CUDA 编程简单入门 Advance CUDA 编程基础 (C++ programming)
- Advance CUDA编程基础 (C++ programming)
- GPU 架构
- CUDA 编程基础
- 基本代码框架
- CUDA Execution Model
- Case Study : Vector Add
- 优化方法举例
- SM 共享内存的使用
- case study :一维卷积计算
- SM 共享内存的使用
- Summary
Advance CUDA编程基础 (C++ programming)
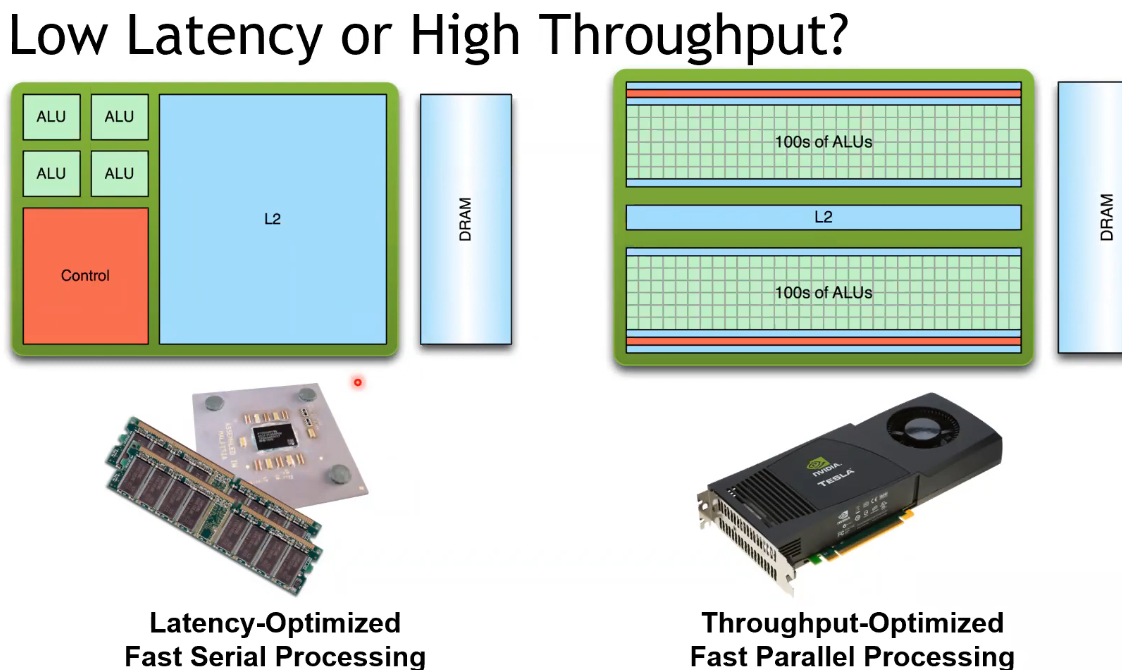
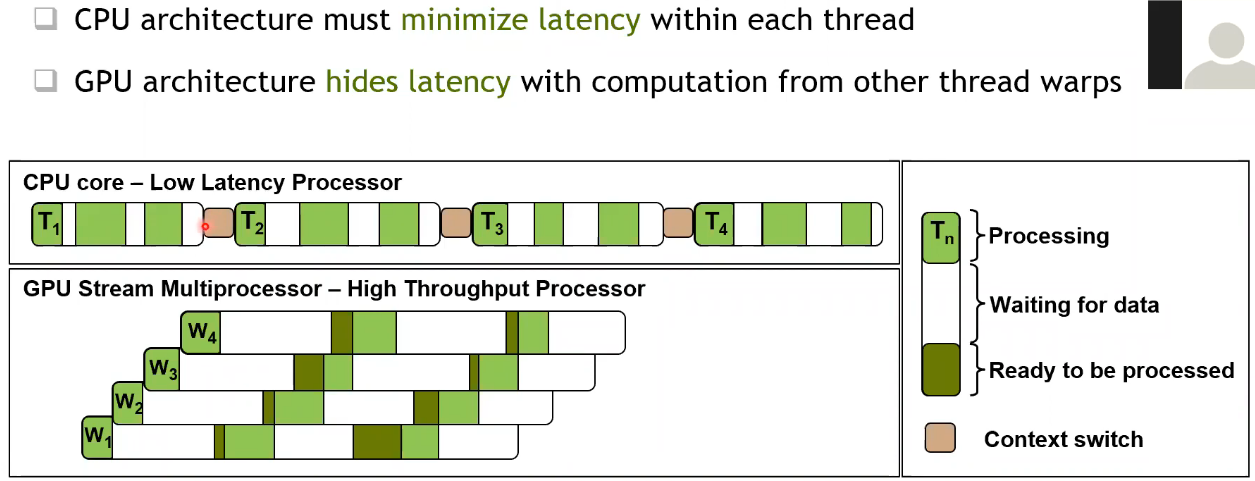
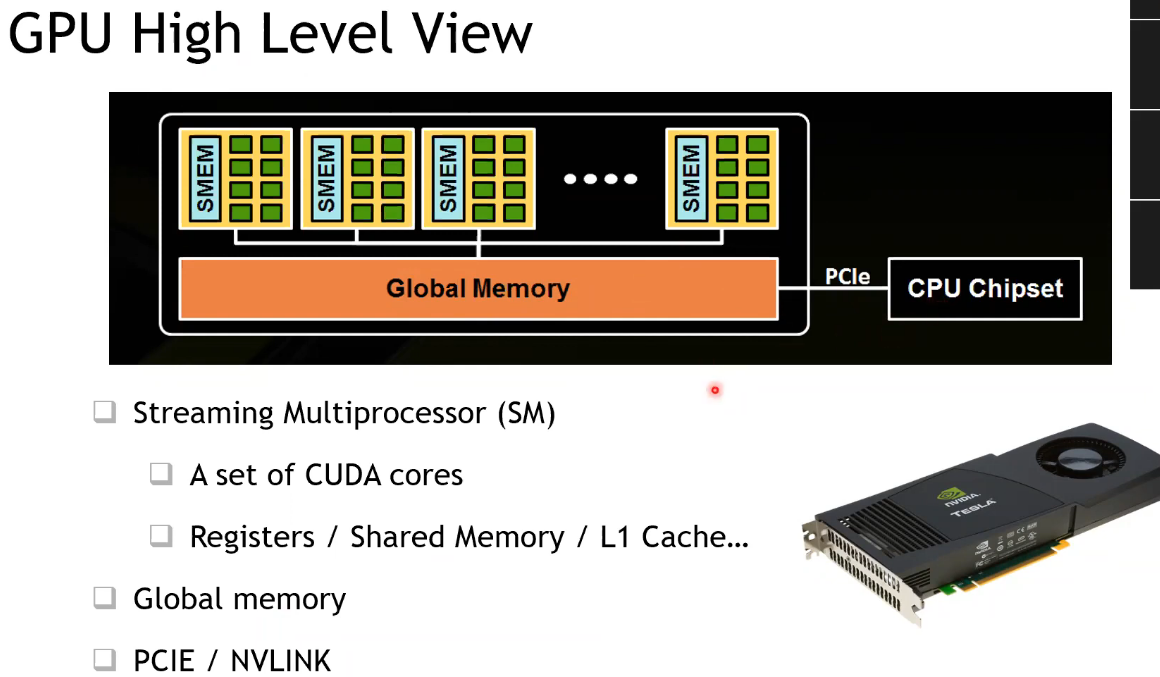
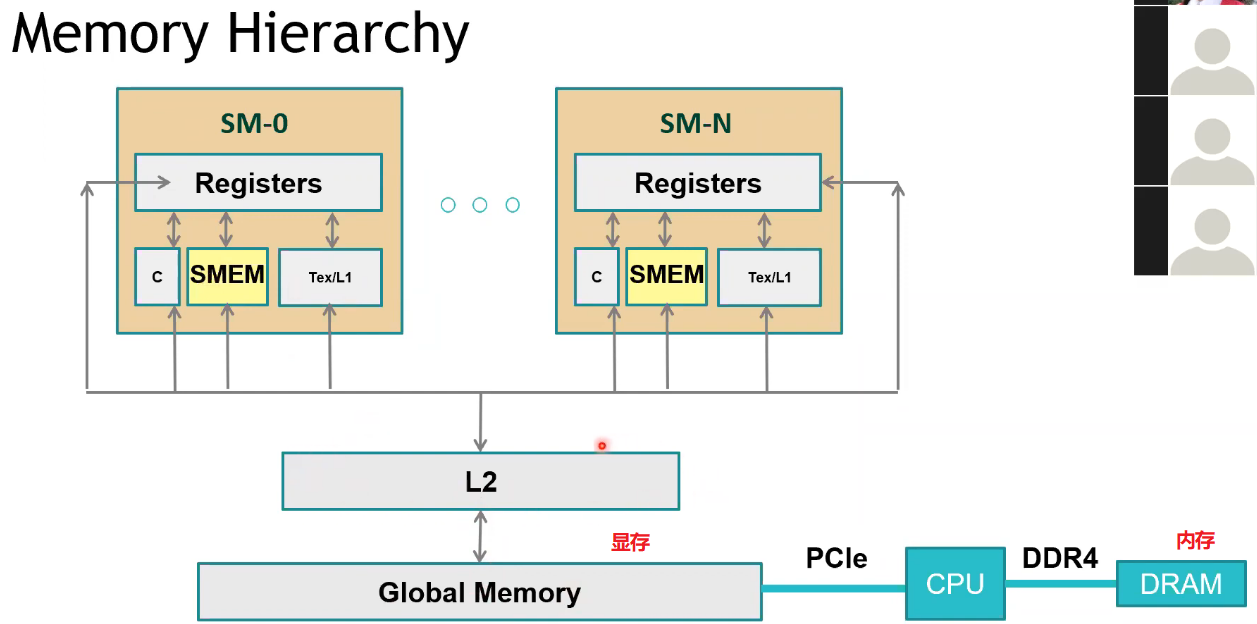
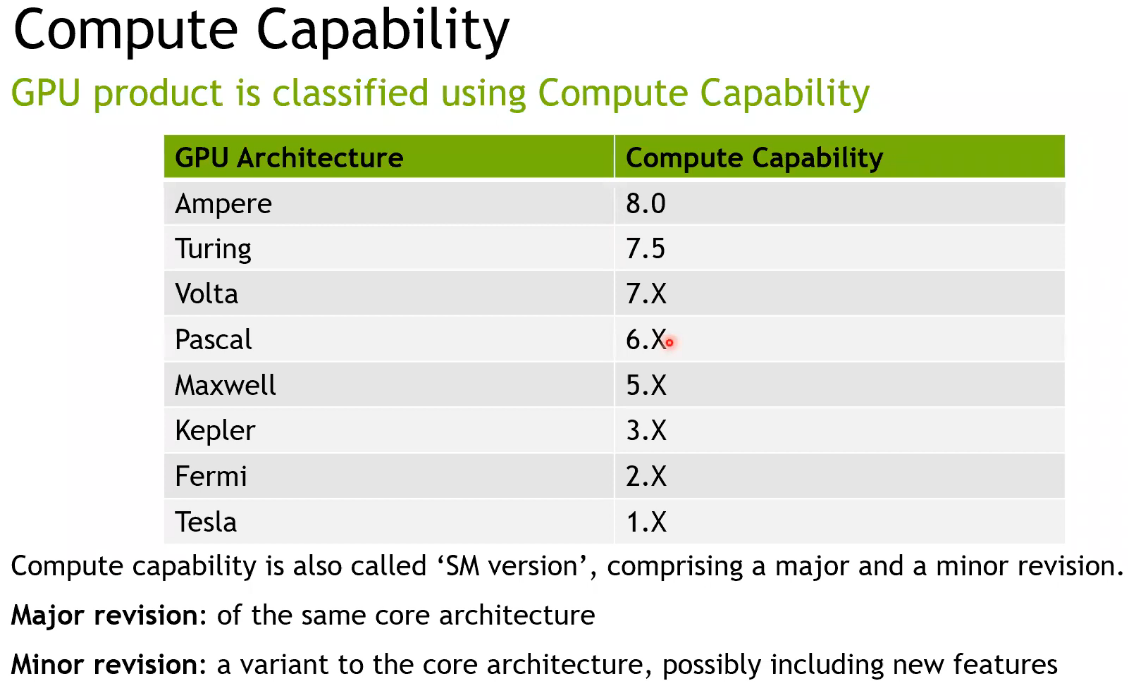
GPU 架构
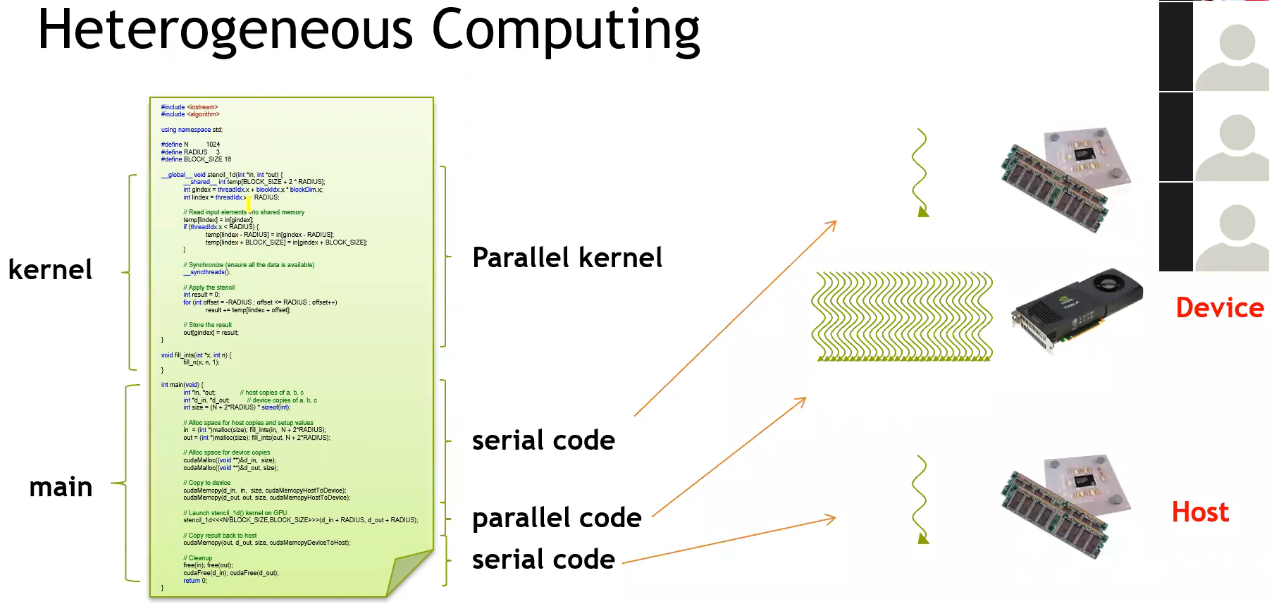
CUDA 编程基础
基本代码框架
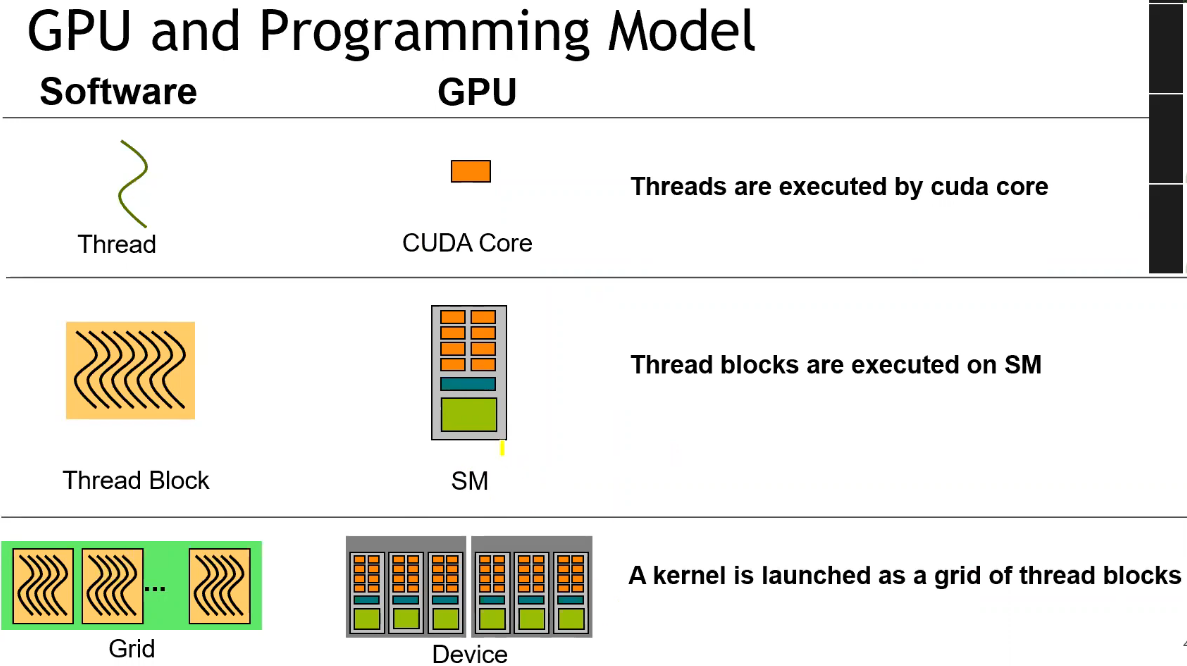
- 整个 GPU 执行 kernel 函数,多个线程执行相同代码;



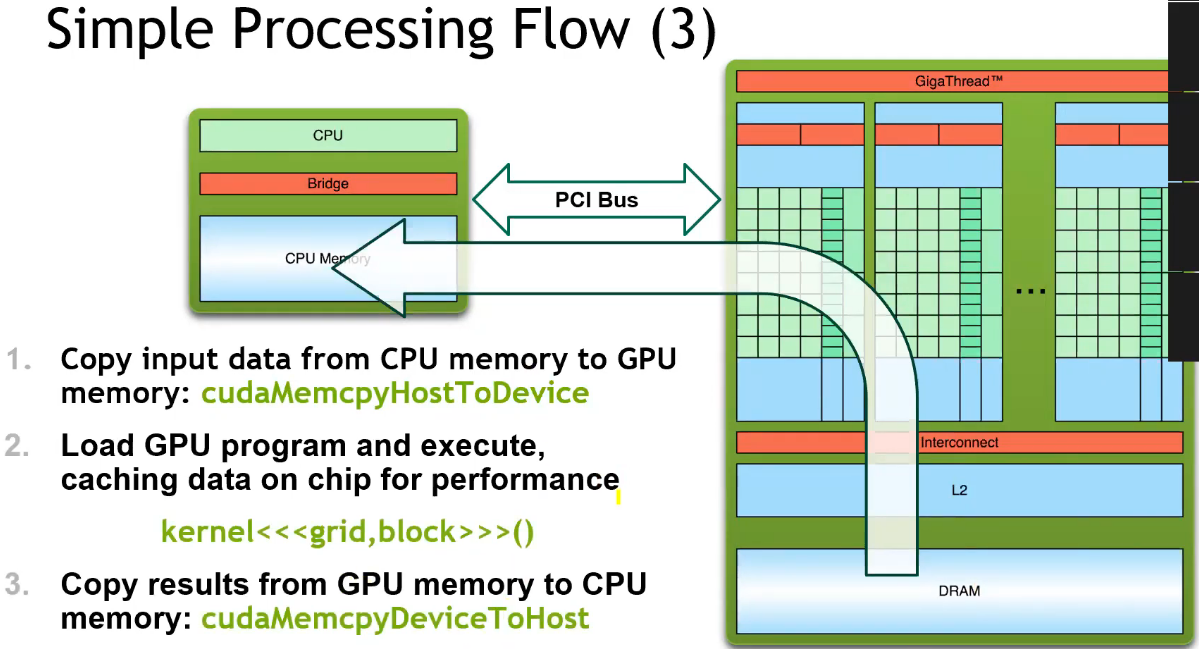
CUDA Execution Model

- 不同 Block 之间是完全异步执行的;
- 且需要通过全局的显存才能进行数据共享,因此开销较大;
- 单个 Block 内的所有线程共享单个 SM 上的共享内存,多个线程可以协作
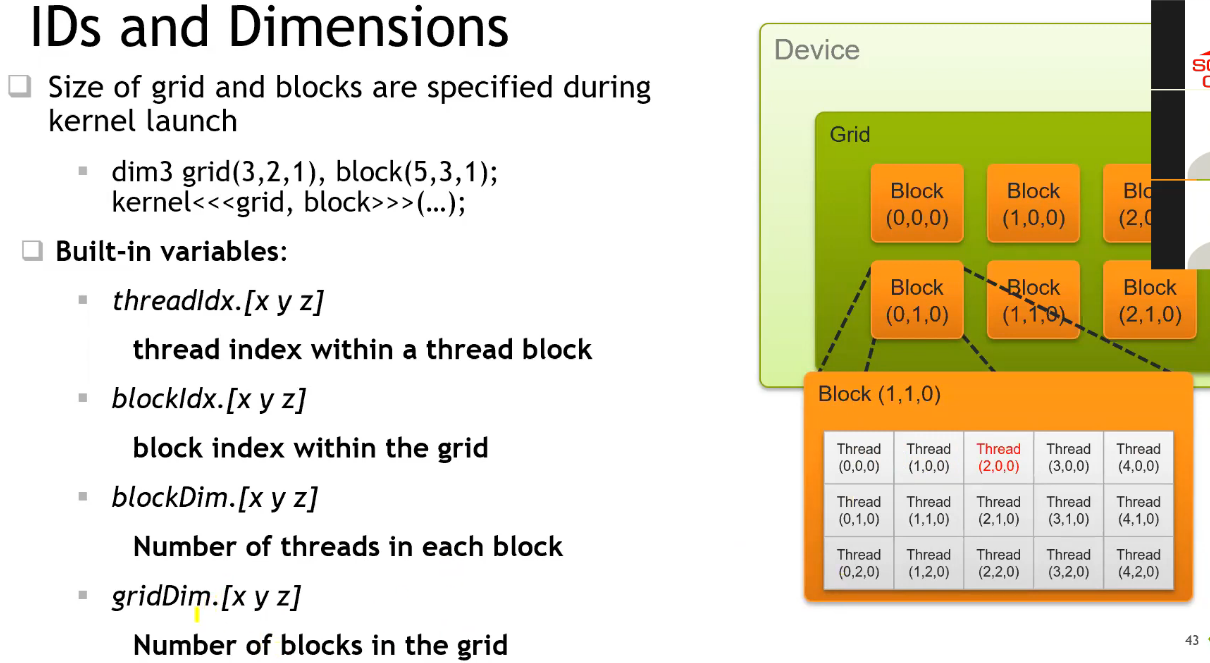
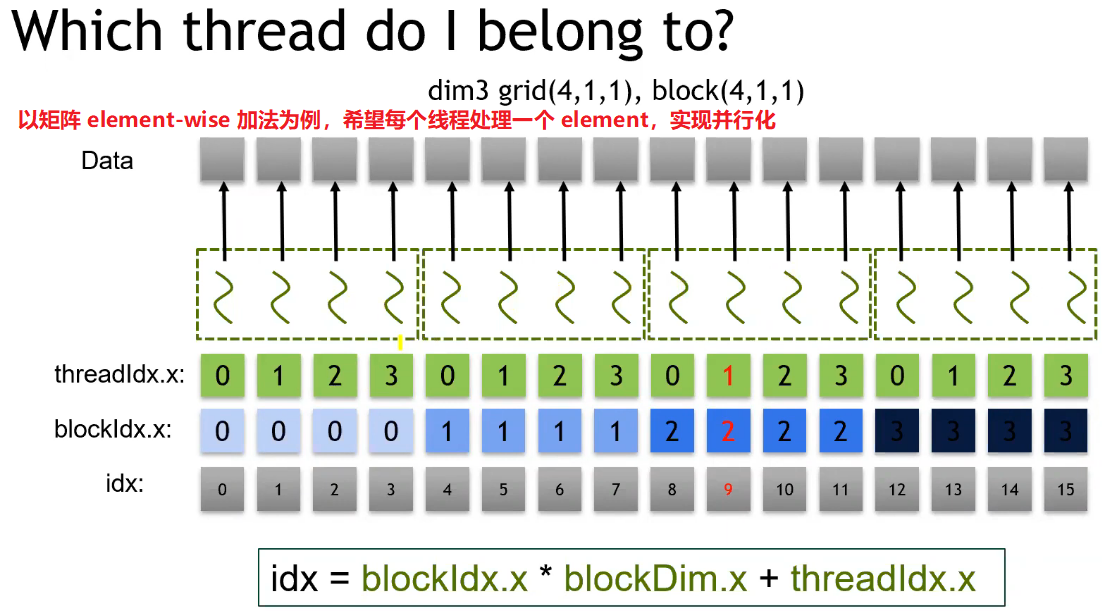
