建筑业建筑业大数据行业现状_建筑—第2部分
建筑业建筑业大数据行业现状
有关深层学习的FAU讲义 (FAU LECTURE NOTES ON DEEP LEARNING)
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
这些是FAU YouTube讲座“ 深度学习 ”的 讲义 。 这是演讲视频和匹配幻灯片的完整记录。 我们希望您喜欢这些视频。 当然,此成绩单是使用深度学习技术自动创建的,并且仅进行了较小的手动修改。 如果发现错误,请告诉我们!
导航 (Navigation)
Previous Lecture / Watch this Video / Top Level / Next Lecture
上一个讲座 / 观看此视频 / 顶级 / 下一个讲座
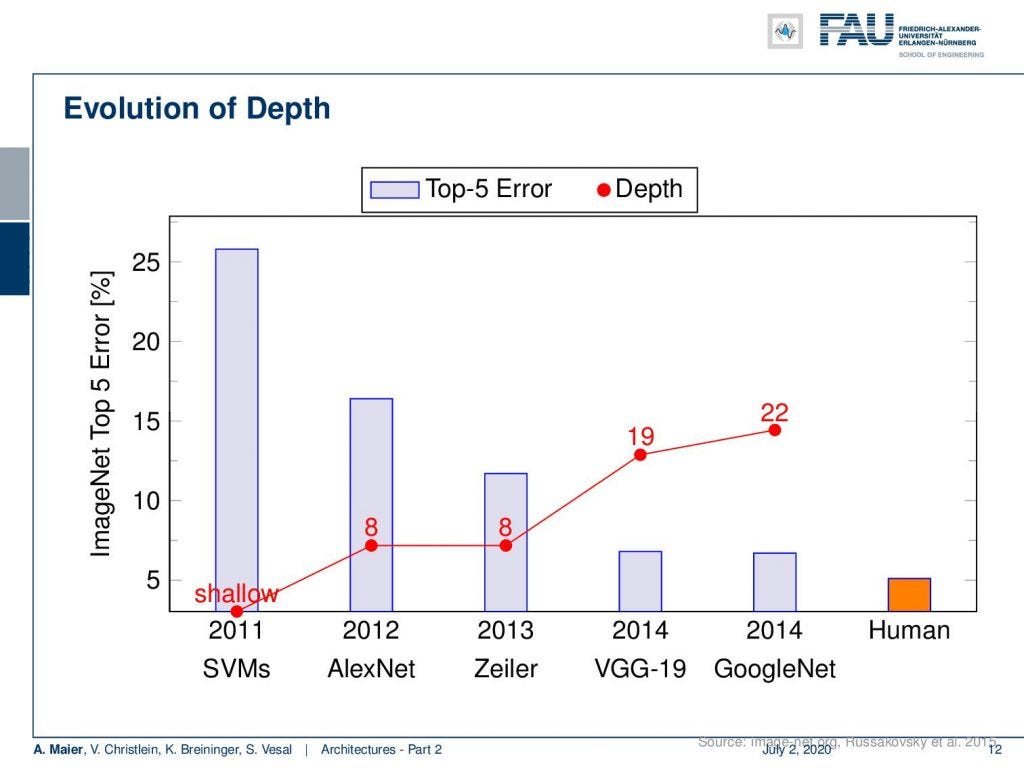
Welcome back to deep learning! Today I want to talk about part two of the architectures. Now, we want to go even a bit deeper in the second part: Deeper models. So, we see that going deeper really was very beneficial for the error rate. So, you can see the results on ImageNet here. In 2011, with a shallow support vector machine, you see that the error rates were really high with 25%. AlexNet already almost cut it to half in 2012. Then Zeiler in 2013, was the next winner with again eight layers. VGG in 2014: 19 layers. GoogleNet in 2014: 22 layers, also almost the same performance. So, you can see that the more we increase the depth, the better seemingly the performance gets. We can see there’s only a little bit of margin left in order to beat human performance.
