nlp gpt论文_gpt 3变形金刚和nlp的狂野世界
nlp gpt论文
介绍(Introduction)
The tech world is so full of fascinating demons. Every now and then, we get to be awed, not without a hint of horror, by a new development. The natural language processing (NLP) model GPT-3 recently developed by OpenAI is exactly a such creature. The Guardian has published an entire article (allegedly) generated by GPT-3. Although not really up to The Guardian’s standard, this piece is convincingly coherent, and probably, human-like. Weighing the potential impact, OpenAI has decided to only open API access to a few selected partners. An understandable choice, one might say: we don’t want to unleash the demon just yet.
科技界充满了迷人的恶魔。 时不时地,我们会被新的发展所敬畏,而不是没有一点恐怖。 OpenAI最近开发的自然语言处理(NLP)模型GPT-3就是这种生物。 卫报已发布了GPT-3产生的整篇文章(据称)。 尽管这件作品并没有真正达到《卫报》的标准,但却令人信服地保持连贯性,甚至可能像人一样。 考虑到潜在影响,OpenAI决定仅向少数选定的合作伙伴开放API访问。 也许有人会说这是一个可以理解的选择:我们现在还不想释放恶魔。
GPT-3 is indeed the latest and arguably the most powerful member in a family of deep learning NLP models, including Transformer (2017), BERT (2018), GPT series (2018, 2019, 2020) and T5 (2019) as its superstars. Based on them, the research community has proposed numerous variations and improvements, approaching or even surpassing human performance on many NLP benchmark tasks.
GPT-3实际上是一系列深度学习NLP模型中的最新成员,并且可以说是最强大的成员,其中包括Transformer (2017), BERT (2018), GPT系列(2018、2019、2020)和T5 (2019)作为其超级明星。 基于它们,研究团体提出了许多变体和改进,在许多NLP基准任务上接近或超过了人类的表现。
At the same time, Huggingface.co and Allen Institute for AI have done a great job packaging different models together and lowering the barrier for real applications. Suddenly, it feels like all the coolest kitchen gadgets (except GPT-3, for now) are just waiting for you to concoct the finest meal. Naturally, the question is, what to use and what to cook?
同时, Huggingface.co和艾伦AI研究所在将不同模型打包在一起并降低实际应用障碍方面做得很好。 突然之间,感觉到所有最酷的厨房小工具(目前为止不包括GPT-3)都在等着您烹制最好的一餐。 当然,问题是,用什么做饭?
As a NLP and deep learning enthusiast, I have been doing my little researches. It could be fun, I thought, to write a small article to review the different transformers (aka kitchen gadget), matching them with trending use cases (aka recipes) according to their features. To add a little consultancy vibe, I will start with a simple framework to help us reason around. But if you already know the field and absolutely hate frameworks, feel free to go directly to the Technical Part (part 2). If you just want a bullet point summary, or curious about how well the “machine” can write, please head down to the Final Words (part 3).
作为NLP和深度学习爱好者,我一直在做一些小小的研究。 我认为写一篇小文章来回顾不同的变压器(又称厨房小工具),并根据它们的功能将它们与流行的用例(又称食谱)进行匹配可能会很有趣。 为了增加一些咨询的氛围,我将从一个简单的框架开始,以帮助我们进行推理。 但是,如果您已经了解该领域并且绝对讨厌框架,请随时直接转到技术部分(第2部分)。 如果您只想获得一个要点摘要,或者对“机器”的书写水平感到好奇,请直接阅读“最终词汇” (第3部分)。
[As usual, all slides can be directly found here]
[和往常一样,所有幻灯片都可以在这里直接找到]
第1部分。您的NLP用例的简单框架 (Part 1. Simple framework for your NLP use case)
The goal of NLP is to build systems (machines, algorithms) to understand language and carry out language related tasks. Since language plays such a crucial role in our society, the application field of NLP seems unlimited. From online shopping to filing tax returns, we are constantly reading text and take subsequence actions. A perfect NLP robot, let’s call him Nate, would be able to understand and take actions like a human-being. To make that happen, Nate needs to have the following abilities.
