《飞桨PaddleSpeech语音技术课程》一句话语音合成全流程实践

一句话语音合成全流程实践
1 声音克隆介绍 & 语音合成基本概念回顾
语音合成(Speech Sysnthesis),又称文本转语音(Text-to-Speech, TTS),指的是将一段文本按照一定需求转化成对应的音频的技术。
1.1 声音克隆的应用场景
随着以语音为交互渠道的产业不断升级,企业对语音合成有着越来越多的需求,比如智能语音助手、手机地图导航、有声书播报等场景都需要用到语音合成技术。通过语音合成技术想要得到一个新的音色,需要定制音库,但是定制音库所耗费的人力成本和时间成本巨大,成为产业升级的屏障。
声音克隆一般是指 one-shot TTS ,即只需要一条参考音频就可以合成该音色的语音,而无需收集大量该音色的音频数据进行训练。
1.2 声音克隆和语音合成的关系
声音克隆属于语音合成的一个小分类,想要合成一个人的声音,可以收集大量该说话人的声音数据进行标注(一般至少一小时,1400+ 条数据),训练一个语音合成模型,也可以用一句话声音克隆方案来实现。
声音克隆模型本质是语音合成的声学模型。
一句话声音克隆的效果没有收集大量数据集训练或收集少量数据集 fintune 一个语音合成模型的效果好,其效果是否可以在商业中落地还有待商榷。
一般商业应用中想要合成某个特定的音色,需要收集大量数据进行训练,即使类似于百度地图的定制化音色播报,也是采用某种小样本 finetune的方案,至少需要用户录制 9 ~ 20 句指定文本内容的音频。
1.3 语音合成的基本流程回顾
本教程主要讲解基于深度学习的语音合成技术,流水线包含 文本前端(Text Frontend)、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块:
- 文本前端模块将原始文本转换为字符/音素
- 声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等
- 声码器将声学特征转换为波形
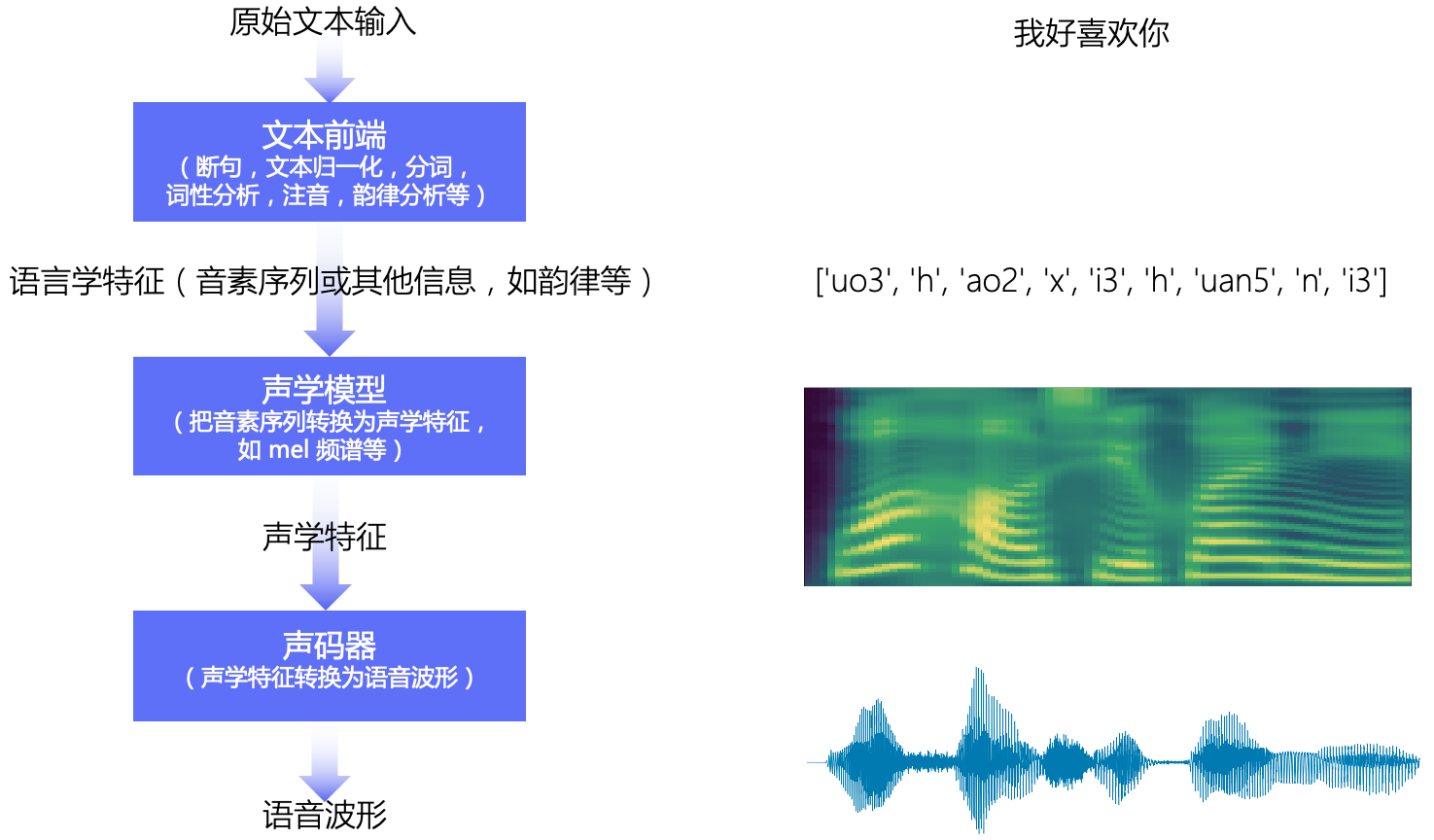
1.3.1 文本前端
文本前端模块主要包含: 分段(Text Segmentation)、文本正则化(Text Normalization, TN)、分词(Word Segmentation, 主要是在中文中)、词性标注(Part-of-Speech, PoS)、韵律预测(Prosody)和字音转换(Grapheme-to-Phoneme,G2P)等。
其中最重要的模块是 文本正则化 模块和 字音转换(TTS 中更常用 G2P 代指) 模块。
各模块输出示例:
• Text: 全国一共有112所211高校
• Text Normalization: 全国一共有一百一十二所二一一高校
• Word Segmentation: 全国/一共/有/一百一十二/所/二一一/高校/
• G2P(注意此句中“一”的读音):quan2 guo2 yi2 gong4 you3 yi4 bai3 yi1 shi2 er4 suo3 er4 yao1 yao1 gao1 xiao4(可以进一步把声母和韵母分开)q uan2 g uo2 y i2 g ong4 y ou3 y i4 b ai3 y i1 sh i2 er4 s uo3 er4 y ao1 y ao1 g ao1 x iao4(把音调和声韵母分开)q uan g uo y i g ong y ou y i b ai y i sh i er s uo er y ao y ao g ao x iao0 2 0 2 0 2 0 4 0 3 ...