- 可通过预定义的变量获取当前线程的全局 ID;
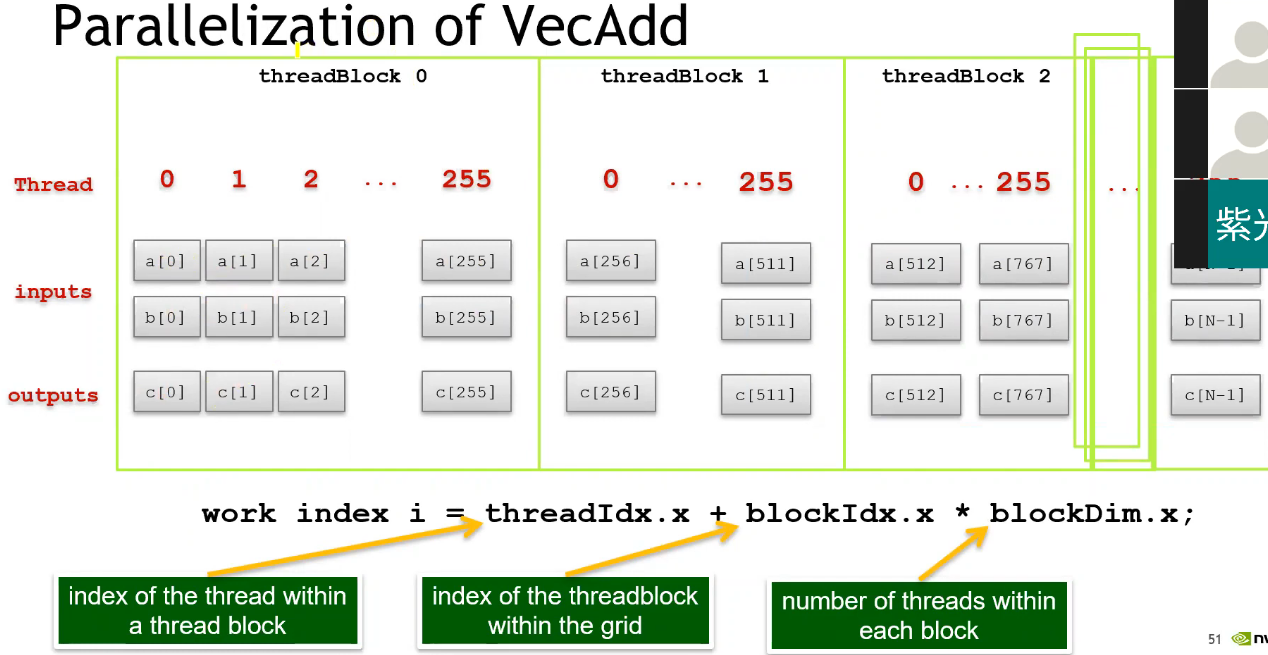
Case Study : Vector Add

- 最重要的一点是:找出程序中可以并行加速的地方!
// file: vecAdd.cu
#include <stdio.h>// GPU kernel
// __global__ 表示:GPU 代码入口函数
__global__ void vecAdd(int N, int* lhs, int* rhs, int* out) {int ind = blockIdx.x * blockDim.x + threadIdx.x; // 获取当前线程全局 IDif (ind < N) // 避免多启动的线程出现内存越界out[ind] = lhs[ind] + rhs[ind];
}int main() {// 初始化const int N = 128;int *h_lhs, *h_rhs, *h_out;int *d_lhs, *d_rhs, *d_out;h_lhs = (int*)malloc(N * sizeof(int));h_rhs = (int*)malloc(N * sizeof(int));h_out = (int*)malloc(N * sizeof(int));memset(h_lhs, 0, N * sizeof(int));for (int i = 0; i < N; ++i) h_rhs[i] = i;// 分配内存// 将修改指针的值,故为二级指针cudaMalloc((void**)&d_lhs, N * sizeof(int));cudaMalloc((void**)&d_rhs, N * sizeof(int));cudaMalloc((void**)&d_out, N * sizeof(int));// 数据拷贝至 GPUcudaMemcpy(d_lhs, h_lhs, N * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_rhs, h_rhs, N * sizeof(int), cudaMemcpyHostToDevice);// launch kernel// <<<grid, block>>> 表示launch configuration,// 即 grid 内的 thread blocks 数,和 thread block 内的 threads 数;// vecAdd<<<(N + 255) / 256, 256>>>(N, d_lhs, d_rhs, d_out);dim3 grid_conf{(N + 255) / 256, 1, 1}, block_conf{256, 1, 1};vecAdd<<<grid_conf, block_conf>>>(N, d_lhs, d_rhs, d_out);// 打印可能的错误信息cudaError_t err = cudaGetLastError();if (err != cudaSuccess)printf(cudaGetErrorString(err));// 结果拷贝回 CPUcudaMemcpy(h_out, d_out, N * sizeof(int), cudaMemcpyDeviceToHost);for (int i = 0; i < N; ++i) printf("%d\n", h_out[i]);return 0;
}
编译方法:
nvcc vecAdd.cu -o shared_memo.exe- 出现问题:
- GPU 计算结果全为 0;
- 报错:“CUDA Error:no kernel image is available for execution on device”,则说明 cuda 版本与 GPU 不匹配;
- 解决方法:
- 指定显卡架构
-arch参数:nvcc vecAdd.cu -o vecAdd.exe -arch=sm_50 -Wno-deprecated-gpu-targets
