互联网面试知识点总结(算法,后端)
大厂面试知识点总结
文章目录
- 大厂面试知识点总结
- 操作系统&计算机组成原理
- 操作系统的一般功能
- 操作系统结构
- 并发与并行 concurrency和parallelism
- 进程,线程和协程
- 进程之间通信的方式(8种)
- 阻塞与非阻塞, 同步与异步
- I/O操作分类(软件访问硬件)
- 分页,分段,虚拟地址
- 计算机网络
- 浏览器输入一个URL(域名),到显示界面的过程
- TCP和UDP
- TCP
- UDP
- HTTP和HTTPS
- HTTP
- HTTPS
- **HTTP不同版本(1.0,1.1,2.0)**
- SSL和TLS
- C/C++
- 语法相关
- const
- #define
- static
- this指针
- inline 内联函数
- **预编译,编译,汇编,链接**
- 虚函数,纯虚函数
- 多态性
- **C++多态类型**:
- 动态多态:基于**继承机制和虚函数**来实现的。
- 静态多态:编译时实现
- 由**模板**具现完成,也就是实例化模板,赋实参时实现。
- 函数多态:基于函数重载。
- 宏多态:基于带变量的宏实现。
- C++ 11中的几种锁
- 1. 互斥”锁 “ mutex
- 2. 条件锁(condition variable)
- 3.自旋锁(不推荐使用)
- 4.递归锁
- C++ 11的新特性
- 新模板
- 新语法
- Python
- 参数传递(值传递,引用传递)
- 拷贝(直接赋值,深拷贝,浅拷贝)
- JAVA
- 基础概念:
- 数据库
- 数据不一致性
- 事务隔离级别
- 数据结构与算法
- 二叉树
- 完全二叉树:
- AVL树
- 红黑树
- 堆排序
- 代码实现
- 最大堆和最小堆
- 典型面试题型:TopK算法
- 七大排序
操作系统&计算机组成原理
操作系统的一般功能
- 进程管理:进程管理的主要作用就是任务调度,在单核处理器下,操作系统会为每个进程分配一个任务,进程管理的工作十分简单;而在多核处理器下,操作系统除了要为进程分配任务外,还要解决处理器的调度、分配和回收等问题
- 内存管理:内存管理主要是操作系统负责管理内存的分配、回收,在进程需要时分配内存以及在进程完成时回收内存,协调内存资源,通过合理的页面置换算法进行页面的换入换出
- 设备管理:根据确定的设备分配原则对设备进行分配,使设备与主机能够并行工作,为用户提供良好的设备使用界面。
- 文件管理:有效地管理文件的存储空间,合理地组织和管理文件系统,为文件访问和文件保护提供更有效的方法及手段。
- 提供用户接口(I/O):操作系统提供了访问应用程序和硬件的接口,使用户能够通过应用程序发起系统调用从而操纵硬件,实现想要的功能
操作系统结构
单体系统
整个系统在内核态以单一程序的方式运行,主程序+服务程序+实用程序
分层系统
用层来分隔不同的功能单元,每一层只与该层的上层和下层通信
微内核
客户-服务器模式,将进程分成两类:
- 服务器:用于提供服务
- 客户端:使用这些服务
并发与并行 concurrency和parallelism
并发: 几个程序在同一个CPU上“同时”运行,但在任意一个时间点上,只有一个程序在CPU上运行;单核CPU不可能真正意义上同时运行不同程序
并行:当操作系统有多个CPU时,不同CPU分别运行不同程序
进程,线程和协程
进程是对运行时程序的封装,是系统进行资源调度和分配的的基本单位,实现了操作系统的并发;
线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发
协程是异步机制,而线程和进程都是同步机制,协程是一种用户态的轻量级线程(也称微线程), 一个线程/进程可以拥有多个协程
进程之间通信的方式(8种)
匿名管道通信
管道是一种半双工的通信方式,数据只能单向流动
高级管道通信
将另一个程序当做一个新的进程在当前程序进程中启动,则它算是当前程序的子进程
有名管道通信(named pipe)
有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
消息队列通信
一种异步的服务间通信方式
信号量通信
不同进程/线程之间的同步手段,多用于进程间的同步和互斥
信号
用于通知进程某个事件已经发生
共享内存通信
映射一段多个进程都可以访问的内存(即共享)
套接字通信
可以用于不同机器之间的进程通信
阻塞与非阻塞, 同步与异步
阻塞是指调用线程或者进程被操作系统挂起;
非阻塞是指调用线程或者进程不会被操作系统挂起。
同步是阻塞模式,进程需要等待请求的反馈才能继续(被挂起)
异步是非阻塞模式,进程不用等待反馈就继续,不用管其他进程状态
