SQL Server索引视图
SQL Server Views are virtual tables that are used to retrieve a set of data from one or more tables. The view’s data is not stored in the database, but the real retrieval of data is from the source tables. When you call the view, the source table’s definition is substituted in the main query and the execution will be like reading from these tables directly.
SQL Server视图是虚拟表,用于从一个或多个表中检索一组数据。 视图的数据未存储在数据库中,但是真正的数据检索是从源表中进行的。 调用视图时,源表的定义将替换为主查询中的内容,其执行就像直接从这些表中读取一样。
Views are mainly created for security purpose in order to restrict user access to specific columns i. These are also created for simplification purpose in order to encapsulate frequently executed, complex queries that read from multiple tables each time. Views perform multi-tables reading too, causing huge amount of IO operations. There are no performance benefits from using standard views; if the view definition contains complex processing and joins between huge numbers of rows from a combination of tables, and you are calling this view very frequently, performance degradation will be noticed clearly.
创建视图主要是出于安全性目的,以便限制用户对特定列的访问。 出于简化目的而创建它们也是为了封装每次从多个表读取的频繁执行的复杂查询。 视图也执行多表读取,从而导致大量的IO操作。 使用标准视图没有性能优势; 如果视图定义包含复杂的处理,并且在来自多个表组合的大量行之间进行联接,并且您非常频繁地调用此视图,则会明显注意到性能下降。
To enhance the performance of such complex queries, a unique clustered index can be created on the view, where the result set of that view will be stored in your database the same as a real table with a unique clustered index. The good thing here is – the queries that are using the table itself can benefits from the view’s clustered index without calling the view itself. Maintaining the clustered index of the view to be unique, the data changed on the source table will be easily found and the change will be reflected to the view. Changing the data directly from the indexed view is possible but shouldn’t be done. Also, it is possible to create non-clustered indexes on a view, providing more possibilities to enhance the queries calling the view.
为了提高此类复杂查询的性能,可以在视图上创建唯一的聚集索引,该视图的结果集将与具有唯一聚集索引的真实表一样存储在数据库中。 这里的好处是–使用表本身的查询可以从视图的聚集索引中受益,而无需调用视图本身。 保持视图的聚簇索引唯一,可以轻松找到在源表上更改的数据,并将更改反映到视图。 可以直接从索引视图更改数据,但不应该这样做。 同样,可以在视图上创建非聚集索引,从而提供了更多增强视图调用查询的可能性。
You can benefit from indexed views if its data is not frequently updated, as the performance degradation of maintaining the data changes of the indexed view is higher than the performance enhancement of using this Indexed View. Indexed views improve the performance of queries that use joins and aggregations in processing huge amount of data and are executed very frequently. The environments that are best suited to indexed views are data warehouses and the Online Analytical Processing (OLAP) databases. On the other hand, it will not improve the performance on tables with many writes and updates such as Online Transaction Processing (OLTP) databases.
如果索引数据不经常更新,则可以从索引视图中受益,因为维护索引视图的数据更改的性能下降比使用此索引视图的性能增强要高。 索引视图提高了在处理大量数据时使用联接和聚合的查询的性能,并且执行频率很高。 数据仓库和联机分析处理(OLAP)数据库是最适合索引视图的环境。 另一方面,它不会提高具有许多写入和更新的表的性能,例如在线事务处理(OLTP)数据库。
Creating indexed views differs from creating normal views in that using the SCHEMA BINDING hint is not optional. This means that you will not be able to apply structure changes on the tables that may affect the indexed view unless you alter or drop that indexed view first. In addition, you need to specify two parts name of these tables including the schema with the table name in the view definition. Also, any user-defined function that is referenced by the created indexed view should be created using WITH SCHEMABINDING hint.
