从Encoder到Decoder实现Seq2Seq模型
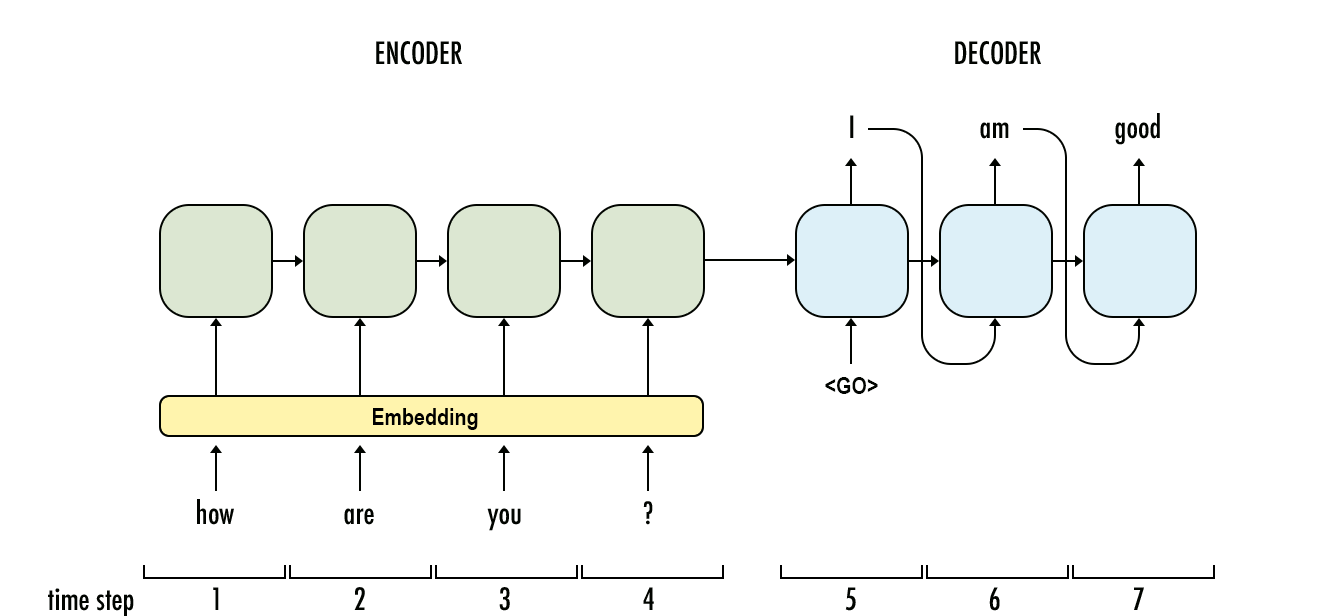
从Encoder到Decoder实现Seq2Seq模型
更新:感谢@Gang He指出的代码错误。get_batches函数中第15行与第19行,代码已经重新修改,GitHub已更新。
前言
好久没有更新专栏,今天我们来看一个简单的Seq2Seq实现,我们将使用TensorFlow来实现一个基础版本的Seq2Seq,主要帮助理解Seq2Seq中的基础架构。
最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。


图中每一个box代表了一个RNN单元,通常是LSTM或者GRU。其实基础的Seq2Seq是有很多弊端的,首先Encoder将输入编码为固定大小状态向量的过程实际上是一个信息“信息有损压缩”的过程,如果信息量越大,那么这个转化向量的过程对信息的损失就越大,同时,随着sequence length的增加,意味着时间维度上的序列很长,RNN模型也会出现梯度弥散。最后,基础的模型连接Encoder和Decoder模块的组件仅仅是一个固定大小的状态向量,这使得Decoder无法直接去关注到输入信息的更多细节。由于基础Seq2Seq的种种缺陷,随后引入了Attention的概念以及Bi-directional encoder layer等,由于本篇文章主要是构建一个基础的Seq2Seq模型,对其他改进tricks先不做介绍。
总结起来说,基础的Seq2Seq主要包括Encoder,Decoder,以及连接两者的固定大小的State Vector。
实战代码
下面我们就将利用TensorFlow来构建一个基础的Seq2Seq模型,通过向我们的模型输入一个单词(字母序列),例如hello,模型将按照字母顺序排序输出,即输出ehllo。
版本信息:Python 3 / TensorFlow 1.1
1. 数据集
数据集包括source与target:
- source_data: 每一行是一个单词
- target_data: 每一行是经过字母排序后的“单词”,它的每一行与source_data中每一行一一对应
例如,source_data的第一行是hello,第二行是what,那么target_data中对应的第一行是ehllo,第二行是ahtw。
2. 数据预览
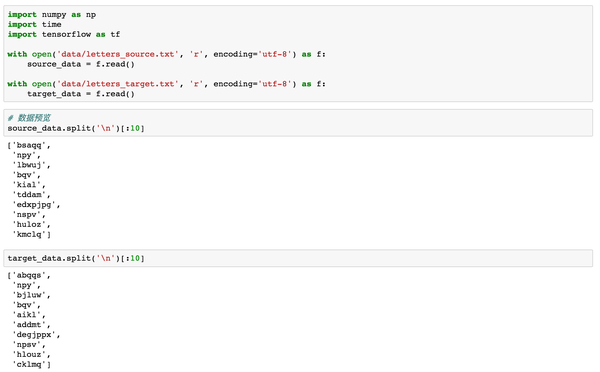
