机器学习:分类_机器学习助您一臂之力。 第3部分:最终推动
机器学习:分类
Photo by Dugan Arnett on Boston Globe
杜根·阿内特(Dugan Arnett)在《波士顿环球报》上的照片
Are you still looking for a new flat? Ready to make the last attempt? If so - follow me and I show you how to reach the finish line.
您还在寻找新公寓吗? 准备进行最后的尝试了吗? 如果是这样,请跟随我,我将向您展示如何到达终点线。
简短介绍和参考 (Short introduction and references)
It is the third part of the cycle directed to explain how could you find the optimal flat on the real estate market. In a few words the main idea - find the best offer among apartments in Yekaterinburg, where I lived before. But I think the same idea can be considered in the context of another city.
这是周期的第三部分,目的是解释如何在房地产市场上找到最佳公寓。 简而言之,主要想法是-在我以前住过的叶卡捷琳堡(Yakaterinburg)的公寓中找到最优惠的价格。 但是我认为可以在另一个城市的背景下考虑相同的想法。
If you have not read the previous parts, it would be a good idea to read them Part1 and Part2.
如果您没有阅读前面的部分,那么最好阅读一下Part1和Part2 。
Also, you could find out Ipython-notebooks over there. This part had to be much shorter than previous ones, but the devil is in details.
此外,你可以找出IPython中的笔记本电脑在那里 。 这部分必须比以前的部分短得多,但是细节是魔鬼。
后果 (Consequences)
As a result of all actions, we got an ML model (Random Forest) which works quite well. Not so good as we expected (the score is above 87%), but for real data, it is good enough. And… let me be honest, that thoughts about result had a strange affect on me. I wanted more score, the gap between the result which was expected and the real prediction was smaller than 3%. Optimism mixed with greed has gone to my head
通过所有操作,我们得到了运行良好的ML模型(随机森林)。 并不像我们预期的那样好(分数高于87%),但是对于真实数据来说,它已经足够好了。 而且……说实话,关于结果的想法对我产生了奇怪的影响。 我想要更高的分数,预期结果与实际预测之间的差距小于3%。 充满贪婪的乐观情绪浮现在我的脑海

I want more gold accuracy
我想要更多 金 准确性
It is widely known, if you want to improve something there will be probably opposite approaches. Usually, it looks like a choice between:
众所周知,如果要改进某些东西,可能会有相反的方法。 通常,它看起来像是在以下两者之间进行选择:
- Evolution vs revolution进化与革命
- Quantity vs quality数量与质量
- Extensive vs intensive广泛vs密集
And because of a lack of will to change horses in midstream, I decided to use RF (Random Forest) with adding a few new features.
由于缺乏在中游换马的意愿,我决定使用RF(随机森林)并添加一些新功能。
It seemed like an idea, "we just need more features" for making the score better. At least that is what I thought.
似乎是一个主意,“我们只需要更多功能”即可使得分更高。 至少那是我的想法。
Per aspera ad astra(通过艰苦奋斗到星星) (Per aspera ad astra (through hardships to the stars))
Let's try to think about related features, which could influence a flat's price. There are features of flat like balcony or age of house and geo-related features like distance to the nearest metro/bus station. What could be next for the same approach with RF?
让我们尝试考虑可能会影响公寓价格的相关功能。 有如阳台或房屋使用年限等单位功能,还有与地理相关的功能,如距最近的地铁/公交车站的距离。 对于采用RF的相同方法,下一步可能是什么?
想法#1。 到中心的距离 (Idea #1. Distance to centre)
We could reuse longitude and latitude (flat coordinates). Base on this information we could count the distance to the centre of the city. The same idea was used for districts, the far we flat located from the centre, the cheaper it should be. And guess what… it works! Not such big growth (+1% of score), but it is better than nothing.
我们可以重用经度和纬度(平面坐标)。 根据这些信息,我们可以算出到市中心的距离。 相同的想法也用于地区,我们离市中心越远,价格就应该越便宜。 猜猜是什么...有效! 没有这么大的增长(分数的+ 1% ),但是总比没有好。
Only one problem is there, the same idea does not make sense for districts which are very far. If you lived outside a city, you could know that there are other rules for the price.
那里只有一个问题,对于遥远的地区来说,相同的想法没有意义。 如果您住在城市外,您可能会知道价格还有其他规定。
It will not be easy for interpretation if we extrapolate that approach.
