客户细分_客户细分初学者指南
客户细分
In this post I’m going to talk about something that’s relatively simple but fundamental to just about any business: Customer Segmentation. At the core of customer segmentation is being able to identify different types of customers and then figure out ways to find more of those individuals so you can… you guessed it, get more customers!
在这篇文章中,我将讨论相对简单但对任何业务都至关重要的事情:客户细分。 客户细分的核心是能够识别不同类型的客户,然后找出找到更多此类个人的方法,以便您……您猜对了,获得了更多客户!
In this post, I’ll detail how you can use K-Means clustering to help with some of the exploratory aspects of customer segmentation. I’ll be walking through the example using Yhat’s own Python IDE, Rodeo, which you can download for Windows, Mac or Linux here. If you’re using a Windows machine, Rodeo ships with Python (via Continuum’s Miniconda). How convenient!
在这篇文章中,我将详细介绍如何使用K-Means聚类来帮助客户细分的一些探索性方面。 我将使用Yhat自己的Python IDE Rodeo遍历该示例,您可以在此处为Windows,Mac或Linux下载该示例。 如果您使用的是Windows计算机,则Rodeo附带Python(通过Continuum的Miniconda)。 多么方便!
我们的数据 (Our Data)
The data we’re using comes from John Foreman’s book Data Smart. The dataset contains both information on marketing newsletters/e-mail campaigns (e-mail offers sent) and transaction level data from customers (which offer customers responded to and what they bought).
我们正在使用的数据来自John Foreman的书Data Smart 。 数据集既包含有关营销新闻通讯/电子邮件活动的信息(发送电子邮件要约),也包含来自客户的交易级别数据(向客户提供响应和购买的商品)。
import pandas as pddf_offers = pd.read_excel("./WineKMC.xlsx", sheetname=0) df_offers.columns = ["offer_id", "campaign", "varietal", "min_qty", "discount", "origin", "past_peak"] df_offers.head()import pandas as pddf_offers = pd.read_excel("./WineKMC.xlsx", sheetname=0) df_offers.columns = ["offer_id", "campaign", "varietal", "min_qty", "discount", "origin", "past_peak"] df_offers.head()
| offer_id | offer_id | campaign | 运动 | varietal | 品种 | min_qty | min_qty | discount | 折扣 | origin | 起源 | past_peak | past_peak | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1个 | January | 一月 | Malbec | 马尔贝克 | 72 | 72 | 56 | 56 | France | 法国 | False | 假 |