I/O操作分类(软件访问硬件)
软件方式:
- 直接访问
- 中断访问
硬件方式:
- DMA(直接内存访问):不需要CPU介入,独立读写系统内存
- 通道控制方式:对DMA的发展,使CPU参与数据传输的控制减少
分页,分段,虚拟地址
分段是为了使程序和数据可以被划分为逻辑上独立的地址空间,并且有助于共享和保护;对程序员不透明(汇编语言内要分段,代码段,数据段,堆栈段…)
逻辑地址,划分为段首地址+段内偏移量,需要替换成物理地址
分页是为了提高内存利用率,实现虚拟地址,获得更大的地址空间,对程序员透明;
虚拟地址,划分为页目录表首地址+页表首地址+页内偏移量,需要替换成逻辑地址——>再换成物理地址
计算机网络
浏览器输入一个URL(域名),到显示界面的过程
1.查找域名对应的IP地址(DNS解析)
- 在本地查找域名的 IP 地址 host文件等
- 发到本地DNS服务器查找
- 根DNS服务器查找
2.建立TCP连接
三次握手过程
3.发送HTTP请求,服务器返回HTTP响应文档
服务器返回HTTP报文。HTTP面向事务,不建立连接(无连接)
4.浏览器解析渲染页面
收到HTML响应后渲染,绘制网页
5.断开TCP连接
四次挥手
TCP和UDP
| 是否面向连接 | 可靠性 | 传输形式 | 传输效率 | 消耗资源 | 应用场景 | 首部字节 | |
|---|---|---|---|---|---|---|---|
| TCP | 面向连接 | 可靠 | 字节流 | 慢 | 多 | 文件/邮件传输 | 20~60 |
| UDP | 无连接 | 不可靠 | 数据报文段 | 快 | 少 | 视频/语音传输 | 8 |
TCP
TCP是面向连接(传输数据前先建立连接/信道),一对一的可靠传输协议
首部:20个字节是固定的,可以根据需要增加更多字节,最短为20Byte
包含源端口,目的端口,序号(每一个字节流都按顺序编号),确认号(期望收到对方下一个字节流的序号),数据偏移(报文首部的实际长度),6个控制位,窗口(自己的接收窗口),校验和,紧急指针
正常传输的时候:每一个报文的序号seq=上一个收到的报文确认号ack;每一个报文的确认号ack=上一个收到的报文序号seq+1
建立连接:三次握手:
A发起连接请求,B回复ack,A再确认B的ack
原因/为什么多一次握手:
- 确认双方的接受能力,发送能力是否正常
- 指定自己的初始化序列号,为后面的可靠传送做准备
- 为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误
- 防止服务器端资源浪费,第三次握手不成功时服务器端及时释放资源
释放连接:四次挥手:
A发连接释放报文段(FIN=1),B收到后发完剩下数据+确认,A再次确认并等待一段时间(2MSL)
原因/为什么TIME WAIT:
- 预防第四次握手(A的ack确认)报文丢失,以备重传
- 确保本次连接相关的所有报文从网络中消失
有效传输,拥塞控制:
拥塞控制原理:
慢启动阈值 + 拥塞避免
指数级慢慢翻倍窗口大小 ,达到阈值后改为累加(拥塞避免)
快速重传
快速恢复
UDP
UDP无连接,不保证可靠传输,可以一对一,一对多,多对多
首部:8个字节,源端口,目的端口,(数据报)长度,校验和
HTTP和HTTPS
HTTP
HTTP 是应用层的超文本数据传输协议,在TCP连接建立后传输数据(面向事务),无连接,无状态(服务器不记得客户)
HTTP状态码:
- 1xx:表示目前是协议的中间状态,还需要后续请求
- 2xx:表示请求成功
- 3xx:表示重定向状态,需要重新请求
- 4xx:表示请求报文错误
- 5xx:服务器端错误
常用状态码…(抄)
常用方法:GET, HEAD, POST, PUT, DELETE…
HTTPS
因为HTTP不安全,传输时有可能被截获,修改或伪造发送者。
原理: HTTP + SSL(TLS) = HTTPS
三个关键指标:加密(Encryption),数据一致性(Data integrity),身份认证(Authentication)
HTTP不同版本(1.0,1.1,2.0)
- HTTP/1.0 每次请求都需要建立一个TCP连接,服务器处理完请求就断开TCP连接
- HTTP/1.1 TCP连接默认不关闭,可以被多个请求复用
- HTTP/2.0 多路复用,同一个连接里,客户端和服务器都可以同时发送多个请求或回应,而且不用按照顺序一一对应
SSL和TLS
SSL/TLS是于在互联网两台计算机之间用于身份验证和加密的安全协议,公钥加密,私钥解密;介乎于TCP和HTTP之间,替代了HTTP通信接口。
TLS是SSL的升级版。
C/C++
语法相关
const
作用:
- 修饰变量,指针,成员函数(表示该函数不能修改成员变量),不能修饰引用
