省掉1/3的回归测试:Facebook用机器学习自动选择测试策略
为了开发新产品特性并且及时更新,我们使用基于主干的开发模型来更改代码库。一旦工程师的代码改动被主分支(主干)接受,我们就尽量让这些改动对其他从事该产品或服务开发工作的工程师快速可见。这种基于主干的开发模型比使用特性分支和特性合并的方法更有效,因为每个人接触的都是代码库的最新版本。重要的一点是,在被接受到主干之前需要对每个提出的改动进行彻底的回归测试。每个代码改动在从主干部署到生产环境之前都经过了彻底的测试,但是允许回归到主干会使评估新的代码改动更加困难,并且会影响工程师的生产效率。
我们开发了一种更好的方法来执行这项回归测试。我们开发了一个使用机器学习方法来创建概率模型的新系统,用于为特定的代码改动选择适合的回归测试。此方法只需要运行一小部分测试,就能有效地检测出错误的改动。与典型的回归测试选择(RTS)工具不同,该系统通过从大量历史代码变动和测试结果数据集中学习,自动得出测试选择策略。
这个预测性测试选择系统已经在Facebook上部署了一年多,使我们能够在主干代码对其他工程师可见之前,确定超过99.9%的回归问题,同时只需要运行与改动代码相关的所有测试中的三分之一。这让我们的测试设施的效率提高了一倍。
随着代码库的进化,系统也只需要很少甚至不需要手动调优。而且它还能够避免产生不一致和不确定性结果的异常测试。
为什么使用构建的依赖项是低效的?
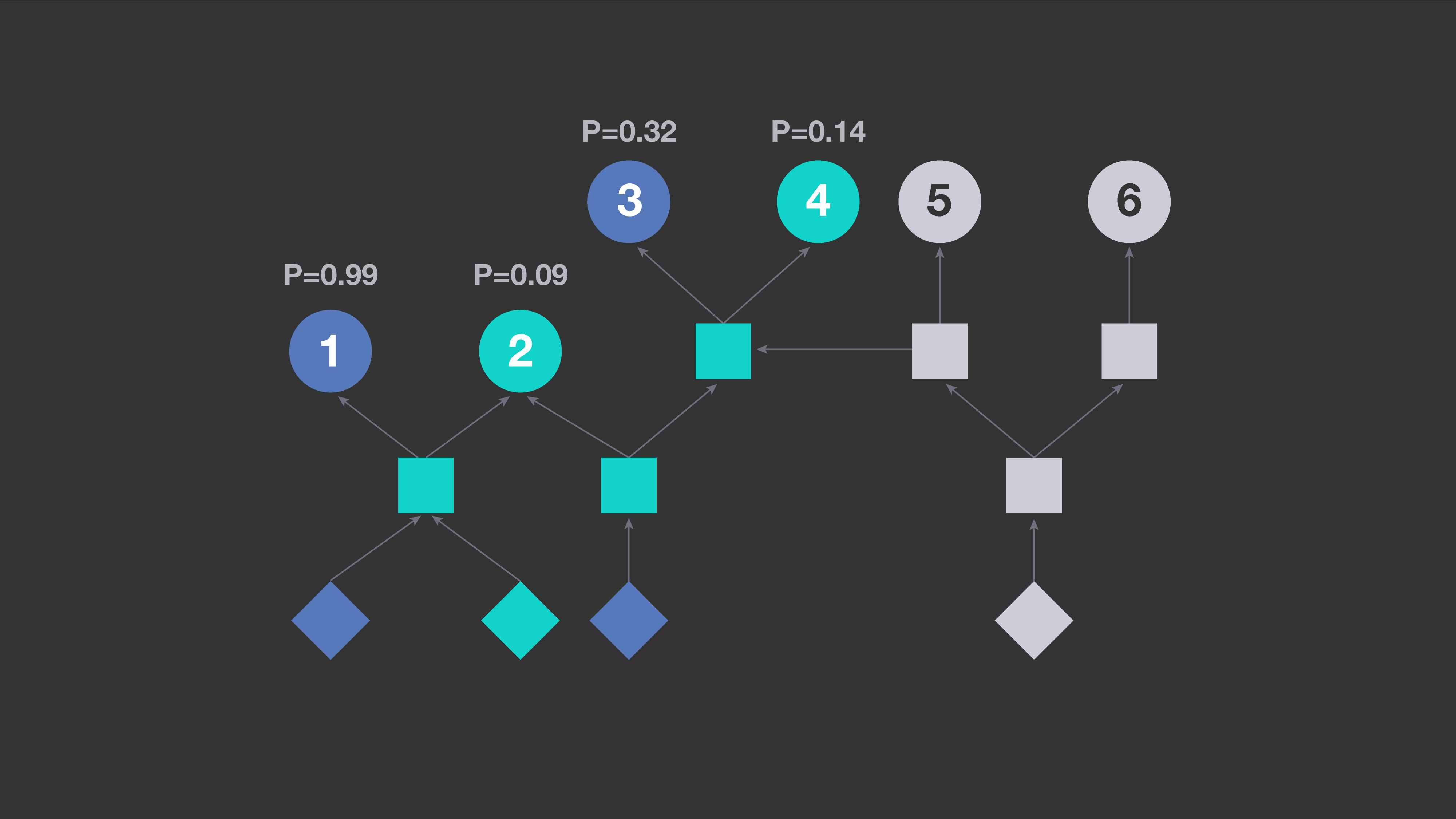