| 1 | 1个 | 2 | 2 | January | 一月 | Pinot Noir | 黑比诺 | 72 | 72 | 17 | 17 | France | 法国 | False | 假 |
| 2 | 2 | 3 | 3 | February | 二月 | Espumante | Espumante | 144 | 144 | 32 | 32 | Oregon | 俄勒冈州 | True | 真正 |
| 3 | 3 | 4 | 4 | February | 二月 | Champagne | 香槟酒 | 72 | 72 | 48 | 48 | France | 法国 | True | 真正 |
| 4 | 4 | 5 | 5 | February | 二月 | Cabernet Sauvignon | 赤霞珠 | 144 | 144 | 44 | 44 | New Zealand | 新西兰 | True | 真正 |
And the transaction level data…
还有交易级别的数据…
| customer_name | 顾客姓名 | offer_id | offer_id | n | ñ | ||
|---|---|---|---|---|---|---|---|
| 0 | 0 | Smith | 史密斯 | 2 | 2 | 1 | 1个 |
| 1 | 1个 | Smith | 史密斯 | 24 | 24 | 1 | 1个 |
| 2 | 2 | Johnson | 约翰逊 | 17 | 17 | 1 | 1个 |
| 3 | 3 | Johnson | 约翰逊 | 24 | 24 | 1 | 1个 |
| 4 | 4 | Johnson | 约翰逊 | 26 | 26 | 1 | 1个 |
Inside of Rodeo, that’ll look something like…
在Rodeo内部,外观类似于…
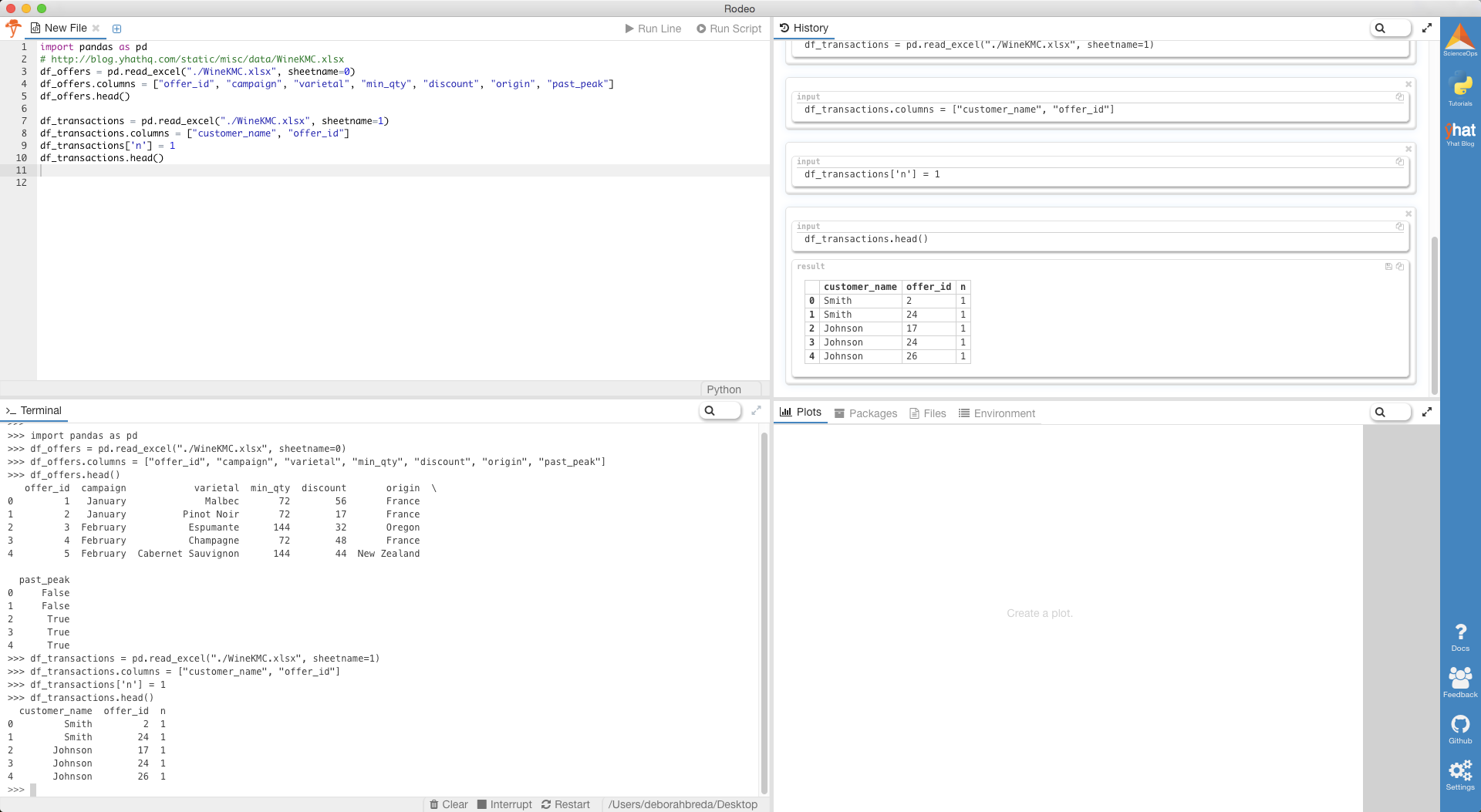
If you’re new to Rodeo, note that you can move and resize tabs, so if you prefer a side-by-side editor and terminal layout, or you want to make the editor full screen, you can.
如果您不熟悉Rodeo,请注意可以移动和调整选项卡的大小,因此,如果您希望并排编辑器和终端布局,或者希望使编辑器全屏显示,则可以。
You can also copy and save the formatted outputs in your history tab, like the data frames we produced above.
您还可以将格式化的输出复制并保存在“历史记录”选项卡中,例如上面我们生成的数据框。
快速的K均值入门 (A quick K-Means primer)
In order to segment our customers, we need a way to compare them. To do this we’re going to use K-Means clustering. K-means is a way of taking a dataset and finding groups (or clusters) of points that have similar properties. K-means works by grouping the points together in such a way that the distance between all the points and the midpoint of the cluster they belong to is minimized.
为了细分我们的客户,我们需要一种比较他们的方法。 为此,我们将使用K-Means聚类 。 K均值是一种获取数据集并查找具有相似属性的点的组(或群集)的方法。 K-means的工作方式是将这些点分组在一起,以使所有点之间的距离以及它们所属的群集的中点最小。
Think of the simplest possible example. If I told you to create 3 groups for the points below and draw a star where the middle of each group would be, what would you do?
想想最简单的例子。 如果我告诉您为下面的点创建3个组,并在每个组的中间画一个星星,您会怎么做?