• Prosody (prosodic words #1, prosodic phrases #2, intonation phrases #3, sentence #4):全国#2一共有#2一百#1一十二所#2二一一#1高校#4(分词的结果一般是固定的,但是不同人习惯不同,可能有不同的韵律)
1.3.2 声学模型
声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等。声学特征以 “帧” 为单位,一般一帧是 10ms 左右,一个音素一般对应 5~20 帧左右。声学模型需要解决的是 “不等长序列间的映射问题”,“不等长”是指,同一个人发不同音素的持续时间不同,同一个人在不同时刻说同一句话的语速可能不同,对应各个音素的持续时间不同,不同人说话的特色不同,对应各个音素的持续时间不同。这是一个困难的 “一对多” 问题。
# 卡尔普陪外孙玩滑梯
000001|baker_corpus|sil 20 k 12 a2 4 er2 10 p 12 u3 12 p 9 ei2 9 uai4 15 s 11 uen1 12 uan2 14 h 10 ua2 11 t 15 i1 16 sil 20
声学模型主要分为自回归模型和非自回归模型。自回归模型在 t 时刻的预测需要依赖 t-1 时刻的输出作为输入,预测时间长,但是音质相对较好;非自回归模型不存在预测上的依赖关系,预测时间快,音质相对较差。
主流声学模型:
- 自回归模型: Tacotron、Tacotron2 和 Transformer TTS 等
- 非自回归模型: FastSpeech、SpeedySpeech、FastPitch 和 FastSpeech2 等
1.3.3 声码器
声码器将声学特征转换为波形,它需要解决的是 “信息缺失的补全问题”。信息缺失是指,在音频波形转换为频谱图时,存在相位信息的缺失;在频谱图转换为 mel 频谱图时,存在频域压缩导致的信息缺失。假设音频的采样率是 16kHz, 即 1s 的音频有 16000 个采样点,一帧的音频有 10ms,则 1s 中包含 100 帧,每一帧有 160 个采样点。声码器的作用就是将一个频谱帧变成音频波形的 160 个采样点,所以声码器中一般会包含上采样模块。
与声学模型类似,声码器也分为自回归模型和非自回归模型:
- 自回归模型:WaveNet、WaveRNN 和 LPCNet 等
- 非自回归模型:Parallel WaveGAN、Multi Band MelGAN、Style MelGAN 和 HiFiGAN 等
更多关于语音合成基础的精彩细节,请参考之前的课程。
2 基于说话人嵌入的声音克隆:SV2TTS
2.1 基本原理
SV2TTS 论文全称是 Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis, 是 Google 发表在 NeurIPS 2018 上的文章。
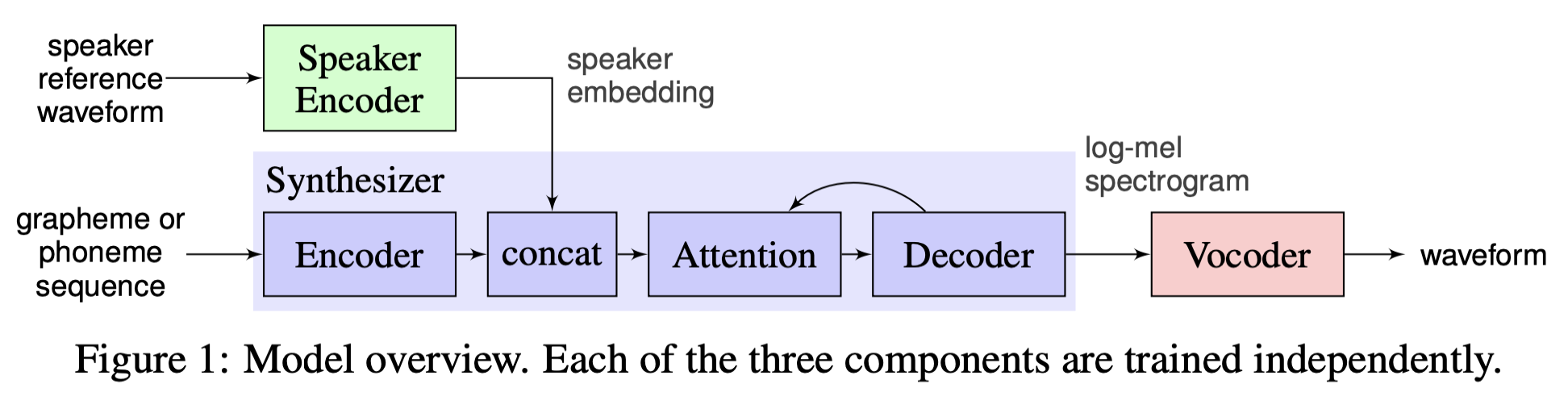
SV2TTS 的声学模型使用了 Tacotron2,声码器使用了 WaveNet, 用于提取 speaker embedding 的声纹模型选择了 GE2E。
SV2TTS 原作的开源代码是 Real-Time-Voice-Cloning, 仅支持英文合成,代码实现中使用的声码器是 WaveRNN,MockingBird fork 自原作仓库并支持了中文合成。
在 Speaker Encoder、Synthesizer 和 Vocoder 阶段,PaddleSpeech 提供了不同的说话人编码器、合成器以及声码器组合。
| Speaker Encoder | Synthesizer | Vocoder |
|---|---|---|
| GE2E / ECAPA-TDNN | Tacotron2 / FastSpeech2 |
GAN Vocoder (Parallel WaveGAN / HiFiGAN / …) |
2.2 模型训练
2.2.1 声纹模型
PaddleSpeech 已提供了预训练好的声纹模型,相关训练代码请参考 GE2E 和 ECAPA-TDNN。
PaddleSpeech 声纹相关课程请参考声纹检索系统与实践。
2.2.2 声学模型
SV2TTS 与多说话人声学模型的区别是:多说话人声学模型在训练模型的时候,输入 spk_id 标识不同的说话人,模型内通过 Speaker Embedding Table (nn.Embedding 类)获取 speaker embeding,预测时只能选择在训练时包含的 spk_id,只能合成训练集内的音色;而 SV2TTS 通过预训练好的声纹模型提取 speaker embeding,预测时可以输入任意说话人的音频作为参考音频,即使该说话人不在训练集中,也可以合成具有其音色的音频。
以 FastSpeech2 为例,两者的区别仅仅是红框所标部分。
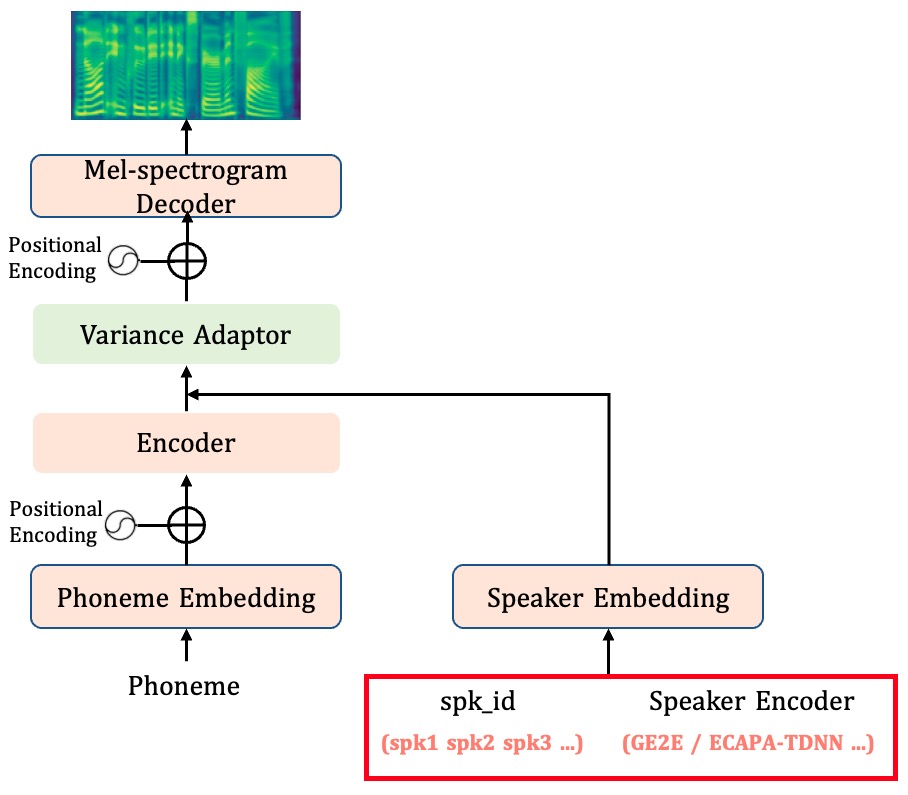
2.2.3 声码器
声音克隆模型本质是语音合成声学模型,声码器可以直接使用 PaddleSpeech 提供的各种声码器:Parallel WaveGAN、Multi Band MelGAN、Style MelGAN 和 HiFiGAN 等, 由于声音克隆会见到各种不同的音色,建议使用 PaddleSpeech 提供的在多说话人数据集 AISHELL-3 和 VCTK 上训练的声码器。
声码器和数据集相关,如果待合成音色是成年女性音色,用 CSMSC(成年女性单说话人数据集)的声码器效果可能会更好,若待合成音色是男性音色,由于和女性声音特征相差较大,用 CSMSC 数据集训练的声码器的表现就不会很好,AISHELL-3、VCTK、CSMSC 都是 24k 的,声码器可以任意换,只是效果好不好的问题。
使用自己的数据重新训练或者 finetune 这些声码器,合成的音频会有更好的音质。
2.3 实践
以 ECAPA-TDNN 声纹模型 + FastSpeech2 声学模型为例,下列代码修改自 voice_cloning.py。
安装 paddlespeech
# pip install paddlespeech or
!git clone https://github.com/PaddlePaddle/PaddleSpeech.git
from IPython.display import clear_output
%cd PaddleSpeech
!pip install .