欢迎回到深度学习! 今天,我想谈谈体系结构的第二部分。 现在,我们想在第二部分中更深入:更深层次的模型。 因此,我们发现深入研究确实对错误率非常有利。 因此,您可以在此处在ImageNet上查看结果。 在2011年,使用浅层支持向量机可以看到,错误率确实很高,只有25%。 AlexNet在2012年几乎将其削减了一半。然后在2013年的Zeiler,又是八层的下一届冠军。 2014年VGG:19层。 2014年的GoogleNet:22层,性能几乎相同。 因此,您可以看到,随着深度的增加,性能似乎越好。 我们可以看到只有一点点余量可以击败人类表现。
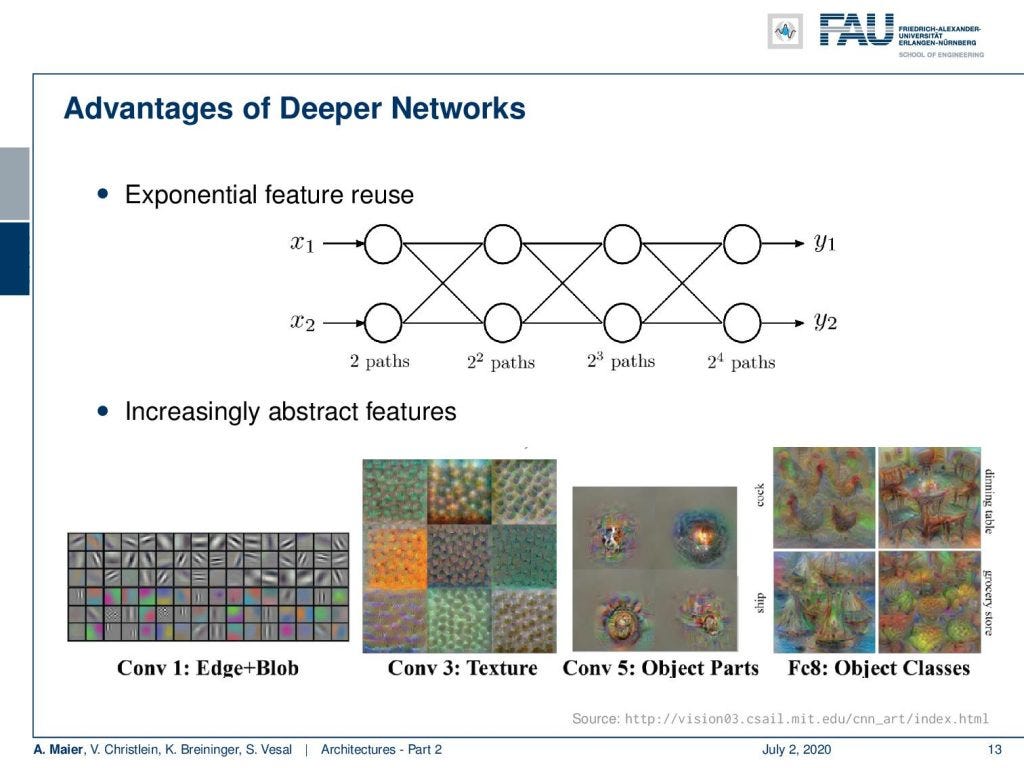
Depth seems to play a key role in building good networks. Why could that be the case? One reason why those deeper networks may be very efficient is something that we call exponential feature reuse. So here you can see if we only had two features. If we stack neurons on top, you can see that the number of possible paths is exponentially increasing. So with two neurons, I have two paths. With another layer of neurons, I have ²² paths. With three layers ²³ paths, ²⁴ paths, and so on. So deeper networks seem somehow to be able to reuse information from the previous layers. We can also see that if we look at what they are doing. If we generate get these visualizations, we see that they increasingly build more abstract representations. So, we somehow see a kind of modularization happening. We think that deep learning works because we are able to have different parts of the function at different positions. So we are disentangling somehow the processing into simpler steps and then we essentially train a program with multiple steps that is able to describe more and more abstract representations. So here we see the first layers, they do maybe edges and blobs. Let’s say, layer number three