NLP的目标是构建用于理解语言并执行与语言相关的任务的系统(机器,算法)。 由于语言在我们的社会中起着至关重要的作用,因此NLP的应用领域似乎是无限的。 从在线购物到报税表,我们一直在阅读文字并采取后续措施。 完美的NLP机器人(我们称其为Nate)将能够理解并采取类似人类的行动。 为实现这一目标,内特需要具备以下能力。
Perception: This is Nate’s ears and eyes. It captures sound or image in the real world and transform them into input signals (texts) for a computer. Speech recognition and optical character recognition (OCR) methods are commonly used to for this part.
知觉:这是内特的耳朵和眼睛。 它捕获现实世界中的声音或图像,并将它们转换为计算机的输入信号(文本)。 语音识别和光学字符识别(OCR)方法通常用于此部分。
Comprehension: This is Nate’s brain. This component is responsible for extracting information and forming knowledge. From word embedding, LSTM to Transformers, deep learning techniques have been developed in recent years to achieve higher levels of comprehension.
理解力:这是内特的大脑。 该组件负责提取信息并形成知识。 从单词嵌入,LSTM到变形金刚,近年来已经开发了深度学习技术,以实现更高的理解水平。
Execution: This is how Nate can take actions and communicate according to his comprehension. The execution could be as straightforward as making a binary choice, or as complicated as writing an essay.
执行力:这就是Nate可以根据自己的理解采取行动和交流的方式。 执行可能像做出二进制选择一样简单,也可能像编写文章一样复杂。
As the perception doesn’t concern the transformer family, we will only discuss comprehension and execution components.
由于感知与变压器系列无关,因此我们仅讨论理解和执行组件。
1.1二维的用例和任务 (1.1 Use cases and tasks in 2 dimensions)
The complexity of comprehension and execution will form the two dimensions of our framework. In addition, word, sentence and document will represent 3 levels of increasing complexities in both dimension. We can thus arrange some NLP use cases on a 2-D scatter chart, like so. Naturally, tasks which lie in the top-right corner are the most difficult ones to tackle and would probably call for some deep learning wizardry.
理解和执行的复杂性将构成我们框架的两个维度。 此外,单词,句子和文档将在两个维度上代表3个级别的不断增加的复杂性。 因此,我们可以像这样在二维散点图上安排一些NLP用例。 自然,位于右上角的任务是最难解决的任务,可能会需要一些深度学习向导。
In the academic world, the closest word for “use case” is “task”. Classic language tasks include Sentiment Analysis, Part of Speech tagging (POS), Natural Language Inference (NLI), Recognising Textual Entailment (RTE) , Question and Answering, etc. Each task has its own objective, benchmark datasets and evaluation metrics (PapersWithCode has a good summary here). Tasks are sometimes lumped together to give a general assessment of a model. GLUE, BLEU, SQuAD and RACE are among the most popular ones, and new models often pride themselves in breaking the record of one test or another.
在学术界,“用例”最接近的词是“任务”。 经典语言任务包括情感分析,语音标记(POS),自然语言推理(NLI),识别文本蕴涵(RTE),问题和答案等。每个任务都有其自己的目标,基准数据集和评估指标( PapersWithCode具有一个很好的总结在这里)。 有时将任务汇总在一起以对模型进行总体评估。 GLUE , BLEU , SQuAD和RACE是最受欢迎的工具,而新模型通常以打破一项或多项测试的记录而自豪。
To find a good model for your use case, it is helpful to check the model’s performance on the tasks (or standardised tests) which best reflect the requirements of your use case. For this purpose, our 2-D scatter chart could again be helpful.
要为您的用例找到一个好的模型,检查在最能反映您用例需求的任务(或标准化测试)中模型的性能是有帮助的。 为此,我们的二维散点图可能会再次有所帮助。
1.2增加约束 (1.2 Adding constraints)
Apart from the simplistic 2D framework, we shouldn’t forget real world constraints. They force us to narrow down our gadget selection by elimination. Some of the most common ones are:
除了简单的2D框架,我们不应该忘记现实世界中的约束。 它们迫使我们通过淘汰来缩小小工具的选择范围。 最常见的一些是:
Latency: Does the system needs to quickly react with the end user? If so, you are in the low latency regime, which requires a fast model and likely precludes some of the chunky guys in the transformer family.
