Learning 元学习
来源:火炉课堂 | 元学习(meta-learning)到底是什么鬼?bilibili 文章目录 1. 元学习概述 Meta 的含义 从 Machine Learning 到 Meta-Learnin ...
- 什么是元学习 (Meta Learning)
目录 元学习(Meta Learning) 元学习介绍 元学习目的 元学习流程 元学习(Meta Learning) 元学习介绍 元学习希望使得模型获取调整超参数的能力,使其可以在获取已有知识的基础上 ...
- 一文弄懂元学习 (Meta Learing)(附代码实战)《繁凡的深度学习笔记》第 15 章 元学习详解 (上)万字中文综述
<繁凡的深度学习笔记>第 15 章 元学习详解 (上)万字中文综述(DL笔记整理系列) 3043331995@qq.com https://fanfansann.blog.csdn.net ...
- 中大博士分析ICLR 2022投稿趋势:Transformer激增,ViT首进榜单前50,元学习大跌
点击上方"视学算法",选择加"星标"或"置顶" 重磅干货,第一时间送达 丰色 发自 凹非寺 量子位 报道 | 公众号 QbitAI 深度学习 ...
- 元学习:Meta-Learning in Neural Networks: A Survey
原文:Timothy M Hospedales, Antreas Antoniou, Paul Micaelli, Amos J Storkey. Meta-Learning in Neural Ne ...
最新文章
- 苹果外包爆料:你手机里的Siri,听到了嘿嘿嘿的声音
- AWS之EC2搭建WordPress博客
- [WinError 10038] 在一个非套接字上尝试了一个操作
- 三层交换机工作原理介绍
- c语言语言教程0基础_C语言基础
- nodejs 获取cpu核心数量_用 NodeJS 充分利用多核 CPU 的资源[每日前端夜话0xCB]
- 网络拓扑故障诊断讲解总结
- mac qt编译出现问题的解决方法
- linux 重启21端口命令,修改SSH默认远程端口为21号端口
- 数据库建模工具powerdisgner16.5
- arcpy判断图层是否存在的方法
- 修改Android模拟器存储位置,更改AndroidAVD模拟器创建路径位置的方法
- mis系统的编写与设计
- 思科路由器及交换机基本配置
- java mediatype属性_SpringMVC 及常用MediaType
- UI设计中标签设计总结
- C++指针详解2_typedef函数声明类型、sizeof特性简介与数组指针间关系说明
- 真方位角计算文献汇总:球面三角形两点之间的方位
- Java实现 蓝桥杯 算法训练 未名湖边的烦恼
- 官方授权正版 Grapher 中文网站 专业 2D、3D 绘图和统计分析软件, 深入了解您的数据软件