IBM SPSS Modeler随机森林算法介绍
在之前的文章《Bagging 或Boosting让你的模型更加优化》中,我们介绍了可以通过Bagging或Boosting技术,使得模型更加稳定和准确率更高,那么今天要介绍的随机森林算法,本身的算法逻辑已经使用了Bagging技术,来构建多棵树,最终实现构建“森林”的目的。
首先我们先来了解下这个算法,记住几个要点就可以:
1.在IBM SPSS Modeler中,随机森林构建的每棵树,使用的算法是C&RT,关于C&RT算法的介绍可以参考之前的文章《IBM SPSS Modeler算法系列------C&R Tree算法介绍》;
2.使用Bagging,每构建一棵树,都是通过随机选择样本数据来构建(有放回的);
3.除了使用Bagging技术,对使用的输入指标,也随机选择。比如说一共有20个输入指标,每选完一次样本数据后,会再随机选择其中的10个指标来构建树。
4.最终的预测结果,会综合前面构建的决策树通过投票的方式得到最终的预测结果,如果是数值型的预测,则是取平均值做为最终的预测结果。
5.在IBM SPSS Modeler中,随机森林算法不仅支持传统的关系型数据库,比如DB2、Oracle、SQL Server等通过ODBC可连接的数据库,也支持Haoop分布式架构的数据,它可以生成MapReduce或者Spark,放到Hadoop平台上去执行,从而提升整个计算效率。
那么接下来,我们来看下在IBM SPSS Modeler的随机森林算法实现客户的流失预测,能给我们呈现出什么样的结果。
首先,我们创建数据流文件 ,如下图:
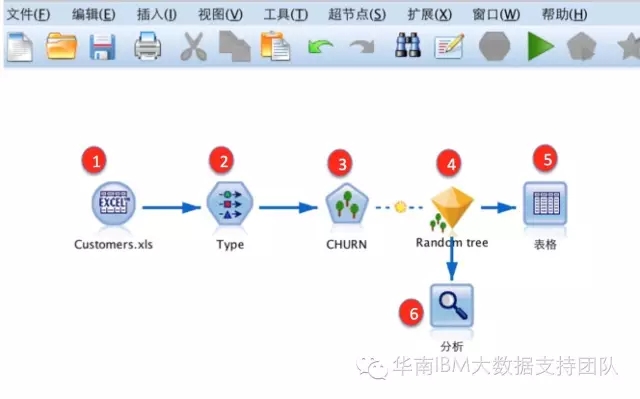
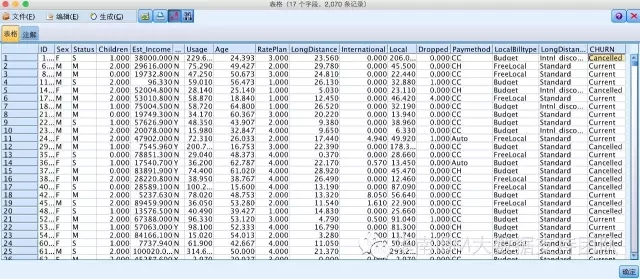
Step1:连接数据源Excel文件,文件内容如下:
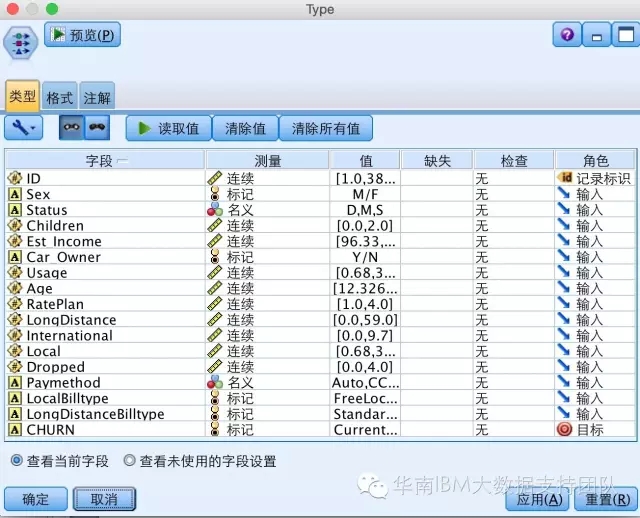
