odoo10参考系列--ORM API 三(字段、继承与扩展、域和更新到新API)
字段
基础字段
class odoo.fields.Field(string=<object object>, **kwargs)
字段描述符包含字段定义,并管理记录中相应字段的访问和分配。当实例化一个字段时,下面的属性可能被提供:
参数
- string -- 用户看到的字段的标签(字符串);如果未设置,则ORM在类中使用字段名(大写)
- help -- 用户看到的字段提示 (字符串)
- readonly -- 字段是否只读 (布尔类型, 默认情况下是
False) - required -- 字段的值是否是必填的(布尔类型, 默认情况下是
False) - index -- 字段是否在数据库中索引 (布尔类型, 默认情况下是
False) - default -- 该字段的默认值;这是一个静态值,或一个接受一个记录集并返回一个值的函数;使用default=None丢弃此字段的默认值
- states -- 映射状态值UI属性-值对列表的一个字典; 可能的属性是: 'readonly', 'required', 'invisible'。 注意: 任何基于状态的条件都要求状态字段值在客户端UI上可用。这通常是通过将其包含在相关视图中,如果最终用户不相关的话,可能是不可见的
- groups -- 分组XML ID(字符串)的逗号分隔列表;这限制了仅对给定组的用户进行字段访问
- copy (
bool) -- 该字段是否值应该复制记录时复制(默认:True表示正常字段,False表示one2many和计算字段, 包括字段属性和相关字段) - oldname (
string) -- 此字段的前一个名称,以便ORM可以在迁移时自动重命名它
计算字段
你可以定义一个值被计算的字段,而不是简单地从数据库中读取。特定于计算字段的属性如下所示。要定义这样一个字段,只需为属性compute提供一个值
参数
- compute -- 计算字段的的方法名称
- inverse -- 使字段倒转的方法名称 (可选的)
- search -- 在字段上实现搜索的方法的名称 (可选的)
- store -- 字段是否存储在数据库中(布尔值,默认情况下计算字段为
False) - compute_sudo -- 该字段是否应计算为超级用户绕过访问权(布尔值,默认情况为
False)
compute, inverse 和search给出的方法是模型方法。 他们的签名如下面的例子所示:
upper = fields.Char(compute='_compute_upper',inverse='_inverse_upper',search='_search_upper')@api.depends('name')
def _compute_upper(self):for rec in self:rec.upper = rec.name.upper() if rec.name else Falsedef _inverse_upper(self):for rec in self:rec.name = rec.upper.lower() if rec.upper else Falsedef _search_upper(self, operator, value):if operator == 'like':operator = 'ilike'return [('name', operator, value)]
计算方法在调用记录集的所有记录分配字段。装饰符odoo.api.depends()必须应用于计算方法来指定字段的依赖;那些依赖的是用于确定何时重新计算字段;重新计算自动保证缓存/数据库的一致性。注意,同样的方法可以用于多个字段,只需在方法中分配所有给定的字段;该方法将为所有这些字段调用一次。
默认情况下,计算字段不存储到数据库中,并在计算中计算。添加属性store=True 将会在数据库中存储字段的值。存储字段的优点是,该字段的搜索是由数据库本身完成的。缺点是它需要更新数据库时,必须重新计算。
逆方法,正如它的名字所说的,是计算方法的逆:被调用的记录具有字段的值,并且必须在字段依赖项上应用必要的更改,以便计算提供预期值。注意,计算字段没有逆方法默认情况下是只读的。
在对模型进行实际搜索之前,在处理域时调用搜索方法。它必须返回一个等价于该条件的域: field operator value
相关字段
相关字段的值是通过跟踪一系列关系字段和在到达模型上读取字段来给出的。要遍历的字段的完整序列由属性指定
参数
related -- 字段名称序列
如果没有重新定义字段属性,则会自动从源字段复制一些字段属性: string, help, readonly, required (只有在序列中的所有字段都是必需的), groups, digits, size, translate, sanitize, selection, comodel_name, domain, context. 所有的语义自由属性都从源字段复制。
默认情况下,相关字段的值不会存储到数据库中。 就行计算字段一样,添加属性store=True 使其可以存储在数据库中。当它们的依赖关系发生改变时,相关字段将自动重新计算。
公司依赖字段
以前称为“属性”字段,这些字段的值取决于公司。换句话说,属于不同公司的用户可能在给定的记录上看到字段的不同值
参数
company_dependent -- 字段是否是公司依赖的 (boolean)