一种常见的回归测试方法是使用从编译元数据中提取的信息,来确定在特定代码改动上应该运行哪些测试。通过分析代码单元之间构建的依赖项,可以确定某次代码改动中传递性地依赖于源的修改的所有测试。例如,在下面的图中,圆形表示测试,正方形表示代码的中间单元,如库,菱形表示存储库中的单个源文件。当且仅当B直接依赖于A时,箭头连接实体A-\u0026gt;B,我们将其解释为A影响B。蓝色菱形表示在示例代码改动中修改的两个文件。所有传递依赖于它们的实体也以蓝色显示。在这个场景中,基于构建的依赖项的测试选择策略将执行测试1、2、3和4。但是测试5和6将不被执行,因为它们不依赖于修改的文件。
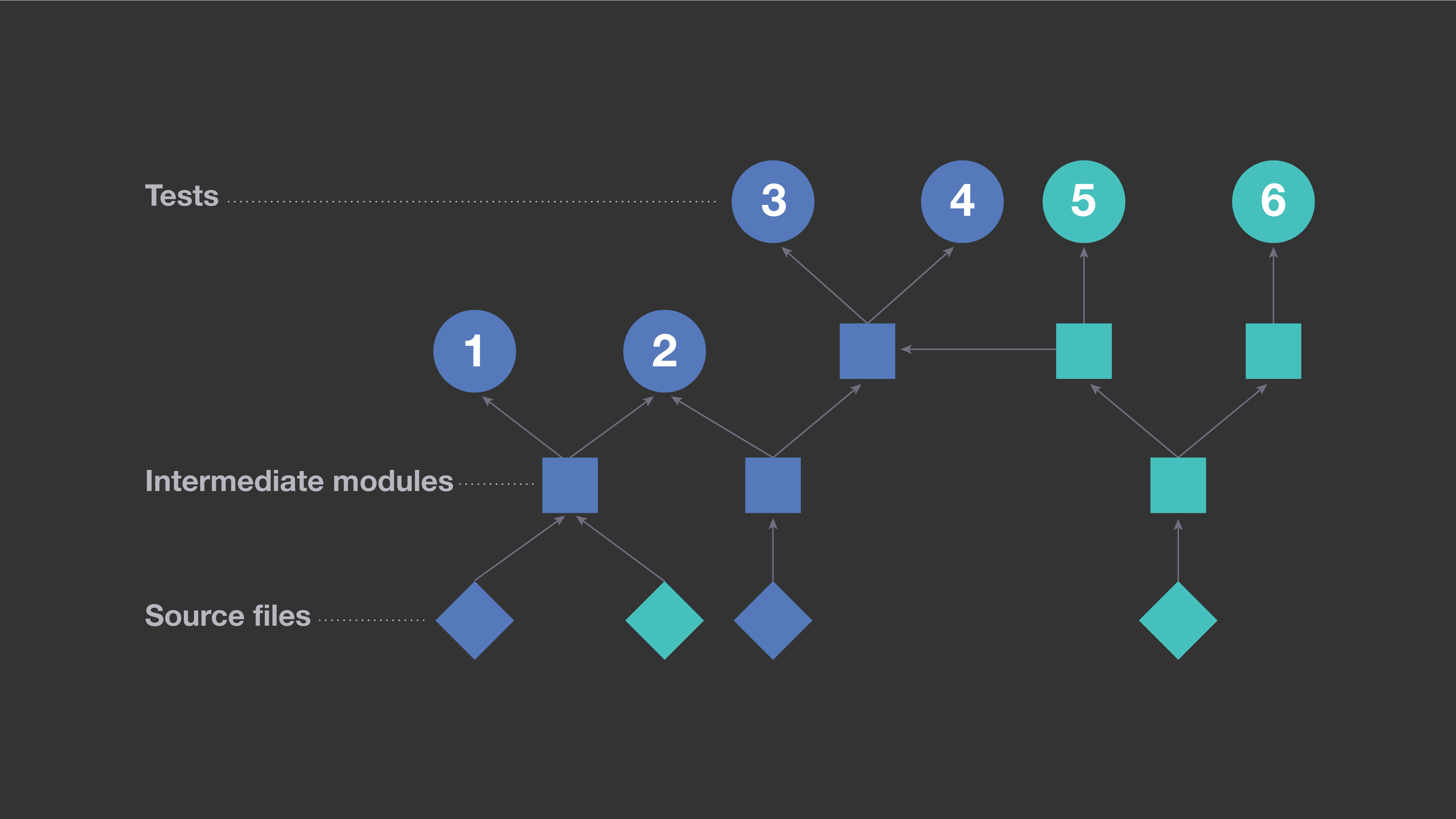
这种方法有一个明显的缺点,它最后表示“这个测试会受到影响”的频率比实际需要的要高。平均而言,对于移动代码库的每个改动,都会导致多达四分之一的可用测试被执行。如果所有依赖于修改文件的测试都是受到影响的,那么我们别无选择,只能执行每个测试。然而,在我们的单片代码库中,终端产品依赖于许多可重用的组件,这些组件使用一小组低级库。实际上,许多传递依赖项与回归测试无关。例如,当某个低级库发生更改时,对使用该库的每个项目重新运行所有测试是很低效的。
研究人员开发了其他的回归测试选择方法,例如基于静态变化-影响分析的方法。然而,由于我们的代码库较大,并且使用的编程语言种类繁多,这些技术在我们的案例中不太实用。
一种新方法:预测测试选择