Step2:类型节点设置影响因素及目标,如下图:
Step3:选择随机森林算法,并使用默认参数设置生成模型。
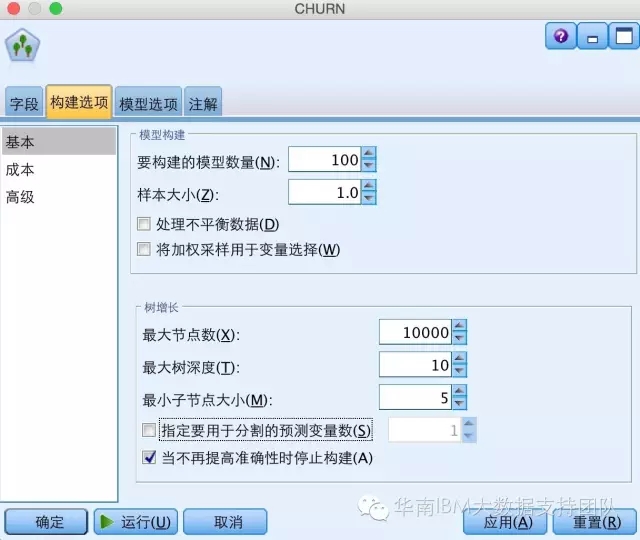
该面板主要涉及到模型构建和树增长两方面的参数,包括以下内容:
- 构建的模型数量:即构建多少棵树;
- 样本大小:是每次随机选择的样本占原来的百分比,如果是1的话,代表每次选择的样本数据与原来的数据量一样,如果是0.9,则选择原来的数据量的90%作为的样本数据,在处理大数据集时,减少样本大小可以提高性能。
- 是否需要处理不平衡数据:如果模型的目标是标志结果(例如,流失或不流失) 比率很小,那么数据是不平衡数据并且模型所执行的 Bootstrap 采样可能会影响模型精确性。要提高准确性,请选中此复选框;模型随后会捕获所需结果中的更大比例部分并生成更好的模型。
- 使用加权采样选择变量: 缺省情况下,每个叶节点的变量是使用同一概率随机选择的。要将加权用于变量并改进选择过程,请选中此复选框。
- 最大节点数:指定允许各个树中存在的最大叶节点数。如果下一次分割时将超过此数字,那么树增长将在进行拆分之前停止。
- 最大树深度:指定根节点下方的最大叶节点级别数;即,样本进行递归拆分的次数。
- 最小子节点大小:指定拆分父节点之后必须包含在子节点中的最小记录数。如果子节点包含的记录数少于您输入的数目,那么不会拆分父节点。
- 指定要用于拆分的最小预测变量数:如果是构建拆分模型,请设置要用于构建每个拆分的最小预测变量数。这防止拆分创建过小的子组。
- 当准确性无法再提高时停止构建:要改进模型构建时间,请选择此选项,以在结果的准确性无法提高时停止模型构建过程。
在高级面板中,考虑到对样本数据选择的质量要求,该算法也涵盖了数据准备的内容。
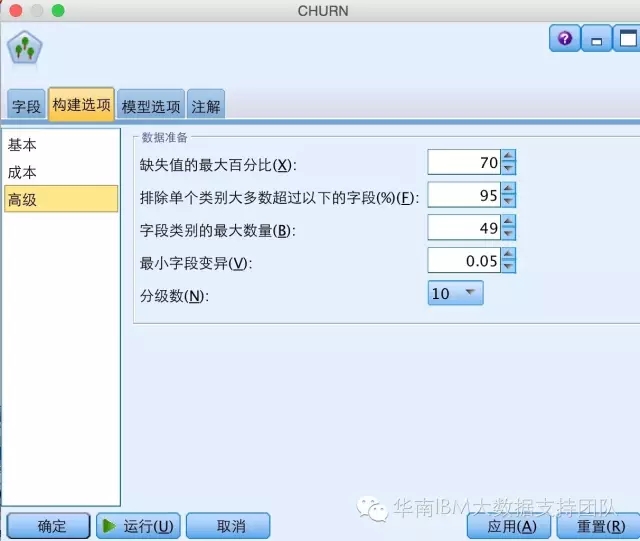
数据准备可设置的参数包括:
- 缺失值最大百分比指定允许任何输入中存在的缺失值的最大百分比:如果该百分比超过了此数字,那么将从模型构建中排除此输出。
- 排除单个类别多数超过以下值的字段指定单个类别可以在某个字段中具有的最大记录百分比:如果任何类别值表示的记录百分比高于指定值,那么将从模型构建中排除整个字段。
- 最大字段类别数:指定字段中可以包含的最大类别数。如果类别数超过了此数字,那么将从模型构建中排除此字段。
- 最小字段变化:如果连续字段的变异系数小于您在此处指定的值,那么将从模型构建中排除此字段。
- 分箱数:请指定要用于连续输入的均等频率分箱数。可用选项包括:2、4、5、10、20、25、50 或 100。
Step4:生成客户流失分析模型。
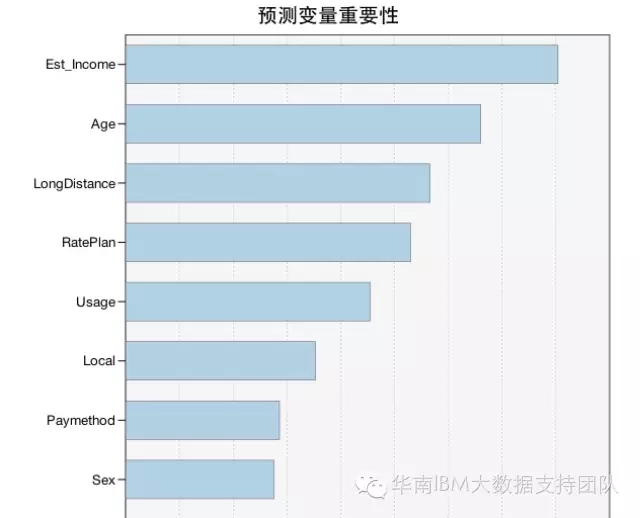
在生成的模型结果里面,会包括对输入指标的重要性排序,如下图:
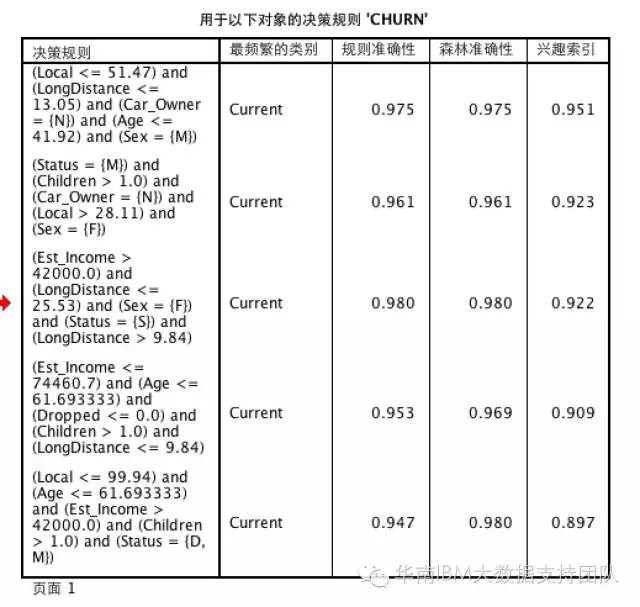
模型结果中,也会包含在生成的这些树中,最频繁出现的规则集,包括决策规则内容、类别、准确性等内容。这些规则集可以协助我们做一些业务解读。
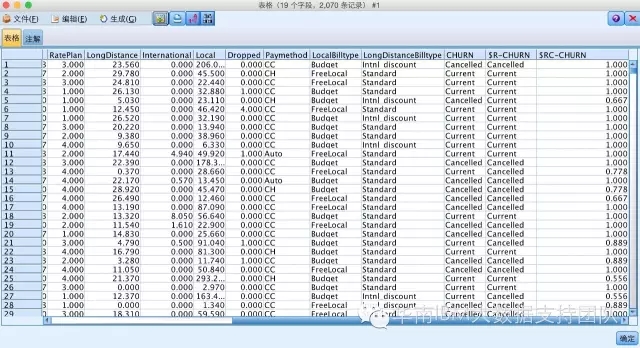
Step5:可以通过表格查看预测结果。
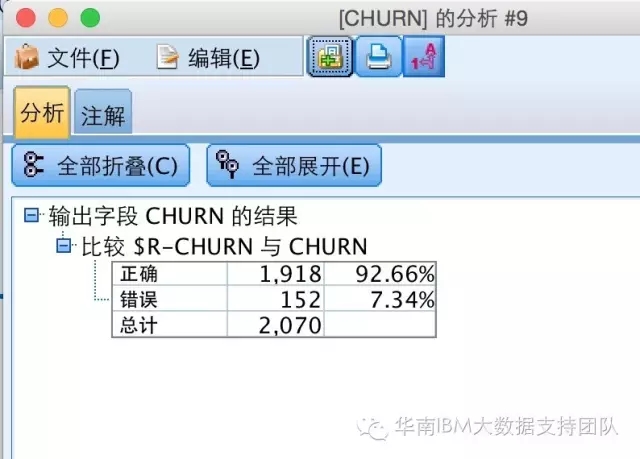
Step6:通过分析节点查看模型准确率。
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
IBM SPSS Modeler随机森林算法介绍相关推荐
- Python数据挖掘项目:构建随机森林算法模型预测分析泰坦尼克号幸存者数据
作者CSDN:进击的西西弗斯 本文链接:https://blog.csdn.net/qq_42216093/article/details/120196972 版权声明:本文为作者原创文章,未经作者同 ...
