WIN10 +pytorch版yolov3训练自己数据集
pytorch版yolov3训练自己数据集
目录
- 1. 环境搭建
- 2. 数据集构建
- 3. 训练模型
- 4. 测试模型
- 5. 评估模型
- 6. 可视化
- 7. 高级进阶-网络结构更改
1. 环境搭建
- 将github库download下来。
git clone https://github.com/ultralytics/yolov3.git- 建议在linux环境下使用anaconda进行搭建
conda create -n yolov3 python=3.7- 安装需要的软件
pip install -r requirements.txt环境要求:
- python >= 3.7
- pytorch >= 1.1
- numpy
- tqdm
- opencv-python
其中只需要注意pytorch的安装:
到https://pytorch.org/中根据操作系统,python版本,cuda版本等选择命令即可。
关于深度学习环境搭建请参看:https://www.cnblogs.com/pprp/p/9463974.html
anaconda常用用法:https://www.cnblogs.com/pprp/p/9463124.html
2. 数据集构建
1. xml文件生成需要Labelimg软件
在Windows下使用:wget https://github.com/pprp/DeepLearning/blob/master/windows_v1.5.1/labelImg.exe- 使用快捷键:
Ctrl + u 加载目录中的所有图像,鼠标点击Open dir同功能
Ctrl + r 更改默认注释目标目录(xml文件保存的地址)
Ctrl + s 保存
Ctrl + d 复制当前标签和矩形框
space 将当前图像标记为已验证
w 创建一个矩形框
d 下一张图片
a 上一张图片
del 删除选定的矩形框
Ctrl++ 放大
Ctrl-- 缩小
↑→↓← 键盘箭头移动选定的矩形框2. VOC2007 数据集格式
-data- VOCdevkit2007- VOC2007- Annotations (标签XML文件,用对应的图片处理工具人工生成的)- ImageSets (生成的方法是用sh或者MATLAB语言生成)- Main- test.txt- train.txt- trainval.txt- val.txt- JPEGImages(原始文件)- labels (xml文件对应的txt文件)通过以上软件主要构造好JPEGImages和Annotations文件夹中内容,Main文件夹中的txt文件可以通过python脚本生成:
import os
import random trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath) num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close()
ftrain.close()
fval.close()
ftest.close()生成labels文件,voc_label.py文件具体内容如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 2 11:42:13 2018
将本文件放到VOC2007目录下,然后就可以直接运行
需要修改的地方:
1. sets中替换为自己的数据集
2. classes中替换为自己的类别
3. 将本文件放到VOC2007目录下
4. 直接开始运行
"""import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] #替换为自己的数据集
classes = ["head", "eye", "nose"] #修改为自己的类别
#classes = ["eye", "nose"]def convert(size, box):dw = 1./(size[0])dh = 1./(size[1])x = (box[0] + box[1])/2.0 - 1y = (box[2] + box[3])/2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h)
def convert_annotation(year, image_id):in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id)) #将数据集放于当前目录下out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')tree=ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult)==1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))bb = convert((w,h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:if not os.path.exists('VOC%s/labels/'%(year)):os.makedirs('VOC%s/labels/'%(year))image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()list_file = open('%s_%s.txt'%(year, image_set), 'w')for image_id in image_ids:list_file.write('VOC%s/JPEGImages/%s.jpg\n'%(year, image_id))convert_annotation(year, image_id)list_file.close()
#os.system("cat 2007_train.txt 2007_val.txt > train.txt") #修改为自己的数据集用作训练到底为止,VOC格式数据集构造完毕,但是还需要继续构造符合darknet格式的数据集(coco)。
需要说明的是:如果打算使用coco评价标准,需要构造coco中json格式,如果要求不高,只需要VOC格式即可,使用作者写的mAP计算程序即可。
voc的xml转coco的json文件脚本:xml2json.py
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 28 15:01:03 2018
需要改动xml_path and json_path
"""
#!/usr/bin/python
# -*- coding:utf-8 -*-
# @Description: xml转换到coco数据集json格式import os, sys, json,xmltodictfrom xml.etree.ElementTree import ElementTree, Element
from collections import OrderedDictXML_PATH = "/home/learner/datasets/VOCdevkit2007/VOC2007/Annotations/test"
