基于规则的语音合成中文文本前端设计【2】
(以下内容搬运自 PaddleSpeech)
TTS Text Frontend
参考一般的流程,把文本前端分为4个阶段
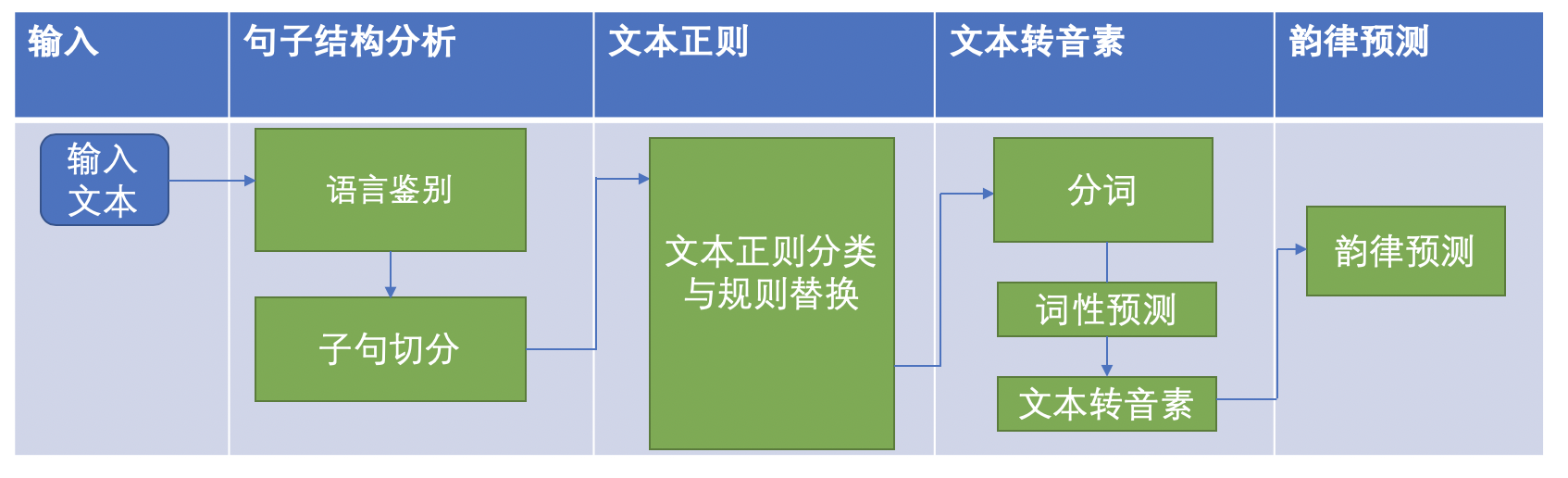
- 句子结构分析
我们给系统输入一个文本,系统要先判断这个文本是什么语言,只有知道是什么语言才知道接下来如何处理。然后把文本划分成一个一个的句子。这些句子再送给后面的模块处理。 - 文本正则化
在中文场景下,文本正则的目的是把那些不是汉字的标点或者数字转化为汉字。比如「这个操作666啊」,系统需要把「666」转化为「六六六」。 - 文本转音素
也就是把文本转化为拼音,由于中文中多音字的存在,所以我们不能直接通过像查新华字典一样的方法去找一个字的读音,必须通过其他辅助信息和一些算法来正确的决策到底要怎么读。这些辅助信息就包括了分词和每个词的词性。 - 韵律预测
用于决定读一句话时的节奏,也就是抑扬顿挫。但是一般的简化的系统都只是预测句子中的停顿信息。也就是一个字读完后是否需要停顿,停顿多久的决策。
其中文本正则化分为三个阶段:
- tokenization(怎么处理 NSW (None Standard Word)让他不被分开,或者如何后处理,找出 NSW 片段);
- NSW 分类(总的类别个数设计,如何分类。其中 1 和 2 可以融合成一个阶段);
- Verbalization: 应用对应的规则进行分类(规则的可复用性,比如大多数数字相关的短语会调用数字的读法)。
文本转音素分为两个阶段:
- 汉字转拼音(需要处理多音字,变调,专有名词特殊读法);
- 拼音转音素。
下面分阶段说明我们希望它如何运作:
文本正则化
Tokenization
一般来说,tokenization 并不等于分词,Multiple Word Token 是存在的,对于 TTS 领域尤为如此,把 4/5, 2020 分开之后,4/5 单独来看可能就难以分清是分数还是比率还是日期了。在基于规则的 Kestrel 系统中,也同样存在。日期,时间,货币,度量短语等是被作为一个单独的 token 处理的,这样也更加符合 TTS 领域的需求。
对于中文领域,如果能复用现有的分词工具是最理想的选择。但现有的中文的分词工具,在分词时,对于 NSW 或者非汉语片段的处理方式值得注意,并没有明确或者统一的处理方式。
NSW 分类
按照 Kestrel 的做法,对于每个 token 进行三分类,
- standard words, 直接照抄即可;
- 标点符号,不发音;
- semiotic class 亦即 NSW. 需要进一步分类。
目前我们计划支持的类别有
整数 CARDINAL
基础组件,在其他类型的 NSW 基本都需要。
序数 ORDINAL
汉语里面基本和基数读法没有差别,除了前附的“第-” ,以及序数中不使用“两”表示数字
2.浮点数 DECIMAL
整数部分按整数读法,小数部分按编号读法。
百分数 PERCENTAGE