%cd -
# 清理很长的内容
clear_output()
# 本项目的依赖需要用到 nltk 包,但是有时会因为网络原因导致不好下载,此处手动下载一下放到百度服务器的包
!wget https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf nltk_data.tar.gz
clear_output()
获取预训练模型和数据
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_aishell3_ckpt_vc2_1.2.0.zip
!unzip -o -d download download/fastspeech2_aishell3_ckpt_vc2_1.2.0.zip
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_aishell3_ckpt_0.5.zip
!unzip -o -d download download/pwg_aishell3_ckpt_0.5.zip
clear_output()
获取 ref_audio
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/docs/demos/ref_audio.zip
!unzip -o -d download download/ref_audio.zip
clear_output()
导入 Python 包
# 设置 gpu 环境
%env CUDA_VISIBLE_DEVICES=0import logging
import sys
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)import os
from pathlib import Pathimport numpy as np
import paddle
import soundfile as sf
import yaml
from yacs.config import CfgNodefrom paddlespeech.cli.vector import VectorExecutor
from paddlespeech.t2s.exps.syn_utils import get_am_inference
from paddlespeech.t2s.exps.syn_utils import get_voc_inference
from paddlespeech.t2s.frontend.zh_frontend import Frontend
clear_output()
主程序
am ='fastspeech2_aishell3'
am_config = 'download/fastspeech2_aishell3_ckpt_vc2_1.2.0/default.yaml'
am_ckpt = 'download/fastspeech2_aishell3_ckpt_vc2_1.2.0/snapshot_iter_96400.pdz'
am_stat = 'download/fastspeech2_aishell3_ckpt_vc2_1.2.0/speech_stats.npy'
phones_dict = "download/fastspeech2_aishell3_ckpt_vc2_1.2.0/phone_id_map.txt"voc = 'pwgan_aishell3'
voc_config = 'download/pwg_aishell3_ckpt_0.5/default.yaml'
voc_ckpt = 'download/pwg_aishell3_ckpt_0.5/snapshot_iter_1000000.pdz'
voc_stat = 'download/pwg_aishell3_ckpt_0.5/feats_stats.npy'# 读取 conf 配置文件并结构化
with open(am_config) as f:am_config = CfgNode(yaml.safe_load(f))
with open(voc_config) as f:voc_config = CfgNode(yaml.safe_load(f))
# 加载模型,第一次使用 vec_executor 时候会下载模型
# speaker encoder
vec_executor = VectorExecutor()frontend = Frontend(phone_vocab_path=phones_dict)
print("frontend done!")# acoustic model
am_inference = get_am_inference(am=am,am_config=am_config,am_ckpt=am_ckpt,am_stat=am_stat,phones_dict=phones_dict)# vocoder
voc_inference = get_voc_inference(voc=voc,voc_config=voc_config,voc_ckpt=voc_ckpt,voc_stat=voc_stat)
ref_audio_path = 'download/ref_audio/yuantian01_02.wav'
sentence = '每当你觉得,想要批评什么人的时候,你切要记着,这个世界上的人,并非都具备你禀有的条件。'input_ids = frontend.get_input_ids(sentence, merge_sentences=True)
phone_ids = input_ids["phone_ids"][0]spk_emb = vec_executor(audio_file=ref_audio_path, force_yes=True)
spk_emb = paddle.to_tensor(spk_emb)with paddle.no_grad():wav = voc_inference(am_inference(phone_ids, spk_emb=spk_emb))sf.write("output.wav",wav.numpy(),samplerate=am_config.fs)
print("Voice Cloning done!")
# 播放参考音频
import IPython.display as dp
dp.Audio("download/ref_audio/yuantian01_02.wav")
# 播放生成的音频
dp.Audio('output.wav', rate=am_config.fs)
SV2TTS 的效果受多说话人数据集和 Speaker Encoder 模型的影响较大,新发音人的声音会跟提取的 speaker embedding 在整个发音人向量空间中的最接近的那几个人的音色会比较像,因此一句话合成整体音色的效果因人而异,音色学习效果并不稳定。
具体实现代码请参考:
- SV2TTS (GE2E + Tacotron2)
- SV2TTS (GE2E + FastSpeech2)
- SV2TTS (ECAPA-TDNN + FastSpeech2)
3 端到端声音克隆:ERNIE-SAT
ERNIE-SAT 是百度自研的文心大模型,是可以同时处理中英文的跨语言的语音-语言跨模态大模型,其在语音编辑、个性化语音合成以及跨语言的语音合成等多个任务取得了领先效果。可以应用于语音编辑、个性化合成、语音克隆、同传翻译等一系列场景。
3.1 基本原理
3.1.1 A3T 简介
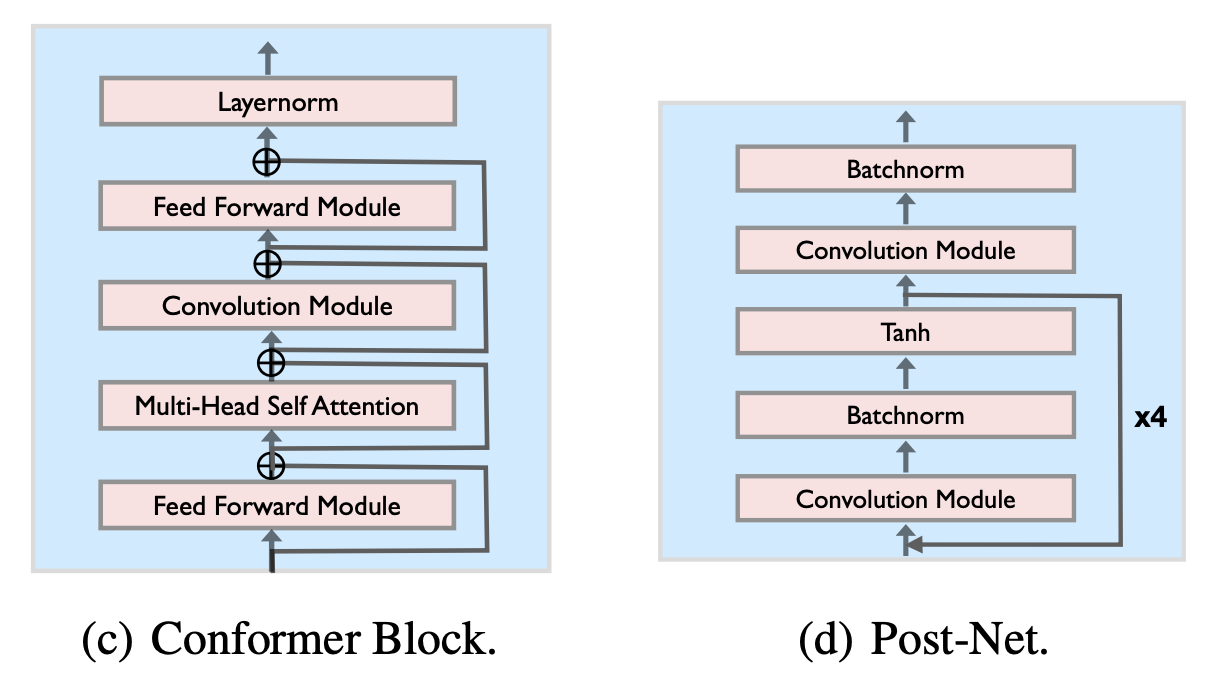
ERNIE-SAT 是基于百度自研模型 A3T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing 的改进,A3T 提出了一种对齐感知的声学、文本预训练模型,可以重建高质量的语音信号,多用于语音编辑任务。
