groupByKey、reduceByKey区别(转)
转载自:
https://www.cnblogs.com/bonelee/p/7111395.html
spark-shell 下:
代码如下:
val words = Array("one", "two", "two", "three", "three", "three")
val wordsRDD = sc.parallelize(words).map(word => (word, 1))
val wordsCountWithReduce = wordsRDD. reduceByKey(_ + _).collect().foreach(println)
val wordsCountWithGroup = wordsRDD.groupByKey().map(w => (w._1, w._2.sum)).collect().foreach(println)虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的key结合。
借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的key是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
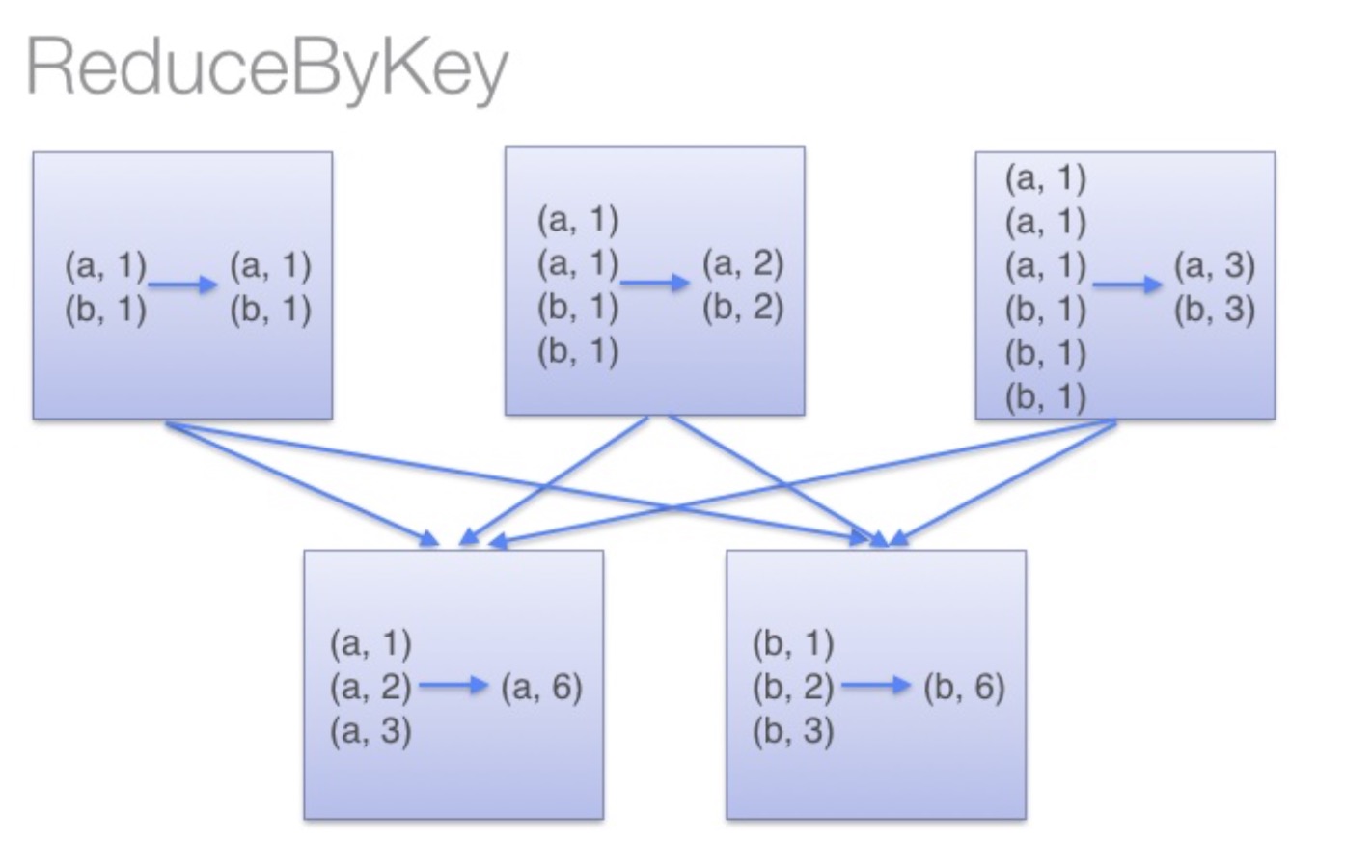
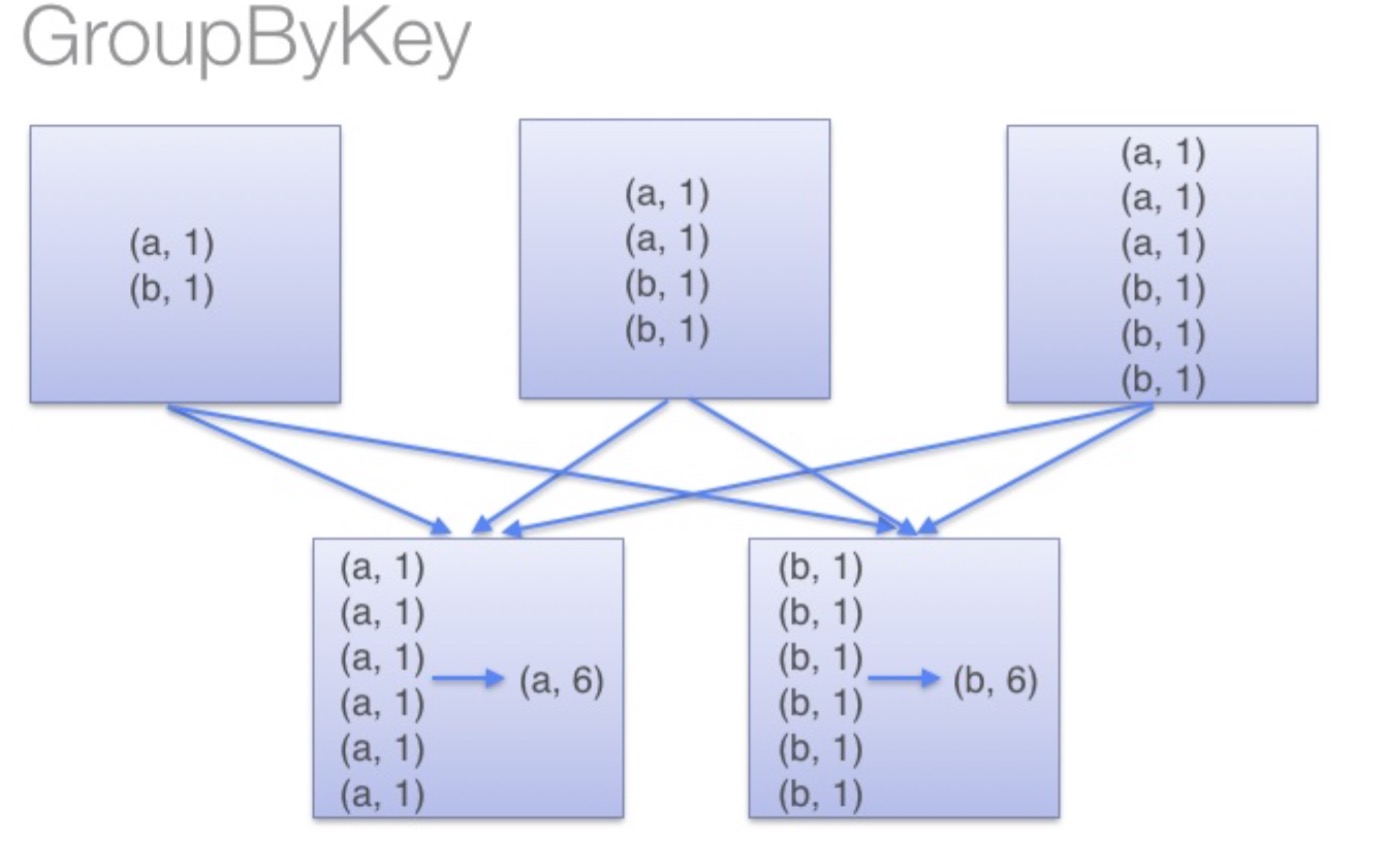
另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
为了确定将数据对移到哪个主机,Spark会对数据对的key调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时Spark会把数据保存到磁盘上。 不过在保存时每次会处理一个key的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
image
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
groupByKey、reduceByKey区别(转)相关推荐
- Spark中distinct、reduceByKey和groupByKey的区别与取舍
1. 代码实例: a. val rdd = sc.makeRDD(Seq("aa", "bb", "cc", "aa", ...
