深度学习|迁移学习|强化学习
1. 深度学习:
基于卷积神经网络的深度学习(包括CNN、RNN),主要解决的领域是 图像、文本、语音,问题聚焦在 分类、回归
也就是我们经典的各种神经网络算法。
![]()
图1:深度学习适用领域
![]()
图2:吴恩达预知的未来五年的主战场-迁移学习
深度学习的局限性:
1. 表达能力的限制。
因为一个模型毕竟是一种现实的反映,等于是现实的镜像,它能够描述现实的能力越强就越准确,而机器学习都是用变量来描述世界的,它的变量数是有限的,深度学习的深度也是有限的。另外它对数据的需求量随着模型的增大而增大,但现实中有那么多高质量数据的情况还不多。所以一方面是数据量,一方面是数据里面的变量、数据的复杂度,深度学习来描述数据的复杂度还不够复杂。
2. 缺乏反馈机制。
目前深度学习对图像识别、语音识别等问题来说是最好的,但是对其他的问题并不是最好的,特别是有延迟反馈的问题,例如机器人的行动,AlphaGo 下围棋也不是深度学习包打所有的,它还有强化学习的一部分,反馈是直到最后那一步才知道你的输赢。还有很多其他的学习任务都不一定是深度学习才能来完成的。
3. 模型复杂度高。
以下是一些当前比较流行的机器学习模型和其所需的数据量,可以看到随着模型复杂度的提高,其参数个数和所需的数据量也是惊人的。

我们可以得出目前传统的机器学习方法(包括深度学习)三个待解决的关键问题:
1). 随着模型复杂度的提高,参数个数惊人。
2). 在新情况下模型泛化能力有待提高。
3). 训练模型的海量的标记费时且昂贵。
4). 表达能力有限且缺乏反馈机制
2. 强化学习:
强化学习,其所带来的推理能力是智能的一个关键特征衡量,真正的让机器有了自我学习、自我思考的能力。
主要应用
- 游戏 AI 领域( AlphaGo);
- 机器人领域;
![]()
图 4::David Silver 将强化学习理解为一种交叉学科
强化学习是主要包含四个元素:
对象(Agent): 也就是我们的智能主题,比如 AlphaGo。
环境(Environment): Agent 所处的场景-比如下围棋的棋盘,以及其所对应的状态(State)-比如当前所对应的棋局。 Agent 需要从 Environment 感知来获取反馈(当前局势对我是否更有利)。
动作 (Actions) : 在每个State下,可以采取什么行动,针对每一个 Action 分析其影响。
奖励 (Rewards) : 执行 Action 之后,得到的奖励或惩罚,Reward 是通过对 环境的观察得到。
输出:Next Action
3. 迁移学习:
可参考腾讯云的一篇博文:https://cloud.tencent.com/developer/article/1005176
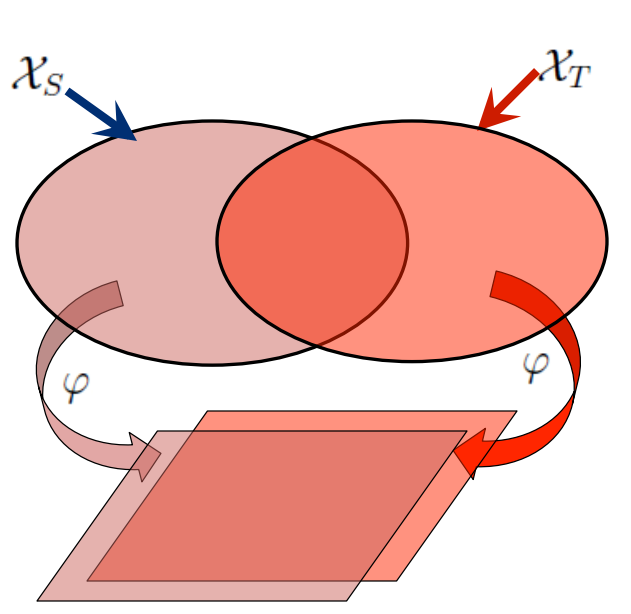
迁移学习的来源是关注的场景缺少足够的数据来完成训练,在这种情况下你需要通过迁移学习来实现模型本身的泛化能力,也就是说当前场景数据集和label不多,但是相关的数据集多,同时也比较类似,所以可以用来掺和在一起增加数据集的量。
![]()
图3:迁移学习和传统机器学习
迁移学习的必要性和价值体现:
1. 复用现有知识域数据,已有的大量工作不至于完全丢弃;
2. 不需要再去花费巨大代价去重新采集和标定庞大的新数据集,也有可能数据根本无法获取;
3. 对于快速出现的新领域,能够快速迁移和应用,体现时效性优势;
迁移学习算法的思路:
1. 通过原有数据和少量新领域数据混淆训练;
2. 将原训练模型进行分割,保留基础模型(数据)部分作为新领域的迁移基础;
3. 通过三维仿真来得到新的场景图像(OpenAI的Universe平台借助赛车游戏来训练);
4. 借助对抗网络 GAN 进行迁移学习的方法;
图5:迁移学习的四种常见的解决方法
- 基于样本的迁移学习
- 基于特征的迁移学习
- 基于参数/特征的迁移学习
- 基于关系的迁移学习
(1) 基于样本的迁移学习

