分布式数据库实战第七节 分布式数据库的现状与未来
24 现状解读:分布式数据库的最新发展情况
你好,恭喜你坚持到了课程的最后一讲。
上一讲,我们探讨了实现数据库中间件的几种技术,包括全局唯一主键、分片策略和跨分片查询,其中最重要的就是分布式事务,希望你可以掌握它。这一讲作为收尾,我将为你介绍 NewSQL 数据库。
首先我试着去定义 NewSQL,它是一类现代的关系型数据库,同时它又具备 NoSQL 的扩展能力。其擅长在 OLTP 场景下提供高性能的读写服务,同时可以保障事务隔离性和数据一致性。我们可以简单理解为,NewSQL 要将 2000 年左右发展而来的 NoSQL 所代表的扩展性与 20 世纪 70 年代发展的关系模型 SQL 和 ACID 事务进行结合,从而获得一个高并发关系型的分布式数据库。
如果我们使用 NewSQL 数据库,可以使用熟悉的 SQL 来与数据库进行交互。SQL 的优势我在模块一中已经有了深入的介绍。使用 SQL 使得原有基于 SQL 的应用不需要改造(或进行微量改造)就可以直接从传统关系型数据库切换到 NewSQL 数据库。而与之相对,NoSQL 数据库一般使用 SQL 变种语言或者定制的 API,那么用户切换到 NoSQL 数据库将会面临比较高的代价。
对于 NewSQL 的定义和适用范围一直存在争议。有人认为 Vertica、Greenplum 等面向 OLAP 且具有分布式特点的数据库也应该归到 NewSQL 里面。但是,业界更加广泛接受的 NewSQL 标准包括:
执行短的读写事务,也就是不能出现阻塞的事务操作;
使用索引去查询一部分数据集,不存在加载数据表中的全部数据进行分析;
采用 Sharded-Nothing 架构;
无锁的高并发事务。
根据以上这些特点,我总结为:一个 NewSQL 数据库是采用创新架构,透明支持 Sharding,具有高并事务的 SQL 关系型数据库。
请注意 DistributedSQL 是一类特殊的 NewSQL,它们可以进行全球部署。
下面就按照我给出的定义中的关键点来向你详细介绍 NewSQL 数据库。
创新的架构
使用创新的数据库架构是 NewSQL 数据库非常引人注目的特性。这种新架构一般不会依靠任何遗留的代码,这与我在“22 | 发展与局限:传统数据库在分布式领域的探索”中介绍的依赖传统数据库作为计算存储节点非常不同。我们以 TiDB 这个典型的 NewSQL 数据库为例。
![]()

可以看到其中的创新点有以下几个。
存储引擎没有使用传统数据库。而使用的是新型基于 LSM 的 KV 分布式存储引擎,有些数据库使用了完全内存形式的存储引擎,比如 NuoDB。
Sharded-Nothing 架构。底层存储到上层工作负载都是独立部署的。
高性能并发事务。TiDB 实现了基于 Percolator 算法的高性能乐观事务。
透明分片。TiDB 实现了自动的范围分片,可以弹性地增减节点。
基于复制技术的自动容灾。使用 Raft 算法实现高可用的数据复制,自动进行故障转移。
可以说,NewSQL 与传统关系型数据库之间的交集在于 SQL 与 ACID 事务,从而保证用户的使用习惯得以延续。
以上描述的创新点我在前两个模块都有详细的说明。这里不知道你是否注意到一个问题:与使用传统数据库构建分布式数据库相比,NewSQL 最为明显的差异来自存储引擎。特别是以 Spanner 为首的一众 NewSQL 数据库,如 YugaByte DB、CockroachDB 和 TiDB 都是使用 LSM 树作为存储引擎,并且都是 KV 结构。如此选择的原理是什么呢?
我在介绍 LSM 的时候,提到其可以高性能地写入与读取,但是牺牲了空间。可能你就据此得出结论,NewSQL 数据库面对 OLTP 场景,希望得到吞吐量的提升,故选择 LSM 树存储引擎,而不选择 B 树类的存储引擎。但是,我也介绍过有很多方法可以改进 B 树的吞吐量。所以这一点并不是关键点。
我曾经也会困惑于这个问题,经过大量研究,并与项目组人员交流。从而得到了一个“结论”:开源的 NewSQL 选择的并不是 LSM 树,而是 RocksDB。选择 RocksDB 难道不是因为它是 LSM 结构的?答案是否定的。大部分以 RocksDB 为存储引擎的开源 NewSQL 数据库看中的是 RocksDB 的性能与功能。可以有一个合理的推论,如果有一款在性能和功能上碾压 RocksDB 的 B 树存储引擎,那么当代开源 NewSQL 数据库的存储引擎版图又会是另一番景象了。
你不用诧异,这种发展趋势其实代表了 IT 技术的一种实用特性。从 TCP/IP 协议的普及,到 Java 企业领域 Spring 替代 EJB,都体现了这种实用性。那就是真正胜利的技术是一定有实用价值的,这种实用价值要胜过任何完美的理论。这也启发我们在观察一个分布式数据库时,不要着急给它分类,因为今天我要介绍的评判 NewSQL 的标准,是基于现有数据库特性的总结,并不能代表未来的发展。我们要学会掌握每种数据库核心特性。
到这里,我还要提一个比较特别的数据库,那就是 OceanBase。OceanBase 的读写跟传统数据库有很大的一点不同就是:OceanBase 的写并不是直接在数据块上修改,而是新开辟一块增量内存用于存放数据的变化。同一笔记录多次变化后,增量块会以链表形式组织在一起,这些增量修改会一直在内存里不落盘。OceanBase 读则是要把最早读入内存的数据块加上后续相关的增量块内容合并读出。这种特点其实与 LSM 树的内存表和数据表有类似之处,只是 OceanBase 在更高维度上。
总结完架构上的创新,下面我将介绍 NewSQL 中关于分片的管理。
透明的 Sharding
我们上文介绍过数据库中间件是如何进行 Sharding 的,那就是使用逻辑的分片键来进行分片计算,将不同的行写入到不同的目标数据库。其中,需要用户深度地参与。比如,需要用户去指定哪个键为分片键,逻辑表与物理表的映射规则,必要的时候还需要进行 SQL 改造,等等。故中间件模式的 Sharding 我们一般称作显示 Sharding,与之相对的就是 NewSQL 数据库提供的透明 Sharding。
透明 Sharding 顾名思义,用户不需要去指定任何的规则,数据就能分散到整个集群中,并自动做了备份处理。那么 NewSQL 是怎么确定分片键的呢?我们以 TiDB 为例。
一个表中的数据是按照 Region 来进行 Sharding 的。每个 Region 有多个副本,从而保障了数据的高可用。不同的表将会有不同的 Region,而不是如传统分库那样每个库里的表都是相同的。 那么一个表下,每一行数据存储在哪个 Region 下是如何确定的呢?
