有监督学习与无监督学习
机器学习的常用方法,主要分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。简单的归纳就是,是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习;没标签则为无监督学习。
有监督学习
监督学习是指数据集的正确输出已知情况下的一类学习算法。因为输入和输出已知,意味着输入和输出之间有一个关系,监督学习算法就是要发现和总结这种“关系”。
监督算法常见的有:
- 线性回归
- 神经网络
- 决策树
- 支持向量机
- KNN
- 朴素贝叶斯算法
无监督学习
无监督学习是指对无标签数据的一类学习算法。因为没有标签信息,意味着需要从数据集中发现和总结模式或者结构。
我们基于数据中的变量之间关系利用聚类算法发现这种内在模式或者结构。
无监督算法有:
- 主成分分析法(PCA)
- 异常检测法
- 自编码算法
- 深度信念网络
- 赫比学习法
- 生成式对抗网络
- 自组织映射网络
半监督学习
有监督和无监督中间包含的一种学习算法是半监督学习(semi-supervised learning)。对于半监督学习,其训练数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量常常极大于有标签数据数量(这也是符合现实情况的)。隐藏在半监督学习下的基本规律在于:数据的分布必然不是完全随机的,通过一些有标签数据的局部特征,以及更多没标签数据的整体分布,就可以得到可以接受甚至是非常好的分类结果。
关系归纳为:
有监督学习(分类,回归)半监督学习(分类,回归)
半监督聚类(有标签数据的标签不是确定的,类似于:肯定不是xxx,很可能是yyy)
无监督学习(聚类)
有监督和无监督的对比
对比一 : 有标签 vs 无标签
有监督机器学习又被称为“有老师的学习”,所谓的老师就是标签。有监督的过程为先通过已知的训练样本(如已知输入和对应的输出)来训练,从而得到一个最优模型,再将这个模型应用在新的数据上,映射为输出结果。再经过这样的过程后,模型就有了预知能力。
而无监督机器学习被称为“没有老师的学习”,无监督相比于有监督,没有训练的过程,而是直接拿数据进行建模分析,意味着这些都是要通过机器学习自行学习探索。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中也会用到无监督学习。比如我们去参观一个画展,我们对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别。比如哪些更朦胧一点,哪些更写实一些。即使我们不知道什么叫做朦胧派和写实派,但是至少我们能把他们分为两个类。
对比二 : 分类 vs 聚类
有监督机器学习的核心是分类,无监督机器学习的核心是聚类(将数据集合分成由类似的对象组成的多个类)。有监督的工作是选择分类器和确定权值,无监督的工作是密度估计(寻找描述数据统计值),这意味着无监督算法只要知道如何计算相似度就可以开始工作。
对比三 : 同维 vs 降维
有监督的输入如果是n维,特征即被认定为n维,也即y=f(xi)或p(y|xi), i =n,通常不具有降维的能力。而无监督经常要参与深度学习,做特征提取,或者干脆采用层聚类或者项聚类,以减少数据特征的维度,使i<n。事实上,无监督学习常常被用于数据预处理。一般而言,这意味着以某种平均-保留的方式压缩数据,比如主成分分析(PCA)或奇异值分解(SVD),之后,这些数据可被用于深度神经网络或其它监督式学习算法。
对比四 :分类同时定性 vs 先聚类后定性
有监督的输出结果,也就是分好类的结果会被直接贴上标签,是好还是坏。也即分类分好了,标签也同时贴好了。类似于中药铺的药匣,药剂师采购回来一批药材,需要做的只是把对应的每一颗药材放进贴着标签的药匣中。
无监督的结果只是一群一群的聚类,就像被混在一起的多种中药,一个外行要处理这堆药材,能做的只有把看上去一样的药材挑出来聚成很多个小堆。如果要进一步识别这些小堆,就需要一个老中医(类比老师)的指导了。因此,无监督属于先聚类后定性,有点类似于批处理。
对比五 :独立 vs 非独立
