蒙特卡洛树搜索算法实现_蒙特卡洛树搜索实现实时学习中的强化学习
蒙特卡洛树搜索算法实现
In the previous article, we covered the fundamental concepts of reinforcement learning and closed the article with these two key questions:
在上一篇文章中 ,我们介绍了强化学习的基本概念,并用以下两个关键问题结束了本文:
1 — how can we find the best move among others if we cannot process all the successive states one by one due to limited amount of time?
1-如果由于时间有限而无法一一处理所有连续状态,我们如何找到其他最佳状态?
2 — how do we map the task of finding best move to long-term rewards if we are limited in terms of computational resources and time?
2-如果我们在计算资源和时间方面受到限制,我们如何映射找到最佳方法以获得长期回报的任务?
In this article, to answer these questions, we go through the Monte Carlo Tree Search fundamentals. Since in the next articles, we will implement this algorithm on “HEX” board game, I try to explain the concepts through examples in this board game environment.If you’re more interested in the code, find it in this link. There is also a more optimized version which is applicable on linux due to utilizing cython and you can find it in here.
在本文中,为了回答这些问题,我们将介绍“蒙特卡洛树搜索”的基本原理。 由于在下一篇文章中,我们将在“ HEX”棋盘游戏上实现此算法,因此我尝试通过此棋盘游戏环境中的示例来解释这些概念。如果您对代码更感兴趣,请在此链接中找到它。 由于利用了cython ,还有一个更优化的版本可用于linux,您可以在这里找到它。
Here are the outlines:
概述如下:
1 — Overview
1 —概述
2 — Exploration and Exploitation Trade-off
2 —勘探与开发的权衡
3 — HEX: A Classic Board Game
3 —十六进制:经典棋盘游戏
4 — Algorithm structure: Selection and Expansion
4 —算法结构:选择和扩展
5 — Algorithm structure: Rollout
5-算法结构:推出
6 — Algorithm structure: Backpropagation
6-算法结构:反向传播
7 — Advantages and Disadvantages
7 —优缺点
Conclusion
结论
总览 (Overview)
Monte Carlo method was coined by Stanislaw Ulam for the first time after applying statistical approach “The Monte Carlo method”. The concept is simple. Using randomness to solve problems that might be deterministic in principle. For example, in mathematics, it is used for estimating the integral when we cannot directly calculate it. Also in this image, you can see how we can calculate pi based on Monte-Carlo simulations.
斯坦尼斯拉夫·乌兰(Stanislaw Ulam)在采用统计方法“蒙特卡洛方法”之后首次提出了蒙特卡洛方法。 这个概念很简单。 使用随机性来解决原则上可以确定的问题。 例如,在数学中,当我们无法直接计算积分时,它用于估计积分。 同样在此图像中,您可以看到我们如何基于蒙特卡洛模拟来计算pi。
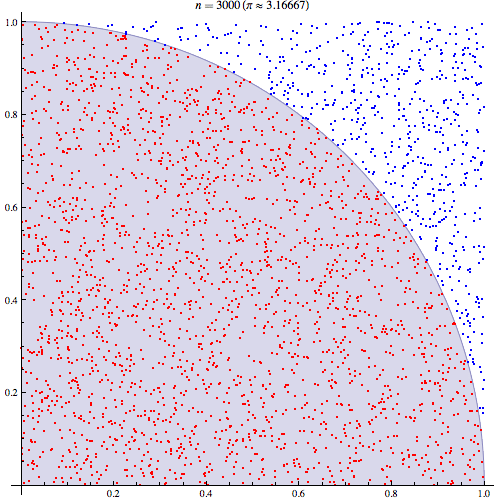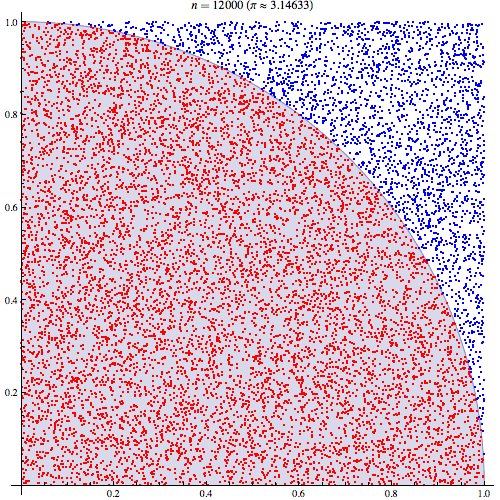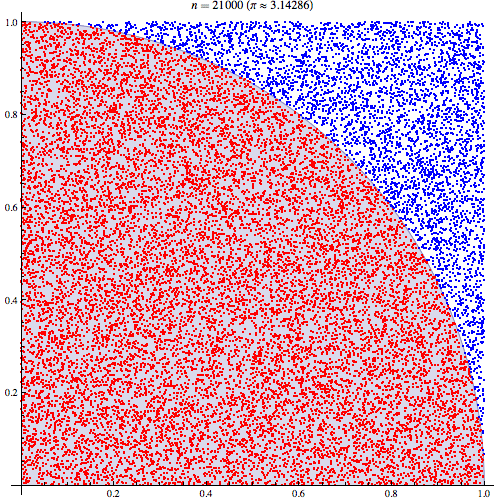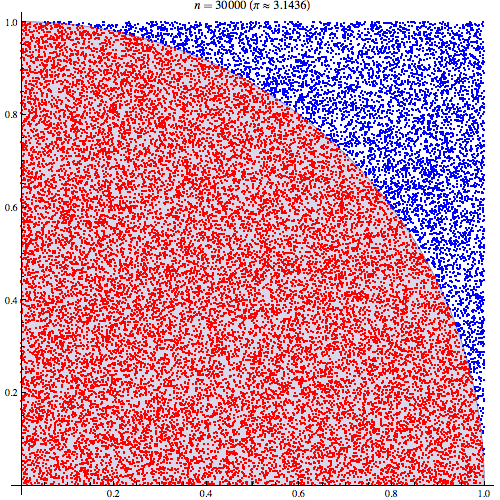
The image above indicates the fact that in monte carlo method the more samples we gather, more accurate estimation of target value we will attain.
上面的图像表明,在蒙特卡洛方法中,我们收集的样本越多,我们将获得的目标值的估计就越准确。
