索引sql server_维护SQL Server索引
索引sql server
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of SQL Server tables and indexes, the guidelines that you can follow in order to design a proper index, the list of operations that can be performed on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes, the different types of SQL Server indexes (above and beyond Clustered and Non-clustered indexes classification), how to tune the performance of the inefficient queries using different types of SQL Server Indexes and finally, how to gather statistical information about index structure and the index usage. In this article, the last article in this series, we will discuss how to benefit from the previously gathered index information in maintaining SQL Server indexes.
在本系列的前几篇文章中(请参阅底部的完整文章TOC),我们讨论了SQL Server表和索引的内部结构,可以用来设计适当索引的指南,可以执行的操作列表。对SQL Server索引执行的操作,如何设计有效的聚集索引和非聚集索引,不同类型SQL Server索引(在聚集索引和非聚集索引分类之上和之外),如何使用不同类型调整低效率查询的性能SQL Server索引,最后,如何收集有关索引结构和索引使用情况的统计信息。 在本文,本系列的最后一篇文章中,我们将讨论如何在维护SQL Server索引时从先前收集的索引信息中受益。
One of the most important administration tasks that every database administrator should care about is maintaining database indexes. As we mentioned previously, you cannot create an index to enhance the performance of your queries and leave it forever without continuously monitoring its usage statistics. The index that fits you now, may degrade the performance of your query in the future, due to the different changes performed on your database data or schema. We discussed, in the previous articles, about gathering different types of information and statistics regarding indexes. Now we will use this gathered information to perform suitable maintenance tasks on that index.
每个数据库管理员应该关注的最重要的管理任务之一是维护数据库索引。 如前所述,您无法创建索引来增强查询的性能并将其永久保留,而无需持续监控其使用情况统计信息。 由于对数据库数据或架构执行的更改不同,现在适合您的索引将来可能会降低查询性能。 在之前的文章中,我们讨论了有关收集有关索引的不同类型的信息和统计信息。 现在,我们将使用这些收集的信息来对该索引执行适当的维护任务。
索引缺失和重复 (Missing and duplicate indexes)
The first thing to look at, in the context of index maintenance, is identifying and creating missing indexes. These are indexes that have been recommended and suggested by the SQL Server Engine to enhance the performance of your queries.
在索引维护的上下文中,要看的第一件事是识别并创建丢失的索引。 这些索引是SQL Server Engine推荐和建议的,可以增强查询的性能。
Review the Tracing and tuning queries using SQL Server indexes article to dig deeply into the missing indexes identification method.
查看“ 使用SQL Server索引进行跟踪和调优查询”一文,以深入研究缺少的索引识别方法。
Another area to concentrate on is the duplication of indexes. It is wort spending time in reviewing the columns that are participating in each index in your database, that is returned by querying the sys.index_columns and sys.indexes system objects described in the previous article, and identify the duplicate indexes that are created on the exact same columns then removing the same. Recall the overhead of indexes on the data modification and index maintaining operations and that it can lead to degraded performance.
另一个需要关注的领域是索引的重复。 浪费时间来检查数据库中每个索引所涉及的列,这些列是通过查询上一篇文章中描述的sys.index_columns和sys.indexes系统对象返回的,并标识在数据库上创建的重复索引。完全相同的列,然后删除相同的列。 回顾索引在数据修改和索引维护操作上的开销,它可能导致性能降低。
堆表 (Heap tables)
Heap tables are tables that contain no Clustered index. This means that the data rows, in the heap table, are not stored in any particular order within each data page. In addition, there is no particular order to control the data pages sequence, that is not linked in a linked list. As a result, retrieving from, inserting into or modifying data in the heap table will be very slow and can be fragmented more easily.
堆表是不包含聚簇索引的表。 这意味着堆表中的数据行不会在每个数据页内以任何特定顺序存储。 另外,没有特殊的顺序来控制数据页的顺序,即未在链接列表中链接。 结果,从堆表中检索,插入或修改数据将非常缓慢,并且可以更轻松地进行分段。
For more information about the heap table, review SQL Server table structure overview.
有关堆表的更多信息,请查看SQL Server表结构概述。
You need first to identify the heap tables in your database and concentrate only on the large tables, as the SQL Server Query Optimizer will not benefit from the indexes created on smaller tables. Heap tables can be detected by querying the sys.indexes system object, in conjunction with other system catalog views, to retrieve meaningful information, as shown in the T-SQL script below:
首先,您需要确定数据库中的堆表,并且只专注于大型表,因为SQL Server Query Optimizer不会从较小表上创建的索引中受益。 可以通过查询sys.indexes系统对象以及其他系统目录视图以检索有意义的信息来检测堆表,如下面的T-SQL脚本所示:
SELECT OBJECT_NAME(IDX.object_id) Table_Name, IDX.name Index_name, PAR.rows NumOfRows, IDX.type_desc TypeOfIndex
FROM sys.partitions PAR
INNER JOIN sys.indexes IDX ON PAR.object_id = IDX.object_id AND PAR.index_id = IDX.index_id AND IDX.type = 0
INNER JOIN sys.tables TBL
ON TBL.object_id = IDX.object_id and TBL.type ='U'
From the previous query result, identify the large heap tables and creating a Clustered index on these tables to enhance the performance of the queries reading from these tables. The result in our case will be as shown below:
从上一个查询结果中,识别出大堆表并在这些表上创建聚簇索引,以增强从这些表读取的查询的性能。 在本例中,结果将如下所示:

未使用的索引 (Unused indexes)
In the previous article, we mentioned two ways to gather usage information about database indexes, the first one using the sys.dm_db_index_usage_stats DMV and the second way using the Index Usage Statistics standard report. Unused indexes that are not used in any seek or scan operations, or are relatively small, or are updated heavily should be removed from your table, as it will degrade data modification and index maintenance operations performance, instead of enhancing the performance of your queries.