百分比的部分按照浮点数读法,前附“百分之”。
分数 FRACTION
分子和分母按照浮点数读法,分母 + “分之” + 分子。
如果有前附整数,先读整数部分,中间加“又”。
比值 RATIO
两部分按浮点数读法,中间加比。
时间 TIME & DURATION
分时间点和时间段两种读法。同时还需要判断是时分秒齐全还是仅有时分还是仅有分秒。
时间段的读法,几小时几分钟几秒即可,各个部分按照整数读法。
时间点的读法,几点几分几秒,各个部分按照整数读法,但是,从第二个数字开始,前附的 0 需要读出。
日期 DATE
需要判断是年月日各段齐全还是仅包含年月还是月和日,各个部分按照整数的读法。
货币 CURRENCY
判断是仅包含一种货币单位的浮点数读法。
还是十元五角这种包含多个货币单位的读法,按照文本的实际写法读出。各个部分按照整数读法。
度量短语 MEASUREMENT EXPRESSION
按照浮点数读法加上对应的度量即可。但是部分度量可能影响符号的读法,比如零下三度一般不读作负三度。度量则需要一个词典。
编号 DIGITS
按照各个数位读出即可。
电话 PHONE
一般按照编号的读法,但是可能存在
一读作yao1的惯例。邮箱 EMAIL
网址
邮箱和网址主要都是涉及英文的读法,所以目前还没有很好的处理方式。
我们的方案是:
一个规则采用 f: NSW -> normalized words 的方法实现。NSW 里面可以根据不同的类别设定不同的字段,并且把字段填充上,这样 verbalization 的时候就可以无需再进行解析。填充的过程可以使用正则表达式做分组匹配。
目前需要做的是,对每一个类别实现一个类型,约定其需要填充的字段,并且写好对应的正则表达式规则去匹配。
Verbalization
Verbalization 的部分是对于每一类提供单独的规则进行展开。其中大部分可以调用数字的 verbalization 方法。各个类别的 Verbalization 方法已经写在上面一节。
Reference
- https://www.researchgate.net/publication/277932107_The_Kestrel_TTS_text_normalization_system
- https://github.com/google/sparrowhawk
- https://github.com/google/re2
G2P
汉字转拼音
目前使用的方案就是先分词(对正则化后的文本分词),然后把分词的结果交由 pypinyin 处理。自定义可以通过自定义单字字段和短语字典的方式来实现。目前主要的问题有多音字和变调。
多音字
两种实现方式:基于模型的多音字消歧模块,另一种基于字典的方式。
目前主要通过扩增短语词典的方式来实现,这样我们可以通过扩增词典来修改 bad case.

![]()
其中 load_phrases_dict 的 PHRASES_DICT 影响到 mmseg 的分词,
![]()
和词到pinyin的转换。
![]()
轻声
可以通过词典解决.