- 指针分为指向常量的指针(pointer to const)和自身是常量的指针(const pointer)
#define
和const区分:
| 宏定义 #define | const 常量 |
|---|---|
| 宏定义,相当于字符替换 | 常量声明 |
| 预处理阶段处理 | 编译阶段处理 |
| 无类型安全检查 | 有类型安全检查 |
| 不分配内存 | 要分配内存 |
| 存储在代码段 | 存储在数据段 |
可通过 #undef 取消
|
不可取消 |
static
- 修饰普通变量,修改变量的存储区域和生命周期(被定义的整个文件内有效),使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰普通函数,表明函数的作用范围,该函数仅在被定义的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
this指针
指向调用该成员函数的那个对象,相当于Python里的self。当对一个对象调用成员函数时,编译程序先将对象的地址赋给
this指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用this指针。在以下场景中,经常需要显式引用this指针:
- 为实现对象的链式引用,比如用
return *this返回当前对象本身 - 为避免对同一对象进行赋值操作,用this进行区分
- 在实现一些数据结构时,如
list。
- 为实现对象的链式引用,比如用
inline 内联函数
相当于把内联函数体直接写在调用内联函数的地方,内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
预编译,编译,汇编,链接
从代码.cpp生成可执行文件.exe的过程:
- 预编译:展开宏定义,头文件,去除注释等,得到纯净的.c文件
- 编译:对.c进行语法和语义检查,得到汇编文件
- 汇编:生成二进制文件
- 链接:把所有目标文件链接成一个可执行文件.exe
虚函数,纯虚函数
虚函数的作用是允许在子类中重新定义与父类同名的函数,并且可以只通过父类指针或引用来访问父类和子类的同名函数(后者即虚函数),即统一了同名函数的调用方式,带来便利。
代码:函数声明前加virtual,一般在基类声明时加上(子类的同名函数也会自动变虚函数)
每个含有虚函数的类都有一个虚函数表(v-table),虚函数表可以继承
纯虚函数:在**基类**中声明的虚函数,在基类中没有定义,但要求任何派生类都要定义自己的实现方法;包含纯虚函数的类称为抽象类,不能实例化
作用:为了更方便地使用多态性,而且也更贴合实际(比如“动物”不应该有具体实例,派生类“虎”“兔”才有)
代码:virtual,参数加“=0”
多态性
定义:同一种事物所表现出的多种形态,“一个接口多种实现”, 比如不同动物叫声不同(但都是"动物"类的子类对象)
类型(两种):
- 静态的,编译时的多态性,重载来实现
- 动态的,运行时的多态性,虚成员来实现
C++多态类型:
动态多态:基于继承机制和虚函数来实现的。
静态多态:编译时实现
由模板具现完成,也就是实例化模板,赋实参时实现。
函数多态:基于函数重载。
宏多态:基于带变量的宏实现。
C++ 11中的几种锁
1. 互斥”锁 “ mutex
多线程编程中的互斥锁,即mutex(互斥量)
用于提供访问保护,保护变量被读写时不被其他线程修改,当前线程读写完成后一定要释放锁,否则会导致死锁
2. 条件锁(condition variable)
就是所谓的条件变量,在相应条件为满足时令线程处于阻塞状态;条件满足时则唤醒该线程
3.自旋锁(不推荐使用)
自旋锁是一种基础的同步原语,用于保障对共享数据的互斥访问
与互斥锁的对比:在获取锁失败的时候不会使得线程阻塞而是一直自旋尝试获取锁,当线程等待自旋锁的时候,CPU不能做其他事情,而是一直处于轮询等待的状态。互斥锁是sleep-waiting,自旋锁是busy-waiting
自旋锁主要适用于被持有时间短,线程不希望再重新调度上花费过多时间的情况。
4.递归锁
recursive_mutex 是同步原语,能够保护共享数据免受多个线程同时访问
C++ 11的新特性
新模板
lambda匿名函数, tuple, array, forward_list
新语法
for的新写法,auto关键字
…
Python
参数传递(值传递,引用传递)
不可变对象:地址和值都不可变,包括数字,字符串,元组
可变对象:地址不可变,值可变,包括列表,字典,集合
不可变对象的传递都属于值传递,
可变对象的传递属于引用传递。
拷贝(直接赋值,深拷贝,浅拷贝)