在上一篇文章中,我们提到了两种收集有关数据库索引的使用情况信息的方法,一种是使用sys.dm_db_index_usage_stats DMV,另一种是使用索引使用情况统计标准报告。 应该从表中删除未在任何查找或扫描操作中使用的,未使用的索引,较小的索引或已大量更新的未使用索引,因为这会降低数据修改和索引维护操作的性能,而不是增强查询的性能。
The best way to deal with the unused indexes is dropping them. But before doing that, make sure that …
处理未使用的索引的最佳方法是删除它们。 但是在执行此操作之前,请确保...
- this index is not a newly created index, 该索引不是新创建的索引,
- that the system will use in the near future, 该系统将在不久的将来使用,
- and that the SQL Server has not been restarted recently 并且SQL Server最近没有重新启动
The reason for this is that the results of these two methods will be refreshed each time the SQL Server restarted and may provide incomplete information to base index removal on. In the case of an inefficiently used Clustered index, make sure to replace it with another one and not keeping the table as heap.
这样做的原因是,每次SQL Server重新启动时,这两种方法的结果都会刷新,并且可能会为索引删除提供不完整的信息。 如果群集索引使用效率低下,请确保将其替换为另一个索引,并且不要将表保留为堆。
修复索引碎片 (Fix index fragmentation )
In SQL Server, most tables are transactional tables, that are not static but are changing over time. Index fragmentation occurs when the logical ordering of the index pages, based on the key value, does not match the physical ordering inside the data file. We discussed previously that, due to frequent data insertion and modification operations, the index pages will be split and fragmented, when the page is full, or the current free space is not fit the newly inserted or updated value, increasing the amount of disk I/O operations required to read the requested data.
在SQL Server中,大多数表都是事务性表,它们不是静态的,而是随时间变化的。 当索引页基于键值的逻辑顺序与数据文件内部的物理顺序不匹配时,就会发生索引碎片。 前面我们讨论过,由于频繁的数据插入和修改操作,索引页将在页面已满或当前可用空间不适合新插入或更新的值时被拆分和分段,从而增加了磁盘I的数量。读取请求的数据所需的/ O操作。
On the other hand, setting the Fill Factor and pad_index index creation options with the proper values will help in reducing the index fragmentation and page split issues. Different ways to gather fragmentation information about the database indexes, such as querying the sys.dm_db_index_physical_stats dynamic management function and Index Physical Statistics standard report, are mentioned in detail in the previous article.
另一方面,将“ Fill Factor”和“ pad_index”索引创建选项设置为适当的值将有助于减少索引碎片和页面拆分问题。 上一篇文章中详细介绍了收集有关数据库索引的碎片信息的不同方法,例如查询sys.dm_db_index_physical_stats动态管理功能和“ 索引物理统计”标准报告。
Index defragmentation makes sure that the index pages are contiguous, providing faster and more efficient way to access the data, instead of reading from spread out pages across multiple separate pages.
索引碎片整理可确保索引页面是连续的,从而提供了更快,更有效的访问数据的方式,而不是从分布在多个单独页面中的页面读取数据。
SQL Server provides us with different ways to fix the index fragmentation problem. The first method is using the DBCC INDEXDEFRAG command, that defragments the leaf level of an index, serially one index at a time using a single thread, in a way that allows the physical order of the pages to match the left-to-right logical order of the leaf nodes, improving scanning performance of the index. The DBCC INDEXDEFRAG command is an online operation that holds no long-term locks on the underlying database object without affecting any running queries or updates. The time required to defragment an index depends mainly on the level of fragmentation, where an index with a small fragmentation percentage can be defragmented faster than a new index can be built. On the other hand, an index that is very fragmented might take considerably longer to defragment than to rebuild. If the DBCC INDEXDEFRAG command is stopped at any time, all completed work will be retained.