如果我们推断这种方法,将很难解释。
想法2。 近地铁 (Idea #2. Near metro)
The metro has a significant influence on price. Especially when it placed in a zone of walking distance. But the meaning of "a walking distance" is not clear. Each person can interpret that parameter in different ways. I could set the limit by manually, but an increase of score would not be over 0.2%
地铁对价格有重大影响。 特别是当它放置在步行距离区域内时。 但是“步行距离”的含义不清楚。 每个人都可以以不同的方式解释该参数。 我可以手动设置限制,但得分的增加不会超过0.2%
At the same time, it does not work with flat from the previous idea. There is no metro nearby.
同时,它不适用于以前的想法。 附近没有地铁。
想法3。 市场的理性与均衡 (Idea #3. Rationality and equilibrium of the market)
The equilibrium of the market is a combination of demand and offer. Adam Smith talked about it. Of course, the market can be overblown. But in general, this idea works well. At least for houses which in the process of construction.
市场均衡是需求和报价的结合。 亚当·史密斯(Adam Smith)谈到了这一点。 当然,市场可能被夸大了。 但总的来说,这个想法很好。 至少对于正在建设中的房屋。
In other words - the more competitors do you have the less probability that people buy your flat (other things being equal). And this produces a supposition - "if around me are placed other flats I need to decrease the price for getting more buyers".
换句话说-竞争对手越多,人们购买您的公寓的可能性就越小(其他条件相同)。 这就产生了一个假设-“如果在我周围放置其他公寓,我需要降低价格以吸引更多买家”。
And It sounds like a quite logical conclusion, is not it?
而且听起来像是很合乎逻辑的结论,不是吗?
So I counted SIMILAR flats near each of them, in the same house and within radius 200 meters. The measures were made for date of selling. Which result would you expect to take? Only 0.1% on cross-validation. Sad but true.
因此,我数了数以千计的公寓附近,同一栋房子内和半径200米以内的类似公寓。 该措施是针对销售日期而制定的。 您希望取得哪个结果? 交叉验证率仅为0.1% 。 悲伤但真实。
重新思考 (Rethinking)
— an unknown wise person
—未知的智者
Okay, a head-on attack does not work. Let's consider this situation from another angle.
好的,正面攻击无效。 让我们从另一个角度考虑这种情况。
Let suppose you are a person who wants to buy a flat near-by river far from the noisy city. You have three variants of advertisement which are similar to each other and price the same (more or less). Formal metrics which describing flat gives you nothing about the environment, they are only metrics on a screen. But there is something important.
假设您是一个想要在远离喧闹城市的地方购买一条平坦的附近河流的人。 您有三种广告变体,它们彼此相似且价格相同(或多或少)。 形形色色的正式指标对您的环境没有任何帮助,它们只是屏幕上的指标。 但是有一些重要的事情。
A description of a flat is a terrific opportunity.
描述公寓是一个了不起的机会。
A flat description could provide everything that you need. It could tell you a story about flat, about neighbours and amazing opportunities related to that specific living place. And sometime one description could make more sense than boring numbers. But in real life is slightly different from our expectation. Let me show you what will/will not work and why.
简单的描述可以提供您需要的一切。 它可以告诉您有关公寓,邻居以及与该特定居住地点相关的绝佳机会的故事。 有时,一种描述可能比无聊的数字更有意义。 但是现实生活中与我们的预期略有不同。 让我告诉您什么将/将不起作用以及为什么。
什么不起作用,为什么? (What will not work and why?)
Expectations - "Whoa! I can try to classify text and find 'good' and 'bad' flats. I will use the same method which usually used for sentiment analyse".
期望 -“哇!我可以尝试对文本进行分类,找到'好'和'坏'的单位。我将使用通常用于情感分析的相同方法。”
Reality - "No, you will not do it. People write nothing bad against their flat. There can be glossing over a real situation or lie"
现实 -“不,你不会做。人们在公寓里写得不好。在真实情况或谎言中可能会蒙上阴影”
Expectations - "Okay. Then I can try to find patterns and find the target audience for a flat. For instance, it could be elderly people or students".
期望 -“好吧。那么我可以尝试找到模式并找到公寓的目标受众。例如,可能是老年人或学生。”
Reality - "No, you will not do it. Sometimes one advertisement has a mention about different ages and social groups, it is just marketing"
现实 -“不,您不会这样做。有时候,一个广告会提及不同的年龄和社会群体,这只是营销”
什么可能会起作用,为什么 (What probably would work and why)
Some keywords - There are words which point out at specific things or moments related to flat. For example, when it is a studio, price would be lower. In general, verbs are useless, but nouns and adverbs can give more context.