直接赋值:就是对象的引用,父对象和子对象都一样
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的deepcopy 方法,完全拷贝了父对象及其子对象。
JAVA
基础概念:
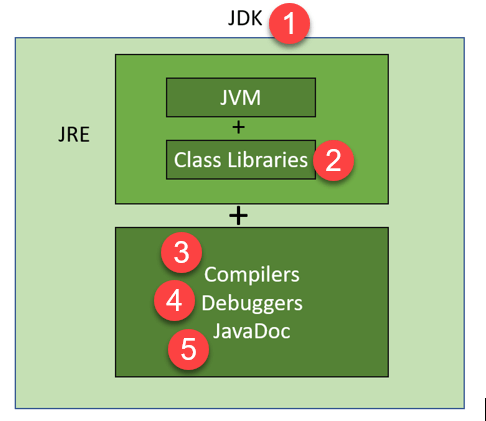
JVM: Java Virtual Machine Java虚拟机
JRE: Java Runtime Environment Java运行环境
JDK: Java Development Kit Java开发工具包
Java语言特点:
- 简单易学(Java语言的语法与C语言和C++语言很接近)
- 面向对象(封装,继承,多态)
- 平台无关性(Java虚拟机实现平台无关性,不受计算机端本身约束)
- 支持网络编程并且很方便(Java语言诞生本身就是为简化网络编程设计的)
- 支持多线程(多线程机制使应用程序在同一时间并行执行多项任)
- 健壮性(Java语言的强类型机制、异常处理、垃圾的自动收集等)
- 安全性
数据库
数据不一致性
数据冗余造成
并发操作造成数据不一致
- 丢失修改
- 不可重复读
- 读“脏数据”
由于各种故障,错误造成
事务隔离级别
排序由高到低,来避免数据不一致性,分别为:
- Serializable(序列化)
- Repeatable read(可重复读)
- Read Committed(已提交读)
- Read Uncommitted(未提交读) 会有“脏读”的问题
数据结构与算法
二叉树
完全二叉树:
- 若设二叉树的深度为h,除第h层外,其它各层(1~h-1) 的结点数都达到最大个数,第h层所有的结点都连续集中在最左边,这就是完全二叉树
- 节点数目相关公式:2h−1−1<N≤2h−12^{h-1}-1<N\leq2^{h-1}2h−1−1<N≤2h−1, 其中NNN为完全二叉树节点数
AVL树
左右子树的高度差绝对值不超过1
平衡因子BF=左子树高度−-−右子树高度
是高度平衡的,频繁插入和删除会引起频繁调整导致效率下降
红黑树
特征:
- 每个节点不是红色就是黑色
- 根节点为黑色
- 没有连续的红色节点
- 每个节点到叶子节点的路径上黑色节点数目相同
- NULL节点是黑色
结论:任意一个节点到叶子节点,红黑树保证最长路径不超过最短路径的二倍,因而近似平衡
红黑树不是高度平衡的。 插入,删除,和查找很高效。
堆排序
代码实现
两个子函数:堆调整(adjust)和swap
排序过程:先建堆,再进入循环:swap堆顶和数组末尾
void heapSort(int arr[], int size)
{for(int i=size/2 - 1; i >= 0; i--) // 对每一个非叶结点进行堆调整(从最后一个非叶结点开始){adjust(arr, size, i);}for(int i = size - 1; i >= 1; i--){swap(arr[0], arr[i]); // 将当前最大的放置到数组末尾adjust(arr, i, 0); // 将未完成排序的部分继续进行堆排序}
}
最大堆和最小堆
最大堆:每个结点的值都大于或等于其左右孩子结点的值
最小堆:每个结点的值都小于或等于其左右孩子结点的值
典型面试题型:TopK算法
大量数据中找出Top K(前K个)元素,适合用堆解决
维护一个大小为K的大顶堆:按顺序遍历N个元素并插入堆中,直到堆满。
然后堆顶和下一个元素比较,
if 堆顶>=下一个元素 忽略
if 堆顶<下一个元素 将堆顶抛弃,然后下一个元素插入堆中
如此反复,遍历完所有数据,堆里的就是Top K个元素。
空间复杂度:O(K)(内存中只需维护一个很小的堆)
时间复杂度:O(Nlog(K))(内存中只需维护一个很小的堆)
七大排序
稳定排序:冒泡排序,简单选择排序,直接插入排序,归并排序
不稳定排序:希尔排序,堆排序,快速排序
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 直接插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(nlogn)~O(n^2) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | O(logn)~O(n) | 不稳定 |
互联网面试知识点总结(算法,后端)相关推荐
- 互联网面试知识点总结(三)- 计算机网络篇
互联网面试知识点总结(三)- 计算机网络篇 ******************************* 概 述 ******************************* 一. OSI七层模型 ...