detects those textures. Layer number five perceives object parts, and layer number eight already object classes. These images here are created from visualizations from AlexNet. So you can see that this somehow seems to be happening really in the network. This is also probably a key reason why deep learning works. We are able to disentangle the function as we try to compute different things at different positions.
深度似乎在建立良好网络中起关键作用。 为什么会这样呢? 那些更深层次的网络可能非常高效的原因之一就是所谓的指数特征重用。 因此,在这里您可以查看我们是否只有两个功能。 如果我们将神经元堆叠在顶部,则可以看到可能路径的数量呈指数增长。 因此,对于两个神经元,我有两条路径。 对于另一层神经元,我有“²”路径。 具有三层“ 3”路径,“ 2”路径等。 因此,更深层次的网络似乎能够以某种方式重用来自先前各层的信息。 如果我们看看他们在做什么,我们也可以看到。 如果生成这些可视化效果 ,我们将看到它们越来越多地构建更多抽象表示。 因此,我们以某种方式看到了一种模块化的情况。 我们认为深度学习之所以起作用,是因为我们能够在不同的位置拥有职能的不同部分。 因此,我们以某种方式将处理分解为更简单的步骤,然后从本质上讲,我们训练了一个具有多个步骤的程序,该程序能够描述越来越多的抽象表示。 因此,在这里我们看到了第一层,它们可能有边缘和斑点。 假设第三层检测到那些纹理。 第五层感知对象部分,第八层已经感知到对象类。 这些图像是根据AlexNet的可视化效果创建的。 因此,您可以看到这种情况似乎确实在网络中发生。 这也可能是深度学习起作用的关键原因。 当我们尝试在不同位置计算不同事物时,我们能够解开函数。
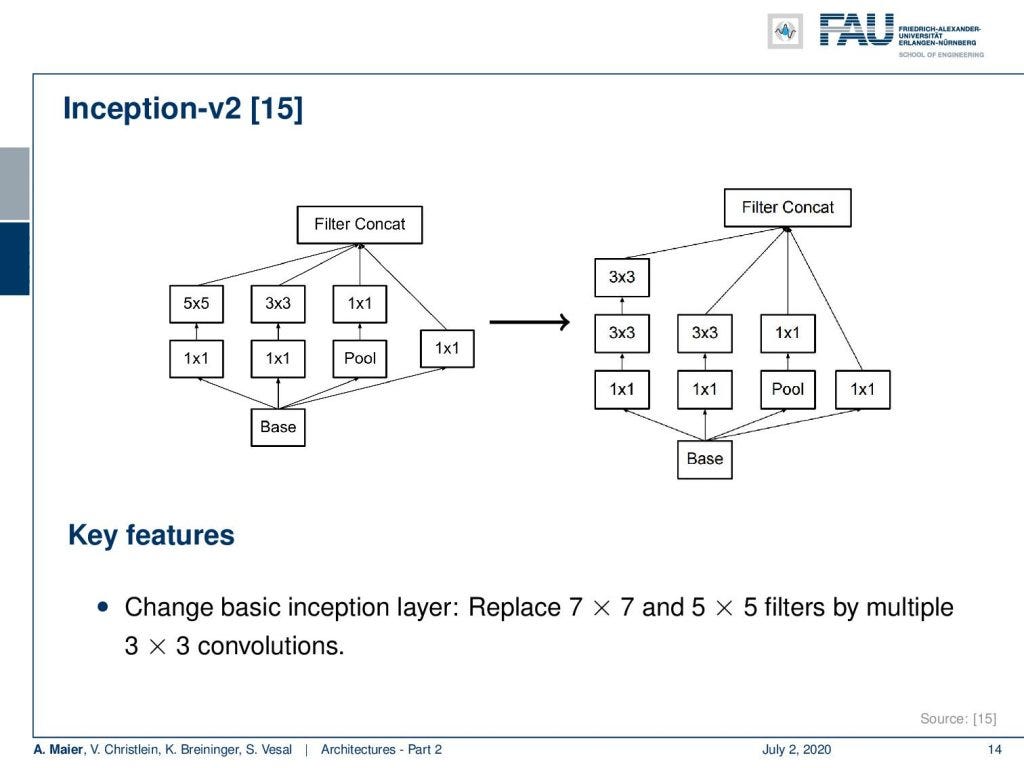
Well, we want to go deeper and one technology that has been implemented there is again the inception modules. The improved Inception modules now essentially replace those filters that we’ve seen with the 5x5 convolutions and 3x3 convolutions into multiple of those conclusions. Instead of doing a 5x5 convolution, you do two 3x3 convolutions in a row. That already saves a couple of computations and you can then replace 5x5 filters by stacking filters on top. We can see that this actually works for a broad variety of kernels that you can actually separate into several steps after another. So, you can cascade them. This filter cascading is something that you would also discuss in a typical computer vision class.