SQL Server为我们提供了解决索引碎片问题的不同方法。 第一种方法是使用DBCC INDEXDEFRAG命令,该命令对索引的叶级别进行碎片整理,使用单个线程一次对一个索引进行一次序列化,其方式允许页面的物理顺序与从左到右的逻辑顺序匹配叶节点的顺序,提高索引的扫描性能。 DBCC INDEXDEFRAG命令是一个联机操作,不对基础数据库对象持有任何长期锁定,而不会影响任何正在运行的查询或更新。 对索引进行碎片整理所需的时间主要取决于碎片级别,在这种情况下,碎片百分比较小的索引可以比建立新索引更快地进行碎片整理。 另一方面,非常零散的索引进行碎片整理可能要比重建花费更长的时间。 如果任何时候停止DBCC INDEXDEFRAG命令,将保留所有已完成的工作。
Assume that we have the below index with fragmentation percentage equal to 99.72%, as shown in the snapshot below, taken from the index properties:
假设下面的索引的碎片百分比等于99.72%,如下面的快照所示,该索引取自索引属性:
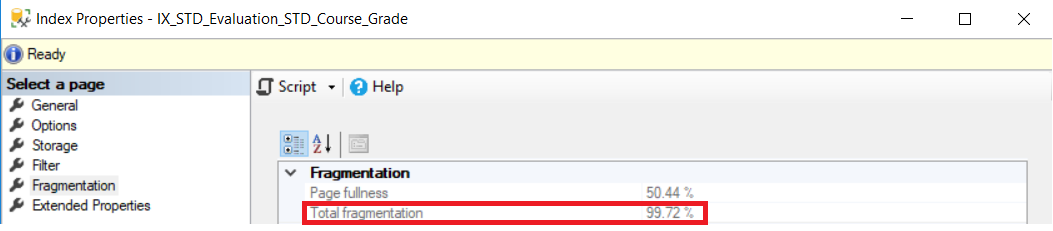
The DBCC INDEXDEFRAG command can be used to defragment all indexes in a specific database, all indexes in a specific table or a specific index only depend on the provided parameters. The below script is used to defragment the previous index that has very high fragmentation percentage:
DBCC INDEXDEFRAG命令可用于对特定数据库中的所有索引进行碎片整理,特定表中的所有索引或特定索引仅取决于所提供的参数。 以下脚本用于对碎片率很高的先前索引进行碎片整理:
DBCC INDEXDEFRAG (IndexDemoDB, 'STD_Evaluation', IX_STD_Evaluation_STD_Course_Grade);
GO
The result returned from the command, shows the number of pages that are scanned, moved and removed during the defragmentation process, as shown below:
从命令返回的结果显示在碎片整理过程中扫描,移动和删除的页面数,如下所示:
Checking the fragmentation percentage after running the DBCC INDEXDEFRAG command, the fragmentation percentage become less than 1% as shown below:
运行DBCC INDEXDEFRAG命令后检查碎片百分比,碎片百分比小于1%,如下所示:
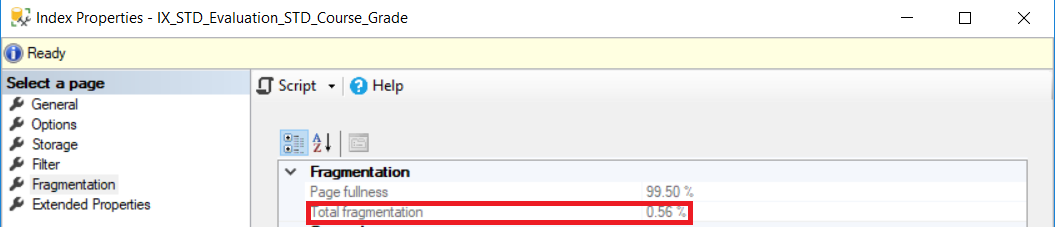
Index fragmentation can be also resolved by rebuilding and reorganizing the SQL Server indexes regularly. The Index Rebuild operation removes fragmentation by dropping the index and creating it again, defragmenting all index levels, compacting the index pages using the Fill Factor values specified in rebuild command, or using the existing value if not specified and updating the index statistics using FULLSCAN of all the data. Recall that rebuilding a disabled index brings it back to life. The index rebuild operation can be performed online, without locking other queries when using the SQL Server Enterprise edition, or offline by holding locks on the database objects during the rebuild operation. In addition, the index rebuild operation can use parallelism when using Enterprise edition. On the other hand, if the rebuild operation failed, a heavy rollback operation will be performed. The index can be rebuilt using ALTER INDEX REBUILD T-SQL command.
索引碎片还可以通过定期重建和重新组织SQL Server索引来解决。 索引重建操作通过删除索引并再次创建索引,对所有索引级别进行碎片整理,使用rebuild命令中指定的“填充因子”值压缩索引页面或使用现有值(如果未指定)并使用FULLSCAN更新索引统计信息来消除碎片。所有数据。 回想一下,重建一个禁用的索引可以使其恢复活力。 索引重建操作可以在线执行,而在使用SQL Server Enterprise版本时不锁定其他查询,也可以通过在重建操作过程中对数据库对象保持锁定来离线执行。 另外,使用企业版时,索引重建操作可以使用并行性。 另一方面,如果重建操作失败,则将执行大量的回滚操作。 可以使用ALTER INDEX REBUILD T-SQL命令来重建索引 。
The Index Reorganize operation physically reorders leaf level pages of the index to match the logical order of the leaf nodes. The index reorganize operation will be always performed online. Microsoft recommends fixing index fragmentation issues by rebuilding the index if the fragmentation percentage of the index exceeds 30%, where it recommends fixing the index fragmentation issue by reorganizing the index if the index fragmentation percentage exceeds 5% and less than 30%. The index reorganize operation will use single thread only, regardless of the SQL Server Edition used. On the other hand, if the reorganize operation fails, it will stop where it left off, without rolling back the reorganize operation. The index can be reorganized using ALTER INDEX REORGANIZE T-SQL command.
