Category Archives: 机器学习
转载自:http://www.52ml.net/categories/machinelearning/page/18
书籍推荐:《大嘴巴漫谈数据挖掘(全彩)》 – china-pub
China-pub链接:《大嘴巴漫谈数据挖掘(全彩)》

作者: 易向军
出版社:电子工业出版社
ISBN:9787121225116
上架时间:2014-3-5
出版日期:2014 年4月
开本:16开
页码:288
版次:1-1
所属分类:计算机 > 数据库 > 数据库存储与管理
编辑推荐
大嘴巴带你玩转数据挖掘
让你知道啤酒君和尿布君为什么会相遇,大数据的小科普让你成为“读心”魔法师!
数据挖掘私人定制 轻松掌控再无敌手
拒绝枯燥越过三境 火爆网络疯狂下载
内容简介
计算机书籍
《大嘴巴漫谈数据挖掘(全彩)》从最基本的概率统计学开始,全面、系统、形象而又深入地描述了数据挖掘的基础概念、应用领域以及常用算法。其中每一种 数据挖掘算法都辅以通俗易懂的实例,读者能够在直观性、趣味性中学习算法的具体流程,明白算法的实现过程。通过《大嘴巴漫谈数据挖掘(全彩)》的学习,读 者可以对数据挖掘的概念、应用和算法技术有一个清晰的理解和认识,并可以熟悉相关统计学的基本原理。
《大嘴巴漫谈数据挖掘(全彩)》适合想从事数据挖掘方面的工作的初学者、数据分析爱好者、分析师,以及一线的数据挖掘开发人员参考阅读,也适合客户经理针 对如何开展针对性的营销活动,避免客户流失而阅读学习,更适合产品经理阅读,因为针对如何预测产品的目标用户,促进用户活跃和业务有效使用,靠经验已经不 行了,数据才最有说服力,更适合企业管理者将其作为一本通俗易懂的数据挖掘基础读物阅读学习,对下属的工作方向给予指导,以及适合教师学生数据挖掘课程辅 导之用。
作译者
浅醉斛觞意渐乱,浮生聚散人堪愁
目录
第一境昨夜西风凋碧树。独上高楼,望尽天涯路…… /10
1.1数据挖掘简介 / 11
开篇点题引五问 /12
大数据中求价值 /13
定义概述归特点 /14
知识决策跨领域 /15
架构特征多形式 /17
数据立方展多维 /19
功能挖掘四大类 /22
分类刻画类标识 /23
数据聚类辨亲疏 /24
预测未来训模型 /25
关联源自购物篮 /27
模型过程方法论 /28
十大算法成经典 /32
1.2数据挖掘应用 /33
行业推广多应用 /34
用户为王放心中 /36
指导运营全周期 /37
前言
为什么要写作本书
一般来说,学习数据挖掘要求读者已经具备一定的专业水平和相关技能。本书从最基本的概率统计开始,由浅入深,由易到难,由总到分,使得普通读者也能够了解和掌握常规的数据挖掘理论和知识。
管理者:虽不用到一线从事具体的数据分析工作,但也需要一本通俗易懂的数据挖掘基础读物,通过学习能够对下属的工作方向给予指导。
客户经理:如何开展针对性的营销活动,避免客户流失,这都需要数据挖掘知识。
产品经理:如何促进产品的用户活跃和业务的有效使用,不仅要靠经验,数据才最有说服力。
工程师:一线的数据挖掘开发人员必然要掌握的。
分析师:撰写经营分析报告数据挖掘知识必不可少。
教师:数据挖掘的参考书。
学生:想从事数据分析和挖掘方面的工作,肯定是要学习的。
数据分析爱好者:一本通俗易懂的入门读物。
本书主要内容
本书基本上涵盖了学习数据挖掘需要掌握的大部分核心知识点,分为三境17章。第一境总体介绍数据挖掘概况和应用领域,第二境讲解基本概率统计知识,第三境具体描述了数据挖掘常用的十大算法。
致谢
本书的顺利出版离不开电子工业出版社博文视点编辑老师们的辛勤工作,在此表示最诚挚的感谢!
同时,对于本书的创作形式和书写理念,本书的出版人孙学瑛女士给予了最大的支持和保留,并提供了大量的指导和帮助。衷心感谢孙老师对本书的重视和欣赏,以及为本书出版所做的一切,并将终身难忘!
由于作者水平有限,书中不足及错误之处在所难免,敬请专家和读者给予批评指正。
易向军
2014年3月
媒体评论
既有漫画小插图,又有七绝或者七律打油诗,相当的简明易懂啊。多次出场的啤酒君和尿布君,相当有喜感。但是看着看着就变成了概率统计教科书了有木有——贝叶斯、高斯。多希望我在考研前看到这本书啊,会对我的数学考试有帮助吧!
——展展
看了这本书,确有解惑醒脑之功效,作者很明白我们这些科技小白的理解能力,不敢把话说得太专业,确实通俗易懂,深入浅出,层层推进,让初学者都有很强的兴趣学进去,对只想做了解的同学来说也不难接受,算是很好的科普作品了。
——大雄不贰
漫谈类,减少了大数据的枯燥,感觉看一遍还不能及时消化,有空再慢慢精读一下。
——杨旭彬
把数据挖掘写得深入浅出,很容易读懂,实用性强。
——傅志华
书中关于数据挖掘章节的介绍,我特别喜欢,毕竟在数据爆炸的今天,只有从数据中找到别人没发现的亮点才是关键。
——由子木
这本书非常值得每一个对数据感兴趣的人士细细研读!
李洪宇
很是喜欢易老师的这种写书风格,可以让我们轻松地学到知识,超赞!
骆彬
把复杂的统计知识和数据挖掘算法用图形化后,就很适合作为科普型的数据挖掘入门书籍,好干货!
——麒程
比较简单,每个点都可以自行扩展学习,就像个全面的大字典目录一样,通读此书后,可以很好地把握常规的数据挖掘知识和思想。
金石头
总体来说通俗易懂,有一些总结和图片很有助于理解,总之是能把数据挖掘这种相对枯燥的东西让人读下去,这样来说总体是非常不错的。
——Woozy
Matlab计算机视觉/图像处理工具箱推荐
计算机视觉/图像处理研究中经常要用到Matlab,虽然其自带了图像处理和计算机视觉的许多功能,但是术业有专攻,在进行深入的视觉算法研究的时候Matlab的自带功能难免会不够用。本文收集了一些比较优秀的Matlab计算机视觉工具箱,希望能对国内的研究者有所帮助。
VLFeat:著名而常用
项目网站:http://www.vlfeat.org
许可证:BSD
著名的计算机视觉/图像处理开源项目,知名度应该不必OpenCV低太多,曾获ACM Open Source Software Competition 2010一等奖。使用C语言编写,提供C语言和Matlab两种接口。实现了大量计算机视觉算法,包括:
- 常用图像处理功能,包括颜色空间变换、几何变换(作为Matlab的补充),常用机器学习算法,包括GMM、SVM、KMeans等,常用的图像处理的plot工具。
- 特征提取,包括 Covariant detectors, HOG, SIFT,MSER等。VLFeat提供了一个vl_covdet() 函数作为框架,可以方便的统一所谓“co-variant feature detectors”,包括了DoG, Harris-Affine, Harris-Laplace并且可以提取SIFT或raw patches描述子。
- 超像素(Superpixel)分割,包括常用的Quick shift, SLIC算法等
- 高级聚类算法,比如整数KMeans:Integer k-means (IKM)、hierarchical version of integer k-means (HIKM),基于互信息自动判定聚类类数的算法Agglomerative Information Bottleneck (AIB) algorithm等
- 高维特曾匹配算法,随机KD树Randomized kd-trees
可以在这里查看VLFeat完整的功能列表。
(欢迎访问计算机视觉研究笔记http://cvnote.info或者关注新浪@cvnote)
MexOpenCV:让Matlab支持调用的OpenCV
项目网站:http://www.cs.sunysb.edu/~kyamagu/mexopencv/
作者Kota Yamaguchi桑是石溪大学(Stony Brook University)的PhD,早些时候自己搞了一套东西把OpenCV的代码编译成Matlab可用的mex接口,然后这个东西迅速火了。今年夏天这个项目被OpenCV吸收为一个模块,貌似是搞了一个Google Summer of Code(GSoC)的项目,最近(大概是9、10月)已经merge到了OpenCV主包,有兴趣的可以到Github的OpenCV库下的module/matlab去玩一下,应该会在10月份的OpenCV 3 alpha里正式发布。现在OpenCV就同时有了Python和Maltab的binding(好强大)。具体的功能就不细说了,既然是OpenCV的binding,当然是可以使用OpenCV的绝大多数算法了。比如这样:
% load an image (Matlab)
I = imread(‘cameraman.tif’);
% compute the DFT (OpenCV)
If = cv.dft(I, cv.DFT_COMPLEX_OUTPUT);