好吧,我们想更进一步,已经实现的一项技术再次是初始模块。 现在,经过改进的Inception模块从本质上将我们用5x5卷积和3x3卷积看到的那些过滤器替换为这些结论的倍数。 而不是进行5x5卷积,而是连续执行两个3x3卷积。 这已经节省了一些计算,然后您可以通过在顶部堆叠滤镜来替换5x5滤镜。 我们可以看到,这实际上适用于各种各样的内核,您可以将它们实际上分成几个步骤。 因此,您可以层叠它们。 这种过滤器级联是您还将在典型的计算机视觉课程中讨论的内容。
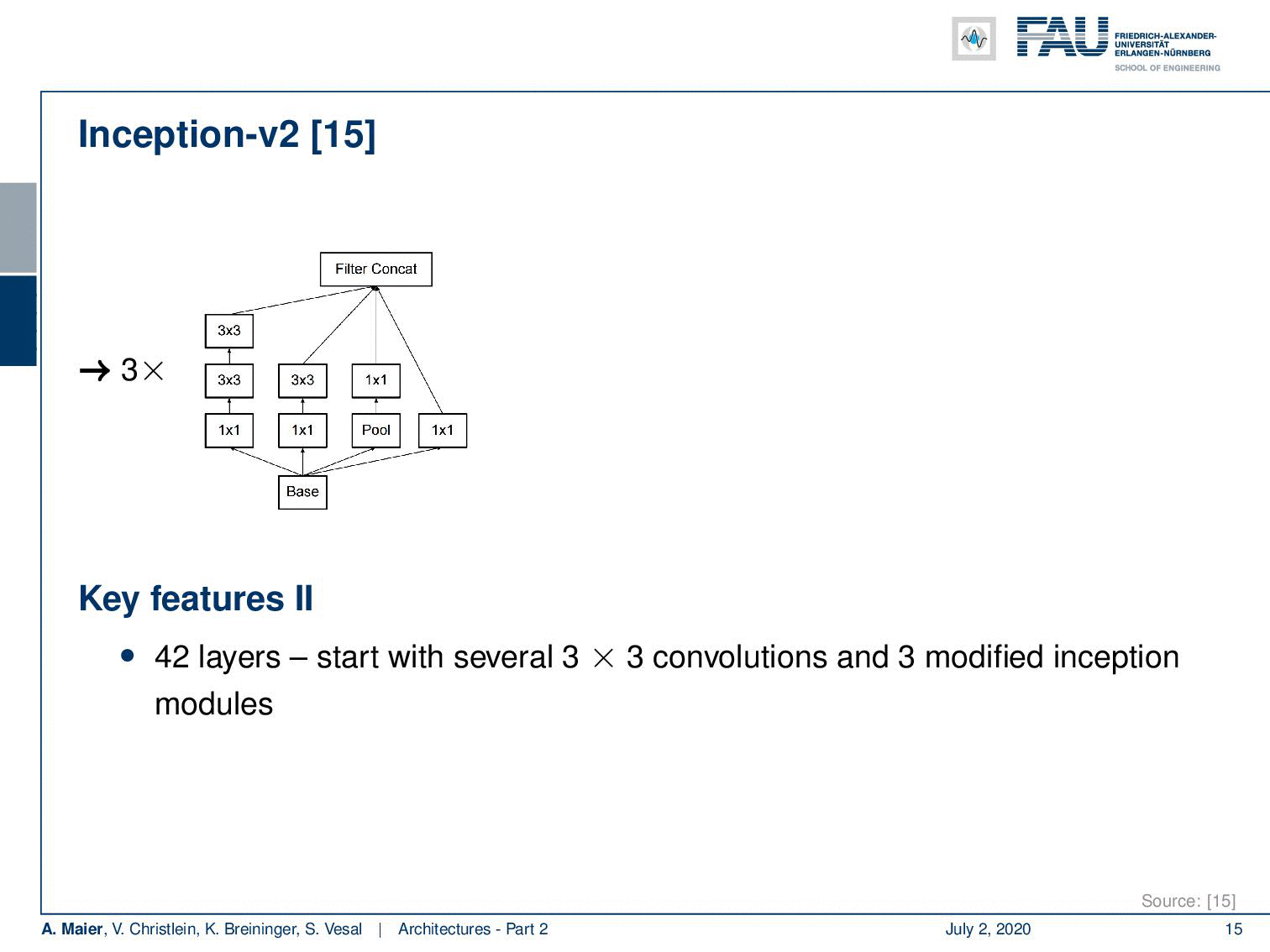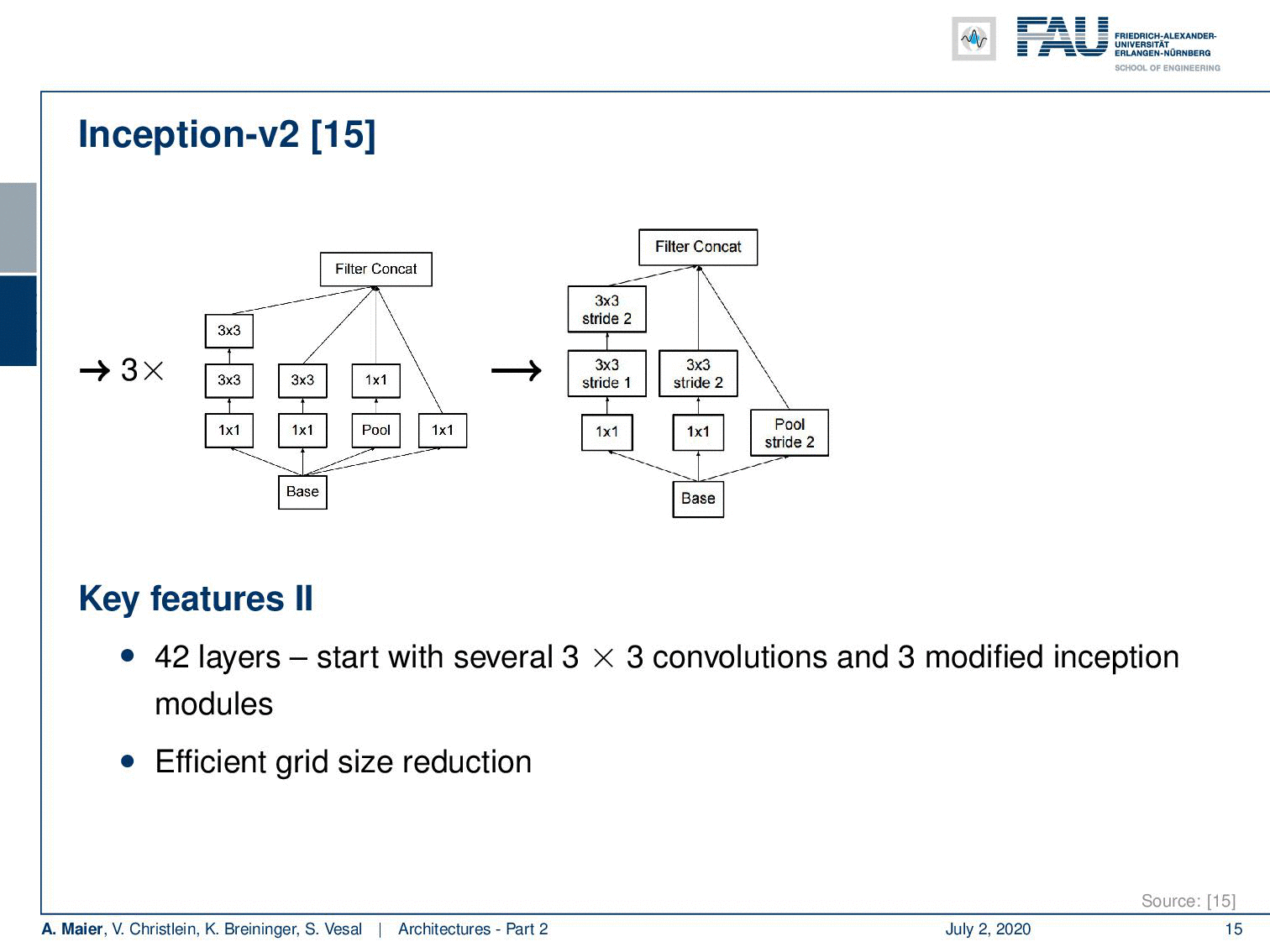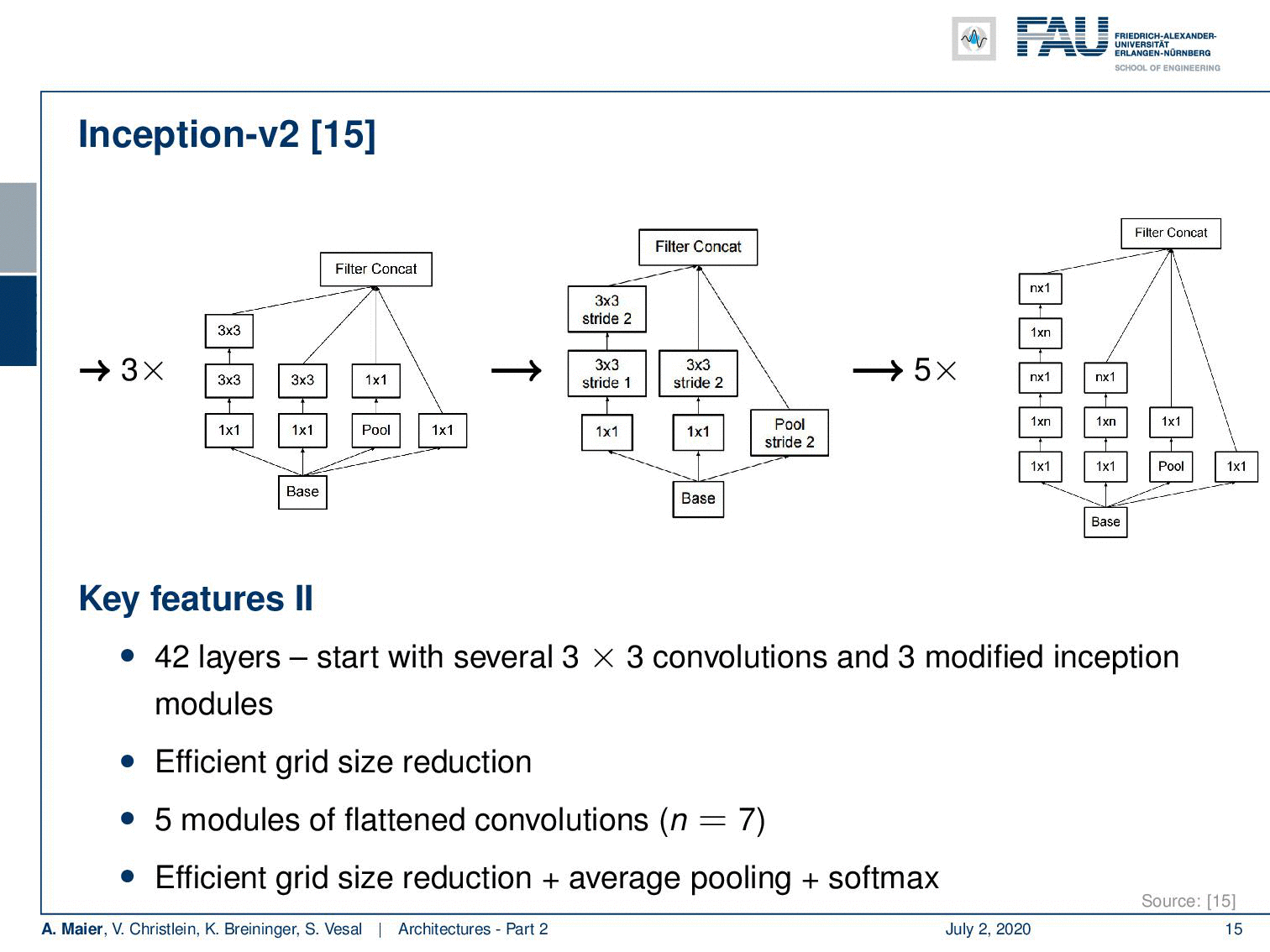
So Inception V2 then already had 42 layers. They start with essentially 3x3 convolutions and three modified inception modules like the one that we just looked at. Then in the next layer, an efficient grid size reduction is introduced that is using strided convolutions. So, you have 1x1 convolutions for channel compression, 3x3 convolutions with stride 1 followed by a 3x3 convolution with a stride of 2. This essentially effectively replaces the different pooling operations. The next idea then was to five times introduce modules of flattened convolutions. Here the idea is to express the convolutions no longer in 2-D convolutions but instead, you separate them into convolutions in x and y-direction. You alternatingly produce those 2 convolutions. So you can see here, we start with 1x1 convolutions in the left branch. Then we do a 1xn convolution followed by a nx1 convolution, followed by a 1xn convolution and so on. This allows us essentially to break