python数据分析第三方库是_python数据分析复盘——数据分析相关库之Pandas
编辑推荐:
本文来源csdn,本文主要对Python的第三方库Pandas,进行高性能易用数据类型和分析。
1.Pandas 简介
1.1 pandas是什么
Pandas是Python第三方库,提供高性能易用数据类型和分析工具
Pandas基于NumPy实现 ,常与NumPy和Matplotlib一同使用
1.2 pandas vs numpy

2.Pandas库的Series类型
2.1 Series的结构
#多维一列,形式是:索引+值。(省略index会自动生成,从0开始)
>>> pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
a 1
b 2
c 3
d 4
e 5
dtype: int64
2.2 Series的创建
Series类型可以由如下类型创建:
1.Python列表
2.标量值
3.Python字典
4.ndarray
5.其他函数,range()等
#标量值
>>> pd.Series(5)
0 5
dtype: int64
#标量值+index 结果会根据索引重新排序
pd.Series(5,index=['a','v','c','d','e'])
a 5
v 5
c 5
d 5
e 5
dtype: int64
#字典
>>> pd.Series({'a':999,'v':888,'c':756,
'd':7,'e':437})
a 999
c 756
d 7
e 437
v 888
dtype: int64
#字典+index
>>>pd.Series({'a':999,'v':888,'c':756,
'd':7,'e':437},index=['a','v'])
a 999
v 888
dtype: int64
#用ndarray创建
>>> pd.Series(np.arange(5),index=np.
arange(14,9,-1))
14 0
13 1
12 2
11 3
10 4
dtype: int32
Seriesd的创建总结:
1.Series类型可以由如下类型创建:
2.Python列表,index与列表元素个数一致
3.标量值,index表达Series类型的尺寸
4.Python字典,键值对中的“键”是索引,index从字典中进行选择操作
5.ndarray,索引和数据都可以通过ndarray类型创建
6.其他函数,range()函数等
2.3 Series基本操作
1.Series类型包括index和values两部分
2.Series类型的操作类似ndarray类型
3.Series类型的操作类似Python字典类型
(1)Series基本操作
#Series基本操作
>>>a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> a.index
Index(['a', 'c', 'd', 'e', 'v'], dtype='object')
>>> a.values
array([1, 3, 4, 5, 2], dtype=int64)
#两套索引并存,但不能混用
>>> a[['a','v']]
a 1
v 2
dtype: int64
>>> a[[0,4]]
a 1
v 2
dtype: int64
#混用,以靠前的为准
>>> a[['a',4]]
a 1.0
4 NaN
dtype: float64
(2)Series类型的操作类似ndarray类型:
索引方法相同,采用 [ ]
可以通过自定义索引的列表进行切片
可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
#采用
[]切片
>>> a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> a[:3]
a 1
c 3
d 4
dtype: int64
#在索引前进行运算
>>> a[a>a.median()]
d 4
e 5
dtype: int64
#以自然常数e为底的指数函数
>>> np.exp(a)
a 2.718282
c 20.085537
d 54.598150
e 148.413159
v 7.389056
dtype: float64
(3)Series类型的操作(类似Python):
通过自定义索引访问
保留字in操作
使用.get()方法
#保留字in
>>> a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> 'a' in a
True
>>> 'v' in a
True
#只匹配索引
>>> 1 in a
False
2.4 Series对齐操作
#Series类型在运算中会自动对齐不同索引的数据.(即对不齐,就当缺失项处理)
>>> a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> b=pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5})
>>> a+b
a 2.0
b NaN
c 6.0
d 8.0
e 10.0
v NaN
dtype: float64
2.5 Series的name属性
#Series对象和索引都可以有一个名字,存储在属性.name中
a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> a.name
>>> a.name="精忠跳水队"
>>> a.name
'精忠跳水队'
>>> a
a 1
c 3
d 4
e 5
v 2
Name: 精忠跳水队, dtype: int64
2.6 Series小结
Series是一维带“标签”数组
index_0 → data_a
Series基本操作类似ndarray和字典,根据索引对齐
3.Pandas库的DataFrame类型
3.1 DataFrame结构
#DataFrame是一个表格型的数据类型,每列值类型可以不同
#DataFrame既有行索引、也有列索引
>>> df = pd.DataFrame(np.random.randint(1,10,(4,5)))
>>> df
0 1 2 3 4
0 8 5 4 1 1
1 3 4 2 7 3
2 4 3 8 9 9
3 7 8 9 1 7
3.2 DataFrame的创建
DataFrame类型可以由如下类型创建:
ndarray对象
由一维ndarray、列表、字典、元组或Series构成的字典
Series类型
其他的DataFrame类型
#由字典创建
(自定义行列索引,会自动补齐缺失的值为NAN)
>>> df=pd.DataFrame({'one':pd.Series([1,2,3],index=