- 指定显卡架构
优化方法举例
SM 共享内存的使用
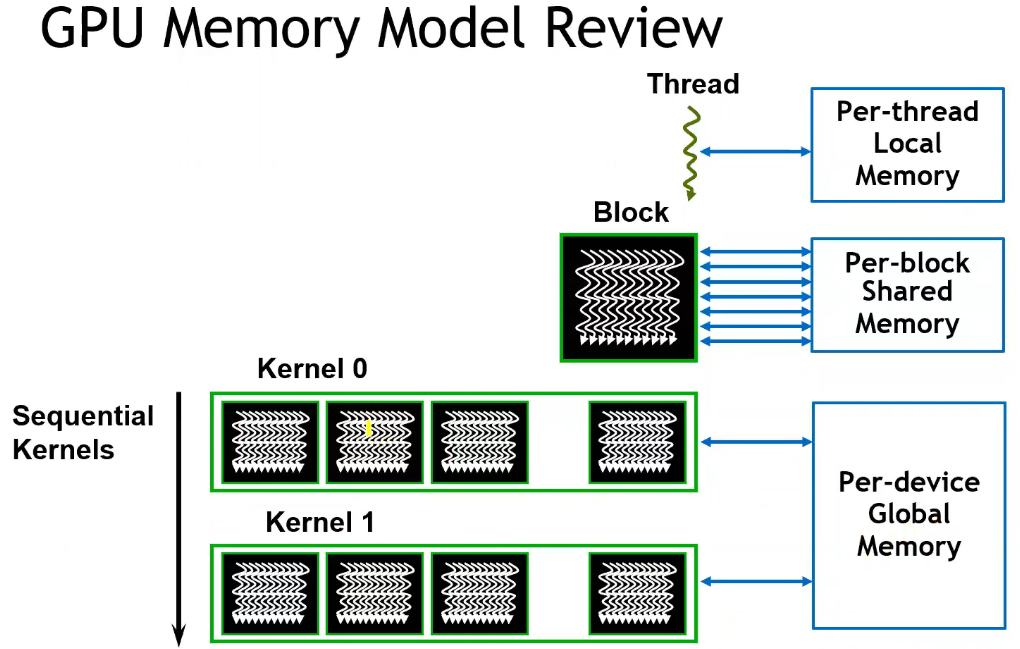
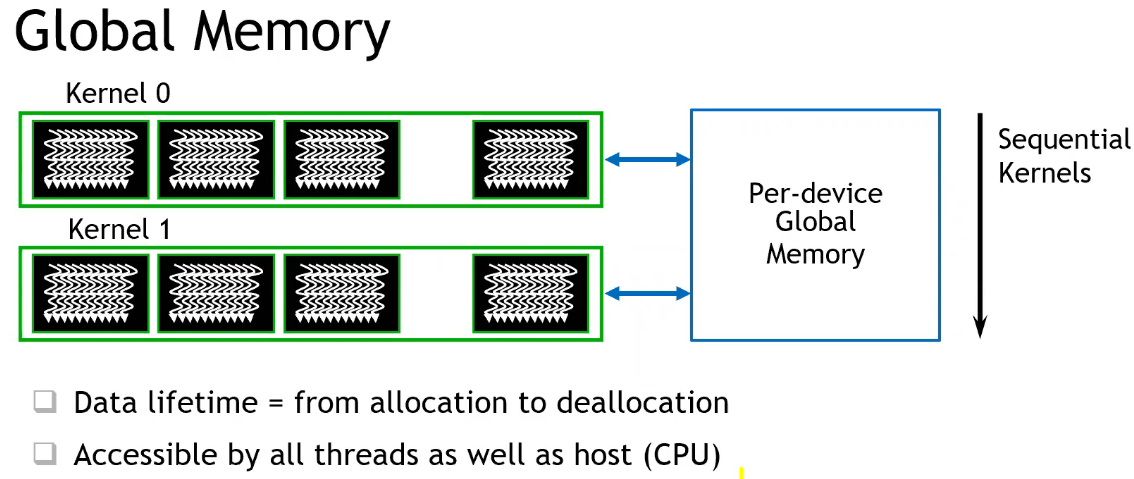
- cudaMalloc 申请在全局显存(global memory),而 Thread 的 Register 或 Block 内的共享内存,速度延迟远低于全局显存;
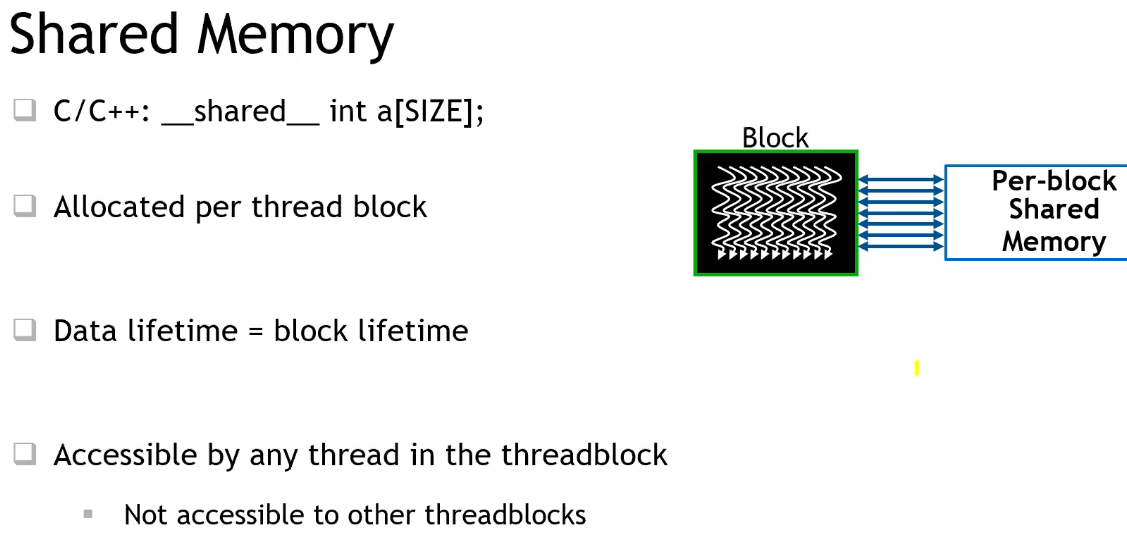
- 注意:线程块内所有线程,共享一个 shared 数组 a,而不会有多个 a;
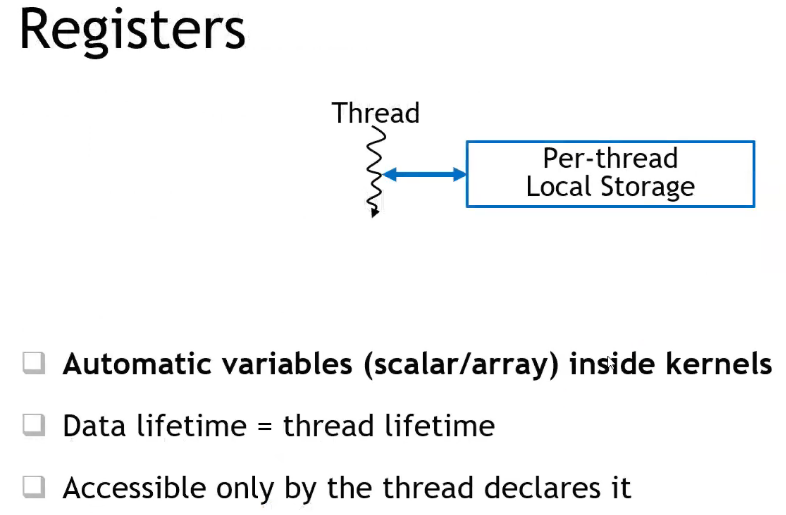
- 编译器尽可能将自动变量(标量)存储在寄存器内,而不是片外显存上的栈空间;
- 需要寻址(如索引等)的自动变量,也不能放在寄存器上;
case study :一维卷积计算
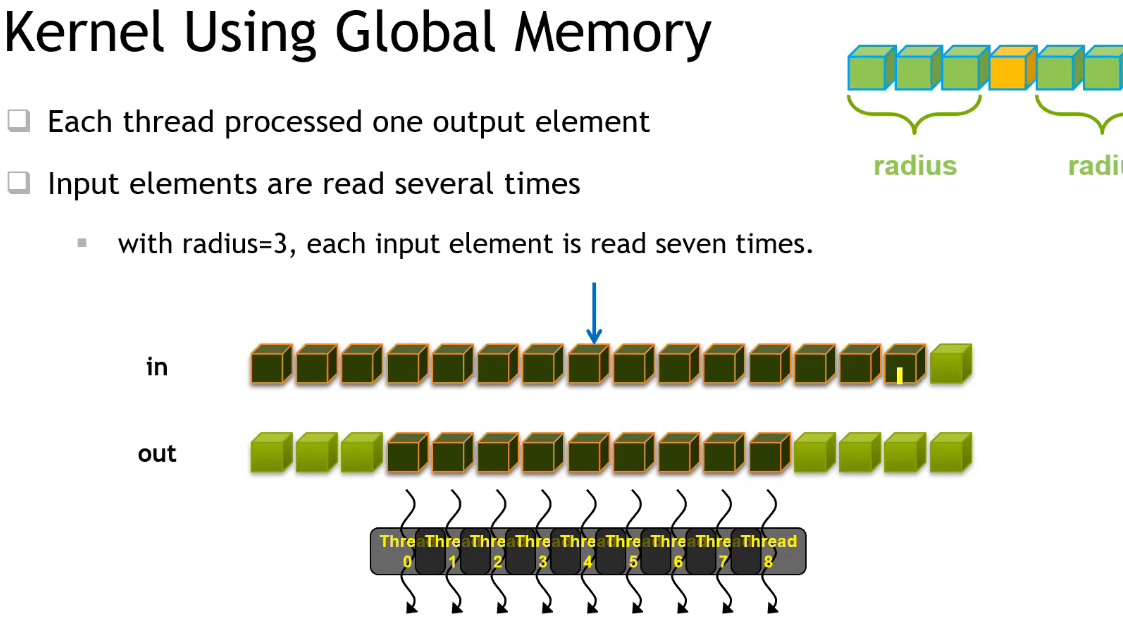
- 并行度:每个卷积结果是相互独立的,可以并行计算;
- 优化点:每个线程都需要从显存中读取 (2*radius + 1) 个数据,而所有被访问到的数据总共是 in 灰色部分,线程间存在重复读取的冗余;为提高访问速度,可以提前将单个 Block 用到的所有数据 cache 到 Block 内的共享内存中;

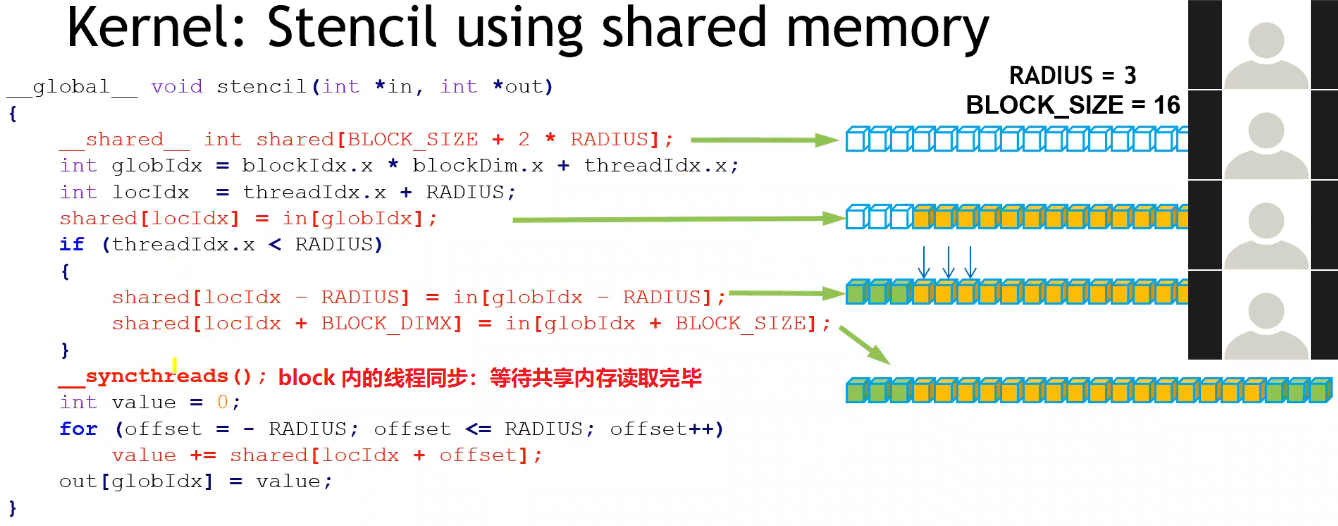

#include <stdio.h>const int BLOCK_SIZE = 128, RADIUS = 5;// GPU kernel