首先要确定的是行是怎么映射到 KV 结构的: key 由 table_id 表 id+rowid 主键组成。如:
t[table_id]_r[row_id]
而 value 保存的就是一整行的数据。那么我们就使用这个 key 来计算这行数据应该落在哪个 Region 里面。
TiDB 是使用范围策略来划分数据。有索引情况下,负责索引的 Region 会根据索引字段范围来划分。基于 key 经过一个转换,将会得出一个数字,然后按范围划分多个区间,每个区间由一个 Region 管理。范围分片的好处我们之前介绍过,就是存储平衡和访问压力的平衡。其原因是,范围分片有机会做更好的动态调度,只有动态了,才能实时自动适应各种动态的场景。
虽然透明 Sharding 为用户带来了使用的便利。但聪明的你可以注意到了,这种隐式的分片方案相比上一讲介绍的方案,从功能上讲是存在缺失的。最明显的是它缺少跨分片 Join 的功能。可以想到,此种 NewSQL 与具有 ER 分片的数据库中间件在性能上是存在差异的。针对此种情况,TiDB 引入了 Placement Rules 来制定将相关联的数据表放在同一个 KV 存储中,从而达到 ER 分片的效果。
当然,随着 NewSQL 的逐步发展,哈希分片也逐步被引入 NewSQL 中。我们知道范围分片有热点问题,虽然可以通过动态拆分合并分片来缓解,但终究不是从根本上解决该问题。特别是对于具有强顺序的数据,比如时间序列,该问题就会变得很突出。而哈希分片就是应对该问题的有效手段。基于这个原因,Cockroach DB 引入哈希分片索引来实现针对序列化数据的扩展能力。
我们小结一下,透明的 Sharding 针对的往往是主键,一般会选择行 ID 作为主键。而如果要实现功能完善的 Sharding,一些用户参与的配置操作还是有必要的。
解决了 Sharding 问题,让我们看看 SQL 层面需要解决的问题吧。
分布式的 SQL
NewSQL 数据库相对于 NoSQL 最强大的优势还是对 SQL 的支持。我曾经在模块一中与你讨论过,SQL 是成功的分布式数据库一个必要的功能。SQL 的重要性我们已经讨论过了,但实现 SQL 一直是被认为很困难的,究其原因主要来源于以下两个方面。
SQL 的非标准性。虽然我们有 SQL99 这种事实标准,但是在工业界,没有一种流行的数据库完全使用标准去构建 SQL。每家都有自己的方言、自己独有的特性,故我们看到的 NewSQL 数据库大部分都会按照已经存在的数据库方言去实现 SQL 语义,比如 TiDB 实现了 MySQL 的语法,而 CockroachDB 实现了 PostgreSQL。
声明式语言。SQL 语言是一种更高级的语言,比我们熟悉的 Java、Go 等都要高级。主要体现为它表述了希望得到什么结果,而没有指示数据库怎么做。这就引出了所谓的执行计划优化等概念,为实现高效的查询引擎带来了挑战。
以上是传统数据库实现 SQL 的挑战,而对于分布式数据库来说还需要将数据分散带来的问题考虑进去,同时在查询优化方面要将网络延迟作为一个重要因素来考量。
对于 NewSQL 而言,如果使用了上面所描述的创新架构,特别是底层使用 KV 存储,那么就需要考虑数据与索引如何映射到底层 KV 上。我在前面已经说明了数据是如何映射到 KV 上的,那就是 key 由 table_id 表 id+rowid 主键组成,value 存放行数据:
t[table_id]_r[row_id] => row_data
而对于索引,我们就要区分唯一索引和非唯一索引。
对于唯一索引,我们将 table_id、index_id 和 index_value 组成 key,value 为上面的 row_id。
t[table_id]_i[index_id][index_value] => row_id
对于非唯一索引,就需要将 row_id 放到 key 中,而 value 是空的。
t[table_id]_i[index_id][index_value]_r[row_id] => null
底层映射问题解决后,就需要进入执行层面了。这里面牵扯大量的技术细节,我不会深入其中,而是为你展示一些 NewSQL 数据库会面临的挑战。
首先是正确性问题。是的,要实现正确的 SQL 语法本身就是挑战。因为 SQL 可以接受用户自定义表和索引,查询使用名字,而执行使用的是 ID,这之间的映射关系会给正确性带来挑战。而其中最不好处理的就是 Null,不仅仅是 NewSQL,传统数据库在处理 Null 的时候也经过了长时间的“折磨”。这也是为什么一个 SQL 类数据库需要经过长时间的迭代才能达到稳定状态的原因。
然后就是性能了。性能问题不仅仅是数据库开发人员,DBA 和最终用户也对它非常关注。如果你经常与数据库打交道,一定对 SQL 优化有一定了解。这背后的原因其实就是 SQL 声明式语言导致的。
大部分 NewSQL 数据库都需要实现传统数据库的优化手段,这一般分为两类:基于规则和基于代价。前者是根据 SQL 语义与数据库特点进行的静态分析,也称为逻辑优化,常见有列裁剪、子查询优化为连接、谓词下推、TopN 下推,等等;而基于代价的优化,需要数据库实时产生统计信息,根据这些信息来决定 SQL 是否查询索引、执行的先后顺序,等等。
而具有分布式数据库特色的优化包括并行执行、流式聚合,基于代价的优化需要考虑网络因素等。故实现分布式数据库的 SQL 优化要更为复杂。