延迟:系统是否需要与最终用户快速React? 如果是这样,则您处于低延迟状态,这需要快速模型,并且可能排除了变压器系列中的一些笨拙的家伙。
Computation power: The question of computation power is sometimes a budget issue, sometimes a design choice. But anyhow, it is probably not a good idea to run the same model on an iPhone and on a cloud TPU.
计算能力:计算能力的问题有时是预算问题,有时是设计选择。 但是无论如何,在iPhone和云TPU上运行相同的模型可能不是一个好主意。
Accuracy: If the model is expected to make medical diagnoses, we should have an extremely low tolerance for error, and higher performance models should always be preferred. On the other hand, for a news recommender, the difference between 90% and 92% accuracy may not be an issue at all.
准确性:如果期望该模型能够进行医学诊断,则我们对错误的容忍度应非常低,而始终应首选性能较高的模型。 另一方面,对于新闻推荐者,90%和92%的准确性之间的差异可能根本不是问题。
1.3奥卡姆剃须刀 (1.3 Occam’s razor)
This section is in fact a big disclaimer. Fancy as they might be, deep learning models are often not the right solution. The transformer family is great for sentence and document level comprehension. So, if your use case only requires word level comprehension and execution, chances are you may not need the heavy machinery of transformers.
该部分实际上是一个很大的免责声明。 纵使如此,深度学习模型通常不是正确的解决方案。 转换器系列非常适合句子和文档级别的理解。 因此,如果您的用例只要求单词级的理解和执行,则可能您不需要变压器的笨重设备。
In fact, for many NLP use cases, old school feature engineering techniques like TF-IDF combined with a random forest might already be good enough. While new technology could bring big improvements in accuracy, the actual value impact may not worth the effort to revamp system design or scale up computation power. For me, a great solution in real life should always be the simplest one that satisfies all the requirements.
实际上,对于许多NLP用例,像TF-IDF这样的老式特征工程技术与随机森林结合起来可能已经足够了。 尽管新技术可以带来巨大的准确性改善,但实际价值影响可能不值得尝试修改系统设计或扩大计算能力。 对我来说,现实生活中的一个好的解决方案应该永远是满足所有要求的最简单的解决方案。
All right, with this in mind, let’s have a closer look at the transformer family.
好吧,考虑到这一点,让我们仔细看一下变压器系列。
第2部分。尝试更多技术性内容 (Part 2. Venturing into more technical stuff)
To keep this article in a reasonable length, we will limit our discussions to the models provided in the package transformer by Huggingface.co. Huggingface.co has not only provided the source code of more than 20 architectures, but also 90 pre-trained models, not including the community contribution. They have also simplified the interface, so that you can try out GPT-2 in a few lines code, or fine-tune T5 with a short script. The stability of the package is something yet to be fully tested, but they definitely provide a great starting point for playing with different NLP models and experimenting with your own ideas. (This article is not sponsored by Huggingface.co, although I wouldn’t mind…)
为了使本文的长度合理,我们将讨论限制在Huggingface.co封装的变压器中提供的模型上。 Huggingface.co不仅提供了20多种体系结构的源代码,还提供了90种经过预训练的模型,其中不包括社区的贡献。 他们还简化了界面,因此您可以在几行代码中试用GPT-2,或者使用简短的脚本微调T5。 软件包的稳定性尚待充分测试,但是它们无疑为使用不同的NLP模型和尝试自己的想法提供了一个很好的起点。 (尽管我不介意,但本文并非由Huggingface.co赞助。)
2.1共同主题 (2.1 Common themes)
Deep learning techniques has been used for NLP for a while, but it was not until the birth of transformer that we saw a significant improvement. Jay Alammar has written a series of brilliant articles to illustrate how those models work. Leaving aside the technical details, we can notice a few common elements which probably lead to their success stories:
深度学习技术已经在NLP中使用了一段时间,但是直到变压器诞生后,我们才看到了显着的进步。 Jay Alammar写了一系列精彩的文章来说明这些模型是如何工作的。 撇开技术细节,我们可以注意到一些可能导致其成功案例的常见要素:
Attention head: Attention head is one of the defining features of the transformer family, and is used consistently ever since first proposed in the first Transformer paper (Vasvani 2017). It provides a highly flexible way to incorporate contextual information (i.e. how a word/token is linked to other words in a sentence or document), which replaced the recursive solutions such as RNN and LSTM.