基于构建的依赖项选择测试,需要知道哪些测试可能受到代码改动的影响。为了开发更好的方法,我们考虑一个不同的问题:给定的测试能发现特定代码改动产生的问题的可能性有多大?如果我们能正确估测出这一点,我们可以做出明智的决定,排除那些几乎不可能发现问题的测试。这是对传统测试选择方法的重大背离,并且开辟了一种新的、更有效的选择测试的方法。
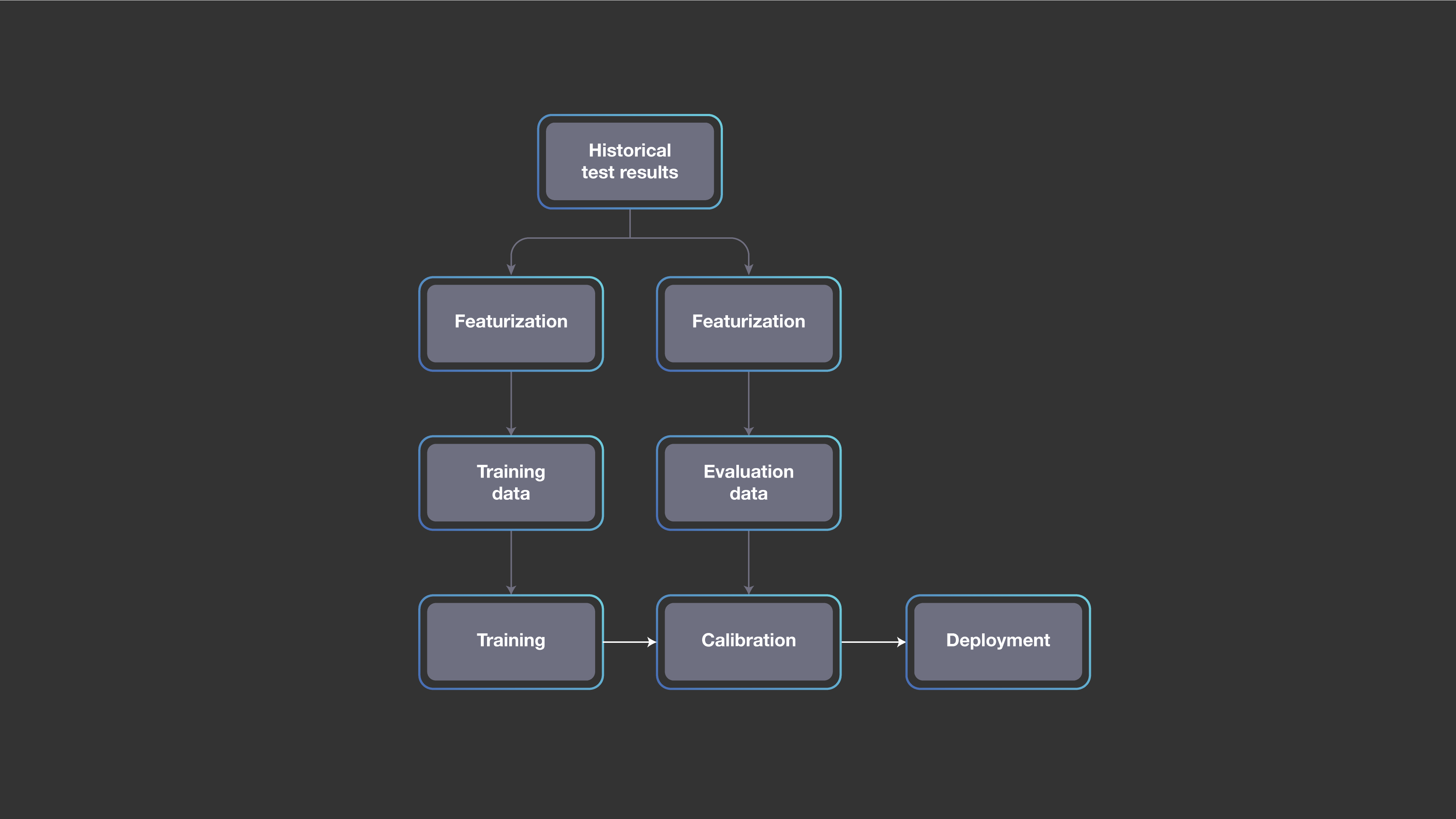
第一步,我们创建一个预测模型,估测对于新提出的代码改动,每个测试失败的概率。我们并不是手动定义模型,而是使用包含历史代码改动测试结果的大型数据集,然后应用标准的机器学习方法来构建模型。
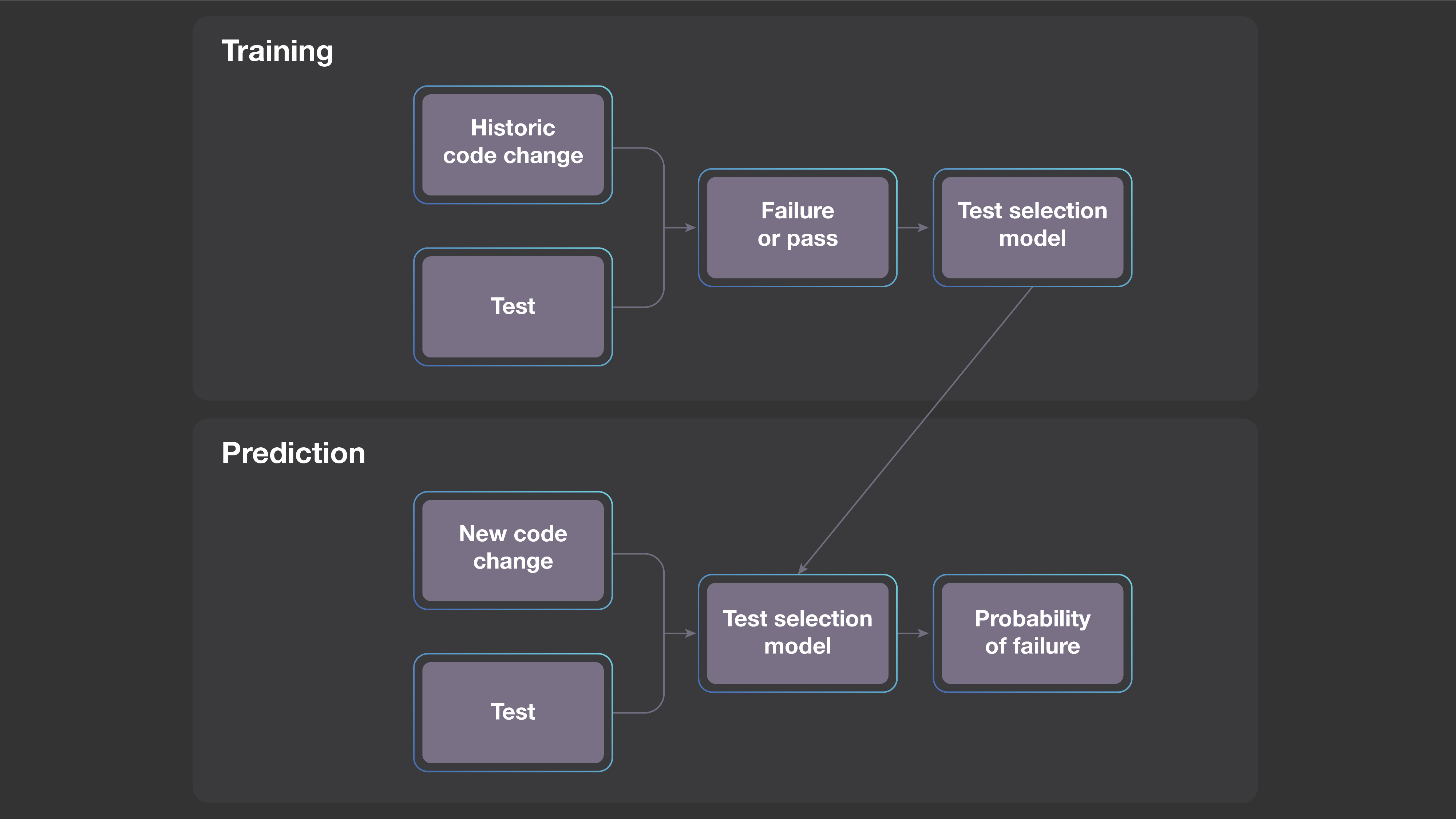
每次新的代码改动总是和以前的情况略有不同,因此模型不能简单地将新的改动与历史改动进行比较,以确定哪些测试值得运行。然而,对于新改动的抽象化结果可以与对应的一个或多个历史代码改动的抽象化结果类似。
在训练期间,系统利用先前的代码改动和测试中提取的特征学习一个模型。然后,当系统分析新的代码改动时,我们将学习到的模型应用于代码改动的基于特征的抽象化结果。对于任何特定的测试,模型便能够预测检测到回归问题出现的可能性。
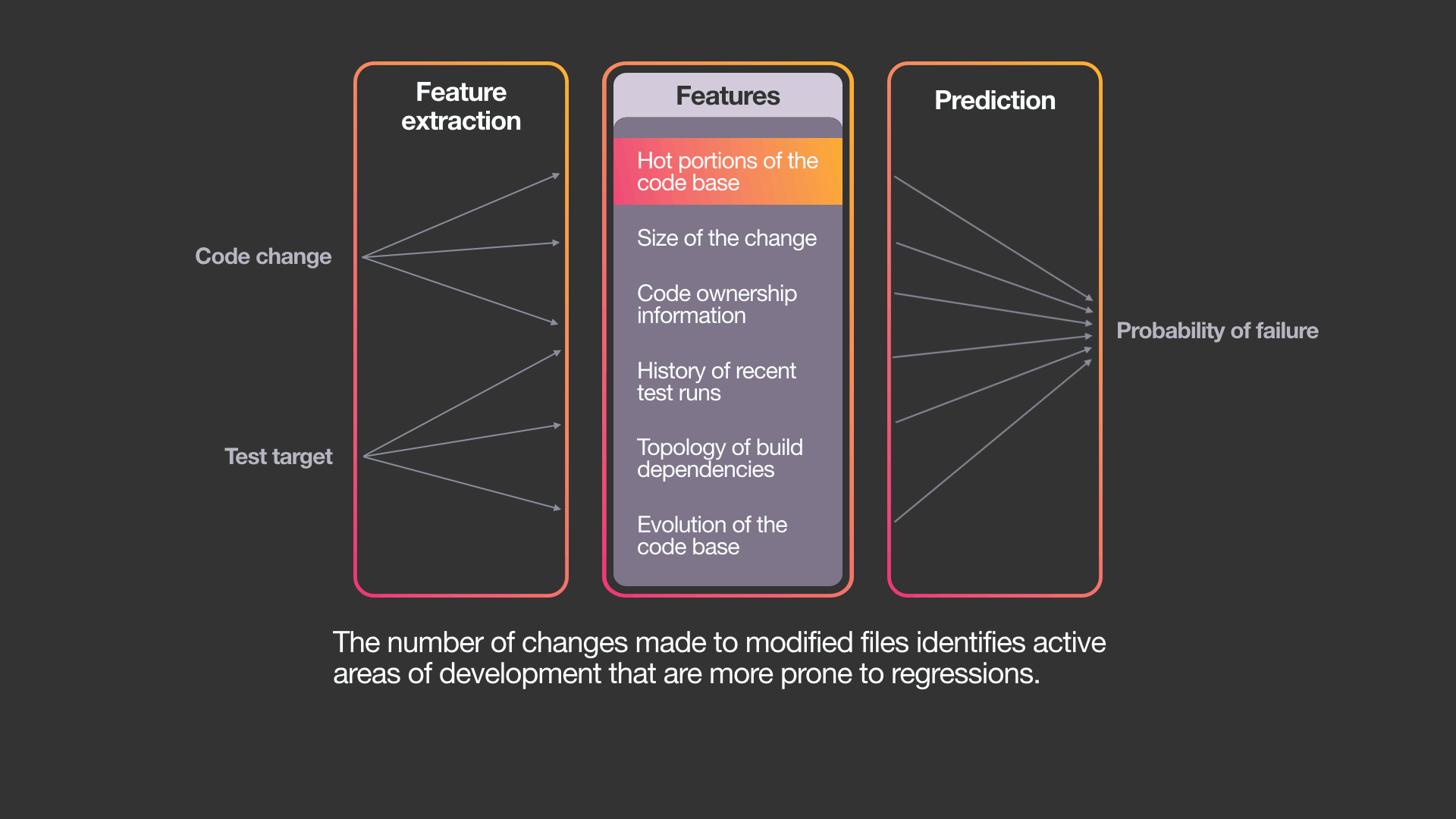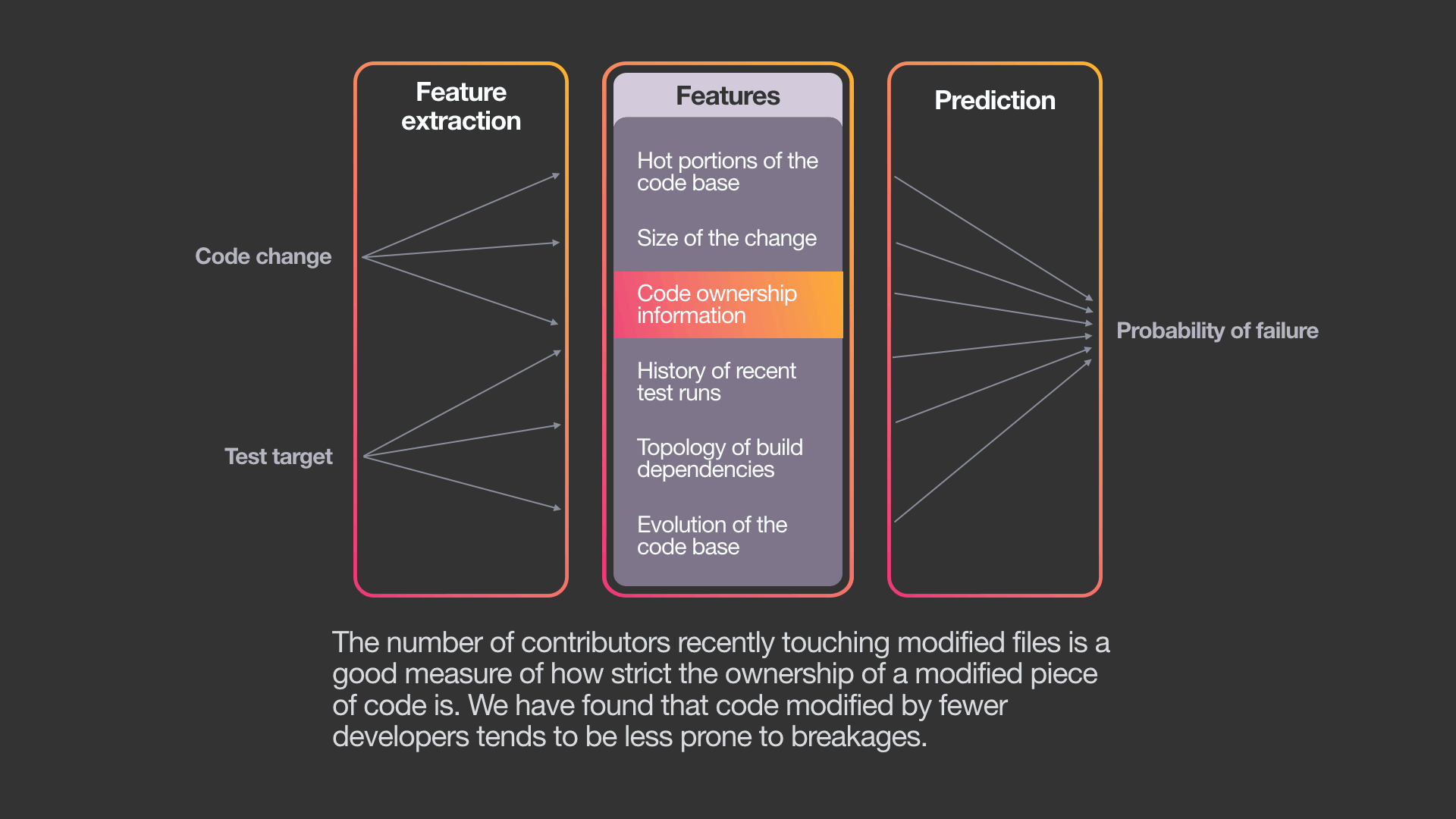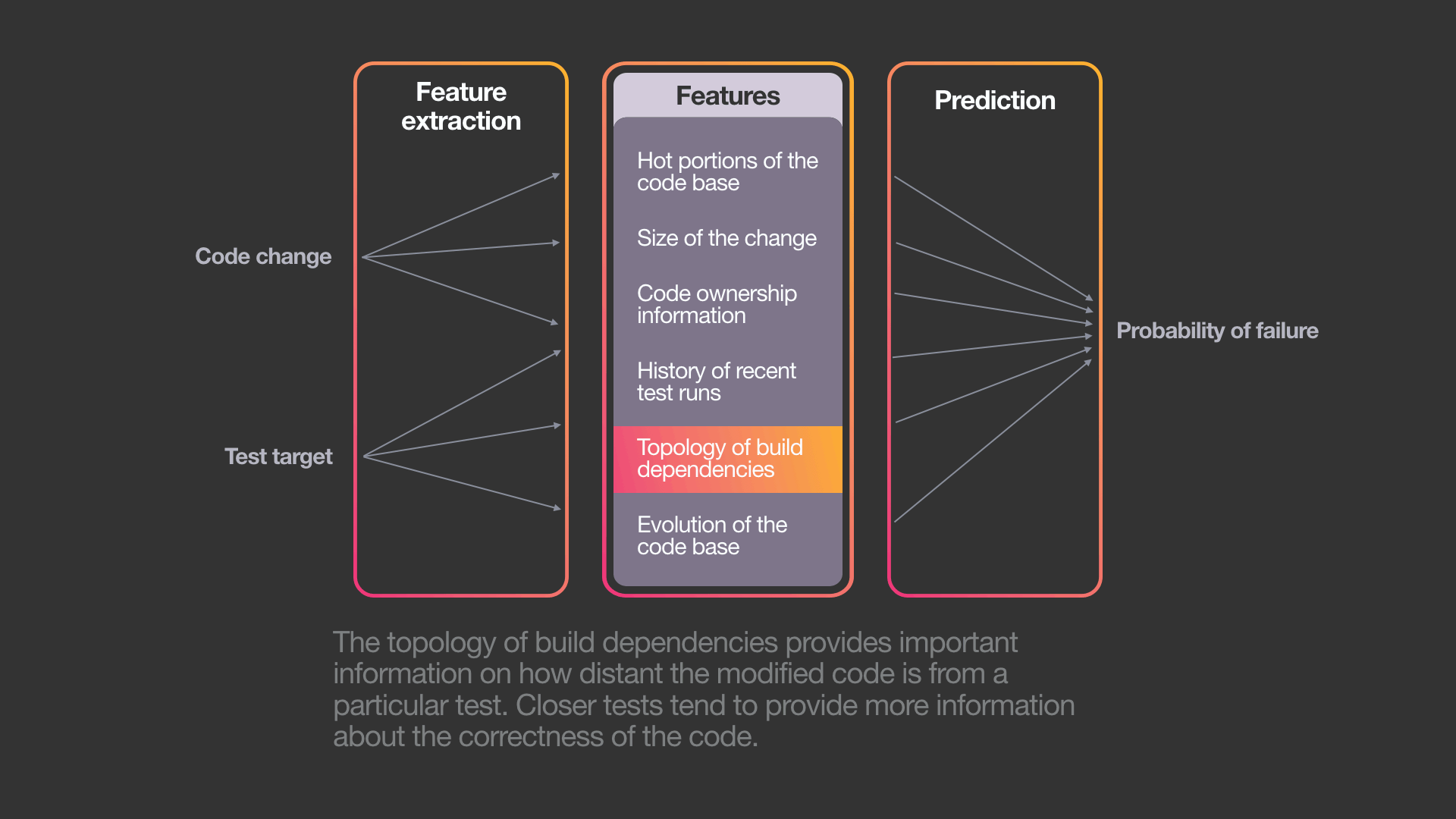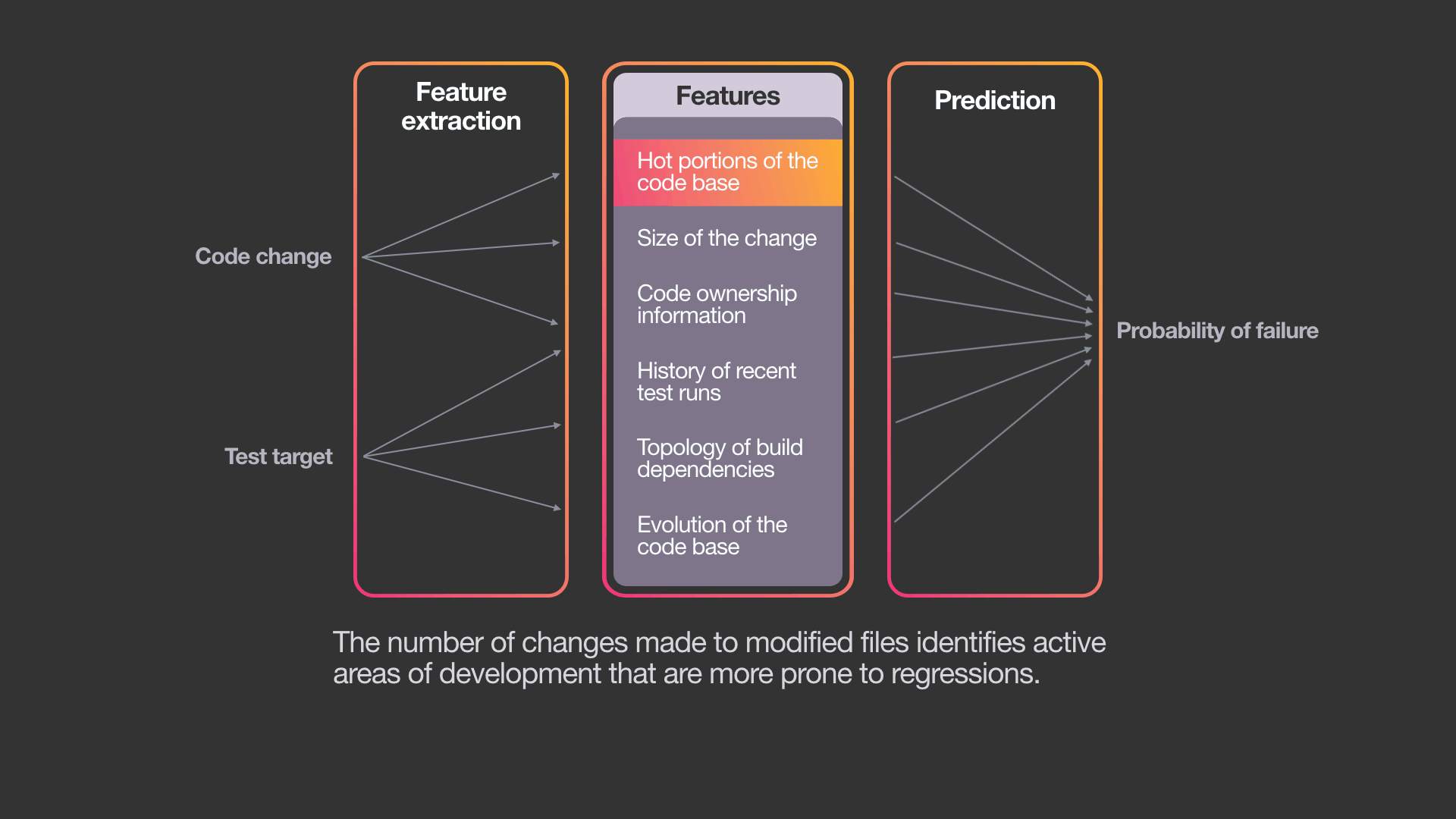
为此,系统使用了标准机器学习算法的变体——梯度增强决策树模型。虽然可以使用其他ML算法,但我们选择这种方法有以下几个原因:决策树是可解释的、易于训练的,并且已经是Facebook机器学习基础结构的一部分。
