动态时间规整算法_如何使用动态时间规整算法进行语音识别
动态时间规整算法
Speech recognition is the process of analyzing audio signals to identify the words spoken by the speaker. Speech recognition has been part of our lives since 1952. We all use this technology in many areas of our daily life. Siri, a digital assistant, is an example of this technology.
语音识别是分析音频信号以识别说话者说话的过程。 自1952年以来,语音识别已成为我们生活的一部分。我们在日常生活的许多领域都使用这项技术。 数字助理Siri是此技术的一个示例。
The dynamic time warping (DTW) algorithm, invented by Soviet researchers in 1970, was used in speech recognition. Over time, new algorithms replaced it, but it is still a popular technique.
苏联研究人员于1970年发明的动态时间规整(DTW)算法用于语音识别。 随着时间的流逝,新算法取代了它,但是它仍然是一种流行的技术。
The dynamic time warping algorithm is a dynamic programming algorithm and a very popular technique in speech recognition. Why is the DTW algorithm a suitable method for speech recognition? Today we will see how this technique is used in speech recognition. Let’s learn this together.
动态时间规整算法是动态编程算法,并且是语音识别中非常流行的技术。 为什么DTW算法是语音识别的合适方法? 今天,我们将了解如何在语音识别中使用这种技术。 让我们一起学习。
了解问题 (Understand the Problem)
Focusing on the solution without fully understanding the problem is one of the biggest mistakes we can make. Let’s first understand the problem. One of the problems in speech recognition is speed.
在没有完全理解问题的情况下专注于解决方案是我们可能犯的最大错误之一。 让我们首先了解问题。 语音识别中的问题之一是速度。
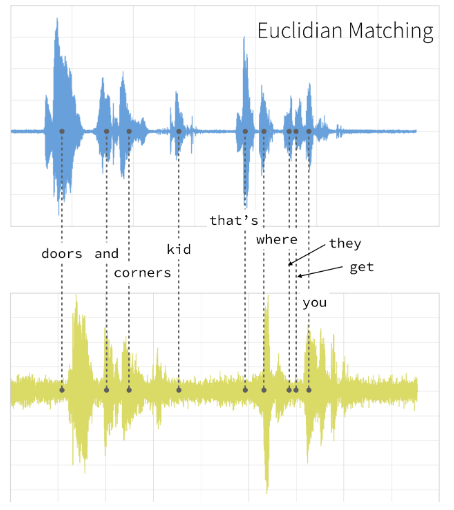
An audio signal generates a time series. Above we see two audio signals(so two time series) of two different people. Euclidian matching, a traditional method, has been used to match time series. Times between the two don’t match. So why?
音频信号生成时间序列。 在上方,我们看到了两个不同人的两个音频信号(即两个时间序列)。 欧几里得匹配是一种传统方法,用于匹配时间序列。 两者之间的时间不匹配。 所以为什么?
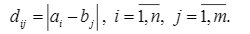
They don’t match because, in this method, the absolute distance between the values of the two elements was calculated. It’s not reliable to do this while the time issue between the two audio signals is so clear.
它们不匹配,因为在此方法中,计算了两个元素的值之间的绝对距离。 当两个音频信号之间的时间问题如此明显时,这样做是不可靠的。

Let’s visualize the time series to understand better. We can think of the time series as a sequence of numbers. When these two time series are compared, they will look different because of the time difference. However, they are the same, but there is a time problem. DTW will solve this problem for us. So how does it solve this?
让我们可视化时间序列以更好地理解。 我们可以将时间序列视为数字序列。 比较这两个时间序列时,由于时间差异,它们看起来会有所不同。 但是,它们是相同的,但是存在时间问题。 DTW将为我们解决这个问题。 那么如何解决呢?
动态时间规整的工作原理 (Working Principle of Dynamic Time Warping)
The solution of the division of audio signals (that is, time series) into equal parts is actually to separate the problem into sub-problems. When we find the optimum path (the shortest path) for each sub-problem, we will have developed an optimum solution for our main problem.