第一种为样本迁移,就是在数据集(源领域)中找到与目标领域相似的数据,把这个数据的权值进行调整,使得新的数据与目标领域的数据进行匹配(将分布变成相同)。样本迁移的特点是:1)需要对不同例子加权;2)需要用数据进行训练,上图的例子就是找到源领域的例子 3,然后加重该样本的权值,使得在预测目标领域时的比重加大。
(2) 基于特征的迁移学习

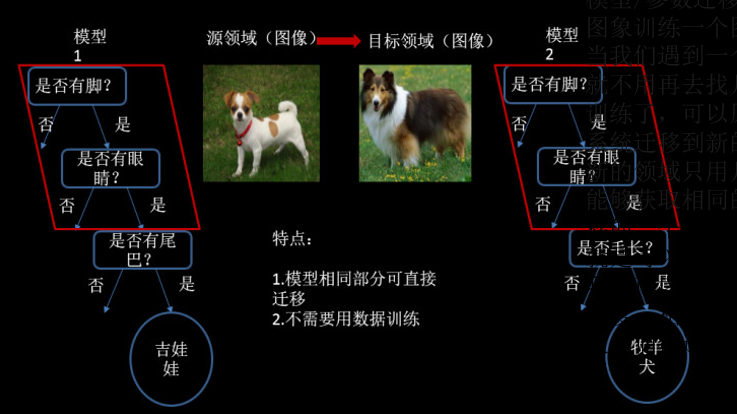
第二种为特征迁移,就是通过观察源领域图像与目标域图像之间的共同特征,然后利用观察所得的共同特征在不同层级的特征间进行自动迁移,上图左侧的例子就是找当两种狗在不同层级上的共同特征,然后进行预测。
(3) 基于参数/模型的迁移学习
第三种为模型迁移,其原理时利用上千万的狗狗图象训练一个识别系统,当我们遇到一个新的狗狗图象领域,就不用再去找几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是我们可以区分,就是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些。
(4) 基于关系的迁移学习

这种关系的迁移,我研究的较少,定义说明是可以将两个相关域之间的相关性知识建立一个映射,例如源域有皇帝、皇后,那么就可以对目标域的男和女之间建立这种关系,一般用在社会网络,社交网络之间的迁移上比较多。
五、迁移学习到底可以解决哪些问题
迁移学习主要可以解决两大类问题:小数据问题和个性化问题。
小数据问题:比方说我们新开一个网店,卖一种新的糕点,我们没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反应到用户可能还会买另外一个东西,所以如果知道用户在另外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买饮料的习惯和买糕点的习惯的关联,我们就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,我们有两个领域,一个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是关联的,就可以把那个模型给迁移过来。
个性化问题:比如我们每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,我们怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。我想这种情况以后会越来越多。
六、迁移学习的应用
1. 我到底是什么颜色?