down kernels into two directions. So, you know because you alternatingly change the orientation of the convolution, you are essentially breaking up the 2-D convolutions by forced separable computation. We can also see that separation of convolution filters works for a broad variety of filters. Of course, this is a restriction as it doesn’t allow all of the possible computations. But remember, we have in the earlier layers full 3x3 convolutions. So they can already learn how to adopt for the later layers. As a result, they can then be processed by the separable convolutions.
因此,Inception V2已经有了42层。 它们从本质上3x3卷积和三个修改后的起始模块开始,就像我们刚刚看过的那样。 然后,在下一层中,使用跨步卷积引入有效的网格尺寸减小。 因此,您需要进行通道压缩的1x1卷积,步幅为1的3x3卷积,然后步幅为2的3x3卷积。这实际上有效地替代了不同的合并操作。 接下来的想法是五次引入扁平化卷积模块。 这里的想法是不再用2D卷积表示卷积,而是将它们分成x和y方向的卷积。 您交替产生这两个卷积。 因此,您可以在这里看到,我们从左侧分支的1x1卷积开始。 然后我们做了1个ň卷积之后正 X1卷积,随后1Xñ卷积等。 这实际上使我们可以将内核分解为两个方向。 因此,您知道,因为您交替更改卷积的方向,所以实际上是通过强制可分离的计算来分解二维卷积。 我们还可以看到卷积过滤器的分离适用于各种各样的过滤器。 当然,这是一个限制,因为它不允许所有可能的计算。 但是请记住,我们在较早的层中具有完整的3x3卷积。 因此,他们已经可以学习如何在以后的层次中采用。 结果,然后可以通过可分离的卷积对其进行处理。

This then leads to Inception V3. For the third version of Inception, they used essentially Inception V2 and introduced RMSprop for the training procedure, batch normalization also in the fully connected layers of the auxiliary classifiers, and label smoothing regularization.
然后,这导致了Inception V3。 对于Inception的第三版,他们本质上使用了Inception V2,并在训练过程中引入了RMSprop,还在辅助分类器的完全连接层中进行了批量归一化,以及标签平滑规则化。

Label smoothing regularization is a really cool trick. So let’s spend a couple of more minutes looking into that idea. Now, if you think about how our label vectors typically look like, we have one hot encoded vectors. This means that our label is essentially a Dirac distribution. This essentially says that one element is correct and all others are wrong. We typically use a softmax. So this means that our activations have a tendency to go towards infinity. This is not so great because we continue to learn larger and larger weights making them more and more extreme. So, we can prevent that if we use weight decay. This will prevent our weights from growing dramatically. We can also use in addition label smoothing. The idea of label smoothing is that instead of using only the Dirac pulse, we kind of smear the probability mass onto the other classes. This is very helpful, in particular, in things like ImageNet where you have rather noisy labels. So, you remember the cases that were not entirely clear. In these noisy label cases, you can see that this label smoothing can really help. The idea is that you multiply your Dirac distribution with one minus some small number ϵ. You then distribute the ϵ that you deducted from the correct class to all the other classes in an equal distribution. So you can see here that is simply 1/K where K is the number of classes. The nice thing about this label smoothing is that you essentially discourage very hard decisions. This really helps in the case of noisy labels. So this is a very nice trick that can help you with building deeper models.