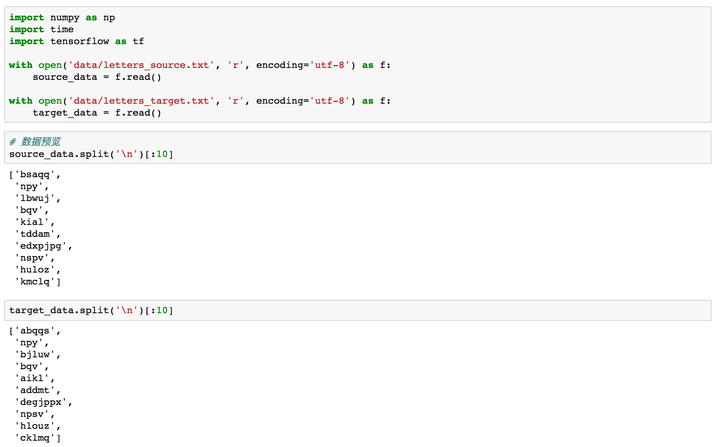
我们先把source和target数据加载进来,可以看一下前10行,target的每一行是对source源数据中的单词进行了排序。下面我们就将基于这些数据来训练一个Seq2Seq模型,来帮助大家理解基础架构。
3. 数据预处理
在神经网络中,对于文本的数据预处理无非是将文本转化为模型可理解的数字,这里都比较熟悉,不作过多解释。但在这里我们需要加入以下四种字符,<PAD>主要用来进行字符补全,<EOS>和<GO>都是用在Decoder端的序列中,告诉解码器句子的起始与结束,<UNK>则用来替代一些未出现过的词或者低频词。
- < PAD>: 补全字符。
- < EOS>: 解码器端的句子结束标识符。
- < UNK>: 低频词或者一些未遇到过的词等。
- < GO>: 解码器端的句子起始标识符。
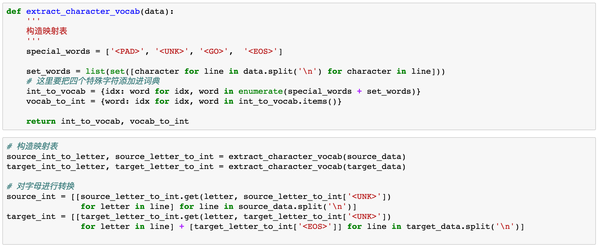
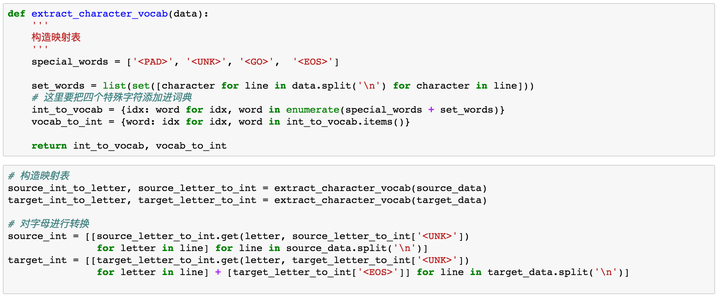
通过上面步骤,我们可以得到转换为数字后的源数据与目标数据。


4. 模型构建
Encoder
模型构建主要包括Encoder层与Decoder层。在Encoder层,我们首先需要对定义输入的tensor,同时要对字母进行Embedding,再输入到RNN层。
在这里,我们使用TensorFlow中的tf.contrib.layers.embed_sequence来对输入进行embedding。
我们来看一个栗子,假如我们有一个batch=2,sequence_length=5的样本,features = [[1,2,3,4,5],[6,7,8,9,10]],使用
tf.contrib.layers.embed_sequence(features,vocab_size=n_words, embed_dim=10)那么我们会得到一个2 x 5 x 10的输出,其中features中的每个数字都被embed成了一个10维向量。
官方关于tf.contrib.layers.embed_sequence()的解释如下:
Maps a sequence of symbols to a sequence of embeddings.
Typical use case would be reusing embeddings between an encoder and decoder.


Decoder
在Decoder端,我们主要要完成以下几件事情:
- 对target数据进行处理
- 构造Decoder
- Embedding
- 构造Decoder层
- 构造输出层,输出层会告诉我们每个时间序列的RNN输出结果
- Training Decoder
- Predicting Decoder
下面我们会对这每个部分进行一一介绍。
1. target数据处理
我们的target数据有两个作用:
- 在训练过程中,我们需要将我们的target序列作为输入传给Decoder端RNN的每个阶段,而不是使用前一阶段预测输出,这样会使得模型更加准确。(这就是为什么我们会构建Training和Predicting两个Decoder的原因,下面还会有对这部分的解释)。
- 需要用target数据来计算模型的loss。
我们首先需要对target端的数据进行一步预处理。在我们将target中的序列作为输入给Decoder端的RNN时,序列中的最后一个字母(或单词)其实是没有用的。我们来用下图解释:
我们此时只看右边的Decoder端,可以看到我们的target序列是[<go>, W, X, Y, Z, <eos>],其中<go>,W,X,Y,Z是每个时间序列上输入给RNN的内容,我们发现,<eos>并没有作为输入传递给RNN。因此我们需要将target中的最后一个字符去掉,同时还需要在前面添加<go>标识,告诉模型这代表一个句子的开始。
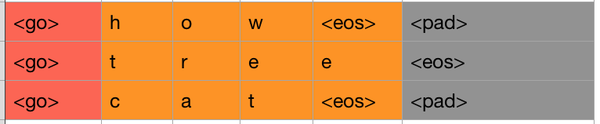
如上图,所示,红色和橙色为我们最终的保留区域,灰色是序列中的最后一个字符,我们把它删掉即可。
我们使用tf.strided_slice()来进行这一步处理。


其中tf.fill(dims, value)参数会生成一个dims形状并用value填充的tensor。举个栗子:tf.fill([2,2], 7) => [[7,7], [7,7]]。tf.concat()会按照某个维度将两个tensor拼接起来。
2. 构造Decoder
- 对target数据进行embedding。
- 构造Decoder端的RNN单元。
- 构造输出层,从而得到每个时间序列上的预测结果。
- 构造training decoder。
- 构造predicting decoder。
注意,我们这里将decoder分为了training和predicting,这两个encoder实际上是共享参数的,也就是通过training decoder学得的参数,predicting会拿来进行预测。那么为什么我们要分两个呢,这里主要考虑模型的robust。