稀少字段
稀少字段有很小的不为空的概率。 因此,许多这样的字段可以被紧凑地序列化到一个公共位置,后者是所谓的“序列化”字段
参数
sparse -- 必须存储此字段值的字段的名称
增量的定义
字段定义为模型类上的类属性。如果扩展模型(参见模型),还可以通过重新定义子类上同名和相同类型的字段来扩展字段定义。在这种情况下,字段的属性取自父类,并由子类中给出的属性重写。
例如,下面的第二个类只在字段state中添加工具提示 :
class First(models.Model):_name = 'foo'state = fields.Selection([...], required=True)class Second(models.Model):_inherit = 'foo'state = fields.Selection(help="Blah blah blah")
class odoo.fields.Char(string=<object object>, **kwargs)
根据: odoo.fields._String
基本字符串字段,可以是长度有限的,通常在客户端显示为单行字符串
参数
- size (
int) -- 该字段存储的最大值的大小 - translate -- 启用字段值的翻译;使用translate=True翻译为整体的字段值;translate也可以是可调用的,这样translate(callback, value)通过使用callback(term)重新得到术语翻译来翻译value
class odoo.fields.Boolean(string=<object object>, **kwargs)
根据: odoo.fields.Field
class odoo.fields.Integer(string=<object object>, **kwargs)
根据: odoo.fields.Field
class odoo.fields.Float(string=<object object>, digits=<object object>, **kwargs)
根据: odoo.fields.Field
精度大小的数字是由属性给出的
参数
digits -- 成对的(总位数, 小数位数), 或一个使用数据库游标并返回成对的(总位数, 小数位数) 的函数
class odoo.fields.Text(string=<object object>, **kwargs)
根据: odoo.fields._String
和 Char 非常相似但使用的字符更长的内容,没有尺寸,通常显示为多行文本框
参数
translate -- 启用字段值的翻译;使用translate=True翻译为整体的字段值;translate也可以是可调用的,这样translate(callback, value)通过使用callback(term)重新得到术语翻译来翻译value
class odoo.fields.Selection(selection=<object object>, string=<object object>, **kwargs)
根据: odoo.fields.Field
参数
- selection -- 指定此字段的可能值。 它是成对的(
value,string)或模型方法或方法名的列表 - selection_add -- 在重写字段的情况下提供选择的扩展。 它是成对的 (
value,string)列表
属性selection 是强制性的,除了在相关字段或者字段扩展的情况下
class odoo.fields.Html(string=<object object>, **kwargs)
根据: odoo.fields._String
class odoo.fields.Date(string=<object object>, **kwargs)
根据: odoo.fields.Field
static context_today(record, timestamp=None)
返回像客户端所在时区一样的以适合日期字段的格式的当前日期 。此方法可用于计算默认值
参数
timestamp (datetime) -- 可选的DateTime值来代替当前的日期和时间 (必须是一个日期,不变的日期在时区之间进行转换)
Return type
str
static from_string(value)
将ORMvalue转换为date值
static to_string(value)
将date值转换为ORM预期的格式
static today(*args)
以ORM期望的格式返回当前日期。此函数可用于计算默认值
class odoo.fields.Datetime(string=<object object>, **kwargs)
根据: odoo.fields.Field
static context_timestamp(record, timestamp)
返回给定时间戳转换为客户端的时区。这种方法并不意味着使用一个默认的初始化,因为DateTime字段自动转换后显示在客户端。 作为默认值 fields.datetime.now() 应该被用来代替使用
参数
timestamp (datetime) -- naive datetime value (expressed in UTC) to be converted to the client timezone单纯的时间值(以UTC表达)被转换为客户端的时区