利用这个模型,我们可以分析特定的代码改动,以找到所有可能受影响的测试,这些测试传递地依赖于修改的文件,然后估计该测试能够检测出由改动引入问题的概率。基于这些估计,系统选择对于特定改动最有可能失败的测试。下图显示了为影响之前例子中两个文件的改动,将选择哪些测试(以蓝色显示),其中每个测试被选择的可能性由0到1之间的数字表示。
模型评价与校准
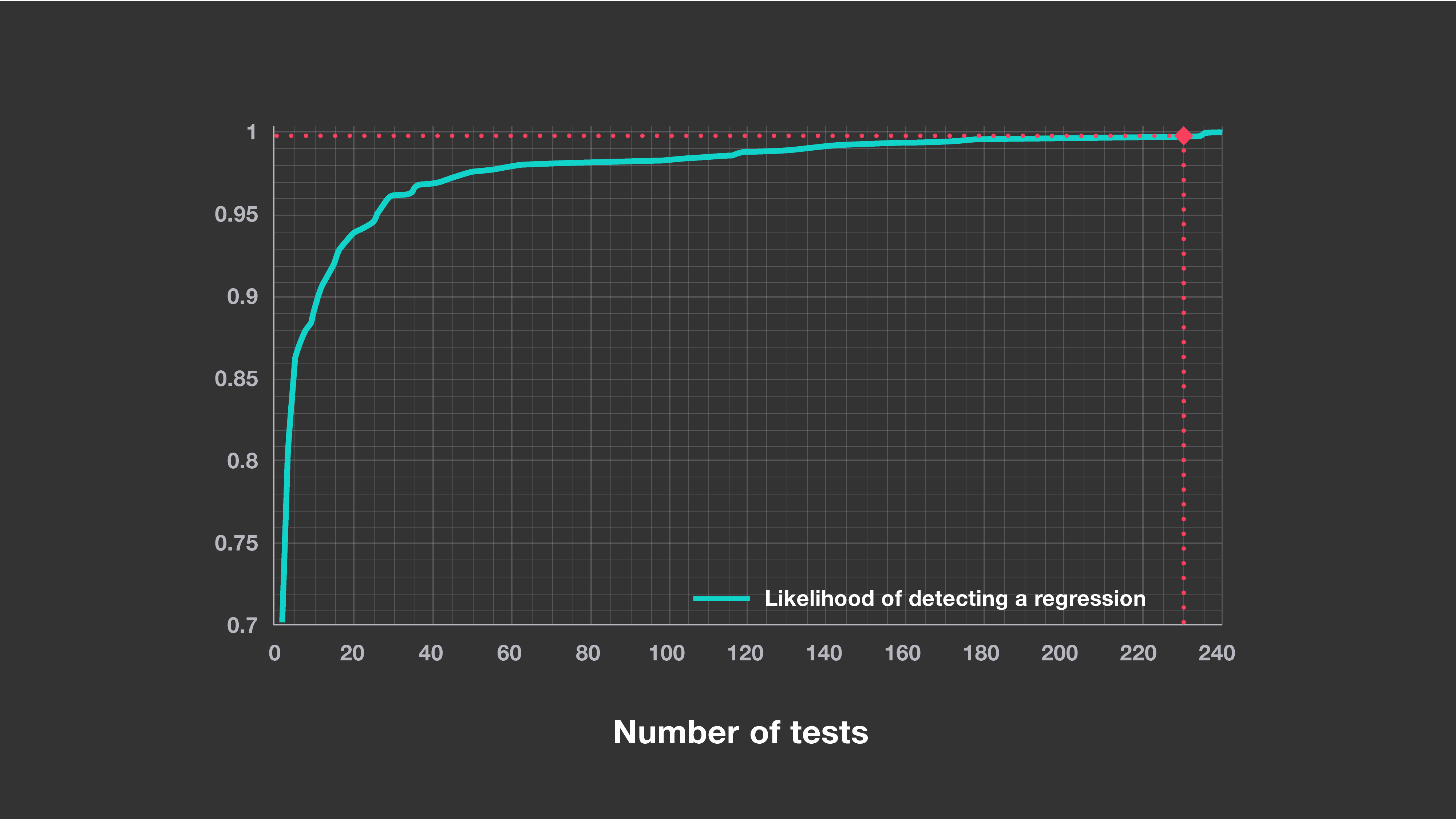
对于每一个代码改动,系统选择测试的数量会影响它在检测回归时的可靠性。使用最近的代码改动作为验证集,我们可以在新改动上评估其准确性。下图显示了每次改动要选择的最大测试数量与该选择的准确性之间的关系。在生产中,我们要求我们的模型能够正确地预测超过95%的测试结果,并且对于超过99.9%有问题的改动至少选择一个会失败的测试。我们发现,这种对精度的高标准导致测试信号的损失可以忽略不计,并且免除了大量不必要的测试。
由于代码库结构不断演变,测试选择策略必须自适应地更改,才能持续满足对正确性的严格要求。然而,对于我们的系统,这很简单,因为我们可以使用最近提交的代码改动的测试结果定期重新训练模型。
解决测试异常
为了确保我们的测试选择在真实情况下可以工作良好,系统需要解决测试异常的问题,即被测试的代码实际上没有改变时,测试结果却从通过变为失败。如果我们训练模型时不识别异常测试的失败情况,会影响模型学习预测测试结果的一致性。在下面的示例中,两个测试选择策略捕捉了所有失败测试的同比例样例。