在training阶段,为了能够让模型更加准确,我们并不会把t-1的预测输出作为t阶段的输入,而是直接使用target data中序列的元素输入到Encoder中。而在predict阶段,我们没有target data,有的只是t-1阶段的输出和隐层状态。
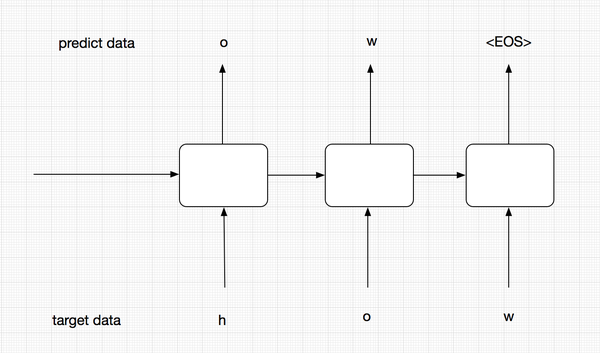
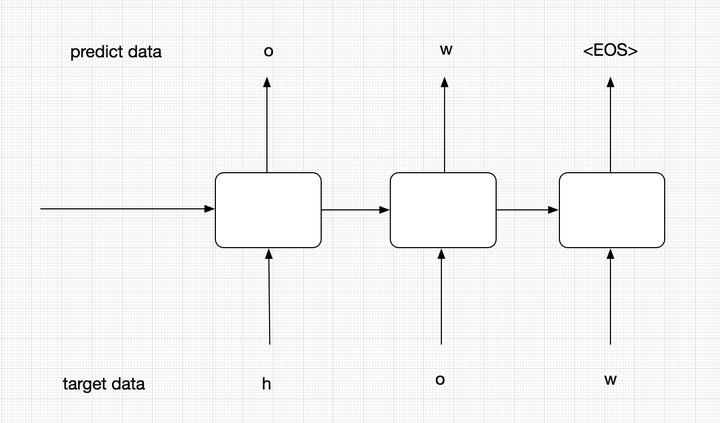
上面的图中代表的是training过程。在training过程中,我们并不会把每个阶段的预测输出作为下一阶段的输入,下一阶段的输入我们会直接使用target data,这样能够保证模型更加准确。
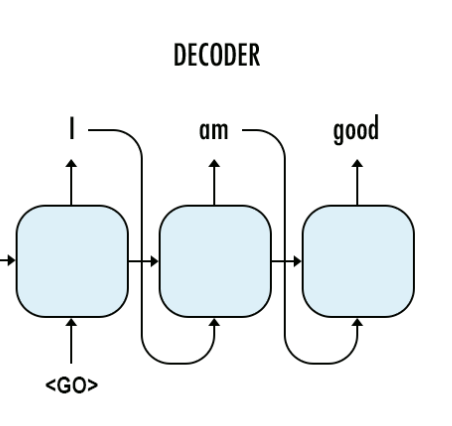
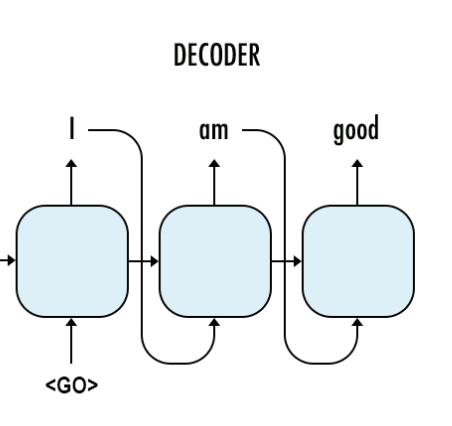
这个图代表我们的predict阶段,在这个阶段,我们没有target data,这个时候前一阶段的预测结果就会作为下一阶段的输入。
当然,predicting虽然与training是分开的,但他们是会共享参数的,training训练好的参数会供predicting使用。
decoder层的代码如下:


构建好了Encoder层与Decoder以后,我们需要将它们连接起来build我们的Seq2Seq模型。


定义超参数
# 超参数
# Number of Epochs
epochs = 60
# Batch Size
batch_size = 128
# RNN Size
rnn_size = 50
# Number of Layers
num_layers = 2
# Embedding Size
encoding_embedding_size = 15
decoding_embedding_size = 15
# Learning Rate
learning_rate = 0.001定义loss function、optimizer以及gradient clipping


目前为止我们已经完成了整个模型的构建,但还没有构造batch函数,batch函数用来每次获取一个batch的训练样本对模型进行训练。
在这里,我们还需要定义另一个函数对batch中的序列进行补全操作。这是啥意思呢?我们来看个例子,假如我们定义了batch=2,里面的序列分别是