注意头:注意头是变压器系列的主要特征之一,自从第一篇《变形金刚》论文首次提出(Vasvani 2017)以来就一直使用。 它提供了一种高度灵活的方式来合并上下文信息(即,单词/标记如何与句子或文档中的其他单词链接),从而取代了递归解决方案(如RNN和LSTM)。
Transfer learning: Except for translation, there are only small amount labelled data for specific language tasks, and they are simply not enough for complex deep learning models. The pre-train and fine-tuning paradigm overcomes this problem by allowing knowledge transfer between different tasks. For instance, a general task in pre-train phase which leverages the vast amount of unlabelled data and a specific task in the fine-tuning phase using a small amount but targeted and labelled data. Other types of knowledge transfer have also been explored (T5, GPT-3), and proved to be highly beneficial.
转移学习:除翻译外,只有少量标签数据可用于特定语言任务,而对于复杂的深度学习模型而言,这些数据还远远不够。 预训练和微调范例通过允许不同任务之间的知识转移克服了这个问题。 例如,训练前阶段的一般任务利用了大量未标记的数据,而微调阶段的特定任务则使用少量但有针对性和标记的数据。 还探索了其他类型的知识转移(T5,GPT-3),并被证明是非常有益的。
Corrupt-and-reconstruct strategy: BERT had the ingenious idea to pre-train models with fill-in-the-blank exercises, in which a text is first corrupted by masking a few words (tokens) and then reconstructed by the model. This exercise prompted significant improvements (jumps) across all language tasks. Since then, masking has almost become a standard pre-train strategy, leading to several innovative variations (XLNet, RoBerta, BART).
破坏和重建策略:BERT具有巧妙的想法,可以使用空白练习对模型进行预训练,其中,首先通过掩盖几个单词(标记)破坏文本,然后由模型进行重建。 此练习在所有语言任务上都带来了显着的改进(跳跃)。 从那时起,遮罩几乎已成为一种标准的训练前策略,从而带来了几种创新的变体(XLNet,RoBerta,BART)。
2.2架构 (2.2 Architecture)
In terms of architecture, transformer models are quite similar. Most of the models follow the same architecture as one of the “founding fathers”, the original transformer, BERT and GPT. They represent three basic architectures: encoder only, decoder only and both.
在架构方面,变压器模型非常相似。 大多数模型都采用与“创始者”之一相同的架构,即最初的变压器BERT和GPT。 它们代表三种基本体系结构:仅编码器,仅解码器和两者。
Encoder only (BERT): Encoder is usually a stack of attention and feed-forward layers, which encode the input text sequence into contextualised hidden states. To generate different output format of language tasks, a task specific head is often added on top of the encoder. For example, a causal language model (CLM, or simply LM) head to predict the next word, or a feed-forward (linear) layer to produce classification labels.
仅编码器(BERT):编码器通常是注意层和前馈层的堆栈,它们将输入文本序列编码为上下文隐藏状态。 为了生成语言任务的不同输出格式,通常在编码器的顶部添加特定于任务的头。 例如,使用因果语言模型(CLM,或简称为LM)来预测下一个单词,或者使用前馈(线性)层来生成分类标签。
Decoder only (GPT): In many ways, an encoder with a CLM head can be considered a decoder. Instead of outputting hidden states, decoders are wired to generate sequences in an auto-regressive way, whereby the previous generated word is used as input to generate the next one.