从上文可以看到,NewSQL 的数据库实现 SQL 层所面临的挑战要远远大于传统数据库。但由于 SQL 执行与优化技术经过多年的积累,现在已经形成了完整的体系。故新一代 NewSQL 数据库可以在此基础上去构建,它们站在巨人的肩膀上,实现完整的 SQL 功能将会事半功倍。
介绍完了 NewSQL 数据库在 SQL 领域的探索,最后我们来介绍其高性能事务的特点。
高性能事务
NewSQL 的事务是其能够得到广泛应用的关键。在上一个模块中我们讨论的 Spanner 与 Calvin,就是典型的创新事务之争。这一讲我将总结几种 NewSQL 数据库处理事务的常见模式,并结合一定的案例来为你说明。
首先的一种分类方式就是集中化事务管理与去中心化事务管理。前者的优势是很容易实现事务的隔离,特别是实现序列化隔离,代价就是其吞吐量往往偏低;而后者适合构建高并发事务,但是需要逻辑时钟来进行授时服务,并保证操作竞争资源的正确性。
以上是比较常规的认识,但是我们介绍过 Calvin 事务模型。它其实是一种集中化的事务处理模式,但却在高竞争环境下具有非常明显的吞吐量的优势。其关键就是通过重新调度事务的执行,消除了竞争,从而提高了吞吐量。采用该模式的除了 Calvin 外,还有 VoltDB。其原理和 Calvin 类似,感兴趣的话你可以自行学习。
而采用去中心化事务的方案一般需要结合:MVCC、2PC 和 PaxosGroup。将它们结合,可以实现序列化的快照隔离,并保证执行过程中各个组件的高可用。采用 PaxosGroup 除了提供高可用性外,一个重要的功能就是将数据进行分区,从而降低获取锁的竞争,达到提高并发事务效率的目的。这种模式首先被 Spanner 所引入,故我们一般称其为 Spanner 类事务模型。
而上一讲我们介绍了京东为 ShardingShpere 打造的 JDTX 又是另一番景象,数据库中间件由于无法操作数据库底层,所以事务方案就被锁死。而 JDTX 采用类似 OceanBase 的模式,首先在数据库节点之外构建了一个独立的 MVCC 引擎,查询最新的数据需要结合数据库节点与 MVCC 引擎中修改的记录,从而获得最新数据。而 MVCC 中的数据会异步落盘,从而保证数据被释放。JDTX 的模式打破了中间件无法实现高性能事务模型的诅咒,为我们打开了思路。
可以看到,目前 NewSQL 的并发事务处理技术往往使用多种经过广泛验证的方案。可以将它比喻为当代的航空母舰,虽然每个部件都没有创新点,但是将它们结合起来却实现了前人无法企及的成就。
总结
这一讲,我介绍了 NewSQL 数据库的定义,并为你详细分析了一个 NewSQL 数据库的关键点,即以下四个。
创新的架构:分布式系统与存储引擎都需要创新。
透明的 Sharding:自动的控制,解放用户,贴合云原生。
分布式 SQL:打造商业可用分布式数据库的关键。
高性能事务:NewSQL 创新基地,是区别不同种类 NewSQL 的关键。
至此,我们课程的主要内容就已经全部介绍完了。
NewSQL 和具有全球部署能力的 DistributedSQL 是当代分布式数据库的发展方向,可以说我们介绍过的所有知识都是围绕在 NewSQL 体系内的。接下来在加餐环节,我会为你介绍其他种类的分布式数据库,以帮助你拓展思路。
感谢学习,希望我的分享会对你带来帮助。
加餐1 概念解析:云原生、HTAP、图与内存数据库
我们课程的主要内容已经介绍完了,经过 24 讲的学习,相信你已经掌握了现代分布式数据库的核心内容。前面我所说的分布式数据库主要针对的是 NewSQL 数据库。而这一篇加餐,我将向你介绍一些与分布式数据库相关的名词和其背后的含义。学习完本讲后,当你再看见一款数据库时,就能知道其背后的所代表的意义了。
我首先介绍与 NewSQL 数据库直接相关的云原生数据库;其次会介绍目前非常火热的 HTAP 融合数据库概念;数据库的模式除了关系型之外,还有多种其他类型,我将以图数据库为例,带你领略非关系型数据库面对典型问题所具备的优势;最后为你介绍内存型数据库。
云原生数据库
云原生数据库从名字看是从云原生概念发展而来的。而云原生一般包含两个概念:一个是应用以服务化或云化的方式提供给用户;另一个就是应用可以依托云原生架构在本地部署与 Cloud 之间自由切换。
第一种概念是目前广泛介绍的。此类云原生数据库是在云基础架构之上进行构建的,数据库组件在云基础设施之上构建、部署和分发。这种云原生属性是它相比于其他类型数据库最大的特点。作为一种云平台,云原生数据库以 PaaS(平台即服务,Platform-as-a-Service)的形式进行分发,也经常被称作 DBaaS(数据库即服务,DataBase-as-a-Service)。用户可以将该平台用于多种目的,例如存储、管理和提取数据。
使用此类云原生数据库一般会获得这样几个好处。
快速恢复
也就是数据库在无须事先通知的情况下,即时处理崩溃或启动进程的能力。尽管现在有先进的技术,但是像磁盘故障、网络隔离故障,以及虚拟机异常等,仍然不可避免。对于传统数据库,这些故障非常棘手。因为用单个机器运行整个数据库,即便一个很小的问题都可能影响所有功能。
而云原生数据库的设计具有显著的快速恢复能力,也就是说可以立即重启或重新调度数据库工作负载。实际上,易处置性已从单个虚拟机扩展到了整个数据中心。随着我们的环境持续朝着更加稳定的方向发展,云原生数据库将发展到对此类故障无感知的状态。
安全性
DBaaS 运行在高度监控和安全的环境里,受到反恶意软件、反病毒软件和防火墙的保护。除了全天候监控和定期的软件升级以外,云环境还提供了额外的安全性。相反,传统数据库容易遭受数据丢失和被不受限制的访问。基于服务提供商通过即时快照副本提供的数据能力,用户可以达成很小的 RPO 和 RTO。