[['h', 'e', 'l', 'l', 'o'],['w', 'h', 'a', 't']]那么这两个序列的长度一个是5,一个是4,变长的序列对于RNN来说是没办法训练的,所以我们这个时候要对短序列进行补全,补全以后,两个序列会变成下面的样子:
[['h', 'e', 'l', 'l', 'o'],['w', 'h', 'a', 't', '<PAD>']]这样就保证了我们每个batch中的序列长度是固定的。
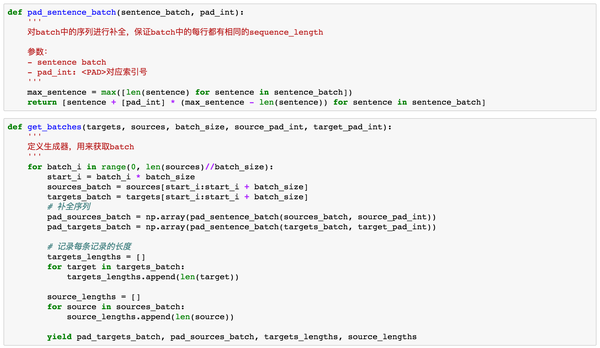
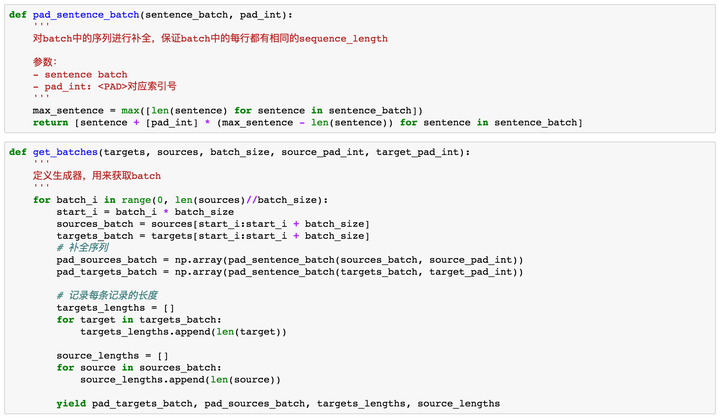
感谢@Gang He提出的错误。此处代码已修正。修改部分为get_batches中的两个for循环,for target in targets_batch和for source in sources_batch(之前的代码是for target in pad_targets_batch和for source in pad_sources_batch),因为我们用sequence_mask计算了每个句子的权重,该权重作为参数传入loss函数,主要用来忽略句子中pad部分的loss。如果是对pad以后的句子进行loop,那么输出权重都是1,不符合我们的要求。在这里做出修正。GitHub上代码也已修改。
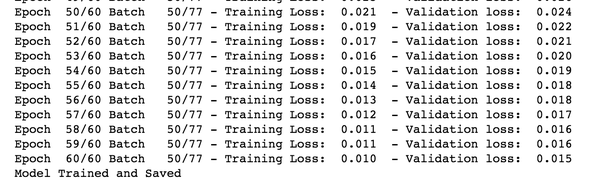
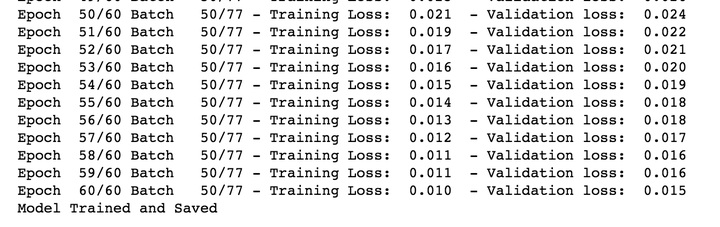
至此,我们完成了整个模型的构建与数据的处理。接下来我们对模型进行训练,我定义了batch_size=128,epochs=60。训练loss如下:
模型预测
我们通过实际的例子来进行验证。
输入“hello”:


输入“machine”:


输入“common”:


总结
至此,我们实现了一个基本的序列到序列模型,Encoder通过对输入序列的学习,将学习到的信息转化为一个状态向量传递给Decoder,Decoder再基于这个输入得到输出。除此之外,我们还知道要对batch中的单词进行补全保证一个batch内的样本具有相同的序列长度。
我们可以看到最终模型的训练loss相对已经比较低了,并且从例子看,其对短序列的输出还是比较准确的,但一旦我们的输入序列过长,比如15甚至20个字母的单词,其Decoder端的输出就非常的差。
完整代码已上传至GitHub。
转载请联系作者获得授权。
赞赏
4 人已赞赏




相关文章:
- Peacock:大规模主题模型及其在腾讯业务中的应用-2015
- KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组以及next数组求解
- 完美世界2020编程题-救雅典娜 英雄AB PK
- 腾讯2013实习生笔试题+答案1-5aadaa 6-10adbcc 11-15 acacc16-20 bbddc
- 阿里内推算法岗位编程笔试题
- 剑指offer-python解答
- 【NLP】Google BERT详解
- 机器学习算法GBDT的面试总结
- 快速理解bootstrap,bagging,boosting-三个概念
- 0-1背包问题的动态规划算法-秒懂
- Barra 结构化风险模型实现(1)——沪深300指数的风格因子暴露度分析
- 干货 | 深度学习的可解释性研究(一):让模型「说人话」
- 斯坦福完全可解释深度神经网络:你需要用决策树搞点事
- LeetCode-二叉树算法总结-层次遍历,路径总和等
- 百度作业帮-产品分析
- 风控模型师面试准备--技术篇(逻辑回归、决策树、集成学习)
- 斯坦福NLP组最新报告:自然语言处理中的学习挑战(附149页报告全文下载
- 谷歌发布端到端AI平台,还有用于视频和表格的AutoML、文档理解API等多款工具
- 匈牙利算法-指派问题、二分图问题等
- 注意力机制-深度学习中的注意力机制+注意力机制在自然语言处理中的应用
- 从特征分解到协方差矩阵:详细剖析和实现PCA算法
- 二叉树前序遍历、中序遍历、后序遍历手稿
- 最新出炉-阿里 2020届算法工程师-自然语言处理(实习生)以及补充:快递最短路径
- 关于”算法工程师/机器学习工程师”的笔试和面试总结
- 多重共线性、异方差和自相关性
- 机器学习算法优缺点改进总结
- 程序员面试100题之十六:二叉树中两个节点的最近公共父节点(最低的二叉树共同祖先)
- KD Tree的原理及Python实现
- 信息检索IR评价中常见的评价指标-MAP\NDCG\ERR\P@10等
- 【TensorFlow】优化方法optimizer总结(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)解析(十三)
从Encoder到Decoder实现Seq2Seq模型相关推荐
- Seq2Seq模型及Attention机制
Seq2Seq模型及Attention机制 Seq2Seq模型 Encoder部分 Decoder部分 seq2seq模型举例 LSTM简单介绍 基于CNN的seq2seq Transformer A ...