JSON_PATH = "./test.json"
json_obj = {}
images = []
annotations = []
categories = []
categories_list = []
annotation_id = 1def read_xml(in_path):'''读取并解析xml文件'''tree = ElementTree()tree.parse(in_path)return treedef if_match(node, kv_map):'''判断某个节点是否包含所有传入参数属性node: 节点kv_map: 属性及属性值组成的map'''for key in kv_map:if node.get(key) != kv_map.get(key):return Falsereturn Truedef get_node_by_keyvalue(nodelist, kv_map):'''根据属性及属性值定位符合的节点,返回节点nodelist: 节点列表kv_map: 匹配属性及属性值map'''result_nodes = []for node in nodelist:if if_match(node, kv_map):result_nodes.append(node)return result_nodesdef find_nodes(tree, path):'''查找某个路径匹配的所有节点tree: xml树path: 节点路径'''return tree.findall(path)print ("-----------------Start------------------")
xml_names = []
for xml in os.listdir(XML_PATH):#os.path.splitext(xml)#xml=xml.replace('Cow_','')xml_names.append(xml)'''xml_path_list=os.listdir(XML_PATH)
os.path.split
xml_path_list.sort(key=len)'''
xml_names.sort(key=lambda x:int(x[:-4]))
new_xml_names = []
for i in xml_names:j = 'Cow_' + inew_xml_names.append(j)#print xml_names
#print new_xml_names
for xml in new_xml_names:tree = read_xml(XML_PATH + "/" + xml)object_nodes = get_node_by_keyvalue(find_nodes(tree, "object"), {})if len(object_nodes) == 0:print (xml, "no object")continueelse:image = OrderedDict()file_name = os.path.splitext(xml)[0]; # 文件名#print os.path.splitext(xml)para1 = file_name + ".jpg"height_nodes = get_node_by_keyvalue(find_nodes(tree, "size/height"), {})para2 = int(height_nodes[0].text)width_nodes = get_node_by_keyvalue(find_nodes(tree, "size/width"), {})para3 = int(width_nodes[0].text)fname=file_name[4:]para4 = int(fname)for f,i in [("file_name",para1),("height",para2),("width",para3),("id",para4)]:image.setdefault(f,i)#print(image)images.append(image) #构建imagesname_nodes = get_node_by_keyvalue(find_nodes(tree, "object/name"), {})xmin_nodes = get_node_by_keyvalue(find_nodes(tree, "object/bndbox/xmin"), {})ymin_nodes = get_node_by_keyvalue(find_nodes(tree, "object/bndbox/ymin"), {})xmax_nodes = get_node_by_keyvalue(find_nodes(tree, "object/bndbox/xmax"), {})ymax_nodes = get_node_by_keyvalue(find_nodes(tree, "object/bndbox/ymax"), {})# print ymax_nodesfor index, node in enumerate(object_nodes):annotation = {}segmentation = []bbox = []seg_coordinate = [] #坐标seg_coordinate.append(int(xmin_nodes[index].text))seg_coordinate.append(int(ymin_nodes[index].text))seg_coordinate.append(int(xmin_nodes[index].text))seg_coordinate.append(int(ymax_nodes[index].text))seg_coordinate.append(int(xmax_nodes[index].text))seg_coordinate.append(int(ymax_nodes[index].text))seg_coordinate.append(int(xmax_nodes[index].text))seg_coordinate.append(int(ymin_nodes[index].text))segmentation.append(seg_coordinate)width = int(xmax_nodes[index].text) - int(xmin_nodes[index].text)height = int(ymax_nodes[index].text) - int(ymin_nodes[index].text)area = width * heightbbox.append(int(xmin_nodes[index].text))bbox.append(int(ymin_nodes[index].text))bbox.append(width)bbox.append(height)annotation["segmentation"] = segmentationannotation["area"] = areaannotation["iscrowd"] = 0fname=file_name[4:]annotation["image_id"] = int(fname)annotation["bbox"] = bboxcate=name_nodes[index].textif cate=='head':category_id=1elif cate=='eye':category_id=2elif cate=='nose':category_id=3annotation["category_id"] = category_idannotation["id"] = annotation_idannotation_id += 1annotation["ignore"] = 0annotations.append(annotation)if category_id in categories_list:passelse:categories_list.append(category_id)categorie = {}categorie["supercategory"] = "none"categorie["id"] = category_idcategorie["name"] = name_nodes[index].textcategories.append(categorie)json_obj["images"] = images