- But how does Monte Carlo Methods come in handy for general game playing?但是,蒙特卡洛方法如何在一般游戏中派上用场呢?
We use Monte Carlo method to estimate the quality of states stochastically based on simulations when we cannot process through all the states. Each simulation is a self-play that traverses the game tree from current state until a leaf state (end of game) is reached.
当我们无法处理所有状态时,我们会使用Monte Carlo方法根据模拟随机 估计状态的质量 。 每个模拟都是一种自玩游戏,可从当前状态遍历游戏树直到达到叶子状态(游戏结束)。
So this algorithm is just perfect to our problem.
因此,该算法非常适合我们的问题。
- Since it samples the future state-action space, it can estimate near optimal action in current state by keeping computation effort low (which addresses the first question).
-由于它对未来的状态动作空间进行采样,因此可以通过保持较低的计算工作量来解决当前状态下的最佳动作(这解决了第一个问题)。
- Also the fact that it chooses the best action based on long-term rewards (rewarding based on the result in tree leaves) answers the second question.
-同样,它基于长期奖励选择最佳行动(根据树叶的结果进行奖励)这一事实也回答了第二个问题。
This process is exactly like when a human wants to estimate the future action to come up with the best possible action in the game of chess. He thinks simulates various games (from current state to the last possible state of future) based on self-play in his/her mind and chooses the one that has the best overall results.
这个过程就像一个人想要估计将来的动作以在国际象棋比赛中做出最好的动作一样。 他认为可以根据自己的想法模拟各种游戏(从当前状态到将来的最后可能状态),并选择总体效果最好的游戏。
Monte Carlo Tree Search (MCTS), which combines monte carlo methods with tree search, is a method for finding optimal decisions in a given domain by taking random samples in the decision space and building a search tree according to the results.
蒙特卡洛树搜索(MCTS)将蒙特卡洛方法与树搜索相结合,是一种通过在决策空间中抽取随机样本并根据结果构建搜索树来在给定域中找到最佳决策的方法。
Before we explain the algorithm structure, we should first discuss the exploration and exploitation trade-off.
在解释算法结构之前,我们应该首先讨论勘探与开发之间的权衡。
勘探与开发的权衡 (Exploration and Exploitation Trade-off)
As explained, In reinforcement learning, an agent always aims to achieve an optimal strategy by repeatedly using the best actions that it has found in that problem (remember the chess example in the previous article). However, there is a probability that the current best action is not actually optimal. As such it will continue to evaluate alternatives periodically during the learning phase by executing them instead of the perceived optimal. In RL terms, this is known as exploration exploitation trade-off. All of the algorithms in RL (MCTS as well) are trying to balance the exploration-exploitation trade-off.