变调
“一” “不” 变调的问题相对简单,只要看其后面的字的声调即可。
三声变调问题相对复杂一些。对于连续的上声字组成的短语,需要分析内部的结构才能准确标注变调。
三声变调
最普通的变调规则即是在一组两个上声(第三声)的合音节中,须将合音节中领先的第一个音节提升到阳平(第二声)。
举例来说,你好(nǐ hǎo)为最普通的中文问候语,nǐ与hǎo原调都是上声,不过合音节第三声的“你”须读为调值略低的阳平(实际为上声的后半段,但听感与阳平几乎一致)即“你好”要念为“ní hǎo”。1. 两个三声:When there are two Third Tones together, the first one changes into the Second Tone.
2. 三个三声ABC: three number "nine" are equally put together, the first two syllables both change into the Second Tone.
(AB)+C:(syllable A + B) is a word, and it modifies syllable C. Both (syllable A + B) change into the Second Tone.A+(BC): syllable A is a word, and it modifies (syllable B + C). Only syllable B changes into the Second Tone. Also, syllable A in this situation is actually pronounced in the Half Third Tone
3. half third tone
When Chinese Pinyin Third Tone goes before the First, the Second or the Fourth Tone
So when we have a 3-syllable word. With the Tones like below, the syllable marked in red and underlined is pronounced as Half Third Tone.
nǎ gēn nǎ ——> Half 3rd + 1st + Full 3rd
gēn nǎ -> 1st + Full 3rd三声变调:最大匹配三声序列,分两个或者三个三声。
三个三声:找到后可以分词,然后应用规则。
是否要加入半三声?两个四声
第一个四声变成半四声。轻声
They are 2-syllable words with both syllables made of the same characters.
In each word, the first character is pronounced in its original Tone
while the second character is pronounced in the Neutral Tone.
爸爸,妈妈,哥哥,他的,好吧,要不,孩子,东西,钉子,脑子The Third Tone in Front of The Neutral Tone
No.1 When the original Tone of the Neutral-tone syllable is the Third Tone, the Third Tone in front of it becomes the Second Tone;
No.2 When the Neutral-tone syllable is originally in the First, the Second or the Fourth Tone, the Third Tone in front of it is pronounced in the Half Third Tone.一不变调
当“一”和“不”夹在词语中间念轻声,例如“看一看”、“好不好”等等。“一”的变调
“一”的原调是第一声。
当“一”在表示数目时,以及在词尾出现时,念为原调。例如︰一二三四、第一等等。
当“一”与量词配搭时,如量词的声调是第一声、第二声或第三声,“一”念成第四声,例如“一根”、“一钱”和“一种”。
如果量词的声调是第四声,“一”念成第二声,例如“一寸”。
(1) When 一 is by itself, meaning "the mathematical number one", it is pronounced in the First Tone "yī".
(2) When Character Yi 一 goes before the First, the Second and the Third Tone, it is pronounced in the Fourth Tone "yì";
(3) When Character Yi 一 goes before the Fourth Tone, it is pronounced in the Second Tone "yí".“不”的变调
“不”的原调是第四声。
当“不”后面跟着第一声、第二声和第三声的字,或者“不”出现在词末,念为原调。例如︰“不高”、“不祥”、“不好”和“我就不”。
当“不”后面的字是第四声,念为第二声,例如“不要”。
Reference
- https://en.wikipedia.org/wiki/Standard_Chinese_phonology#Tone_sandhi
- https://github.com/Kyubyong/g2pC/blob/master/g2pc/g2pc.py#L84
- https://github.com/mozillazg/python-pinyin/issues/133
- https://zh.wikipedia.org/wiki/%E8%AE%8A%E8%AA%BF
拼音转音素
目前我们有两个方案,但是大同小异,其中一套和汉语拼音更为相近,只需要做简单的处理,另一套则则是识别领域的方案。
总结
NSW
10 种 NSW,具体见代码
变调
4 种变调:一、不、三声、轻声。具体见代码.
多音字
采用自定义多音字字典的方式,基于pypinyin库实现。
Reference
- https://www.shenzhenware.com/articles/13355
- https://zhuanlan.zhihu.com/p/70629035
- https://github.com/PaddlePaddle/PaddleSpeech/issues/678
- https://github.com/PaddlePaddle/PaddleSpeech/issues/632
P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
基于规则的语音合成中文文本前端设计【2】相关推荐
- 基于规则的语音合成中文文本前端设计
(以下内容搬运自 PaddleSpeech) Chinese Rule-Based Text Frontend A TTS system mainly includes three modules: ...
