一个IO的传奇一生 (9) -- Noop和Deadline调度器
Linux中常见IO调度器
Noop调度器算法
Noop是Linux中最简单的调度器,这个调度器基本上没做什么特殊的事情,就是把邻近bio进行了合并处理。从IO的QoS角度来看,这个Noop调度器就是太简单了,但是从不同存储介质的特性来看,这个Noop还是有一定用武之地的。例如,对于磁盘介质而言,为了避免磁头抖动,可以通过调度器对写请求进行合并。对于SSD存储介质而言,这个问题不存在了,或者说不是那么简单的存在了。如果SSD内部能够很好的处理了写放大等问题,那么调度器这一块就不需要做什么特殊处理了,此时Noop就可以发挥作用了。
通过阅读Noop调度器的代码,我们可以了解到一个调度器是如何实现的,对外的接口是什么?所以,了解一个调度器的框架,从Noop开始是非常好的一个选择。
Noop调度器的实现非常简单,其主要完成了一个elevator request queue,这个request queue没有进行任何的分类处理,只是对输入的request进行简单的队列操作。但是,需要注意的是,虽然Noop没有做什么事情,但是elevator还是对bio进行了后向合并,从而最大限度的保证相邻的bio得到合并处理。Noop调度器实现了elevator的基本接口函数,并将这些函数注册到linux系统的elevator子系统中。
需要注册到elevator子系统中的基本接口函数声明如下:
static struct elevator_type elevator_noop = {
.ops = {
/* 合并两个request */
.elevator_merge_req_fn = noop_merged_requests,
/* 调度一个合适的request进行发送处理 */
.elevator_dispatch_fn = noop_dispatch,
/* 将request放入调度器的queue中 */
.elevator_add_req_fn = noop_add_request,
/* 获取前一个request */
.elevator_former_req_fn = noop_former_request,
/* 获取后一个request */
.elevator_latter_req_fn = noop_latter_request,
.elevator_init_fn = noop_init_queue,
.elevator_exit_fn = noop_exit_queue,
},
.elevator_name = "noop",
.elevator_owner = THIS_MODULE,
};
由于Noop调度器没有对request进行任何的分类处理、调度,因此上述这些函数的实现都很简单。例如,当调度器需要发送request时,会调用noop_dispatch。该函数会直接从调度器所管理的request queue中获取一个request,然后调用elv_dispatch_sort函数将请求加入到设备所在的request queue中。Noop dispatch函数实现如下:
static int noop_dispatch(struct request_queue *q, int force)
{
struct noop_data *nd = q->elevator->elevator_data;
if (!list_empty(&nd->queue)) {
struct request *rq;
/* 从调度器的队列头中获取一个request */
rq = list_entry(nd->queue.next, struct request, queuelist);
list_del_init(&rq->queuelist);
/* 将获取的request放入到设备所属的request queue中 */
elv_dispatch_sort(q, rq);
return 1;
}
return 0;
}
当需要往noop调度器中放入request时,可以调用noop_add_request,该函数的实现及其简单,就是将request挂入调度器所维护的request queue中。Noop_add_request函数实现如下:
static void noop_add_request(struct request_queue *q, struct request *rq)
{
struct noop_data *nd = q->elevator->elevator_data;
/* 将request挂入noop调度器的request queue */
list_add_tail(&rq->queuelist, &nd->queue);
}
由此可见,noop调度器的实现是很简单的,仅仅实现了一个调度器的框架,用一条链表把所有输入的request管理起来。通过noop调度器的例子,我们可以了解到实现一个调度器所需要的基本结构:
/* 包含基本的头文件 */
#include <linux/blkdev.h>
#include <linux/elevator.h>
#include <linux/bio.h>
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/init.h>
/* 定义调度器所需要的数据结构,一条管理request的队列是必须的 */
struct noop_data {
struct list_head queue;
};
/* 实现调度器的接口函数 */
static struct elevator_type elevator_noop = {
.ops = {
/* 调度器的功能函数 */
.elevator_merge_req_fn = noop_merged_requests,
……
/* 初始化/注销调度器,通常在下面这些函数初始化调度器内部的一些数据结构,例如noop_data */
.elevator_init_fn = noop_init_queue,
.elevator_exit_fn = noop_exit_queue,
},
.elevator_name = "noop",
.elevator_owner = THIS_MODULE,
};
/* 注册调度器 */
static int __init noop_init(void)
{
elv_register(&elevator_noop);
return 0;
}
/* 销毁调度器 */
static void __exit noop_exit(void)
{
elv_unregister(&elevator_noop);
}
/* 模块加载时调用noop_init */
module_init(noop_init);
/* 模块退出时调用noop_exit */
module_exit(noop_exit);
Deadline调度器算法