返回类型
datetime
返回
时间戳转换为在上下文时区中的时区处理时间
static from_string(value)
将ORM value 转换为一个 datetime 值
static now(*args)
以ORM期望的格式返回当前日期和时间。此函数可用于计算默认值
static to_string(value)
以ORM期望的格式转换一个datetime 值
相关字段
class odoo.fields.Many2one(comodel_name=<object object>, string=<object object>, **kwargs)
根据: odoo.fields._Relational
这个字段的值是一个大小为 0 (无记录) 或 1 (单个记录)的记录集
参数
- comodel_name -- 目标模型的名称(字符串)
- domain -- 在客户端(域或字符串)设置候选值的可选域
- context -- 处理该字段(字典)时在客户端使用的可选上下文
- ondelete -- 删除引用记录时应该做什么;可能的值是:
'set null','restrict','cascade' - auto_join -- 在搜索该字段时是否生成连接 (布尔类型,默认值
False) - delegate -- 将其设置为True,使目标模型的字段可以从当前模型访问s (对应于
_inherits)
属性comodel_name 是强制的除了是相关字段或者字段扩展的情况下
class odoo.fields.One2many(comodel_name=<object object>, inverse_name=<object object>, string=<object object>, **kwargs)
根据: odoo.fields._RelationalMulti
One2many字段; 这个字段的值是在comodel_name中所有记录的记录集,这样字段 inverse_name等于当前记录的记录集。
参数
- comodel_name -- 目标模型的名称(字符串)
- inverse_name -- 在
comodel_name(字符串)中的逆Many2one字段名称 - domain -- 在客户端(域或字符串)设置候选值的可选域
- context -- 处理该字段(字典)时在客户端使用的可选上下文
- auto_join -- 在搜索该字段时是否生成连接 (布尔类型,默认值
False) - limit -- 读取时使用的可选限制(整数)
属性comodel_name 和inverse_name 是强制的除了是相关字段或者字段扩展的情况下
class odoo.fields.Many2many(comodel_name=<object object>, relation=<object object>, column1=<object object>, column2=<object object>,string=<object object>, **kwargs)
根据: odoo.fields._RelationalMulti
Many2many字段; 这个字段的值是一个记录集
参数
comodel_name -- 目标模型的名称(字符串)
属性 comodel_name是强制的除了是相关字段或者字段扩展的情况下
参数
- relation -- 存储在关系数据库中的可选的表名称(字符串)
- column1 -- 在表
relation(字符串)中引用“这些”记录的列的可选名称 - column2 -- 在表
relation(字符串)中引用“那些”记录的列的可选名称
属性relation, column1 和column2 是可选的。 如果没有给出名字,名字是从模型的自动生成,并提供 model_name 和comodel_name 是不同的!
参数
- domain -- 在客户端(域或字符串)设置候选值的可选域
- context -- 处理该字段(字典)时在客户端使用的可选上下文
- limit -- 读取时使用的可选限制(整数)
class odoo.fields.Reference(selection=<object object>, string=<object object>, **kwargs)
根据: odoo.fields.Selection
继承和扩展
Odoo提供了三种不同的机制模式以模块化的方式扩展模型:
- 从现有的模型创建新模型,向副本添加新信息,但将原来的模块保留
- 扩展其他模块中定义的模型,替换以前的版本
- 将模型的一些字段委托给它包含的记录
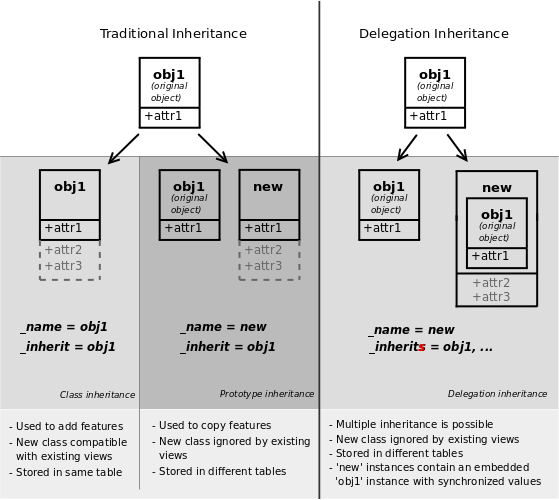
传统继承
当_inherit 和_name 属性一起使用的时候, Odoo使用作为基类的现有的模型创建一个新模型。新模型从基类获取所有字段、方法和元信息(缺省值)。
class Inheritance0(models.Model):_name = 'inheritance.0'name = fields.Char()def call(self):return self.check("model 0")def check(self, s):return "This is {} record {}".format(s, self.name)class Inheritance1(models.Model):_name = 'inheritance.1'_inherit = 'inheritance.0'def call(self):return self.check("model 1")