一些关键字 -有些单词指出与Flat有关的特定事物或关键时刻。 例如,当是工作室时,价格会更低。 通常,动词是没有用的,但是名词和副词可以提供更多的上下文。
The alternative source of information - Using description for filling empty or NaN-values more correct. Sometimes the description contains more information than formal features of advertisement.
替代信息来源 -使用描述填充空值或NaN值更正确。 有时,说明中包含的信息要比广告的形式特征更多。
I suspect it based on human laziness to fill not required fields like "balcony". Putting everything in the description seems like a more preferable idea
我怀疑它是基于人的惰性来填充“阳台”之类的非必填字段。 将所有内容放在描述中似乎是一个更可取的主意
获取资讯 (Getting information)
I skip describing of the typical process of tokenisation/lemmatization/stemming. Also, I believe that there are authors able to describe it better than me.
我跳过了对记号化/词性化/词干的典型过程的描述。 另外,我相信有些作者能够比我更好地描述它。
Although I think there should be a mention of the toolset used for extracting features. In nutshell, it looks like.
尽管我认为应该提到用于提取特征的工具集。 简而言之,它看起来像。
separating->matching by part of speech
分离->词性匹配
After pre-processing of advertisement text I got a set of Russian words like these.
在对广告文字进行预处理之后,我得到了一组像这样的俄语单词。

The original text is placed https://pastebin.com/Pxh8zVe3
原始文本放置在https://pastebin.com/Pxh8zVe3
I tried to use the approach from Word2Vec, but there was not a special dictionary for flats and advertisements, so the general picture looked weird
我尝试使用Word2Vec中的方法,但没有专门针对单位和广告的词典,因此总体图片看起来很奇怪
the distance between words does not suitable to expectations
单词之间的距离不符合期望
Therefore I kept it as simple as possible and decided to make several new columns for dataset
因此,我将其保持尽可能简单,并决定为数据集添加几个新列
少说话,多动作 (A little less conversation, a little more action)
Time to get our hands dirty and do some practical things. Find out new features. Several important factors were separated by an influence on price.
是时候动手做一些实际的事情了。 找出新功能。 对价格的影响将几个重要因素分开。
积极影响 (positive impact)
furniture — sometimes people could leave a bed, a washer and so on.
家具 -有时人们可以留下床,洗衣机等。
luxury - flats with luxurious things like jacuzzi, or an exclusive interior
豪华房 -配有按摩浴缸或豪华内饰等豪华物件的公寓
video-control - it makes people feel safe, frequently it considers it as advantage
视频控制 -使人们感到安全,经常将其视为优势
负面影响 (negative impact)
dorm - yes, sometimes it is a flat in a dorm. Not s o popular, but significantly cheaper than an average flat
宿舍 -是的,有时它是宿舍中的公寓。 不太受欢迎,但比普通公寓便宜得多
rush - when people rush to sell out their flat usually they are ready to decrease price.
急 -当人们急于出售他们的公寓时,他们通常准备降低价格。
studio - as I said before - they are cheaper than their flats-analogues.
工作室 -正如我之前说过的-它们比公寓类似物便宜。
Let's collect them in something universal
让我们将它们收集在通用的东西中
df3 = pd.read_csv('flats3.csv')positive_impact = ['мебель', 'luxury','видеонаблюдение']
negative_impact = ['studio', 'rush','dorm']
geo_features = ['metro','num_of_stops_1km','num_of_shops_1km','num_of_kindergarden_1km', 'num_of_medical_1km','center_distance']
flat_features=['total_area', 'repair','balcony_y', 'walls_y','district_y', 'age_y']
competitors_features = ['distance_200m', 'same_house']
cols = ['cost']
cols+=flat_features
cols+=geo_features
cols+=competitors_features
cols+=positive_impact
cols+=negative_impact
df3 = df3[cols]一般影响 (general impact)
it is just a combination of negative and positive features. Initially, for every flat, it equals 0. For example, studio with video-control will still have general impact equals 0(1[positive]–1[negative]=0)
它只是消极和积极特征的结合。 最初,每个单位等于0。例如,具有视频控制功能的工作室的总体影响力仍为0( 1 [positive] –1 [negative] = 0 )
df3['impact'] = 0