弹性扩展性
能够在运行时进行按需扩展的能力是任何企业成长的先决条件。因为这种能力让企业可以专注于追求商业目标,而不用担心存储空间大小的限制。传统数据库将所有文件和资源都存储在同一主机中,而云原生数据库则不同,它不仅允许你以不同的方式存储,而且不受各种存储故障的影响。
节省成本
建立一个数据中心是一项独立而完备的工程,需要大量的硬件投资,还需要能可靠管理和维护数据中心的训练有素的运维人员。此外,持续地运维会给你的财务带来相当大的压力。而使用云原生的 DBaaS 平台,你可以用较低的前期成本,获得一个可扩展的数据库,这可以让你腾出双手,实现更优化的资源分配。
以上描述的云原生数据库一般都是采用全新架构的 NewSQL 数据库。最典型的代表就是亚马逊的 Aurora。它使用了日志存储实现了 InnoDB 的功能,从而实现了分布式条件下的 MySQL。目前各个主要云厂商的 RDS 数据库都有这方面的优势,如阿里云 PolarX,等等。
而第二种云原生数据库理论上可以部署在企业内部(私有云)和云服务商(公有云),而许多企业尝试使用混合模式来进行部署。面向这种场景的云原生数据库并不会自己维护基础设施,而是使自己的产品能运行在多种云平台上,ClearDB 就是这类数据库典型代表。这种跨云部署提高了数据库整体的稳定性,并可以改善服务全球应用的数据响应能力。
当然,云原生数据库并不仅限于关系型,目前我们发现 Redis、MongoDB 和 Elasticsearch 等数据库都在各个主要云厂商提供的服务中占有重要的地位。可以说广义上的云原生数据库含义是非常宽泛的。
以上带你了解了云原生数据库在交付侧带来的创新,下面我来介绍 HTAP 融合数据库在数据模型上有哪些新意。
HTAP
介绍 HTAP 之前,让我们回顾一下 OLTP 和 OLAP 的概念。我之前已经介绍过,OLTP 是面向交易的处理过程,单笔交易的数据量很小,但是要在很短的时间内给出结果;而 OLAP 场景通常是基于大数据集的运算。它们两个在大数据时代就已经分裂为两条发展路线了。
但是 OLAP 的数据往往来自 OLTP 系统,两者一般通过 ETL 进行衔接。为了提升 OLAP 的性能,我们需要在 ETL 过程中进行大量的预计算,包括数据结构的调整和业务逻辑处理。这样的好处是可以控制 OLAP 的访问延迟,提升用户体验。但是,因为要避免抽取数据对 OLTP 系统造成影响,所以必须在系统访问的低峰期才能启动 ETL 过程,例如对于电商系统,一般都是午夜进行。
这样一来, OLAP 与 OLTP 的数据延迟通常就在一天左右,大家习惯把这种时效性表述为 N+1。其中,N 就是指 OLTP 系统产生数据的日期,N+1 是 OLAP 中数据可用的日期,两者间隔为 1 天。你可能已经发现了,这个体系的主要问题就是 OLAP 系统的数据时效性,24 个小时的延迟太长了。是的,进入大数据时代后,商业决策更加注重数据的支撑,而且数据分析也不断向一线操作渗透,这都要求 OLAP 系统更快速地反映业务的变化。
此时就出现了将两种融合的 HTAP。HTAP(Hybrid Transaction/Analytical Processing)就是混合事务分析处理,它最早出现在 2014 年 Gartner 的一份报告中。Gartner 用 HTAP 来描述一种新型数据库,它打破了 OLTP 和 OLAP 之间的隔阂,在一个数据库系统中同时支持事务型数据库场景和分析型数据库场景。这个构想非常美妙,HTAP 可以省去烦琐的 ETL 操作,避免批量处理造成的滞后,更快地对最新数据进行分析。
由于数据产生的源头在 OLTP 系统,所以 HTAP 概念很快成为 OLTP 数据库,尤其是 NewSQL 风格的分布式数据库和云原生数据库。通过实现 HTAP,它们试图向 OLAP 领域进军。这里面比较典型代表是 TiDB,TiDB 4.0 加上 TiFlash 这个架构能够符合 HTAP 的架构模式。
TiDB 是计算和存储分离的架构,底层的存储是多副本机制,可以把其中一些副本转换成列式存储的副本。OLAP 的请求可以直接打到列式的副本上,也就是 TiFlash 的副本来提供高性能列式的分析服务,做到了同一份数据既可以做实时的交易又做实时的分析,这是 TiDB 在架构层面的巨大创新和突破。
以上就是 HTAP 数据库的演化逻辑和典型代表。下面我们继续拓展知识的边界,看看多种模式的分布式数据库。
内存数据库
传统的数据库通常是采用基于磁盘的设计,原因在于早期数据库管理系统设计时受到了硬件资源如单 CPU、单核、可用内存小等条件的限制,把整个数据库放到内存里是不现实的,只能放在磁盘上。可以说内存数据库是在存储引擎层面上进行全新架构的 NewSQL 数据库。
伴随着技术的发展,内存已经越来越便宜,容量也越来越大。单台计算机的内存可以配置到几百 GB 甚至 TB 级别。对于一个数据库应用来说,这样的内存配置已经足够将所有的业务数据加载到内存中进行使用。通常来讲,结构化数据的规模并不会特别大,例如一个银行 10 年到 20 年的交易数据加在一起可能只有几十 TB。这样规模的结构化数据如果放在基于磁盘的 DBMS 中,在面对大规模 SQL 查询和交易处理时,受限于磁盘的 I/O 性能,很多时候数据库系统会成为整个应用系统的性能瓶颈。
如果我们为数据库服务器配置足够大的内存,是否仍然可以采用原来的架构,通过把所有的结构化数据加载到内存缓冲区中,就可以解决数据库系统的性能问题呢?这种方式虽然能够在一定程度上提高数据库系统的性能,但在日志机制和更新数据落盘等方面仍然受限于磁盘的读写速度,远没有发挥出大内存系统的优势。内存数据库管理系统和传统基于磁盘的数据库管理系统在架构设计和内存使用方式上还是有着明显的区别。