李航在其著作《统计学习方法》(清华大学出版社)中阐述了一个观点:对于不同的场景,正负样本的分布可能会存在偏移(可能是大的偏移,也可能偏移比较小)。好比我们手动对数据做标注作为训练样本,并把样本画在特征空间中,发现线性非常好,然而在分类面,总有一些混淆的数据样本。对这种现象的一个解释是,不管训练样本(有监督),还是待分类的数据(无监督),并不是所有数据都是相互独立分布的。或者说,数据和数据的分布之间存在联系。作为训练样本,大的偏移很可能会给分类器带来很大的噪声,而对于无监督,情况就会好很多。可见,独立分布数据更适合有监督,非独立数据更适合无监督。
对比六 : 不透明 vs 可解释性
由于有监督算法最后输出的一个结果,或者说标签。yes or no,一定是会有一个倾向。但是,如果你想探究为什么这样,有监督会告诉你:因为我们给每个字段乘以了一个参数列[w1, w2, w3...wn]。你继续追问:为什么是这个参数列?为什么第一个字段乘以了0.01而不是0.02?有监督会告诉你:这是我自己学习计算的!然后,就拒绝再回答你的任何问题。是的,有监督算法的分类原因是不具有可解释性的,或者说,是不透明的,因为这些规则都是通过人为建模得出,及其并不能自行产生规则。所以,对于像反洗钱这种需要明确规则的场景,就很难应用。而无监督的聚类方式通常是有很好的解释性的,你问无监督,为什么把他们分成一类?无监督会告诉你,他们有多少特征有多少的一致性,所以才被聚成一组。你恍然大悟,原来如此!于是,进一步可以讲这个特征组总结成规则。如此这般分析,聚类原因便昭然若揭了。
对比七 :DataVisor无监督独有的拓展性
试想这样一个n维模型,产出结果已经非常好,这时又增加了一维数据,变成了n+1维。那么,如果这是一个非常强的特征,足以将原来的分类或者聚类打散,一切可能需要从头再来,尤其是有监督,权重值几乎会全部改变。而DataVisor开发的无监督算法,具有极强的扩展性,无论多加的这一维数据的权重有多高,都不影响原来的结果输出,原来的成果仍然可以保留,只需要对多增加的这一维数据做一次处理即可。
如何选择有监督和无监督
了解以上对比后,我们在做数据分析时,就可以高效地做选择了。首先,我们查看现有的数据情况。假如在标签和训练数据都没有的情况下,毫无疑问无监督是最佳选项。但其实对数据了解得越充分,模型的建立就会越准确,学习需要的时间就会越短。我们主要应该了解数据的以下特性: 特征值是离散型变量还是连续型变量;特征值中是否存在缺失的值;何种原因造成缺失值;数据中是否存在异常值;某个特征发生的频率如何。
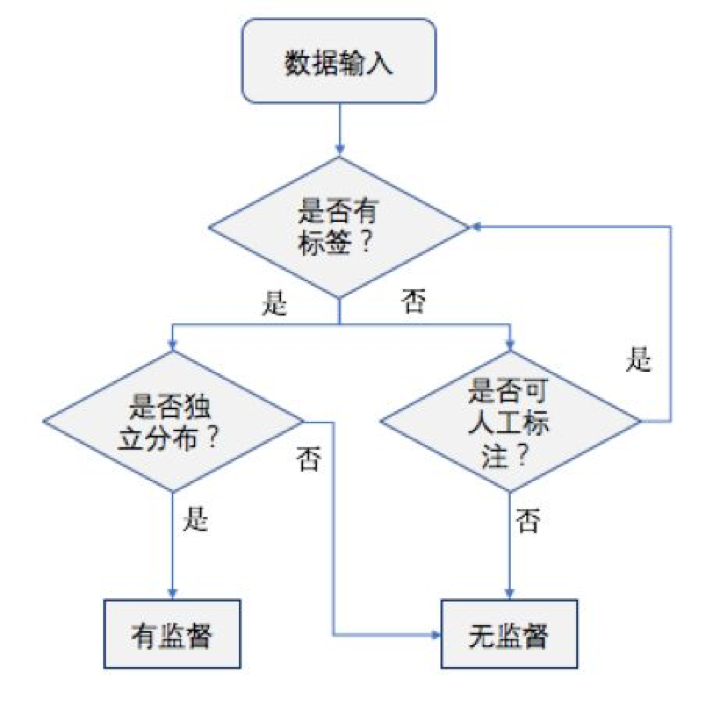
其次,数据条件是否可改善?在实际应用中,有些时候即使我们没有现成的训练样本,我们也能够凭借自己的双眼,从待分类的数据中人工标注一些样本,这样就可以把条件改善,从而用于有监督学习。当然不得不说,有些数据的表达会非常隐蔽,也就是我们手头的信息不是抽象的形式,而是具体的一大堆数字,这样我们很难人工对它们进行分类。举个例子,在bag - of - words 模型中,我们采用k-means算法进行聚类,从而对数据投影。在这种情况下,我们之所以采用k-means,就是因为我们只有一大堆数据,而且是很高维的,若想通过人工把他们分成50类是十分困难的。想象一下,一个熊孩子把50个1000块的拼图混在了一起,你还能够再把这50000个凌乱的小方块区分开吗?所以说遇到这种情况也只能选用无监督学习了。
最后,看样本是否独立分布。对于有训练样本的情况,看起来采用有监督总是比采用无监督好。但有监督学习就像是探索悬崖时的一个安全绳,有着一定的指导作用。就像是即使班级里的第一名,也非常需要标准答案来获得肯定,对吧?做完题对一下答案,总觉得会更安心一点。但对于非独立分布的数据,由于其数据可能存在内在的未知联系,因而存在某些偏移量,这个时候假如追求单一的“标准答案”反而会错失其数据背后隐藏关联。就像是做数学题,往往还有标准答案以外的其他解法。而在反欺诈的场景中,这些隐藏关联往往包含着一个未知地欺诈团伙活动。所以在反欺诈领域中无监督机器学习能实现更准确和广泛的欺诈检测。
参考网址
什么是无监督学习?