json_obj["type"] = "instances"
json_obj["annotations"] = annotations
json_obj["categories"] = categoriesf = open(JSON_PATH, "w")
#json.dump(json_obj, f)
json_str = json.dumps(json_obj)
f.write(json_str)
print ("------------------End-------------------")(运行bash yolov3/data/get_coco_dataset.sh,仿照格式将数据放到其中)
但是这个库还需要其他模型:
3. 创建*.names file,
其中保存的是你的所有的类别,每行一个类别,如data/coco.names:
head
eye
nose4. 更新data/coco.data,其中保存的是很多配置信息
classes = 3 # 改成你的数据集的类别个数
train = ./data/2007_train.txt # 通过voc_label.py文件生成的txt文件
valid = ./data/2007_test.txt # 通过voc_label.py文件生成的txt文件
names = data/coco.names # 记录类别
backup = backup/ # 记录checkpoint存放位置
eval = coco # 选择map计算方式5. 更新cfg文件,修改类别相关信息
打开cfg文件夹下的yolov3.cfg文件,大体而言,cfg文件记录的是整个网络的结构,是核心部分,具体内容讲解请见:https://pprp.github.io/2018/09/20/tricks.html
只需要更改每个[yolo]层前边卷积层的filter个数即可:
每一个[region/yolo]层前的最后一个卷积层中的 filters=num(yolo层个数)*(classes+5) ,5的意义是5个坐标,论文中的tx,ty,tw,th,po
举个例子:我有三个类,n = 3, 那么filter = 3 * (3+5) = 21
[convolutional]
size=1
stride=1
pad=1
filters=255 # 改为 21
activation=linear[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 # 改为 3
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=16. 数据集格式说明
- yolov3- data- 2007_train.txt- 2007_test.txt- coco.names- coco.data- annotations(json files)- images(将2007_train.txt中的图片放到train2014文件夹中,test同理)- train2014- 0001.jpg- 0002.jpg- val2014- 0003.jpg- 0004.jpg- labels(voc_labels.py生成的内容需要重新组织一下)- train2014- 0001.txt- 0002.txt- val2014- 0003.txt- 0004.txt- samples(存放待测试图片)2007_train.txt内容示例:
/home/dpj/yolov3-master/data/images/val2014/Cow_1192.jpg
/home/dpj/yolov3-master/data/images/val2014/Cow_1196.jpg
.....注意images和labels文件架构一致性,因为txt是通过简单的替换得到的:
images -> labels
.jpg -> .txt3. 训练模型
预训练模型:
- Darknet
*.weightsformat: https://pjreddie.com/media/files/yolov3.weights - PyTorch
*.ptformat: https://drive.google.com/drive/folders/1uxgUBemJVw9wZsdpboYbzUN4bcRhsuAI
开始训练:
python train.py --data data/coco.data --cfg cfg/yolov3.cfg如果日志正常输出那证明可以运行了
![]()
如果中断了,可以恢复训练
python train.py --data data/coco.data --cfg cfg/yolov3.cfg --resume4. 测试模型
将待测试图片放到data/samples中,然后运行
python detect.py --weights weights/best.pt5. 评估模型
python test.py --weights weights/latest.pt如果使用cocoAPI使用以下命令:
git clone https://github.com/cocodataset/cocoapi && cd cocoapi/PythonAPI && make && cd ../.. && cp -r cocoapi/PythonAPI/pycocotools yolov3
cd yolov3python3 test.py --save-json --img-size 416
Namespace(batch_size=32, cfg='cfg/yolov3-spp.cfg', conf_thres=0.001, data_cfg='data/coco.data', img_size=416, iou_thres=0.5, nms_thres=0.5, save_json=True, weights='weights/yolov3-spp.weights')
Using CUDA device0 _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', total_memory=16130MB)Class Images Targets P R mAP F1