创建索引视图与创建普通视图的区别在于,使用SCHEMA BINDING提示不是可选的。 这意味着除非您先更改或删除该索引视图,否则您将无法在表上应用可能影响索引视图的结构更改。 另外,您需要指定这些表的两个部分名称,包括在视图定义中带有表名称的架构。 另外,应使用WITH SCHEMABINDING提示来创建所创建的索引视图引用的任何用户定义函数。
Once the Indexed view is created, its data will be stored in your database the same as any other clustered index, so the storage space for the view’s clustered index should be taken into consideration. Having the indexed view’s clustered index stored in the database, with its own statistics created to optimize the cardinality estimation, different from the underlying tables’ statistics, the SQL engine will not waste the time substituting the source tables’ definition in the main query, and it will read directly from the view’s clustered index.
创建索引视图后,其数据将与任何其他聚集索引一样存储在数据库中,因此应考虑该视图的聚集索引的存储空间。 将索引视图的聚集索引存储在数据库中,并创建其自己的统计信息以优化基数估计,这与基础表的统计信息不同,SQL引擎不会浪费时间在主查询中替换源表的定义,并且它将直接从视图的聚集索引中读取。
There are some limitations when you create an indexed view. You can’t use EXISTS, NOT EXISTS, OUTER JOIN, COUNT(*), MIN, MAX, subqueries, table hints, TOP and UNION in the definition of your indexed view. Also, it is not allowed to refer to other views and tables in other databases in the view definition. You can’t use the text, ntext, image and XML, data types in your indexed views. Float data type can be used in the indexed view but can’t be used in the clustered index. If the Indexed view’s definition contains GROUP BY clause, you should add COUNT_BIG(*) to the view definition
创建索引视图时有一些限制。 您不能在索引视图的定义中使用EXISTS , NOT EXISTS , OUTER JOIN , COUNT(*) , MIN , MAX , 子查询,表提示 , TOP和UNION 。 另外,不允许在视图定义中引用其他数据库中的其他视图和表。 您不能在索引视图中使用text , ntext , image和XML数据类型。 浮动数据类型可以在索引视图中使用,但不能在聚集索引中使用。 如果索引视图的定义包含GROUP BY子句,则应在视图定义中添加COUNT_BIG(*)
Another restriction on creating an indexed view is that there are a few SET options that should have certain values in your database if you manage to create an indexed view in it. For example, the ANSI_NULLS, ANSI_PADDING, ANSI_WARNINGS, ARITHABORT,CONCAT_NULL_YIELDS_NULL, and QUOTED_IDENTIFIER options should be ON, and the NUMERIC_ROUNDABORT option should be OFF. Non-deterministic columns can’t be used in the indexed view definition. These are the columns that don’t return the same value each time, like the GETDATE() function.
创建索引视图的另一个限制是,如果您设法在数据库中创建索引视图,则应该在数据库中有一些SET选项应该具有某些值。 例如, ANSI_NULLS,ANSI_PADDING,ANSI_WARNINGS,ARITHABORT,CONCAT_NULL_YIELDS_NULL和QUOTED_IDENTIFIER选项应为ON ,而NUMERIC_ROUNDABORT选项应为OFF 。 非确定性列不能在索引视图定义中使用。 这些列每次都不会返回相同的值,例如GETDATE()函数。
Benefits of clustered indexes created for an indexed view depends on the SQL Server edition. If you are using SQL Server Enterprise edition, SQL Server Query Optimizer will automatically consider the created clustered index as an option in the execution plan if it is the best index found. Otherwise, it will use a better one. In the other SQL Server editions such as Standard edition, the SQL Server Query Optimizer will access all the underlying source tables and use its indexes. In order to force the SQL Server Query Optimizer to use the index view’s clustered index in the execution plan for the query, you should use the WITH (NOEXPAND) table hint in the FROM clause.