标签平滑正则化是一个很酷的技巧。 因此,让我们花更多的时间研究这个想法。 现在,如果您考虑一下我们的标记向量的典型外观,那么我们就有一个热编码向量。 这意味着我们的标签实质上是Dirac分布。 这从本质上说一个要素是正确的,而所有其他要素都是错误的。 我们通常使用softmax。 因此,这意味着我们的激活趋向于无穷大。 这并不是很好,因为我们继续学习越来越大的权重,使其越来越极端。 因此,如果使用重量衰减,我们可以防止这种情况。 这将防止我们的体重急剧增加。 我们还可以使用附加标签平滑功能。 标签平滑的思想是,我们不仅仅使用Dirac脉冲,而是将概率质量涂抹到其他类别上。 这非常有用,特别是在像ImageNet这样标签比较嘈杂的地方。 因此,您还记得尚不完全清楚的案例。 在这些嘈杂的标签情况下,您可以看到这种标签平滑处理确实有用。 这个想法是您将Dirac分布乘以1减去一些小数ϵ。 然后,您将从正确的类别中扣除的in均等地分布到所有其他类别中。 因此,您可以在这里看到的仅仅是1 / K,其中K是类数。 标签平滑处理的好处是,您实质上不鼓励做出艰难的决定。 这对于标签嘈杂确实很有帮助。 因此,这是一个非常好的技巧,可以帮助您构建更深入的模型。

Next time, we want to look into building those really deep models. With what we have seen so far, we would ask: Why not just stack more and layers on top? Well, there’s a couple of problems that emerge if you try to do that and we will look into the reasons for that in the next video. We will also propose some solutions to going really deep. So, thank you very much for listening and see you in the next video.
下次,我们想研究构建那些真正深入的模型。 到目前为止,我们会问:为什么不只是堆叠更多的层并放在顶部? 好吧,如果您尝试这样做会出现很多问题,我们将在下一个视频中探讨造成这种情况的原因。 我们还将提出一些真正深入的解决方案。 因此,非常感谢您的收听,并在下一个视频中与您相见。
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.
如果你喜欢这篇文章,你可以找到这里更多的文章 ,更多的教育材料,机器学习在这里 ,或看看我们的深入 学习 讲座 。 如果您希望将来了解更多文章,视频和研究信息,也欢迎关注YouTube , Twitter , Facebook或LinkedIn 。 本文是根据知识共享4.0署名许可发布的 ,如果引用,可以重新打印和修改。
翻译自: https://towardsdatascience.com/architectures-part-2-2d2ac8f7458e
建筑业建筑业大数据行业现状
http://www.taodudu.cc/news/show-1874104.html
相关文章:
- 脸部识别算法_面部识别技术是种族主义者吗? 先进算法的解释
- ai人工智能对话了_产品制造商如何缓解对话式AI中的偏见
- 深度神经网络 轻量化_正则化对深度神经网络的影响
- dbscan js 实现_DBSCAN在PySpark上的实现
- 深度学习行人检测简介_深度学习简介
- ai初创企业商业化落地_初创企业需要问的三个关于人工智能的问题
- scikit keras_使用Scikit-Learn,Scikit-Opt和Keras进行超参数优化
- 异常检测时间序列_DeepAnT —时间序列的无监督异常检测
- 机器学习 结构化数据_聊天机器人:根据结构化数据创建自然语言
- mc2180 刷机方法_MC控制和时差方法
- 城市ai大脑_激发AI研究的大脑五个功能
- 神经网络算法优化_训练神经网络的各种优化算法
- 算法偏见是什么_人工智能中的偏见有什么作用?
- 查看-增强会话_会话助手平台-Hinglish Voice等!
- 可解释ai_人工智能解释
- 机器学习做自动聊天机器人_聊天机器人业务领袖指南
- 神经网络 代码python_详细使用Python代码和数学构建神经网络— II
- tensorflow架构_TensorFlow半监督对象检测架构
- 最牛ai波士顿动力上台阶_波士顿动力的位置如何使美国成为人工智能的关键参与者...
- 阿里ai人工智能平台_AI标签众包平台
- 标记偏见_人工智能的偏见
- lstm预测单词_从零开始理解单词嵌入| LSTM模型|
- 动态瑜伽 静态瑜伽 初学者_使用计算机视觉对瑜伽姿势进行评分
- 全自动驾驶论文_自动驾驶汽车:我们距离全自动驾驶有多近?
- ocr图像识别引擎_CycleGAN作为OCR图像的去噪引擎
- iphone 相机拍摄比例_在iPhone上拍摄:Apple如何解决Deepfakes和其他媒体操纵问题
- 机器学习梯度下降举例_举例说明:机器学习
- wp-autoblog_AutoBlog简介
- 人脸识别 特征值脸_你的脸值多少钱?
- 机器学习算法的差异_我们的机器学习算法可放大偏差并永久保留社会差异
建筑业建筑业大数据行业现状_建筑—第2部分相关推荐
- 2022-2028年中国工业大数据行业深度调研及投资前景预测报告
[报告类型]产业研究 [出版时间]即时更新(交付时间约3个工作日) [发布机构]智研瞻产业研究院 [报告格式]PDF版 本报告介绍了工业大数据行业相关概述.中国工业大数据行业运行环境.分析了中国工业大 ...
- 大数据行业前景_大数据未来展望
大数据的概念问世这么多年来,大数据从技术,政策和资本等多个角度已经切入到社会方方面面,未来数据也会成为的经济驱动因素中越来越重要的一部分.对未来而言,大数据的发展将影响到产业.企业和个人.需要学习大数 ...