训练时,根据 MFA 获取 mel 频谱和音素的对齐信息,mask 住单词文本对应的 mel 频谱,并对其进行重建。
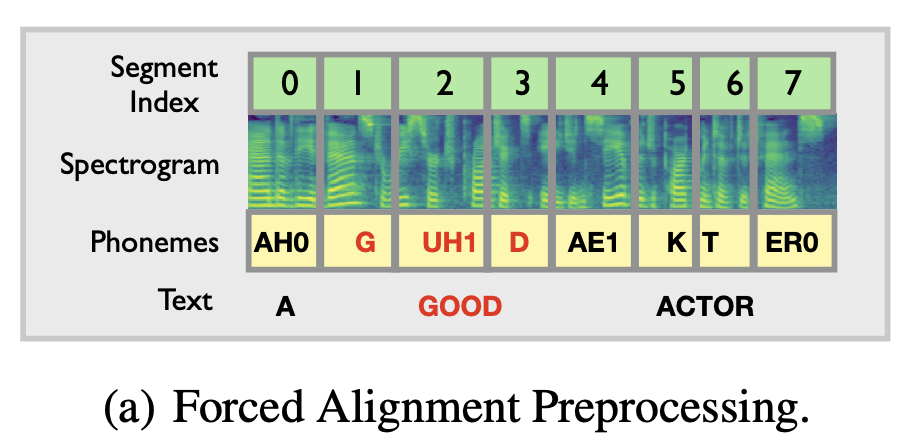
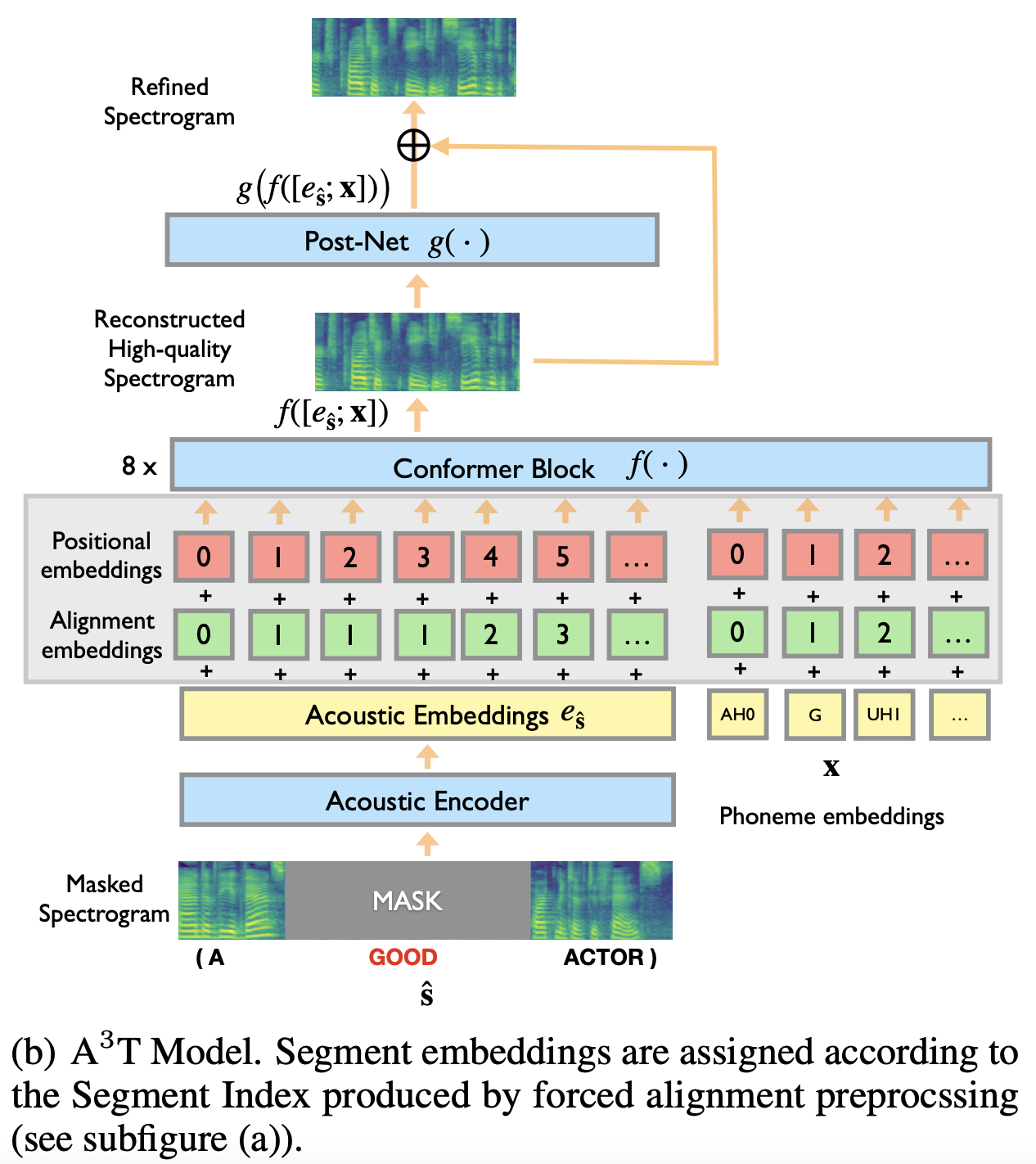
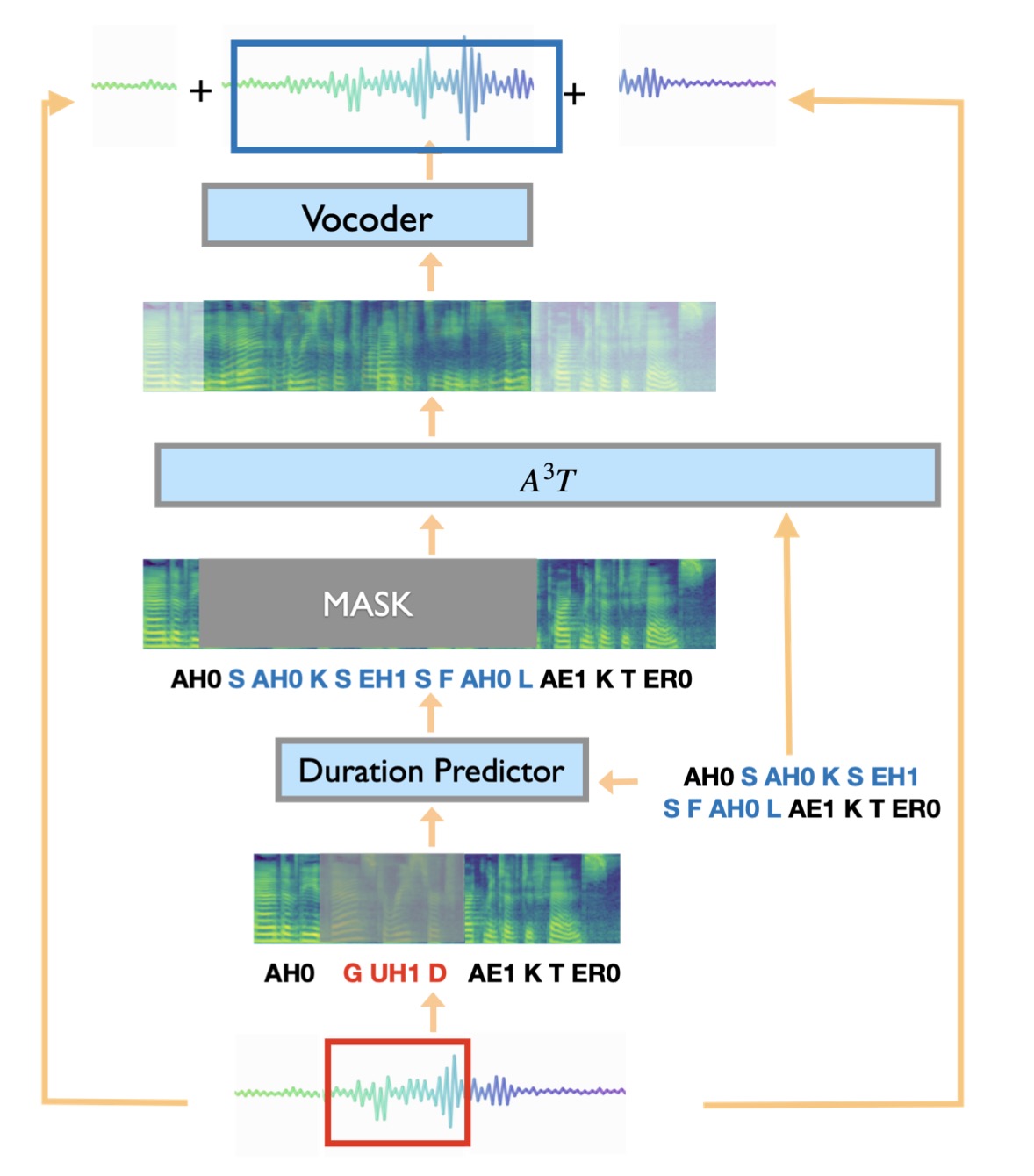
预测时,使用额外的 Duration Predictor 模块(如,预训练好的 FastSpeech2 模型的 duration_predictor)获取待重建音频(输入文本对应的音频)的时长,构造相应的长度的空 mel 频谱并 mask 住,模型预测对应的 mel 频谱。
A good\color{red}{good}good actor -> A successful\color{blue}{successful}successful actor
3.1.2 模型框架
ERNIE-SAT 中提出了 3 项创新:
- 提出了一个通用的端到端语音和文本联合预处理框架用于跨语言语音合成,它可以联合学习语音和文本输入的统一表示。
- 由于多语语音语料库有限,有效地利用多个单语语音数据在单一模型中构建双语音素列表,并利用不同语言的数据重建语音和文本的训练目标。模型在跨语言推理过程中可生成高质量的语音。
- 能够对看不见的说话人执行跨语言语音合成,并且优于基于说话人嵌入的多说话人 TTS 方法(SV2TTS)。

ERNIE-SAT 是基于 A3T 的改进,A3T 没有对文本(phoneme)做 mask,只对语音(mel 频谱)做了 mask,只能对被 mask 住的语音做高质量重建,ERNIE-SAT 同时对语音和文本做 mask,可以同时重建语音信息和文本信息;此外,A3T 只能处理单语言的情况,并不支持跨语言合成,ERNIE-SAT 可以实现跨语言合成:
- 纯中文和纯英文的 ERNIE-SAT,模型结构和 A3T 一样,直接使用 VCTK 数据集(英文)或 AISHELL-3 数据集(中文)进行训练
- 中英文混合的 ERNIE-SAT 是语音和文本一起 mask,可以实现跨语言合成任务,混合 VCTK 数据集(英文)和 AISHELL-3 数据集(中文)进行训练
- 随机 mask 住 80% 的 mel 频谱特征
- 再 mask 住剩余的 20% 的 mel 频谱特征对应的 phoneme 里的一半
3.2 ERNIE-SAT 和 SV2TTS 的区别与联系
- SV2TTS 和 ERNIE-SAT 本质都是语音合成声学模型,需要输入合成文本信息,输出 mel 频谱特征,其后需要接声码器才能合成音频,都属于 one-shot TTS 模型。
- SV2TTS 和 ERNIE-SAT 都是声音克隆模型,都需要输入参考音频获取合成音频的音色信息。
- SV2TTS 需要额外的声纹模型作为 speaker encoder 提取参考音频的 speaker embedding 作为输入,在训练和预测时,并不是一个 end-to-end 的系统;ERNIE-SAT 直接输入参考音频的 mel 频谱获取音色特征,在训练和预测时都是完全 end-to-end 的。
- 对于 SV2TTS 所需的声纹模型来说,在低资源的语言场景中,收集大量多说话人、多语言数据来训练模型提取 speaker embedding 非常困难。
- SV2TTS 仅有声音克隆功能,ERNIE-SAT 在声音克隆的基础上,可同时完成语音编辑以及跨语言的语音合成任务。
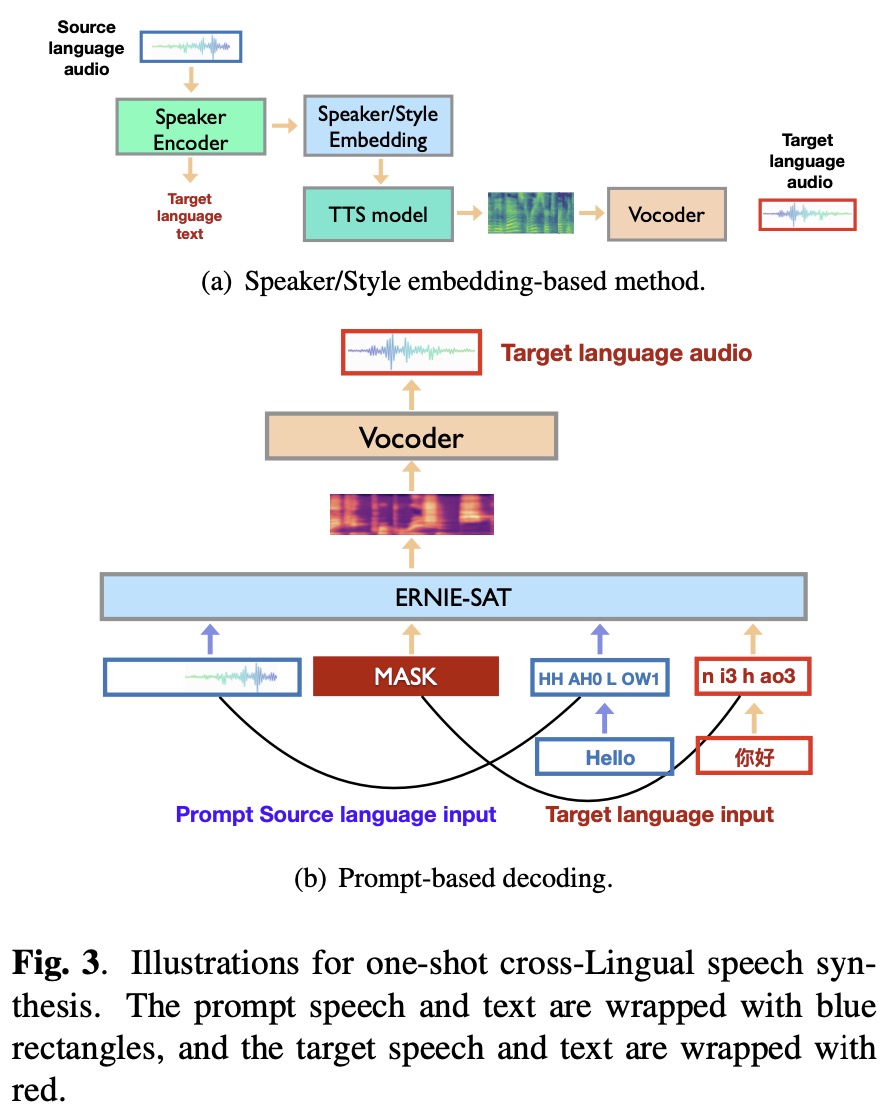
3.3 实践
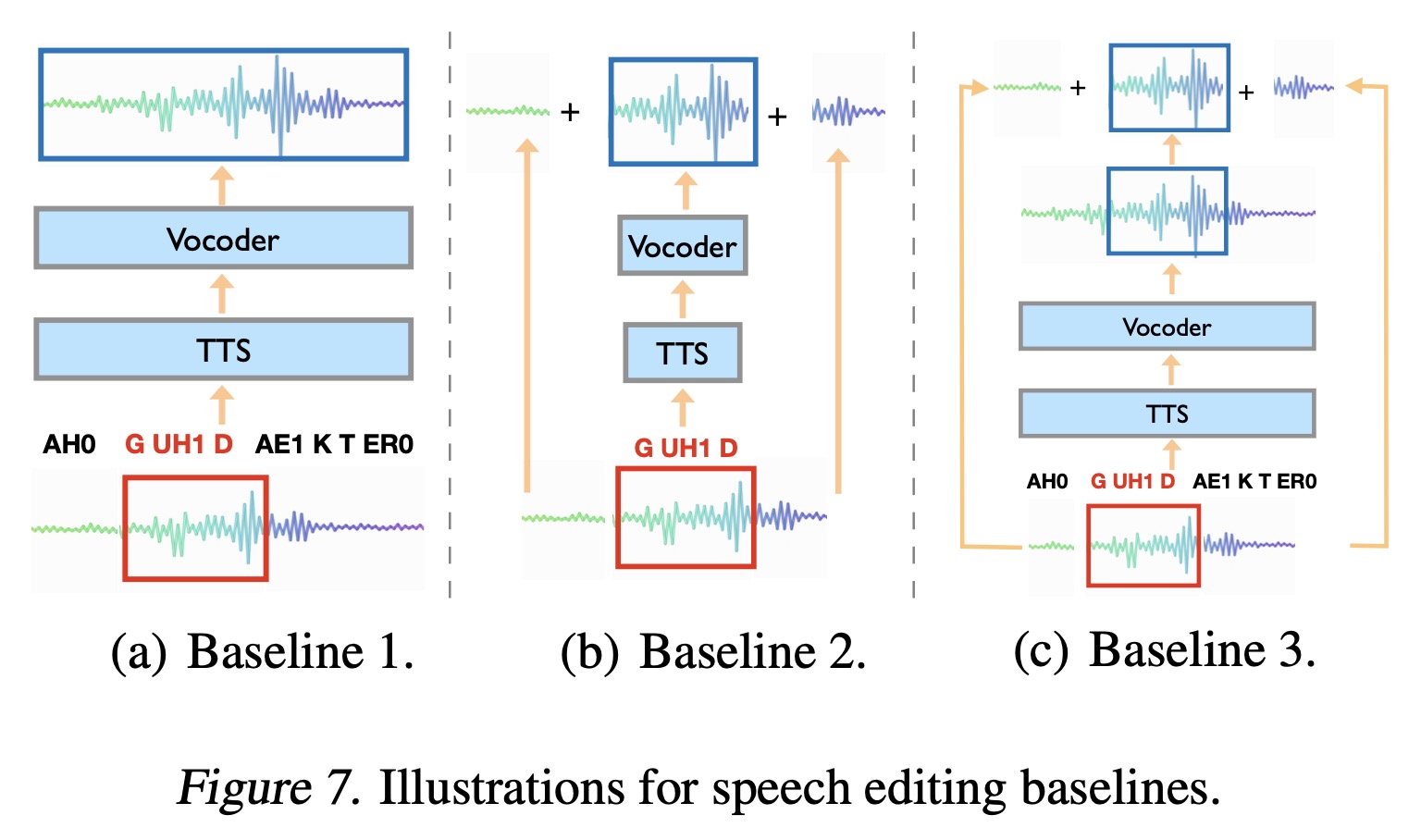
纯中文或纯英文的 ERNIE-SAT 支持语音编辑和个性化合成,中英文混合的 ERNIE-SAT 支持跨语言合成,本质都是声音克隆。
以英文语音编辑为例,下列代码修改自 ernie_sat/synthesize_e2e.py,环境准备参考 vctk/ernie_sat。
For that reason cover should\color{red}{should}should not\color{red}{not}not be given -> For that reason cover is\color{blue}{is}is not\color{blue}{not}not impossible\color{blue}{impossible}impossible to\color{blue}{to}to be given
获取预训练模型和数据
# prepare aligner
!mkdir -p tools/aligner
%cd tools
# download MFA
# !wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.0.1/montreal-forced-aligner_linux.tar.gz
!wget https://paddlespeech.bj.bcebos.com/MFA/montreal-forced-aligner_linux.tar.gz
# extract MFA
!tar xvf montreal-forced-aligner_linux.tar.gz
# fix .so of MFA
%cd montreal-forced-aligner/lib
!ln -snf libpython3.6m.so.1.0 libpython3.6m.so
%cd -
# download align models and dicts
%cd aligner
!wget https://paddlespeech.bj.bcebos.com/MFA/ernie_sat/aishell3_model.zip
!wget https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/simple.lexicon
!wget https://paddlespeech.bj.bcebos.com/MFA/ernie_sat/vctk_model.zip
!wget https://paddlespeech.bj.bcebos.com/MFA/LJSpeech-1.1/cmudict-0.7b
%cd ../../
clear_output()
# prepare pretrained FastSpeech2 models
!mkdir download
%cd download
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_conformer_baker_ckpt_0.5.zip
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_ljspeech_ckpt_0.5.zip
!unzip fastspeech2_conformer_baker_ckpt_0.5.zip
!unzip fastspeech2_nosil_ljspeech_ckpt_0.5.zip
%cd ../
clear_output()
# prepare source data
!mkdir source
%cd source
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/SSB03540307.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/SSB03540428.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/LJ050-0278.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/p243_313.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/p299_096.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/this_was_not_the_show_for_me.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/source/README.md