为索引视图创建的聚集索引的好处取决于SQL Server版本。 如果使用的是SQL Server Enterprise版,则SQL Server Query Optimizer将自动将创建的聚集索引作为执行计划中的选项,前提是它是找到的最佳索引。 否则,它将使用更好的一种。 在其他SQL Server版本(例如Standard Edition)中,SQL Server Query Optimizer将访问所有基础源表并使用其索引。 为了强制SQL Server查询优化器在查询的执行计划中使用索引视图的聚集索引,应在FROM子句中使用WITH(NOEXPAND)表提示。
Let’s review a small demo to test and compare the performance of a standard view and an indexed view that will read the employee information required for his manager from the Employee, EmployeeDepartmentHistory, Department, Shift and EmployeePayHistory tables under the HumanResources schema from the SQLSHACKDEMO database.
让我们回顾一个小型演示,以测试和比较标准视图和索引视图的性能,该视图将从SQLSHACKDEMO数据库下HumanResources架构下的Employee,EmployeeDepartmentHistory,Department,Shift和EmployeePayHistory表读取其经理所需的员工信息。
The below script will create a standard view that retrieves the requested information:
以下脚本将创建一个标准视图,以检索所请求的信息:
USE SQLShackDemo
GO
CREATE VIEW EmployeeFullInfo
AS
SELECT EMP.[BusinessEntityID],EMP.[LoginID],EMP.[JobTitle],EMP.[BirthDate],EMP.[MaritalStatus],EMP.[Gender],EMP.[HireDate],Dep.Name AS Department,SH.Name AS ShiftName,EMPPayHist.Rate AS EmployeeRateFROM [SQLShackDemo].[HumanResources].[Employee] AS EMPJOIN [SQLShackDemo].[HumanResources].[EmployeeDepartmentHistory] AS EMPDepHistON EMP.BusinessEntityID =EMPDepHist.BusinessEntityID JOIN [SQLShackDemo].[HumanResources].[Department] AS DepON DEP.DepartmentID =EMPDepHist .DepartmentID JOIN [SQLShackDemo].[HumanResources].[Shift] SHON EMPDepHist.ShiftID=SH.ShiftID JOIN [SQLShackDemo].[HumanResources].[EmployeePayHistory] EMPPayHistON EMP.BusinessEntityID =EMPPayHist.BusinessEntityID Once the EmployeeFullInfo view is created, the user’s access is limited to see only the view columns and the complex logic that reads from the five tables is encapsulated into one small select statement from the view directly like the below one:
创建EmployeeFullInfo视图后,用户的访问权限将被限制为仅查看视图列,并且从五张表中读取的复杂逻辑被封装到该视图的一个小的选择语句中,就像下面的语句一样:
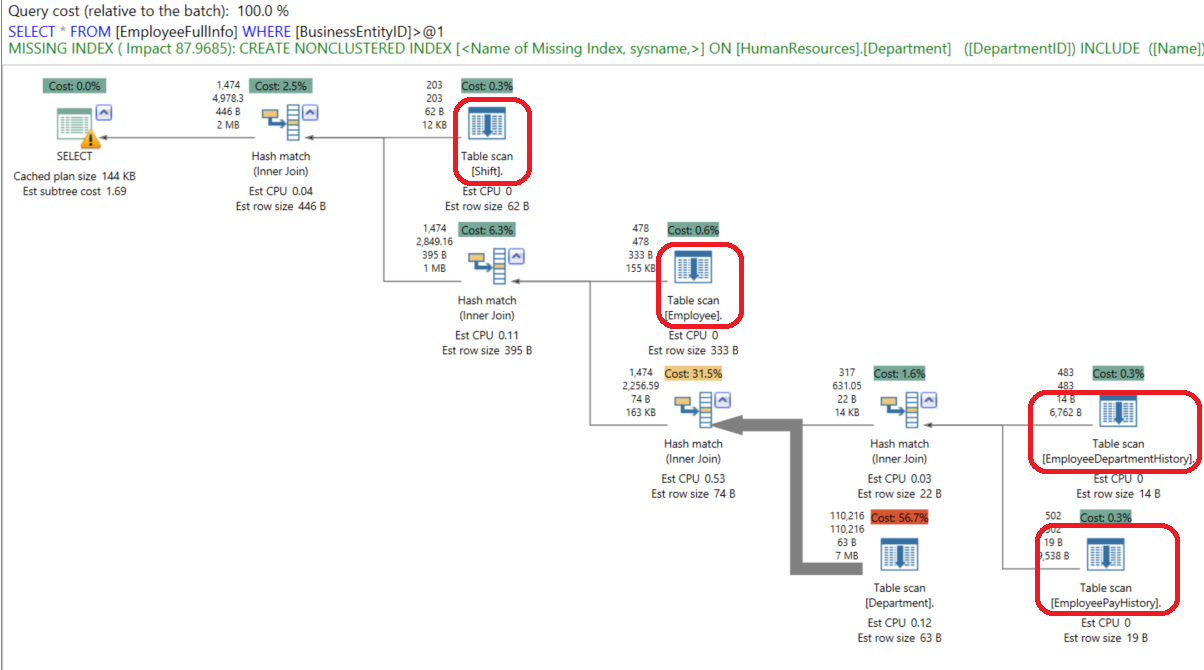
SELECT * FROM EmployeeFullInfo where BusinessEntityID >12As we can see from the query’s execution plan generated using the APEXSQL Plan application, no performance benefits are achieved from this view, as the SQL Server Query Optimizer reads the data from the source tables performing Table Scan, ending with the below complex plan.