Peter Kovesi的工具箱:轻量好用,侧重图像处理
项目网站:http://www.csse.uwa.edu.au/~pk/research/matlabfns/
这位Peter大哥目前在The University of Western Australia工作,他自己写了一套Matlab计算机视觉算法,所谓工具箱其实就是许多m文件的集合,全部Matlab实现,无需编译安装,支持Octave(如果没有Matlab的话,有了这个工具箱也可以在Octave下进行图像处理了)。别看这位大哥单枪匹马,人家的工具箱可是相当有名,研究时候需要哪个Matlab的计算机视觉小功能,直接到他家主页上下几个m文件放在自己文件夹就好了。这个工具箱主要以图像处理算法为主,附带一些三维视觉的基本算法,列一些包括的功能:
- Feature Detection via Phase Congruency,求达人解释这个是啥
- Spatial Feature Detection,Harris、Canny之类的特征算法
- Edge Linking and Line Segment Fitting,边缘特征和线特征的各种操作
- Image Denoising,图像降噪
- Surface Normals to Surfaces,从法向量积分出表面
- Scalogram Calculation,求达人解释这个是啥
- Anisotropic diffusion,著名的保边缘平滑算法
- Frequency Domain Transformations,傅立叶变换
- Functions Supporting Projective Geometry,透视几何、三维视觉的一些算法
- Feature Matching、特征匹配
- Model Fitting and Robust Estimation、RANSAC
- Fingerprint Enhancement,指纹图像增强
- Interesting Synthetic Images,一些好玩儿的图像生成算法
- Image Blending,图像融合
- Colourmaps and colour conversions,颜色空间算法
可以在网站上看到全部功能的介绍和下载,非常推荐试一下,也可以学到不少算法。
Machine Vision Toolbox:侧重机器视觉、三维视觉
项目网站:http://www.petercorke.com/Machine_Vision_Toolbox.html
许可证:LGPL
以前没有用过这个工具箱,最近发现竟然非常强大,而且和我自己的工作还很相关。这个工具箱侧重机器视觉,作者是另一个Peter,Peter Corke在机器人界很有名,他在2011年写了一本书《Robotics, Vision & Control》介绍了机器视觉相关的颜色、相机模型、三维视觉、控制等研究,并配套这个工具箱。算法包括了大量常用的视觉和图像处理小函数,,这些就不提了,提几个别的工具箱一般没有的功能
- Bag of words的Matlab实现
- 各种相机模型的实现,包括普通相机、鱼眼相机、Catadioptric相机模型等等。如果你做机器人视觉、挂在各种广角相机的话,这些模型实现会很有用
- 自带简单的相机标定功能
- 对极几何(Epipolar Geomtry)的相关算法函数
- Plucker坐标的实现,做广义相机模型(Generalized camera model)很有用

Piotr’s Image & Video Matlab Toolbox:侧重物体识别
项目网站:http://vision.ucsd.edu/~pdollar/toolbox/doc/index.html
许可证:Simple BSD
(补充一个工具箱)由UCSD的Piotr Dollar编写,侧重物体识别(Object Recognition)检测相关的特征提取和分类算法。这个工具箱属于专而精的类型,主要就是Dollar的几篇物体检测的论文的相关算法,如果做物体识别相关的研究,应该是很好用的。同时它的图像操作或矩阵操作函数也可以作为Matlab图像处理工具箱的补充,功能主要包括几个模块:
- channels模块,图像特征提取,包括HOG等,Dollar的研究工作提出了一种Channel Feature的特征1,因此这个channels主要包括了提取这一特征需要的一些基本算法梯度、卷及等基本算法
- classify模块,一些快速的分类相关算法,包括random ferns, RBF functions, PCA等
- detector模块,与Channel Feature特征对应的检测算法1
- filters模块,一些常规的图像滤波器
- images模块,一些常规的图像、视频操作,有一些很实用的函数
- matlab模块,一些常规的Matlab函数,包括矩阵计算、显示、变量操作等,很实用
- videos模块,一些常规的视频操作函数等
1. P. Dollár, Z. Tu, P. Perona and S. Belongie, “Integral Channel Features”, BMVC 2009.
DIPUM Toolbox:经典教材配套
项目地址:http://www.imageprocessingplace.com/DIPUM_Toolbox_2/DIPUM_Toolbox_2.htm
冈萨雷斯著名的图像处理教材《数字图像处理》的配套工具包,主要是书中图像处理算法的实现,名气自然是不必说了,网上可以免费下到加密后的p文件放在Matlab下面用,作为图像处理入门的上手玩具。

MATLAB Functions for Multiple View Geometry:又一个经典教材配套
项目网站:http://www.robots.ox.ac.uk/~vgg/hzbook/code/
许可证:MIT
又是一本大名鼎鼎的教材《计算机视觉中的多图几何》(Multiple View Geometry in Computer Vision),值得所有做三维视觉的研究者好好研究的书,国内很早就翻译了中文版。作者Zisserman提供了部分书中算法的Matlab实现,是深入理解书中理论的非常好的辅助材料。

其他的工具箱
- DIPImage & DIPLib,提供Matlab和C接口的图像处理功能,比较早,现在估计很少有人用或者知道了吧?
- Matlab CVPR toolbox,计算机视觉和模式识别相关的Matlab功能,好像没什么人用。
- 相关领域的工具箱,比如做机器学习的、做Markov随机场的等等,以后有机会写一下。
- 特定功能的工具箱,比如相机标定工具箱,这个可推荐的还阵挺多,以后有机会写一下。
- 这个链接里可以找到一些Matlab的开源工具箱。
转自 计算机视觉研究笔记
基于矩阵分解的推荐算法,简单入门
本文将要讨论基于矩阵分解的推荐算法,这一类型的算法通常会有很高的预测精度,也活跃于各大推荐系统竞赛上面,前段时间的百度电影推荐最终结果的前10名貌似都是把矩阵分解作为一个单模型,最后各种ensemble,不知道正在进行的阿里推荐比赛(http://102.alibaba.com/competition/addDiscovery/index.htm),会不会惊喜出现。。。。好了,闲话不扯了,本文打算写一篇该类型推荐算法的入门篇









1 /** 2 3 评分矩阵R如下 4 5 D1 D2 D3 D4 6 7 U1 5 3 - 1 8 9 U2 4 - - 1 10 11 U3 1 1 - 5 12 13 U4 1 - - 4 14 15 U5 - 1 5 4 16 17 ***/ 18 19 #include<iostream> 20 21 #include<cstdio> 22 23 #include<cstdlib> 24 25 #include<cmath> 26 27 using namespace std; 28 29 30 31 void matrix_factorization(double *R,double *P,double *Q,int N,int M,int K,int steps=5000,float alpha=0.0002,float beta=0.02) 32 33 { 34 35 for(int step =0;step<steps;++step) 36 37 { 38 39 for(int i=0;i<N;++i) 40 41 { 42 43 for(int j=0;j<M;++j) 44 45 { 46 47 if(R[i*M+j]>0) 48 49 { 50 51 //这里面的error 就是公式6里面的e(i,j) 52 53 double error = R[i*M+j]; 54 55 for(int k=0;k<K;++k) 56 57 error -= P[i*K+k]*Q[k*M+j]; 58 59 60 61 //更新公式6 62 63 for(int k=0;k<K;++k) 64 65 { 66 67 P[i*K+k] += alpha * (2 * error * Q[k*M+j] - beta * P[i*K+k]); 68 69 Q[k*M+j] += alpha * (2 * error * P[i*K+k] - beta * Q[k*M+j]); 70 71 } 72 73 } 74 75 } 76 77 } 78 79 double loss=0; 80 81 //计算每一次迭代后的,loss大小,也就是原来R矩阵里面每一个非缺失值跟预测值的平方损失 82 83 for(int i=0;i<N;++i) 84 85 { 86 87 for(int j=0;j<M;++j) 88 89 { 90 91 if(R[i*M+j]>0) 92 93 { 94 95 double error = 0; 96 97 for(int k=0;k<K;++k) 98 99 error += P[i*K+k]*Q[k*M+j];
100
101 loss += pow(R[i*M+j]-error,2);
102
103 for(int k=0;k<K;++k)
104
105 loss += (beta/2) * (pow(P[i*K+k],2) + pow(Q[k*M+j],2));
106
107 }
108
109 }
110
111 }
112
113 if(loss<0.001)
114
115 break;
116
117 if (step%1000==0)
118
119 cout<<"loss:"<<loss<<endl;
120
121 }
122
123 }
124
125
126
127 int main(int argc,char ** argv)
128
129 {
130
131 int N=5; //用户数
132
133 int M=4; //物品数
134
135 int K=2; //主题个数
136
137 double *R=new double[N*M];
138
139 double *P=new double[N*K];
140
141 double *Q=new double[M*K];
142
143 R[0]=5,R[1]=3,R[2]=0,R[3]=1,R[4]=4,R[5]=0,R[6]=0,R[7]=1,R[8]=1,R[9]=1;
144
145 R[10]=0,R[11]=5,R[12]=1,R[13]=0,R[14]=0,R[15]=4,R[16]=0,R[17]=1,R[18]=5,R[19]=4;
146
147
148
149 cout<< "R矩阵" << endl;
150
151 for(int i=0;i<N;++i)
152
153 {
154
155 for(int j=0;j<M;++j)
156
157 cout<< R[i*M+j]<<',';
158
159 cout<<endl;
160
161 }
162
163
164
165 //初始化P,Q矩阵,这里简化了,通常也可以对服从正态分布的数据进行随机数生成
166
167 srand(1);
168
169 for(int i=0;i<N;++i)
170
171 for(int j=0;j<K;++j)
172
173 P[i*K+j]=rand()%9;
174
175
176
177 for(int i=0;i<K;++i)
178
179 for(int j=0;j<M;++j)
180
181 Q[i*M+j]=rand()%9;
182
183 cout <<"矩阵分解 开始" << endl;
184
185 matrix_factorization(R,P,Q,N,M,K);
186
187 cout <<"矩阵分解 结束" << endl;
188
189
190
191 cout<< "重构出来的R矩阵" << endl;
192
193 for(int i=0;i<N;++i)
194
195 {
196
197 for(int j=0;j<M;++j)
198
199 {
200
201 double temp=0;
202
203 for (int k=0;k<K;++k)
204
205 temp+=P[i*K+k]*Q[k*M+j];
206
207 cout<<temp<<',';
208
209 }
210
211 cout<<endl;
212
213 }
214
215 free(P),free(Q),free(R);
216
217 return 0;
218
219 }
执行的结果如下图所示,