- 深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
下面来看看groupByKey和reduceByKey的区别: val conf = new SparkConf().setAppName("GroupAndReduce").se ...
- groupByKey与reduceByKey区别
If we compare the result of both ( "groupByKey" and "reduceByKey") transformatio ...
- 【Spark】reduceByKey和GroupByKey
尽可能的使用reduceByKey而不使用GroupByKey 1.区别
- Spark:reduceByKey与groupByKey进行对比
两者不同之处: 返回值类型不同:reduceByKey返回的是RDD[(K, V)],而groupByKey返回的是RDD[(K, Iterable[V])],举例来说这两者的区别.比如含有一下数据的 ...
- reduceByKey与GroupByKey,为什么尽量少用GroupByKey
reduceByKey与GroupByKey reduceByKey与GroupByKey在函数运算的时候,结果是相同的 reduceByKey运用图 GroupByKey:运用图 放到一起在计算统计 ...
- Spark精华问答 | Spark和Hadoop的架构区别解读
总的来说,Spark采用更先进的架构,使得灵活性.易用性.性能等方面都比Hadoop更有优势,有取代Hadoop的趋势,但其稳定性有待进一步提高.我总结,具体表现在如下几个方面. 1 Q:Spark和 ...
- Spark中foreachPartition和mapPartitions的区别
Spark中foreachPartition和mapPartitions的区别 spark的运算操作有两种类型:分别是Transformation和Action,区别如下: Transformatio ...
- 2021年大数据Spark(十五):Spark Core的RDD常用算子
目录 常用算子 基本算子 分区操作函数算子 重分区函数算子 1).增加分区函数 2).减少分区函数 3).调整分区函数 聚合函数算子 Scala集合中的聚合函数 ...
最新文章
- react-redux的Provider和connect
- Leetcode409最长回文串 -字符哈希
- Boost:基于不同容器的有界缓冲区比较
- mysql 当前用户连接数_实战:判断mysql中当前用户的连接数-分组淘选
- 用SHA1或MD5 算法加密数据(示例:对用户身份验证的简单实现)
- C#得到CPU的序列号、硬盘序列号、网卡序列号
- 你真的知道Java同步锁何时释放?
- 推荐几十本投资书籍、互联网书籍及热门查看流量的工具
- iOS IM开发建议(一)App框架设计
- 1031 质量环(深层搜索演习)
- yamdi 实现添加元数据的注入flv文件,实现Nginx搭建flv视频浏览器上点播拖拽
- Unity跨iOS、Android平台使用protobuf-net的方法(.Net 2.0)《二》
- Hdu-5053 the Sum of Cube(水题)
- 清北学堂noip2018集训D4
- 2017 AMC8中文
- 当程序员这么多年,我学到了25条人生经验
- Hadoop分布式集群安装
- 第二次尝试制作html5游戏
- 音质好的linux主机,5千音质好的HIFI播放器有哪些?5款性价比“神砖”简评
- 《lwip学习9》-- UDP协议