__global__ void conv_1d(int *in, int *out) {// 单个 Block 共享内存里只有一个实例 shared,所有线程共享__shared__ int shared[BLOCK_SIZE + 2 * RADIUS];int global_ind =blockIdx.x * blockDim.x + threadIdx.x; // 获取当前线程全局 IDint local_ind = threadIdx.x + RADIUS;shared[local_ind] = in[global_ind]; // 每个线程负责读取中心元素// 部分线程负责读取 RADIUS 对应数据if (threadIdx.x < RADIUS) {shared[local_ind - RADIUS] = in[global_ind - RADIUS];shared[local_ind + BLOCK_SIZE] = in[global_ind + BLOCK_SIZE];}// 需要等到 RADIUS 部分数据读完后,其它线程才能继续__syncthreads(); // barrier,线程同步// 计算卷积int value = 0;for (int offset = -RADIUS; offset <= RADIUS; ++offset)value += shared[local_ind + offset];out[global_ind] = value;
}int main() {// 初始化const int N_VALID = 256;const int N_TOTAL = N_VALID + 2 * RADIUS;int *h_in, *h_out;int *d_in, *d_out;h_in = (int *)malloc(N_TOTAL * sizeof(int));h_out = (int *)malloc(N_VALID * sizeof(int));// memset(h_in, 10, N_TOTAL * sizeof(int));// memset 逐字节赋值,只适用于 0 或 -1;for (int i = 0; i < N_TOTAL; ++i) h_in[i] = 1;// 