如前所述,在强化学习中,代理始终旨在通过重复使用在该问题中发现的最佳行动来实现最佳策略 (请记住上一篇国际象棋示例)。 但是,当前的最佳动作实际上可能不是最佳的。 因此,它将继续通过执行替代方案而不是感知到的最佳方案,在学习阶段定期评估替代方案。 用RL术语来说,这称为勘探开发权衡 。 RL中的所有算法(以及MCTS)都在尝试平衡勘探与开发之间的权衡。
I think this video best explains the concept of exploration-exploitation:
我认为这段视频最能说明勘探开发的概念:
十六进制:经典棋盘游戏 (HEX: A Classic Board Game)
Now it’s time to get to know the Hex game. It has simple rules:
现在是时候了解十六进制游戏了。 它有简单的规则 :
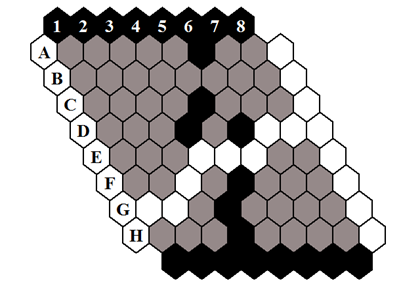
- Black and white alternate turns.黑白交替轮流。
- On each turn a player places a single stone of its color on any unoccupied cell.玩家在每个回合上将一块彩色的石头放在任何未占用的单元上。
- The winner is the player who forms a chain of their stones connecting their two opposing board sides.获胜者是将两块相对的棋盘面连接起来的石头链。
Hex can never end in a draw and be played on any n × n board [1].
十六进制永远不能以平局结束,不能在任何n×n棋盘上玩[1] 。
Now let`s go through the algorithm structure.
现在让我们看一下算法的结构。
算法结构 (Algorithm structure)
1 —选择和扩展 (1 — Selection and Expansion)
In this step, agent takes the current state of the game and selects a node (Each node represents the state resulted by choosing an action) in tree and traverses the tree. Each move in each state is assigned with two parameters namely as total rollouts and wins per rollouts (they will be covered in rollout section).
在此步骤中,代理获取游戏的当前状态 ,并在树中选择一个节点(每个节点代表通过选择一个动作所导致的状态)并遍历该树。 每种状态下的每次移动都分配有两个参数,即总卷数和每卷的胜利数(它们将在卷数部分中介绍)。
The strategy to select optimal node among other nodes really matters. Upper Confidence Bound applied to Trees (UCT) is the simplest and yet effective strategy to select optimal node. This strategy is designed to balance the exploitation-exploration trade-off. This is UCT formula:
在其他节点之间选择最佳节点的策略确实很重要。 应用于树(UCT)的上限置信度是选择最佳节点的最简单但有效的策略。 该策略旨在平衡开发与开发之间的权衡。 这是UCT公式:
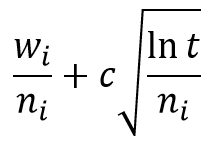
In this formula i indicates i-th node in children nodes. W is the number of wins per rollouts and n is the number of all rollouts. This part of formula represents the exploitation.Cis the exploration coefficient and it’s a constant in range of [0,1]. This parameter indicates how much agent have to favor unexplored nodes. t is the number of rollouts in parent node. the second term represents the exploration term.