仅解码器(GPT ):在许多方面,可以将具有CLM磁头的编码器视为解码器。 代替输出隐藏状态,连接解码器以自动回归的方式生成序列,从而将先前生成的单词用作输入以生成下一个单词。
Both (Transformer): The distinction between encoder and decoder makes most sense when they both exist in the same structure, as in Transformer. In an encoder-decoder structure, input sequence is first “encoded” into hidden states, and then “decoded” to generate an output sequence. Encoder and decoder can even share the same weights to make training more efficient.
两者(Transformer) :当编码器和解码器都以相同的结构存在时,就像在Transformer中一样,它们之间的区别最有意义。 在编码器/解码器结构中,输入序列首先被“编码”为隐藏状态,然后被“解码”以生成输出序列。 编码器和解码器甚至可以共享相同的权重,以提高训练效率。
The architecture of the model often constraints the type of tasks it can execute: Encoders (without any task specific head) only output hidden states, which can be incorporated as features in other model. Decoders (or encoder + decoder) are created for text generation, which make them suitable for tasks like machine translation, summarisation and abstractive question and answering. Task specific heads provide extra flexibility in the output format, allowing it to fine-tune on classification related tasks.
模型的体系结构通常会限制其可以执行的任务类型:编码器(没有任何特定于任务的头)仅输出隐藏状态,这些状态可以作为功能集成到其他模型中。 创建用于文本生成的解码器(或编码器+解码器),使其适合于机器翻译,摘要和抽象性问题与回答之类的任务。 特定于任务的头在输出格式上提供了额外的灵活性,从而使其可以微调与分类相关的任务。
2.3趋势 (2.3 Trends)
Besides the 3 basic architectures, there have been several innovative modifications, which we will discuss in a moment. However, in general, I feel that the research in transformers follows a few big trends. The most influential one is obviously: scaling up.
除了3种基本架构之外,还有一些创新的修改,我们将在稍后讨论。 但是,总的来说,我认为对变压器的研究遵循了一些大趋势。 最有影响力的是:扩大规模。
Trend 1: Scaling up
趋势1:扩大规模
Deep learning models are becoming larger and deeper, consuming ever more data and computation power. Transformers are no exceptions. Since BERT’s unsupervised pre-train unlocked the power of hundreds of billions of online data, it becomes possible to train bigger models. The largest GPT-3 has 175 billion parameters, which is more than 500 times the largest BERT. If we compare the performance of different models (GLUE and SQuAD 1.1) with their numbers of parameters, we can see a roughly log-linear trend. (GPT series are not included since they are not fine-tuned for those tasks, and only yield mediocre results, which is not really their fault.) It is more difficult to get a quantitative view on tasks like summarisation or translation due to the diversity in benchmark dataset. However, GPT-3’s essay on Guardian seems to have proved “the bigger, the smarter”.
深度学习模型变得越来越大,越来越消耗数据和计算能力。 变形金刚也不例外。 由于BERT的不受监督的预训练释放了数千亿在线数据的力量,因此有可能训练更大的模型。 最大的GPT-3具有1,750亿个参数,是最大的BERT的500倍以上。 如果将不同模型(GLUE和SQuAD 1.1)的性能与它们的参数数量进行比较,我们可以看到大致的对数线性趋势。 (不包括GPT系列,因为它们没有针对这些任务进行微调,并且只能产生中等水平的结果,这实际上不是他们的错。)由于多样性,很难对诸如摘要或翻译之类的任务获得定量的看法在基准数据集中。 但是,GPT-3关于《卫报》的文章似乎已被证明“更大,更聪明”。
Trend 2: Seamless transfer
趋势2:无缝转移
The second trend is the generalisation of transfer learning. This is where things gets more interesting. We have mentioned how the pre-train + fine-tuning paradigm accelerated the research in this field. Yet, the knowledge transfer between different tasks, or so-called “multi-tasking”, was still not obvious, mostly different tasks require different task specific heads. However, T5 solved this issue nicely by reformulating all tasks into a unified “text-to-text” format, thus removing the need for task specific architecture. With the same architecture, knowledge could be transferred “smoothly” between pre-train and different fine-tuning tasks, by simply changing the data and loss function.