- 后端面试知识点大串烧(蚂蚁美团头条腾讯面试经历)
笔者在面过 猿辅导,去哪儿,旷视, 陌陌,头条, 阿里, 快手, 美团, 腾讯之后,除了收获一大堆面试问题,还思考到如何成为面试官眼中的"爱技术,爱思考,靠谱,有潜力候选人的"一些 ...
- 机器学习算法工程师面试知识点汇总
机器学习算法工程师面试知识点汇总 机器学习 梯度下降 k-means 1 × 1卷积核 模型 SVM Bagging & Boosting 随机森林 激活函数 Sigmod tanh ReLU ...
- 深度学习算法工程师面试知识点总结(四)
这是算法工程师面试知识点总结的第四篇,有兴趣的朋友可以看看前三篇的内容: 深度学习算法工程师面试知识点总结(一) 深度学习算法工程师面试知识点总结(二) 深度学习算法工程师面试知识点总结(三) 基于t ...
- Java 面试知识点解析(七)——Web篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Redis面试知识点
Redis面试知识点 1.Redis概述 在我们日常的Java Web开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉 ...
- java后端面试大全,java后端面试宝典
文章目录 -2 flink -1 linux of view linux查看占用cup最高的10个进程的命令: 〇.分布式锁 & 分布式事务 0-1分布式锁--包含CAP理论模型 概述 分布式 ...
- Java面试知识点(全)- Java面试基础部分三
Java面试知识点(全)https://nanxiang.blog.csdn.net/article/details/130640392 注:随时更新 文章目录 ThreadPoolExecutor ...
- 程序员如何快速准备面试中的算法 - 结构之法
准备面试.学习算法,特别推荐最新出版的我的新书<编程之法:面试和算法心得>,已经上架京东等各大网店 前言 我决定写篇短文,即为此文.之所以要写这篇文章,缘于微博上常有朋友询问,要毕业找工作 ...
最新文章
- html表格中加入斜线,在HTML中显示带斜线的表格
- 皮一皮:有一种着急叫做妈妈想你快点脱单...
- 河南大学生带着捡来的妹妹求学12年
- 汇编语言的程序设计方法(循环结构和分支结构)
- HTML5边玩边学(9):俄罗斯方块就是这么简单 之 数据模型篇
- IDEA优雅整合Maven+SSM框架(详细思路+附带源码)
- deepin 安装cuda 编译 ffmpeg
- excel制作录入和查询系统_叮咚!您有一份Excel人员信息查询系统,请您查收~
- 如何在 Mac 上映射网络驱动器
- 在哪下拼多多上传助手?拼多多软件方法介绍
- 电脑开机加速,一下子就提升了20几秒
- Hack The Box——Academy
- 打印正六边形(C语言)
- 蓄电池内阻测试仪分析软件,福禄克 Fluke BT500系列蓄电池内阻测试仪
- excel数据处理_有没有可以完全替代并超越excel的表格和数据处理软件?
- html头像动画,用CSS3实现头像旋转效动画
- Photoshop照片一键转换手绘效果图动作
- 华为服务器安装nas系统,服务器 nas 配置
- HTML表单基本格式与代码
- css 多文件上传框美化