- 人工智能之随机森林算法项目实战
文章目录 (1)随机森林算法介绍 随机性体现 (2)随机森林应用场景 (3) Spark随机森林训练和预测过程 训练 预测 分类 回归 (4) Spark随机森林模型参数详解 (5) Spark随机森 ...
- 使用IBM SPSS Modeler进行随机森林算法预测
IBM SPSS产品系列最主要的两款软件为IBM SPSS Statistics和IBM SPSS Modeler. IBM SPSS Statistics主要用于统计分析,如均值比较.方差分析.相关 ...
- 非常值得收藏的 IBM SPSS Modeler 算法简介
IBM SPSS Modeler以图形化的界面.简单的拖拽方式来快速构建数据挖掘分析模型著称,它提供了完整的统计挖掘功能,包括来自于统计学.机器学习.人工智能等方面的分析算法和数据模型,包括如关联.分 ...
- 《IBM SPSS Modeler数据与文本挖掘实战》之文本挖掘算法
随着文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术.现代文本分类和聚类领域面临巨大的挑战,而且随着学者研究的不断深入,其中的一些深层次问题也逐渐暴露出来,一些问题也已经成为本学科进一 ...
- spark 随机森林算法案例实战
随机森林算法 由多个决策树构成的森林,算法分类结果由这些决策树投票得到,决策树在生成的过程当中分别在行方向和列方向上添加随机过程,行方向上构建决策树时采用放回抽样(bootstraping)得到训练数 ...
- php 集成 spss,〖SPSS Modeler〗 IBM SPSS Modeler 整合不同数据库之间的数据
来自IBM DEVELOPERWORKS 简介 由于目前企业客户的业务量和数据量都在不断的提高,随着企业的发展,很多企业的数据存储都不局限于同一个数据库上,如果要对这些存储在不同数据库上的数据进行处理 ...
- IBM SPSS Modeler 18.1最新版本正式发布 | 附下载
IBM 数据挖掘分析平台IBM SPSS Modeler在市场上一直占据领导者地位,其专业性及易用性一直受到广大用户的喜爱,该平台也不负众望,我们的研发团队一直致力于不断的技术更新及功能的提升,最新版 ...
- IBM SPSS Modeler数据库内建模
IBM SPSS Modeler Server支持对数据库供应商的数据挖掘工具和建模工具进行整合,其中包括IBM Netezza.IBM DB2 InfoSphere Warehouse.Oracle ...
最新文章
- 关于学习Mongodb的几篇文章
- internet 协议入门
- 设置程序中的html,如何在Behat中为HTML格式化程序设置自定义模板
- ITK:在保留边缘的同时使图像平滑
- 为什么安装了Microsoft .NET Framework 4之后我的电脑网卡启动会变得很慢很慢。。...
- Android开发之利用动画做出Activity悬浮滑动效果
- 云栖大会 | 马云提出“新制造”战略将影响全球
- 为什么网格布局不显示java_java – 在GridLayout中不显示组件的FlowLayout?
- 一个使用Logging Application Block的小问题[xgluxv]
- 面试:Java分派机制
- Linux shell的条件判断、循环语句及实例
- oracle异构迁移,异构数据库系统迁移到Oracle 工具 - Oracle SQL Developer
- 基于Starling移动项目开发准备工作
- C++ STL 堆(heap)的初始化及其正确使用
- js实现xml转json和json转xml
- 让瓶子里的小人跟你互动,它是怎么做到的?
- 欧美IT外包的几种业务模式
- PostgreSQL入门基本语法之DDL-(user、database、schema)
- Obsidian学习从0到1 —— 使用技巧
- IO与CPU跟线程的关系
热门文章
- 重点计算机应用基础2010,计算机应用基础WIN7+OFFICE2010_课件重点.ppt
- 深入理解服务器CPU三大体系结构--SMP、NUMA、MPP
- RP原型资源分享-购物类App
- 我和关注我的前1000个粉丝“合影”啦,收集前1000个粉丝进行了一系列数据分析,收获满满
- dcloud如何苹果ios系统真机测试-HBuilderX真机运行ios测试
- 解决更改Maven本地仓库地址springboot项目报错,永久设置Maven本地仓库地址的方法
- 大数据项目之Flink实时数仓(数据采集/ODS层)
- python包和库的区别_python的库和包
- gslx680触摸屏驱动源码码分析(gslX680.c)
- python数据分析(五)——numpy+matplotlib实例