第二个趋势是转学的普遍化。 这是事情变得更加有趣的地方。 我们已经提到了预训练+微调范例如何加速了该领域的研究。 然而,不同任务之间的知识转移或所谓的“多任务”仍然不明显,大多数不同的任务需要不同的任务负责人。 但是, T5通过将所有任务重新格式化为统一的“文本到文本”格式很好地解决了这个问题,从而消除了对特定于任务的体系结构的需求。 使用相同的体系结构,只需更改数据和损失函数,就可以在预训练和不同的微调任务之间“平稳地”转移知识。
On the other hand, GPT series have chosen a completely different approach. Indeed, GPT-3 rejected completely the idea of “fine-tuning”, making the hypothesis that given enough data and enough parameters (a ridiculously large amount), a model would need no fine-tuning at all. This means that not only the architecture stays the same across different tasks, but the entire model parameters also remain unchanged. It hopes to create a generalist machine who would be able to understand new tasks specified as natural language, in the same way as a human being. Although not yet a full victory, GPT-3 has achieved stunning results. The fine-tuning free knowledge transfer worked more or less successfully on various language tasks. In practice, it would be quite unrealistic for almost everyone except the powerful few (GAFA) to deploy such a gigantic model, let alone the whole ethical issues that it stirred. But GPT-3 has definitely created its own fashion in the world of Artificial General Intelligence.
另一方面,GPT系列选择了完全不同的方法。 确实,GPT-3完全拒绝了“微调”的想法,提出了这样的假设:只要有足够的数据和足够的参数(数量可笑),模型就根本不需要微调。 这意味着不仅体系结构在不同任务之间保持不变,而且整个模型参数也保持不变。 它希望创建一个通才机器,该机器能够以与人类相同的方式理解指定为自然语言的新任务。 尽管尚未完全取得胜利,但GPT-3取得了惊人的成绩。 经过微调的免费知识转移或多或少地成功地完成了各种语言任务。 实际上,除了功能强大的少数几个公司(GAFA)之外,几乎每个人都无法部署这样一个巨大的模型,更不用说它引发的整个道德问题了。 但是GPT-3无疑在人工智能领域创造了自己的时尚。
“For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets…”
“对于所有任务,应用GPT-3无需进行任何梯度更新或微调,而仅通过与模型的文本交互来指定任务和少量演示。 GPT-3在许多NLP数据集上均具有出色的性能……”
— Language Models are Few-Shot Learners
-语言模型学习者很少
Trend 3: Smart efficiency
趋势三:智能效率
Among the family of giants, there are a few outliers who are more interested in efficiency, and managed to achieve good results with smaller frames. They are practical players who live in a world constraint by finite data and computation resources, like many of us.
在巨人家族中,有一些离群值对效率更感兴趣,并且在较小的框架下能够取得良好的效果。 与我们许多人一样,他们是实践者,他们生活在有限的数据和计算资源的世界中。
XLNet proposed a nice fix to BERT’s discrepancy issue caused by attention masks, RoBERTa tweaked the masking and training procedure, BART experimented with various masking strategies. All of them successfully improved BERT’s performance without increasing the model size.
XLNet提出了一个很好的解决方案,用于解决由注意力遮罩引起的BERT差异问题, RoBERTa调整了遮罩和训练过程, BART尝试了各种遮罩策略。 所有这些都成功地提高了BERT的性能,而没有增加模型大小。
In the other direction, innovative methods have been created to shrink model size without harming performance: ALBERT went aggressive on parameter-sharing, Electra found its inspiration in GAN, and MobileBERT leveraged teacher forcing to make the network deep and slim. Reformer reduced the complexity of attention head from O(N²) to O(NlogN). These models are the happy outliers on the performance vs. size chart. They are probably also the most application friendly ones.