并使用它们:
a = env['inheritance.0'].create({'name': 'A'})b = env['inheritance.1'].create({'name': 'B'})a.call()b.call()
结果如下:
"This is model 0 record A""This is model 1 record B"
当使用标准Python继承时,第二个模型继承了第一个模型的check 方法和name字段, 但重写了 call方法
扩展
当使用_inherit 属性但是没有使用_name属性时,将创建一个新模型替换现有模型,本质上是在原来模型上扩展的。将新的字段或方法添加到现有的模型(在其他模块中创建),或者定制或重新配置它们(例如,更改它们的默认排序顺序)是非常有用的:
class Extension0(models.Model):_name = 'extension.0'name = fields.Char(default="A")class Extension1(models.Model):_inherit = 'extension.0'description = fields.Char(default="Extended")
env = self.env{'name': "A", 'description': "Extended"}
结果如下:
注
它也会产生各种自动字段,除非它们已经禁用
委托
第三个继承机制提供了更多的灵活性(可以在运行时更改),但花费较小的力量:使用 _inherits属性实现一个模型委托来查找任何没有在当前模型到“子”模型中找到的字段。委托是通过在父模型上自动设置的Reference字段来执行的:
class Child0(models.Model):_name = 'delegation.child0'field_0 = fields.Integer()class Child1(models.Model):_name = 'delegation.child1'field_1 = fields.Integer()class Delegating(models.Model):_name = 'delegation.parent'_inherits = {'delegation.child0': 'child0_id','delegation.child1': 'child1_id',}child0_id = fields.Many2one('delegation.child0', required=True, ondelete='cascade')child1_id = fields.Many2one('delegation.child1', required=True, ondelete='cascade')
record = env['delegation.parent'].create({'child0_id': env['delegation.child0'].create({'field_0': 0}).id,'child1_id': env['delegation.child1'].create({'field_1': 1}).id,})record.field_0record.field_1
结果如下:
01
并且可以直接在委派字段上进行写入:
record.write({'field_1': 4})
警告
在使用委托继承时,方法不是继承的,只有字段可继承
域
一个域是一个标准的列表,每个标准都是一个三元(或 list 或 tuple)的 (field_name, operator, value),具体如下:
field_name (str)
当前模型的字段名称, 或者通过Many2one使用点符号的关系遍历,例如 'street'或 'partner_id.country'
operator (str)
用来比较使用value的field_name 的运算符。有效运算符是:
=
等于
!=
不等于
>
大于
>=
大于等于
<
小于
<=
小于等于
=?
不等于(如果 value 是 None 或 False则返回true; 否则就像 =)
=like
匹配value模式的field_name 。 模式中的下划线_代表(匹配)任何单个字符;百分号标志%匹配任何字符串的零或多个字符
like
匹配%value%模式的field_name 。和=like 类似但在匹配之前用“%”包装value
not like
与%value%模式不匹配
ilike
不区分大小写like
not ilike
不区分大小写not like
=ilike
不区分大小写=like
in
等于任何一个来自value的项, value 应该是项的列表
not in
不等于所有来自value的项
child_of
是一个 value 记录的子(后代)记录
在语义模型中考虑 (即紧随靠_parent_name命名的关系字段)
value
变量类型,必须和指定字段具有可比性(通过operator)
域标准可以使用前缀形式的逻辑运算符进行组合:
'&'
逻辑与AND, 默认操作来组合以下标准。 元数 2 (使用下一个2个标准或组合).
'|'
逻辑或OR, 元数 2.
'!'
逻辑非NOT, 元数 1.