将音频信号(即时间序列)划分为相等部分的解决方案实际上是将问题分解为子问题。 当找到每个子问题的最佳路径(最短路径)时,我们将为主要问题开发最佳解决方案。
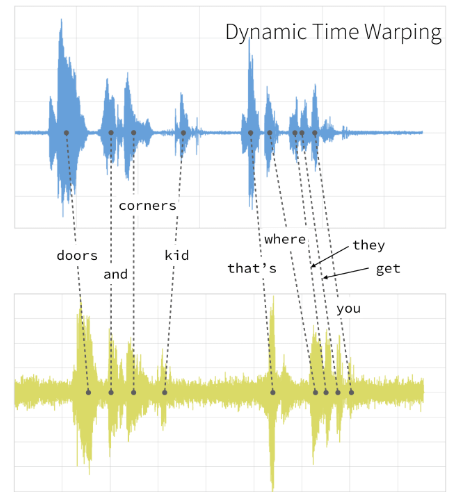
DTW creates a shift in time and maps each element in the series to the closest element in the other series. In other words, DTW finds the optimum distance(the optimum distance here is the shortest distance) between the elements while doing this mapping. So a time shift will be created.
DTW创建时间偏移,并将序列中的每个元素映射到另一个序列中最接近的元素。 换句话说,DTW在执行此映射时会找到元素之间的最佳距离(此处的最佳距离是最短距离)。 因此将创建一个时移。
These distances between points are stored in a table. This is called memoization. Then the shortest paths are added, and this is our similarity measure between two time series. Remember, we are trying to detect the similarity between the two signals.
点之间的这些距离存储在表格中。 这称为记忆 。 然后添加最短路径,这是我们在两个时间序列之间的相似性度量。 请记住,我们正在尝试检测两个信号之间的相似性。
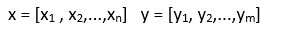
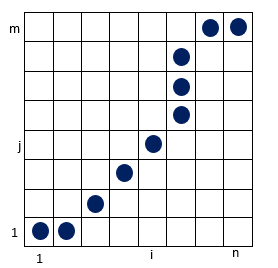
While all this is happening, a path called the warping path is created. Time is shifted according to this path, so the two series reach the same time levels. As the warping path becomes smaller, the similarity between the two time series increases. The warping path occurs according to some rules. The warping function represents these rules. The warping function is applied to both series. Time alignment takes place in this way. This function contains some restrictions: monotonicity, continuity, boundary conditions, and warping window. Thanks to these restrictions, the paths to be tried are limited.
在所有这些发生的同时,创建了一个称为翘曲路径的路径 。 时间根据此路径移动,因此两个系列达到相同的时间水平。 随着翘曲路径变小,两个时间序列之间的相似度增加。 翘曲路径根据某些规则发生。 翘曲函数代表这些规则。 变形功能适用于两个系列。 时间对齐以这种方式进行。 此函数包含一些限制:单调性,连续性,边界条件和翘曲窗口。 由于这些限制,尝试的路径受到限制。
Let me show an example. We have two time series.
让我举一个例子。 我们有两个时间序列。
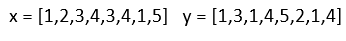
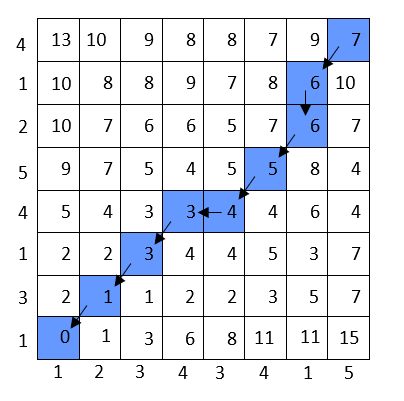
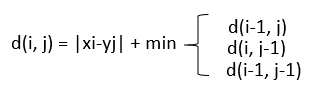
We create a matrix according to the length of the time series. In this example, it’s an 8x8 matrix. We place the values in the time series on the x and y planes. There is a formula we use to calculate the distance between every element in one sequence and every element in the other sequence:
我们根据时间序列的长度创建一个矩阵。 在此示例中,它是一个8x8矩阵。 我们将时间序列中的值放在x和y平面上。 我们使用一个公式来计算一个序列中的每个元素与另一序列中的每个元素之间的距离:
After calculating the distances, we determine the warping path. The sum of the minimum distances gives us a measure of similarity between the two time series.