另一方面,已经创建了创新的方法来缩小模型大小而不损害性能: ALBERT积极进行参数共享, Electra在GAN中找到了灵感,而MobileBERT则利用教师强迫使网络更深,更苗条。 重整器将注意力的复杂度从O(N²)降低到O(N log N)。 这些模型是性能与尺寸图上的异常值。 它们可能也是最易于应用程序的。
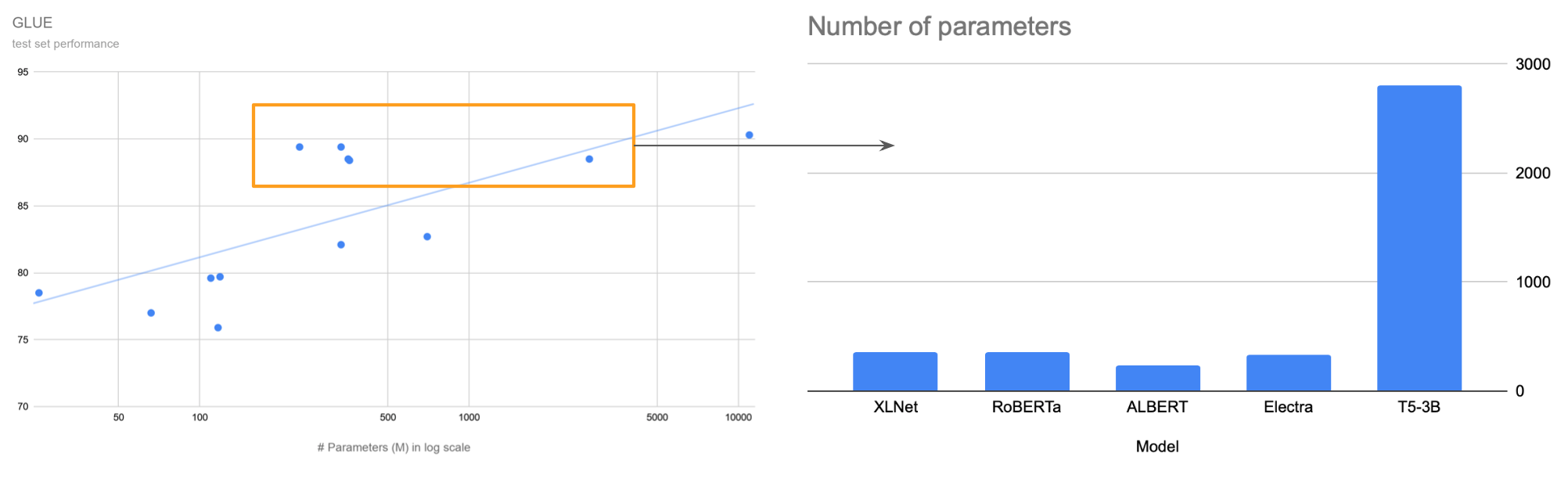
Trend 4: The specialists
趋势4:专家
The last trend is probably not a trend. They are the BERTs, GPTs or Transformers that have been modified and tweaked for a special purpose: Longformer and Transformer-XL focus on lengthy documents, CamemBERT and FlauBERT have undoubtedly French roots, Ctrl provides more control in text generation, DialoGPT aims to be your chatty friend, Pegasus is born for summarisation, and mBART, XLM, mBERT are multi/cross-lingual experts. Like in any other field, specialists shine in their fields, and probably only in their own fields. It is therefore crucial for us to find the best match.
最后的趋势可能不是趋势。 它们是经过特殊修改和调整的BERT,GPT或变形金刚: Longformer和Transformer-XL专注于冗长的文档, CamemBERT和FlauBERT无疑具有法语根源, Ctrl提供了更多的文本生成控制, DialoGPT旨在成为您的健谈的朋友, Pegasus是为总结而生的, mBART , XLM和mBERT是多语言/跨语言专家。 像在其他任何领域一样,专家在各自的领域发光,并且可能仅在各自的领域发光。 因此,对于我们而言,找到最佳匹配至关重要。
2.4动手资源 (2.4 Hands-on resources)
The transformers package provided by Huggingface.co is really easy to use. The Pipeline API provides a simple high-level interface to apply pre-defined tasks, literally with 3 lines.