%cd ../
clear_output()
# 下载预训练模型
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/ernie_sat/erniesat_vctk_ckpt_1.2.0.zip
!unzip -o -d download download/erniesat_vctk_ckpt_1.2.0.zip
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_vctk_ckpt_0.2.0.zip
!unzip -o -d download download/hifigan_vctk_ckpt_0.2.0.zip
clear_output()
导入 Python 包
import os
from pathlib import Path
from typing import Listimport librosa
import numpy as np
import paddle
import pypinyin
import soundfile as sf
import yaml
from pypinyin_dict.phrase_pinyin_data import large_pinyin
from yacs.config import CfgNodefrom paddlespeech.t2s.datasets.am_batch_fn import build_erniesat_collate_fn
from paddlespeech.t2s.datasets.get_feats import LogMelFBank
from paddlespeech.t2s.exps.ernie_sat.align import get_phns_spans
from paddlespeech.t2s.exps.ernie_sat.utils import eval_durs
from paddlespeech.t2s.exps.ernie_sat.utils import get_dur_adj_factor
from paddlespeech.t2s.exps.ernie_sat.utils import get_span_bdy
from paddlespeech.t2s.exps.ernie_sat.utils import get_tmp_name
from paddlespeech.t2s.exps.syn_utils import get_am_inference
from paddlespeech.t2s.exps.syn_utils import get_voc_inference
from paddlespeech.t2s.exps.syn_utils import norm
定义 ERNIE-SAT 所需功能函数
def _p2id(phonemes: List[str]) -> np.ndarray:# replace unk phone with spphonemes = [phn if phn in vocab_phones else "sp" for phn in phonemes]phone_ids = [vocab_phones[item] for item in phonemes]return np.array(phone_ids, np.int64)def prep_feats_with_dur(wav_path: str,old_str: str='',new_str: str='',source_lang: str='en',target_lang: str='en',duration_adjust: bool=True,fs: int=24000,n_shift: int=300):'''Returns:np.ndarray: new wav, replace the part to be edited in original wav with 0List[str]: new phonesList[float]: mfa start of new wavList[float]: mfa end of new wavList[int]: masked mel boundary of original wavList[int]: masked mel boundary of new wav'''wav_org, _ = librosa.load(wav_path, sr=fs)phns_spans_outs = get_phns_spans(wav_path=wav_path,old_str=old_str,new_str=new_str,source_lang=source_lang,target_lang=target_lang,fs=fs,n_shift=n_shift)mfa_start = phns_spans_outs['mfa_start']mfa_end = phns_spans_outs['mfa_end']old_phns = phns_spans_outs['old_phns']new_phns = phns_spans_outs['new_phns']span_to_repl = phns_spans_outs['span_to_repl']span_to_add = phns_spans_outs['span_to_add']# 中文的 phns 不一定都在 fastspeech2 的字典里, 用 sp 代替if target_lang in {'en', 'zh'}:old_durs = eval_durs(old_phns, target_lang=source_lang)else:assert target_lang in {'en', 'zh'}, \"calculate duration_predict is not support for this language..."orig_old_durs = [e - s for e, s in zip(mfa_end, mfa_start)]if duration_adjust:d_factor = get_dur_adj_factor(orig_dur=orig_old_durs, pred_dur=old_durs, phns=old_phns)d_factor = d_factor * 1.25else:d_factor = 1if target_lang in {'en', 'zh'}:new_durs = eval_durs(new_phns, target_lang=target_lang)else:assert target_lang == "zh" or target_lang == "en", \"calculate duration_predict is not support for this language..."