计算距离后,我们确定翘曲路径。 最小距离的总和使我们可以度量两个时间序列之间的相似性。
Let’s say we have voice recordings of two different people who say the same sentence. They will have said the same words at different times. It would be appropriate to use the DTW algorithm to solve the time shift here. We have said that an audio signal generates a time series. So, to measure the similarity between the two time series we have, we must do the following:
假设我们有两个说相同句子的人的录音。 他们将在不同的时间说相同的话。 在这里使用DTW算法来解决时移是适当的。 我们已经说过,音频信号会生成一个时间序列。 因此,要衡量两个时间序列之间的相似度,我们必须执行以下操作:
- Divide both time series into equal parts.将两个时间序列均分。
- Compare one point in the time series with every point in the other time series and store the distances in the table. (This is the memoization part.)将时间序列中的一个点与另一时间序列中的每个点进行比较,并将距离存储在表中。 (这是备忘录部分。)
- Do step 2 for each point in the time series.对时间序列中的每个点执行步骤2。
- Then do step 2 and step 3 for the second time series.然后对第二个时间序列执行步骤2和步骤3。
- Create the warping path.创建变形路径。
- Add all the minimum distances. This is a measure of the similarity between the two time series.加上所有最小距离。 这是两个时间序列之间相似度的度量。
If you do not create a time shift in this way, two time series that are similar will appear as different series because the words are not spoken at the same time.
如果您不以这种方式创建时移,则两个相似的时间序列将显示为不同的序列,因为单词不是同时说出的。
The complexity of the algorithm is O(N*M) where N and M represent the length of each sequence.
该算法的复杂度为O(N * M),其中N和M代表每个序列的长度。
使用DTW算法的单词识别 (Word Identification Using DTW Algorithm)
Word definition can be done in two ways: a comparison of signal spectrograms or direct comparison of signals.
字定义可以通过两种方式完成:信号频谱图的比较或信号的直接比较。
We have already explained the direct comparison of the signals above. However, numerical values in a sequence can be quite high. In such a case, numerical values should be reduced with a certain sensitivity. If the time series contains a large number of elements, this can cause some problems. For example, many distance calculations are made. There is a method developed to solve such problems: FastDTW.
我们已经解释了上面信号的直接比较。 但是,序列中的数值可能会很高。 在这种情况下,应该以一定的灵敏度减小数值。 如果时间序列包含大量元素,则可能会引起一些问题。 例如,进行了许多距离计算。 有一种解决此类问题的方法:FastDTW。
The comparison of signal spectrograms has also the same logic. A spectrogram is a diagram used to analyze the sound according to the time. A numeric signal is divided into certain ranges. This is called a window. A transform (quick Fourier transform) is applied for each window, and they are stored in a matrix.
信号频谱图的比较也具有相同的逻辑。 频谱图是用于根据时间分析声音的图。 数字信号被分为某些范围。 这称为窗口 。 将变换(快速傅立叶变换)应用于每个窗口,并将它们存储在矩阵中。
动态编程的痕迹 (Traces of Dynamic Programming)
Separating a complex problem into sub-problems and memoization is the logic of dynamic programming. Because it hides the solution of each sub-problem, it does not have to solve it again when it encounters the same sub-problem. In this way, time is saved. However, more space is needed because the solution of each sub-problem is stored.
将复杂的问题分为子问题和备忘录是动态编程的逻辑。 因为它隐藏了每个子问题的解决方案,所以在遇到相同的子问题时不必再次解决它。 这样,可以节省时间。 但是,由于存储了每个子问题的解决方案,因此需要更多空间。
结论 (Conclusion)
Now we understand why the DTW algorithm is suitable for speech recognition. We have learned how DTW is used to define the word and to process audio signals. We have seen how it accomplished this process. We also saw the difference from Euclidian, a traditional method of matching.