如果系统不能区分哪些测试失败是异常的,哪些不是,那么它将无法知道哪个策略是最好的。策略A具有更好的准确性,因为它捕获了所有发现实际问题的测试。然而,策略B选择了许多由于异常性而不是由于代码的实际问题而导致失败的测试。
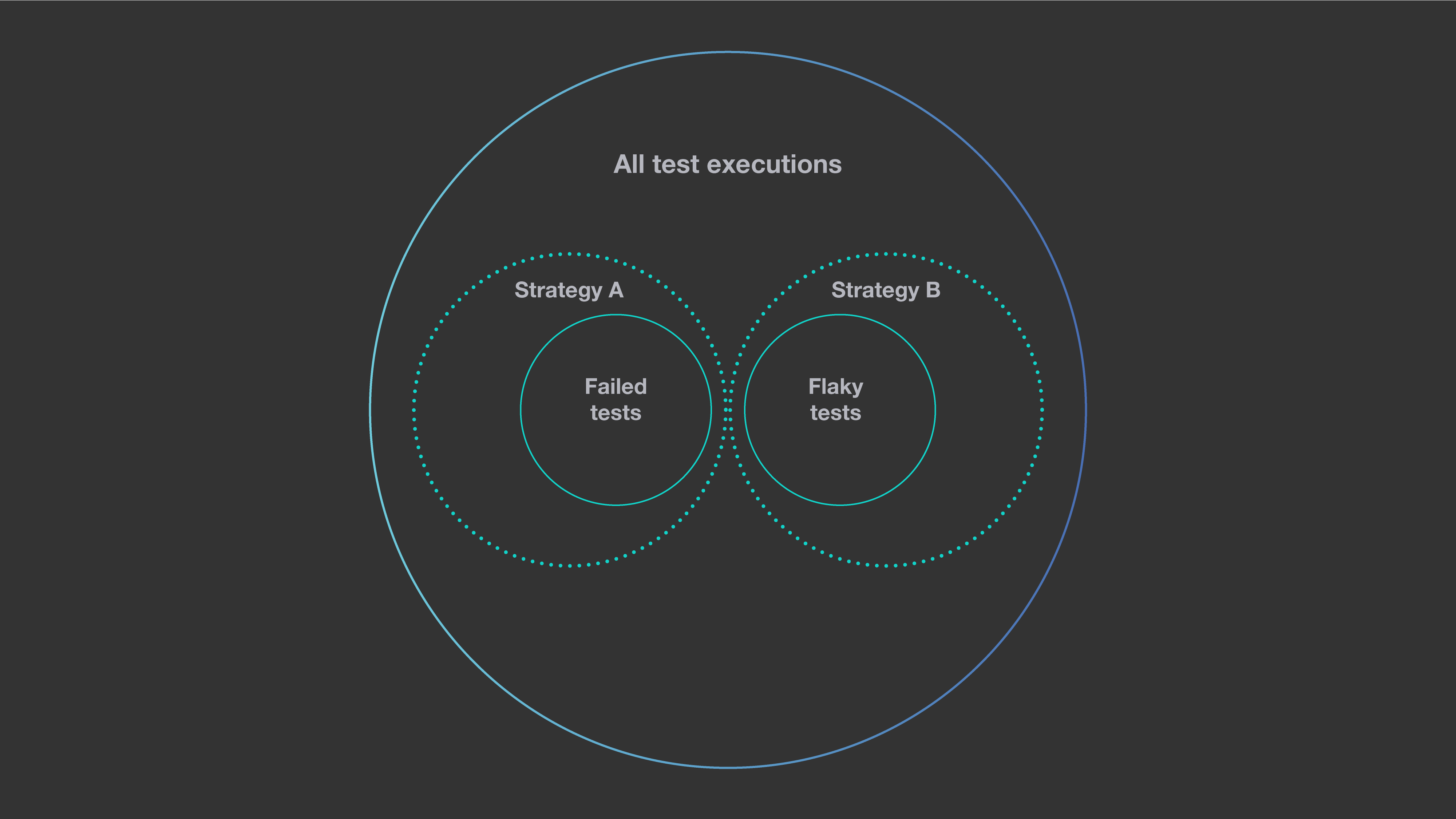
为了减轻异常性对学习测试选择模型的影响,我们在收集训练数据时不断地重试失败的测试。这种方法可以让我们将一致性失败(代表代码真正的问题)的测试与表现异常、不可再现的测试失败区分开来。
检测和确定问题
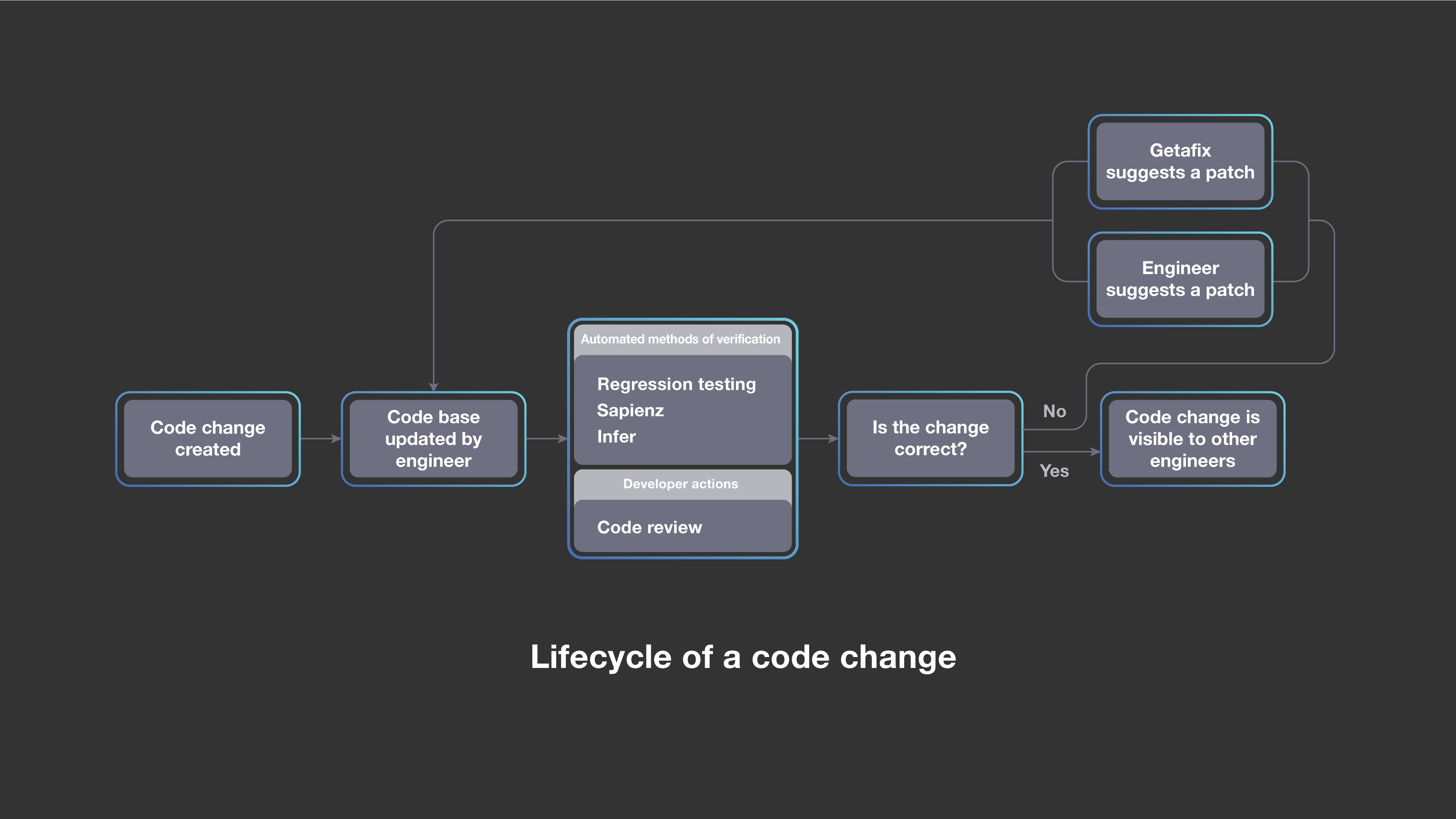
这个系统是我们构建智能工具以使代码开发过程更加可靠和有效的一部分。Sapienz,我们的基于搜索的自动化软件测试系统,以及Getafix,我们的自动bug修复工具,也帮助我们自动检测和修复回归问题——也就是说,工程师们只需要花费很少甚至完全不需要花费精力。
预测性测试选择(本博客中描述的系统)通过选择工程师定义的测试的正确子集来有效地检测回归。Sapienz生成新的测试序列,该序列揭示了移动应用程序崩溃的条件,Getafix对由我们的测试和验证工具发现的问题给出补丁建议,然后由编写改动的工程师进行评审,并且选择接受或拒绝。总之,这些系统使工程师们能够为使用Facebook产品的数十亿人更快、更有效地创建和部署产品新特性。
未来计划
预测性测试选择是Facebook的几个项目之一,旨在应用统计学方法和机器学习来提高回归测试的有效性。随着我们进一步提高系统的效率和准确性,我们也在应用相关的方法来识别测试覆盖中的潜在差距。