分配内存// 将修改指针的值,故为二级指针cudaMalloc((void **)&d_in, N_TOTAL * sizeof(int));cudaMalloc((void **)&d_out, N_VALID * sizeof(int));// 数据拷贝至 GPUcudaMemcpy(d_in, h_in, N_TOTAL * sizeof(int), cudaMemcpyHostToDevice);// launch kernel// <<<grid, block>>> 表示launch configuration,// 即 grid 内的 thread blocks 数,和 thread block 内的 threads 数;// 注意起始位置 d_in 偏移 RADIUS 个元素conv_1d <<<(N_VALID + BLOCK_SIZE - 1) / BLOCK_SIZE, BLOCK_SIZE>>> (d_in + RADIUS, d_out);// 打印可能的错误信息cudaError_t err = cudaGetLastError();if (err != cudaSuccess)printf(cudaGetErrorString(err));// 结果拷贝回 CPUcudaMemcpy(h_out, d_out, N_VALID * sizeof(int), cudaMemcpyDeviceToHost);for (int i = 0; i < N_VALID; ++i) printf("%d ", h_out[i]);return 0;
}
Summary

CUDA 编程简单入门 Advance CUDA 编程基础 (C++ programming)相关推荐
- ARM NEON 编程简单入门1
原文:http://blog.csdn.net/silentob/article/details/72954618 ARM NEON 编程简单入门1 NEON简介 NEON是适用于ARM Corte ...