# duration 要是整数new_durs_adjusted = [int(np.ceil(d_factor * i)) for i in new_durs]new_span_dur_sum = sum(new_durs_adjusted[span_to_add[0]:span_to_add[1]])old_span_dur_sum = sum(orig_old_durs[span_to_repl[0]:span_to_repl[1]])dur_offset = new_span_dur_sum - old_span_dur_sumnew_mfa_start = mfa_start[:span_to_repl[0]]new_mfa_end = mfa_end[:span_to_repl[0]]for dur in new_durs_adjusted[span_to_add[0]:span_to_add[1]]:if len(new_mfa_end) == 0:new_mfa_start.append(0)new_mfa_end.append(dur)else:new_mfa_start.append(new_mfa_end[-1])new_mfa_end.append(new_mfa_end[-1] + dur)new_mfa_start += [i + dur_offset for i in mfa_start[span_to_repl[1]:]]new_mfa_end += [i + dur_offset for i in mfa_end[span_to_repl[1]:]]# 3. get new wav# 在原始句子后拼接if span_to_repl[0] >= len(mfa_start):wav_left_idx = len(wav_org)wav_right_idx = wav_left_idx# 在原始句子中间替换else:wav_left_idx = int(np.floor(mfa_start[span_to_repl[0]] * n_shift))wav_right_idx = int(np.ceil(mfa_end[span_to_repl[1] - 1] * n_shift))blank_wav = np.zeros((int(np.ceil(new_span_dur_sum * n_shift)), ), dtype=wav_org.dtype)# 原始音频,需要编辑的部分替换成空音频,空音频的时间由 fs2 的 duration_predictor 决定new_wav = np.concatenate([wav_org[:wav_left_idx], blank_wav, wav_org[wav_right_idx:]])# 4. get old and new mel span to be maskold_span_bdy = get_span_bdy(mfa_start=mfa_start, mfa_end=mfa_end, span_to_repl=span_to_repl)new_span_bdy = get_span_bdy(mfa_start=new_mfa_start, mfa_end=new_mfa_end, span_to_repl=span_to_add)# old_span_bdy, new_span_bdy 是帧级别的范围outs = {}outs['new_wav'] = new_wavouts['new_phns'] = new_phnsouts['new_mfa_start'] = new_mfa_startouts['new_mfa_end'] = new_mfa_endouts['old_span_bdy'] = old_span_bdyouts['new_span_bdy'] = new_span_bdyreturn outsdef prep_feats(wav_path: str,old_str: str='',new_str: str='',source_lang: str='en',target_lang: str='en',duration_adjust: bool=True,fs: int=24000,n_shift: int=300):with_dur_outs = prep_feats_with_dur(wav_path=wav_path,old_str=old_str,new_str=new_str,source_lang=source_lang,target_lang=target_lang,duration_adjust=duration_adjust,fs=fs,n_shift=n_shift)wav_name = os.path.basename(wav_path)utt_id = wav_name.split('.')[0]wav = with_dur_outs['new_wav']phns = with_dur_outs['new_phns']mfa_start = with_dur_outs['new_mfa_start']mfa_end = with_dur_outs['new_mfa_end']old_span_bdy = with_dur_outs['old_span_bdy']new_span_bdy = with_dur_outs['new_span_bdy']span_bdy = np.array(new_span_bdy)mel = mel_extractor.get_log_mel_fbank(wav)erniesat_mean, erniesat_std = np.load(erniesat_stat)normed_mel = norm(mel, erniesat_mean, erniesat_std)tmp_name = get_tmp_name(text=old_str)tmpbase = './tmp_dir/' + tmp_nametmpbase = Path(tmpbase)tmpbase.mkdir(parents=True, exist_ok=True)mel_path = tmpbase / 'mel.npy'np.save(mel_path, normed_mel)durations = [e - s for e, s in zip(mfa_end, mfa_start)]text = _p2id(phns)datum = {"utt_id": utt_id,"spk_id": 0,"text": text,"text_lengths": len(text),"speech_lengths": len(normed_mel),"durations": durations,"speech": np.load(mel_path),"align_start": mfa_start,"align_end": mfa_end,"span_bdy": span_bdy}batch = collate_fn([datum])outs = dict()outs['batch'] = batchouts['old_span_bdy'] = old_span_bdyouts['new_span_bdy'] = new_span_bdyreturn outsdef get_mlm_output(wav_path: str,old_str: str='',new_str: str='',source_lang: str='en',target_lang: str='en',duration_adjust: bool=True,fs: int=24000,n_shift: int=300):prep_feats_outs = prep_feats(wav_path=wav_path,old_str=old_str,new_str=new_str,source_lang=source_lang,target_lang=target_lang,duration_adjust=duration_adjust,fs=fs,n_shift=n_shift)batch = prep_feats_outs['batch']new_span_bdy = prep_feats_outs['new_span_bdy']old_span_bdy = prep_feats_outs['old_span_bdy']out_mels = erniesat_inference(speech=batch['speech'],text=batch['text'],masked_pos=batch['masked_pos'],speech_mask=batch['speech_mask'],text_mask=batch['text_mask'],speech_seg_pos=batch['speech_seg_pos'],text_seg_pos=batch['text_seg_pos'],span_bdy=new_span_bdy)# 