Probably (or hopefully) something like this…
可能(或希望)这样的事情……
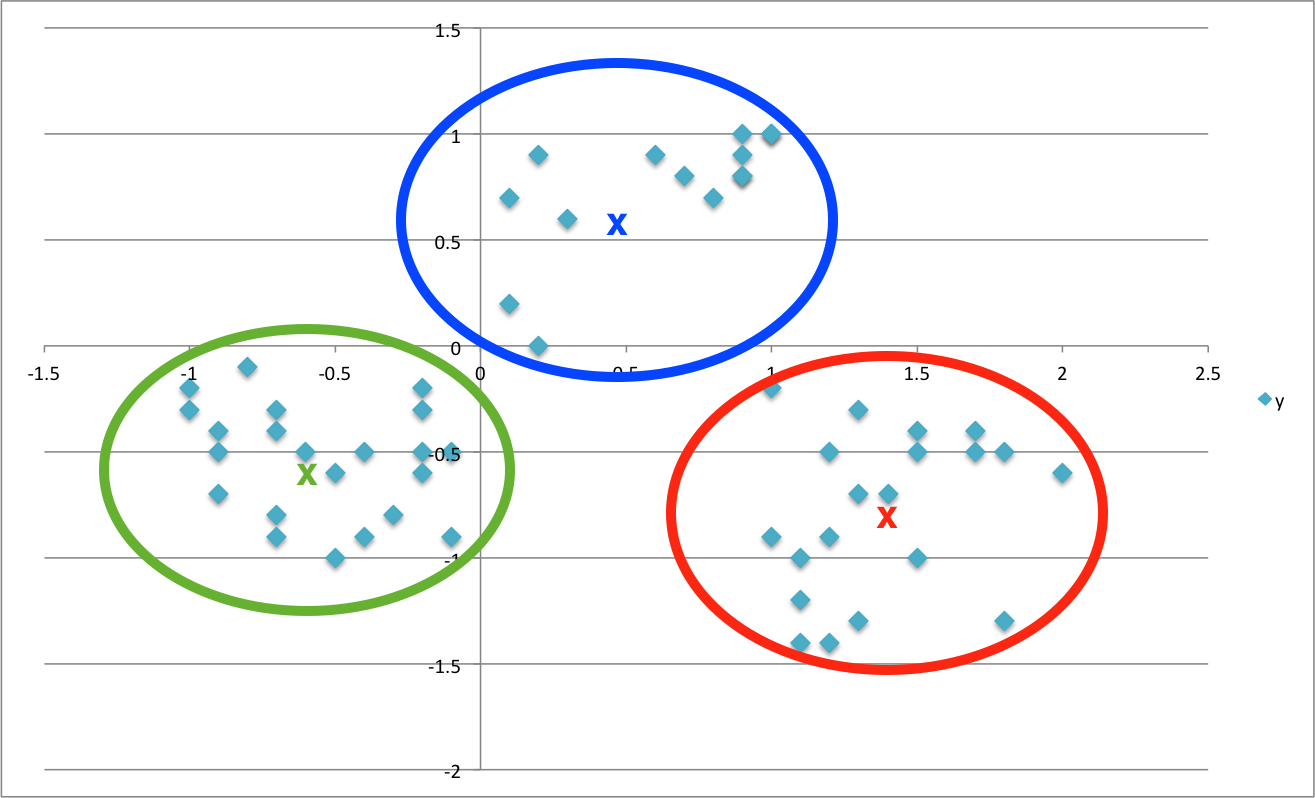
In K-Means speak, the “x”‘s are called “centroids” and indicate (you guessed it), the center of a given cluster. I’m not going to go into the ins and outs of what K-Means is actually doing under the hood, but hopefully this illustration gives you a good idea.
用K均值表示,“ x”被称为“质心”,表示(您猜对了)给定簇的中心。 我不会深入探讨K-Means实际在幕后所做的事情,但是希望此图可以为您提供一个好主意。
聚集客户 (Clustering our customers)
Okay, so how does clustering apply to our customers? Well since we’re trying to learn more about how our customers behave, we can use their behavior (whether or not they purchased something based on an offer) as a way to group similar minded customers together. We can then study those groups to look for patterns and trends which can help us formulate future offers.