- 儿童编程python入门_儿童编程python入门
经常会有小朋友问我,"我想做个黑客,我该学什么编程语言?",或者有的小朋友会说:"我要学c,我要做病毒".其实对于这些小朋友而言他们基本都没有接触过编程语言,只 ...
- php面向对象编程快速入门,PHP面向对象编程的快速入门
面向对象编程(OOP)是我们编程的一项基本技能,PHP4对OOP提供了良好的支持.如何使用OOP的思想来进行PHP的高级编程,对于提高PHP编程能力和规划好Web开发构架都是非常有意义的.下面我们就通 ...
- 网络编程简单入门,基础知识需先掌握
文章目录 网络编程入门 网络编程概述 网络编程三要素 ==IP地址== IP地址分类 通过控制台,获取IP的方法 InetAddress 三个常用方法 ==端口== 端口号 ==协议== UDP协议 ...
- 【博学谷学习记录】超强总结,用心分享 | 狂野大数据shell编程—简单入门
目录 前言 一.shell简介 二.入门案例 1.编写shell脚本 2.shell的运行方式 3.shell的数据类型 4.shell的变量 5.shell的字符串 6.shell的运算符 7.sh ...
- 51单片机编程简单入门——点亮实验板上的LED灯
1.使用uVision4创建项目 2.选择MCU的型号:Atmel->AT89C52 3.是否创建C51启动文件,选否.启动文件以前汇编常用,现在少用了. 4.新建文件,需指定命名为.c文件 5 ...
- Python编程:从入门到实践(基础知识)
第一章 起步 计算机执行源程序的两种方式: 编译:一次性执行源代码,生成目标代码 解释:随时需要执行源代码 源代码:采用某种编程语言编写的计算机程序 目标代码:计算机可执行,101010 编程语言分为 ...
- python代码编程教学入门,python代码编程火影忍者