一个典型的内存数据库需要从下面几个方面进行优化。
去掉写缓冲:传统的缓冲区机制在内存数据库中并不适用,锁和数据不需要再分两个地方存储,但仍然需要并发控制,需要采用与传统基于锁的悲观并发控制不同的并发控制策略。
尽量减少运行时的开销:磁盘 I/O 不再是瓶颈,新的瓶颈在于计算性能和功能调用等方面,需要提高运行时性能。
可扩展的高性能索引构建:虽然内存数据库不从磁盘读数据,但日志依然要写进磁盘,需要考虑日志写速度跟不上的问题。可以减少写日志的内容,例如把 undo 信息去掉,只写 redo 信息;只写数据但不写索引更新。如果数据库系统崩溃,从磁盘上加载数据后,可以采用并发的方式重新建立索引。只要基础表在,索引就可以重建,在内存中重建索引的速度也比较快。
综上可以看到,构建内存数据库并不是简单地将磁盘去掉,而是需要从多个方面去优化,才能发挥出内存数据库的优势。而图数据库则是通过修改数据模型来实现高性能的,下面让我们看看其具体的功能。
图数据库
图数据库(graph database)是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。该系统的关键概念是图,它直接将存储中的数据项,与数据节点和节点间表示关系的边的集合相关联。这些关系允许直接将存储区中的数据连接在一起,并且在许多情况下,可以通过一个操作进行检索。图数据库将数据之间的关系作为优先级。查询图数据库中的关系很快,因为它们永久存储在数据库本身中。可以使用图数据库直观地显示关系,使其对于高度互联的数据非常有用。
如果内存数据库是在底层存储上进行的创新,那么图数据库就是在数据模型上进行了改造。构造图数据库时,底层存储既可以使用 LSM 树等 KV 存储,也可以使用上一讲介绍的内存存储,当然一些图数据库也可以使用自创的存储结构。
由于图数据所依赖的算法本质上没有考虑分布式场景,故在分布式系统处理层面形成了两个流派。
以节点为中心
这是传统分布式理论作用在图数据库中的一种形式。此类数据库以节点为中心,使相邻的节点就近交换数据。图算法采用了比较直接的模式,其好处是并发程度较好,但是效率很低。适合于批量并行执行简单的图计算。典型代表是就是 Apache Spark。故此种数据库又被称为图计算引擎。
以算法为中心
这是针对图计算算法特别设计的数据库。其底层数据格式满足了算法的特性,从而可以使用较低的资源处理较多的图数据。但是此类数据库是很难进行大范围扩展的。其典型代表有 Neo4j。
当然我们一般可以同时使用上面两种处理模式。使用第一种来进行大规模数据的预处理和数据集成工作;使用第二种模式来进行图算法实现和与图应用的对接工作。
总之,图数据库领域目前方兴未艾,其在社交网络、反欺诈和人工智能等领域都有非常大的潜力。特别是针对最近的新冠疫情,有很多团队利用图数据库分析流行病学,从而使人们看到了该领域数据库的优势。
图数据库与文档型数据库、时间序列数据库等都是面向特殊数据模型的数据库。此类数据库之所以能越来越火热,除了它们所在领域被重视以外,最重要的底层原因还是存储引擎和分布式系统理论、工具的日趋成熟。可以预见,今后一些热门领域会相继产出具有领域特色的数据库。
总结
本讲作为加餐的知识补充,为你介绍了多种分布式数据库。其中云原生与 HTAP 都是 NewSQL 数据库的发展分支。云原生是从交付领域入手,提供给用户一个开箱即用的数据库。而 HTAP 拓展了 NewSQL 的边界,引入了 OLAP,从而抢占了部分传统大数据和数据分析领域的市场。
而内存数据库是针对数据库底层的创新,除了内存数据库外,2021 年随着 S3 存储带宽的增加和其单位存储价格持续走低,越来越多的数据库开始支持对象存储。今后,随着越来越多的创新硬件的加入,我们还可能看到更多软硬结合方案数据库的涌现。
最后我介绍了图数据库,它作为特殊领域数据库在领域内取得成就,是通用关系型数据无法企及的。而随着存储引擎和分布式理论的发展,此类数据库将会越来越多。
如此多的分布式数据库真是让人眼花缭乱,那么我们该如何去选择呢?下一节加餐我会结合几个典型领域,来给你一些指引。
我们不见不散。
加餐2 数据库选型:我们该用什么分布式数据库?
经过 24 讲的基础知识学习以及上一讲加餐,我已经向你介绍了分布式数据库方方面面的知识。这些知识,我觉得大概会在三个方面帮到你,分别是数据库研发、架构思维提升和产品选型。特别是 NewSQL 类数据库相关的知识,对于你认识面向交易的场景很有帮助。
我先后在电信与电商行业有十几年的积累,我想,你也非常希望知道在这些主流场景中分布式数据库目前的应用状况。这一讲我就要为你介绍银行、电信和电商领域内分布式数据库的使用状况。
首先我要从我的老本行电商行业开始。
电商:从中间件到 NewSQL
分布式数据库,特别是分布式中间这一概念就是从电商,尤其是阿里巴巴集团催生出来的。阿里集团也是最早涉及该领域的企业。这里我们以其 B2B 平台部产生的 Cobar 为例介绍。
2008 年,阿里巴巴 B2B 成立了平台技术部,为各个业务部门的产品提供底层的基础平台。这些平台涵盖 Web 框架、消息通信、分布式服务、数据库中间件等多个领域的产品。它们有的源于各个产品线在长期开发过程中沉淀出来的公共框架和系统,有的源于对现有产品和运维过程中新需求的发现。
数据库相关的平台就是其中之一,主要解决以下三方面的问题:
为海量前台数据提供高性能、大容量、高可用性的访问;
为数据变更的消费提供准实时的保障;
高效的异地数据同步。