好吧,那么群集如何适用于我们的客户? 好吧,因为我们试图了解有关客户行为的更多信息,所以我们可以使用他们的行为(无论他们是否根据要约购买了商品)作为将相似想法的客户聚集在一起的一种方式。 然后,我们可以研究这些小组以寻找可以帮助我们制定未来报价的模式和趋势。
The first thing we need is a way to compare customers. To do this, we’re going to create a matrix that contains each customer and a 0/1 indicator for whether or not they responded to a given offer. This is easy enough to do in Python:
我们需要的第一件事是比较客户的方法。 为此,我们将创建一个矩阵,其中包含每个客户和一个0/1指标,用于指示他们是否响应给定的报价。 这在Python中很容易做到:
# join the offers and transactions table df = pd.merge(df_offers, df_transactions) # create a "pivot table" which will give us the number of times each customer responded to a given offer matrix = df.pivot_table(index=['customer_name'], columns=['offer_id'], values='n') # a little tidying up. fill NA values with 0 and make the index into a column matrix = matrix.fillna(0).reset_index() # save a list of the 0/1 columns. we'll use these a bit later x_cols = matrix.columns[1:]# join the offers and transactions table df = pd.merge(df_offers, df_transactions) # create a "pivot table" which will give us the number of times each customer responded to a given offer matrix = df.pivot_table(index=['customer_name'], columns=['offer_id'], values='n') # a little tidying up. fill NA values with 0 and make the index into a column matrix = matrix.fillna(0).reset_index() # save a list of the 0/1 columns. we'll use these a bit later x_cols = matrix.columns[1:]
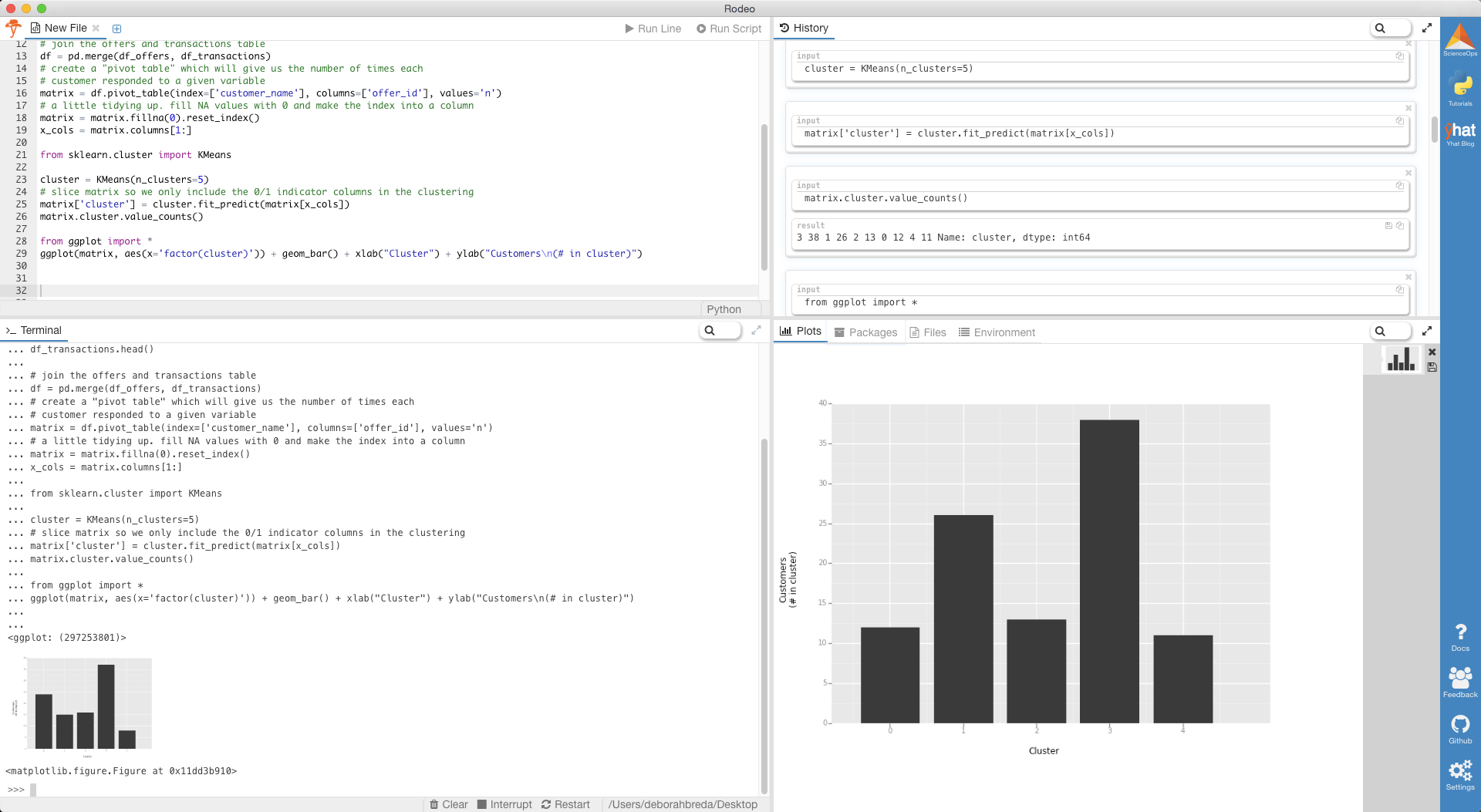
Now to create the clusters, we’re going to use the KMeans functionality from scikit-learn. I arbitrarily chose 5 clusters. My general rule of thumb is to have at least 7x as many records as I do clusters.