Calculating mAP: 100%|█████████████████████████████████████████| 157/157 [05:59<00:00, 1.71s/it]all 5e+03 3.58e+04 0.109 0.773 0.57 0.186Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.335Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.565Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.349Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.151Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.360Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.493Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.280Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.432Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.458Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.255Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.494Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.620python3 test.py --save-json --img-size 608 --batch-size 16
Namespace(batch_size=16, cfg='cfg/yolov3-spp.cfg', conf_thres=0.001, data_cfg='data/coco.data', img_size=608, iou_thres=0.5, nms_thres=0.5, save_json=True, weights='weights/yolov3-spp.weights')
Using CUDA device0 _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', total_memory=16130MB)Class Images Targets P R mAP F1
Computing mAP: 100%|█████████████████████████████████████████| 313/313 [06:11<00:00, 1.01it/s]all 5e+03 3.58e+04 0.12 0.81 0.611 0.203Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.366Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.607Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.386Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.207Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.391Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.485Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.296Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.464Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.494Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.331Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.517Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.6186. 可视化
可以使用python -c from utils import utils;utils.plot_results()
创建drawLog.py
def plot_results():# Plot YOLO training results file 'results.txt'import globimport numpy as npimport matplotlib.pyplot as plt#import os; os.system('rm -rf results.txt && wget https://storage.googleapis.com/ultralytics/results_v1_0.txt')plt.figure(figsize=(16, 8))s = ['X', 'Y', 'Width', 'Height', 'Objectness', 'Classification', 'Total Loss', 'Precision', 'Recall', 'mAP']files = sorted(glob.glob('results.txt'))for f in files:results = np.loadtxt(f, usecols=[2, 3, 4, 5, 6, 7, 8, 17, 18, 16]).T # column 16 is mAPn = results.shape[1]for i in range(10):plt.subplot(2, 5, i + 1)plt.plot(range(1, n), results[i, 1:], marker='.', label=f)plt.title(s[i])if i == 0:plt.legend()plt.savefig('./plot.png')
if __name__ == "__main__":plot_results()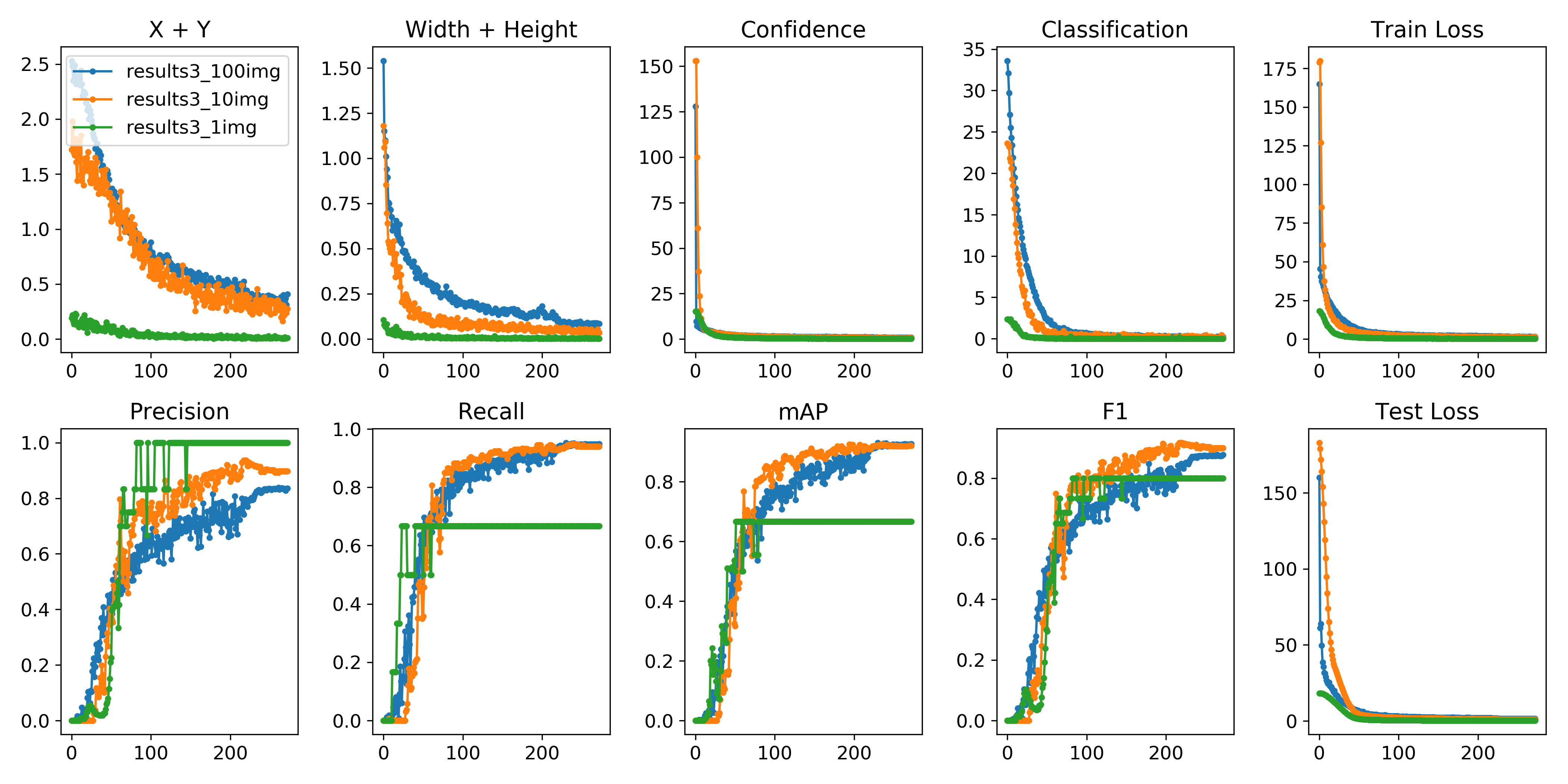
7. 高级进阶-网络结构更改
详细cfg文件讲解:https://pprp.github.io/2018/09/20/tricks.html
参考资料以及网络更改经验:https://pprp.github.io/2018/06/20/yolo.html
欢迎在评论区进行讨论,也便于我继续完善该教程。
代码改变世界
WIN10 +pytorch版yolov3训练自己数据集相关推荐
- 使用pytorch版faster-rcnn训练自己数据集
使用pytorch版faster-rcnn训练自己数据集 引言 faster-rcnn pytorch代码下载 训练自己数据集 接下来工作 参考文献 引言 最近在复现目标检测代码(师兄强烈推荐FPN, ...