for i, row in df3.iterrows():impact = 0for positive in positive_impact:if row[positive]:impact+=1for negative in negative_impact:if row[negative]:impact-=1df3.at[i, 'impact'] = impactOkay, we have a data, new features and old target with 10% of mean error for prediction. Do some typical operation as we did before
好的,我们有一个数据,新功能和旧目标,均值的平均误差为10%,可用于预测。 像以前一样做一些典型的操作
y = df3.cost
X = df3.drop(columns=['cost'])X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)旧方法(功能的广泛增长) (Old approach(extensive growth of features))
We will make a new model based on old ideas
我们将基于旧观念创建新模型
data = []
max_features = int(X.shape[1]/2)
for x in range(1,20):regressor = RandomForestRegressor(verbose=0,n_estimators=128,max_features=max_features, max_depth=x,random_state=42)model = regressor.fit(X_train, y_train)score = do_cross_validation(X, y, model)data.append({'max_depth':x,'score':score})
data = pd.DataFrame(data)
f, ax = plot.subplots(figsize=(10, 10))
sns.lineplot(x="max_depth", y="score", data=data)
max_result = data.loc[data['score'].idxmax()]ax.set_title(f'Max score - {max_result.score}\nDepth {max_result.max_depth} ')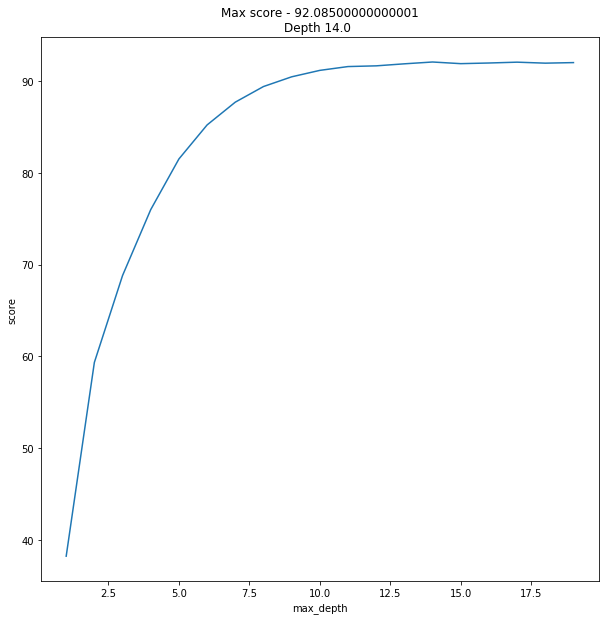
And the result was slightly… unexpected.
结果有点……出乎意料。
92% is overwhelming result. I mean, to say I was shocked would be an understatement.
92%是压倒性的结果。 我的意思是说我感到震惊是轻描淡写。
But why it worked so well? Let's have a look at new features.
但是为什么效果如此好呢? 让我们看一下新功能。
regressor = RandomForestRegressor(random_state=42,max_depth=max_result.max_depth,n_estimators=128,max_features=max_features)
rf3 = regressor.fit(X_train, y_train)
feat_importances = pd.Series(rf3.feature_importances_, index=X.columns)
feat_importances.nlargest(X.shape[1]).plot(kind='barh')Importance all features for our model
重视我们模型的所有功能
The importance does not give information about the contribution of features(that is a different story ), it is only showing how active model use one or another feature. But for the current situation, it looks informative. Some of the new features are more important than previous ones, others almost useless.
重要性没有提供有关功能的贡献的信息(这是一个不同的故事),而只是显示了活动模型如何使用一个或另一个功能。 但是对于当前的情况,它看起来很有用。 一些新功能比以前的功能更重要,其他功能几乎没有用。
新方法(密集处理数据) (New approach(intensive work with data))
Well… the finish line is crossed, the result is achieved. Could it be better? Short answer - "Yes, it could"
好吧……越过终点线,结果就实现了。 会更好吗? 简短答案- “是,可以”
- First, we could reduce the depth of a tree. It will lead to a smaller time for training and prediction as well.首先,我们可以减少一棵树的深度。 这也将减少培训和预测的时间。
- Second, we could a little bit increase a score of prediction.第二,我们可以稍微提高预测分数。
For both moments we will use XGBoost. Sometimes people prefer to use other boosters like LightGBM or CatBoost, but my humble opinion - the first one is good enough when you have a lot of data, a second one is better if you have work with categorical variables. And as a bonus - XGBoost just seems faster
在这两个时刻,我们将使用XGBoost 。 有时人们更喜欢使用LightGBM或CatBoost之类的其他增强器,但我的拙见-当您拥有大量数据时,第一个就足够了,如果您使用分类变量,第二个就更好。 作为奖励-XGBoost似乎更快
from xgboost import XGBRegressor,plot_importance
data = []
for x in range(3,10):regressor = XGBRegressor(verbose=0,reg_lambda=10,n_estimators=1000, objective='reg:squarederror', max_depth=x,random_state=42)model = regressor.fit(X_train, y_train)score = do_cross_validation(X, y, model)data.append({'max_depth':x,'score':score})
data = pd.DataFrame(data)
f, ax = plot.subplots(figsize=(10, 10))
sns.lineplot(x="max_depth", y="score", data=data)
max_result = data.loc[data['score'].idxmax()]ax.set_title(f'Max score-{max_result.score}\nDepth {max_result.max_depth} ')
The result is better than the previous one.