现在创建集群,我们将使用scikit-learn的KMeans功能。 我任意选择了5个集群。 我的一般经验法则是,至少有7倍的记录是集群的记录。
Notice that in Rodeo, you can view the histogram in the terminal, history or plots tab. If you’re working on multiple monitors, you can even pop out the plot into its own window.
请注意,在Rodeo中,您可以在终端,历史记录或绘图选项卡中查看直方图。 如果您正在使用多台显示器,甚至可以将绘图弹出到其自己的窗口中。
可视化集群 (Visualizing the clusters)
A really cool trick that the probably didn’t teach you in school is Principal Component Analysis. There are lots of uses for it, but today we’re going to use it to transform our multi-dimensional dataset into a 2 dimensional dataset. Why you ask? Well once it is in 2 dimensions (or simply put, it has 2 columns), it becomes much easier to plot!
一个可能在学校没教过你的绝妙的技巧是主成分分析 。 它有很多用途,但是今天我们将使用它将多维数据集转换为二维数据集。 你为什么问? 好吧,一旦它在2维(或简单地说,它有2列)中,绘制起来就容易多了!
Once again, scikit-learn comes to the rescue!
再次, scikit-learn可以解救!
from sklearn.decomposition import PCApca = PCA(n_components=2) matrix['x'] = pca.fit_transform(matrix[x_cols])[:,0] matrix['y'] = pca.fit_transform(matrix[x_cols])[:,1] matrix = matrix.reset_index()customer_clusters = matrix[['customer_name', 'cluster', 'x', 'y']] customer_clusters.head()from sklearn.decomposition import PCApca = PCA(n_components=2) matrix['x'] = pca.fit_transform(matrix[x_cols])[:,0] matrix['y'] = pca.fit_transform(matrix[x_cols])[:,1] matrix = matrix.reset_index()customer_clusters = matrix[['customer_name', 'cluster', 'x', 'y']] customer_clusters.head()
| offer_id | offer_id | customer_name | 顾客姓名 | cluster | 簇 | x | X | y | ÿ |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Adams | 亚当斯 | 2 | 2 | -1.007580 | -1.007580 | 0.108215 | 0.108215 |