索引重新组织操作对索引的叶级页面进行物理重新排序,以匹配叶节点的逻辑顺序。 索引重组操作将始终在线执行。 Microsoft建议如果索引的碎片百分比超过30%,则通过重建索引来解决索引碎片问题;如果索引碎片的百分比超过5%并且小于30%,Microsoft建议通过重组索引来解决索引碎片问题。 索引重组操作将仅使用单线程,而不管所使用SQL Server版本如何。 另一方面,如果重组操作失败,它将在停止的地方停止,而不会回滚重组操作。 可以使用ALTER INDEX REORGANIZE T- SQL命令重新组织索引 。
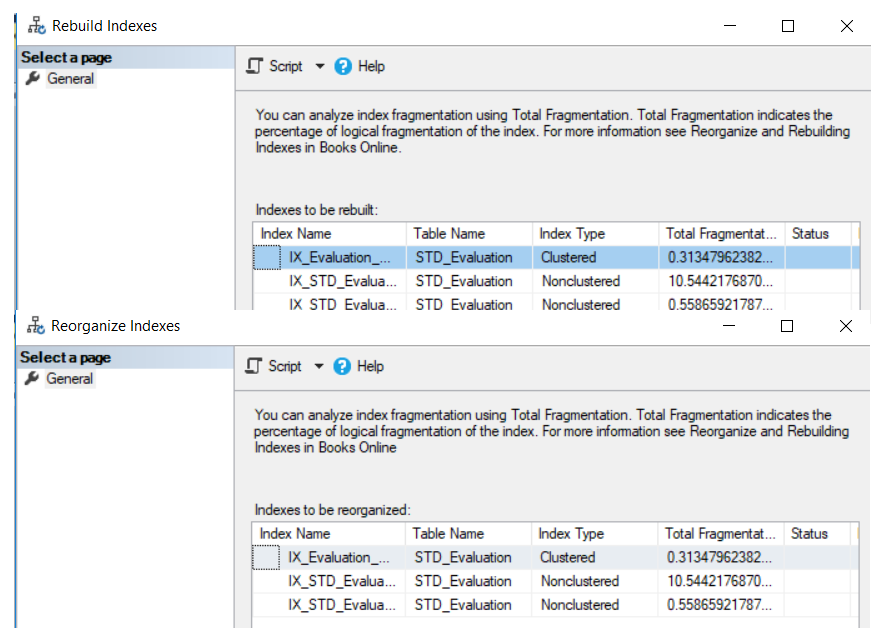
The index can be rebuilt or reorganized using SQL Server Management Studio by browsing the Indexes node under your table, choose the index that you manage to defragment, right-clicking on that index and choose the Rebuild or Reorganize option, based on the fragmentation percentage of that index, as shown below:
可以使用SQL Server Management Studio通过以下方式来重建或重新组织索引 :浏览表下的“ 索引”节点,选择要进行碎片整理的索引,右键单击该索引,然后根据碎片的百分比选择“重新构建或重新组织”选项。该索引,如下所示:
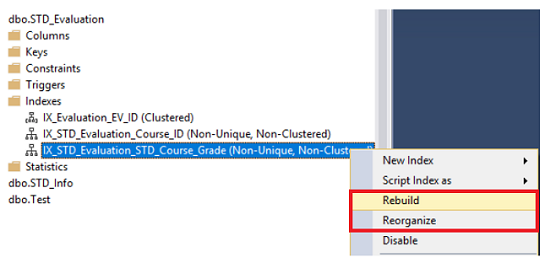
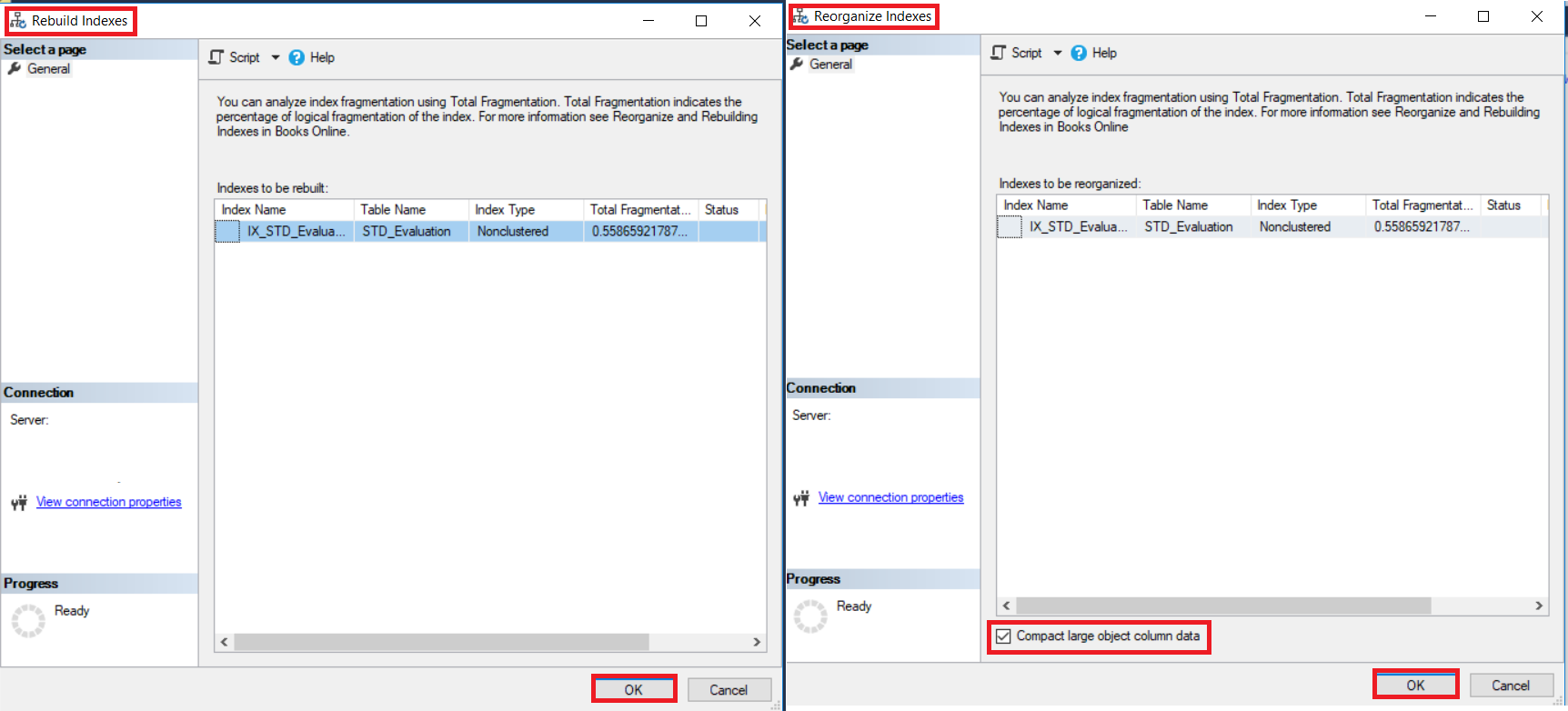
In the displayed Rebuild or Reorganize windows, click on the OK button to defragment the selected index, with the ability to compact all column data that contains LOB data while reorganizing the index, with the fragmentation level of each index, as shown in the snapshot below:
在显示的“重建或重新组织”窗口中,单击“确定”按钮以对所选索引进行碎片整理,并能够在重组索引的同时压缩包含LOB数据的所有列数据,并具有每个索引的碎片级别,如下面的快照所示。 :
SQL Server allows you to rebuild or reorganize all table indexes, by right-clicking on the Indexes node under your table and choose to Rebuild All or Reorganize All option, as shown below:
SQL Server允许您通过右键单击表下的Indexes节点并选择Rebuild All或Reorganize All选项来重建或重新组织所有表索引,如下所示:
The displayed rebuild or reorganize window will list all the table indexes that will be defragmented using that operation, with the fragmentation level of each index, as shown in the snapshots below:
显示的“重建或重组”窗口将列出使用该操作将进行碎片整理的所有表索引,以及每个索引的碎片级别,如以下快照所示:
The same operations can be also performed using T-SQL commands. You can rebuild the previous index, using the ALTER INDEX REBUILD T-SQL command, with the ability to set the different index creation options, such as the FILL FACTOR, ONLINE or PAD_INDEX, as shown in below:
也可以使用T-SQL命令执行相同的操作。 您可以使用ALTER INDEX REBUILD T-SQL命令重建先前的索引,并能够设置不同的索引创建选项,例如FILL FACTOR,ONLINE或PAD_INDEX,如下所示:
USE [IndexDemoDB]
GO
ALTER INDEX [IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
Also, the index can be reorganized, using the ALTER INDEX REORGANIZE T-SQL command below:
另外,可以使用下面的ALTER INDEX REORGANIZE T-SQL命令重新组织索引:
USE [IndexDemoDB]
GO
ALTER INDEX [IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
You can also organize all the table indexes, by providing the ALTER INDEX REORGANIZE T-SQL statement with ALL option, instead of the index name, as in the T-SQL statement below:
您还可以通过为ALTER INDEX REORGANIZE T-SQL语句提供ALL选项而不是索引名来组织所有表索引,如下面的T-SQL语句所示:
ALTER INDEX ALL ON [dbo].[STD_Evaluation]
REORGANIZE ;
GO
And rebuild all the table indexes, by providing the ALTER INDEX REBUILD T-SQL statement with ALL option, instead of the index name, as in the T-SQL statement below:
并通过提供带有ALL选项的ALTER INDEX REBUILD T-SQL语句(而不是索引名称)来重建所有表索引,如下面的T-SQL语句所示:
ALTER INDEX ALL ON [dbo].[STD_Evaluation]
REBUILD WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