在该公式中, i表示子节点中的第i个节点。 W是每次部署的获胜数, n是所有部署的数。 公式的这一部分代表开发。 C是勘探系数,在[0,1]范围内是一个常数。 此参数指示有多少代理必须支持未探索的节点。 t是父节点中的部署数量。 第二项代表探索项。
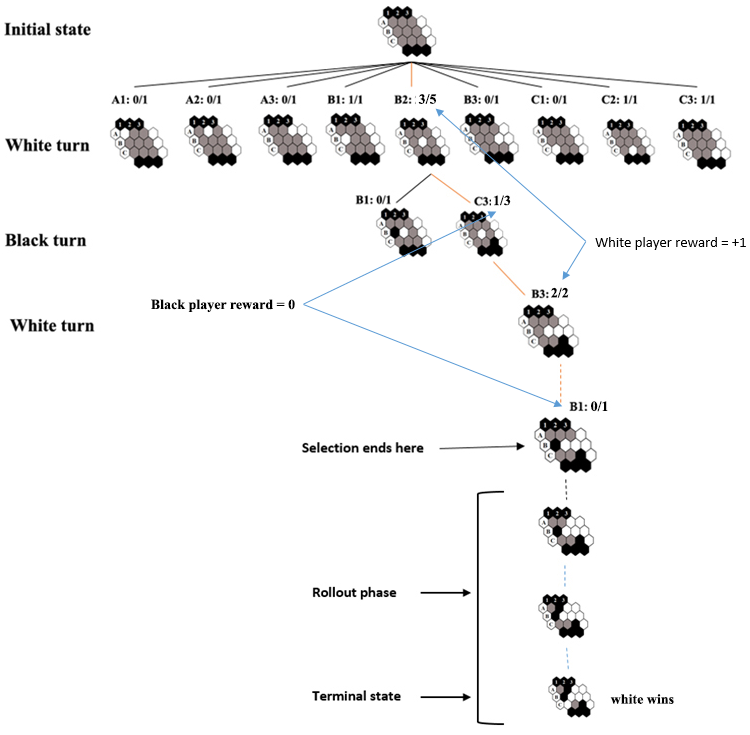
Let’s go through an example in order to have all information provided to sink in. Look at the image below:
让我们来看一个示例,以便提供所有信息以供参考。看下面的图像:
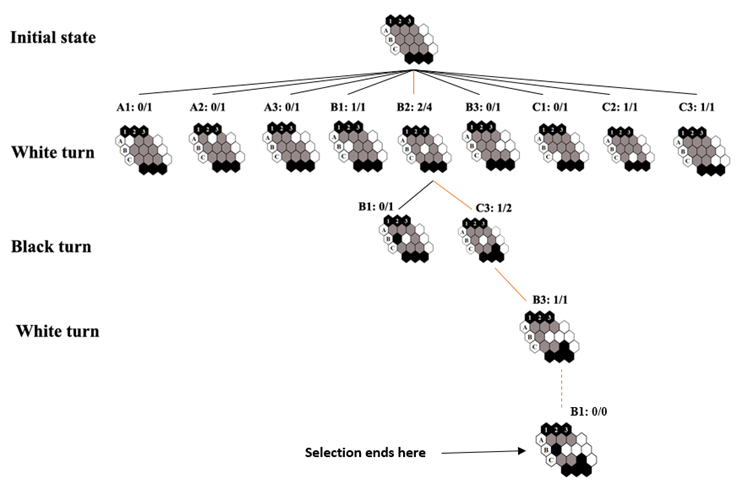
Consider the action C3 in depth 2. is 2 and is 1. t is the parent node number of rollouts which is 4. As you see selection phase stops in the depth where we have an unvisited node. Then in the expansion phase when we visit B1 in depth 4, we add it to tree.
考虑深度2中的动作C3为2且为1。t是展开的父节点数,即4。如您所见,选择阶段停止在深度中我们没有访问节点的位置。 然后在扩展阶段,当我们访问深度4的B1时,将其添加到树中。
2-推出(也称为模拟,播放) (2 — Rollout (also called simulation, playout))
In this step, based on predefined policy (like completely random selection) we select actions until we reach a terminal state. The result of game for current player is either 0 (if it loses the rollout) or 1 (if it wins the rollout) at the terminal state. In the game of HEX, the terminal state is always reachable and the result of game is loss or win (no draws). But in games like chess we might get in an infinite loop due to the extensibility of chess branch factor and depth of search tree.