提示
主要是否定标准的组合
个体标准通常有一个否定的形式 (例如 = -> !=, < -> >=),这比否定正面的要简单
例子
寻找命名为ABC的伙伴,来自比利时或德国,他们的语言不是英语:
[('name','=','ABC'),('language.code','!=','en_US'),'|',('country_id.code','=','be'),('country_id.code','=','de')]
此域被解释为:
(name is 'ABC')
AND (language is NOT english)
AND (country is Belgium OR Germany)
从旧API移植到新API
- 新的API中避免使用空的id列表,而是使用记录集
- 仍然在旧API中编写的方法应该由ORM自动桥接,不需要切换到旧API,只需调用它们就好像它们是一种新的API方法一样。详细信息请参见旧API方法的自动桥接
search()返回一个没有标点的记录集, 例如浏览它的结果fields.related和fields.function使用一个带着related=或者compute=的参数的正常字段类型替换- 在
compute=上的depends()方法必须是完全的,它必须是计算方法使用的所有字段和子字段的列表。最好是有太多的依赖(将重新计算字段的情况下,是不需要的)不要依赖不够(会忘记重新计算字段然后值将不正确的) - 删除所有在计算字段上的
onchange方法。当它们的关系发生变化,计算字段会自动重新计算,这是使用由客户端自动生成的onchange方法 - 装饰
model()和multi()是桥接时从旧的API调用上下文,而用于内部或新的API(如计算)时它们是无用的 - 删除
_default,,在相应的字段上使用default=参数替代 如果一个字段的
string=参数是字段名称的标题包装版本:name = fields.Char(string="Name")它是无用的,应该被删除
multi=参数在新API字段上不做任何事情,在所有相关字段上使用相同的compute=方法以获得相同的结果- 通过名字(作为一个字符串)提供
compute=,inverse=和search=三个方法,这使得它们是可重写的(消除了中间“蹦床”功能的需要) - 仔细检查所有的字段和方法有不同的名称,在冲突发生时没有警告(因为Python处理它,在Odoo看到什么之前)
- 正常的新API输入是
from odoo import fields, models。 如果兼容性装饰是必要的,使用from odoo import api, fields, models - 避免使用
one()修饰符,它可能不符合你的期望 - 删除
create_uid,create_date,write_uid和write_date字段的显示定义: 它们现在被创建为常规的“合法”字段,并且可以像其他任何字段一样读和写 当直接转换是不可能的(语义不能桥接)或“旧的API版本”是不可取的,可以改进新的API,它可以使用完全不同的“老API”和“使用
v7()和v8()相同的方法名称的新API”实现。该方法首先要定义使用旧API的风格和v7()装饰,它应该重新定义使用相同的名字,但新的API的风格和v8()装饰。来自旧API上下文的调用将被分派到第一个实现,来自新API上下文的调用将被分派到第二个实现。一个实现可以通过切换上下文调用(并且经常)调用另一个实现危险
使用这些装饰使得方法极难覆盖、难理解和文档化
_columns或_all_columns的使用应该被_fields取代,它提供了新样式odoo.fields.Field实例的访问实例(而不是就样式的odoo.osv.fields._column)。使用新API风格创建的非存储的计算字段在_columns中是不可使用的并只能通过_fields检查
- 在分配方法中的
self可能是不必要的和可能打破翻译的反思 环境(Environment)对象依赖于某些线程本地状态,在使用它们之前必须设置。 有必要这样做去使用
odoo.api.Environment.manage()上下文管理器,当尝试在尚未设置的上下文中使用新API时,例如新线程或Python交互环境:>>> from odoo import api, modules >>> r = modules.registry.RegistryManager.get('test') >>> cr = r.cursor() >>> env = api.Environment(cr, 1, {}) Traceback (most recent call last):... AttributeError: environments >>> with api.Environment.manage(): ... env = api.Environment(cr, 1, {}) ... print env['res.partner'].browse(1) ... res.partner(1,)
旧API方法的自动桥接
当模型初始化时,所有的方法都会自动扫描和桥接,如果它们看起来像旧API风格中声明的模型一样。这种桥接使它们可以透明地调用新的API样式方法。
如果第二个位置参数(在self之后)被称为cr或cursor,则方法被匹配为“旧API样式”。该系统也能识别第三个位置参数被称为uid或user和第四被称为id或ids。它还识别存在任何称为context的参数 。
当从一个新的API中调用这样的方法时,系统会自动的从目前的环境Environment(cr, user 和 context)或当前的记录集(id 和ids)填充的参数匹配。
在必要的情况下,可以通过装饰旧样式方法来定制桥接:
- 完全禁用它,通过使用noguess()装饰方法将不会有桥接,方法将与新API和旧API风格完全相同
显示的定义桥接,这主要是因为不正确匹配的方法(因为参数是以意外的方式命名):
cr()将自动在当前光标位置的显式提供的参数
cr_uid()将自动在当前光标和用户ID显式地提供参数
cr_uid_ids()将自动在当前光标,用户的ID和记录集的ids显示地提供参数
cr_uid_id()将循环的当前记录集和为每一个记录调用一次方法,把当前光标,用户的ID和记录的ID显式提供的参数
危险
当从一个新API上下文调用时,这个包装器的结果总是一个列表
所有这些方法都有一个以_context为后缀的版本(例如
cr_uid_context()) ,它也通过键盘传递当前上下文。- 双实现使用
v7()和v8()将被忽略,因为他们提供自己的“桥梁”
ps:有翻译不当之处,欢迎留言指正。
原文地址:https://www.odoo.com/documentation/10.0/reference/orm.html
odoo10参考系列--ORM API 三(字段、继承与扩展、域和更新到新API)相关推荐
- odoo10参考系列--ORM API 二(新旧API兼容性、模型参考和方法修饰符)
新API与旧API的兼容性 现在的Odoo是从就的(不规律的)API过渡来的,它可能需要从一个手动桥接到另一个手动桥接: RPC层(XML-RPC和RPC)是在旧的API的形式表达,表达的纯粹的方法在 ...