In SQL Server 2014, new functionality was introduced that allows us to control how the locking mechanism, that is required by the online index rebuild operation, is handled. This mechanism is called Managed Lock Priority, that benefits from the newly defined Low-Priority queue that contains the processes with priorities lower than the ones waiting in the wait queue, giving the database administrator the ability to manage the waiting priorities.
在SQL Server 2014中,引入了新功能,使我们可以控制如何处理在线索引重建操作所需的锁定机制。 这种机制称为Managed Lock Priority ,它受益于新定义的Low-Priority队列,该队列包含优先级低于等待队列中的进程的进程,从而使数据库管理员能够管理等待的优先级。
For more information, check out How to control online Index Rebuild Locking using SQL Server 2014 Managed Lock Priority.
有关更多信息,请查看如何使用SQL Server 2014 Managed Lock Priority控制联机索引重建锁定 。
维护索引统计 (Maintain the index statistics)
Index statistics are used by the SQL Server Query Optimizer to determine if the index will be used in query execution. Outdated statistics will lead the Query Optimizer to select the wrong index while executing the query. From the SQL Server operating system aspect, when selecting an index, the SQL Server Query Optimizer will ignore the index if it has a high fragmentation percentage (as searching in it will cost more than the table scan), the index values are not very unique, the index statistics are outdated or the columns order in the query does not match the index key columns order.
SQL Server查询优化器使用索引统计信息来确定是否在查询执行中使用索引。 过时的统计信息将导致查询优化器在执行查询时选择错误的索引。 从SQL Server操作系统的角度来看,当选择索引时,如果SQL Server Query Optimizer的碎片率很高(因为在其中进行搜索将比在表扫描中花费更多),则它将忽略该索引,因此索引值不是很唯一,索引统计信息已过时或查询中的列顺序与索引键列顺序不匹配。
Index statistics can be updated automatically by the SQL Server Engine, or manually using the sp_updatestats stored procedure, that runs UPDATE STATISTICS against all user-defined and internal tables in the current database, or using the UPDATE STATISTICS T-SQL command, that can be used to update the statistics of all the table indexes or update the statistics of a specific index in the table.
索引统计信息可以由SQL Server引擎自动更新,也可以使用sp_updatestats存储过程手动更新,该存储过程针对当前数据库中的所有用户定义表和内部表运行UPDATE STATISTICS,或者使用UPDATE STATISTICS T-SQL命令。用于更新所有表索引的统计信息或更新表中特定索引的统计信息。
The below T-SQL statement is used to update the statistics of all indexes under the STD_Evaluation table:
下面的T-SQL语句用于更新STD_Evaluation表下所有索引的统计信息:
UPDATE STATISTICS STD_Evaluation;
GO
Where the below T-SQL statement will update the statistics of only one index, under that table:
下面的T-SQL语句将仅更新该表下一个索引的统计信息:
UPDATE STATISTICS STD_Evaluation IX_STD_Evaluation_STD_Course_Grade;
GO
You can also update the statistics of all the table indexes, by specifying the sampling rows percentage, as shown in the T-SQL statement below:
您还可以通过指定采样行百分比来更新所有表索引的统计信息,如下面的T-SQL语句所示:
UPDATE STATISTICS STD_Evaluation WITH SAMPLE 50 PERCENT;
Or forced it to scan all the table rows during the table’s statistics update, using the FULLSCAN option, shown below:
或者使用表中所示的FULLSCAN选项强制其在表的统计信息更新期间扫描所有表行 下面:
UPDATE STATISTICS STD_Evaluation WITH FULLSCAN, NORECOMPUTE;
GO
自动化SQL Server索引维护 (Automating SQL server index maintenance)
Until this point, we are familiar with how to make a decision if we will rebuild or reorganize a SQL Server index, based on the fragmentation percentage, and how to defragment a specific index or all table indexes using the rebuild or reorganize methods. We also reviewed the importance of performing the different types of index maintenance tasks regularly, in order to allow the SQL Server Query Optimizer to consider these indexes to enhance the performance of the different queries and minimize the overhead of these indexes on the overall database system.