从使用APEXSQL Plan应用程序生成的查询的执行计划中可以看出,此视图无法带来性能优势,因为SQL Server Query Optimizer从执行表扫描的源表中读取数据,以下面的复杂计划结束。
To write an indexed view for the same previous complex logic, we need first to add the WITH SCHEMABINDING statement to the view as it is a must here. This will prevent any changes in the underlying tables that may affect the view’s columns:
要为以前的相同复杂逻辑编写索引视图,我们首先需要在视图中添加WITH SCHEMABINDING语句,因为这是必须的。 这将防止基础表中的任何更改可能影响视图的列:
USE SQLShackDemo
GO
CREATE VIEW [HumanResources].EmployeeFullInfo_Indexed
WITH SCHEMABINDING AS
SELECT EMP.[BusinessEntityID],EMP.[LoginID],EMP.[JobTitle],EMP.[BirthDate],EMP.[MaritalStatus],EMP.[Gender],EMP.[HireDate],Dep.Name AS Department,SH.Name AS ShiftName,EMPPayHist.Rate AS EmployeeRateFROM [HumanResources].[Employee] AS EMPJOIN [HumanResources].[EmployeeDepartmentHistory] AS EMPDepHistON EMP.BusinessEntityID =EMPDepHist.BusinessEntityID JOIN [HumanResources].[Department] AS DepON DEP.DepartmentID =EMPDepHist .DepartmentID JOIN [HumanResources].[Shift] SHON EMPDepHist.ShiftID=SH.ShiftID JOIN [HumanResources].[EmployeePayHistory] EMPPayHistON EMP.BusinessEntityID =EMPPayHist.BusinessEntityID GOAfter creating the view, we will create a Unique Clustered Index on the EmployeeFullInfo_Indexed view covering all its fields:
创建视图之后,我们将在EmployeeFullInfo_Indexed视图上创建一个唯一的聚集索引,覆盖其所有字段:
CREATE UNIQUE CLUSTERED INDEX IX_VEMPInfo ON EmployeeFullInfo_Indexed([BusinessEntityID],[LoginID],[JobTitle],[BirthDate],[MaritalStatus],[Gender],[HireDate],Department,ShiftName);As the SQL Server edition installed on my test machine is standard edition, I need to force the SQL Server Query Optimizer to use the created index in the query plan by adding the WITH (NOEXPAND) table hint to my query as below:
由于我的测试计算机上安装SQL Server版本是标准版本,因此我需要通过将WITH(NOEXPAND)表提示添加到我的查询中,以强制SQL Server查询优化器在查询计划中使用创建的索引,如下所示:
SELECT * FROM EmployeeFullInfo_Indexed WITH (NOEXPAND) WHERE BusinessEntityID >12As you can see from the execution plan generated using the APEXSQL Plan application, it looks totally different; rather than having the five tables’ scan, the SQL Server Query Optimizer determines that using the view’s clustered index is the optimal way to get the requested data from the view. It is clear that the optimizer reads all the data from the clustered index itself without touching the underlying tables.