现在我们了解了为什么DTW算法适合语音识别。 我们已经了解了DTW如何用于定义单词和处理音频信号。 我们已经看到它是如何完成此过程的。 我们还看到了与传统匹配方法Euclidian的区别。
It looked like a rather complicated issue, but it wasn’t that hard, right? Remember, if you understand what the problem is, the solutions make more sense to you. Good work everyone!
它看起来像一个相当复杂的问题,但这并不难,对吧? 请记住,如果您了解问题所在,则解决方案对您更有意义。 大家好!
资源资源 (Resources)
https://www.researchgate.net/publication/26569937_Dynamic_Programming_Algorithms_in_Speech_Recognition
https://www.researchgate.net/publication/26569937_Dynamic_Programming_Algorithms_in_Speech_Recognition
https://databricks.com/blog/2019/04/30/understanding-dynamic-time-warping.html
https://databricks.com/blog/2019/04/30/understanding-dynamic-time-warping.html
翻译自: https://medium.com/better-programming/how-to-do-speech-recognition-with-a-dynamic-time-warping-algorithm-159c2a1bb83c
动态时间规整算法
http://www.taodudu.cc/news/show-1873906.html
相关文章:
- 逻辑运算 神经网络_使用神经网络实现逻辑门(第2部分)
- ai 实用新型专利_专利制度协调AI创造的创新
- 缓冲区是人为设定的吗_人为的,但这真的是情报吗?
- 对Librehash海洋协议审查的回应
- 使用lstm实现文本生成_Spamilton:使用LSTM和Hamilton歌词生成文本
- nlp n-gram_NLP中的单词嵌入:一键编码和Skip-Gram神经网络
- nas神经网络架构搜索_神经建筑搜索(NAS)基础
- web与ai相结合成为趋势_将AI和行为科学相结合可以改变体验
- 递归神经网络/_递归神经网络
- Kardashev量表和AI:可能的床友
- 变异数分析_人工智能系统中分析变异的祸害
- ai时代大学生的机遇和挑战_评估AI对美术的影响:威胁或机遇
- 人工智能+智能运维解决方案_人工智能驱动的解决方案可以提升您的项目管理水平
- c语言 机器语言 汇编语言_多语言机器人新闻记者
- BrainOS —最像大脑的AI
- 赵本山 政治敏锐_每天5分钟保持敏锐的7种方法
- 面试问到处理过什么棘手问题_为什么调节人工智能如此棘手?
- python svm向量_支持向量机(SVM)及其Python实现
- 游戏世界观构建_我们如何构建技术落后的世界
- 信任的机器_您应该信任机器人吗?
- ai第二次热潮:思维的转变_基于属性的建议:科技创业公司如何使用AI来转变在线评论和建议
- 建立RoBERTa模型以发现Reddit小组的情绪
- 谷歌浏览器老是出现花_Google全新的AI平台值得您花时间吗?
- nlp gpt论文_开放AI革命性的新NLP模型GPT-3
- 语音匹配_什么是语音匹配?
- 传统量化与ai量化对比_量化AI偏差的风险
- ai策略机器人研究a50_跟上AI研究的策略
- ai人工智能 工业运用_人工智能在老年人健康中的应用
- 人工智能民主化无关紧要,数据孤岛以及如何建立一家AI公司
- 心公正白壁无瑕什么意思?_人工智能可以编写无瑕的代码后,编码会变得无用吗?
动态时间规整算法_如何使用动态时间规整算法进行语音识别相关推荐
- Python_机器学习_算法_第1章_K-近邻算法
Python_机器学习_算法_第1章_K-近邻算法 文章目录 Python_机器学习_算法_第1章_K-近邻算法 K-近邻算法 学习目标 1.1 K-近邻算法简介 学习目标 1 什么是K-近邻算法 1 ...