在此之前,我们熟悉如何根据碎片百分比来决定是否重建或重新组织SQL Server索引,以及如何使用重建或重新组织方法对特定索引或所有表索引进行碎片整理。 我们还回顾了定期执行不同类型的索引维护任务的重要性,以便允许SQL Server查询优化器考虑这些索引,以增强不同查询的性能并最大程度地减少这些索引在整个数据库系统上的开销。
On the other hand, performing index maintenance tasks manually is not a good practice, as these operations may take a long time that the DBA will not have that patience to wait for, in addition to that the DBA is not always available to remember running these tasks, which may lead to cumulatively high fragmentation percentage.
另一方面,手动执行索引维护任务不是一个好习惯,因为这些操作可能需要很长时间才能使DBA没有耐心等待,此外,DBA并非总是可以记住运行这些操作任务,这可能导致累积的碎片百分比很高。
There are two options to automate the indexes maintenance. The first option is to schedule a customized index maintenance script, to rebuild, reorganize, defrag and update statistics based on the index fragmentation percentage using SQL Server Agent job, that can be your own script based on your system behavior and requirement, or customize my favorite flexible Ola Hallengren’s index maintenance script, that provide you with large number of options that can fit wide range of systems behaviors.
有两个选项可以自动执行索引维护。 第一种选择是安排一个自定义的索引维护脚本,使用SQL Server代理作业基于索引碎片百分比重建,重新组织,整理碎片和更新统计信息,该脚本可以是基于系统行为和要求的自己的脚本,或者自定义最喜欢的灵活Ola Hallengren的索引维护脚本,它为您提供了许多选项,可以适应各种系统行为。
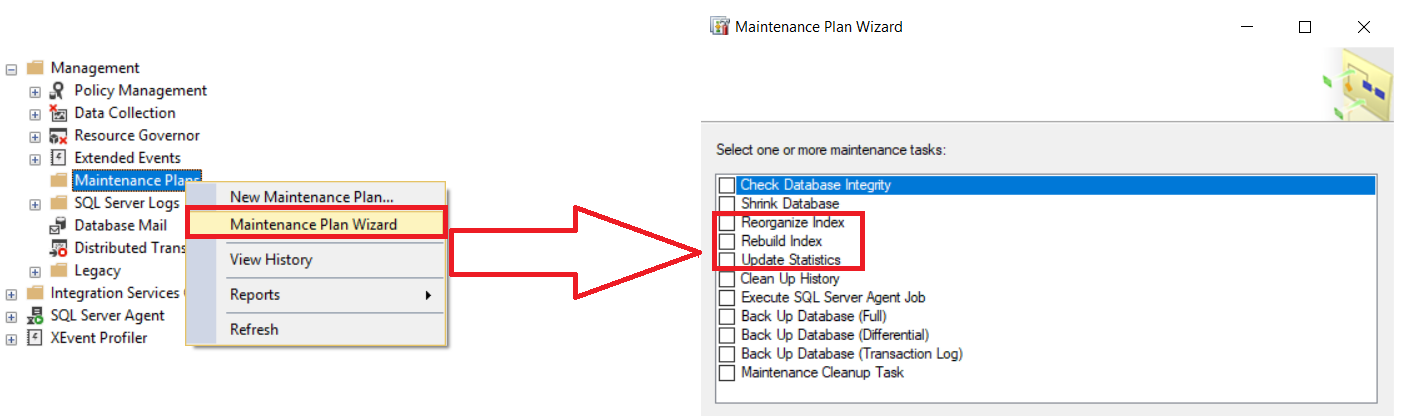
The second option to automate the index maintenance tasks is using the Rebuild Index, Reorganize Index and Update Statistics Maintenance Plans, from the Management nodes, as shown below:
自动化索引维护任务的第二个选项是使用管理节点中的“重建索引”,“重组索引”和“更新统计信息维护计划”,如下所示:
You need to specify the name of the database or databases that you manage to perform the index maintenance task on, with the ability to narrow it to be performed on a specific table or table, and schedule that maintenance to be performed during the non-peak time, based on workload that specifies the maintenance windows available on your company, your database structure, how fast the data is fragmented and the SQL Server Edition. Recall that the downtime required to perform index maintenance tasks can be decreased by using the Enterprise Edition, that allows you to perform the index rebuild operation online and use parallel plans.
您需要指定要在其上执行索引维护任务的一个或多个数据库的名称,并能够缩小要在特定表或表上执行的索引的能力,并安排在非高峰期执行的维护时间,该时间基于指定公司上可用的维护窗口的工作量,数据库结构,数据分段的速度以及SQL Server Edition。 回想一下,使用Enterprise Edition可以减少执行索引维护任务所需的停机时间,该版本使您可以在线执行索引重建操作并使用并行计划。
Using SQL Server Maintenance Plans to automate the index maintenance tasks is not a preferred option when using SQL Server versions prior to 2016, due to lack of control on these heavy operations. This is because these maintenance tasks will be performed on all table or database indexes regardless of the fragmentation percentage of these indexes. Such operations will require long maintenance window and will intensively consume the server resources when maintaining large databases.