['a','v','c']),'two':pd.Series([1,2,3,4,5],index=
['a','b','c','d','e'])})
>>> df
one two
a 1.0 1.0
b NaN 2.0
c 3.0 3.0
d NaN 4.0
e NaN 5.0
v 2.0 NaN
#由字典+列表创建。统一index,尺寸必须相同
>>> df=pd.DataFrame({'one':[1,2,3],'two':[2,2,3],'three'
:[3,2,3]},index=['a','b','c'])
>>> df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
#索引(类似Series,依据行列索引)
>>> df['one']['a']
1
>>> df['three']['c']
3
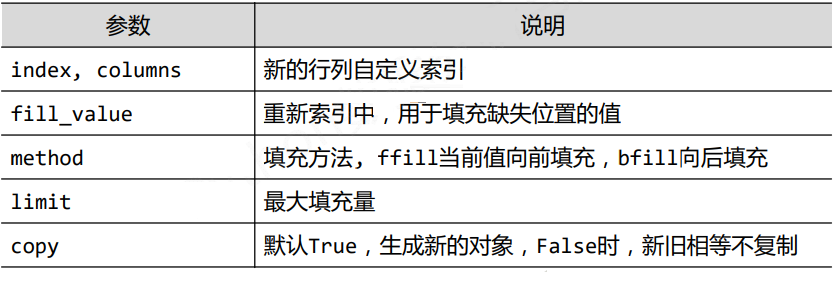
3.3 pandas数据类型操作——重新索引
#由a
b c改为c a b
>>> df.reindex(['c','a','b'])
one three two
c 3 3 3
a 1 3 2
b 2 2 2
#重排并增加列
>>> df.reindex(columns=['three','two','one','two'])
three two one two
a 3 2 1 2
b 2 2 2 2
c 3 3 3 3
#原始的数据
>>> df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
#插入列
>>> newc=df.columns.insert(3,'新增')
>>> newc
Index(['one', 'three', 'two', '新增'], dtype='object')
#插入新数据
>>> newd=df.reindex(columns=newc,fill_value=99)
>>> newd
one three two 新增
a 1 3 2 99
b 2 2 2 99
c 3 3 3 99
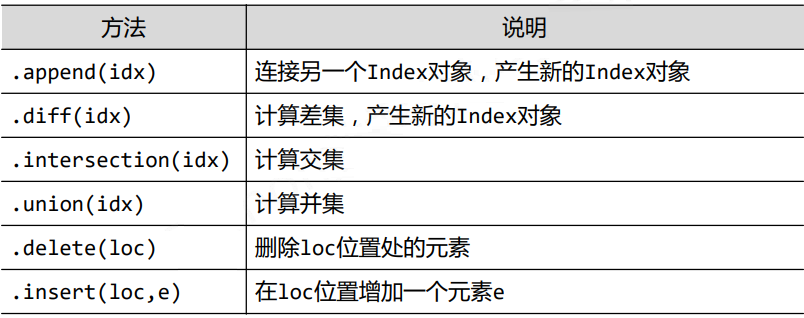
3.4pandas数据类型操作——索引类型
>>>
df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
>>> nc=df.columns.delete(1)
>>> ni=df.index.insert(3,'new_index')
#无填充
>>> df.reindex(columns=nc,index=ni)
one two
a 1.0 2.0
b 2.0 2.0
c 3.0 3.0
new_index NaN NaN
#有填充
>>> df.reindex(columns=nc,index=ni,method='ffill')
one two
a 1 2
b 2 2
c 3 3
new_index 3 3
#删除行列
#默认删 除行
>>> df.drop('b')
one three two
a 1 3 2
c 3 3 3
#轴1为列
>>> df.drop('three',axis=1)
one two
a 1 2
b 2 2
c 3 3
3.5pandas数据类型运算——算数运算
算数运算法则:
算术运算根据行列索引,补齐后运算,运算默认产生浮点数
补齐时缺项填充NaN (空值)
二维和一维、一维和零维间为广播运算
采用+ ‐ * /符号进行的二元运算产生新的对象
(1)采用+ ‐ * /符号进行的二元运算:
#用符号运算,无法处理缺失值
>>> df1 =pd.DataFrame({'one':[1,2,3],'two':
[4,5,6]},index=['a','b','c'])
>>> df2 =pd.DataFrame({'one':[1,2,3]},
index=['a','b','c'])
>>> df1+df2
one two
a 2 NaN
b 4 NaN
c 6 NaN
(2)采用方法形式进行二元运算:

>>>
df1 =pd.DataFrame({'one':[1,2,3],'two':[4,5,6]},
index=['a','b','c'])
>>> df2 =pd.DataFrame({'one':[1,2,3]},index=['a','b','c'])
#用方法进行运算,可选参数处理缺失值
>>> df1.add(df2,fill_value=0)
one two
a 2 4.0
b 4 5.0
c 6 6.0
#运算方式
#只对对应维度及对应位置进行运算,常数则进行广播运算。
无匹配位置,则置为NAN
df =pd.DataFrame({'one':[1,2,3],'two':[2,2,3],'three'
:[3,2,3]},index=['a','b','c'])
df3=df=pd.DataFrame({'one':[1,2,3]},index=['a','b','c'])
df4=pd.DataFrame({'two':[2,2,3]},index=['a','b','c'])
#常数
>>> df3-1
one
a 0
b 1
c 2
>>> df -1
one three two
a 0 2 1
b 1 1 1
c 2 2 2
#对应维度
>>> df3 -df
one three two
a 0 NaN NaN
b 0 NaN NaN
c 0 NaN NaN
>>> df-df4
one three two
a NaN NaN 0
b NaN NaN 0
c NaN NaN 0
3.6pandas数据类型运算——比较运算
(1)法则
比较运算只能比较相同索引的元素,不进行补齐
二维和一维、一维和零维间为广播运算
采用>、<、 >=、 <= 、==、 !=等符号进行的二元运算产生布尔对象
>>>
dfx
one three two
a 1 3 2
b 1 3 2
c 1 3 2
>>> df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
>>> df>dfx
one three two
a False False False
b True False False
c True False True
4.Pandas数据类型小结
1.据类型与索引的关系,操作索引即操作数据
2.Series = 索引+ 一维数据
3.DataFrame = 行列索引+ 多维数据
4.重新索引、数据删除、算术运算、比较运算
5.像对待单一数据一样对待Series和DataFrame对象
python数据分析第三方库是_python数据分析复盘——数据分析相关库之Pandas相关推荐
- python实现第三方验证码获取_python利用第三方模块,发送短信验证码(测试案例)...