大家一看这幅图就知道,这里以此前网上流行的一个连衣裙图片为例。如图所示,如果你想通过深度学习判断这条裙子到底是蓝黑条纹还是白金条纹,那就必须收集大量的包含蓝黑条纹或者白金条纹的裙子的图像数据。参考上文提到的问题规模和参数规模之间的对应关系,建立这样一个精准的图像识别模型至少需要 140M 个参数,1.2M 张相关的图像训练数据,这几乎是一个不可能完成的任务。
现在引入迁移学习,用如下公式可以得到在迁移学习中这个模型所需的参数个数:
No. of parameters = Size(inputs) 1 Size(outputs) 1 = 2048 11 1]~ 4098parameters
可以看到,通过迁移学习的引入,针对同一个问题的参数个数从**140M 减少到了 4098**,减少了 10 的 5 次方个数量级!这样的对参数和训练数据的消减程度是惊人的。
这里给大家介绍一个迁移学习的工具 NanoNets,它是一个简单方便的基于云端实现的迁移学习工具,其内部包含了一组已经实现好的预训练模型,每个模型有数百万个训练好的参数。用户可以自己上传或通过网络搜索得到数据,NanoNets 将自动根据待解问题选择最佳的预训练模型,并根据该模型建立一个 NanoNets(纳米网络),并将之适配到用户的数据。以上文提到的蓝黑条纹还是白金条纹的连衣裙为例,用户只需要选择待分类的名称,然后自己上传或者网络搜索训练数据,之后 NanoNets 就会自动适配预训练模型,并生成用于测试的 web 页面和用于进一步开发的 API 接口。如下所示,图中为系统根据一张连衣裙图片给出的分析结果。具体使用方法详见 NanoNets 官网:http://nanonets.ai/ 。

2. Deepmind 的作品 progressive neural network(机器人)
Google 的 Deepmind 向来是大家关注的热点,就在去年,其将三个小游戏 Pong, Labyrinth, Atari 通过将已学其一的游戏的 parameter 通过一个 lateral connection feed 到一个新游戏。外墙的可以看 youtub 的视频:https://www.youtube.com/watch?v=aWAP_CWEtSI,与此同时,DeepMind 最新的成果 Progressive Neural Networks终于伸向真正的机器人了!

它做了什么事情呢?就是在仿真环境中训练一个机械臂移动,然后训练好之后,可以把知识迁移到真实的机械臂上,真实的机械臂稍加训练也可以做到和仿真一样的效果!视频在这:https://www.youtube.com/watch?v=YZz5Io_ipi8
3. 舆情分析

迁移学习也可应用在舆情分析中,如用户评价方面。以电子产品和视频游戏留言为例,上图中绿色为好评标签,而红色为差评标签。我们可以从上图左侧的电子产品评价中找到特征,促使它在这个领域(电子产品评价)建立模型,然后利用模型把其迁移到视频游戏中。这里可以看到,舆情也可以进行大规模的迁移,而且在新的领域不需要标签。
4. 个性化对话

训练一个通用型的对话系统,该系统可能是闲聊型,也可能是一个任务型的。但是,我们可以根据在特定领域的小数据修正它,使得这个对话系统适应不同任务。比如,一个用户想买咖啡,他并不想回答所有繁琐的问题,例如是要大杯小杯,热的冷的?
5. 基于迁移学习的推荐系统
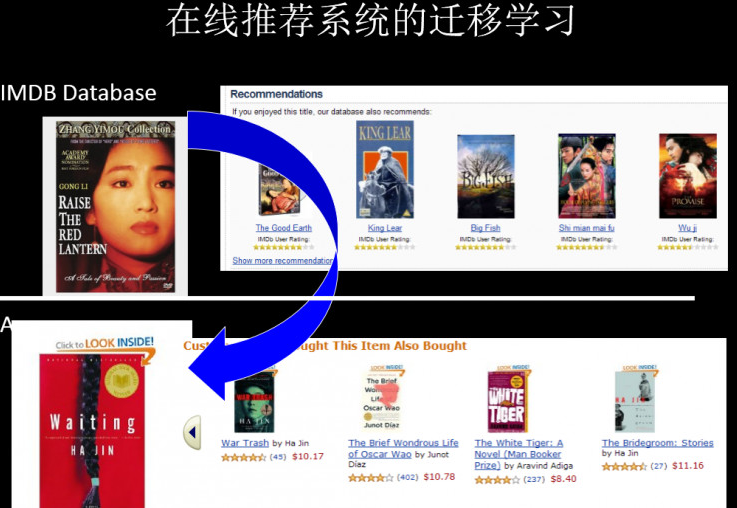
在线推荐系统中利用迁移学习,可以在某个领域做好一个推荐系统,然后应用在稀疏的、新的垂直领域。(影像资料——>书籍资料)
6. 迁移学习在股票中的预测
香港科技大学杨强教授的学生就把迁移学习应用到大家公认的很难的领域中——预测股市走势。下图所示为 A 股里面的某个股票,用过去十年的数据训练该模型。首先,运用数据之间的连接,产生不同的状态,让各个状态之间能够互相迁移。其次,不同状态之间将发生变化,他们用了一个强化学习器模拟这种变化。最后,他们发现深度学习的隐含层里面会自动产生几百个状态,基本就能够对这十年来的经济状况做出一个很完善的总结。
杨强教授也表示,这个例子只是在金融领域的一个小小的试验。不过,一旦我们对一个领域有了透彻的了解,并掌握更多的高质量数据,就可以将人工智能技术迁移到这个领域来,在应用过程中对所遇到的问题作清晰的定义,最终能够实现通用型人工智能的目的。