- python调用yolov3模型,pytorch版yolov3训练自己的数据(数据,代码,预训练模型下载链接)...
1.数据预处理 准备图片数据(JPEGImages),标注文件(Annotations),以及划分好测试集训练集的索引号(ImageSets) 修改代码中voc_label.py文件中的路径以及类别, ...
- 1 PyTorch版YOLOv3 代码中文注释 之 训练 train.py test.py detect.py
文章目录 PyTorch版YOLOv3 代码中文注释 1. 相关链接: 2. 代码结构: 3. train.py 3.1. train.py 中包含的主要功能 4. test.py 4.1. test ...
- 史上最详细的Pytorch版yolov3代码中文注释详解(四)
史上最详细的Pytorch版yolov3代码中文注释详解(一):https://blog.csdn.net/qq_34199326/article/details/84072505 史上最详细的Pyt ...
- <计算机视觉四> pytorch版yolov3网络搭建
鼠标点击下载 项目源代码免费下载地址 <计算机视觉一> 使用标定工具标定自己的目标检测 <计算机视觉二> labelme标定的数据转换成yolo训练格式 <计算机 ...
- Tensorflow版yolov3训练自己的数据
Tensorflow版yolov3训练自己的数据 源代码:https://github.com/YunYang1994/TensorFlow2.0-Examples/tree/master/4-Obj ...
- yolov3 训练及数据集准备【记录】
------------------------------ 本文仅供学习交流,如有错误,望交流指教 ------------------------------ yolov3 训练及数据集准备[记录 ...
- Pytorch 版YOLOV5训练自己的数据集
1.环境搭建 https://github.com/ultralytics/yolov5 2.安装需要的软件 pip install -U -r requirements.txt 3.准备数据 在da ...
- 【windows10】使用pytorch版本deeplabv3+训练自己数据集
目录 序言 开发环境 一.准备数据集 二.修改配置 三.开始训练 四.模型测试 序言 最近工作需要用到语义分割,跑了一个deeplabv3+的模型,deeplabv3+是一个非常不错的语义分割模型,使 ...
最新文章
- docker逃逸 从Play-with-Docker容器逃逸到Docker主机
- WPS for Linux(ubuntu)字体缺失解决办法(转)
- powerdns mysql_安装PowerDNS(使用MySQL后端)和Poweradmin在Debian Lenny
- maven依赖包下载地址
- Lintcode: Unique Paths
- php判断子字符串位置,PHP怎样查询子字符串位置
- redis安装与基本配置
- 关于嵌入式学习随笔-1《STM32简介》
- POJ2826 An Easy Problem?!
- android cpu降温代码,Android手机CM设置中CPU模式解释
- 【Java必备技能四】如何使用泛型?
- OpenCasCade – 载入IGES文件
- 基于Layabox引擎的魔塔微信小游戏设计与实现
- 手机端用云服务器文件在哪里设置,如何使用FolderSync在安卓手机上同步文件夹到坚果云? | 坚果云帮助中心...
- android自定义listview 显示数组,android TextView控件如何显示Listview数组内容到一个Textview控件上?...
- erlang中的ets和dets
- 【转】当我们说“区块链是无需信任的”,我们的意思是
- JavaScript教程-18-JavaScript中的内置对象Global
- The server encountered an internal error that prevented it from fulfilling this request. exception
- Ureport2 ---报表设计(2)--报表计算模型