在2016年之前使用SQL Server版本时,由于对这些繁琐的操作缺乏控制,因此使用SQL Server维护计划来自动化索引维护任务不是首选方法。 这是因为这些维护任务将在所有表或数据库索引上执行,而不管这些索引的碎片百分比如何。 此类操作将需要较长的维护时间,并且在维护大型数据库时将大量消耗服务器资源。
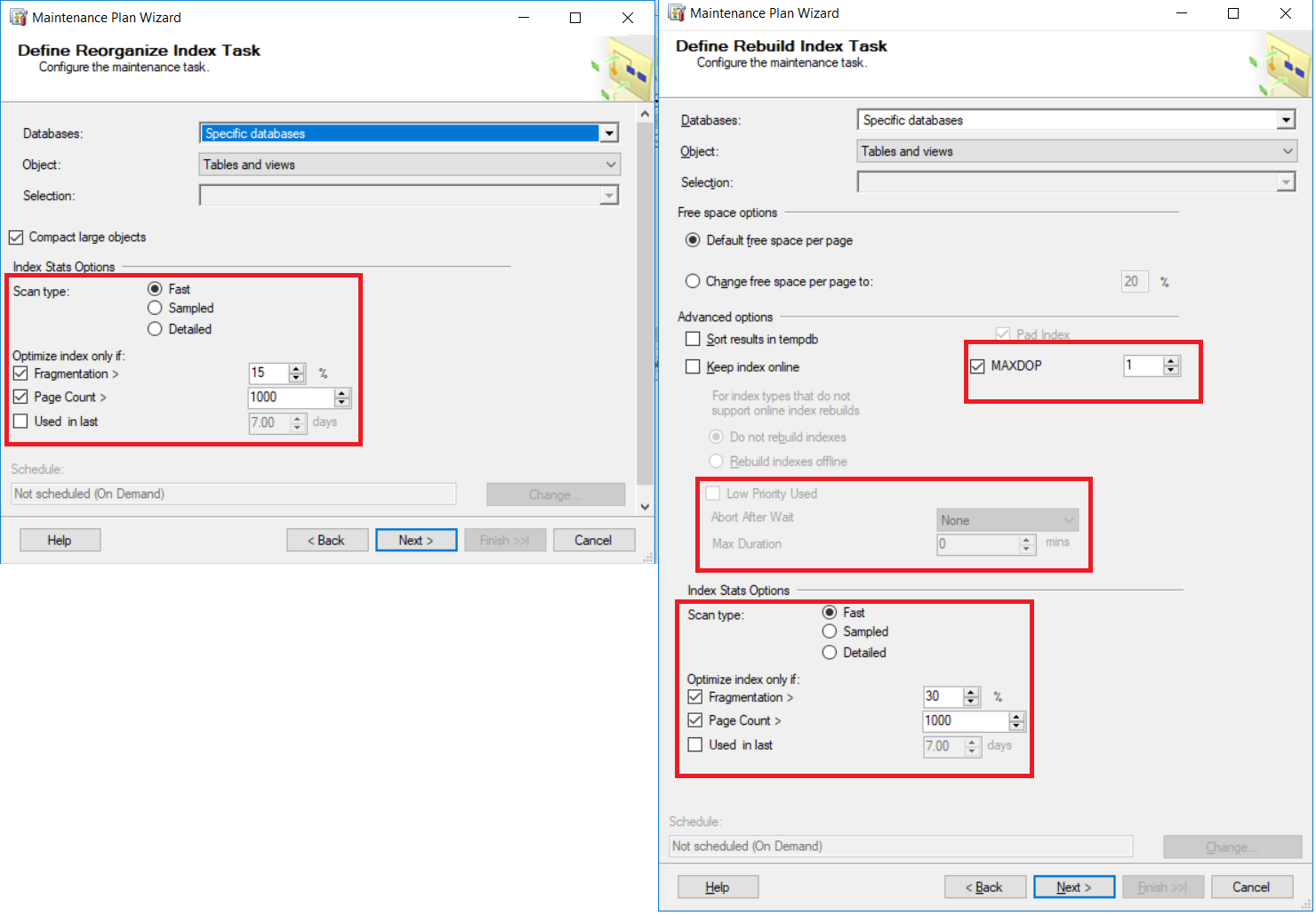
Starting from SQL Server 2016, new options were added to the index maintenance tasks that allow us to perform the Rebuild Index and Reorganize Index tasks, based on the fragmentation percentage of the index, and other useful options to control the index maintenance process.
从SQL Server 2016开始,新的选项已添加到索引维护任务中,使我们能够根据索引的碎片百分比执行“重建索引”和“重新组织索引”任务,以及其他用于控制索引维护过程的有用选项。
For more information about this enhancement, check the SQL Server 2016 Maintenance Plan Enhancements.
有关此增强功能的更多信息,请检查“ SQL Server 2016维护计划增强功能” 。
The following snapshots summarize how we can specify the fragmentation percentage parameters for both the index rebuild and reorganize maintenance plans, and other controlling options, as shown below:
以下快照概述了如何为索引重建和重组维护计划以及其他控制选项指定碎片百分比参数,如下所示:
索引维护要求 (Index maintaining requirements)
When you rebuild an index, additional temporary disk space is required during theoperation to store a copy of the old index, rolling back the changes in case of failure, and to isolate the index online rebuild operation from the effects of modifications made by other transactions using row versioning and sorting the index key values. If the SORT_IN_TEMPDB option is enabled, tempdb space, that fits the index size, should be available to sort the index values. This option speeds up the index rebuild process by separating the index transactions from the concurrent user transactions, if the tempdb database is in a separate disk drive. On the other hand, additional permanent disk space is required to store the new structure of the index.
重建索引时,在操作过程中需要额外的临时磁盘空间来存储旧索引的副本,在发生故障的情况下回滚更改,并使索引联机重建操作与其他事务使用行版本控制和索引索引值排序。 如果启用了SORT_IN_TEMPDB选项,则适合索引大小的tempdb空间应可用于对索引值进行排序。 如果tempdb数据库位于单独的磁盘驱动器中,则此选项通过将索引事务与并发用户事务分开来加快索引重建过程。 另一方面,需要额外的永久磁盘空间来存储索引的新结构。
To perform large-scale operations, such as index Rebuild and Reorganize operations, that can fill the transaction log quickly, the database transaction log file should have sufficient free space to store the index operation transactions, that will not be truncated until the operation is completed successfully, and any concurrent user transactions performed during the index operation.
为了执行可以快速填充事务日志的大规模操作(例如索引重建和重组操作),数据库事务日志文件应具有足够的可用空间来存储索引操作事务,直到操作完成后才会被截断成功,以及在索引操作期间执行的所有并发用户事务。
The huge amount of log transactions written to the database transaction log files during the index defragment operations requires a longer time to backup the transaction log file. This effect can be minimized by performing transaction log backups more frequently during index maintenance operations or changing the database recovery model to SIMPLE or BULK LOGGED to minimize the logging during that operation, if applicable. In addition, extra network overhead will be caused by pushing a large amount of transaction logs to the mirrored or Availability Groups secondary servers. If a noticeable network issue is caused during index maintenance operations, you can overcome that issue by pausing the data synchronization process during the index maintenance operations, if applicable.