如下面的架构图所示,应用层通过 Cobar 访问数据库。
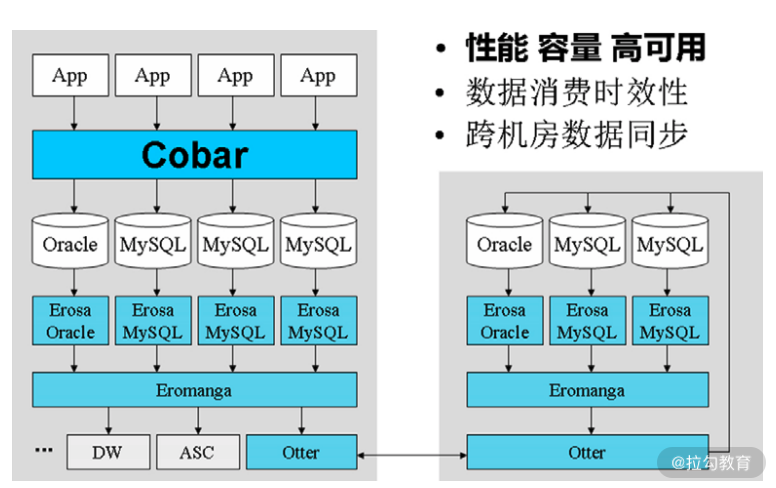
其对数据库的访问分为读操作(select)和写操作(update、insert和delete)。写操作会在数据库上产生变更记录,MySQL 的变更记录叫 binlog,Oracle 的变更记录叫 redolog。Erosa 产品解析这些变更记录,并以统一的格式缓存至 Eromanga 中,后者负责管理变更数据的生产者、Erosa 和消费者之间的关系,负责跨机房数据库同步的 Otter 是这些变更数据的消费者之一。
Cobar 可谓 OLTP 分布式数据库解决方案的先驱,至今其中的思想还可以从现在的中间件,甚至 NewSQL 数据库中看到。但在阿里集团服役三年后,由于人员变动而逐步停止维护。这个时候 MyCAT 开源社区接过了该项目的衣钵,在其上增加了诸多功能并进行 bug 修改,最终使其在多个行业中占用自己的位置。
但是就像我曾经介绍的那样,中间件产品并不是真正的分布式数据库,它有自己的局限。比如 SQL 支持、查询性能、分布式事务、运维能力,等等,都有不可逾越的天花板。而有一些中间件产品幸运地得以继续进阶,最终演化为 NewSQL,甚至是云原生产品。阿里云的 PolarDB 就是这种类型的代表,它的前身是阿里云的分库分表中间件产品 DRDS,而 DRDS 来源于淘宝系的 TDDL 中间件。
PolarDB 相比于传统的中间件差别是采用了共享存储架构。率先采用这种架构的恰好也是一家电商到云计算的巨头:亚马逊。而这个数据库产品就是 Aurora。
Aurora 采用了这样一种架构。它将分片的分界线下移到事务及索引系统的下层。这个时候由于存储引擎保留了完整的事务系统,已经不是无状态的,通常会保留单独的节点来处理服务。这样存储引擎主要保留了计算相关逻辑,而底层存储负责了存储相关的像 redo、刷脏以及故障恢复。因此这种结构也就是我们常说的计算存储分离架构,也被称为共享盘架构。
PolarDB 在 Aurora 的基础上采用了另外一条路径。RDMA 的出现和普及,大大加快了网络间的网络传输速率,PolarDB 认为未来网络的速度会接近总线速度,也就是瓶颈不再是网络,而是软件栈。因此 PolarDB 采用新硬件结合 Bypass Kernel 的方式来实现高效的共享盘实现,进而支撑高效的数据库服务。由于 PolarDB 的分片层次更低,从而做到更好的生态兼容,这也就是为什么 PolarDB 能够很快做到社区版本的全覆盖。副本件 PoalrDB 采用了 ParalleRaft 来允许一定范围内的乱序确认、乱序 Commit 以及乱序 Apply。但是 PolarDB 由于修改了 MySQL 的源码和数据格式,故不能与 MySQL 混合部署,它更适合作为云原生被部署在云端提供 DBaaS 服务。
以 Spanner 为代表的“无共享”类型的 NewSQL 由于有较高的分片层次,可以获得接近传统分库分表的扩展性,因此容易在 TPCC 这样的场景下取得好成绩,但其需要做业务改造也是一个大的限制。以 Aurora 及 PolarDB 为代表的“共享存储”的 NewSQL 则更倾向于良好的生态兼容,几乎为零的业务改造,来交换了一定程度的可扩展性。
可以说从 Cobar 到现在的 PolarDB,我们看到了分布式数据库在电商与云计算领域的成长。其他典型代表如京东数科的 ShardingShpere 也有类似的发展脉络。可以说电商领域,乃至互联网行业,都进入了以自主知识产权研发的模式,对技术的掌控力较高,从而打造了良好的生态环境。
以上介绍完了电商这个比较技术激进的行业,下面再来看一些传统行业的表现。
电信:去 IOE
电信作为重要的 IT 应用行业,过去 20 年一直引领着技术发展的潮流。但电信却又是关系到国计民生的重要行业,故技术路线相比于电商、互联网来说更为保守。其中 Oracle 数据库常年“霸占”着该领域,而分布式计算场景被众多子系统所承担着。以中国联通为例,在 2010 年前后,联通集团的各个省系统就有数百个之多,它们之间的数据是通过 ETL 工具进行同步,也就是从应用层保证了数据一致性。故从当时的情况看,其并没有对分布式数据库有很强的需求。
但在 2012 年前后,也就是距今大概 10 年前。中国联通开始尝试引入阿里集团的技术,其中上文提到的 Cobar 就在其中。为什么三大运营商中联通首先发力呢?原因是联通当年刚完成对老网通的合并,急需将移动网业务与固网业务进行整合。其次是联通集团总部倾向于打造全国集中系统,而这就需要阿里集团提供帮助。
根据当年参与该项目的人回忆,现场近千人一起参与,众多厂商系统工作,最终在距离承诺上线日期没几天的时候才完成了主要功能的验证。按现在的技术评估标准,当年这个项目并不是十分成功。但是这个项目把阿里的“去 IOE”理念深深地写入了电信领域内所有参与者的基因里面,从运营商到供应商,所有人都觉得分布式数据库的解决方案是未来的趋势。
而后 Cobar 衍生的 MyCAT 在联通与电信多个产品线开始落地,而各个供应商也开始模仿 Cobar 制作了自己的中间件产品。可以说,正是上面描述的背景,使数据库中间件模式逐步在电信领域内被广泛接受,其底色就是去“IOE”。
2016 年之后,电信行业没有放弃演化的步伐,各个主要供应商开始尝试去构建 NewSQL 数据库,其中特别是以 PGXC 架构为核心的 NewSQL 数据库引人瞩目。PGXC(PostgreSQL-XC)的本意是指一种以 PostgreSQL 为内核的开源分布式数据库。因为 PostgreSQL 的影响力和开放的软件版权协议(类似 BSD),很多厂商在 PGXC 上二次开发,推出自己的产品。不过,这些改动都没有变更主体架构风格,所以我把这类产品统称为 PGXC 风格,如亚信的 AntDB、人大金仓的 KingbaseDB 都是这类数据库的典型代表。此类数据库开始在行业内部快速落地。