Huggingface.co提供的变压器套件非常易于使用。 Pipeline API提供了一个简单的高级接口来应用预定义的任务,字面意义为3行。
from transformers import pipelineclassifier = pipeline('sentiment-analysis')classifier('We are very happy to show you the
nlp gpt论文_gpt 3变形金刚和nlp的狂野世界相关推荐
- nlp gpt论文_GPT-3:NLP镇的最新动态
nlp gpt论文 什么是GPT-3? (What is GPT-3?) The launch of Open AI's 3rd generation of the pre-trained langu ...
- 电信保温杯笔记——NLP经典论文:BERT
电信保温杯笔记--NLP经典论文:BERT 论文 介绍 ELMo 对输入的表示 OpenAI GPT 对输入的表示 BERT 对输入的表示 模型结构 整体结构 输入 模型参数量 Input Embed ...
- NLP经典论文:ELMo 笔记
NLP经典论文:ELMo 笔记 论文 介绍 模型结构 文章部分翻译 Abstract ELMo: Embeddings from Language Models 3.1 Bidirectional l ...
- ICLR2020 NLP优秀论文分享(附源码)
来源:知乎 https://zhuanlan.zhihu.com/p/139069973 作者:清华阿罗 本文长度为1500字,建议阅读5分钟 为你分享ICLR2020 NLP优秀论文. 1.REFO ...
- NLP经典论文:Sequence to Sequence、Encoder-Decoder 、GRU 笔记
NLP经典论文:Sequence to Sequence.Encoder-Decoder.GRU 笔记 论文 介绍 特点 模型结构 整体结构 输入 输出 整体流程 流程维度 GRU 模型结构 GRU单 ...
- NLP经典论文:Layer Normalization 笔记
NLP经典论文:Layer Normalization 笔记 论文 介绍 模型结构 batch normalization 和 layer normalization 的相同点 batch norma ...
- NLP经典论文:Word2vec、CBOW、Skip-gram 笔记
NLP经典论文:Word2vec.CBOW.Skip-gram 笔记 论文 介绍 模型结构 CBOW模型 整体模型 输入 输出 整体流程 整体维度 输入层与投影层 输入 输出 输出层 输入 输出 原本 ...
- NLP经典论文:Attention、Self-Attention、Multi-Head Attention、Transformer 笔记
NLP经典论文:Attention.Self-Attention.Multi-Head Attention.Transformer 笔记 论文 介绍 特点 模型结构 整体结构 输入 输出 Attent ...
- 2018 年度 ML、NLP 会议论文大盘点:周明、张潼、孙茂松数据亮眼
2018 年度 ML.NLP 会议论文大盘点:周明.张潼.孙茂松数据亮眼 统计数据覆盖 ACL.EMNLP.COLING.TACL.NeurIPS.ICML.ICLR. AAAI 等 12 个会议/期 ...
最新文章
- 刚进园子,广州的冬天像夏天
- docker mysql 查找ip_Docker 查看运行服务ip
- origin图上显示数据标签_【数据绘图】好图分享:寒假?不存在的!
- laravel5.2基础多模块开发(pingpong/modules)
- 3 关于数据仓库维度数据处理的方法探究系列——缓慢变化维概述和原理
- XP系统限制修改IP有新招
- mock平台架构及实现
- java中GET方式提交和POST方式提交
- 岛国人气美少女竟然每晚跟 3 个人通宵打麻将?
- Java并发教程–信号量
- java工具keytool生成p12数字证书文件
- 数据运营小白如何搭建“初期用户生命周期体系”?
- 成为JavaGC专家Part II — 如何监控Java垃圾回收机制
- lme4:用于混合效应模型分析的R包
- python3 软件加密狗_给软件制作加密狗 - virbox加密空间站 - OSCHINA - 中文开源技术交流社区...
- mysql 只读_MySQL设置只读模式
- icc校色文件使用教程_Windows7色彩管理显示器ICC设置方法
- 力扣(300,674)补9.11
- Pygame学习笔记 6 —— 3D游戏
- java properties文件 变量_properties文件和环境变量
热门文章