在索引碎片整理操作期间,写入数据库事务日志文件的大量日志事务需要更长的时间来备份事务日志文件。 通过在索引维护操作期间更频繁地执行事务日志备份,或将数据库恢复模型更改为SIMPLE或BULK LOGGED,以最大程度地减少该操作期间的日志记录(如果适用),可以将这种影响最小化。 此外,由于将大量事务日志推送到镜像或可用性组辅助服务器,将导致额外的网络开销。 如果在索引维护操作期间引起了明显的网络问题,则可以通过在索引维护操作期间暂停数据同步过程来解决该问题(如果适用)。
结论 (Conclusion)
In this articles series, we tried to cover all concepts that are related to the SQL Server indexing, starting from the basic structure of the SQL Server tables and indexes, diving in designing the indexes and tuning the queries using these indexes, and finishing with gathering statistical information about the index and use this information to maintain the indexes. I hope that you enjoyed this series and improved your knowledge.
在本系列文章中,我们尝试涵盖与SQL Server索引相关的所有概念,从SQL Server表和索引的基本结构开始,着重设计索引并使用这些索引调整查询,最后完成收集工作。有关索引的统计信息,并使用此信息来维护索引。 我希望您喜欢这个系列并提高您的知识。
目录 (Table of contents)
| SQL Server indexes – series intro |
| SQL Server table structure overview |
| SQL Server index structure and concepts |
| SQL Server index design basics and guidelines |
| SQL Server index operations |
| Designing effective SQL Server clustered indexes |
| Designing effective SQL Server non-clustered indexes |
| Working with different SQL Server indexes types |
| Tracing and tuning queries using SQL Server indexes |
| Gathering SQL Server index statistics and usage information |
| Maintaining SQL Server Indexes |
| Top 25 interview questions and answers about SQL Server indexes |
| SQL Server索引–系列介绍 |
| SQL Server表结构概述 |
| SQL Server索引结构和概念 |
| SQL Server索引设计基础和准则 |
| SQL Server索引操作 |
| 设计有效SQL Server群集索引 |
| 设计有效SQL Server非聚集索引 |
| 使用不同SQL Server索引类型 |
| 使用SQL Server索引跟踪和调整查询 |
| 收集SQL Server索引统计信息和使用情况信息 |
| 维护SQL Server索引 |
| 有关SQL Server索引的25个最佳面试问答 |
翻译自: https://www.sqlshack.com/maintaining-sql-server-indexes/
索引sql server
索引sql server_维护SQL Server索引相关推荐
- 索引sql server_优化SQL Server索引策略
索引sql server 指数策略概述 (Index strategies overview) This article is about techniques for optimizing the ...
- 索引sql server_有关SQL Server索引的十大问题和解答
索引sql server 介绍 (Introduction) Without a doubt, few technologies in SQL Server cause as much confusi ...
- 游标sql server_学习SQL:SQL Server游标
游标sql server SQL Server cursors are one common topic on the Internet. You'll find different opinions ...
- 游标sql server_使用SQL Server游标–优点和缺点
游标sql server 介绍 (Intro) In relational databases, operations are made on a set of rows. For example, ...
- java连接数据库sql server_将SQL Server数据库连接到Java
我的项目没有使用任何IDE. 整个编码使用Textpad完成. 所以我需要帮助连接sql server数据库和我的项目. 这是bean类,其中编写了用于数据库连接的业务逻辑. 我已经安装了SQL服务器 ...
- oracle 建分区索引_Oracle的分区表和Local索引创建与维护
Oracle的分区表和Local索引创建与维护 SQL> connect eygle/eygle Connected. SQL> CREATE TABLE dbobjs 2 (OBJEC ...
- 关于SQL Server中索引使用及维护简介
一.聚簇索引(clustered indexes)的使用 聚簇索引是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序.由于聚簇索引的索引页面指针指向数据页面,所以使用聚簇索引查找数据几乎总是 ...
- SQL Server索引的创建与维护
文章目录 创建索引 聚集索引与非聚集索引 [聚集索引设计] [非聚集索引设计] 填充因子 重新组织和重新生成 索引碎片 页面密度 创建索引 SQL Server的索引较为常用的有聚集索引.非聚集索引. ...
- SQL Server索引设计 第五篇
SQL Server索引的设计主要考虑因素如下: 检查WHERE条件和连接条件列: 使用窄索引: 检查列的选择性: 检查列的数据类型: 考虑列顺序: 考虑索引类型(聚集索引OR非聚集索引): 一.检查 ...
最新文章
- 数据持久化(六)之Using CoreData with MagicalRecord
- java安全编码指南之:堆污染Heap pollution
- 概率论 - BZOJ - 4001 TJOI2015
- Windows 操作系统的安全设置
- 私家车合乘系统 matlab,私家车贴上邻里合乘标志 武汉探路拼车合法化
- Hbase(2)——基础语句(2)
- android 折叠式布局,Android卡片式折叠交互效果
- Ecstore中的微信支付怎么样配置
- 11.性能之巅 洞悉系统、企业与云计算 --- 云计算
- 设置Cookie的生命周期
- ROS(indigo) 安装和使用更新版本的Gazebo----3,4,5,6,7 附:中国机器人大赛中型组仿真比赛说明
- 【tensorrt】——插件写法及python plugin大体流程
- vue的组件/data的参数/组件传值/插槽/侦听器/生命周期钩子函数
- Jooq新手在SpringBoot中接入Jooq
- 我如何使用iPad作为学习工具
- 网易云音乐真实链接地址
- 把图片修改为单色图片
- Linux shell脚本实现归档文件
- SSM 农产品销售管理系统
- 缓存与数据库的数据更新