在此步骤中,基于预定义的策略(例如完全随机选择),我们选择操作,直到达到最终状态。 在终端状态下,当前玩家的游戏结果为0 (如果失败,则失败)或1 (如果胜利,则失败)。 在十六进制的游戏中,终端状态始终是可到达的,游戏的结果是输赢(无平局)。 但是在象棋这样的游戏中,由于象棋分支因子的可扩展性和搜索树的深度,我们可能陷入无限循环。
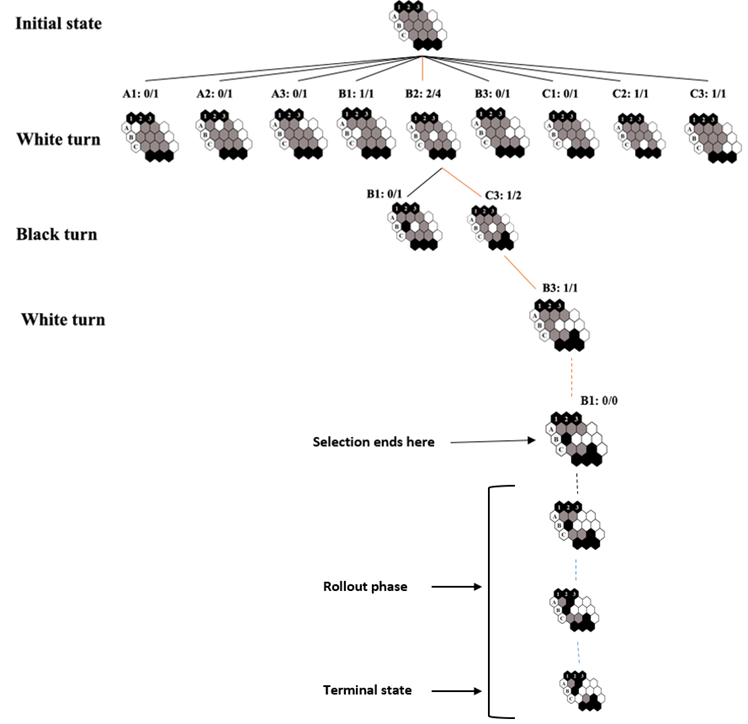
In the image above, after that black player chose B1 in expansion step, in the simulation step a rollout is started to terminal state of game.
在上图中,该黑人玩家在扩展步骤中选择了B1,然后在模拟步骤中开始将游戏推广到游戏的最终状态。
In here, we chose random actions to reach the terminal state of the game. In terminal state as you see, white player has won the game by connecting the left to right with its stones. Now it’s time to use this information in backpropagation part.
在这里,我们选择了随机动作来达到游戏的最终状态。 如您所见,在终端状态下,白人玩家通过从左到右连接石头赢得了比赛。 现在是时候在反向传播部分中使用此信息了。
3-反向传播 (3 — Backpropagation)
In this part, we update the statistics (rollout number and the number of wins per total rollouts) in the nodes which we traversed in tree for selection and expansion parts.
在本部分中,我们更新在树中遍历的节点中用于选择和扩展部分的节点中的统计信息(推广数量和每总推广的获胜次数)。
During backpropagation we need to update the rollout numbers and wins/losses stats of nodes. Only thing we need is to figure out the player who won the game in rollout (e.g. white player in figure 4).
在反向传播期间,我们需要更新部署数量和节点的赢/亏状态。 我们唯一需要做的就是找出在发布中赢得比赛的玩家(例如,图4中的白人玩家)。
For the figure 4, since the black player is the winner (who chose the action in terminal state), all the states resulted by black player actions are rewarded by 1 and states which resulted by white player actions are given 0 reward (we can choose punishment by set it to -1).
对于图4,由于黑人玩家是获胜者(他们选择了终端状态的动作),因此黑人玩家动作导致的所有状态都将获得1奖励,而白人玩家行为导致的所有状态将获得0奖励(我们可以选择将其设置为-1)。
For all states (tree nodes selected through step 1), total rollouts number increases by one as the figure 6 displays.
对于所有状态(通过步骤1选择的树节点),如图6所示,总卷展数量增加1。
These steps keep repeating until a predefined condition ends the loop (like time limit).
这些步骤不断重复,直到预定义条件结束循环(如时间限制)为止。
的优点和缺点 (Advantages and Disadvantages)
Advantages:
优点:
1 — MCTS is a simple algorithm to implement.
1-MCTS是一种易于实现的算法。
2 — Monte Carlo Tree Search is a heuristic algorithm. MCTS can operate effectively without any knowledge in the particular domain, apart from the rules and end conditions, and can find its own moves and learn from them by playing random playouts.
2-蒙特卡洛树搜索是一种启发式算法。 MCTS可以在规则和最终条件之外的任何特定领域内有效地运作,而无需任何知识,并且可以通过播放随机播报找到自己的动作并从中学习。
3 — The MCTS can be saved in any intermediate state and that state can be used in future use cases whenever required.
3-MCTS可以以任何中间状态保存,并且可以在需要时在以后的用例中使用该状态。
4 — MCTS supports asymmetric expansion of the search tree based on the circumstances in which it is operating.