迁移学习的应用越来越广泛,这里仅仅介绍了冰山一角,例如生物基因检测、异常检测、疾病预测、图像识别等等。
七、风头正劲的迁移学习

当今全世界都在推动迁移学习,当今 AAAI 中大概有 20 多篇迁移学习相关文章,而往年只有五六篇。与此同时,如吴恩达等深度学习代表人物也开始做迁移学习。正如吴恩达在 NIPS 2016 讲座上画了一副草图,大致的意思如下图所示:

有一点是毋庸置疑的:迄今为止,机器学习在业界的应用和成功,主要由监督学习推动。而这又是建立在深度学习的进步、更强大的计算设施、做了标记的大型数据集的基础上。近年来,这一波公众对 人工智能技术的关注、投资收购浪潮、机器学习在日常生活中的商业应用,主要是由监督学习来引领。但是,该图在吴恩达眼中是推动机器学习取得商业化成绩的主要驱动技术,而且从中可以看出,吴恩达认为下一步将是迁移学习的商业应用大爆发。
最后,借鉴香港科技大学计算机与工程系主任,全球第一位华人 AAAI Fellow 杨强教授在 2016 年底腾讯暨 KDD China 大数据峰会上的一页胶片来作为结束。
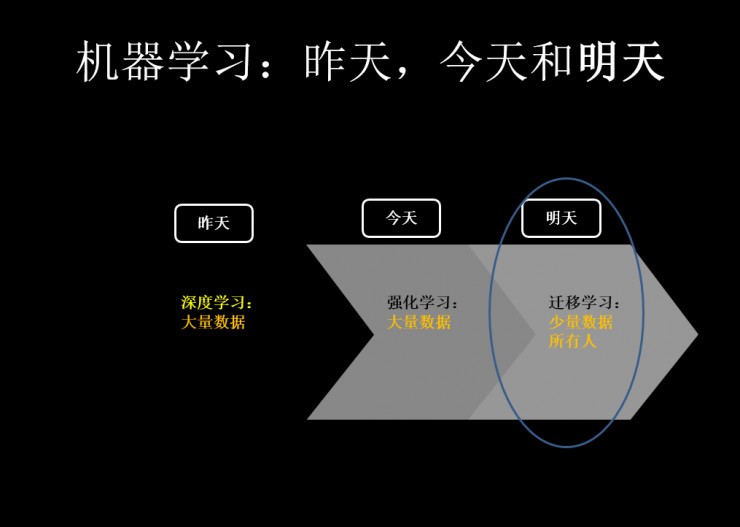
昨天我们在深度学习上有着很高成就。但我们发现深度学习在有即时反馈的领域和应用方向有着一定的优势,但在其他领域则不行。打个比方:就像我在今天讲个笑话,你第二天才能笑得出来,在今天要解决这种反馈的时延问题需要强化学习来做。而在明天,则有更多的地方需要迁移学习:它会让机器学习在这些非常珍贵的大数据和小数据上的能力全部释放出来。做到举一反三,融会贯通。
参考资料:
1. 2016 香港科技大学杨强 KDD China 技术峰会演讲
2. A survey of transfer learning. Karl Weiss 2016
3. A survey of transfer learning. Dai,Yang Q 2009
深度学习|迁移学习|强化学习相关推荐
- 机器学习深度学习加强学习_加强强化学习背后的科学
机器学习深度学习加强学习 机器学习 ,强化学习 (Machine Learning, Reinforcement Learning) You're getting bore stuck in lock ...
- 叶梓老师人工智能培训之强化学习与深度强化学习提纲(强化学习讲师培训)
强化学习与深度强化学习提纲(强化学习讲师培训) 第一天 强化学习 第一课 强化学习综述 1.强化学习要解决的问题 2.强化学习方法的分类 3.强化学习方法的发展趋势 4.环境搭建实验(Gym,Te ...
- AI内训讲师叶梓-强化学习与深度强化学习提纲(强化学习讲师培训)
叶梓老师更多教程资料可点击个人主业查看 第一天 强化学习 第一课 强化学习综述 1.强化学习要解决的问题 2.强化学习方法的分类 3.强化学习方法的发展趋势 4.环境搭建实验(Gym ...
- 强化学习应用简述---强化学习方向优秀科学家李玉喜博士创作
强化学习 (reinforcement learning) 经过了几十年的研发,在一直稳定发展,最近取得了很多傲人的成果,后面会有越来越好的进展.强化学习广泛应用于科学.工程.艺术等领域. 下面简单列 ...
- 强化学习q学习求最值_Q学习简介:强化学习
强化学习q学习求最值 by ADL 通过ADL Q学习简介:强化学习 (An introduction to Q-Learning: reinforcement learning) This arti ...
- 【强化学习知识】强化学习简介