今天学到个利用python第三方,发送短信验证码的代码,速实现一遍,短信立即收到,果断记录在案! 环境:虚拟机上centos7平台,python2.7版本: 第三方服务提供商是:云通讯官网:www.y ...
- python绘制简单图形可以引入的库是_Python基本图形绘制及库引用
turtle库的使用 概述:turtle(海龟)库是turtle绘图体系的python实现 turtle库的理解: -有一只海龟,其实在窗体正中心,在画布上游走 -走过的轨迹形成了绘制的图形 -海龟由 ...
- python数据分析复盘——爬虫相关库
Requests.BeautifulSoup.re.lxml.css selector .scrapy 1.Requests 1.1 Requests的7个主要方法 其中,request()方法是其它 ...
- python安装第三方扩展包_Python之安装第三方扩展库
PyPI 地址:https://pypi.python.org/pypi 如果你知道你要找的库的名字,那么只需要在右上角搜索栏查找即可. 1.pip安装扩展库 (1)安装最新版本的扩展库: cmd&g ...
- python爬取凤凰新闻网_python凤凰新闻数据分析(一)python爬虫数据爬取
标签的内容 first_new_td = BeautifulSoup(str(first_new[0]),'html.parser') first_new_item = first_new_td.fi ...
- opencv在python环境下的安装_python环境下安装opencv库的方法
注意:安装opencv以前须要先安装numpy,matplotlib等python 1.安装方法windows 方法1.在线安装函数 1.先安装opencv-python测试 pip install ...
- python词云下载什么_python词云安装什么库
python词云需要安装wordcloud库. 安装方法: 在cmd使用pip install wordcloud命令即可安装. wordcloud库把词云当作一个WordCloud对象:wordcl ...
- python设计选择题代码源_Python程序的设计试题库完整
. . . < Python 程序设计>题库 一. 填空题 第一章 基础知识 1 . Python 安装扩展库常用的是 _______ 工具.( pip ) 2 . Python 标准库 ...
- python中调用π的值_python如何调用math函数库求π值
python如何调用math函数库求π值 发布时间:2020-11-25 09:41:21 来源:亿速云 阅读:103 作者:小新 小编给大家分享一下python如何调用math函数库求π值,相信大部 ...
- python录屏工具下载_Python移动端录屏库
Python移动端录屏库 背景 日常移动端专项测试和自动化测试通常有一些场景如:Ui自动化的操作捕获.App启动耗时.视频启播耗时等,通常都有需要边操作边录屏,而对于启动耗时测试通常还需要质量较高且帧 ...
最新文章
- 分享下自己写的一个微信小程序请求远程数据加载到页面的代码
- java 计算移动平均线_基于Java语言开发的个性化股票分析技术:移动平均线(MA)...
- 谷歌浏览器chrome的vuejs devtools 插件的安装
- 云厂商靠不靠谱?“国家级标准”鉴定结果来啦
- 如何快速学好python语言_如何快速的学习Python语言
- xpe低配置系统解决“写缓存失败”问题
- neo4j unwind
- ASP.NET数据绑定控件数据项中的服务器控件注册JS方法
- 当vue遇到pwa--vue+pwa移动端适配解决方案模板案例
- 鲁大师2022半年报电脑排行:RTX 3090 Ti继任“卡皇”,顶级笔记本开始拼颜值!
- 14.嵌入式控制器EC实战 SMBus读取电池信息并控制充放电
- 阿里数据仓库-数据模型建设方法总结(全)
- 阿里工程师修养之:技术三板斧:关于技术规划、管理、架构的思考的概述
- 无状态,无连接的理解
- 从源数据库抽取数据到中间库
- MATLAB 全景图切割及盒图显示
- SQL 取数值小数后两位,但不四舍五入。
- HBuildX的下载安装教程
- 车牌输入法 车牌号快捷输入法 支持普通车牌新能源车牌
- LOCATE函数的用法