有监督学习与无监督学习相关推荐
- 机器学习概念 — 监督学习、无监督学习、半监督学习、强化学习、欠拟合、过拟合、后向传播、损失和优化函数、计算图、正向传播、反向传播
1. 监督学习和无监督学习 监督学习 ( Supervised Learning ) 和无监督学习 ( Unsupervised Learning ) 是在机器学习中经常被提及的两个重要的学习方法. ...
- 强化学习(Reinforcement Learning)是什么?强化学习(Reinforcement Learning)和常规的监督学习以及无监督学习有哪些不同?
强化学习(Reinforcement Learning)是什么?强化学习(Reinforcement Learning)和常规的监督学习以及无监督学习有哪些不同? 目录
- 机器学习系列 1:监督学习和无监督学习
https://www.toutiao.com/a6690813539747103246/ 2019-05-15 09:31:00 机器学习系列 1:监督学习和无监督学习 机器学习就是通过一大堆数据集 ...
- 监督学习和无监督学习
自理解机器学习的概念时,没有深刻理解监督学习和无监督学习的区别,在网上查找了部分资料,现在总结如下: 总的来说,机器学习任务将根据训练样本是否有label,可以分为监督学习和无监督学习,这是最简单直接 ...
- 机器学习一 -- 什么是监督学习和无监督学习?
机器学习中的监督学习和无监督学习 说在前面 最近的我一直在寻找实习机会,很多公司给了我第一次电话面试的机会,就没有下文了.不管是HR姐姐还是第一轮的电话面试,公司员工的态度和耐心都很值得点赞,我也非常 ...
- 聚类(序)——监督学习与无监督学习
聚类系列: 聚类(序)----监督学习与无监督学习 聚类(1)----混合高斯模型 Gaussian Mixture Model 聚类(2)----层次聚类 Hierarchical Clusteri ...
- 小白都看得懂的监督学习与无监督学习
hello~一晃就十一月啦!开始写简书也半个月啦!之前对机器学习中的监督学习与无监督学习,只是有个概念,前几天学习知识的时候,又遇到了,所以打算好好记录下来. 在理解监督学习和无监督学习之前,我们先来 ...
- 监督学习与无监督学习的区别_机器学习
最近发现很多人还是不能真正分清机器学习的学习方法,我以个人的愚见结合书本简单说一下这个 机器学习中,可以根据学习任务的不同,分为监督学习(Supervised Learning),无监督学习(Unsu ...
- 监督学习无监督学习_无监督学习简介
监督学习无监督学习 To begin with, we should know that machine primarily consists of four major domain. 首先,我们应 ...
- 无监督学习 k-means_无监督学习-第1部分
无监督学习 k-means 有关深层学习的FAU讲义 (FAU LECTURE NOTES ON DEEP LEARNING) These are the lecture notes for FAU' ...
最新文章
- Android Custom View系列《圆形菜单一》
- 利用STM32 的串口来发送和接收数据实验
- MATLAB 求图像的极大值极小值,平均值
- 争对让望对思野葛对山栀注解_笠翁对韵.支_李召洋、于婷、杨盼兮、于婷_高音质在线试听_笠翁对韵.支歌词|歌曲下载_酷狗音乐...
- SAP ERP项目业务流程方案设计重点内容
- Pandas基本操作指南-2天学会pandas
- QGraphicsItem获取不到鼠标事件
- VMware+Win7+windbg 双机调试
- vue-cli 3.0
- 将本地已经存在的代码跟github上新建的仓库建立关联,解决“fatal: 'origin' does not appear to be a git repository...”
- python试卷生成_Python学习笔记文件读写之生成随机的测试试卷文件
- Xcode 真机 iPhone is not available 及 is busy 解决
- Android拍照与相册选取图片
- 孪生网络 Siamese Network
- css手指代码,CSS3动画:通过Animation实现简单的手指点击动画
- 一键抓取网页的所有图片
- 《壁纸 : 手机高清壁纸大全》EULA条款协议
- 我的C站万粉成长之路、2021 笔耕不辍
- React 18 的七大更新点你知道几个?
- 用数据分析验证,王者荣耀完胜阴阳师,小学生才是最终的赢家
热门文章
- php 监听 扫描枪,Android监听扫描枪内容(一)
- 电子电路学习笔记(16)——晶振电路的电容
- [渝粤教育] 九江学院 看影视学社交礼仪 参考 资料
- 四大行、三大运营商在列,或有15家公司参与央行数字货币
- 次世代角色建模入门教学-人体比例和肌肉骨骼
- 修改mysql的authen_关于MySQL连接抛出Authentication Failed错误分析
- 在使用Assimp库时编译器报错:C2589 “(”:“::”右边的非法标记 AssimpLoadStl
- 前端三大主流框架到底学哪个好呢?
- 采用python语言对csv文件写入、最可能采用的字符串方法_2020尔雅无人机原理与构造答案章节答案...
- C# Spire操作Word文档生成PDF或JPG格式