- odoo10参考系列--ORM API 一(记录集、环境、通用方法和创建模型)
记录集 版本8.0中新东西: 这个在Odoo8.0中新加的API的页面文档应该是不断向前发展的主要开发API.同时它还提供了关于移植或桥接版本7和更早版本的"旧API"的信息,但没 ...
- Odoo10参考系列--QWeb报表
报表是写在HTML / QWeb中,像Odoo中的所有普通视图.你可以使用普通QWeb 流程控制工具.PDF的渲染是通过wkhtmltopdf执行的. 如果要在某个模型上创建报表,则需要定义该报表和它 ...
- odoo10参考系列--视图三(其他高级视图)
图表 图表视图用于在多个记录或记录组上可视化聚合视图.它的根元素是<graph> ,可以有以下属性: type 使用bar (默认的), pie 和line三个中的一个图表类型 stack ...
- Odoo10参考系列--Odoo指导方针
本文介绍了新版Odoo编码指南.那些旨在提高代码的质量 (例如更好的可读性)和Odoo应用程序.实际上,适当的代码简化了维护.调试,降低了复杂性,提高了可靠性. 这些指导原则应适用于每一个新的模块和新 ...
- Odoo10参考系列--混合而有用的类
Odoo实现了一些有用的类和混合,使您可以轻松地在对象上添加常用的行为.本指南将详细介绍其中的大部分内容,包括示例和用例. 消息特征 消息集成 基本消息系统 将消息功能集成到模型中非常容易.简单地继承 ...
- odoo10参考系列--数据文件
Odoo就是一个非常大的数据驱动, 因此,模块定义的一大部分就是对其管理的各种记录的定义: 用户界面(菜单.视图),安全(访问权限和访问规则),报表和普通数据都通过记录定义. 结构 在Odoo定义数据 ...
- odoo10参考系列--操作(Actions)
操作定义系统响应用户操作的行为:登录.操作按钮.发票的选择,- 操作可以存储在数据库中,也可以直接作为字典返回,例如按钮方法.所有操作共享两个强制属性: type 当前操作的类别,决定可以使用哪些字段 ...
- odoo10参考系列--QWeb
QWeb是被Odoo[2]使用的主要的模版引擎.它是一个XML模板引擎[1],主要用于生成HTML片段和页面. 模板指令指定的XML属性的前缀 t-,例如t-if 为条件,与元素和其他属性被直接渲染. ...
最新文章
- 8核32g mysql性能_MySQL性能优化之参数配置
- 取最后一个字符 oracle,oracle截取最后一个字符
- 图像放大算法一:最近邻法(Nearest Interpolation)
- Focal Loss 的Pytorch
- GPU:nvidia-smi的简介、安装、使用方法之详细攻略
- orm2 中文文档 3. 定义模型
- 外媒:苹果明年上半年推出iPhone SE 3 支持5G搭载A14处理器
- 瑞禧分享二维晶体表征介绍及定制SnPSe3晶体;CoBi4Te7 磁性拓扑绝缘体/CuInP2S6晶体;Nb2SiTe4晶体/Sb2TeSe2晶体等
- linux im-scim-bridge.so 使用,Ubuntu SCIM 输入法不能光标跟随的解决
- 微课在小学计算机教学中的应用,微课技术在小学信息技术课堂中的应用
- EditPlus安装步骤
- 王垠四十行代码mark
- 关联分析法,超详解!进来秒懂!!
- GoLang 抽奖系统 设计
- 如何在微信朋友圈分享网页内容的时候能够有缩略图
- SpringBoot中使用Easyexcel实现Excel导入导出功能(三)
- 魔百盒CM211-2_ZG代工-强刷固件包和教程
- git commit 命令详解
- 好用的电视盒子软件推荐:无广告看电视我选这两款
- 返璞归真-删除文件默认打开方式