python源代码编程软件 编写python源代码的软件.首推的Pycharm. PyCharm用于bai一般IDE具备的功能,比如, 调试.语法高亮.Project管理.du代码跳转.智能提示.自动 ...
- 编程新手入门:初学编程的正确学习方法!快速提升你的学习效率
感觉对于学习c语言无从下手,特别是刚入门的朋友.看到那些奇怪的,不合常理的符号,感觉完全是摸不着路一样.然后写这篇文章,谈一下个人的学习方法和学习效率,希望对大家有帮助,特别是新手! 一.书的选择 首 ...
最新文章
- java tcp 三次握手_用Java代码分析TCP的三次握手四次挥手过程
- 《数学之美》第9章 图论和网络爬虫
- C++中sprintf()函数的使用详解
- Centos6.6安装zabbix server 3.2
- Window 2000 网络操作命令全释
- SAP最大命中数的修改
- This Style does not belong to the supplied Workbook. Are you trying to assign a style from one workb
- 前端学习(1002):简洁版滑动下拉菜单问题解决
- LeetCode 1323. 6 和 9 组成的最大数字
- maven引用外部jar依赖
- php安装扩展igbinary
- 【数据预测】基于matlab鸟群算法优化BP神经网络数据预测【含Matlab源码 1772期】
- 可视化排班管理_呼叫中心外包之管理要点与数据分析对策
- Powerbuilder 12.5 下载地址
- Android Socket通信
- 全志F1C100s入坑与填坑 uboot Linux Kernel 与buildroot
- 基于时域线性插值法计算信号的周期
- 看ftp服务器文件日期,ftp查看服务器当前日期
- 谁在维护linux内核,故意向Linux内核中提及漏洞? Linux 内核维护者封杀明尼苏达大学...
- MySql (4)-储存引擎、索引、锁、集群