Deadline这种调度器对读写request进行了分类管理,并且在调度处理的过程中读请求具有较高优先级。这主要是因为读请求往往是同步操作,对延迟时间比较敏感,而写操作往往是异步操作,可以尽可能的将相邻访问地址的请求进行合并,但是,合并的效率越高,延迟时间会越长。因此,为了区别对待读写请求类型,deadline采用两条链表对读写请求进行分类管理。但是,引入分类管理之后,在读优先的情况下,写请求如果长时间得到不到调度,会出现饿死的情况,因此,deadline算法考虑了写饿死的情况,从而保证在读优先调度的情况下,写请求不会被饿死。
Deadline这种调度算法的基本思想可以采用下图进行描述:
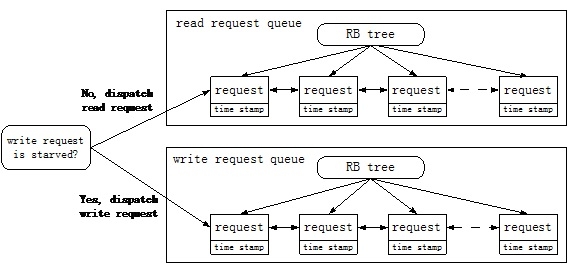
读写请求被分成了两个队列,并且采用两种方式将这些request管理起来。一种是采用红黑树(RB tree)的方式将所有request组织起来,通过request的访问地址作为索引;另一种方式是采用队列的方式将request管理起来,所有的request采用先来后到的方式进行排序,即FIFO队列。每个request会被分配一个time stamp,这样就可以知道这个request是否已经长时间没有得到调度,需要优先处理。在请求调度的过程中,读队列是优先得到处理的,除非写队列长时间没有得到调度,存在饿死的状况。
在请求处理的过程中,deadline算法会优先处理那些访问地址临近的请求,这样可以最大程度的减少磁盘抖动的可能性。只有在有些request即将被饿死的时候,或者没有办法进行磁盘顺序化操作的时候,deadline才会放弃地址优先策略,转而处理那些即将被饿死的request。
总体来讲,deadline算法对request进行了优先权控制调度,主要表现在如下几个方面:
1)读写请求分离,读请求具有高优先调度权,除非写请求即将被饿死的时候,才会去调度处理写请求。这种处理可以保证读请求的延迟时间最小化。
2)对请求的顺序批量处理。对那些地址临近的顺序化请求,deadline给予了高优先级处理权。例如一个写请求得到调度后,其临近的request会在紧接着的调度过程中被处理掉。这种顺序批量处理的方法可以最大程度的减少磁盘抖动。
3)保证每个请求的延迟时间。每个请求都赋予了一个最大延迟时间,如果达到延迟时间的上限,那么这个请求就会被提前处理掉,此时,会破坏磁盘访问的顺序化特征,回影响性能,但是,保证了每个请求的最大延迟时间。
与deadline相关的请求调度发送函数是deadline_dispatch_requests,该函数的实现、分析如下:
static int deadline_dispatch_requests(struct request_queue *q, int force)
{
struct deadline_data *dd = q->elevator->elevator_data;
const int reads = !list_empty(&dd->fifo_list[READ]);
const int writes = !list_empty(&dd->fifo_list[WRITE]);
struct request *rq;
int data_dir;
/*
* batches are currently reads XOR writes
请求批量处理入口
*/
if (dd->next_rq[WRITE])
rq = dd->next_rq[WRITE];
else
rq = dd->next_rq[READ];
/* 如果批量请求处理存在,并且还没有达到批量请求处理的上限值,那么继续请求的批量处理 */
if (rq && dd->batching < dd->fifo_batch)
/* we have a next request are still entitled to batch */
goto dispatch_request;
/*
* at this point we are not running a batch. select the appropriate
* data direction (read / write)
*/
/* 优先处理读请求队列 */
if (reads) {
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ]));
/* 如果写请求队列存在饿死的现象,那么优先处理写请求队列 */
if (writes && (dd->starved++ >= dd->writes_starved))
goto dispatch_writes;
data_dir = READ;
goto dispatch_find_request;
}
/*
* there are either no reads or writes have been starved
*/
/* 没有读请求需要处理,或者写请求队列存在饿死现象 */
if (writes) {
dispatch_writes:
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE]));
dd->starved = 0;
data_dir = WRITE;
goto dispatch_find_request;
}
return 0;
dispatch_find_request:
/*
* we are not running a batch, find best request for selected data_dir
*/
if (deadline_check_fifo(dd, data_dir) || !dd->next_rq[data_dir]) {
/* 如果请求队列中存在即将饿死的request,或者不存在需要批量处理的请求,那么从FIFO队列头获取一个request */
/*
* A deadline has expired, the last request was in the other
* direction, or we have run out of higher-sectored requests.
* Start again from the request with the earliest expiry time.
*/
rq = rq_entry_fifo(dd->fifo_list[data_dir].next);
} else {
/* 继续批量处理,获取需要批量处理的下一个request */
/*
* The last req was the same dir and we have a next request in
* sort order. No expired requests so continue on from here.
*/
rq = dd->next_rq[data_dir];
}
dd->batching = 0;
dispatch_request:
/* 将request从调度器中移出,发送至设备 */
/*
* rq is the selected appropriate request.