近些年,电信行业内部也逐步接触了最具创新性的 NewSQL,但是此类数据库选择范围很小。电信运营商更倾向于与国内厂商合作,如 TiDB 和 OceanBase 已经有在三大运营商和铁搭公司上线的案例。不过,我们可以发现,目前新一代 NewSQL 接管的系统不是属于创新领域,就是属于边缘业务,还未触及核心系统。但是我们可以认为,未来将会有更多的场景使用到创新性的 NewSQL 数据库。
最后再来说说银行系统。
银行:稳中前进
银行与电信是非常类似的行业,但是银行的策略会更保守。银行并没有在内部推动轰轰烈烈的去“IOE”运动,故其在 OLTP 领域一直使用传统数据库,如 Oracle 和 DB2。
一直到近 5 年开始,银行的 IT 架构才发生重大调整。比如行业标杆的工商银行的架构改造在 2018 年大规模落地,而调研和试点工作则在更早的 2016~2017 年。这个时点上,商用 NewSQL 数据库刚刚推出不久,而金融场景的种种严苛要求,注定了银行不会做第一个吃螃蟹的人,那么这种可能性就被排除了。同样,另一种 PGXC 风格的分布式数据库也正待破茧而出,反而是它的前身,“分布式中间件 + 开源单体数据库”的组合更加普及。
后来的结果是工行选择了爱可生开源的 DBLE + MySQL 的组合,选择 MySQL 是因为它的普及程度足够高;而选择 DBLE 则因为它是在 MyCat 的基础上研发,号称“增强版 MyCat”,由于 MyCat 已经有较多的应用案例,所以这一点给 DBLE 带来不少加分。这一模式在工行内部推行得很好,最终使 MySQL 集群规模达到上千节点。虽然表面看起来还是非常保守,因为同期的电信行业已经开始推进 PGXC 架构落地了。但是工行,乃至真个银行行业,也走上了“去 IOE”的道路,可以想到,整个行业也是朝着 NewSQL 数据库的方向前进的。而且目前工商银行已经宣布与 OceanBase 进行合作,这预示着行业中 NewSQL 化的浪潮即将来临。
相对于 OLTP 技术应用上的平淡,工行在 OLAP 方面的技术创新则令人瞩目。基本是在同期,工行联合华为成功研发了 GaussDB 200,并在生产环境中投入使用。这款数据库对标了 Teradata 和 Greenplum 等国外 OLAP 数据库。在工行案例的加持下,目前不少银行计划或者正在使用这款产品替换 Teradata 数据库。
总结
这篇加餐我为你总结了几个重点行业使用分布式数据库,特别是 OLTP 类数据库的情况。我们可以从中看到一些共同点:
发展脉络都是单机数据库、中间件到 NewSQL,甚至电商领域开始做云计算;
各个行业依据自己的特点进行发展,虽然基本都经过了这些阶段,但是它们之间是有技术滞后性的;
先发展的行业带动了其他行业,特别是电商领域的技术被其他行业引用,达到了协同发展的效果;
国产数据库崛起,近年采购的全新架构的 NewSQL 数据库,我们都可以看到国产厂家的身影,一方面得力于国有电信、银行等企业的政策支持,另一方面国产数据库的进步也是大家有目共睹的。
这三个具有典型性的行业,为我们勾画来整个分布式数据库在中国的发展。希望你能从它们的发展轨迹中汲取养分,从而能使用分布式数据库为自己的工作、学习助力。
以上就是最后一节加餐的内容了,希望可以帮助到你,再见。
结束语 分布式数据库,未来可期
你好,我是高洪涛。课程到这里就要和你说再见了。
不知不觉三个月转瞬即逝,感谢你一直以来的陪伴。人总说“相识是缘分,相守是情投”,能坚持学完全部 24 讲内容和两节加餐,证明我们彼此之间情谊是相合的,而情谊的纽带我想就是对分布式数据库技术的欣赏与热爱吧。
我大概在 2015 年开始接触分布式数据库这个领域,刚开始就见识了数据库中间件技术的大繁荣,并有幸成为国内最早制作分布式中间件的专业人员。而后经过几年的积累,我目前正在设计和实现一款专业领域的 NoSQL 数据库。这一路走来,我愈发觉得当下热爱技术的同学对基础软件的认知水平远远不够,所以当拉勾教育找到我并希望开设这门课时,我是非常开心的,因为能有一次机会与你分享我对分布式数据库的理解。
最初设计课程的时候,我非常担心这类核心系统听众不多。因为中国虽然是目前世界上 IT 用户最多的国家,中文也是 IT 最大的受众群体。但我们的开发者中,绝大多数都是面向应用开发的,如果单纯从实用主义的角度看,核心系统,特别是数据库相关主题能否得到广大读者的接受,这一点我内心其实没有底。但是,课程上线以来,不论是订阅量还是你们的反馈,都让我越来有动力把专栏好好写下去。
这门专栏是关于分布式数据库底层逻辑的,关注这个领域的专业人员逐步增多,这使我对国产数据库,乃至国产核心系统的发展抱有了极大的憧憬。事实也正逐步验证我的这种看法,特别是 TiDB 与 Oceanbase 开始在电信、银行等国家重点行业中商用,这预示着国产数据库,特别是 NewSQL 类国产数据库将承担越来越重要的任务。
虽然,NewSQL 数据库目前应用的案例还很有限,但它未来的想象空间是巨大的。而最关键的因素是,越来越多的组织和企业开始参与其中。我相信,只要人类社会持续将资源放置在一个领域内,最终该领域都会取得重大突破。从移动互联网到电动汽车,这些案例都侧面证明了这个说法。那么,现在都有哪些 NewSQL 数据库值得我们关注呢?