拼接音频output_feat = paddle.concat(x=out_mels, axis=0)wav_org, _ = librosa.load(wav_path, sr=fs)outs = dict()outs['wav_org'] = wav_orgouts['output_feat'] = output_featouts['old_span_bdy'] = old_span_bdyouts['new_span_bdy'] = new_span_bdyreturn outsdef get_wav(wav_path: str,source_lang: str='en',target_lang: str='en',old_str: str='',new_str: str='',duration_adjust: bool=True,fs: int=24000,n_shift: int=300,task_name: str='synthesize'):outs = get_mlm_output(wav_path=wav_path,old_str=old_str,new_str=new_str,source_lang=source_lang,target_lang=target_lang,duration_adjust=duration_adjust,fs=fs,n_shift=n_shift)wav_org = outs['wav_org']output_feat = outs['output_feat']old_span_bdy = outs['old_span_bdy']new_span_bdy = outs['new_span_bdy']masked_feat = output_feat[new_span_bdy[0]:new_span_bdy[1]]with paddle.no_grad():alt_wav = voc_inference(masked_feat)alt_wav = np.squeeze(alt_wav)old_time_bdy = [n_shift * x for x in old_span_bdy]if task_name == 'edit':wav_replaced = np.concatenate([wav_org[:old_time_bdy[0]], alt_wav, wav_org[old_time_bdy[1]:]])else:wav_replaced = alt_wavwav_dict = {"origin": wav_org, "output": wav_replaced}return wav_dict
主程序
erniesat_config = 'download/erniesat_vctk_ckpt_1.2.0/default.yaml'
erniesat_ckpt = 'download/erniesat_vctk_ckpt_1.2.0/snapshot_iter_199500.pdz'
erniesat_stat = 'download/erniesat_vctk_ckpt_1.2.0/speech_stats.npy'
phones_dict = 'download/erniesat_vctk_ckpt_1.2.0/phone_id_map.txt'voc = 'hifigan_vctk'
voc_config = 'download/hifigan_vctk_ckpt_0.2.0/default.yaml'
voc_ckpt = 'download/hifigan_vctk_ckpt_0.2.0/snapshot_iter_2500000.pdz'
voc_stat = 'download/hifigan_vctk_ckpt_0.2.0/feats_stats.npy'task_name = 'edit'
wav_path = 'source/p243_313.wav'
# should not -> is not impossible to
old_str = 'For that reason cover should not be given'
new_str = 'For that reason cover is not impossible to be given'
source_lang = 'en'
target_lang = 'en'
duration_adjust = True
output_name = 'sat_output.wav'# evaluate(args)
with open(erniesat_config) as f:erniesat_config = CfgNode(yaml.safe_load(f))
with open(voc_config) as f:voc_config = CfgNode(yaml.safe_load(f))
# convert Chinese characters to pinyin
if source_lang == 'zh':old_str = pypinyin.lazy_pinyin(old_str,neutral_tone_with_five=True,style=pypinyin.Style.TONE3,tone_sandhi=True)old_str = ' '.join(old_str)
if target_lang == 'zh':new_str = pypinyin.lazy_pinyin(new_str,neutral_tone_with_five=True,style=pypinyin.Style.TONE3,tone_sandhi=True)new_str = ' '.join(new_str)if task_name == 'edit':new_str = new_str
elif task_name == 'synthesize':new_str = old_str + ' ' + new_str
else:new_str = old_str + ' ' + new_str# Extractor
mel_extractor = LogMelFBank(sr=erniesat_config.fs,n_fft=erniesat_config.n_fft,hop_length=erniesat_config.n_shift,win_length=erniesat_config.win_length,window=erniesat_config.window,n_mels=erniesat_config.n_mels,fmin=erniesat_config.fmin,fmax=erniesat_config.fmax)collate_fn = build_erniesat_collate_fn(mlm_prob=erniesat_config.mlm_prob,mean_phn_span=erniesat_config.mean_phn_span,seg_emb=erniesat_config.model['enc_input_layer'] == 'sega_mlm',text_masking=False)vocab_phones = {}with open(phones_dict, 'rt') as f:phn_id = [line.strip().split() for line in f.readlines()]
for phn, id in phn_id:vocab_phones[phn] = int(id)# ernie sat model
erniesat_inference = get_am_inference(am='erniesat_dataset',am_config=erniesat_config,am_ckpt=erniesat_ckpt,am_stat=erniesat_stat,phones_dict=phones_dict)# vocoder