C++矩阵运算库推荐
最近在几个地方都看到有人问C++下用什么矩阵运算库比较好,顺便做了个调查,做一些相关的推荐吧。主要针对稠密矩阵,有时间会再写一个稀疏矩阵的推荐。
Armadillo:C++下的Matlab替代品
地址:http://arma.sourceforge.net/
许可证:MPL 2.0
目前使用比较广的C++矩阵运算库之一,是在C++下使用Matlab方式操作矩阵很好的选择,许多Matlab的矩阵操作函数都可以找到对应,这 对习惯了Matlab的人来说实在是非常方便,另外如果要将Matlab下做研究的代码改写成C++,使用Armadillo也会很方便,这里有一个简易的Matlab到Armadillo的语法转换。下面列了一些Armadillo的特性:
- 支持整数,浮点数,和复数矩阵。
- 支持矩阵逐元素操作,包括abs · conj · conv_to · eps · imag/real · misc functions (exp, log, pow, sqrt, round, sign, …) · trigonometric functions (cos, sin, …)等等。
- 支持矩阵分块操作。
- 支持对整体矩阵的操作diagvec · min/max · prod · sum · statistics (mean, stddev, …) · accu · as_scalar · det · dot/cdot/norm_dot · log_det · norm · rank · trace等等。
- Matlab用户,你甚至可以找到你熟悉的hist · histc · unique · cumsum · sort_index · find · repmat · linspace等函数。
- 除了自带的矩阵基本运算之外,可自动检测是否安装有BLAS,或更快的 OpenBLAS, Intel MKL, AMD ACML,并使用他们替代自带基本运算实现。
- 提供接口使用LAPACK进行矩阵分解运算,svd · qr · lu · fft等等。
- 提供了稀疏矩阵类,支持常用操作,但暂时没有矩阵分解的实现。
- 更新比较活跃,有一些计算机视觉、机器学习、物理方面的开源项目在使用,比如MLPACK (Machine Learning Library)。
总体来讲很好用的矩阵库,速度上因为可以使用OpenBLAS等库进行加速,因此还是不错的。网上可以找到一个叫Nghia Ho的人写的关于和eigen及opencv的速度比较做参考,速度略优。不过也由于依赖LAPACK等库完成矩阵分解计算,在windows上运行可能会比较痛苦。
Eigen3:强大且只需头文件

地址:http://eigen.tuxfamily.org/
许可证:主要为MPL 2.0,部分有来自第三方的代码为LGPL
非常强大的矩阵运算库,我一直在用,大家用了都说好。使用类似Matlab的方式操作矩阵,可以在这里查看官方的与Maltab的对应关系,个人感觉单纯讲和Matlab的对应的话,可能不如Armadillo对应的好,但功能绝对强大。Eigen包含了绝大部分你能用到的矩阵算法,同时提供许多第三方的接口。Eigen一个重要特点是没有什么依赖的库,本身仅有许多头文件组成,因此非常轻量而易于跨平台。你要做的就是把用到的头文件和你的代码放在一起就可以了。Eigen的一些特性:
- 支持整数、浮点数、复数,使用模板编程,可以为特殊的数据结构提供矩阵操作。比如在用ceres-solver进行做优化问题(比如bundle adjustment)的时候,有时候需要用模板编程写一个目标函数,ceres可以将模板自动替换为内部的一个可以自动求微分的特殊的double类型。而如果要在这个模板函数中进行矩阵计算,使用Eigen就会非常方便。
- 支持逐元素、分块、和整体的矩阵操作。
- 内含大量矩阵分解算法包括LU,LDLt,QR、SVD等等。
- 支持使用Intel MKL加速
- 部分功能支持多线程
- 稀疏矩阵支持良好,到今年新出的Eigen3.2,已经自带了SparseLU、SparseQR、共轭梯度 (ConjugateGradient solver)、bi conjugate gradient stabilized solver等解稀疏矩阵的功能。同时提供SPQR、UmfPack等外部稀疏矩阵库的接口。
- 支持常用几何运算,包括旋转矩阵、四元数、矩阵变换、AngleAxis(欧拉角与Rodrigues变换)等等。
- 更新活跃,用户众多(Google、WilliowGarage也在用),使用Eigen的比较著名的开源项目有ROS(机器人操作系统)、PCL(点云处理库)、Google Ceres(优化算法)。OpenCV自带到Eigen的接口。
总体来讲,如果经常做一些比较复杂的矩阵计算的话,或者想要跨平台的话,非常值得一用。
OpenCV:方便的计算机视觉计算库
![]()
地址:http://opencv.org/
许可证:目前是BSD
OpenCV在计算机视觉领域名气实在是太大了,而且最近几年库里的算法开始爆炸式的增长,最近貌似计划推出OpenCV 3了(参见这里)。有人开始抱怨OpenCV现在内容太杂了,不过这样的好处就是从是研究开发的话,一个库就可以得到大部分计算机视觉的流行算法,省去了很多麻烦。
OpenCV自带的矩阵计算功能算不上是专业的矩阵计算库,但是如果你用C++写机器学习、计算机视觉的程序,一定会经常用到。OpenCV的矩阵 计算功能还算比较完善,虽然速度略差劲,但用在大多数的开发和研究领域也是足够了。特别是OpenCV 2.2之后提供了类Matlab的矩阵C++接口,使得直接使用OpenCV进行矩阵计算变得简单易用。列两个比较值得一提的特点:
- 大量计算机视觉、机器学习相关的矩阵操作,非常方便。比如PCA、LDA、三维空间投影等等。
- 自带并行加速的矩阵计算功能。其中cv::gpu模块提供了CUDA支持的GPU矩阵计算功能,cv::ocl模块提供了OpenCL支持的并行矩阵计算功能。可以非常方便的进行并行矩阵计算,不过不足的是这两个模块还暂时缺少矩阵分解的实现。我曾见过朋友在做深度学习的时候用cv::ocl模块进行大矩阵乘法,貌似效果还不错。
ViennaCL:并行矩阵计算
![]()
网址:http://viennacl.sourceforge.net/
许可证:MIT
作者Karl Rupp来自维也纳大学,开发了一套Vienna*系列的开源软件,其中还包括ViennaMath(symbolic math符号计算)、ViennaFEM(有限元)等等。ViennaCL在后台支持OpenCL、OpenMP和CUDA,可以方便地使用各种型号的CPU或GPU进行并行计算。
- 目前矩阵类型支持float和double,1.4.2版尚不支持复数矩阵。
- 支持常用的矩阵运算和分解。
- 接口很有好,并提供接口到uBLAS、Eigen、MTL 4等矩阵库。
安装使用有非常详细的官方文档。
PETSc:大规模并行科学计算
网站:http://www.mcs.anl.gov/petsc/
许可证:Copyright University of Chicago (GPL compatible)
PETSc(Portable, Extensible Toolkit for Scientific Computation) 是美国能源部ODE2000支持开发的20多个ACTS工具箱之一,由Argonne国家实验室开发的可移植可扩展科学计算 工具箱,主要用于在分布式存储环境高效求解偏微分方程组及相关问题。PETSc所有消息传递通信均采用MPI标准实现。线性方程组求解器是PETSc的核 心组件之一,PETSc几乎提供了所有求解线性方程组的高效求解器,既有串行求解也有并行求解,既有直接法求解也有迭代法求解。对于大规模线性方程组, PETSc提供了大量基于Krylov子空间方法和各种预条件子的成熟而有效的迭代方法,以及其他通用程序和用户程序的接口。PETSc具有一般库软件所具备的高性能、可移植等优点,而且面向对象技术使得PETSc内部功能部件的使用非常方便,接口简单而又适用面广,可以缩短开发周期,减少工作量。[直接粘百度百科了]。
PETSc在网上可一找到很多英文资料,使用也比较广泛。不过在学校实验室的一般的科学计算可能接触的还比较少。推荐一个YouTube(可能要翻墙)的五集PETSc简单入门《PRACE Video Tutorial – PETSc Tutorial》。
其他的矩阵计算库和资料
在Stackexchange上有一个帖子《Recommendations for a usable, fast C++ matrix library?》里面搜罗了许多矩阵运算库。另外INRIA有人写了一个文档《Linear Algebra Libraries》,对常见的矩阵运算库进行了总结。除了上面提到的几个库之外,下面还有一些比较常用或坚持更新的矩阵库:
- uBLAS:Boost包中的BLAS库接口,据说速度一般。
- GSL:GNU Scientific Library自带的矩阵运算,据说速度一般。
- MTL 4:Matrix Template Library version 4,类似Eigen和Armadillo,有开源版本。
- Trilinos:和PETSc同是美国能源部ODE2000支持开发的20多个ACTS工具箱之一,用于大规模计算。
本文转载自:cvnote
2048-AI程序算法分析
针对目前火爆的2048游戏,有人实现了一个AI程序,可以以较大概率(高于90%)赢得游戏,并且作者在stackoverflow上简要介绍了AI的算法框架和实现思路。但是这个回答主要集中在启发函数的选取上,对AI用到的核心算法并没有仔细说明。这篇文章将主要分为两个部分,第一部分介绍其中用到的基础算法,即Minimax和Alpha-beta剪枝;第二部分分析作者具体的实现。

基础算法
2048本质上可以抽象成信息对称双人对弈模型(玩家向四个方向中的一个移动,然后计算机在某个空格中填入2或4)。这里“信息对称”是指在任一时 刻对弈双方对格局的信息完全一致,移动策略仅依赖对接下来格局的推理。作者使用的核心算法为对弈模型中常用的带Alpha-beta剪枝的 Minimax。这个算法也常被用于如国际象棋等信息对称对弈AI中。
Minimax
下面先介绍不带剪枝的Minimax。首先本文将通过一个简单的例子说明Minimax算法的思路和决策方式。
问题
现在考虑这样一个游戏:有三个盘子A、B和C,每个盘子分别放有三张纸币。A放的是1、20、50;B放的是5、10、100;C放的是1、5、20。单位均为“元”。有甲、乙两人,两人均对三个盘子和上面放置的纸币有可以任意查看。游戏分三步:
- 甲从三个盘子中选取一个。
- 乙从甲选取的盘子中拿出两张纸币交给甲。
- 甲从乙所给的两张纸币中选取一张,拿走。
其中甲的目标是最后拿到的纸币面值尽量大,乙的目标是让甲最后拿到的纸币面值尽量小。
下面用Minimax算法解决这个问题。
基本思路
一般解决博弈类问题的自然想法是将格局组织成一棵树,树的每一个节点表示一种格局,而父子关系表示由父格局经过一步可以到达子格局。Minimax 也不例外,它通过对以当前格局为根的格局树搜索来确定下一步的选择。而一切格局树搜索算法的核心都是对每个格局价值的评价。Minimax算法基于以下朴 素思想确定格局价值:
- Minimax是一种悲观算法,即假设对手每一步都会将我方引入从当前看理论上价值最小的格局方向,即对手具有完美决策能力。因此我方的策略应该是选择那些对方所能达到的让我方最差情况中最好的,也就是让对方在完美决策下所对我造成的损失最小。
- Minimax不找理论最优解,因为理论最优解往往依赖于对手是否足够愚蠢,Minimax中我方完全掌握主动,如果对方每一步决策都是完美的, 则我方可以达到预计的最小损失格局,如果对方没有走出完美决策,则我方可能达到比预计的最悲观情况更好的结局。总之我方就是要在最坏情况中选择最好的。
上面的表述有些抽象,下面看具体示例。
解题
下图是上述示例问题的格局树:

注意,由于示例问题格局数非常少,我们可以给出完整的格局树。这种情况下我可以找到Minimax算法的全局最优解。而真实情况中,格局树非常庞大,即使是计算机也不可能给出完整的树,因此我们往往只搜索一定深度,这时只能找到局部最优解。
我们从甲的角度考虑。其中正方形节点表示轮到我方(甲),而三角形表示轮到对方(乙)。经过三轮对弈后(我方-对方-我方),将进入终局。黄色叶结 点表示所有可能的结局。从甲方看,由于最终的收益可以通过纸币的面值评价,我们自然可以用结局中甲方拿到的纸币面值表示终格局的价值。
下面考虑倒数第二层节点,在这些节点上,轮到我方选择,所以我们应该引入可选择的最大价值格局,因此每个节点的价值为其子节点的最大值:

这些轮到我方的节点叫做max节点,max节点的值是其子节点最大值。
倒数第三层轮到对方选择,假设对方会尽力将局势引入让我方价值最小的格局,因此这些节点的价值取决于子节点的最小值。这些轮到对方的节点叫做min节点。
最后,根节点是max节点,因此价值取决于叶子节点的最大值。最终完整赋值的格局树如下:

总结一下Minimax算法的步骤:
- 首先确定最大搜索深度D,D可能达到终局,也可能是一个中间格局。
- 在最大深度为D的格局树叶子节点上,使用预定义的价值评价函数对叶子节点价值进行评价。
- 自底向上为非叶子节点赋值。其中max节点取子节点最大值,min节点取子节点最小值。
- 每次轮到我方时(此时必处在格局树的某个max节点),选择价值等于此max节点价值的那个子节点路径。
在上面的例子中,根节点的价值为20,表示如果对方每一步都完美决策,则我方按照上述算法可最终拿到20元,这是我方在Minimax算法下最好的决策。格局转换路径如下图红色路径所示:

对于真实问题中的Minimax,再次强调几点:
- 真实问题一般无法构造出完整的格局树,所以需要确定一个最大深度D,每次最多从当前格局向下计算D层。
- 因为上述原因,Minimax一般是寻找一个局部最优解而不是全局最优解,搜索深度越大越可能找到更好的解,但计算耗时会呈指数级膨胀。
- 也是因为无法一次构造出完整的格局树,所以真实问题中Minimax一般是边对弈边计算局部格局树,而不是只计算一次,但已计算的中间结果可以缓存。
Alpha-beta剪枝
简单的Minimax算法有一个很大的问题就是计算复杂性。由于所需搜索的节点数随最大深度呈指数膨胀,而算法的效果往往和深度相关,因此这极大限制了算法的效果。
Alpha-beta剪枝是对Minimax的补充和改进。采用Alpha-beta剪枝后,我们可不必构造和搜索最大深度D内的所有节点,在构造过程中,如果发现当前格局再往下不能找到更好的解,我们就停止在这个格局及以下的搜索,也就是剪枝。
Alpha-beta基于这样一种朴素的思想:时时刻刻记得当前已经知道的最好选择,如果从当前格局搜索下去,不可能找到比已知最优解更好的解,则停止这个格局分支的搜索(剪枝),回溯到父节点继续搜索。
Alpha-beta算法可以看成变种的Minimax,基本方法是从根节点开始采用深度优先的方式构造格局树,在构造每个节点时,都会读取此节点 的alpha和beta两个值,其中alpha表示搜索到当前节点时已知的最好选择的下界,而beta表示从这个节点往下搜索最坏结局的上界。由于我们假 设对手会将局势引入最坏结局之一,因此当beta小于alpha时,表示从此处开始不论最终结局是哪一个,其上限价值也要低于已知的最优解,也就是说已经 不可能此处向下找到更好的解,所以就会剪枝。
下面同样以上述示例介绍Alpha-beta剪枝算法的工作原理。我们从根节点开始,详述使用Alpha-beta的每一个步骤:
- 根节点的alpha和beta分别被初始化为−∞,和+∞。
- 深度优先搜索第一个孩子,不是叶子节点,所以alpha和beta继承自父节点,分别为−∞,和+∞
- 搜索第三层的第一个孩子,同上。
- 搜索第四层,到达叶子节点,采用评价函数得到此节点的评价值为1。

- 此叶节点的父节点为max节点,因此更新其alpha值为1,表示此节点取值的下界为1。
- 再看另外一个子节点,值为20,大于当前alpha值,因此将alpha值更新为20。
- 此时第三层最左节点所有子树搜索完毕,作为max节点,更新其真实值为当前alpha值:20。
- 由于其父节点(第二层最左节点)为min节点,因此更新其父节点beta值为20,表示这个节点取值最多为20。

- 搜索第二层最左节点的第二个孩子及其子树,按上述逻辑,得到值为50(注意第二层最左节点的beta值要传递给孩子)。由于50大于20,不更新min节点的beta值。

- 搜索第二层最左节点的第三个孩子。当看完第一个叶子节点后,发现第三个孩子的alpha=beta,此时表示这个节点下不会再有更好解,于是剪枝。

- 继续搜索B分支,当搜索完B分支的第一个孩子后,发现此时B分支的alpha为20,beta为10。这表示B分支节点的最大取值不会超过10, 而我们已 经在A分支取到20,此时满足alpha大于等于beta的剪枝条件,因此将B剪枝。并将B分支的节点值设为10,注意,这个10不一定是这个节点的真实 值,而只是上线,B节点的真实值可能是5,可能是1,可能是任何小于10的值。但是已经无所谓了,反正我们知道这个分支不会好过A分支,因此可以放弃了。

- 在C分支搜索时遇到了与B分支相同的情况。因此讲C分支剪枝。

此时搜索全部完毕,而我们也得到了这一步的策略:应该走A分支。
可以看到相比普通Minimax要搜索18个叶子节点相比,这里只搜索了9个。采用Alpha-beta剪枝,可以在相同时间内加大Minimax的搜索深度,因此可以获得更好的效果。并且Alpha-beta的解和普通Minimax的解是一致的。
针对2048游戏的实现
下面看一下ov3y同学针对2048实现的AI。程序的GitHub在这里,主要程序都在ai.js中。
建模
上面说过Minimax和Alpha-beta都是针对信息对称的轮流对弈问题,这里作者是这样抽象游戏的:
- 我方:游戏玩家。每次可以选择上、下、左、右四个行棋策略中的一种(某些格局会少于四种,因为有些方向不可走)。行棋后方块按照既定逻辑移动及合并,格局转换完成。
- 对方:计算机。在当前任意空格子里放置一个方块,方块的数值可以是2或4。放置新方块后,格局转换完成。
- 胜利条件:出现某个方块的数值为“2048”。
- 失败条件:格子全满,且无法向四个方向中任何一个方向移动(均不能触发合并)。
如此2048游戏就被建模成一个信息对称的双人对弈问题。
格局评价
作为算法的核心,如何评价当前格局的价值是重中之重。在2048中,除了终局外,中间格局并无非常明显的价值评价指标,因此需要用一些启发式的指标来评价格局。那些分数高的“好”格局是容易引向胜利的格局,而分低的“坏”格局是容易引向失败的格局。
作者采用了如下几个启发式指标。
单调性
单调性指方块从左到右、从上到下均遵从递增或递减。一般来说,越单调的格局越好。下面是一个具有良好单调格局的例子:

平滑性
平滑性是指每个方块与其直接相邻方块数值的差,其中差越小越平滑。例如2旁边是4就比2旁边是128平滑。一般认为越平滑的格局越好。下面是一个具有极端平滑性的例子:

空格数
这个很好理解,因为一般来说,空格子越少对玩家越不利。所以我们认为空格越多的格局越好。
孤立空格数
这个指标评价空格被分开的程度,空格越分散则格局越差。
具体来说,2048-AI在评价格局时,对这些启发指标采用了加权策略。具体代码如下:
// static evaluation function
AI.prototype.eval = function() {
var emptyCells = this.grid.availableCells().length;
var smoothWeight = 0.1,
//monoWeight = 0.0,
//islandWeight = 0.0,
mono2Weight = 1.0,
emptyWeight = 2.7,
maxWeight = 1.0;
return this.grid.smoothness() * smoothWeight
//+ this.grid.monotonicity() * monoWeight
//- this.grid.islands() * islandWeight
+ this.grid.monotonicity2() * mono2Weight
+ Math.log(emptyCells) * emptyWeight
+ this.grid.maxValue() * maxWeight;
};
|
有兴趣的同学可以调整一下权重看看有什么效果。
对对方选择的剪枝
在这个程序中,除了采用Alpha-beta剪枝外,在min节点还采用了另一种剪枝,即只考虑对方走出让格局最差的那一步(而实际2048中计算 机的选择是随机的),而不是搜索全部对方可能的走法。这是因为对方所有可能的选择为“空格数×2”,如果全部搜索的话会严重限制搜索深度。
相关剪枝代码如下:
// try a 2 and 4 in each cell and measure how annoying it is
// with metrics from eval
var candidates = [];
var cells = this.grid.availableCells();
var scores = { 2: [], 4: [] };
for (var value in scores) {
for (var i in cells) {
scores[value].push(null);
var cell = cells[i];
var tile = new Tile(cell, parseInt(value, 10));
this.grid.insertTile(tile);
scores[value][i] = -this.grid.smoothness() + this.grid.islands();
this.grid.removeTile(cell);
}
}
// now just pick out the most annoying moves
var maxScore = Math.max(Math.max.apply(null, scores[2]), Math.max.apply(null, scores[4]));
for (var value in scores) { // 2 and 4
for (var i=0; i<scores[value].length; i++) {
if (scores[value][i] == maxScore) {
candidates.push( { position: cells[i], value: parseInt(value, 10) } );
}
}
}
|
搜索深度
在2048-AI的实现中,并没有限制搜索的最大深度,而是限制每次“思考”的时间。这里设定了一个超时时间,默认为100ms,在这个时间内,会从1开始,搜索到所能达到的深度。相关代码:
// performs iterative deepening over the alpha-beta search
AI.prototype.iterativeDeep = function() {
var start = (new Date()).getTime();
var depth = 0;
var best;
do {
var newBest = this.search(depth, -10000, 10000, 0 ,0);
if (newBest.move == -1) {
//console.log('BREAKING EARLY');
break;
} else {
best = newBest;
}
depth++;
} while ( (new Date()).getTime() - start < minSearchTime);
//console.log('depth', --depth);
//console.log(this.translate(best.move));
//console.log(best);
return best
}
|
因此这个算法实现的效果实际上依赖于执行javascript引擎机器的性能。当然可以通过增加超时时间来达到更好的效果,但此时每一步行走速度会相应变慢。
算法的改进
目前这个实现作者声称成功合成2048的概率超过90%,但是合成4096甚至8192的概率并不高。作者在github项目的REAMDE中同时给出了一些优化建议,这些建议包括:
- 缓存结果。目前这个实现并没有对已搜索的树做缓存,每一步都要重新开始搜索。
- 多线程搜索。由于javascript引擎的单线程特性,这一点很难做到,但如果在其它平台上也许也可考虑并行技术。
- 更好的启发函数。也许可以总结出一些更好的启发函数来评价格局价值。
参考文献
- 2048 Game
- 2048-AI github
- An Exhaustive Explanation of Minimax, a Staple AI Algorithm
- Tic Tac Toe: Understanding the Minimax Algorithm
- CS 161 Recitation Notes – Minimax with Alpha Beta Pruning
原文: 张洋(@敲代码的张洋)
机器学习自学指南
事实上有许多的途径可以了解机器学习,也有许多的资源例如书籍、公开课等可为所用,一些相关的比赛和工具也是你了解这个领域的好帮手。本文我将围绕这个话题,给出一些总结性的认识,并为你由程序员到机器学习高手的蜕变旅程中提供一些学习指引。
机器学习的四个层次
根据能力可以将学习过程分成四个阶段。这也是一个有助于我们将所有学习资源进行分类的好方法。
- 初学阶段
- 新手阶段
- 中级阶段
- 高级阶段
我之所以把初学阶段和新手阶段区分开来,是因为我想让那些完全初学者(对这个领域感兴趣的程序员)在初学阶段对机器学习有一个大致的认识,以便决定是否继续深入。
我们将分别探讨这四个阶段,并推荐一些能够帮助我们更好地理解机器学习和提高相关技能的资源。对学习阶段进行这样的分类只是我个人的建议,也许每个分类的前后阶段中也有一些适合当前阶段的资源。
我认为对机器学习有一个整体性的认识是非常有帮助的,我也希望能听听你们的想法,通过在下面评论告诉我吧!

初学阶段
初学者是指那些对机器学习感兴趣的程序员。他们或许已经接触过一些相关的书籍、wiki网页,或者是已经上过几节机器学习课程,但是他们并没有真正地了解机器学习。他们在学习过程感到沮丧是因为他们得到的建议往往是针对中级或高级阶段的。
初学者需要的是一个感性的认识而不是纯粹的代码、教科书、课程。他们首先需要对机器学习有一个是什么、为什么、怎么做的认识以此为接下来的阶段学习奠定基础。
- 入门书籍:阅读一些为程序员而写的数据挖掘与机器学习的入门书籍,例如《机器学习:实用案例解析 》、《集体智慧编程》、《数据挖掘:实用机器学习工具和技术》,这些都是很好的入门书籍,推荐一篇进一步讨论这个话题的文章:《机器学习的最佳入门学习资源》
- 相关概述视频:也可以看一些科普性质的机器学习演讲。例如: 《采访Tom Mitchel》、《Peter Norvig 在Facebook的大数据演讲》
- 与人交谈:与机器学习领域的老手交流,问问他们是如何入门的,有什么资源值得推荐,是什么让他们对机器学习如此狂热。
- 机器学习课程101:我总结了一些关于入门的观点,《为初学者准备的机器学习课程101》,如果你喜欢可以看一看。
新手阶段
新手是指那些已经对机器学习有一定了解的人,他们已经阅读过一些专业书籍或者是接受过完整地课程学习,并且对这个东西有很大的兴趣想做更深入的了解,想通过进一步学习去解决他们所面临的问题。
下面是给新手的一些资料或者建议:
- 完成一门课程:完整地学习一门机器学习的课程,例如斯坦福大学的机器学习课程。多做课程笔记,尽可能地完成课程作业,多问问题。
- 阅读一些书籍:这里指的不是教科书,而是为上面所列举的为程序员初学者所准备的书籍。
- 掌握一门工具:学会使用一门分析工具或者类库,例如python的机器学习包Scikit-Learn、java的机器学习包WEKA、R语言或者其他类似的。具体地说,学习如何使用你在课程或书本上学来的算法,看看它们处理问题的实际效果。
- 写一写代码:动手实现一些简单的算法,例如感知机、K近邻、线性回归。试图写一些小程序去阐述你对这些算法的理解。
- 学习相关教程:完整地跟一门教程,为你所完成的小项目建立一个文件夹,其中包含数据集、脚本代码等,以便你可以随时回顾并有所收获。
中级阶段
在新手阶段已经阅读过一些专业书籍并完成了一些专业课程,这些人已经懂得如何使用机器学习相关的工具,并且也已经为实现机器学习算法和完成一些教程 写过不少的代码了。中级阶段其实是一个自我突破的过程,可以通过建立自己的项目去探索新的技巧并在社区的交流互动中获取更多的知识。
中级阶段的目标是学习如何实现并使用准确、合适、健壮机器学习算法。同样,他们也在数据预处理、数据清洗、归纳总结上花了不少时间,并思考这些数据能解决什么问题。
下面是给中级学习者的一些资料或者建议:
- 建立自己的小项目:自己设计小型的编程项目或者是应用机器学习算法解决问题的小实验。这就像是为探索你自己所感兴趣的技术而设计一些教程。你可以自己实现一个算法或者是提供一些实现这些算法类库的链接。
- 数据分析:习惯于从数据集中探索并总结。知道什么时候该用什么工具,获取用于探索、学习相关技术的数据。
- 阅读教科书:阅读并消化机器学习相关的教科书。这可能对理解用数学方式描述相关技术的能力有一定的要求,并且需要了解用公式的方式去对描述问题和算法。
- 编写你自己的工具:为开源的机器学习平台或类库编写插件和相关的程序包。这是学习如何实现健壮的、能用于生产环境下的算法的一个很好的锻炼机会。 将你的程序包运用到项目中,将代码提交给社区进行代码审核,如果可能的话,努力将你的程序发布到开源的平台上,从大家的反馈中进一步学习。
- 竞赛:参加与机器学习有关的比赛,比如与机器学习会议有关的,或者是提供像Kaggle这样的平台的比赛。参与讨论、提问题,学习其他参赛者是如何解决问题的。将这些项目、方法和代码添加到你的项目库中。
高级阶段
机器学习的高级玩家是那些已经整理过大量机器学习算法或者是自己独立实现算法的人。他们或许参加过机器学习的竞赛又或许写过机器学习的程序包。他们已经阅读过许多书籍、学习过许多相关课程,对这一领域有较充分的认识,同时对自己研究的几个关键技术有很深入的了解。
这些高级使用者平时负责生产环境下的机器学习系统的建立、部署和维护。他们能时刻紧跟这个行业的最新动态,通过自己或他人的一线开发经验发现并了解每一种机器学习技术的细微差距。
下面是给高级阶段学习者的一些资料:
- 定制开发算法:根据业务需求定制开发算法,实现会议、期刊论文中关于某个相似问题的算法。
- 自己设计算法:设计全新的算法去解决工作中 遇到的问题,这样做的目的更多的是为工作中所面临的困难找到最佳的解决方案,而不是进行该领域的前沿研究。
- 案例学习:阅读甚至是重新设计机器学习竞赛或者是其他参赛者所提供的实际案例。这些一直在谈“我是如何做到”的论文或文章中总是塞满了关于数据准备、工程实践以及使用技术的微妙技巧。
- 方法论:总结处理问题的过程并系统化,可以正式地分享出来也可以仅仅是作为个人总结。他们总有一套自己解决问题的思路并且不断地提炼和改进处理过程,试图用更好的技术来或得最佳实践。
- 学术研究:参加学术会议,阅读研究论文和学术专著,与机器学习领域的专家交流学习。他们会记录工作中所积累的经验发布到相关的期刊或者自己博客上,然后回到工作岗位继续研究。
知识在不断地收获,但学习永无止境。在机器学习的征途中遇到问题时你可以随时停住脚步自己钻研问题自行解决,或者绕道而行查阅资料借用群体智慧,事实上,我希望绕道而行成为一种常态。
这样的学习阶段划分是以程序员的角度来规划的,这可以作为技术人员实现从入门到精通的一条线性学习路线。我很乐意收到对于这篇文章的批评建议,这样可以使文章变得更好。在特定的学习阶段你可以得到更多的学习资源,因为针对每个阶段所推荐的学习资源也仅仅是我个人的建议。
好了,现在想想你在哪个学习阶段呢?接下来你该怎么做?
原文链接: Machine Learning Mastery 翻译: 伯乐在线 - zhibinzeng
译文链接: http://blog.jobbole.com/58937/
SIFT特征提取分析
SIFT(Scale-invariant feature transform)是一种检测局部特征的算法,该算法通过求一幅图中的特征点(interest points,or corner points)及其有关scale 和 orientation 的描述子得到特征并进行图像特征点匹配,获得了良好效果,详细解析如下:
算法描述
SIFT特征不只具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果。整个算法分为以下几个部分:
1. 构建尺度空间
这是一个初始化操作,尺度空间理论目的是模拟图像数据的多尺度特征。
高斯卷积核是实现尺度变换的唯一线性核,于是一副二维图像的尺度空间定义为:

其中 G(x,y,σ) 是尺度可变高斯函数 
(x,y)是空间坐标,是尺度坐标。σ大小决定图像的平滑程度,大尺度对应图像的概貌特征,小尺度对应图像的细节特征。大的σ值对应粗糙尺度(低分辨率),反之,对应精细尺度(高分辨率)。为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。

下图所示不同σ下图像尺度空间:

关于尺度空间的理解说明:2kσ中的2是必须的,尺度空间是连续的。在 Lowe的论文中 ,将第0层的初始尺度定为1.6(最模糊),图片的初始尺度定为0.5(最清晰). 在检测极值点前对原始图像的高斯平滑以致图像丢失高频信息,所以 Lowe 建议在建立尺度空间前首先对原始图像长宽扩展一倍,以保留原始图像信息,增加特征点数量。尺度越大图像越模糊。
图像金字塔的建立:对于一幅图像I,建立其在不同尺度(scale)的图像,也成为子八度(octave),这是为了scale-invariant,也就是在任何尺度都能够有对应的特征点,第一个子八度的scale为原图大小,后面每个octave为上一个octave降采样的结果,即原图的1/4(长宽分别减半),构成下一个子八度(高一层金字塔)。


尺度空间的所有取值,i为octave的塔数(第几个塔),s为每塔层数
由图片size决定建几个塔,每塔几层图像(S一般为3-5层)。0塔的第0层是原始图像(或你double后的图像),往上每一层是对其下一层进行Laplacian变换(高斯卷积,其中σ值渐大,例如可以是σ, k*σ, k*k*σ…),直观上看来越往上图片越模糊。塔间的图片是降采样关系,例如1塔的第0层可以由0塔的第3层down sample得到,然后进行与0塔类似的高斯卷积操作。
2. LoG近似DoG找到关键点<检测DOG尺度空间极值点>
为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。 一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点,如图所示。

同一组中的相邻尺度(由于k的取值关系,肯定是上下层)之间进行寻找

s=3的情况
使用Laplacian of Gaussian能够很好地找到找到图像中的兴趣点,但是需要大量的计算量,所以使用Difference of Gaussian图像的极大极小值近似寻找特征点.DOG算子计算简单,是尺度归一化的LoG算子的近似,有关DOG寻找特征点的介绍及方法详见http://blog.csdn.net/abcjennifer/article/details/7639488,极值点检测用的Non-Maximal Suppression。
3. 除去不好的特征点
这一步本质上要去掉DoG局部曲率非常不对称的像素。
通过拟和三维二次函数以精确确定关键点的位置和尺度(达到亚像素精度),同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力,在这里使用近似Harris Corner检测器。
①空间尺度函数泰勒展开式如下: ,对上式求导,并令其为0,得到精确的位置, 得
,对上式求导,并令其为0,得到精确的位置, 得
②在已经检测到的特征点中,要去掉低对比度的特征点和不稳定的边缘响应点。去除低对比度的点:把公式(2)代入公式(1),即在DoG Space的极值点处D(x)取值,只取前两项可得:

若  ,该特征点就保留下来,否则丢弃。
,该特征点就保留下来,否则丢弃。
③边缘响应的去除
一个定义不好的高斯差分算子的极值在横跨边缘的地方有较大的主曲率,而在垂直边缘的方向有较小的主曲率。主曲率通过一个2×2 的Hessian矩阵H求出:

导数由采样点相邻差估计得到。
D的主曲率和H的特征值成正比,令α为较大特征值,β为较小的特征值,则

令α=γβ,则

(r + 1)2/r的值在两个特征值相等的时候最小,随着r的增大而增大,因此,为了检测主曲率是否在某域值r下,只需检测

if (α+β)/ αβ> (r+1)2/r, throw it out. 在Lowe的文章中,取r=10。
4. 给特征点赋值一个128维方向参数
上一步中确定了每幅图中的特征点,为每个特征点计算一个方向,依照这个方向做进一步的计算, 利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性。

为(x,y)处梯度的模值和方向公式。其中L所用的尺度为每个关键点各自所在的尺度。至此,图像的关键点已经检测完毕,每个关键点有三个信息:位置,所处尺度、方向,由此可以确定一个SIFT特征区域。
在实际计算时,我们在以关键点为中心的邻域窗口内采样,并用直方图统计邻域像素的梯度方向。梯度直方图的范围是0~360度,其中每45度一个柱,总共8个柱, 或者每10度一个柱,总共36个柱。Lowe论文中还提到要使用高斯函数对直方图进行平滑,减少突变的影响。直方图的峰值则代表了该关键点处邻域梯度的主方向,即作为该关键点的方向。

直方图中的峰值就是主方向,其他的达到最大值80%的方向可作为辅助方向

由梯度方向直方图确定主梯度方向
该步中将建立所有scale中特征点的描述子(128维)

关键点描述子的生成步骤

5. 关键点描述子的生成
首先将坐标轴旋转为关键点的方向,以确保旋转不变性。以关键点为中心取8×8的窗口。

Figure.16*16的图中其中1/4的特征点梯度方向及scale,右图为其加权到8个主方向后的效果。
图左部分的中央为当前关键点的位置,每个小格代表关键点邻域所在尺度空间的一个像素,利用公式求得每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,箭头长度代表梯度模值,然后用高斯窗口对其进行加权运算。
图中蓝色的圈代表高斯加权的范围(越靠近关键点的像素梯度方向信息贡献越大)。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点,如图右部分示。此图中一个关键点由2×2共4个种子点组成,每个种子点有8个方向向量信息。这种邻域方向性信息联合的思想增强了算法抗噪声的能力,同时对于含有定位误差的特征匹配也提供了较好的容错性。

在每个4*4的1/16象限中,通过加权梯度值加到直方图8个方向区间中的一个,计算出一个梯度方向直方图。
这样就可以对每个feature形成一个4*4*8=128维的描述子,每一维都可以表示4*4个格子中一个的scale/orientation. 将这个向量归一化之后,就进一步去除了光照的影响。
5. 根据SIFT进行Match
生成了A、B两幅图的描述子,(分别是k1*128维和k2*128维),就将两图中各个scale(所有scale)的描述子进行匹配,匹配上128维即可表示两个特征点match上了。
实际计算过程中,为了增强匹配的稳健性,Lowe建议对每个关键点使用4×4共16个种子点来描述,这样对于一个关键点就可以产生128个数据,即最终形成128维的SIFT特征向量。此时SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则可以进一步去除光照变化的影响。 当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,Lowe提出了比较最近邻距离与次近邻距离的方法,距离比率ratio小于某个阈值的认为是正确匹配。因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。Lowe推荐ratio的阈值为0.8。但作者对大量任意存在尺度、旋转和亮度变化的两幅图片进行匹配,结果表明ratio取值在0. 4~0. 6之间最佳,小于0. 4的很少有匹配点,大于0. 6的则存在大量错误匹配点。(如果这个地方你要改进,最好给出一个匹配率和ration之间的关系图,这样才有说服力)作者建议ratio的取值原则如下:
ratio=0. 4 对于准确度要求高的匹配;
ratio=0. 6 对于匹配点数目要求比较多的匹配;
ratio=0. 5 一般情况下。
也可按如下原则:当最近邻距离<200时ratio=0. 6,反之ratio=0. 4。ratio的取值策略能排分错误匹配点。
当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。
实验结果:



Python+opencv实现:

- import cv2
- import numpy as np
- #import pdb
- #pdb.set_trace()#turn on the pdb prompt
- #read image
- img = cv2.imread(‘D:\privacy\picture\little girl.jpg’,cv2.IMREAD_COLOR)
- gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- cv2.imshow(‘origin’,img);
- #SIFT
- detector = cv2.SIFT()
- keypoints = detector.detect(gray,None)
- img = cv2.drawKeypoints(gray,keypoints)
- #img = cv2.drawKeypoints(gray,keypoints,flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
- cv2.imshow(‘test’,img);
- cv2.waitKey(0)
- cv2.destroyAllWindows()
C实现:
- // FeatureDetector.cpp : Defines the entry point for the console application.
- //
- // Created by Rachel on 14-1-12.
- // Copyright (c) 2013年 ZJU. All rights reserved.
- //
- #include “stdafx.h”
- #include “highgui.h”
- #include “cv.h”
- #include “vector”
- #include “opencv\cxcore.hpp”
- #include “iostream”
- #include “opencv.hpp”
- #include “nonfree.hpp”
- #include “showhelper.h”
- using namespace cv;
- using namespace std;
- int _tmain(int argc, _TCHAR* argv[])
- {
- //Load Image
- Mat c_src1 = imread( “..\\Images\\3.jpg”);
- Mat c_src2 = imread(“..\\Images\\4.jpg”);
- Mat src1 = imread( “..\\Images\\3.jpg”, CV_LOAD_IMAGE_GRAYSCALE);
- Mat src2 = imread( “..\\Images\\4.jpg”, CV_LOAD_IMAGE_GRAYSCALE);
- if( !src1.data || !src2.data )
- { std::cout<< ” –(!) Error reading images ” << std::endl; return -1; }
- //sift feature detect
- SiftFeatureDetector detector;
- std::vector<KeyPoint> kp1, kp2;
- detector.detect( src1, kp1 );
- detector.detect( src2, kp2 );
- SiftDescriptorExtractor extractor;
- Mat des1,des2;//descriptor
- extractor.compute(src1,kp1,des1);
- extractor.compute(src2,kp2,des2);
- Mat res1,res2;
- int drawmode = DrawMatchesFlags::DRAW_RICH_KEYPOINTS;
- drawKeypoints(c_src1,kp1,res1,Scalar::all(-1),drawmode);//在内存中画出特征点
- drawKeypoints(c_src2,kp2,res2,Scalar::all(-1),drawmode);
- cout<<“size of description of Img1: “<<kp1.size()<<endl;
- cout<<“size of description of Img2: “<<kp2.size()<<endl;
- //write the size of features on picture
- CvFont font;
- double hScale=1;
- double vScale=1;
- int lineWidth=2;// 相当于写字的线条
- cvInitFont(&font,CV_FONT_HERSHEY_SIMPLEX|CV_FONT_ITALIC, hScale,vScale,0,lineWidth);//初始化字体,准备写到图片上的
- // cvPoint 为起笔的x,y坐标
- IplImage* transimg1 = cvCloneImage(&(IplImage) res1);
- IplImage* transimg2 = cvCloneImage(&(IplImage) res2);
- char str1[20],str2[20];
- sprintf(str1,”%d”,kp1.size());
- sprintf(str2,”%d”,kp2.size());
- const char* str = str1;
- cvPutText(transimg1,str1,cvPoint(280,230),&font,CV_RGB(255,0,0));//在图片中输出字符
- str = str2;
- cvPutText(transimg2,str2,cvPoint(280,230),&font,CV_RGB(255,0,0));//在图片中输出字符
- //imshow(“Description 1″,res1);
- cvShowImage(“descriptor1″,transimg1);
- cvShowImage(“descriptor2″,transimg2);
- BFMatcher matcher(NORM_L2);
- vector<DMatch> matches;
- matcher.match(des1,des2,matches);
- Mat img_match;
- drawMatches(src1,kp1,src2,kp2,matches,img_match);//,Scalar::all(-1),Scalar::all(-1),vector<char>(),drawmode);
- cout<<“number of matched points: “<<matches.size()<<endl;
- imshow(“matches”,img_match);
- cvWaitKey();
- cvDestroyAllWindows();
- return 0;
- }
===============================
辅助资料:





===============================
Reference:
Lowe SIFT 原文:http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
SIFT 的C实现:https://github.com/robwhess/opensift/blob/master/src
MATLAB 应用Sift算子的模式识别方法:http://blog.csdn.net/abcjennifer/article/details/7372880
http://blog.csdn.net/abcjennifer/article/details/7365882
http://en.wikipedia.org/wiki/Scale-invariant_feature_transform#David_Lowe.27s_method
http://blog.sciencenet.cn/blog-613779-475881.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080950.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080951.html
http://blog.csdn.net/ijuliet/article/details/4640624
http://www.cnblogs.com/cfantaisie/archive/2011/06/14/2080917.html (部分图片有误,以本文中的图片为准)
马氏距离简介
马氏距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为(x-μ)’Σ^(-1)(x-μ)。
Definition
Formally, the Mahalanobis distance of a multivariate vector  from a group of values with mean
from a group of values with mean  and covariance matrix
and covariance matrix  is defined as:
is defined as:

Mahalanobis distance (or “generalized squared interpoint distance” for its squared value) can also be defined as a dissimilarity measure between two random vectors  and
and  of the same distribution with the covariance matrix :
of the same distribution with the covariance matrix :
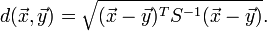
If the covariance matrix is the identity matrix, the Mahalanobis distance reduces to the Euclidean distance. If the covariance matrix is diagonal, then the resulting distance measure is called the normalized Euclidean distance:

where  is the standard deviation of the
is the standard deviation of the  (
(  ) over the sample set.
) over the sample set.
马氏优缺点:
七篇重要的数据科学论文
7 Important Data Science Papers
It is back-to-school time, and here are some papers to keep you busy this school year. All the papers are free. This list is far from exhaustive, but these are some important papers in data science and big data.
Google Search
- PageRank – This is the paper that explains the algorithm behind Google search.
Hadoop
- MapReduce – This paper explains a programming model for processing large datasets. In particular, it is the programming model used in hadoop.
- Google File System – Part of hadoop is HDFS. HDFS is an open-source version of the distributed file system explained in this paper.
NoSQL
These are 2 of the papers that drove/started the NoSQL debate. Each paper describes a different type of storage system intended to be massively scabable.
- Amazon Dynamo
- Google Bigtable
Machine Learning
- 10 algorithms in data mining | pdf download – This paper covers a number (10 to be exact) of important machine learning algorithms.
- A Few Useful Things to Know about Machine Learning – This paper is filled with tips, tricks, and insights to make machine learning more successful.
Bonus Paper
- Random Forests – One of the most popular machine learning techniques. It is heavily used in Kaggle competitions, even by the winners.
本文转载自:datascience101
互联网推荐系统漫谈

[核心提示] 读项亮的《推荐系统实践》后总结所得:算法虽然不能解决全部问题,但算法可以变得更人性化。网络就是社会,其实算法和人之间早已不那么泾渭分明了。
推荐系统这个东西其实在我们的生活中无处不在,比如我早上买包子的时候,老板就经常问我要不要来杯豆浆,这就是一种简单的推荐。随着互联网的发展,把线下的这种模式搬到线上成了大势所趋,它大大扩展了推荐系统的应用:亚马逊的商品推荐,Facebook的好友推荐,Digg的文章推荐,豆瓣的豆瓣猜,Last.fm和豆瓣FM的音乐推荐,Gmail里的广告……在如今互联网信息过载的情况下,信息消费者想方便地找到自己感兴趣的内容,信息生产者则想将自己的内容推送到最合适的目标用户那儿。而推荐系统正是要充当这两者的中介,一箭双雕解决这两个难题。
推荐系统的评判标准
首先我们得明确什么是好的推荐系统。可以通过如下几个标准来判定。
- 用户满意度 描述用户对推荐结果的满意程度,这是推荐系统最重要的指标。一般通过对用户进行问卷或者监测用户线上行为数据获得。
- 预测准确度 描述推荐系统预测用户行为的能力。一般通过离线数据集上算法给出的推荐列表和用户行为的重合率来计算。重合率越大则准确率越高。
- 覆盖率 描述推荐系统对物品长尾的发掘能力。一般通过所有推荐物品占总物品的比例和所有物品被推荐的概率分布来计算。比例越大,概率分布越均匀则覆盖率越大。
- 多样性 描述推荐系统中推荐结果能否覆盖用户不同的兴趣领域。一般通过推荐列表中物品两两之间不相似性来计算,物品之间越不相似则多样性越好。
- 新颖性 如果用户没有听说过推荐列表中的大部分物品,则说明该推荐系统的新颖性较好。可以通过推荐结果的平均流行度和对用户进行问卷来获得。
- 惊喜度 如果推荐结果和用户的历史兴趣不相似,但让用户很满意,则可以说这是一个让用户惊喜的推荐。可以定性地通过推荐结果与用户历史兴趣的相似度和用户满意度来衡量。
简而言之,一个好的推荐系统就是在推荐准确的基础上,给所有用户推荐的物品尽量广泛(挖掘长尾),给单个用户推荐的物品尽量覆盖多个类别,同时不要给用户推荐太多热门物品,最牛逼的则是能让用户看到推荐后有种「相见恨晚」的感觉。
推荐系统的分类
推荐系统是建立在大量有效数据之上的,背后的算法思想有很多种,要大体分类的话可以从处理的数据入手。
1.利用用户行为数据
互联网上的用户行为千千万万,从简单的网页浏览到复杂的评价,下单……这其中蕴含了大量的用户反馈信息,通过对这些行为的分析,我们便能推知用户的兴趣喜好。而这其中最基础的就是「协同过滤算法」。
「协同过滤算法」也分两种,基于用户(UserCF)和基于物品(ItemCF)。所谓基于用户,就是跟据用户对物品的行为,找出兴趣爱好相似的一些用户,将其中一个用户喜欢的东西推荐给另一个用户。举个例子,老张喜欢看的书有A,B,C,D;老王喜欢看的书有A,B,C,E。通过这些数据我们可以判断老张和老王的口味略相似,于是给老张推荐E这本书,同时给老王推荐D这本书。对应的,基于物品就是先找出相似的物品。怎么找呢?也是看用户的喜好,如果同时喜欢两个物品的人比较多的话,就可以认为这两个物品相似。最后就只要给用户推荐和他原有喜好类似的物品就成。举例来说,我们发现喜欢看《从一到无穷大》的人大都喜欢看《什么是数学》,那如果你刚津津有味地看完《从一到无穷大》,我们就可以立马给你推荐《什么是数学》。
至于什么时候用UserCF,什么时候用ItemCF,这都要视情况而定。一般来说,UserCF更接近于社会化推荐,适用于用户少,物品多,时效性较强的场合,比如Digg的文章推荐;而ItemCF则更接近个性化推荐,适用于用户多,物品少的场合,比如豆瓣的豆瓣猜、豆瓣FM,同时ItemCF还可以给出靠谱的推荐理由,例如豆瓣的「喜欢OO的人也喜欢XX」和亚马逊的「买了XX的人也买了OO」。