- 距离矢量路由算法_计算机网络自学笔记:选路算法
网络层必须确定从发送方到接收方分组所经过的路径.选路就是在网络中的路由器里的给某个数据报确定好路径(即路由). 一台主机通常直接与一台路由器相连接,该路由器即为该主机的默认路由器,又称为该主机的默认网 ...
- 喜用神最正确的算法_关于RFID系统的防碰撞算法有哪些呢?
在超高频读写器的产品参数中经常会出现"防碰撞协议"等字眼,那么可以实现防碰撞协议的算法有哪些呢?下面就和小编一起来了解了解! 1.纯ALOHA算法 此算法主要采用标签先发言的方式, ...
- 希尔排序是一种稳定的排序算法_全面解析十大排序算法之四:希尔排序
点击上方蓝字关注我们吧 1. 十种排序算法的复杂度和稳定性 时间复杂度:一个算法消耗所需要的时间 空间复杂度:运行一个算法所需要的内存时间 稳定性:如一个排列数组:1.4.5.6.4.7. 此时有一对 ...
- java实现apriori算法_七大经典、常用排序算法的原理、Java 实现以及算法分析
0. 前言 大家好,我是多选参数的程序员,一个正再 neng 操作系统.学数据结构和算法以及 Java 的硬核菜鸡.数据结构和算法是我准备新开的坑,主要是因为自己再这块确实很弱,需要大补(残废了一般) ...
- 沃舍尔算法_[数据结构拾遗]图的最短路径算法
前言 本专题旨在快速了解常见的数据结构和算法. 在需要使用到相应算法时,能够帮助你回忆出常用的实现方案并且知晓其优缺点和适用环境.并不涉及十分具体的实现细节描述. 图的最短路径算法 最短路径问题是图论 ...
- 错误录入 算法_如何使用验证错误率确定算法输出之间的关系
错误录入 算法 Monument (www.monument.ai) enables you to quickly apply algorithms to data in a no-code inte ...
- 路径规划算法_自动驾驶汽车路径规划算法浅析
自动驾驶汽车的路径规划算法最早源于机器人的路径规划研究,但是就工况而言却比机器人的路径规划复杂得多,自动驾驶车辆需要考虑车速.道路的附着情况.车辆最小转弯半径.外界天气环境等因素. 本文将为大家介绍四 ...
- xgboost算法_工业大数据:分析算法
一. 应用背景 大数据分析模型的研究可以分为3个层次,即描述分析(探索历史数据并描述发生了什么).预测分析(未来的概率和趋势)和规范分析(对未来的决策给出建议).工业大数据分析的理论和技术研究仍处于起 ...
- ++代码实现 模糊综合算法_干货 | 十大经典排序算法最强总结(内含代码实现)...
一.算法分类 十种常见排序算法可以分为两大类: 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序. 非比较类排序:不通过比较来决定元 ...
最新文章
- flask_sqlalchemy 多对多 关系 对中间表的操作
- QuartzCore框架-- iOS中的动画
- 开了一论坛,专门讨论控件技术
- glusterfs快速安装
- 验证视图状态 MAC 失败的解决办法
- 字体怎么安装到电脑上_文章还在使用电脑上的固定字体?这款字体软件超好用...
- LeetCode 507. Perfect Number
- canal 入门(1)
- postfix+dovecot+maildrop+mailscanner+clamav+spamassassin搭建rhel6平台邮件服务器
- 阿里云云计算 48 云安全中心
- Ubuntu五笔输入法的安装过程
- 爬取学校教务网课表与成绩 java版
- MATLAB随机信号分析与处理
- win10如何添加linux开机引导,win10 linux 双系统怎么设置开机引导
- 学计算机做近视眼手术,做完近视眼手术后多久可以看电脑
- 【Unity3d】U3d灯光
- 2020年的19种最佳React Native App模板(包括5种免费)
- 计算机专业ib选课,IB 课程里,总算发现一个貌似容易的学科了!
- linux终端里面的光标很粗,怎么调细
- 云端服务器部署前端工程