从使用APEXSQL Plan应用程序生成的执行计划中可以看到,它看起来完全不同。 SQL Server查询优化器没有进行五个表的扫描,而是确定使用视图的聚簇索引是从视图获取请求的数据的最佳方法。 显然,优化器从聚簇索引本身读取所有数据,而无需触及基础表。
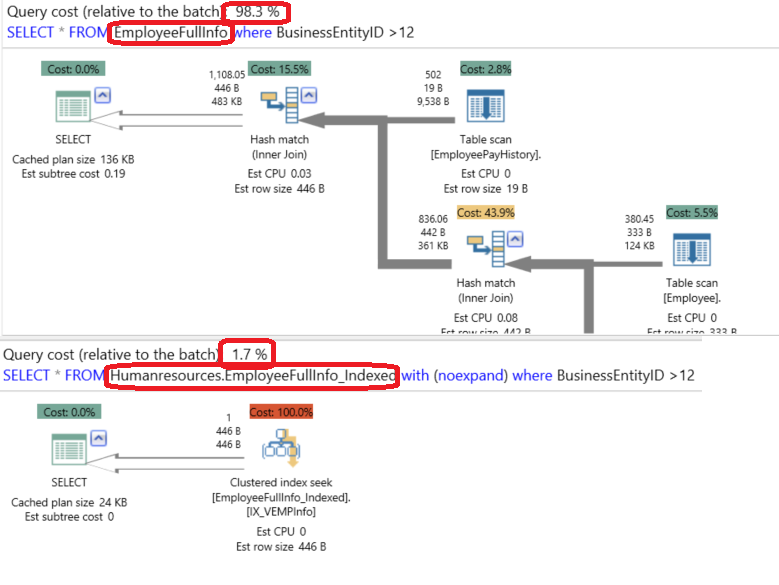
In order to compare the performance of the two views and the enhancement we got from that indexed view, let’s run the two SELECT statements in the same sessions, as follows, and study the cost shown in the execution plan for each one:
为了比较两个视图的性能以及从该索引视图获得的增强功能,让我们在相同的会话中运行两个SELECT语句,如下所示,并研究每个执行视图中显示的成本:
SELECT * FROM EmployeeFullInfo where BusinessEntityID >12
GO
SELECT * FROM EmployeeFullInfo_Indexed with (noexpand) where BusinessEntityID >12The enhancement achieved by using the indexed view can be easily derived from the execution plan generated using the APEXSQL Plan application below, as the cost of using the standard view compared to the indexed view is 98:2, which means that the indexed view is better than the standard view by a factor of 20 times in our example:
通过使用索引视图实现的增强可以很容易地从下面使用APEXSQL Plan应用程序生成的执行计划中得出,因为与索引视图相比,使用标准视图的成本为98:2,这意味着索引视图更好在我们的示例中,它比标准视图高出20倍:
结论 ( Conclusion )
Using SQL Server indexed views can be considered as a good technique for enhancing query performance by reducing the IO cost and duration for the query, in addition to simplifying complex query logic when joining multiple tables and maintaining the data security. But it requires testing, planning, and deep studying why you need to use the indexed views and you should do a full analysis of the net performance impact, measuring performance enhancements vs costs
使用SQL Server索引视图可以被认为是通过减少查询的IO成本和持续时间来增强查询性能的一种好方法,此外,当简化连接多个表并维护数据安全性时,可以简化复杂的查询逻辑。 但这需要测试,规划和深入研究为什么需要使用索引视图,并且应该对净性能影响进行全面分析,衡量性能增强与成本之间的关系。
翻译自: https://www.sqlshack.com/sql-server-indexed-views/
SQL Server索引视图相关推荐
- SQL Server索引视图以(物化视图)及索引视图与查询重写
SQL Server索引视图以(物化视图)及索引视图与查询重写 本文出处:http://www.cnblogs.com/wy123/p/6041122.html 经常听Oracle的同学说起来物化视图 ...