协同过滤算法也有不少缺点,最明显的一个就是热门物品的干扰。举个例子,协同过滤算法经常会导致两个不同领域的最热门物品之间具有较高的相似度,这样很可能会给喜欢《算法导论》的同学推荐《哈利波特》,显然,这不科学!要避免这种情况就得从物品的内容数据入手了,后文提到的内容过滤算法就是其中一种。
除了协同过滤算法,还有隐语义模型(LFM)应用得也比较多,它基于用户行为对物品进行自动聚类,从而将物品按照多个维度,多个粒度分门别类。然后根据用户喜欢的物品类别进行推荐。这种基于机器学习的方法在很多指标上优于协同过滤,但性能上不太给力,一般可以先通过其他算法得出推荐列表,再由LFM进行优化。
2.利用用户标签数据
我们知道很多网站在处理物品条目的时候会通过用户自己标注的标签来进行分类,比如网页书签Delicious,博客的标签云,豆瓣书影音的标签。这些标签本身就是用户对物品的一种聚类,以此作为推荐系统的依据还是很有效的。
关于标签的推荐,一种是根据用户打标签的行为为其推荐物品,还有一种是在用户给物品打标签的时候为其推荐合适的标签。
根据标签推荐物品的基本思想就是找到用户常用的一些标签,然后找到具有这些标签的热门物品,将其推荐给用户。这里要注意两个问题,一个是要保证新颖性和多样性,可以用TF-IDF方法来降低热门物品的权重;另一个则是需要清除某些同义重复标签和没有意义的标签。
在用户打标签时为其推荐标签也是相当重要的,一方面能方便用户输入标签,一方面能提高标签质量,减少冗余。典型的应用场景就是用豆瓣标记书影音。这里的思想就是将当前物品上最热门的标签和用户自己最常用的标签综合在一起推荐给用户。其实豆瓣就是这么做的,它在用户标记物品的时候,给用户推荐的标签就分为「我的标签」和「常用标签」两类,而在「我的标签」里也考虑了物品的因素。

基于标签的推荐有很多优点,一方面可以给用户提供比较准确的推荐理由;另一方面标签云的形式也提高了推荐的多样性,给了用户一定的自主选择。标签其实可以看做一种物品的内容数据,比如书的作者,出版社,类型;音乐的国别,风格,作者等等,基于这些信息的推荐可以弥补上述基于用户行为推荐的一些弱点。
3.利用上下文信息
此处所谓的上下文,是指用户所处的时间,地点,心情等。这些因素对于推荐也是至关重要的,比如听歌的心情,商品的季节性等等。
这里主要以时间为例说说,在很多新闻资讯类网站中,时效性是很重要的一点,你要推荐一篇一年前的新闻给用户,估计会被骂死。在这种推荐中就需要加入时间衰减因子,对于越久之前的物品,赋予越小的权重。同样的思想也可以用在基于用户行为的推荐中,这里有很多可以优化的地方。对于ItemCF来说,同一用户在间隔很短的时间内喜欢的不同物品可以给予更高的相似度,而在找相似物品时也可以着重考虑用户最近喜欢的物品;对于UserCF,如果两个用户同时喜欢了相同的物品,那么可以给予这两个用户更高的相似度,而在推荐物品时,也可着重推荐口味相近的用户最近喜欢的物品。我们可以给相似度和用户的行为赋予一定权重,时间间隔越久权重越低,经过这种改进的「协同过滤算法」往往能得到用户更满意的结果。

类似的,在LBS成为应用标配的今天,可以根据物品与用户的距离赋予相应的权重,再综合其他因素得到靠谱的地点推荐。
4.利用社交网络数据
如今以Facebook,Twitter为首的社交网络大行其道,而其中的海量数据也是一大宝库。实验证明,由于信任的作用,来自好友的推荐往往能获取更高的点击率,鉴于此,亚马逊就利用了Facebook的信息给用户推荐好友喜欢的商品。此种推荐类似于UserCF,只是寻找用户之间的关系时除了兴趣相似度以外还得考虑熟悉度(如共同好友个数),这样一来,你的闺蜜们和基友们喜欢的物品很可能就会被推荐给你。
在社交网络内部也有许多推荐算法的应用。其中最重要的当属好友推荐,可依据的数据有很多:人口统计学属性(例如人人的找同学),共同兴趣(如Twitter中转发的信息),好友关系(共同好友数量,N度人脉)。另外还有信息流(Timeline)推荐,这其中以Facebook的EdgeRank为代表,大致思想就是:如果一个会话(Feed)被你熟悉的好友最近产生过重要的行为,它在信息流的排序中就会有比较高的权重。另外,基于社交网络兴趣图谱和社会图谱的精准广告投放也是推荐系统的关键应用,它决定着社交网站的变现能力。

推荐系统的冷启动问题
介绍了这么多类的推荐系统,最后说说推荐系统的一个主要问题:冷启动问题。具体分三种情况:如何给新用户做个性化推荐,如何将新物品推荐给用户,新网站在数据稀少的情况下如何做个性化推荐。
对此也有相应的解决方案。对于新用户,首先可以根据其注册信息进行粗粒度的推荐,如年龄,性别,爱好等。另外也可以在新用户注册后为其提供一些内容,让他们反馈对这些内容的兴趣,再根据这些数据来进行推荐。这些内容需要同时满足热门和多样的要求。而对于新物品的推荐,可能就要从其内容数据上下功夫了。我们可以通过语义分析对物品抽取关键词并赋予权重,这种内容特征类似一个向量,通过向量之间的余弦相似度便可得出物品之间的相似度,从而进行推荐。这种内容过滤算法在物品(内容)更新较快的服务中得到大量应用,如新闻资讯类的个性化推荐。

而在网站初建,数据不够多的情况下,可能就要先通过人工的力量来建立早期的推荐系统了。简单一点的,人工编辑热门榜单,高级一点的,人工分类标注。国外的个性化音乐电台Pandora就雇了一批懂计算机的音乐人来给大量音乐进行多维度标注,称之为音乐基因。有了这些初始数据,就可以方便地进行推荐了。国内的Jing.fm初期也是通过对音乐的物理信息,情感信息,社会信息进行人工分类,而后再通过机器学习和推荐算法不断完善,打造出了不一样的个性化电台。
除了这些,利用社交网络平台已有的大量数据也是一个不错的方法,尤其是那些依托于其他SNS账号系统的服务。
算法vs人
有很多人怀疑推荐系统是否会让一个人关注的东西越来越局限,但看完这些你会觉得并非如此,多样性,新颖性和惊喜度也都是考察推荐系统的要素。而至于算法和人究竟哪个更重要的争论,我很赞同唐茶创始人李如一的一个观点:
在技术社群的讨论里,大家默认觉得让推荐算法变得更聪明、让软件变得更「智能」一定是好事。但人不能那么懒的。连「发现自己可能感兴趣的内容」这件事都要交给机器做吗?不要觉得我是Luddite。真正的技术主义者永远会把人放到第一位。
我想补充的是,算法虽然不能解决全部问题,但算法可以变得更人性化。套用某人「网络就是社会」的论断,其实算法和人之间早已不那么泾渭分明了。
头图来源:Dribbble
本文转载自:极客公园
Category Archives: 机器学习相关推荐
- Category Archives: Linux
原文地址:http://blog.solrex.org/articles/solrex-linux-cheatsheet.html Cheatsheet:原意是考试的时候带的小抄,所以说是 cheat ...
- oracle gtx,ORACLE
Category Archives: ORACLE 所有Oracle技术文章 看到群里有人提出一个需求,一张表数据量很大,只想导出其中一部分列. 无论是老版本exp还是数据泵expdp,Oracle都 ...
- 人工智能,大数据,云计算大杂烩
百度ABC ABC = AI+Big data + Cloud Computing 百度 基础云, 天像(智能多媒体平台),天算(智能大数据平台),天工(智能物联网平台),天智(人工智能平台) 监督学 ...
- 《说服力-让你的PPT会说话》9月上海公开课简章
Skip to content 秋叶的职场人生感悟 70后,水瓶男,立志做高情商的职场玩家,PPT和项目管理内训师 关于博主 最热博文 联系秋叶 登录 首页 | 如何做好项目经理 | 如何成为PPT高 ...
- [论文翻译] Deep Learning
[论文翻译] Deep Learning 论文题目:Deep Learning 论文来源:Deep learning Nature 2015 翻译人:BDML@CQUT实验室 Deep learnin ...
- wordpress内容调用_WordPress网站的基本内容
wordpress内容调用 Once you have created your WordPress website and installed your chosen theme, the next ...
- 如何使用砌体在WordPress中添加Pinterest样式发布网格
This is a guest post by Josh Pollock 这是Josh Pollock的来宾帖子 The Pinterest-like grid display of posts ha ...
- Deep Learning — LeCun, Yann, Yoshua Bengio and Geoffrey Hinton
原文链接Deep Learning 由于作者太菜,本文70%为机翻.见谅见谅 第一篇是三巨头LeCun, Yann, Yoshua Bengio和Geoffrey Hinton做的有关Deep Lea ...
- 【转载】图解 Python 深拷贝和浅拷贝
伯乐在线 > Python - 伯乐在线 > 所有文章 > 基础知识 > 图解 Python 深拷贝和浅拷贝 图解 Python 深拷贝和浅拷贝 2015/09/28 · 基础 ...
最新文章
- 三分钟了解“Java重写”
- 【计算理论】计算理论总结 ( 上下文无关文法 CFG 转为下推自动机 PDA 示例 2 ) ★★
- Spring AOP 源码分析 - 筛选合适的通知器
- 【Linux部署】【elasticsearch-6.4.3 单机版】【不能以root用户运行es 及 max_map_count 问题解决】(含 安装包+分词插件 云盘资源)
- 《leetcode》reverse-integer
- fftw库在windows下的的编译和配置
- js 正则表达式 整合
- 信息学奥赛一本通(1060:均值)
- keytool使用方法总结
- javaweb功能模块如何合理设计_燃油燃气锅炉烟道如何设计才更合理?
- python编程考试_《Python程序设计》试题库
- android菜单动画,利用 android studio 制作一个菜单动画
- 计算机平方在线使用,开平方计算器在线
- Java对象转Map的解决办法
- 原子结构示意图全部_原子结构示意图和元素及元素周期表
- Android中的PackageManager
- c语言学生成绩及格率,c语言百分制输入学生的考试分数统计学生及格率
- 【科普】当手机遭遇短信验证码轰炸,这几点尤其要注意
- Bugku CTF Web 滑稽 计算器 GET POST 矛盾 alert 你必须让他停下
- finalcut剪切快捷键_Final Cut Pro 笔记(一) 常用快捷键与技巧