机器学习正在改变生活的方方面面,我们相信软件工程也不会例外。
查看英文原文:Predictive test selection: A more efficient way to ensure reliability of code changes
会议推荐:12月20-21,AICon将于北京开幕,在这里可以学习来自Google、微软、BAT、360、京东、美团等40+AI落地案例,与国内外一线技术大咖面对面交流。
省掉1/3的回归测试:Facebook用机器学习自动选择测试策略相关推荐
- 机器学习如何选择模型 机器学习与数据挖掘区别 深度学习科普
今天看到这篇文章里面提到如何选择模型,觉得非常好,单独写在这里. 更多的机器学习实战可以看这篇文章:http://www.cnblogs.com/charlesblc/p/6159187.html 另 ...
- 使用Hyperopt实现机器学习自动调参
文章目录 机器学习自动调参 1. Hyperopt **Hyperopt搜索参数空间** 参数空间的设置 使用sample函数从参数空间内采样: 在参数空间内使用函数: **指定搜索的算法** 实例 ...
- 机器学习模型 知乎_机器学习-模型选择与评价
交叉验证 首先选择模型最简单的方法就是,利用每一种机器学习算法(逻辑回归.SVM.线性回归等)计算训练集的损失值,然后选择其中损失值最小的模型,但是这样是不合理的,因为当训练集不够.特征过多时容易过拟 ...
- 回归测试概念和4种回归测试策略——你想知道的都在这里啦!