文章目录 前言 1. Q learning 2. Sarsa 3. Deep Q Network(DQN) 4. 总结 前言 强化学习是机器学习中的一大类,它可以让机器学着如何在环境中拿到高分, 表现 ...
- 《强化学习周刊》第44期:RL-CoSeg、图强化学习、安全强化学习
No.44 智源社区 强化学习组 强 化 学 习 研究 观点 资源 活动 周刊订阅 告诉大家一个好消息,<强化学习周刊>已经开启"订阅功能",以后我们会向您自动推送最 ...
- 学习笔记:强化学习与最优控制(Chapter 2)
Approximation in Value Space 学习笔记:强化学习与最优控制(Chapter 2) Approximation in Value Space 1. 综述 2. 基于Value ...
- 强化学习笔记-01强化学习介绍
本文是博主对<Reinforcement Learning- An introduction>的阅读笔记,不涉及内容的翻译,主要为个人的理解和思考. 1. 强化学习是什么?解决什么样的问题 ...
- 强化学习-什么是强化学习?白话文告诉你!
目录 1.强化学习简介 2.强化学习的概念: 3.马尔可夫决策过程 4.Bellman方程 5.Q-Learning基本原理实例讲解 1.强化学习简介 世石与AlphaGo的这场人机世纪巅峰对决,不但 ...
最新文章
- 数据预处理+缺失值处理方案+Missing Value+pandas+缺失值填充方法、方案
- 移动语义(move semantic)和完美转发(perfect forward)
- unused import statement
- win10共享打印机怎么设置_怎么设置打印机共享?
- spring security method security
- user-agent java_user-agent
- AndroidStudio安卓原生开发_Activity的启动模式部分singleTop启动模式和singleTask启动模式---Android原生开发工作笔记87
- php打开文件对话框,JS打开选择本地文件的对话框
- 4K视频在线看,网速跟不上怎么办?
- java捕鱼达人代码java捕鱼游戏代码
- 1H413000工业机电工程安装技术—— 1H413020电气工程安装技术
- NOD32离线升级更新包使用方法
- 海明贴近度matlab,Matlab学习系列23.-模糊聚类分析原理及实现.docx
- 武器瞄准镜 - MOD和相关程序讲解
- (IP)回送地址(Loopback Address)
- Bootstrap 超大屏幕(Jumbotron)
- hexo的安装配置以及主题更换保姆级教程
- 怎么将pdf压缩?pdf文件如何压缩?
- 刺客信条奥德赛缺少dll文件_刺客信条奥德赛打不开怎么办 刺客信条奥德赛无法运行解决办法...
- Python二维码扫描
热门文章
- redux中导入createStore中间有条线,解决方案及redux的使用。(react)
- Electron 自定义托盘实战——桌面计算器
- 【安全知识分享】2021年安全生产月主题宣讲课件(附下载)
- OFFICE、EXCEL、WORD、PPT操作技巧个人笔记本(持续更新)
- 竟有比双十一更令人发指的福利……
- 问题 - GitLab repositories 文件夹权限异常
- Spring学习笔记(二十三)——实现网站微信扫码登录获取微信用户信息Demo
- 【原创】技术员 Ghost Win 10 X64 企业贺岁版2018
- halcon深度图,平面拟合后,高度矫正
- 麦当劳巨无霸汉堡合作超人气动漫《机动战士高达》