- seq2seq模型_Bart: Seq2Seq预训练模型
文章来源于微信公众号:雨石季 原文链接:请点击 文章仅用于学习交流,如有侵权请联系删除 Overall Transformer最早出来是为了解决机器翻译问题,因而Transformer模型分为两部分, ...
- seq2seq模型_彻底理解 Seq2Seq 模型
Seq2Seq 是一种循环神经网络的变种,包括编码器 (Encoder) 和解码器 (Decoder) 两部分.Seq2Seq 是自然语言处理中的一种重要模型,可以用于机器翻译.对话系统.自动文摘. ...
- Seq2Seq,Seq2Seq模型使用技巧
Seq2Seq是一种循环神经网络的变种,包括编码器(Encoder)和解码器(Decoder)两部分组成.Seq2Seq是自然语言处理中的一种重要模型,可以用于机器翻译.对话系统.自动摘要. 首先介绍 ...
- 基于Seq2Seq的中文聊天机器人编程实践(Encoder编码器-Decoder解码器框架 + Attention注意力机制)
日萌社 人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) Encoder编码器-Decoder解码器框架 + Atten ...
- Seq2Seq模型实现(Decoder部分)
0.引言: 承接上一篇,现在继续对于seq2seq模型进行讲解,decoder部分是和encoder部分对应的,层数.隐藏层.单元数都要对应. 1.LSTM Seq2Seq Decoder Decod ...
- transformers5--t5模型中encoder与decoder内容不同解读
t5模型中encoder与decoder内容不同 查看transformers库之中的encoder和decoder部分内容的不同 综合分析t5LayerSelfAttention和t5LayerCr ...
- NLP-生成模型-2016:CopyNet【Copy机制赋予seq2seq模型从源文本中复制词汇的能力,解决Decoder的OOV问题】
<原始论文:Incorporating Copying Mechanism in Sequence-to-Sequence Learning> 本文开篇,作者就提出他们的目标是解决seq2 ...
- seq2seq模型_直观理解并使用Tensorflow实现Seq2Seq模型的注意机制
采用带注意机制的序列序列结构进行英印地语神经机器翻译 Seq2seq模型构成了机器翻译.图像和视频字幕.文本摘要.聊天机器人以及任何你可能想到的包括从一个数据序列到另一个数据序列转换的任务的基础.如果 ...
最新文章
- MVC,三层架构,工厂模型,七层
- c 没有mysql名称空间_MySQL如何删除#sql开头的临时表
- OC特有语法:分类category,给NSString增加方法计算字符串中数字的个数
- iframe的应用 实现无刷新用户注册
- 如何在Python中针对一个值检查多个变量?
- Linux(Ubuntu 16) 下Java开发环境的配置(二)------Tomcat的配置及常见问题
- https://sysdig.com/blog/
- Jetpack 迁移到 androidX support MD
- IntelliJ IDEA For Mac 快捷键,够骚,速度收藏!
- 「转发领抱枕」40万奖金等你来挑战!阿里云ECS Cloudbuild开发者大赛重磅开启
- asp.net 获取当前页面html代码,在asp.net中获取当前页面的URL的方法(推荐)
- apollocaffe编译问题
- 导入百度导航SDK遇到的相关问题
- Centos7 制作系统iso镜像文件
- ABAP编程中对内表的定义,后面接一个OCCURS (n)是代表什么意思。
- excel-countifs和sumifs函数
- CodeForces - 1538G Gift Set (二分)
- 快速查询中通速递物流,查看未签收单号的最后站点
- Ext中TextField的 label和feild的间距的设定
- 面试官常问的设计模式及常用框架中设计模式的使用(一)