前言: 回归测试是指修改了旧代码后,重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误.自动回归测试将大幅降低系统测试.维护升级等阶段的成本.回归测试作为软件生命周期的一个组成部分,在整个软 ...
- 如何为你的机器学习问题选择合适的算法?
机器学习算法选择速查 机器学习算法选择速查表介绍 机器学习算法速查使用指南 随着机器学习越来越流行,也出现了越来越多能很好地处理任务的算法.但是,你不可能预先知道哪个算法对你的问题是最优的.如果你有足 ...
- 使用TPOT自动选择scikit-learn机器学习模型和参数
声明:原文地址:使用TPOT自动选择scikit-learn机器学习模型和参数,此文是本人学习原文的结果,略有改动.侵删. 在上一篇博客中我们在anacoda中安装了tpot: anacoda下安装T ...
- TPOT自动选择机器学习模型和参数--回归示例
前两篇博客写了在anacoda下安装tpot库和使用tpot做分类的例子,这篇是写做回归的例子 anacoda下安装tpot库 使用TPOT自动选择scikit-learn机器学习模型和参数--分类示 ...
- Facebook 应用机器学习团队专访:人工智能在 Facebook 中的应用
当下,应用机器学习团队(Applied Machine Learning Group)对 Facebook 的影响体现在方方面面,涉及阅读.交流方法和理解方式等多种层面.同时,应用机器学习团队甚至还能 ...
- Facebook使用机器学习手段来自动优化其系统性能