| 1 | 1个 | Allen | 艾伦 | 4 | 4 | 0.287539 | 0.287539 | 0.044715 | 0.044715 |
| 2 | 2 | Anderson | 安德森 | 1 | 1个 | 0.392032 | 0.392032 | 1.038391 | 1.038391 |
| 3 | 3 | Bailey | 贝利 | 2 | 2 | -0.699477 | -0.699477 | -0.022542 | -0.022542 |
| 4 | 4 | Baker | 贝克 | 3 | 3 | -0.088183 | -0.088183 | -0.471695 | -0.471695 |
What we’ve done is we’ve taken those x_cols columns of 0/1 indicator variables, and we’ve transformed them into a 2-D dataset. We took one column and arbitrarily called it x and then called the other y. Now we can throw each point into a scatterplot. We’ll color code each point based on it’s cluster so it’s easier to see them.
我们要做的是获取0/1指标变量的x_cols列,并将其转换为2D数据集。 我们取一列,并随意将其命名为x ,然后将其命名为另一列y 。 现在我们可以将每个点放入散点图中。 我们将根据每个点的簇对它们进行颜色编码,以便于查看。
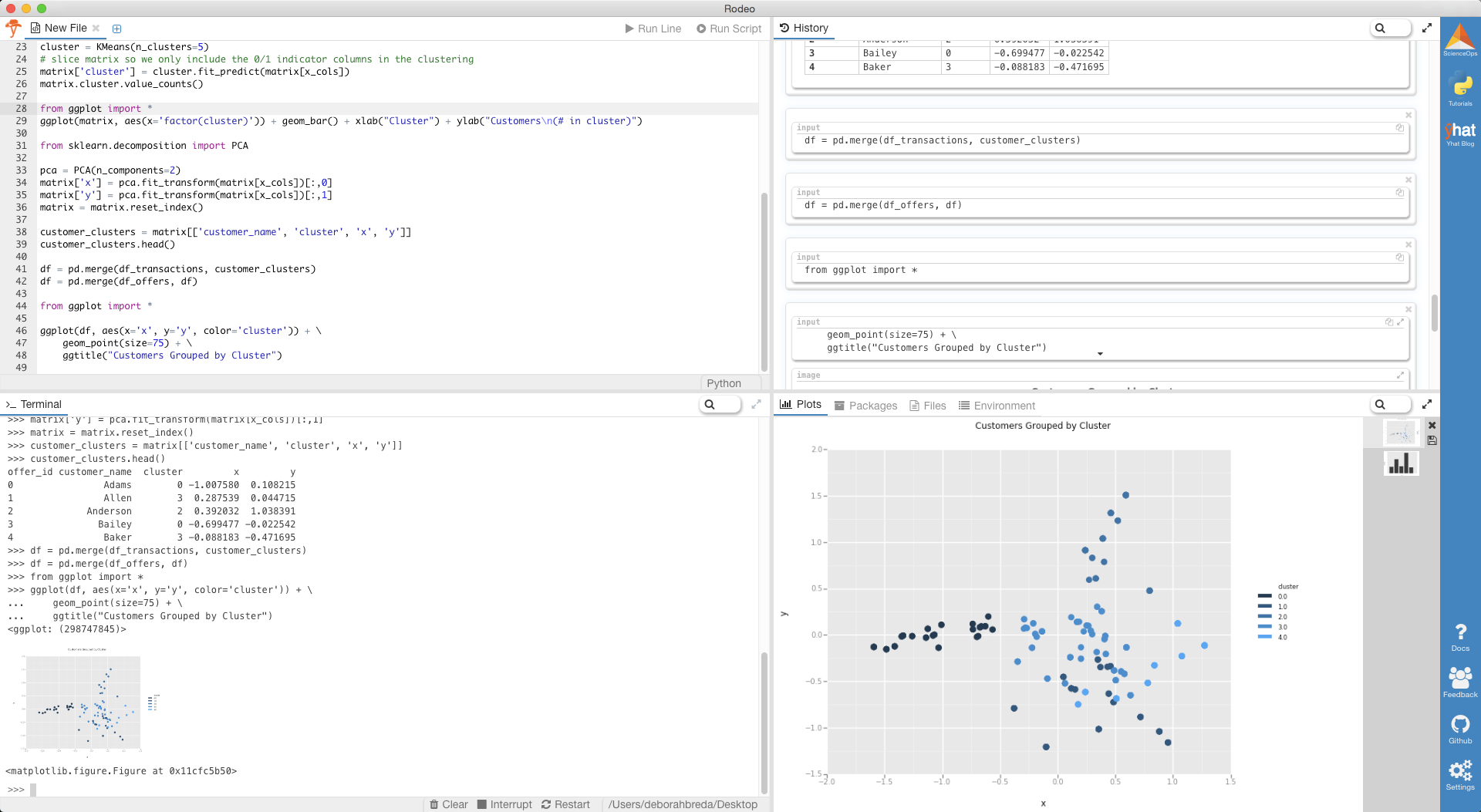
If you want to get fancy, you can also plot the centers of the clusters as well. These are stored in the KMeans instance using the cluster_centers_ variable. Make sure that you also transform the cluster centers into the 2-D projection.
如果想花哨的话,还可以绘制群集的中心。 它们使用cluster_centers_变量存储在KMeans实例中。 确保您还将群集中心转换为二维投影。
cluster_centers = pca.transform(cluster.cluster_centers_) cluster_centers = pd.DataFrame(cluster_centers, columns=['x', 'y']) cluster_centers['cluster'] = range(0, len(cluster_centers))ggplot(df, aes(x='x', y='y', color='cluster')) + geom_point(size=75) + geom_point(cluster_centers, size=500) +ggtitle("Customers Grouped by Cluster")cluster_centers = pca.transform(cluster.cluster_centers_) cluster_centers = pd.DataFrame(cluster_centers, columns=['x', 'y']) cluster_centers['cluster'] = range(0, len(cluster_centers))ggplot(df, aes(x='x', y='y', color='cluster')) + geom_point(size=75) + geom_point(cluster_centers, size=500) +ggtitle("Customers Grouped by Cluster")