- 大数据行业现状分析和最新行业动态
本质:通过大量现象,总结规律,进行预测 与传统通过因果关系进行预测的区别 eg:因果关系:王者荣耀火爆->推测腾讯股票会上涨,然后自己购买 现在:通过大数据检测到很多人购买-->自己购买 ...
- 独家 | 一文盘点数据行业的动态演变(附链接)
作者:Deepesh Nair 翻译:王雨桐 校对:丁楠雅 本文约5800字,建议阅读15分钟. 本文从多个角度盘点数据行业近年来的变化,并对当前数据行业现状进行了分析和评价. 近年来,数据行业不断涌 ...
- 推荐 :一文盘点数据行业的动态演变(附链接)
作者:Deepesh Nair:翻译:王雨桐:校对:丁楠雅 本文约5800字,建议阅读15分钟. 本文从多个角度盘点数据行业近年来的变化,并对当前数据行业现状进行了分析和评价. 近年来,数据行业不断涌 ...
- 人工智能行业有哪些岗位_建筑行业年薪超50万,哪些岗位有希望达到?你是什么岗位呢?昆山建造师培训学校...
建筑行业年薪超50万,哪些岗位有希望达到?你是什么岗位呢? 在我国的众多行业中,建筑行业的收入可以排在前三名了,收入是比较高的,不管是施工建筑工地的工人,还是技术岗位的建筑注册人才,收入都是十分不错的 ...
- 月均数据_程序员月均薪多少,2019全国互联网行业程序员就业大数据报告
<2019全国互联网行业程序员就业大数据报告>,该报告针对程序员画像.专业背景.职能供需分布.城市分布特征和薪资优势等方面进行分析.作者:子瑜说IT 下面,一起来看看,2019年1月-9月 ...
- 盈建科弹性板6计算_盈建科(300935):国内建筑结构设计软件行业的领先企业...
点击上方 新股知识学堂 每日推送一只新股内容 个股点评 盈建科是国内建筑结构设计软件行业的领先企业,公司的主要产品YJK建筑结构设计软件系统可以为结构工程师的设计活动提供必要的软件工具支持.公司的装配 ...
- 【数据分发服务DDS】软件定义汽车【四】-行业现状
引言 思绪乱飞导致失眠,索性打开电脑记录了下来,前几篇主要写技术,本篇主要介绍一下行业现状,介绍技术和数据是相对客观的,但是谈观点就会有我自己的主观意识在里面,所以这方面仅供大家参考,主要包含以下内容 ...
- 中国光伏建筑一体化(BIPV)行业发展趋势前瞻与四五战略规划研究报告2022-2028年
中国光伏建筑一体化(BIPV)行业发展趋势前瞻与四五战略规划研究报告2022-2028年 第1章:中国BIPV发展环境分析1.1 BIPV定义与优越性分析 1.1.1 BIPV定义 1.1.2 B ...
最新文章
- 《Nature》发布毫米级软体机器人,可在没有任何物理干预情况下游走于人体
- java冒泡排序_Java算法分析之冒泡排序(Bubble Sort)
- 12_VersionedCollapsingMergeTree,Log Engine Family(Log引擎,StripeLog引擎,TinyLog引擎)
- Linux 系统的日志管理
- 从零开始入门 K8s:深入剖析 Linux 容器
- WM_Paint 消息疑问解析
- jQuery 对话框 jQuery.plugin
- linux menuconfig usb,[Linux]make menuconfig里面的选项很重要
- SharePoint 2013 母版页修改后,无法添加应用程序
- jdk文件夹里点哪个是安装_jdk在哪个文件夹里面
- 【python】QQ 空间照片下载器
- Soap+xml实现webservice 调用
- 【C/C++】多线程中的几种锁
- 激光干涉仪测量五轴机床旋转轴精度的方法
- 解决电脑右侧数字键盘无法打出数字问题
- 用 C 语言编写的程序被称为,用c语言编写的程序被称为
- Revit一款主要用于进行建筑信息建模的软件
- Python 处理日期与时间的全面总结
- 基矢量的协变导数、矢量的协变导数
- 异同移动平均线原理(macd)
热门文章
- hdu1048(c++)
- [ora-02289] sequence does not exist
- pytesseract识别数字
- 20200105每日一句
- 传智播客Java 方法
- Atitit 源码语句解析结构 目录 1.1. 栈帧(stack frame).每个独立的栈帧一般包括: 1 1.2. 局部变量表(Local Variable Table) 2 2. ref 2
- Atitit sumdoc ta index list atiitt 2008 diary 大事记v2 s222.docx Atiti. 2010---2016大事记 just world new
- Atitit 人脸识别 眼睛形态 attilax总结
- Atitit 如何利用先有索引项进行查询性能优化
- Atitit 发帖机实现(4 )- usbQBM1601 gui操作标准化规范与解决方案attilax总结