voc_inference = get_voc_inference(voc=voc,voc_config=voc_config,voc_ckpt=voc_ckpt,voc_stat=voc_stat)wav_dict = get_wav(wav_path=wav_path,source_lang=source_lang,target_lang=target_lang,old_str=old_str,new_str=new_str,duration_adjust=duration_adjust,fs=erniesat_config.fs,n_shift=erniesat_config.n_shift,task_name=task_name)sf.write(output_name, wav_dict['output'], samplerate=erniesat_config.fs)
print(f"\033[1;32;m Generated audio saved into{output_name}! \033[0m")# 播放输入音频
import IPython.display as dp
dp.Audio("source/p243_313.wav")
# 播放编辑好的音频
dp.Audio('sat_output.wav', rate=erniesat_config.fs)
具体实现代码请参考:
- 纯中文 ERNIE-SAT
- 纯英文 ERNIE-SAT
- 中英文混合 ERNIE-SAT
SV2TTS 和 ERNIE-SAT 均属于一句话克隆,其合成效果有限,能获取一定量的数据情况下,可以考虑小数据集微调方案,具有更高的音色相似度和更好的音频质量。请参考多语言合成与小样本合成技术应用实践。
Web 页面体验 SV2TTS、ERNIE-SAT 一句话合成和小数据集微调:
- github 项目体验地址
- AiStudio在线体验地址:【PaddleSpeech进阶】PaddleSpeech小样本合成方案体验
PS:
本教程所指的声音克隆的英文名称是 Voice Cloning,简称 VC,在语音合成领域,有另一种细分领域也简称 VC,全称是 Voice Conversion 声音转换,两者的区别是,Voice Cloning 同时输入参考音频和输入文本,合成的音频有参考音频的音色,说话内容是输入文本;Voice Conversion 输入 source audio 和 target audio 两个音频,无需输入文本,合成的音频具有 target audio 的音色和 source audio 的文本内容以及韵律特征。柯南的变声领结实际上是用 Voice Conversion 声音转换技术实现的(用毛利小五郎的音色说出柯南的说话内容)。Voice Cloning 合成音频的韵律性能是一般是 TTS 模型本身决定的,而 Voice Conversion 合成音频的韵律一般是由 source audio 决定的。
大家以后在语音合成领域看到 “VC” 一定要分清楚指的是声音克隆 Voice Cloning 还是声音转换 Voice Conversion 哟。
关注 PaddleSpeech
喜欢的同学可以点个 ⭐️star⭐️ 支持我们,PaddleSpeech传送门:https://github.com/PaddlePaddle/PaddleSpeech
《飞桨PaddleSpeech语音技术课程》一句话语音合成全流程实践相关推荐
- 【飞桨PaddleSpeech语音技术课程】— 语音合成
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 『听』和『说』 人类通过听觉获取的信息大约占所有感知信息的 20% ~ 30%.声音存储了丰富的语义以及时序信息,由 ...
- 【飞桨PaddleSpeech语音技术课程】— 一句话语音合成全流程实践
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 一句话语音合成全流程实践 点击播放视频 1 声音克隆介绍 & 语音合成基本概念回顾 语音合成(Speech ...
- 【飞桨PaddleSpeech语音技术课程】— 流式语音合成技术揭秘与实践
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) PP-TTS:流式语音合成原理及服务部署 1 流式语音合成服务的场景与产业应用 语音合成(Speech Sysnth ...
- 【飞桨PaddleSpeech语音技术课程】— 语音识别-定制化识别
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 定制化语音识别 1. 背景 在一些特定场景下,要求ASR系统对某些固定句式的关键词准确识别. 打车报销单场景,要求日 ...
- 【飞桨PaddleSpeech语音技术课程】— 语音唤醒
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 1. KWS 概述 随着人工智能的飞速发展,市场上推出了各式各样的智能设备,AI 语音的发展更是使得语音助手成为各大 ...
- 【飞桨PaddleSpeech语音技术课程】— 语音识别-Deepspeech2
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 语音识别--DeepSpeech2 0. 视频理解与字幕 # 下载demo视频 !test -f work/sour ...
- 【飞桨PaddleSpeech语音技术课程】— 声音分类
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 1. 识别声音 通过声音,人的大脑会获取到大量的信息,其中的一个场景是:识别和归类.如:识别熟悉的亲人或朋友的声音. ...
- 【飞桨PaddleSpeech语音技术课程】— 语音翻译
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) End-to-End Speech (to Text) Translation 前言 背景知识 语音翻译(ST, S ...
- 【飞桨PaddleSpeech语音技术课程】— 语音识别-Transformer
使用 Transformer 进行语音识别 0. 视频理解与字幕 # 下载demo视频 !test -f work/source/subtitle_demo1.mp4 || wget -c https ...
最新文章
- win7如何启动计算机,win7开机启动项怎么设置 电脑开机启动项在哪里设置
- Pass4side CompTIA PK0-002题库下载
- SQL一对多特殊查询,取唯一一条
- vscode 配置php
- 每日程序C语言49-猴子分桃子问题
- 使用AWS使Spring Boot应用程序无服务器运行
- 搭建Cent OS7服务器时需要注意的一些问题
- w ndows10怎么没体验指数,Win10没有“Windows体验指数”功能怎么进行系统评分【图文】...
- 程序崩溃优雅退出之-SetUnhandledExceptionFilter
- 记一次 ORA-600 [12700] 故障案例
- 一个Lua脚本的解密过程
- java生成密码生成
- 计算机cpu近几年价格,CPU性能过剩的福利 十年老电脑还能再战几年?
- 将字符串中的英文大写字母换成小写字母-c语言实现
- Python机器学习个人总结
- 富士通scan按钮自动扫描设置
- Java 8 Update 201 (8u201)
- 「普通人VS程序员」电脑还可以这样关机,神操作 建议阅读
- 百度云其实真的很不错
- git如何忽略一个文件
热门文章