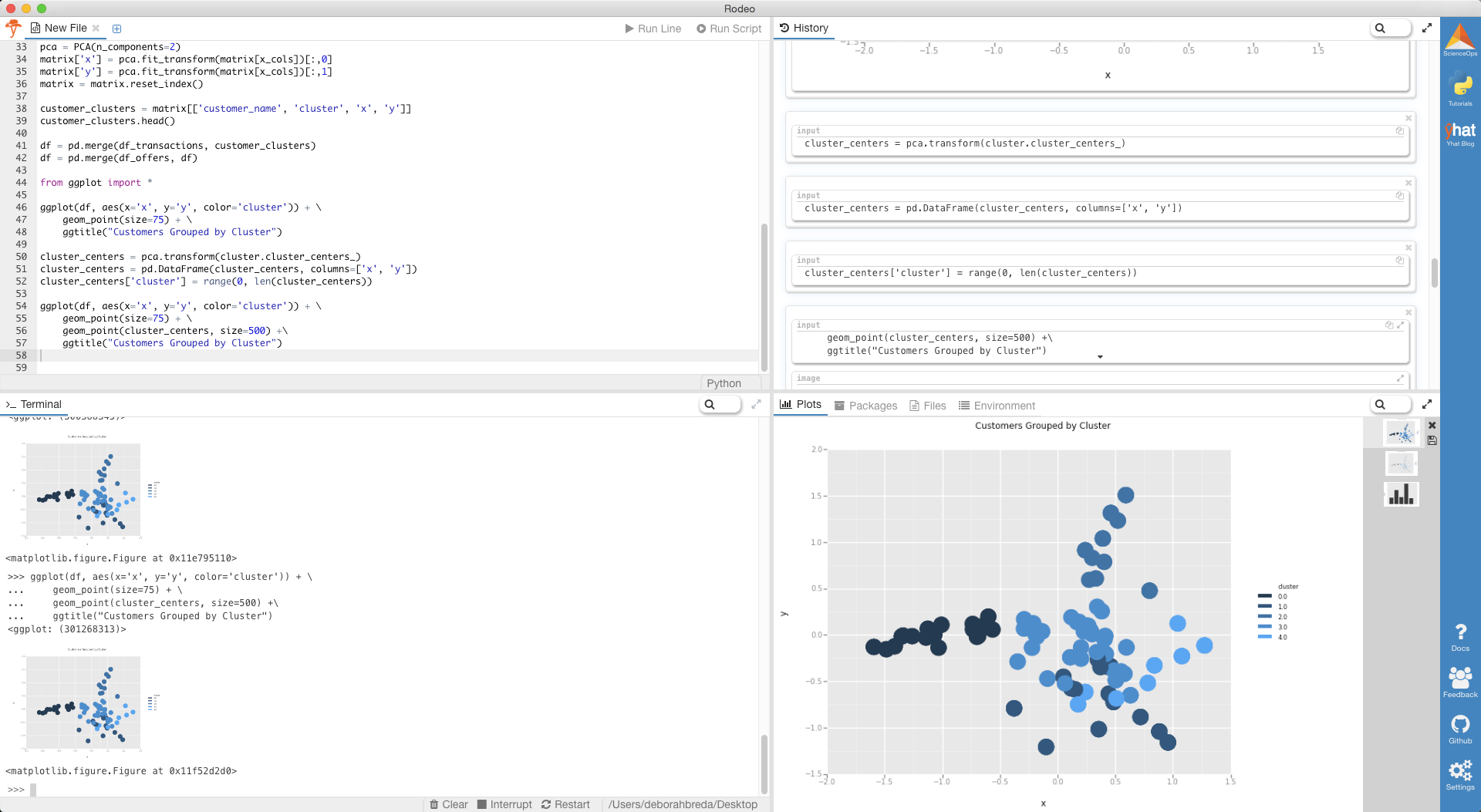
深入挖掘集群 (Digging deeper into the clusters)
Let’s dig a little deeper into the clusters. Take cluster 4 for example. If we break out cluster 4 and compare it to the remaining customers, we can start to look for interesting facets that we might be able to exploit.
让我们更深入地研究集群。 以集群4为例。 如果我们分解集群4并将其与其余客户进行比较,我们就可以开始寻找可以利用的有趣方面。
As a baseline, take a look at the varietal counts for cluster 4 vs. everyone else. It turns out that almost all of the Cabernet Sauvignon offers were purchased by members of cluster 4. In addition, none of the Espumante offers were purchased by members of cluster 4.
作为基准,请看一下聚类4与其他所有对象的varietal计数。 事实证明,几乎所有赤霞珠的报价都由集群4的成员购买。此外,Espumante的报价都不是集群4的成员购买的。
| is_4 | is_4 | varietal | 品种 | count | 计数 |
|---|---|---|---|---|---|
| False | 假 | Champagne | 香槟酒 | 45 | 45 |
| Espumante | Espumante | 40 | 40 | ||
| Prosecco | 普罗塞克 | 37 | 37 | ||
| Pinot Noir | 黑比诺 | 37 | 37 | ||
| Malbec | 马尔贝克 | 17 | 17 | ||
| Pinot Grigio | 比诺格里乔 | 16 | 16 | ||
| Merlot | 美乐 | 8 | 8 | ||
| Cabernet Sauvignon | 赤霞珠 | 6 | 6 | ||
| Chardonnay | 霞多丽 | 4 | 4 | ||
| True | 真正 | Champagne | 香槟酒 | 36 | 36 |
| Cabernet Sauvignon | 赤霞珠 | 26 | 26 | ||
| Malbec | 马尔贝克 | 15 | 15 | ||
| Merlot | 美乐 | 12 | 12 | ||
| Chardonnay | 霞多丽 | 11 | 11 | ||
| Pinot Noir | 黑比诺 | 7 | 7 | ||
| Prosecco | 普罗塞克 | 6 | 6 | ||
| Pinot Grigio | 比诺格里乔 | 1 | 1个 |
You can also segment out numerical features. For instance, look at how the mean of the min_qty field breaks out between 4 vs. non-4. It seems like members of cluster 4 like to by in bulk!