*/
dd->batching++;
deadline_move_request(dd, rq);
return 1;
}
Deadline调度器需要处理的核心数据结构是deadline_data,该结构描述如下:
struct deadline_data {
/*
* run time data
*/
/*
* requests (deadline_rq s) are present on both sort_list and fifo_list
*/
/* 采用红黑树管理所有的request,请求地址作为索引值 */
struct rb_root sort_list[2];
/* 采用FIFO队列管理所有的request,所有请求按照时间先后次序排列 */
struct list_head fifo_list[2];
/*
* next in sort order. read, write or both are NULL
*/
/* 批量处理请求过程中,需要处理的下一个request */
struct request *next_rq[2];
/* 计数器:统计当前已经批量处理完成的request */
unsigned int batching; /* number of sequential requests made */
sector_t last_sector; /* head position */
/* 计数器:统计写队列是否即将饿死 */
unsigned int starved; /* times reads have starved writes */
/*
* settings that change how the i/o scheduler behaves
*/
/* 配置信息:读写请求的超时时间值 */
int fifo_expire[2];
/* 配置信息:批量处理的request数量 */
int fifo_batch;
/* 配置信息:写饥饿值 */
int writes_starved;
int front_merges;
};
总体而言,Noop和Deadline算法实现是比较简单的.
转载于:https://blog.51cto.com/alanwu/1393068
一个IO的传奇一生 (9) -- Noop和Deadline调度器相关推荐
- 一个IO的传奇一生(8) -- elevator子系统
Elevator子系统介绍 Elevator子系统是IO 路径上非常重要的组成部分,前面已经分析过,elevator中实现了多种类型的调度器,用于满足不同应用的需求.那么,从整个IO路径的角度来看,e ...
- 一个IO的传奇一生(10)-- CFQ调度算法
CFQ调度器算法 在相对比较老的Linux中,CFQ机制的实现还比较简单,仅仅是针对不同的thread进行磁盘带宽的公平调度.但是,自从新Kernel引入Cgroup机制之后,CFQ的机制就显得比较复 ...
- 一文深入了解Linux IO 调度器
[推荐阅读] 浅谈linux 内核网络 sk_buff 之克隆与复制 深入linux内核架构--进程&线程 了解Docker 依赖的linux内核技术 每个块设备或者块设备的分区,都对应有自身 ...
- [IO系统]18 IO调度器 - CFQ
CFQ(CompletelyFair Queuing)算法,顾名思义,绝对公平算法. 1.1 原理 CFQ试图为竞争块设备使用权的所有进程分配一个请求队列和一个时间片,在调度器分配给进程的时间片内 ...
- 服务器io修改,更改 Linux I/O 调度器来改善服务器性能
为了从 Linux 服务器榨取尽可能多的性能,请了解如何更改 I/O 调度器以满足你的需求. Linux I/O 调度器()控制内核提交读写请求给磁盘的方式.自从 2.6 内核以来,管理员已经能够更改 ...
- 更改as的默认gradle地址_面试官:谈谈这4种磁盘IO调度算法--CFQ、NOOP、Deadline、AS...
概述 今天主要分享下磁盘IO调度算法,虽然对于我们平时只需要设置deadline就行了,不过了解下它的4种算法也还是不错的. I/O 调度算法 I/O 调度算法在各个进程竞争磁盘I/O的时候担当了裁判 ...
- 约翰·格伦:77岁宇航员的传奇一生
1962年,约翰·格伦成为首位抵达地球轨道的美国人,而在36年后,1998年,77岁高龄的格伦又成为迄今进入太空最年长的宇航员.这是他的传奇一生. 约翰·格伦(1921.07.18~2016.12.8 ...
- Hello‘s P2P—一个普通程序出生入死的一生
计算机系统 大作业 题 目 程序人生-Hello's P2P 专 业 人工智能 学 号 2021120020 班 级 21E0361 学 生 吕佳琦 指 导 教 师 史先俊 计算机科学与技术学院 20 ...
- 一代爱国电脑天才,郭盛华的传奇一生
一代爱国电脑天才,郭盛华的传奇一生 郭盛华是谁?我相信很多从事互联网的朋友都知道,他无疑是网络安全领域风云人物里最耀眼的那一位.他到底有哪些值得我们深思和学习的地方呢?今天给大家详细说说. 郭盛华,他 ...
最新文章
- 字符串转换成utf-8编码
- 关于plsql连接oracle数据库session失效时间设置
- row_number() OVER(PARTITION BY)函数
- C#中PostMessage和SendMessage的参数传递实例
- 零基础学Java的10个方法
- android 编译时解析xml布局,android – 在xml布局中引用build.gradle versionName属性
- Redis事务和秒杀业务设计
- thinkphp所有参数配置
- TensorFlow入门(2)矩阵基础
- [转]微信小程序之加载更多(分页加载)实例 —— 微信小程序实战系列(2)...
- OICQ登录号码清除器实现原理
- cf服务器人最多,玩家实测CF各大区在线人数排名 你的区排第几?
- Ultimate Tic-Tac-Toe
- [Mark]The problems solutions of vmware vsphere
- 2020 ICPC 济南 A Matrix Equation (高斯消元)
- 收发器(Transceiver)架构4——发信机1
- 用C语言做一个迷宫小游戏
- 天龙八部元宝兑换代码
- 物联网技术的应用领域
- iphone应用开发