4-MCTS支持基于其运行情况的搜索树的非对称扩展。
Disadvantages:
缺点:
1 — As the tree growth becomes rapid after a few iterations, it might require a huge amount of memory.
1-随着几次迭代后树的增长变得Swift,它可能需要大量的内存。
2 — There is a bit of a reliability issue with Monte Carlo Tree Search. In certain scenarios, there might be a single branch or path, that might lead to loss against the opposition when implemented for those turn-based games. This is mainly due to the vast amount of combinations and each of the nodes might not be visited enough number of times to understand its result or outcome in the long run.
2-蒙特卡洛树搜索存在一些可靠性问题。 在某些情况下,可能存在单个分支或路径,当为那些基于回合的游戏实施时,可能导致输给对手。 这主要是由于大量的组合,从长远来看,每个节点可能没有被足够多次地访问以了解其结果或结果。
3 — MCTS algorithm needs a huge number of iterations to be able to effectively decide the most efficient path. So, there is a bit of a speed issue there.
3-MCTS算法需要大量的迭代才能有效地确定最有效的路径。 因此,那里存在速度问题。
4 — MCTS can return a recommended move at any time because the statistics about the simulated games are constantly updated. The recommended moves aren’t great when the algorithm starts, but they continually improve as the algorithm runs.
4-MCTS可以随时返回建议的举动,因为有关模拟游戏的统计信息会不断更新。 当算法开始时,建议的举动并不好,但是随着算法的运行,它们会不断提高。
结论 (Conclusion)
Now we figured out how the MCTS algorithm can efficiently use randomness to sample all the possible scenarios and come up with the best action over its simulations. The quality of action chosen by MCTS in each time lies in the fact that how well it can handle the exploration and exploitation in the environment.
现在,我们弄清楚了MCTS算法如何能够有效地使用随机性对所有可能的场景进行采样,并在模拟过程中提出最佳措施。 MCTS每次选择的行动质量取决于这样一个事实,即它可以很好地处理环境中的勘探和开发。
OK, now that we covered necessary theoretical concepts so far, we’re good to go to the next level with getting our hands dirty with code. In the next article, first, we’re going to describe the whole framework and necessary modules to implement, then we will implement the basic MCTS with UCT. After that, we will improve the framework by adding more functionality to our code.
好的,到目前为止,我们已经涵盖了必要的理论概念,我们很高兴进入新的阶段,着手编写代码。 在下一篇文章中,首先,我们将描述整个框架和要实现的必要模块,然后,我们将使用UCT实现基本的MCTS。 之后,我们将通过向代码中添加更多功能来改进框架。
翻译自: https://towardsdatascience.com/monte-carlo-tree-search-implementing-reinforcement-learning-in-real-time-game-player-25b6f6ac3b43
蒙特卡洛树搜索算法实现
http://www.taodudu.cc/news/show-5050129.html
相关文章:
- 强化学习笔记(七):蒙特卡洛树搜索(MonteCarlo Tree Search)
- 环境设计相关html,环境艺术设计专业需要什么样配置的电脑?
- 【快速了解造成游戏过程卡的罪魁祸首】
- ChinaJoy直击:AMD显卡树立1080p高帧率、高保真PC游戏新标准
- 计算机AMD方案不超过4000元,4000元左右AMD R5-1400配RX570全新芯片显卡电脑配置推荐...
- 2005年显卡盘点
- 主流显卡生产厂商全面剖析--各种显卡品牌
- 计算机专业台式机推荐,台式机显卡哪款好 台式机显卡推荐【详细介绍】
- 显卡挑选1
- 修改cpu控制文件init.qcom.post_boot.改调节器
- Fanuc数据控机床数据采集Focus2基于c#的数据采集
- 工业数据采集方案:有何作用和特点?
- 工业设备数据采集的意义
- 工业数据采集智能网关盘点
- c#实现上位机数据采集的项目总结
- 工业智能网关是工厂设备数据采集解决方案工具
- 基于高并发的数据采集器
- 数据采集的数据源有哪些?