- 浅谈SQL Server索引视图(物化视图)以及索引视图与查询重写
目录 (一)前言 (二)正文 1. 物化视图(索引视图)与查询重写的基本概念 2. 创建测试环境 (1)建表 (2)写数据 3. 索引视图创建 (1)创建语法 (2)为索引视图创建索引 4. 查询重写 ...
- SQL Server物化视图学习笔记
一. 基本知识 摘抄自http://www.cnblogs.com/kissdodog/p/3385161.html SQL Server索引 - 索引(物化)视图 <第九篇> 索引视 ...
- SQL Server 索引结构及其使用(一)[转]
SQL Server 索引结构及其使用(一) 作者:freedk 一.深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索引(cluste ...
- SQL Server 索引和表体系结构(三)
SQL Server 索引和表体系结构(三) 原文:SQL Server 索引和表体系结构(三) 包含列索引 概述 包含列索引也是非聚集索引,索引结构跟聚集索引结构是一样,有一点不同的地方就是包含列索 ...
- SQL Server索引总结二
从CREATE开始 通过显式的CREATE INDEX命令 在创建约束时作为隐含的对象 随约束创建的隐含索引 当向表中添加如下两种约束之一时,就会创建隐含索引. 主键约束(聚集索引) 唯一约束(唯一索 ...
- 索引sql server_维护SQL Server索引
索引sql server In the previous articles of this series (see the full article TOC at bottom), we discus ...
- 索引sql server_SQL Server报告– SQL Server索引利用率
索引sql server Understanding indexing needs allows us to ensure that important processes run efficient ...
- sql错误索引中丢失_收集,汇总和分析丢失SQL Server索引统计信息
sql错误索引中丢失 描述 (Description) Indexing is key to efficient query execution. Determining what indexes a ...
最新文章
- Mac下安装PIL库
- python读取文件多行内容-Python读取文件、大文件和指定行内容的几种方法
- python拼音怎么写-【学习】python 汉语转拼音
- PHP 基本数据类型
- 数据库系统实训——实验二——单表查询
- 小米为什么拆分红米? | 畅言
- Python Cookbook(第3版)pdf
- 使用篇-基于Laravel开发博客应用系列 —— 联系我们 发送邮件 队列使用(基于数据库)...
- caffe运行问题(持续更新),sublime设置
- 暴力解决配置HTTPS后无法使用Hermit
- Server JRE 简介
- android 获取IP地址
- 读书笔记5 《精进:如何成为一个很厉害的人》 采铜
- python目前版本强势英雄_王者荣耀:分析S10星耀局以上一些强势英雄及版本目前排位的形势...
- 饥荒开服(含各种踩雷)
- 前端项目中常用的工具包(拖拽排序表格、打印导出表格、文本复制等)【持续更新~~~】
- 用实例给新手讲解易懂的RSA加密解密算法
- LoRa Gateway 笔记 3.1.3 帮助程序 util_pkt_logger 进行 LoRa 空口抓包
- oo 浏览文件服务器,文件服务器的配置.docx
- AdVoice广告录音制作软件如何音乐语音混音穿插制作广告