- 开源(离线)中文文本转语音TTS(语音合成)工具整理
开源(离线)中文文本转语音TTS(语音合成)工具整理 目录 文章目录 目录 PaddleSpeech VoiceVox TensorFlowTTS ttskit OpenTTS eSpeak 微软 T ...
- 【语音合成】TensorFlowTTS 中文文本转语音
[语音合成]TensorFlowTTS 中文文本转语音 文章目录 [语音合成]TensorFlowTTS 中文文本转语音 简介 环境配置 1.windows端 2.ubuntu端(可行) 程序运行 1 ...
- 怎样构建中文文本标注工具?(附工具、代码、论文等资源)
来源:Paperweekly 本文长度为2218字,建议阅读4分钟 本文为你介绍中文文本标注工具的构建方法,并提供多个开源文本标注工具. 项目地址: https://github.com/crownp ...
- 构想:中文文本标注工具(内附多个开源文本标注工具)
■ 项目地址 | https://github.com/crownpku/Chinese-Annotator 自然语言处理的大部分任务是监督学习问题.序列标注问题如中文分词.命名实体识别,分类问题如关 ...
- 大规模中文文本处理中的自动切词和标注技术
Internet网络通信技术和大容量存储技术的发展,加速了信息流通的速度,形成了大规模真实文本库.这些信息具有规模大.实时性强.内容分布广和格式灵活多样等特点,从而迫使人们考虑语言信息处理的新理论和新 ...
- 效率为王!易用的前端设计工具推荐
如果没有设计基础,怎样才有高效工作?今天就介绍几个易用的前端设计工具,并根据不同的用途,从配色.原型设计.字体.图片.以及切图标注五大方面进行分类介绍. 前端设计配色工具 1.ColorSupplyy ...
- python 文本分析库_Python有趣|中文文本情感分析
前言 前文给大家说了python机器学习的路径,这光说不练假把式,这次,罗罗攀就带大家完成一个中文文本情感分析的机器学习项目,今天的流程如下: 数据情况和处理 数据情况 这里的数据为大众点评上的评论数 ...
- mfc获取子窗口句柄_前端设计-JavaScript中父窗口与子窗口间的通信
父窗体与子窗体之间的通信 在之前文章讲解windows程序设计过程中,我们曾描述了windows程序窗口之间通信与控制实现方法与过程,如窗体之间参数传递等.本文主要从Web程序开发前端JavaScri ...
最新文章
- python c#_【分享】C# 调用 Python 脚本, 与 Python 调用 C# 类库
- moss 与SAP iView web part 整合
- Oracle里default什么意思,ORACLE中默认值default的使用方法.doc
- 高精度模板(含加减乘除四则运算)
- **PCD数据获取:Kinect+OpenNI+PCL对接(代码)
- 多合一图床源码 - QQ图床/搜狗图床/头条图床
- 基于表的数据字典构造MySQL建表语句
- bankbone 模型简单介绍
- 初译 Support Vector Machines:A Simple Tutorial(一)
- 中兴e8820刷openwrt_中兴E8820V2(电信天翼宽带类似新路由3歌华链)-拆机及OpenWrt固件...
- pytorch读取lmdb文件报错,lmdb.InvalidParameterError:解决
- 虚拟机linux删除文件后未释放空间,【Linux命令】删除大文件后磁盘空间未释放问题...
- android 车载安富蓝牙电话开发,Android平台BLE低功耗蓝牙开发
- Connection id “0HMGNTPDIIA4M“.Request id “0HMGNTPDIIA4M:00000001“:An unhandled exception was thrown
- html实现圆形计时器特效,如何用css3实现圆形倒计时
- 计算机二级Python操作题练习(第一套)
- Linux安装GBase8a数据库
- SICP读书笔记 3.1
- 集客 ap ac扫盲贴 来自恩山论坛
- 联想计算机如何进bois,小编教你联想电脑怎么进入bios