- 使用OPCServer通过Modbus协议对汇川PLC进行工业数据采集
- QT图形界面在工业数据采集显示系统的应用
- 数据来源渠道及采集工具_工业数据采集工具
- 树莓派python工业数据采集系统
- 终于有人把工业数据采集讲明白了
- 那些你可能需要的音乐聚合网站
- Python疫起学习·万丈高楼平地起Day09(精简版|浓缩就是精华)爬虫知识附上案例爬取北京地区短租房信息、爬取酷狗TOP500的数据以及爬取网易云音乐热歌榜单
- hexo yilia主题添加音乐
- Java毕业作品设计:音乐管理系统(网页版)
- music功能 vue_Vue 全家桶实现移动端酷狗音乐功能
- 淘宝商品详情接口(app、h5端)
- 使用淘宝接口查询ip归属地
蒙特卡洛树搜索算法实现_蒙特卡洛树搜索实现实时学习中的强化学习相关推荐
- 深度强化学习_深度学习理论与应用第8课 | 深度强化学习
本文是博雅大数据学院"深度学习理论与应用课程"第八章的内容整理.我们将部分课程视频.课件和讲授稿进行发布.在线学习完整内容请登录www.cookdata.cn 深度强化学习是一种将 ...
- 蒙特卡洛树搜索 棋_蒙特卡罗树搜索赢得黑白棋
蒙特卡洛树搜索 棋 With the COVID-19 pandemic still wreaking havoc around the world, many of us have been stu ...
- 蒙特卡洛方法、蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS) 学习
文章目录 1. 从多臂赌博机说起 2. UCB 3. 蒙特卡洛树搜索 4. 伪代码 提出一个问题: 假设你当前有n个币,面前有k个赌博机.每个赌博机投一个币后摇动会产生随机的产出,你会怎么摇? 1. ...
- 结构体实验报告总结_解读!清华、谷歌等10篇强化学习论文总结
强化学习(Reinforcement Learning,RL)正成为当下机器学习中最热门的研究领域之一.与常见的监督学习和非监督学习不同,强化学习强调智能体(agent)与环境(environment ...
- python 替换文本 通配符_使用通配符搜索和替换文本文件中的字符串
尝试在python中对文本文件的内容使用通配符进行搜索/替换: 如果文本文件的内容看起来像:"all_bcar_v0038.ma"; "all_bcar_v0002.ma ...
- c++ 删除二叉树的子树_数据结构—树|二叉树|前序遍历、中序遍历、后序遍历【图解实现】...
点击蓝字关注我们 AI研习图书馆,发现不一样的精彩世界 数据 结构 二叉树的遍历 一.树 在谈二叉树的知识点之前,我们首先来看一下树和图的基本概念.树:不包含回路的连通无向图,树是一种简单的非线性结构 ...
- 监督学习和无监督学习_一篇文章区分监督学习、无监督学习和强化学习
经过之前的一些积累,终于有勇气开始进军机器学习了!说实话,机器学习 这个概念是我入行的最纯粹的原因,包括大学选专业.学习 Python 语言-这些有时间仔细梳理下经历再写,总之这个系列的文章就是我自学 ...
- 机器学习_监督学习、非监督学习、半监督学习以及强化学习概念介绍
机器学习中通常根据数据是否有标签可以分为监督学习(supervised learning).非监督学习(unsupervised learning) 和半监督学习(semi-supervised le ...
- 强化学习-动态规划_强化学习-第5部分
强化学习-动态规划 有关深层学习的FAU讲义 (FAU LECTURE NOTES ON DEEP LEARNING) These are the lecture notes for FAU's Yo ...
最新文章
- 小人脸检测 - Finding Tiny Faces
- python爬虫之微打赏(scrapy版)
- MemCache在Windows环境下的搭建及启动
- 随机采样方法整理与讲解(MCMC、Gibbs Sampling等)
- 中文NER涨点神器!基于多元数据的双流Transformer编码模型
- 牛客练习赛46T1-华华教奕奕写几何【数学】
- div alert html,基于jQuery的弹出消息插件 DivAlert之旅(一)
- mybatis源码学习篇之——执行流程分析
- 简单的物流项目实战,WPF的MVVM设计模式(二)
- linux下安装oracle客户端
- win10隐藏任务栏_win7/10任务栏合并但不隐藏标签
- 共享软件业余者VS共享软件专业者
- mysql-sql操作
- 用VB实现的QQ自动登录器
- day13_spring环境配置及bean使用
- c#Ulong用一个高位Uint和低位Uint表示
- 安全集成服务资质是什么都有哪些等级?申请安全集成服务资质认证有什么好处?
- 禁用微软杀毒和移除以Paint 3D打开的相关注册表:
- STK Components规格书
- 对C++库链接的认识