结果比上一个更好。
Of course, it is the not big difference between Random Forest and XGBoost. And each of them could be used as a good tool for resolving our problem with prediction. It is up to you.
当然,Random Forest和XGBoost之间的区别并不大。 而且它们每个都可以用作解决预测问题的好工具。 它是由你决定。
结论 (Conclusion)
Is the result achieved? Definitely yes.
结果达到了吗? 绝对可以。
The solution is available there and can be used anyone for free. If you are interested in the evaluation of an apartment using this approach, please do not hesitate and contact me.
该解决方案在那里可用,任何人都可以免费使用。 如果您对使用这种方法评估公寓感兴趣,请不要犹豫并与我联系。
As prototype it placed there
作为原型,它放置在那里
Thank you for reading!.
感谢您的阅读! 。
翻译自: https://habr.com/en/post/475136/
机器学习:分类
机器学习:分类_机器学习助您一臂之力。 第3部分:最终推动相关推荐
- 机器学习:分类_机器学习基础:K最近邻居分类
机器学习:分类 In the previous stories, I had given an explanation of the program for implementation of var ...
- 机器学习分类_机器学习之简单分类模型
本文主要探讨了机器学习算法中一些比较容易理解的分类算法,包括二次判别分析QDA,线性判别分析LDA,朴素贝叶斯Naive Bayes,以及逻辑回归Logistic Regression,还会给出在ir ...
- 机器学习 可视化_机器学习-可视化
机器学习 可视化 机器学习导论 (Introduction to machine learning) In the traditional hard-coded approach, we progra ...
- 机器学习术语_机器学习术语神秘化。
机器学习术语 Till this day, my favorite definition of a Machine is ; something that makes work easier. At ...
- 机器学习指南_机器学习-快速指南
机器学习指南 机器学习-快速指南 (Machine Learning - Quick Guide) 机器学习-简介 (Machine Learning - Introduction) Today's ...
- 机器学习 导论_机器学习导论
机器学习 导论 什么是机器学习? (What is Machine Learning?) Machine learning can be vaguely defined as a computers ...
- 机器学习算法_机器学习算法中分类知识总结!
↑↑↑关注后"星标"Datawhale每日干货 & 每月组队学习,不错过Datawhale干货 译者:张峰,Datawhale成员 本文将介绍机器学习算法中非常重要的知识- ...
- 基于朴素贝叶斯分类器的西瓜数据集 2.0 预测分类_机器学习之朴素贝叶斯
1.贝叶斯原理 朴素贝叶斯分类(Naive Bayesian,NB)源于贝叶斯理论,是一类基于概率的分类器,其基本思想:假设样本属性之间相互独立,对于给定的待分类项,求解在此项出现的情况下其他各个类别 ...
- em算法怎么对应原有分类_机器学习基础-EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断等等.本文就对 ...
最新文章
- mysql 书签查找_my-bookmark
- linux 限制连接时间,linux抵御DDoS攻击方法 通过iptables限制TCP连接和频率
- 点关机后主机不能自动关机的原因
- delphi 算术溢出解决方法_性能优化系列:JVM 内存划分总结与内存溢出异常详解分析...
- 设计配色专辑,很值得设计师拥有
- 《互联网+ 电商平台设计与运营》一一2.4 小结
- 压缩JS方法:uglifyjs
- python编程之处理GB级的大型文件
- 揭秘黑石、橡树等巨头的不良资产赚钱术
- 【中级篇】Linux下搭建MySQL数据库系统
- java pdf 富文本_Java生成pdf,兼富文本
- python pdf文件处理
- echarts异步数据加载(在下拉框选择事件中异步更新数据)
- 51单片机两只老虎 c语言,基于51单片机的简易电子琴(两只老虎)
- Arduino Uno 火焰传感器实验
- 嵌入式驱动工程师学习路线【建议收藏】
- HDU-6578 Blank(DP)2019暑假杭电多校第一场
- python小组项目总结报告_项目总结报告范文78922
- 美林数据“智能反窃电分析应用”荣获大数据星河奖
- b. 《计算机软件保护条例》没有规定软件著作权人的改编权,自然人创作的享有著作权的计算机软件的权利保护期限为()。...