首先是具有创新架构的 NewSQL 类数据库。
这里以 Spanner 和 F1 为主,其中 F1 主要作为 SQL 引擎,而事务一致性、复制机制、可扩展存储等特性都是由 Spanner 完成的,所以我们有时会忽略 F1,而更多地提到 Spanner。
Spanner 和 F1 在 2017 年已经发生了新的变化,Spanner 的论文是“Spanner:Becoming a SQL System”。就像论文名字所说的,Spanner 完善了 SQL 功能,这样就算不借助 F1,它也能成为一个完整的数据库。这篇论文用大量篇幅介绍了 SQL 处理机制,同时在系统定位上相比 2012 版有一个大的变化,强调了兼容 OLTP 和 OLAP,也就是 HTAP。
对应的,Spanner 在存储层的设计也从 2012 版中的 CFS 切换到了 Ressi。Ressi 是类似 PAX 的行列混合数据布局(Data Layout)。F1 的新论文是“F1 Query:Declarative Querying at Scale”。这一版论文中 F1 不再强调和 Spanner 的绑定关系,而是支持更多的底层存储。非常有意思的是,F1 也声称自己可以兼顾 OLTP 和 OLAP。
由于 Spanner 的名声在外,一众借鉴 Spanner 概念的数据库需要被大家所了解。如 TiDB、YugabyteDB 等。但是每家数据库都是有自己的特色,它们在时钟、分片和事务上都各不相同。
其次,除了 Spanner,OceanBase 目前在行业内部也得到了越来越多的认可,它具有优异的性能、完善的功能;同时最重要的是它由支付宝这个重量级的商业案例背书,所以得到了金融、银行客户的青睐。
此外,以 AWS 的 Aurora 和阿里云的 PolarDB 为代表的云原生分布式数据库采用了另一种策略。它采用了共享存储模式,放弃了一定的扩展能力,但是却换来了对传统式数据库优良的支撑能力。但是这种策略目前看仅仅能在云厂商落地,因为其技术方案比较特别,很难在一般的 IDC 中进行复制。
除了创新架构的 NewSQL 外,另一类分布式数据库可能你在之后的学习和工作中更容易接触到。那就是从数据库中间件发展而来的 NewSQL 数据库,如以 MySQL 为基础的 Vitess。但是对于咱们国内用户而言,更常见的 PGXC 类型的数据库,比如 TDSQL、GoldenDB,等等。它们由于具有传统数据库的用户接口,目前越来越多的组织开始将它们落地。至于数据库中间件,目前单纯的中间件都已经到了发展的瓶颈,并逐步被淘汰,如果不引入更多偏向于 NewSQL 的架构,这些中间件终将消失在历史之中。
好了,我们回顾了整个分布式数据库目前的状态,那么未来在哪里?其实眼下我们就站在了历史的路口之上。
首先,分布式数据库的产品进入了高速发展时期,越来越多的组织正在或计划采用新一代架构的分布式数据库。特别是在 2021 年的 4 月份,Oracle 在 DB-Engine 的排名大幅下滑,而相对的 Postgre 和一种云原生数据库排名快速上升,这也预示着曾经不可撼动的商业帝国正在逐步褪色,新的时代在向我们招手。
其次,在中美竞争加剧的背景下,国产基础核心系统软件和国产数据库将会得到更多的机会,人们将会在电信、银行、能源等众多领域逐步完成国产替代。而新一代的国产数据库无非是分布式数据库。未来,从业者们也将有越来越多的机会直接使用它们。除了使用,国内的开发者也会有更多的机会参与数据库的研发过程,从而完成我们整个技术人才层次的升级。
基于对现状的认知和对未来的寄望,我把这门专栏定位成你在历史的十字路口中的向导,希望可以为你指明方向。
感谢你的支持和陪伴,山高路远,我们后会有期!
Hello 小伙伴,课程已经全部结束了,不知道这 24 讲和 2 节加餐对你的帮助如何?小编真诚邀请你根据自己的实际情况填写这份调查问卷,你的反馈就是我们进步的方向。同时也希望你在未来能够乘风破浪、披荆斩棘,成为更好的自己!
分布式数据库实战第七节 分布式数据库的现状与未来相关推荐
- 分布式场景实战第七节 微服务场景实战
18 如何处理好微服务之间千丝万缕的关系? 17 讲讲解了服务间数据依赖的场景,除了这种场景之外,其实我们还会碰到服务间依赖太杂乱的场景,这一讲我们将围绕这个场景进行讨论,还是先把整个场景描述一下. ...
- 分布式数据库实战第六节 数据库中间件的研究
21 知识串讲:如何取得性能和可扩展性的平衡? 这一讲我们来总结一下模块三.经过这个模块的学习,相信你已经对分布式数据库中分布式系统部分常见的技术有了深刻的理解.这是一节知识串讲的课,目的是帮助你将所 ...
- 分布式场景实战第六节 微服务数据治理方案
16 数据一致性:下游服务失败上游服务如何独善其身? 前面三讲我们聊了微服务的 9 个痛点,有些痛点没有好的解决方案,而有些痛点刚好有一些对策,后面的课程我们就来讲解某些痛点对应的解决方案. 这一讲我 ...
- mysql数据库实战_主题:MySQL数据库操作实战
昨天项目发布,要做数据移行,要实现的功能很变态,时间很紧迫,基本上是使出了全身解数,才能有快又准地完成工作,期间发现很多小技巧串联起来使用,效果的确非常好. 武器: 1 mysqldump+mysql ...
- 分布式数据库实战第五节 保证分布式系统中的数据库可靠
16 再谈一致性:除了 CAP 之外的一致性模型还有哪些? 在"05 | 一致性与 CAP 模型:为什么需要分布式一致性"中,我们讨论了分布式数据库重要的概念--一致性模型.由于篇 ...
- (数据库系统概论|王珊)第十章数据库恢复技术-第四、五、六、七节:数据库恢复技术和数据库镜像
文章目录 一:数据库恢复的实现技术 (1)数据转储(备份) A:转储的分类 ①:按照系统是否运行事物时分类 ②:按转储的范围分类 (2)登记日志文件 A:日志文件的内容 B:日志文件的作用 C:登记日 ...
- Redisson分布式锁实战-1:构建分布式锁
我们现在来到Task类当中,这个方法就是V4了/*** Redisson分布式锁实现* @throws InterruptedException*/ // @Scheduled(cron=" ...
- springCloud分布式事务实战(三)分布式事务处理器的编译和运行之注册中心编写与测试...
SpringCloud注册中心编写和测试 (1)创建注册中心工程 (2)添加jar包 pom.xml <project xmlns="http://maven.apache.org/ ...
- 软考-架构师-第三章-数据库系统 第七节 数据库设计(读书笔记)
版权声明 主要针对希赛出版的架构师考试教程<系统架构设计师教程(第4版)>,作者"希赛教育软考学院".完成相关的读书笔记以便后期自查,仅供个人学习使用,不得用于任何商业 ...
最新文章
- SFB 项目经验-37-分配公网证书 For SFB 2015-持久聊天服务器(图解)
- C语言//注释使下一行代码失效
- c语言中指针的类型,学习C语言中的指针类型
- 如何成为有思想、创新的程序员
- WCF后续之旅(11): 关于并发、回调的线程关联性(Thread Affinity)
- 宿舍管理系统项目管理师_2020下半年信息系统项目管理师真题——案例分析(带解析)...
- 1、绪论初识机器学习
- Observe rainy world
- 做生意、做营销常犯的10个错误和对策
- 蓝桥杯 BASIC-4 基础练习 数列特征
- JDBC实现增删改查功能
- FM信号测试软件,音频测试方案:音频FM指标测试方法
- LOIC低轨道离子拒绝服务攻击
- 根据列表内车牌号,统计各省市车牌占有量
- 使用instsrv.exe+srvany.exe将应用程序安装为windows服务的方法
- 职称论文通过查重之后就能发表吗?
- 以衍复为例,聊聊当下的沪深300指数增强
- 靶机渗透练习84-The Planets:Earth
- 扁平化设计与思维导图
- 阿里巴巴、蚂蚁金服 《H5、前端招聘》