在 Facebook 数十亿用户眼里,Facebook 的服务看起来就像是一个统一的移动 App 或网站.但从公司内部看,却有着不同的视角.Facebook 提供了数千种服务,功能包罗万象,从均衡互联 ...
最新文章
- SQL的不合理有效性
- Java数据库连接池实现原理
- 约数研究pascal程序
- java 单例 饿汉式_Java-单例设计模式(懒汉与饿汉)
- The Coding Kata: FizzBuzzWhizz in Modern C++11
- 专家视角 | 小荷的 Oracle Database 18c 新特性快速一瞥
- 求斐波那契数列第n位的几种实现方式及性能对比(c#语言)
- VMware 虚拟机克隆 CentOS 6.5 之后,网络配置问题的解决方案
- MyBatis Plus EntityWarpper参数的介绍
- ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defi
- Linux下的Nginx安装(开机自启动)
- 5V转±12V无变压器双boost电路
- RINEX 3.02版本文件格式介绍
- fastjason 0day 漏洞修复
- npm启动报错——端口被占用
- 电脑软件:主流的压缩软件对比,看完你就会选择了
- 机器学习03:人工神经网络
- Python海龟画图 画一个爱心 赶快给女朋友来一个
- 2019全国大众点评数据更新
- delta和gamma中性_套期保值中性技术操作之构建delta—gamma中性