您还可以分割数字特征。 例如,查看min_qty字段的均值如何在4与非4之间min_qty 。 似乎集群4的成员喜欢批量购买!
df.groupby("is_4")[['min_qty', 'discount']].mean()df.groupby("is_4")[['min_qty', 'discount']].mean()
| min_qty | min_qty | discount | 折扣 | ||
|---|---|---|---|---|---|
| is_4 | is_4 | ||||
| False | 假 | 47.685484 | 47.685484 | 59.120968 | 59.120968 |
| True | 真正 | 93.394737 | 93.394737 | 60.657895 | 60.657895 |

Send a bulk Cab Sav offer Cluster 4’s way!
发送大量Cab Sav Sav提供Cluster 4的方式!
最后的想法 (Final Thoughts)
翻译自: https://www.pybloggers.com/2017/02/beginners-guide-to-customer-segmentation/
客户细分
客户细分_客户细分初学者指南相关推荐
- 客户细分_客户细分:K-Means聚类和A / B测试
客户细分 语境 (Context) I have been working in Advertising, specifically Digital Media and Performance, fo ...
- python 聚类 客户细分_客户细分——K-Means聚类
RFM模型多用于已知目标数据集,场景具有一定的局限性,本篇运用一个适用比较广泛的聚类算法--K-Means,它属于无监督机器学习,K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大 ...
- python初学者编程指南_动态编程初学者指南
python初学者编程指南 编程辅导 (PROGRAMMING TUTORIAL) Dynamic programming is an art, the more problems you solve ...
- 效果图底图 线框图_线框图初学者指南
效果图底图 线框图 线框图是任何屏幕设计过程中的重要一步. 它主要允许您定义设计的信息层次结构,从而使您可以轻松地根据希望用户处理信息的方式来规划布局. 如果您还没有使用线框图,是时候让您的脚湿了. ...
- python做什么模型_主题模型初学者指南[Python]
引言 近年来涌现出越来越多的非结构化数据,我们很难直接利用传统的分析方法从这些数据中获得信息.但是新技术的出现使得我们可以从这些轻易地解析非结构化数据,并提取出重要信息. 主题模型是处理非结构化数据的 ...
- rfm模型分析与客户细分_如何使用基于RFM的细分来确定最佳客户
rfm模型分析与客户细分 With some free time at hand in the midst of COVID-19 pandemic, I decided to do pro bono ...
- 能力建设指南_客户指南创建网站实际需要的内容
能力建设指南 Web developers: Email potential or current clients to this article for help clarifying your p ...
- 客户行为模型 r语言建模_客户行为建模:汇总统计的问题
客户行为模型 r语言建模 As a Data Scientist, I spend quite a bit of time thinking about Customer Lifetime Value ...
- 窗口属性 客户矩形_航空公司客户价值分析
目录 1.背景与挖掘目标 2.分析方法与过程 2.1 总体流程 2.2 数据抽取 2.3 数据探索分析 2.4 数据预处理 2.4.1 数据清洗 2.4.2 属性规约 2.4.3 数据变换 2.5 模 ...
- 步进电机无细分和20细分_细分网站导航会话
步进电机无细分和20细分 目标与应用 (Goal and applications) This article will show a method for segmenting website na ...
最新文章
- Python使用matplotlib可视化散点图、使用seaborn中的lmplot函数使用多子图可视化不同分组的散点图最优拟合线性回归曲线
- boost::bind的使用
- 腾讯面试题 TCP/IP协议四个层次
- Anaconda多环境多版本python配置指导
- mysql查询不同老师所教不同课程_mysql学习训练记录及笔记(二)
- arcgis python脚本筛选与线共边的面_ArcGis Python脚本——遍历输出面或折线要素的折点坐标...
- php向数组前加如指定键的值,PHP array_fill_keys():使用指定的键和值来填充数组
- 神州租车接盘方出现了, 股价收盘涨23%
- 网络01:双无线路由器无缝对接设置
- Linux如何切换字符或者图形界面
- Docker-Harbor:推送镜像/登录失败(Error response from daemon: Get https://reg.harbor.com/v2/: dial tcp 192...)
- 读书笔记12 《新周刊485期 三商:智商、情商、时间商》
- Ctfshow菜狗杯------传说之下(雾)
- MSP430F149单片机-IAP升级
- 腾讯广点通广告投放-Web转化数据API自归因文档对接
- 图像算法---白平衡AWB
- Layer 图层圆角、边框 、底纹其他常用操作
- 2021暑假集训-个人赛11
- 第九章 面向对象方法学(3)
- 虚拟机 高性能服务器,3种提高虚拟机性能并最大化效率的方法